- 什么是POD?
- POD有以下特点:
- 为什么使用POD作为最小单元,而不是container
- 为什么允许一个POD里有多个容器
- POD中如何管理多个容器
- POD的yaml格式定义配置文件说明
- 如何使用Pod
- POD的持久性和终止
- Pause
- 我们首先在节点上运行一个pause容器
- 然后再运行一个nginx容器,nginx将为localhost:2368创建一个代理。
- 然后再为ghost创建一个应用容器
- Pod中共享的名称空间:
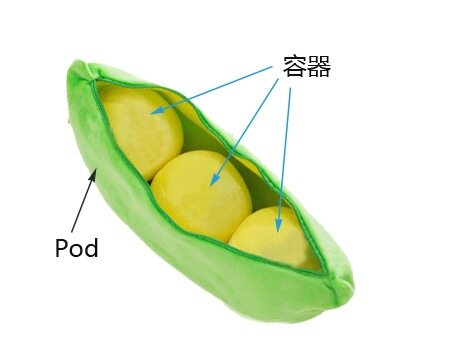
什么是POD?
kubernetes中的一切都可以理解为是一种资源对象,POD,rc,service,都可以理解是 一种资源对象。POD的组成示意图如下,由一个叫”pause“的根容器,加上一个或多个用户自定义的容器构造。pause的状态带便了这一组容器的状态,POD里多个业务容器共享POD的Ip和数据卷。在kubernetes环境下,POD是容器的载体,所有的容器都是在POD中被管理,一个或多个容器放在POD里作为一个单元方便管理

POD有以下特点:
- 一个POD可以理解为一个应用实例,提供服务;
- POD中容器始终部署在同一个Node上;
- POD中容器共享网络,存储资源;
- Kubernetes直接管理POD,而不是容器;
在POD的生命周期中,POD被创建后,被分配一个唯一的ID(UID),调度到节点上,并一致维持期望的状态直到被终结(根据重启策略)或者被删除。如果node死掉了,分配到了这个node上的POD,在经过一个超时时间后会被重新调度到其他node节点上。一个给定的POD(如UID定义的)不会被“重新调度”到新的节点上,而是被一个同样的POD取代,如果期望的话甚至可以是相同的名字,但是会有一个新的UID(查看replication controller获取详情)。
为什么使用POD作为最小单元,而不是container
直接部署一个容器看起来更简单,但是这里也有更好的原因为什么在容器基础上抽象一层呢?根本原因是为了管理容器,kubernetes需要更多的信息,比如重启策略,它定义了容器终止后要采取的策略;或者是一个可用性探针,从应用程序的角度去探测是否一个进程还存活着。基于这些原因,kubernetes架构师决定使用一个新的实体,也就是POD,而不是重载容器的信息添加更多属性,用来在逻辑上包装一个或者多个容器的管理所需要的信息。
为什么允许一个POD里有多个容器
POD里的容器运行在一个逻辑上的"主机"上,它们使用相同的网络名称空间 (即同一POD里的容器使用相同的ip和相同的端口段区间) 和相同的IPC名称空间。它们也可以共享存储卷。这些特性使它们可以更有效的通信,并且POD可以使你把紧密耦合的应用容器作为一个单元来管理。也就是说当多个应用之间是紧耦合关系时,可以将多个应用一起放在一个POD中,同个POD中的多个容器之间互相访问可以通过localhost来通信(可以把POD理解成一个虚拟机,共享网络和存储卷)。
因此当一个应用如果需要多个运行在同一主机上的容器时,为什么不把它们放在同一个容器里呢?首先,这样何故违反了一个容器只负责一个应用的原则。这点非常重要,如果我们把多个应用放在同一个容器里,这将使解决问题变得非常麻烦,因为它们的日志记录混合在了一起,并且它们的生命周期也很难管理。因此一个应用使用多个容器将更简单,更透明,并且使应用依赖解偶。并且粒度更小的容器更便于不同的开发团队共享和复用。
POD中如何管理多个容器
POD中可以同时运行多个进程(作为容器运行)协同工作,同一个POD中的容器会自动的分配到同一个 node 上,同一个POD中的容器共享资源、网络环境和依赖,它们总是被同时调度。
POD中共享的环境包括Linux的namespace,cgroup和其他可能的隔绝环境,这一点跟Docker容器一致。在POD的环境中,每个容器中可能还有更小的子隔离环境。POD中的容器共享IP地址和端口号,它们之间可以通过localhost互相发现。它们之间可以通过进程间通信,需要明白的是同一个POD下的容器是通过lo网卡进行通信。例如SystemV信号或者POSIX共享内存。不同POD之间的容器具有不同的IP地址,不能直接通过IPC通信。POD中的容器也有访问共享volume的权限,这些volume会被定义成POD的一部分并挂载到应用容器的文件系统中。
总而言之。POD中可以共享两种资源:网络 和 存储
- 网络:每个POD都会被分配一个唯一的IP地址。POD中的所有容器共享网络空间,包括IP地址和端口。POD内部的容器可以使用localhost互相通信。POD中的容器与外界通信时,必须分配共享网络资源(例如使用宿主机的端口映射)。
- 存储:可以POD指定多个共享的Volume。POD中的所有容器都可以访问共享的volume。Volume也可以用来持久化POD中的存储资源,以防容器重启后文件丢失。
POD的yaml格式定义配置文件说明
apiVersion: v1 # 必选,版本号
kind: Pod # 必选,Pod
metadata: # 必选,元数据name: nginx-pod # 必选,Pod名称namespace: default # 必选,Pod所属的命名空间labels: # 可选,自定义标签,Map格式app: nginx # 标签键值对annotations: # 可选,自定义注解description: "Nginx web server" # 注解,用于描述该Pod
spec: # 必选,Pod中容器的详细属性containers: # 必选,Pod中容器列表- name: nginx # 必选,容器名称image: nginx:1.21.6 # 必选,容器的镜像地址和名称imagePullPolicy: IfNotPresent # 获取镜像的策略command: ["/bin/sh", "-c"] # 容器的启动命令列表(覆盖)args: ["echo Hello Kubernetes!"] # 容器的启动命令参数列表workingDir: /usr/share/nginx/html # 容器的工作目录volumeMounts: # 挂载到容器内部的存储卷配置- name: nginx-config-volume # 引用Pod.spec.volumes[]中定义的共享存储卷的名称mountPath: /etc/nginx # 存储卷在容器内挂载的绝对路径readOnly: true # 设置为只读模式ports: # 容器需要暴露的端口列表- name: http # 端口名称containerPort: 80 # 容器需要监听的端口号hostPort: 8080 # 容器所在主机需要监听的端口号env: # 容器运行前需设置的环境变量列表- name: NGINX_PORT # 环境变量名称value: "80" # 环境变量的值resources: # 资源限制和请求的设置limits: # 资源限制的设置cpu: "500m" # CPU限制,单位为Core数memory: "512Mi" # 内存限制,单位为MiBrequests: # 资源请求的设置cpu: "250m" # CPU请求,容器启动的初始可用数量memory: "256Mi" # 内存请求,容器启动的初始可用数量livenessProbe: # 对Pod中容器的健康检查设置httpGet: # 设置为 HttpGet 检查方式path: / # URL路径port: 80 # 对应端口initialDelaySeconds: 10 # 容器启动完成后首次探测的时间,单位为秒timeoutSeconds: 5 # 健康检查探测的超时时间,单位为秒periodSeconds: 15 # 健康检查的定期探测时间间隔,单位为秒successThreshold: 1 # 成功探测几次后认为健康failureThreshold: 3 # 失败探测几次后认为不健康securityContext: # 安全上下文设置privileged: false # 是否使用特权模式restartPolicy: Always # Pod的重启策略nodeSelector: # NodeSelector调度,指定Pod调度到具有特定标签的Node上disktype: ssd # 标签的键值对imagePullSecrets: # Pull镜像时使用的Secret名称- name: myregistrykey # Secret名称hostNetwork: false # 是否使用主机网络模式volumes: # 在该Pod上定义的共享存储卷列表- name: nginx-config-volume # 共享存储卷名称configMap: # 类型为ConfigMap的存储卷name: nginx-config # 绑定的ConfigMap名称items: # 如果仅需挂载ConfigMap对象中的指定Key时使用- key: nginx.confpath: nginx.conf
如何使用Pod
通常把POD分为两类:
- 自主式POD :这种POD本身是不能自我修复的,当POD被创建后(不论是由你直接创建还是被其他Controller),都会被Kuberentes调度到集群的Node上。直到POD的进程终止、被删掉、因为缺少资源而被驱逐、或者Node故障之前这个POD都会一直保持在那个Node上。POD不会自愈。如果POD运行的Node故障,或者是调度器本身故障,这个POD就会被删除。同样的,如果POD所在Node缺少资源或者POD处于维护状态,POD也会被驱逐。
- 控制器管理的POD:Kubernetes使用更高级的称为Controller的抽象层,来管理POD实例。Controller可以创建和管理多个POD,提供副本管理、滚动升级和集群级别的自愈能力。例如,如果一个Node故障,Controller就能自动将该节点上的POD调度到其他健康的Node上。虽然可以直接使用POD,但是在Kubernetes中通常是使用Controller来管理POD的。如下图:
每个POD都有一个特殊的被称为"根容器"的Pause 容器。 Pause容器对应的镜像属于Kubernetes平台的一部分,除了Pause容器,每个POD还包含一个或者多个紧密相关的用户业务容器。
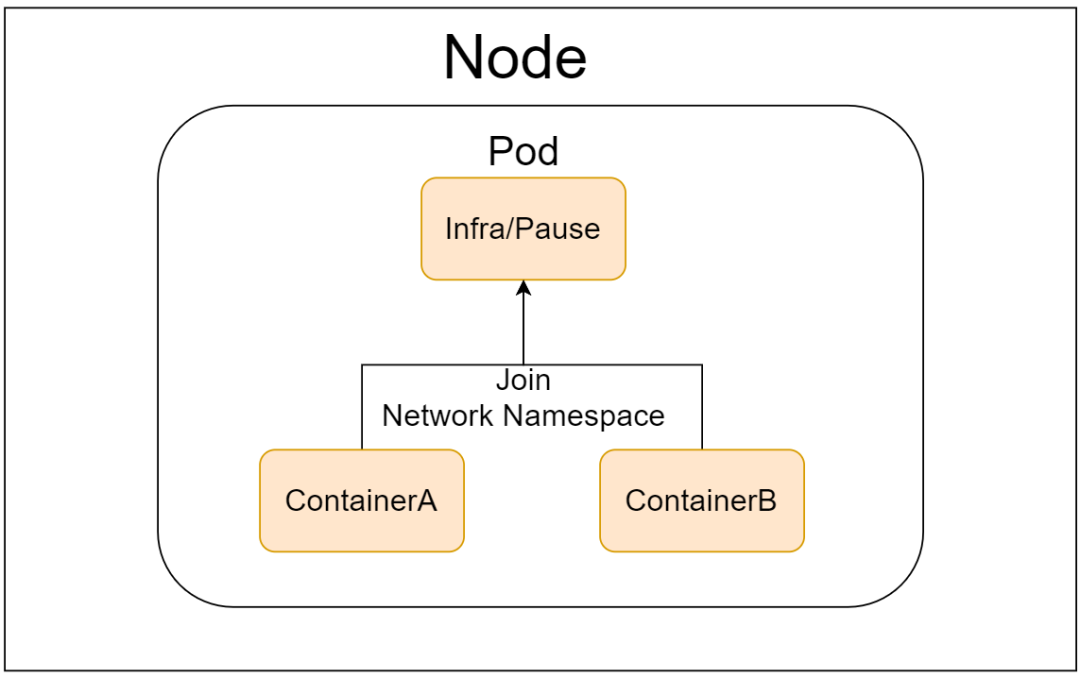
Kubernetes设计这样的POD概念和特殊组成结构有什么用意呢?
原因一:在一组容器作为一个单元的情况下,难以对整体的容器简单地进行判断及有效地进行行动。比如一个容器死亡了,此时是算整体挂了么?那么引入与业务无关的Pause容器作为POD的根容器,以它的状态代表着整个容器组的状态,这样就可以解决该问题。
原因二:POD里的多个业务容器共享Pause容器的IP,共享Pause容器挂载的Volume,这样简化了业务容器之间的通信问题,也解决了容器之间的文件共享问题。
POD的持久性和终止
Pod的持久性
- Pod在设计上就不是作为持久化实体的。在调度失败、节点故障、缺少资源或者节点维护的状态下都会死掉会被驱逐。通常,用户不需要手动直接创建Pod,而是应该使用controller(例如Deployments),即使是在创建单个Pod的情况下。Controller可以提供集群级别的自愈功能、复制和升级管理。
Pod的终止
- 因为Pod作为在集群的节点上运行的进程,所以在不再需要的时候能够优雅的终止掉是十分必要的(比起使用发送KILL信号这种暴力的方式)。用户需要能够放松删除请求,并且知道它们何时会被终止,是否被正确的删除。用户想终止程序时发送删除pod的请求,在pod可以被强制删除前会有一个宽限期,会发送一个TERM请求到每个容器的主进程。一旦超时,将向主进程发送KILL信号并从API server中删除。如果kubelet或者container manager在等待进程终止的过程中重启,在重启后仍然会重试完整的宽限期。
示例流程如下:
- 用户发送删除Pod的命令,默认宽限期是30秒;
- 在Pod超过该宽限期后API server就会更新Pod的状态为"dead";
- 在客户端命令行上显示的Pod状态为"terminating";
- 跟第三步同时,当kubelet发现pod被标记为"terminating"状态时,开始停止pod进程:
- 如果在pod中定义了preStop hook,在停止pod前会被调用。如果在宽限期过后,preStop hook依然在运行,第二步会再增加2秒的宽限期;
- 向Pod中的进程发送TERM信号;
- 跟第三步同时,该Pod将从该service的端点列表中删除,不再是replication controller的一部分。关闭的慢的pod将继续处理load balancer转发的流量;
- 过了宽限期后,将向Pod中依然运行的进程发送SIGKILL信号而杀掉进程。
- Kublete会在API server中完成Pod的的删除,通过将优雅周期设置为0(立即删除)。Pod在API中消失,并且在客户端也不可见。
删除宽限期默认是30秒。 kubectl delete命令支持 --grace-period= 选项,允许用户设置自己的宽限期。如果设置为0将强制删除pod。在kubectl>=1.5版本的命令中,你必须同时使用 --force 和 --grace-period=0 来强制删除pod。
Pod的强制删除是通过在集群和etcd中将其定义为删除状态。当执行强制删除命令时,API server不会等待该pod所运行在节点上的kubelet确认,就会立即将该pod从API server中移除,这时就可以创建跟原pod同名的pod了。这时,在节点上的pod会被立即设置为terminating状态,不过在被强制删除之前依然有一小段优雅删除周期。【需要注意:如果删除一个pod后,再次查看发现pod还在,这是因为在deployment.yaml文件中定义了副本数量!还需要删除deployment才行。即:"kubectl delete pod pod-name -n namespace" && "kubectl delete deployment deployment-name -n namespace"】
Pause
Pause容器,又叫Infra容器。我们检查node节点的时候会发现每个node节点上都运行了很多的pause容器,例如如下:
[root@master01 ~]# docker ps |grep pause
b64743cdafc3 registry.cn-hangzhou.aliyuncs.com/google_containers/pause:3.5 "/pause" 3 seconds ago Up 2 seconds k8s_POD_coredns-5db5696c7-hzmz8_kube-system_e6731c9d-b869-478c-bd92-4ab0269100d0_16
11cda9acfeeb registry.cn-hangzhou.aliyuncs.com/google_containers/pause:3.5 "/pause" 3 seconds ago Up 3 seconds k8s_POD_cluster-test-8b47d69f5-ztp8g_default_f799a8b6-7f57-4545-9cca-10a65125e2c0_9
9f9aa4eb7b44 registry.cn-hangzhou.aliyuncs.com/google_containers/pause:3.5 "/pause" 4 seconds ago Up 4 seconds k8s_POD_metrics-server-6bf7dcd649-vbswr_kube-system_ee301025-6f64-4b1d-a45a-93ee54ed677e_8
d6033bb2d90f registry.cn-hangzhou.aliyuncs.com/google_containers/pause:3.5 "/pause" 28 seconds ago Up 27 seconds k8s_POD_calico-node-vwgvd_kube-system_d9db971a-dc40-4330-bf87-826fcb13654e_12
 kubernetes中的pause容器主要为每个业务容器提供以下功能:
kubernetes中的pause容器主要为每个业务容器提供以下功能:
- 在pod里担任与其他容器
namespace共享的基础; - 启用pid命名空间,开启init进程,负责处理僵尸进程。
(注意:这里虽然开启了PID名称空间共享,但是在Kubelet中--docker-disable-shared-pid=true关闭了PID共享,所以Pod中的每个容器都将具有自己的PID 1,并且每个容器将需要自己处理僵尸进程)
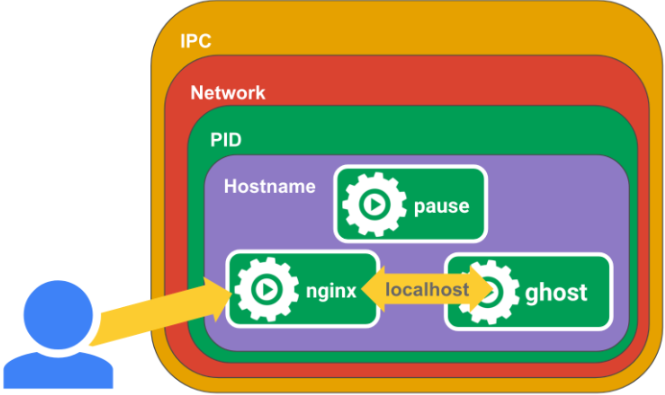
我们首先在节点上运行一个pause容器
[root@node01 ~]# docker run -d --name pause --ipc=shareable -p 8880:80 registry.cn-hangzhou.aliyuncs.com/google_containers/pause-amd64:3.1
c535b224ad280c600c761483543128b1a10a12776b8deceb35bda750c8a9a10a
然后再运行一个nginx容器,nginx将为localhost:2368创建一个代理。
[root@node01 ~]# cat <<EOF >> nginx.conf
error_log stderr;
events { worker_connections 1024; }
http {access_log /dev/stdout combined;server {listen 80 default_server;server_name example.com www.example.com;location / {proxy_pass http://127.0.0.1:2368;}}
}
EOF[root@node01 ~]# docker run -d --name nginx -v `pwd`/nginx.conf:/etc/nginx/nginx.conf --net=container:pause --ipc=container:pause --pid=container:pause nginx
8651621e55ac24d8470eb43077397af08ca1e0090301b6f9bb30902535e5936e
然后再为ghost创建一个应用容器
[root@oracle ~]# docker run -d --name ghost --net=container:pause --ipc=container:pause --pid=container:pause ghost:2.7.1
Unable to find image 'ghost:2.7.1' locally
2.7.1: Pulling from library/ghost
Digest: sha256:727f18f41e0835f673c23d037ee3f56f3bfeaca8e7bfbabdd803107c2e35839f
Status: Downloaded newer image for ghost:2.7.1
c479167c5577994b9c455343e88f9d9a14762f4c1840851aaf56429ed131ff5c
解析:
- pause 容器将内部的80端口映射到了宿主机的8880端口;
- pause容器在宿主机上设置好了网络namespace后,nginx容器加入到该网络namespace中;
- nginx容器启动的时候指定了–net=container:pause;
- ghost容器启动的时候同样加入到了该网络namespace中;
- 这样三个容器就共享了网络,互相之间就可以使用localhost直接通信,
- –ipc=contianer:pause –pid=container:pause就是三个容器的ipc和pid处于同一个namespace中,init进程为pause;
这时我们进入到ghost容器中查看进程情况。
[root@node01 ~]# docker exec -it ghost /bin/bash
root@c535b224ad28:/var/lib/ghost# ps axu
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 0.0 0.0 1012 4 ? Ss 03:48 0:00 /pause
root 6 0.0 0.0 32472 780 ? Ss 03:53 0:00 nginx: master process nginx -g daemon off;
systemd+ 11 0.0 0.1 32932 1700 ? S 03:53 0:00 nginx: worker process
node 12 0.4 7.5 1259816 74868 ? Ssl 04:00 0:07 node current/index.js
root 77 0.6 0.1 20240 1896 pts/0 Ss 04:29 0:00 /bin/bash
root 82 0.0 0.1 17496 1156 pts/0 R+ 04:29 0:00 ps axu
在ghost容器中同时可以看到pause和nginx容器的进程,并且pause容器的PID是1。而在kubernetes中容器的PID=1的进程即为容器本身的业务进程。
Pod中共享的名称空间:
- PID命名空间:Pod中的不同应用程序可以看到其他应用程序的进程ID;
- 网络命名空间:Pod中的多个容器能够访问同一个IP和端口范围;
- IPC命名空间:Pod中的多个容器能够使用SystemV IPC或POSIX消息队列进行通信;
- UTS命名空间:Pod中的多个容器共享一个主机名;Volumes(共享存储卷):
- Pod中的各个容器可以访问在Pod级别定义的Volumes;