声明
原创文章,转载请标注。https://www.cnblogs.com/boycelee/p/18055933
《码头工人的一千零一夜》是一位专注于技术干货分享的博主,追随博主的文章,你将深入了解业界最新的技术趋势,以及在Java开发和安全领域的实用经验分享。无论你是开发人员还是对逆向工程感兴趣的爱好者,都能在《码头工人的一千零一夜》找到有价值的知识和见解。
配置中心系列文章
《【架构师视角系列】风控场景下的配置中心设计思考》 https://www.cnblogs.com/boycelee/p/18355942
《【架构师视角系列】Apollo配置中心之架构设计(一)》https://www.cnblogs.com/boycelee/p/17967590
《【架构师视角系列】Apollo配置中心之Client端(二)》https://www.cnblogs.com/boycelee/p/17978027
《【架构师视角系列】Apollo配置中心之Server端(ConfigSevice)(三)》https://www.cnblogs.com/boycelee/p/18005318
《【架构师视角系列】QConfig配置中心系列之架构设计(一)》https://www.cnblogs.com/boycelee/p/18013653
《【架构师视角系列】QConfig配置中心系列之Client端(二)》https://www.cnblogs.com/boycelee/p/18033286
《【架构师视角系列】QConfig配置中心系列之Server端(三)》https://www.cnblogs.com/boycelee/p/18055933
1、什么是配置中心?
配置中心时分布式系统的重要组件,其目的是集中管理与分发服务所需要的配置文件。它的目的是将分布式系统中的配置简化并进行统一管理。
1.1、特点
1.1.1、集中管理
将分布式系统的配置文件集中存储和管理,且有统一的管理平台界面供运维人员对配置进行查看与修改。避免由于数据配置地点不统一而造成数据不统一的问题。
1.1.2、动态更新
配置中心支持动态更新配置。当配置发生变化时,配置中心会立即将更新后的配置推送给所有订阅的服务实例,不需要重启服务实例。
2、为什么需要配置中心?
风控场景通常需要频繁修改策略进行攻防对抗,一般策略管理平台与策略执行引擎是两个服务,目的是为了解耦,使得业务需求的变更对策略执行引擎执行的影响最小化。通常策略引擎获取策略配置的方法有以下几种,分别是:共享存储、远程调用或配置中心。
2.1、方案优缺点
2.1.1、共享存储(如共享Redis)
优点:
- 高效访问:共享存储能够提供快速的数据访问速度,尤其是在本地或网络延迟较低的情况下。
- 简单实现:直接在Redis等共享存储中存储策略数据,简化了策略获取的实现。
缺点:
- 数据大小限制:需要控制存储值的大小,避免大key问题。例如,如果存储的策略配置过大,可能会导致Redis的性能下降,增加了管理和维护的复杂性。
- 耦合性问题:策略管理平台和策略执行引擎之间的耦合性较高。如果策略管理平台的增删查改操作未考虑性能优化,可能会影响到策略执行引擎的稳定性和效率。策略执行引擎可能因为管理平台的操作延迟或性能问题而出现异常。
2.1.2、远程调用(如HTTP调用)

优点:
- 解耦:策略管理平台和策略执行引擎通过远程调用进行交互,减少了两者之间的直接依赖。策略执行引擎不需要直接访问共享存储,而是通过API获取策略数据,提高了系统的灵活性和扩展性。
- 实时性:可以实现实时的数据获取和策略更新,只要网络稳定,策略数据可以快速地传递到策略执行引擎。
缺点:
- 稳定性依赖:远程调用依赖于配置管理服务的稳定性。配置管理服务必须保持高可用和高稳定性,否则会影响策略执行引擎的性能。如果配置管理服务不稳定或存在网络问题,可能会导致策略数据获取失败或延迟。
- 网络延迟:远程调用涉及网络传输,可能会引入一定的延迟,特别是在网络条件不佳的情况下。这对需要快速响应的场景可能会带来挑战。
2.1.3、配置中心

优点:
-
统一管理:将所有配置数据集中管理,简化了配置的维护和管理过程。管理员可以在一个地方进行所有配置的修改和管理。
-
动态更新:支持实时更新配置,策略的修改可以即时生效,无需重启服务,提高了系统的灵活性和适应能力。
-
缓存机制:许多配置中心实现了缓存机制,以提高读取速度和响应时间,减少对后端存储的压力。
-
分布式架构:通过分布式架构,配置中心能够处理大量的配置数据,并提供高可用性和容错能力。
-
系统解耦:配置中心将配置管理与应用逻辑解耦,应用服务不需要直接访问数据库或共享存储,从而减少了系统之间的耦合度。
缺点:
-
单点故障:配置中心可能成为系统中的单点故障,如果配置中心出现问题,可能会影响到所有依赖它的服务。需要进行高可用性和容错设计来减少这种风险。
-
性能瓶颈:在配置请求频繁或配置数据量非常大的情况下,配置中心可能成为性能瓶颈,需要对其进行优化和扩展。
-
运维成本:高可用性、分布式架构和大规模的数据存储都可能增加配置中心的运维成本,尤其是在大规模系统中。
3、如何设计配置中心?(怎么做)
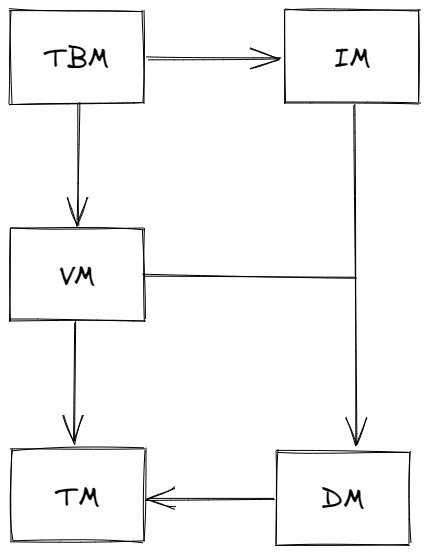
3.1、架构图

3.2、架构分层
分为客户端层、网络层、服务层以及数据层
3.2.1、客户端层
-
Client
提供实时配置获取与更新
-
Admin
提供Web界面用于管理配置
3.2.2、网络层
-
Nginx
流量分发,通过简单配置文件来配置后端服务器列表。当然也可以使用Zookeeper、Eureka等注册中心,动态地进行服务注册与发现。
3.2.3、服务层
-
Config Service
提供配置获取接口
-
Admin Service
提供配置管理接口(配置更新、配置发布)
3.2.4、数据层
-
Config DB
存储配置中心与配置相关的数据
-
Admin DB
存储配置中心与配置无关的数据
3.3、时序图
其中主要涉及三个部分,分别是启动部分、推送部分以及配置同步部分。
3.3.1、启动部分
- Step 1:启动配置预热。在配置中心启动时,进行预热,加载零版本数据到本地缓存。
- Step 2:
checkUpdateAndLoadData。客户端携带空间ID(namespace)访问配置中心后端。 - Step 3:返回最新版本号和配置数据。配置中心返回预热期间缓存的最新版本号和该空间下的配置数据。
3.3.2、推送部分
- Step 4:
checkUpdate(长轮询)。客户端将空间ID(namespace)和本地版本号发送至配置中心,并保持长轮询以监听该空间的状态变化。 - Step 5:检测最新版本号(轮询 + 实时)。通过定时任务轮询或查询本地缓存,检测当前请求中的版本号与配置中心的最新版本是否一致。
- Step 6:版本号不匹配(立即返回)。如果客户端的版本号与配置中心的版本号不一致,直接返回最新配置的版本号。
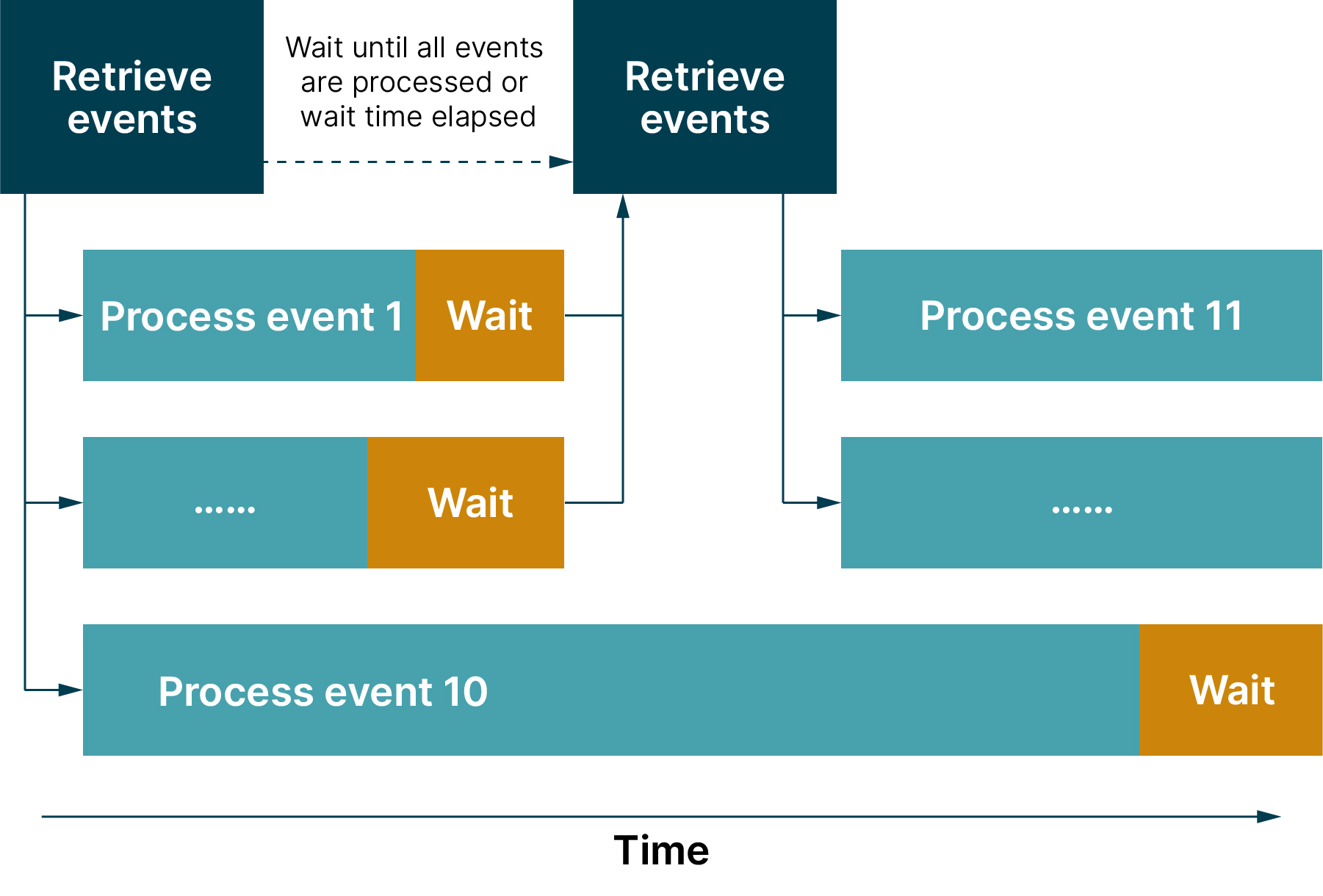
- Step 7:时间轮推进。为了避免“惊群效应”,当配置发生变更时,使用时间轮机制分批推送更新给监听的客户端。
- Step 8:版本号匹配(等待)。如果客户端的版本号与配置中心的版本号一致,客户端与配置中心继续保持长轮询监听。
- Step 9:
loadData。当客户端发现checkUpdate返回的版本号与本地版本不一致时,调用loadData接口,并携带本地版本号和最新版本号,以获取最新的配置数据。 - Step 10:区间版本号配置。服务端使用客户端提供的本地版本号和最新版本号,查询缓存或数据库以返回该版本区间的配置信息。
3.3.3、配置同步部分
- Step 11:新增、修改或发布配置,通过配置中心管理平台的界面进行操作。
- Step 12:同步通知,将第三方应用的配置修改同步到配置中心。
- Step 13:同步状态,配置中心响应状态并提供对应的配置ID。
- Step 14:配置发布,将配置中心返回的ID提交到配置中心,以完成配置发布。
- Step 15:发布结果,配置中心返回配置发布的结果信息。
3.4、设计难点
3.4.1、配置中心启动
场景描述
启动压力大。验证目标是3个namsapce,各10万条数据量,单条数据2KB,共计600M

问题描述
如果在1秒内,有20台配置中心实例同时向数据库请求获取全量配置,每台请求的数据量为200M,这样的高并发请求必然会导致数据库过载甚至宕机。
方案描述
-
预热阶段:在配置中心启动后,会经历一段预热期。这段时间的长短取决于配置中心中部署的实例数量。为避免数据库查询压力过大,配置中心通过分布式锁的机制,使各实例依次排队查询数据库,以获取所需的配置数据。
-
缓存机制:配置中心设计了两种缓存机制:零版本缓存和增量缓存。零版本缓存用于存储全量配置数据,而增量缓存则存储增量数据。这种设计的原因将在后续内容中详细解释。
3.4.2、三方应用启动
场景描述
1000台三方应用同时启动,并在1s内拉取全量配置数据,单台拉取200m数据。

问题描述
如果1000台第三方应用同时启动,并在1秒内每台都拉取200M的全量配置数据,这样的高并发请求会对系统造成巨大压力。
方案描述
-
本地缓存:配置中心会定时或在启动时将全量配置数据刷新至“零版本缓存”,而在每次配置变更时则会主动刷新“增量缓存”。这样设计是为了确保配置拉取请求不会直接冲击数据库,从而减轻数据库的负担。
-
缓存失效处理:在极端情况下,如果本地缓存失效,系统会确保每个配置中心实例在同一时间段内仅有一个线程能够访问数据库,以避免同时接收大量请求而导致数据库压力过大。
3.4.3、配置发布
场景描述
当新配置发布时,2000台第三方应用实例监听配置变化,需要采取措施避免出现‘惊群效应’。

问题描述
如果同时通知所有监听配置的第三方应用实例,并且所有应用都访问配置中心,可能会引发资源竞争,从而导致配置中心性能下降。
方案描述
-
定时扫描:配置中心实例每30秒扫描一次数据库,以检查是否有新的配置更新。当发现最新版本号与注册的Client版本不一致时,则触发推送。
-
配置推送:实现了一个简易的时间轮机制,每隔100毫秒推送5个第三方应用实例,使2000台应用实例能够在40秒内完成推送,实现秒级响应。
3.4.4、缓存设计
场景描述
启动时需要拉取全量数据(零版本),新配置变更推送时需要拉取增量数据(增量)

问题描述
在拉取全量配置数据时,需要根据版本区间进行拉取。例如,当客户端当前版本为1001时,版本区间为0至1001。如果以版本号作为键,每次拉取全量数据时,需要遍历这些版本号来获取对应的配置。
方案描述
-
零版本配置:使用版本区间作为键,每小时刷新一次缓存数据,以确保零版本配置与最新版本之间的差距保持在合理范围内,同时避免增量存储数据过大。
-
增量配置:使用版本号作为键。每次获取数据时,通过遍历版本号来获取对应的配置。由于版本号数量较少,对性能的影响相对可控,同时由于数量少,存储时间较短,直接查询对数据库的压力也较小。
总结
与Apollo和Qconfig相比,该配置中心更为轻量化。它采用增量更新机制,而Apollo和Qconfig在每次配置更新时都会拉取空间下的全量数据,这在配置量大的场景下可能会导致性能压力。该配置中心的特点在于支持单条配置存储量和单个空间下的容量更大,从而更好地满足大规模配置管理的需求。
三、最后
《码头工人的一千零一夜》是一位专注于技术干货分享的博主,追随博主的文章,你将深入了解业界最新的技术趋势,以及在Java开发和安全领域的实用经验分享。无论你是开发人员还是对逆向工程感兴趣的爱好者,都能在《码头工人的一千零一夜》找到有价值的知识和见解。
懂得不多,做得太少。欢迎批评、指正。
![[图文直播]使用EasyOCR识别图片上的文字](https://img2023.cnblogs.com/blog/3485711/202408/3485711-20240812232925752-921682892.png)