论文提出新颖的基于
Transformer的端到端方法DLAFormer,在统一的模型中集成多个文档布局分析任务,包括图形页面对象检测、文本区域检测、逻辑角色分类和阅读顺序预测。为了实现这一目标,将各种DLA子任务视为关系预测问题并提出了统一标签空间方法,使得统一关系预测模块能够有效而高效地同时处理这些任务来源:晓飞的算法工程笔记 公众号
论文: DLAFormer: An End-to-End Transformer For Document Layout Analysis

- 论文地址:https://arxiv.org/abs/2405.11757
Introduction
文档布局分析(DLA)是从文档图像中恢复文档的物理结构和逻辑结构的过程,包括物理布局分析和逻辑结构分析。在给定输入文档图像的情况下,物理布局分析旨在识别感兴趣的物理同质区域(也称为页面对象),如表格、图形对象、数学公式和不同类型的文本区域。逻辑结构分析旨在为每个识别出的区域分配逻辑角色(例如标题、章节标题、页眉、页脚、段落等),并确定它们之间的逻辑关系(例如阅读顺序关系)。文档布局分析在推动对文档内容进行理解方面发挥着至关重要的作用,实现了各种应用,如文档数字化、转换、存档和检索。然而,由于文档布局中固有复杂多样的内容和错综复杂性,使得该问题具有极大挑战性。
文档布局分析包括许多复杂的子任务,如图形页面对象检测、文本区域检测、逻辑角色分类、阅读顺序预测等。虽然先前的研究主要集中在利用专门的模型来解决这些单独的子任务,但将这些子任务整合起来的兴趣与日俱增,将DLA子任务集成到一个连贯框架中是提高效率和有效性的有前途的途径。为了实现这一愿景,最近的一些倡议已经开始采用更全面的方法,设计了多分支或多阶段框架,能够同时处理几个子任务。虽然这些方法在某些DLA基准测试中表现不错,多分支或多阶段框架可能会在解决这些DLA子问题时引入级联错误,也会带来可扩展性挑战并且难以容纳额外任务。
论文提出了DLAFormer,一种基于Transformer的端到端方法用于文档布局分析。与通常采用多分支或多阶段架构的传统方法不同,DLAFormer通过将各种DLA子任务(如文本区域检测、逻辑角色分类和阅读顺序预测)视为关系预测问题来简化训练过程。这些任务的标签被统一到一个单一的、全面的标签空间中,从而简化了学习机制。DLAFormer建立在受DETR启发的编码器-解码器Transformer架构之上,能够同时推断所有关系,通过一个统一的关系预测模块实现端到端训练过程。受可变形DETR启发,论文引入了新颖的类型查询来捕捉各种页面对象的分类信息。这增强了转换器解码器中内容查询语义上相关性信息获取能力,改善了模型对这些DLA子任务的处理能力。此外,DLAFormer采用粗到精策略来精确识别文档图像中的图形页面对象。DLAFormer具有以下几个优点:
- 在灵活查询机制和统一标签空间方法下,
DLAFormer展示出卓越可扩展性,并无缝集成新型DLA任务进入框架中。 - 新关系标签可以无缝融入到统一标签空间中,并且新元素类型可以无缝地作为新类型查询进行处理。在统一标签空间下使用统一关系预测模块可以在单次传递中预测所有关系,可以更加有效和高效地捕捉这些布局单元之间潜在联系。
DLAFormer通过自注意机制融合鲁棒背景信息来增强功能,并且通过交互注意机制实现对全局和局部文档布局信息进行不同关注。
本文的主要贡献可以总结如下:
-
提出了
DLAFormer,一种新颖的基于Transformer的端到端方法,用于文档布局分析,将图形页面对象检测、文本区域检测、逻辑角色分类和阅读顺序预测等任务整合到一个统一的模型中。 -
将各种文档布局分析子任务(如文本区域检测、逻辑角色分类和阅读顺序预测)视为关系预测问题,并提出了一种统一标签空间方法,使统一的关系预测模块能够同时有效和高效地处理这些任务。
-
实验结果表明,
DLAFormer在两个文档布局分析基准测试上优于先前采用多分支或多阶段架构处理多任务的方法。
Problem Definition
一个文档图像本质上包含多种区域,包括文本区域和非文本区域。文本区域作为书面内容的语义单元,包括按照自然阅读顺序排列的文本行,并与逻辑标签相关联,例如段落、列表/列表项、标题、章节标题、页眉、页脚、脚注和标题说明。非文本区域通常包括表格、图形和数学公式等图形元素。这些区域之间通常存在多种逻辑关系,其中最常见的是阅读顺序关系。
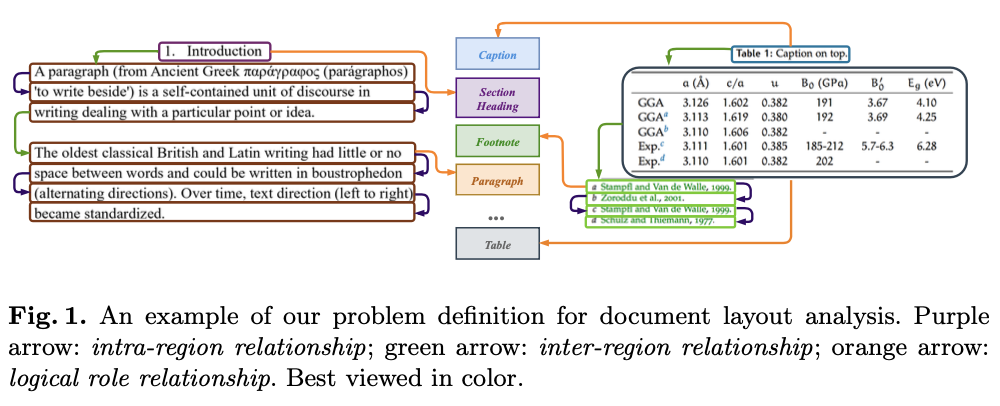
因此,论文定义了三种不同类型的关系:区内关系、区间关系和逻辑角色关系。这些关系旨在将基本文本单元(如文本行)分组为连贯的文本区域,并探索这些区域之间的逻辑连接。具体而言,给定由 \(N\) 个文本行 \([T_1, T_2, ..., T_N]\) 和 \(M\) 个图形对象 \([G_1, G_2, ..., G_M]\) 组成的文档图像 \(D\) ,定义关系如下:
-
如图
1所示,考虑每个文本区域,其中包括按自然阅读顺序排列的多个文本行。为同一文本区域内所有相邻的文本行建立区内关系。对于只包含单个文本行的文本区域,将该文本行的关系指定为自引用关系。 -
为了深入研究这些文本区域和非文本区域之间的逻辑连接,构建了展示逻辑连接的所有区域对之间的区间关系。例如,如图
1所示,在两个相邻段落之间以及表格与其对应的标题或脚注之间建立了一个区间关系。 -
如图
1所示,勾勒出各种逻辑角色单元,包括标题、章节标题、段落、标题等。鉴于每个文本区域都被分配了一个逻辑角色,在文本区域中的每个文本行与其对应的逻辑角色单元之间建立了逻辑角色关系。
通过定义这些关系,将各种DLA子任务(如文本区域检测、逻辑角色分类和阅读顺序预测)作为关系预测挑战来框定,并将不同关系预测任务的标签合并到一个统一的标签空间中,从而利用一个统一模型同时处理这些任务。
Methodology
Model Overview
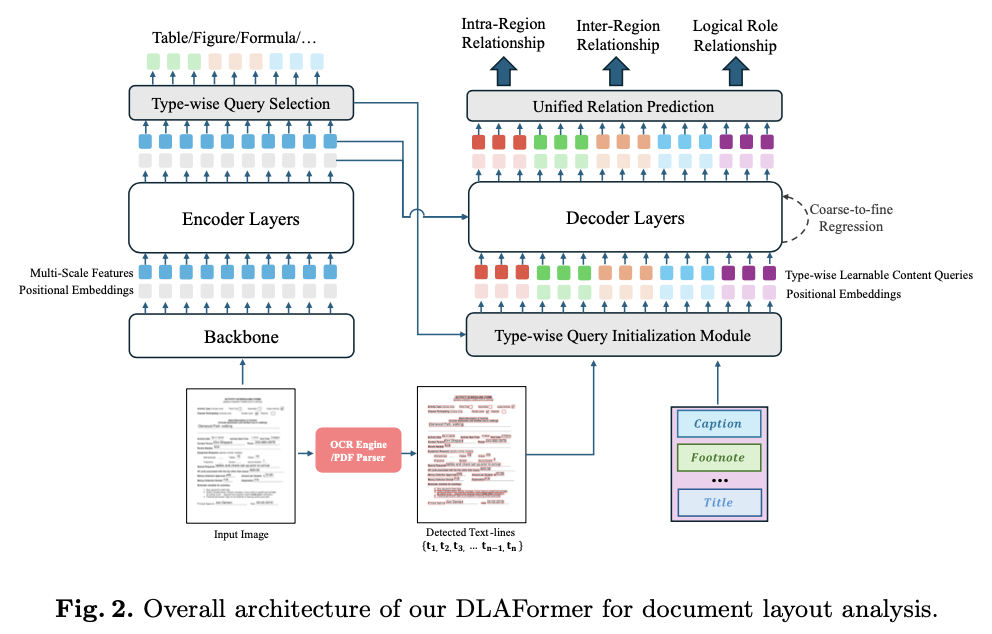
利用统一标签空间的新视角,论文提出了DLAFormer,一种基于Transformer的端到端文档布局分析方法。DLAFormer遵循DETR类似的模型架构,包括骨干网络、多层Transformer编码器、多层Transformer解码器、统一关系预测头和粗到细的检测头。
整个流程如图2所示,给定一个文档图像:
- 使用
ResNet或Swin Transformer等骨干网络提取多尺度特征 \(\{C_3,C_4,C_5\}\) ,然后将这些特征与相应的位置嵌入一起输入到Transformer编码器中。为了增强处理多尺度特征的计算效率,集成了一个可变形Transformer编码器来增强这些提取的特征。在编码器中进行特征增强后,采用类型查询选择策略来获取每个潜在图形对象提议的参考框和类别标签。 - 对于给定文档图像中的文本行,利用
PDF解析器或OCR引擎提取它们的边界框。这些图形对象提议和文本行将作为查询并输入到Transformer解码器中。 - 为了增强这些查询的物理含义,并为各种类型的查询从不同区域自适应地捕获特征,论文引入了一种类型查询初始化模块,将类型查询初始化为内容查询,以供后续的解码器使用。
- 在获取位置查询、内容查询和它们的参考框之后,利用可变形
Transformer解码器来增强这些查询。这涉及到将自注意力模块纳入其中以模拟这些查询之间的交互,同时采用可变形交叉注意力模块来从多尺度特征图中捕获全局和局部布局信息。受Deformable DETR的启发,采用粗到细的回归策略来逐层迭代地细化图形对象查询的参考框。 - 为了揭示这些查询之间的逻辑连接,我们引入了一个统一的关系预测头,有效且高效地同时处理关系预测任务。
Type-wise Query Selection
在DETR和DAB-DETR中,解码器查询是静态嵌入,不包含任何特定于单个图像的编码器特征。这些模型直接从训练数据中学习锚点或位置查询,并将内容查询初始化为全零向量。为了增强改进解码器查询的先验知识,Deformable DETR引入了一种机制,其中来自编码器的多尺度特征被输入到一个带有二元分类器的辅助检测头部。基于每个编码器特征的对象得分选择前K个特征,用以初始化位置和内容查询。同时,相应的预测框被用来初始化参考框。为了解决由选定的编码器特征引起的解码器潜在歧义和混淆问题,DINO提出了一种混合查询选择方法。该方法仅有选择性地使用top-K个特征来增强位置查询,可学习内容查询保持与之前一样不变。
尽管DINO的方法带来了显著的改进,但可学习内容查询的不清晰物理含义仍然是一个问题。为了解决这个问题,论文引入了一种类型化查询选择策略,利用潜在的类别信息来初始化内容查询,从而摆脱了使用“静态”内容查询的方式。由于各种类型的图形对象(如公式、表格和图表)之间在视觉特征上存在显著差异,通过使用类别信息初始化内容查询可以使这些查询自适应地捕捉到解码器中关键特征。具体而言,用多分类器替换辅助检测头部中的二元分类器以区分每个选定特征的类别。虽然预测参考框仍然被用于初始化位置查询,但预测类别被传递到后续的类型化查询初始化模块中。在该模块内,为每种类型的查询分配一个可学习类型化内容查询。
Type-wise Query Initialization Module
论文引入了一种类型化查询初始化模块,以标准化不同查询之间的逻辑关系建模,确保输入解码器的统一性。如图2所示,类型化查询初始化模块将三个组件作为输入:解码器输出的图形对象提议的参考框和类别、OCR引擎或PDF解析器提取的文本行的边界框、预定义的逻辑角色类型。
对于来自编码器的图形对象提议,通过将正弦位置编码应用于参考框来初始化位置查询。同时,为每个类别定义可学习特征并通过选择相应的特征来初始化内容查询。对于文本行也采用类似的方法,先根据边界框初始化位置查询,然后为这些文本行定义一个独特的可学习特征,作为内容查询的初始化。
以前的逻辑角色分类方法通常使用静态参数分类器,将其视为简单的多类分类任务。受动态算法的启发,将逻辑角色分类重新定义为关系预测问题。在这个框架中,为预定义的逻辑角色建立了位置和内容查询,例如标题、章节标题、说明等。这种方法允许逻辑角色查询动态地适应其特征提取过程到每个图像的具体情况。然后,图像中的每个基本单元都被赋予预测指向这些动态逻辑角色查询的指针的任务,增强了模型对独特图像内容的适应性和响应能力。此外,论文为每种逻辑角色类型使用可学习特征作为内容查询初始化。为了查询对象的结构统一性,为每种逻辑角色类型定义相应的可学习参考框。在训练过程中,引入辅助的有监督将属于特定逻辑角色的所有查询的联合框作为该角色的目标框。
Unified Relation Prediction Head
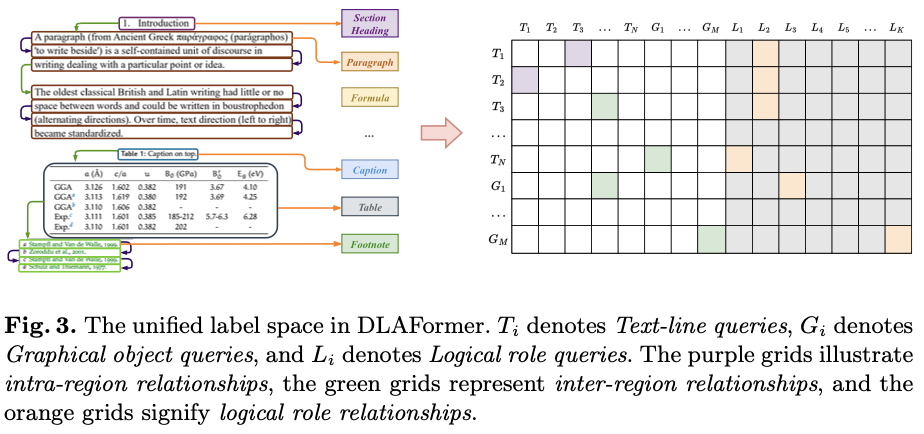
在解码器层的增强过程中,包括文本行查询、图形对象查询和逻辑角色查询在内的三种类型的查询被输入到统一关系预测头中,以揭示这些查询之间的逻辑连接。论文定义了三种不同类型的关系:区域内关系、区域间关系和逻辑角色关系。为了有效且高效地同时处理这些关系预测任务,引入了一种统一的标签空间方法,如图3所示。具体而言,定义一个标签矩阵 \(M \in \mathbb{Z}^{H\times W}\) ,其中第 \(i\) 行和第 \(j\) 列中的每个元素可以取四个可能的值。以图3为例,标签矩阵中的空单元格表示没有从第 \(i\) 个查询指向第 \(j\) 个查询的逻辑关系。另外三种类型的单元格表示三种预定义的关系,每种关系都有其独特的解释。有了这个统一的标签空间,统一关系预测头由两个模块组成:关系预测模块和关系分类模块。
-
Relation Prediction Module
考虑到文本行/图形对象查询之间的逻辑关系及其与逻辑角色查询之间的联系,将所有文本行和图形对象查询归类为 \(\{q_1, q_2, ..., q_H\}\),将逻辑角色查询归类为 \(\{q_{H+1}, q_{H+2}, ..., q_{W}\}\)。按以下方法计算代表 \(q_i\) 与 \(q_j\) 之间逻辑关系概率的分数 \(s_{ij}\):
其中, \(FC^r_q\) 和 \(FC^r_k\) 分别表示具有1,024个节点的单个全连接层,用于将 \(q_i\) 和 \(q_j\) 映射到不同的特征空间; \(\circ\) 表示点积操作。
-
Relation Classification Module
使用多类分类器,通过计算不同类别的概率分布来确定 \(q_i\) 和 \(q_j\) 之间的关系类型:
其中, \(FC^c_q\) 和 \(FC^c_k\) 都表示具有1,024个节点的单个全连接层; \(BiLinear\) 表示双线性分类器; \(argmax\) 用于确定概率分布 \(p_{ij}\) 中具有最高值的索引 \(c_{ij}\) ,作为预测的关系类型。
Optimization
在DLAFormer中,采用了与Deformable DETR相同的检测头部,只是在编码器中将二元分类器替换为多类分类器,检测头部的优化遵循Deformable DETR中概述的训练范式。在训练过程中,在解码器的每一层都加入了共享的统一关系预测头部以促进训练。所有这些关系预测模块和关系分类模块都一致地使用softmax交叉熵作为它们的损失函数进行有效优化。模型的整体损失由聚合每个预测头部的单个损失确定。
Experiments
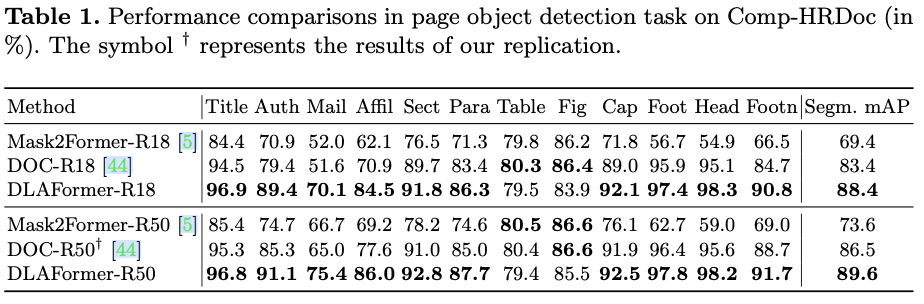
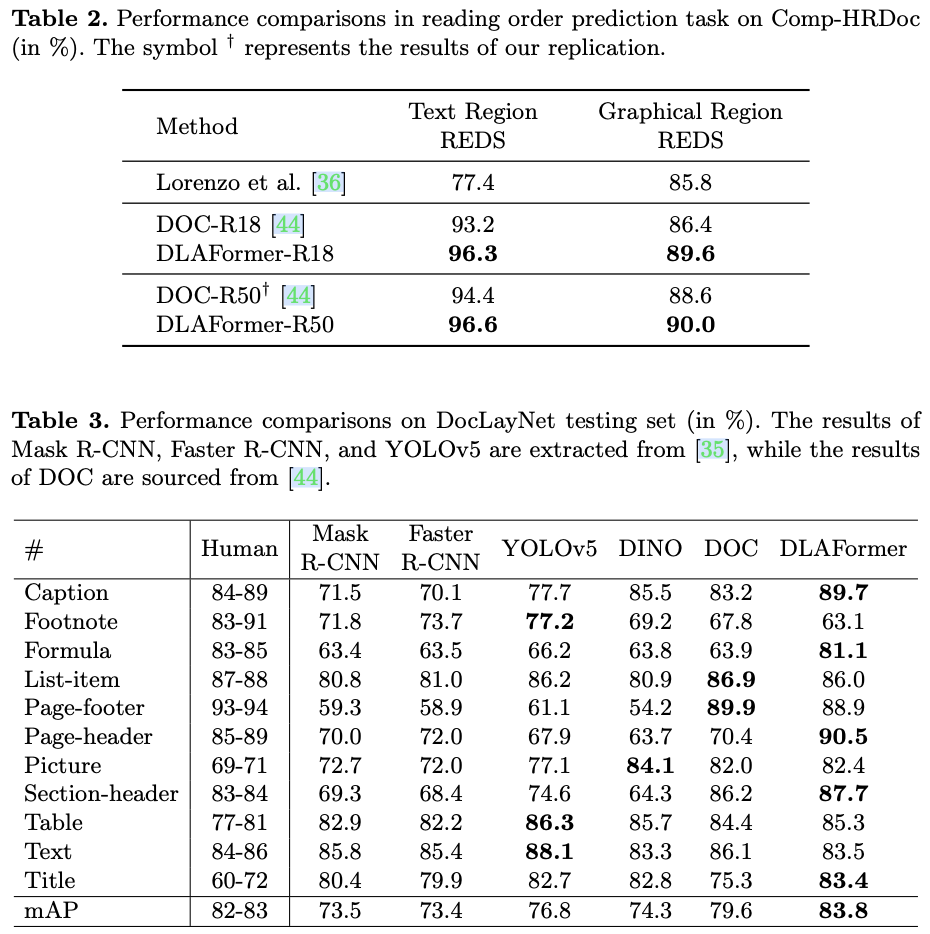
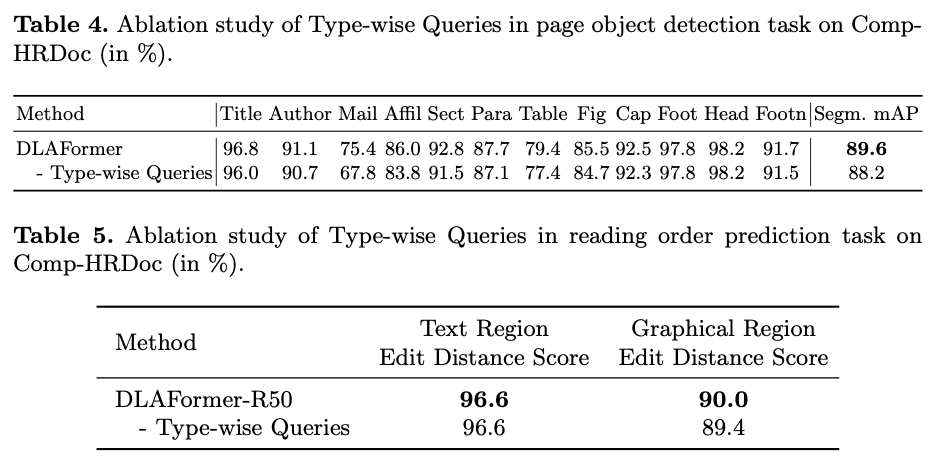
如果本文对你有帮助,麻烦点个赞或在看呗~
更多内容请关注 微信公众号【晓飞的算法工程笔记】