Verilog编码风格及设计建议
- 相比于case语句,casez语句将z态看做不关心,casex语句将z态和x态看做不关心。并且所有case类型语句均没有优先级。
- 锁存器是组合逻辑产生的,一般没有复位端,所以根据其所存特性,在上电的时候没法确定其初始状态,因此正常情况下要避免使用。
- 组合逻辑环是一种高风险设计,从稳定性来说,可能会导致电路产生振荡、毛刺以及冲突等,从时序上来说,整个环路逻辑的时序延迟极易受到组合逻辑门延迟和布线延迟的影响,陷入deadloop,并且EDA在进行环路计算时序时,会主动切割时序路径从而引入许多不确定因素。
- 对于赋值和判决条件两边的信号位宽必须相等,位宽不等时,无符号数通过高位补0至相同位宽;有符号数使用$singed()语句对两端均进行高位补符号位至相同位宽。
- 对于复位和使能信号,尽量减小其扇出,过高的扇出会造成较大的网络延迟,不利于时序收敛,对于解决方法:对于数据信号不会出现X态传播时可以不进行复位;对于使能信号可以将使能copy成多份并分别驱动以减少后端压力。
- If-else必须写全分支,即使不需要考虑else的情况也要写成保持状态,综合可以生成icg降低功耗。
- 对于2的整数次幂除法或乘法尽量选取移位操作来实现,对于非2的整数幂乘法可以通过拆分的方式转换为移位器和加法器的组合实现;对于非2的整数幂乘法只能nbit位翻倍扩展并通过移位操作、比较和减法操作分别执行n次得到。
具体实现:对于32位的无符号数除法,被除数a除以除数b,他们的商和余数一定不会超过32位,首先将a转换成高32位为0,低32位为a的temp_a,再将b转换成高32位为b,低32位为0的temp_b。在每个周期开始前,先将temp_a左移一位,末尾补0,然后与b相比较看是否大于b,若大于b,则temp_a=temp_a-temp_b+1,否则继续往下执行。上面的移位操作、比较和减法要执行32次,执行完成后得到的temp_a的高32位为两数a和b相除的余数,低32位表示商。具体的算法流程可从下图的例子中得到体现

电路设计中常见问题原理
8. 为何在进行多级触发器链(打拍)消除亚稳态的时候,两个时钟域之间不能有组合逻辑?
答:这是因为对于组合逻辑多输入单输出时,各输入端同时变化的时候存在物理时间差,在组合逻辑的输出就表现为毛刺的产生,而目标域采样时,不仅有setup time和hold time的约束,还有毛刺产生所带来的错误数据的风险,因此这无疑给整体数据传输增加风险,尤其对于较快目标域来说风险更大。
9. 对于同一个时钟树引出的两条时钟,直接形成触发器链路,若skew较大的话,可能会导致链路后端触发器时序违例,若skew更大的话,虽然可能会覆盖掉时序违例,但可能会出现数据错误采样。
10. 同步边沿检测:只能在时钟有效沿来临的时候进行检测,特点是面积小,速度快但可能会丢失部分边沿数据。
异步边沿检测:通过打拍的方式进行检测,特点时面积较大。所需周期较多但边沿数据完整。
11. 行波进位加法器:多bit数据相加时,某一位对应相加时依赖上一位的进位输入,而对于越高位相加所需的计算延迟就越大,这种将极大影响加法器的工作频率。
超前进位加法器:通过将进位输入进行等式代换可以转化为各级输入的组合逻辑关系式而不依赖上一级计算得到进位输入,这种结构可以大大降低整体运算延迟,提高计算频率,但代价是所需的逻辑门面积较大,相比行波进位属于面积换速度,实际工程中按要求取舍。
Verilog编码SVT需求建议
12. 模块顶层中只允许定义一个module,不能在一个.v文件中写多个module。
13. 使用parameter计算得到的parameter需要提前定义为localparam类型。
14. AXI总线协议中的master口的信号添加后缀_m,slave口的添加后缀_s。
低功耗编程注意事项
15. 时序逻辑中,else分支不写复制内容,EDA工具会自动综合出clock gating,节省功耗。例如:
always@ (posedge clk or negedge rstn) begin
if(!rstn)
data_cnt <= ‘d0;
else if(enable)
data_cnt <= data_cnt + ‘d1 ;
else
end
综合工具会自动优化成如下电路:

16. 对于纯打拍逻辑采用FIFO形式可以降低动态功耗,代码如下:
always@ (posedge clk) begin
if(data_valid& data_ready)begin
data_r1 <= data;
data_r2 <= data_r1;
data_r3 <= data_r2;
data_r4 <= data_r3;
……
end
end
使用FIFO:
assign rd_en = ~empty & data_ready;
assign wr_en = ~full & data_valid;
fifo u_fifo
(
.rst (rst ),
.wr_clk (clk ),
.rd_clk (clk ),
.din (data ),
.wr_en (wr_en ),
.rd_en (rd_en ),
.dout (dout ),
.full (full ),
.empty (empty )
);
17. 根据实际设计需求采用合适的编码方式可以降低数据信号的翻转率,例如FIFO中bin2grey模块,在数据变化时只有一位改变,既能降低翻转功耗,还能降低毛刺的出现。
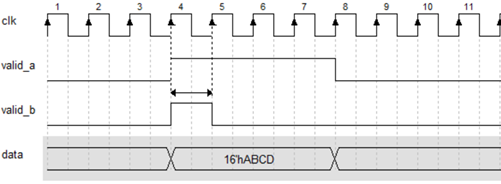
18. 赋值使能的脉宽越窄(占空比减小),产生的clock gating时间就相对越长,则动态功耗越低。例如下图valid_b一拍完成data的赋值,相比valid_a减少3拍的clk翻转功耗。
19. 减少变化频率较高的信号,降低翻转功耗。
通过逻辑重排,优化逻辑结构。例如下图:
A信号变化频繁,每次A变化,连带后面的链路都会跟着翻转,因此将A放到链路最后,可以降低其他信号的连带翻转率,从而降低动态功耗。

时钟设计
20. 选用支持静态clock gating的模块,可以在长期不使用的时候将其时钟关断,节省功耗;选用支持动态clock gating的模块,通过动态周期性的开关控制模块clock的使能信号进而实现动态调节时钟信号,降低功耗。
21. 选择合适的时钟频率,达到既满足数据吞吐量(性能)的要求,又不会浪费过多的频率(功耗)。在保持能耗比接近的情况下,并且满足性能的条件下,尽可能的降低系统频率。
以上一种手动的方法,另一种通过实时应用场景检测以及自身频率的设定,分档位对系统进行频率调节,实现动态调节,降低某些场景下过高的工作频率以节省功耗。例如:当信号的采样率从8倍过采降低为2倍过采,相应的滤波器模块可跟随 采样率的变化降低4倍的工作频率,以节省功耗。
缓存设计
22. Memory模块设计也可以进行分阶段(LS-light sleep、DS-deep sleep以及SD- shutdown)进行动态调整功耗,根据使用场景由LS依次向SD阶段进行唤醒。
具体如下:
当模块进入自动clock gating时,可以主动将LS拉高,使RAM进入LS状态,节省功耗。
若RAM支持自动DS时,模块进入自动clock gating时,可以进一步拉高DS,使RAM进入DS状态,节省功耗,并且DS相比于LS,功耗节省更加明显,但唤醒时间也更长。
低资源设计
23. 尽量采用形状规则的RAM,非规则RAM面积利用率很低,并且位宽过小、深度过小的RAM会比较浪费资源;并且使用大Memory的场景时,可以通过分块拼接的方式进行控制,不使用的块可以进入LS/DS状态以节省资源;类型的选取上,优先选择SP RAM,其次选择BP/TP RAM,禁止使用DP RAM,相同位宽深度下,SP RAM的面积和功耗远低于BP/TP RAM。
微架构设计
24. 模块采用分时复用设计,对于在一个周期内占空比较低的数据,可以通过分时复用的方式提升单时钟周期内的利用率并节省面积,这里需要考虑的代价交换:①节省的面积是否大于复用带来的MUX资源;②节省面积带来的收益是否高于复用造成的逻辑和时序复杂度。
25. RAM采用分时复用设计,根据需求提前设计好RAM bank的数量和大小,通过MUX的方式统一进行调度和管理,达到各模块分时调用RAM的目的,从而降低资源。例如OFDM系统中时域、频域、比特域常以流水的形式分时占用RAM处理和共享数据。

26. 采用流量均衡的设计,避免性能过度设计浪费资源,下图中,若非特殊需求,否则需要将通路流量平均分配。

27. 减少非同时调用的Memory存储位宽,通过控制位,将Memory进行分时控制,减小面积以及功耗。例如:原始数据,INFO A和INFO B不会同时生效

29. 改变算法结构,不同存储信息若不会同时发生,那么可以复用RAM中的bit位,通过控制位指示,例如下,算法要求做好运算,完成交织后输出;实际可以先交织再运算。输入数据于RAM中的运算因子,经过运算后得到32bit数据,写入 RAM后交织读。

当输入前后数据没有依赖的时候,完全可以先将输入存入RAM后,交织读取数据与因子后再进行计算,这样缓存的大小减少1/2

congestion和时序优化
30. Congestion优化面积:对于某些较大的MUX时,实际的物理绕线会严重制约实际面积,例如下图:256bit的256to1 MUX有256^2的绕线,优化方法:①采用二级MUX嵌套,前级进行八选一进行分块输出,后级再进行八选一输出选定数据。 两级MUX间打两拍;②直接使用RAM进行信息索引。
31. 时序优化面积:选择工艺库中功耗和面积较低的cell。
异步设计原则
32. 在多bit数据传输时,对于每bit线传输的物理延迟是不同的,目标时钟域可能采集到中间态,设计的核心就是要避免中间态误传递,通过格雷码,DMUX,握手等方式避免这种问题。
常用异步设计方法
33. 使用DMUX进行跨异步,如图所示,对于多bit CDC并且多bit数据要保持一段时间时,可以将流程等效为数据有效位的单bit CDC问题。当bclk快于aclk时,数据有效位在bclk下直接打两拍同步到该时钟域下,此时多bit数据再aclk下依旧保持 有效,使用同步后的数据有效位作为DMUX的选通信号,将多bit信号进行同步,此处将多bit数据位和单bit数据有效位在目标时钟域下多打一拍是为了将这两个数据进行同步。若bclk慢于aclk时,可以修改对应红色虚线框的单bit CDC结构即可。

Note:使用DMUX进行多bit CDC时,将无法支持流水跨异步传输,需要等待上次传输全部完成,在进行下次传输。
34. 对于单bit CDC,快采慢时无影响;慢采快时需要进行脉冲展宽确保数据不丢失。
工具及工程文件
35. filelist文件夹下的.lst .f .sim.f等文件是用于其他流程需求的所有文件路径,在这里一并汇总,方便直接调用。


36. fsdb(fast signal data base):快速信号数据库,是相当于vcd文件经过霍夫编码压缩之后的精简版,是一种verdi的专用格式,VCS默认输出波形格式为vpd,需要加入fsdb指令输出fsdb文件。