目录
- 概
- 符号说明
- Motivation
- Neo-GNN
- 代码
Neo-GNNs: Neighborhood overlap-aware graph neural networks for link prediction. NeurIPS, 2021.
概
一种计算上相对高效的, 同时利用结构信息和特征信息的链接预测模型.
符号说明
- \(\mathcal{G} = (\mathcal{V}, \mathcal{E})\), graph;
- \(\mathcal{V} = \{v_1, v_2, \ldots, v_N\}\), \(N\) nodes;
- \(\mathcal{E} = \{e_{ij} | v_i, v_j \in \mathcal{V}\}\), edges;
- \(A \in \mathbb{R}^{N \times N}\), adjacency matrix;
- \(D \in \mathbb{R}^{N \times N}\), diagonal matrix \(D_{ii} = \sum_{j} A_{ij}\);
- \(X \in \mathbb{R}^{N \times F}\), node features
Motivation
-
link prediction 有很多启发式的方法, 比如利用
\[S_{CN}(u, v) = |\mathcal{N}(u) \cap \mathcal{N}(v) | = \sum_{k \in \mathcal{N}(u) \cap \mathcal{N}(v)} 1, \\ S_{RA}(u, v) = \sum_{k \in \mathcal{N}(u) \cap \mathcal{N}(v)} \frac{1}{d_k}, \\ S_{AA}(u, v) = \sum_{k \in \mathcal{N}(u) \cap \mathcal{N}(v)} \frac{1}{\log d_k}. \] -
作者的做法是将它一般化, 即
\[S(u, v) = \sum_{k \in \mathcal{N}(u) \cap \mathcal{N}(v)} x_k. \]
Neo-GNN
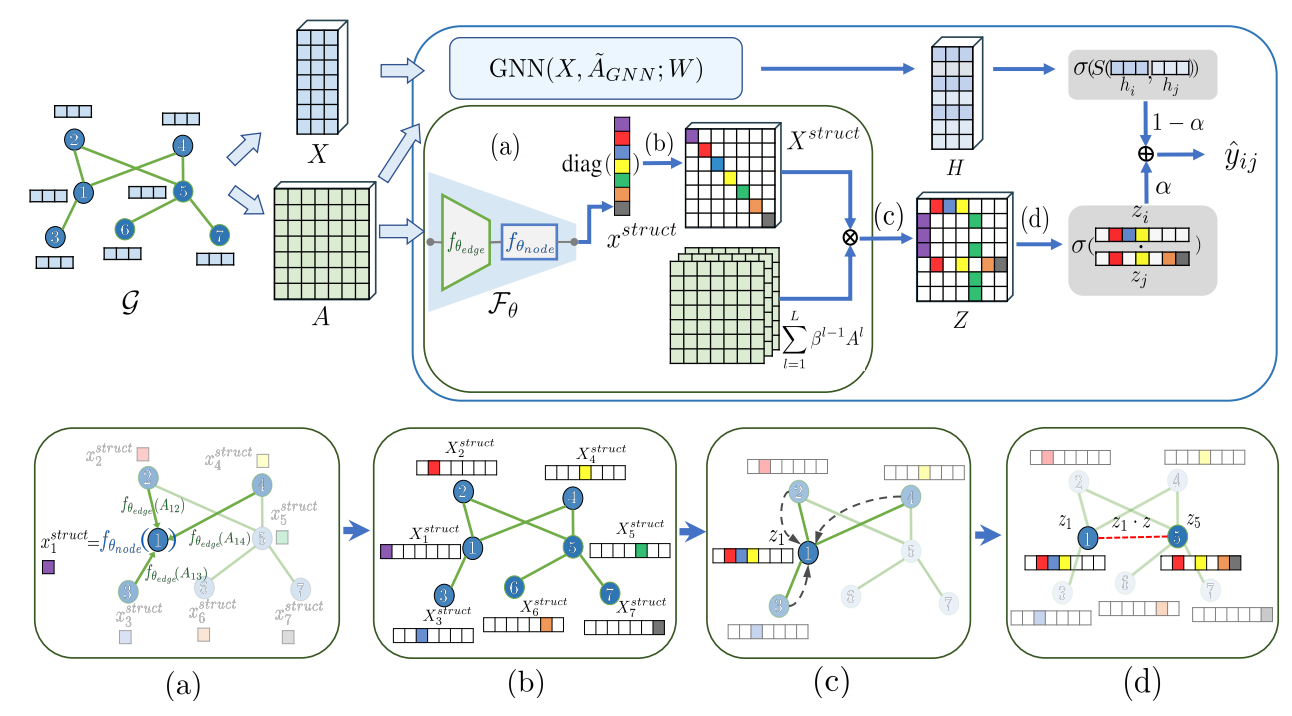
-
\(x_k\) 是这般设计的:
\[x_i^{struct} = \mathcal{F}_{\theta}(A_i) = f_{\theta_{node}} \bigg(\sum_{j \in \mathcal{N}_i} f_{\theta_{edge}} (A_{ij}) \bigg), \]通过可学习的参数从邻接矩阵 \(A\) 中获得有用的结构信息.
-
有更一般的计算方式. 我们令
\[X^{struct} = \text{diag}(x^{struct}) \in \mathbb{R}^{N \times N}, \]则当 \(f_{\theta_{edge}}(x) = x\) 而 \(f_{\theta_{edge}}(x) = 1 / \sqrt{\log x}\) 的时候,
\[S(u, v) = z_u^T z_v, \: Z = AX^{struct}. \] -
更为一般的, 为了利用更高阶的信息, 作者实际上采用如下的形式:
\[Z = g_{\Phi} (\sum_{l=1}^L \beta^{l-1} A^l X^{struct}), \]其中 \(\beta\) 是用来控制高阶信息的一个超参数.
-
除此之外, 通过一个普通的 GNN 得到传统的 (smoothed) 节点特征:
\[H = \text{GNN}(X, \tilde{A}_{GNN}; W) \in \mathbb{R}^{N \times d'}. \] -
最后两个结点存在边的概率通过如下的方式得到:
\[\hat{y}_{ij} = \alpha \cdot \sigma (z_i^T z_j) + (1 - \alpha) \cdot \sigma (s(h_i, h_j)), \]其中 \(\alpha\) 是可训练的参数.
-
训练的时候, 两个分支也要单独参与训练:
\[\mathcal{L} = \sum_{(i, j) \in D} (\lambda_1 BCE(\hat{y}_{ij}, y_{ij})) + \lambda_2 BCE(\sigma(z_i^T z_j), y_{ij}) + \lambda_3 BCE(\sigma(s(h_i, h_j)), y_{ij}). \]
代码
[official]


![[COCI2017-2018#5] Planinarenje](https://img2024.cnblogs.com/blog/2490134/202408/2490134-20240825141102113-226417116.png)