Quantization (量化) & Knowledge Distillation(蒸馏)
Ollama:量化技术
量化是一种将模型中的浮点数参数(如32位浮点数)转换为低精度数值(如8位整数)的技术。通过减少数值的精度,可以显著减少模型的计算复杂度和存储需求。
量化类型:
1.权重量化:仅对模型的权重进行量化。
2.激活量化:对模型的输入和中间层的激活值进行量化。
3.混合量化:结合权重量化和激活量化,进一步优化模型。
量化方法:
1.线性量化:将浮点数线性映射到低精度数值。
2.非线性量化:使用非线性函数进行映射,通常能更好地保留模型性能。
量化优势:
1.减少模型大小,便于在资源受限的设备(如移动设备、嵌入式设备)上部署。
2.提高推理速度,降低计算资源消耗。
量化挑战:
1.量化可能导致模型精度下降,尤其是在极端低精度的情况下。
2.需要设计合适的量化策略,以在精度和效率之间取得平衡。
Bit(位) ->Bytes(字节) 8 : 1
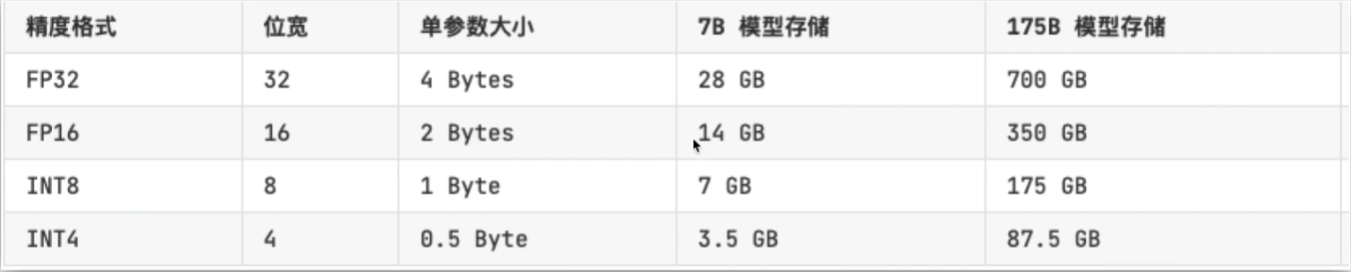
训练后量化(Post-Training Quantization)
量化感知训练(Quantization-Aware Training): llama.cpp (gguf) 项目,把不重要的数据狠狠地压缩
混合精度量化(Mixed-Precision Quantization)
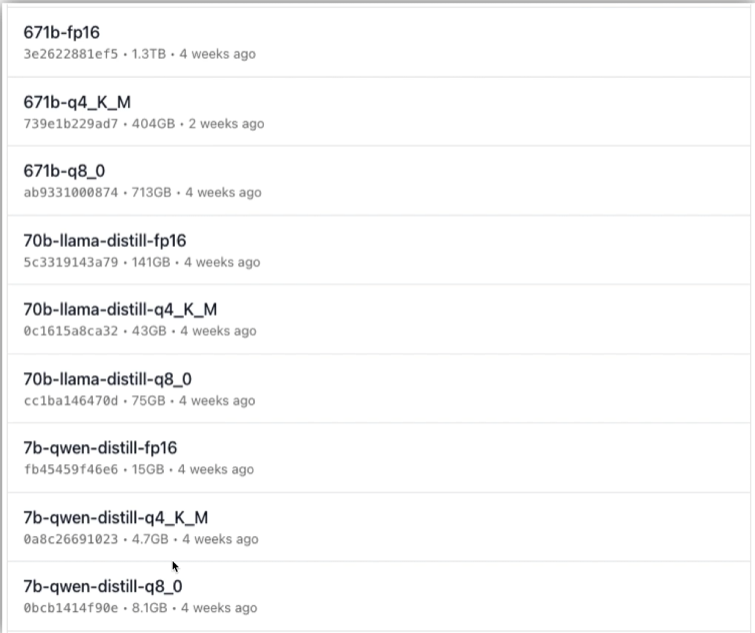
类似于:7b-qwen-distill-q4_K_M
q4中 q代表量化,4个bit存储
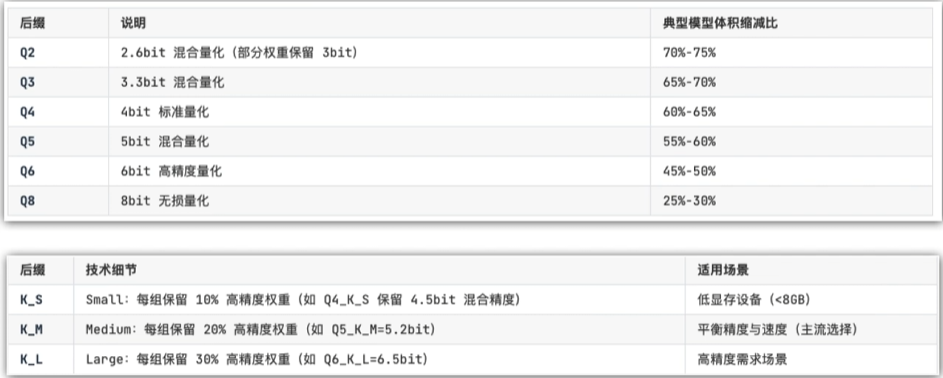
蒸馏技术
蒸馏是一种将大模型(教师模型)的知识迁移到小模型(学生模型)的技术。通过模仿教师模型的输出,学生模型可以在保持较高性能的同时,显著减少参数量和计算复杂度。
蒸馏方法:
1.软标签蒸馏:使用教师模型输出的概率分布(软标签)作为学生模型的训练目标,而不是硬标签(如类别标签)。
2.特征蒸馏:让学生模型模仿教师模型的中间层特征表示,而不仅仅是输出层。
3.自蒸馏:使用同一个模型的不同部分进行知识迁移,通常用于模型压缩。
蒸馏优势:
1.学生模型通常比教师模型更小、更快,适合在资源受限的环境中部署。
2.学生模型可以通过模仿教师模型的行为,获得与教师模型相近的性能。
蒸馏挑战:
1.学生模型的能力有限,可能无法完全模仿教师模型的所有行为。
2.蒸馏过程需要精心设计,以确保学生模型能够有效学习教师模型的知识。

NLP(自然语言处理)中有一种叫软蒸馏(知识蒸馏),例子:老师叫学生拆概率
Transformer原理:学习人类语言序列,苹果是( ) ? 甜的、红的 , 不断预测下一个词出现的概率
Transformer 的核心思想是完全依赖注意力机制,摒弃了传统的循环神经网络(RNN)和卷积神经网络(CNN)结构
让小模型模仿大模型的输出概率分布
token 词表每一家厂商都不同,软蒸馏做不了,大语言 时代是硬蒸馏(SFT),类似于直接拿着教师模型的回答去微调小模型
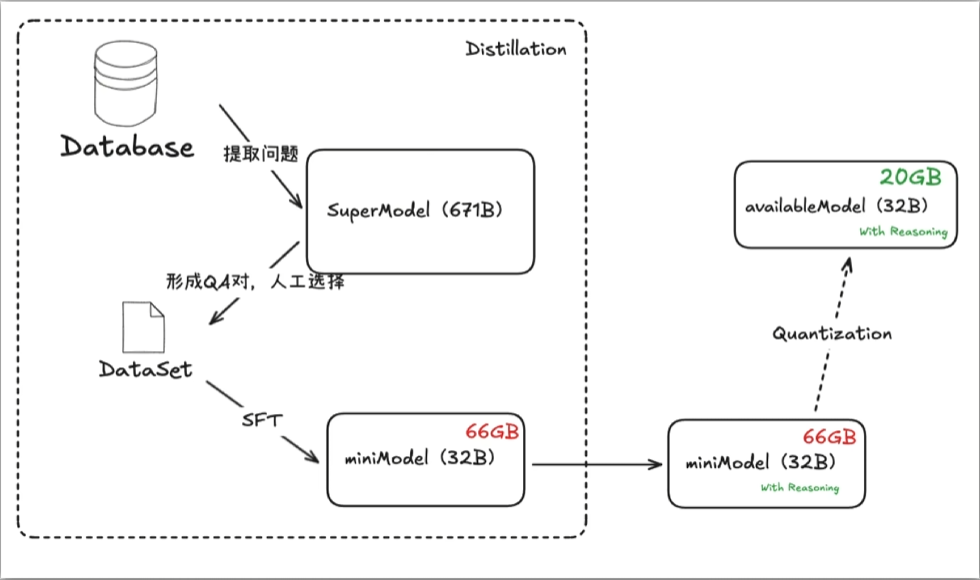
DeepSeek的知识蒸馏

DeepSeek热潮后的新路径
总结
量化与蒸馏是两种重要的模型压缩与优化技术,能够帮助大模型在资源受限的环境中高效运行。
量化通过降低数值精度来减少模型大小和计算复杂度,而蒸馏通过知识迁移将大模型压缩为小模型。
结合使用量化与蒸馏,可以进一步优化模型,使其在保持高性能的同时,适应更多的应用场景。
SuperModel 经过 SFT 量化到企业垂直领域(比如说金融)就只有32b(66GB),之后进行量化到Int4版本后只剩32b(20GB)







![[I.2][个人作业 软件案例分析]](https://s2.loli.net/2025/03/13/NhMm2I4fUtAi3lX.jpg)