Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
1. 论文信息
原文地址:https://arxiv.org/abs/2103.14030
官网地址:https://github.com/microsoft/Swin-Transformer
2. 网络框架
2.1 swim VS vit
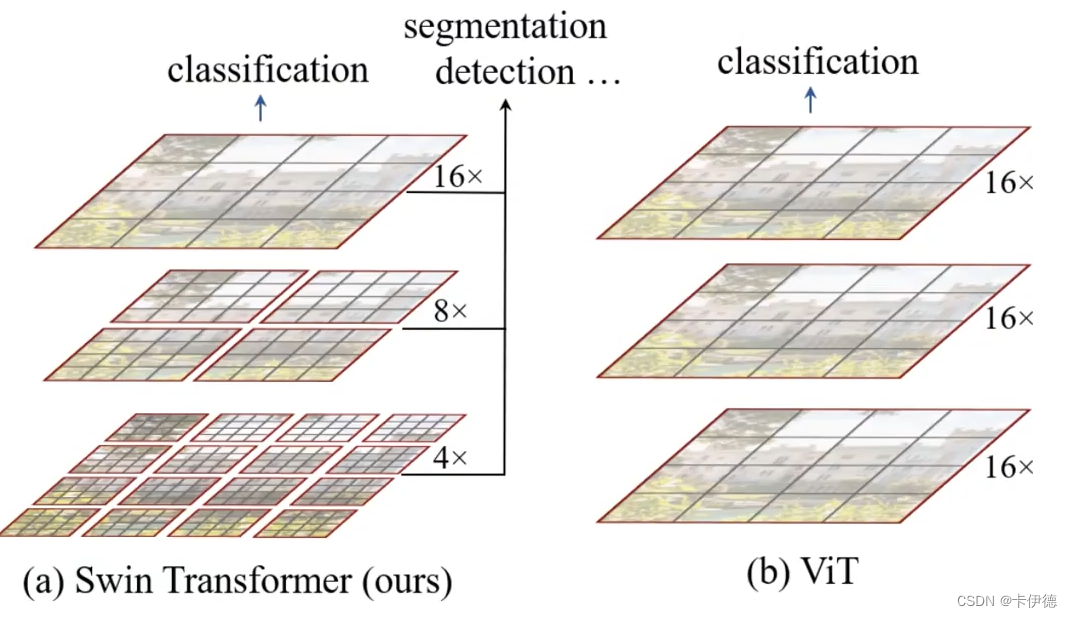
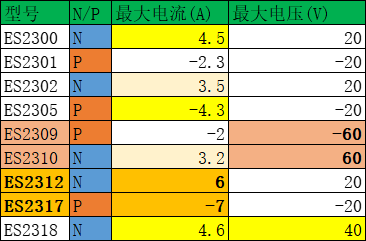
从图中可以得到,Swin相较于ViT的区别在于:Swim模型的特征图具有层次性,随着特征层加深,特征图的高和宽逐渐变小(4倍、8倍和16倍下采样);
**注:**所谓下采样就是将图片缩小,就类似于图片越来越模糊(打码),像素越来越少。如上图(a),最下面的图片大小为经过4倍下采样得到的,中间的为8倍下采样得到的,最上面的为16倍下采样得到的。
2.2 模型整体结构
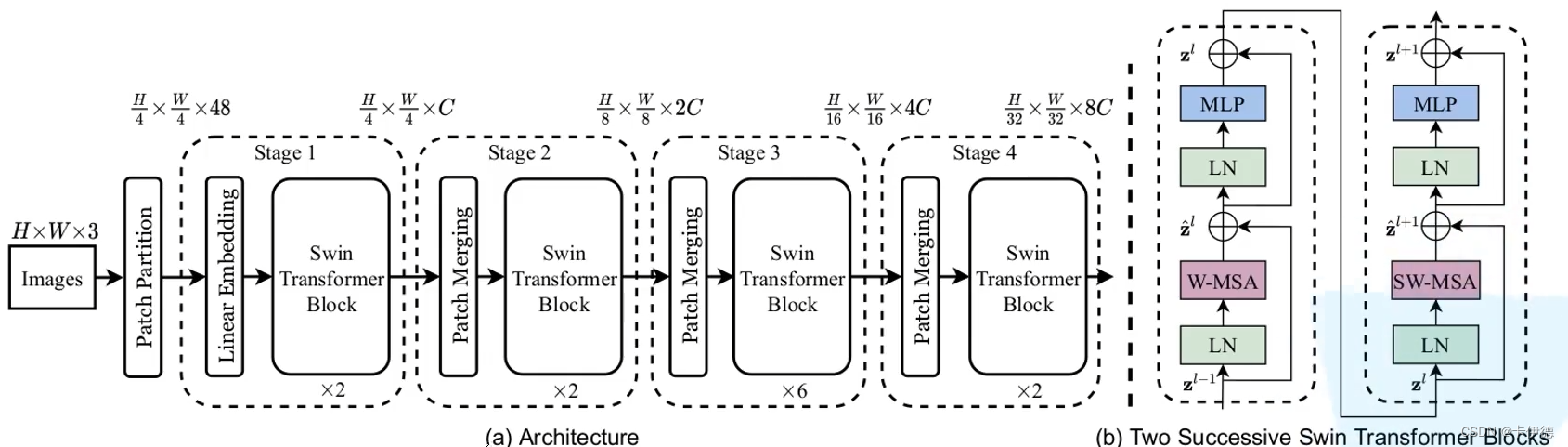
最右边两个图为Swim Transformer的每个块结构,类似于ViT的块结构,其核心修改的地方就是将原本的MSA变为W-MSA。
左边展示的为Swim模型的整个处理流程为:输入(H, W, 3)维的彩色图片,首先执行Patch Partition,特征维度变为(W/4, H/4, 48);接着,连续执行Stage1、Stage2、Stage3和Stage4(注意每个Stage下面有个×2、×6、×n,表示包含n个该Stage),每个Stage的结构几乎相同,维度变化也类似,分别将宽和高变为原来的一半,通道变为原来的二倍。其中,Stage1相较于其他Stage不同的是其第一部分为Linear Embedding,而非Patch Merging。其详细结构如下:
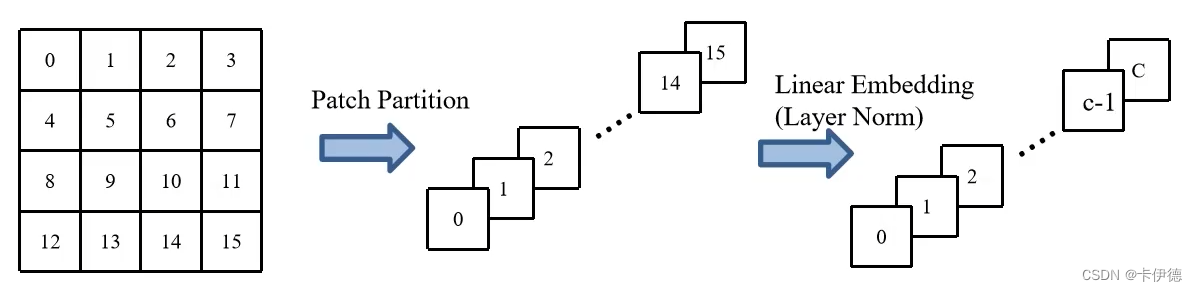
图中,对于一个大小为44的图片而言,为了好理解,将每个块(像素)进行编号0-15;然后执行Patch Partition,将每个块沿着通道维度展开,通俗的理解就是,一个班有16个人,然后去食堂打饭,按照从左往右、从上到下的顺序排好队;这样一来每个块的大小就是H/4和W/4,而通道就是队列的长度163=48(从前往后看,每个人的厚度为3,则16个人厚度为48);最后执行Linear Embedding,该操作主要用来调整通道数,将通道数调整为C(图中画错了,最后一个应该是c-1,而不是C)。
2.3 Patch Merging
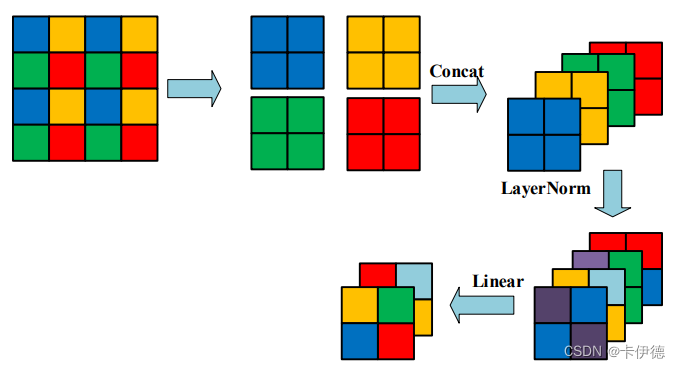
该模块主要存在于Stage2-4,作用主要为下采样,即高和宽减半、通道翻倍,其结构如图:
(https://img-blog.csdnimg.cn/2e9a301e541f4e57abfc67280dd0830c.png)
在如图所示,设输入特征为44维度,首先,用22大小的窗口,将每个窗口内相同位置的像素取出,拼接为四个2×2大小的块;然后,和上面Patch Partition类似,将四个块沿着通道方向拼接,通道变为原来通道的四倍;最后,执行Layer Norm和Linear的全连接,通道变为原来的一半(即原始通道的二倍)。经过以上操作后,通道变为原来的二倍,宽度和高度变为原来的一半。
3 W-MSA详解
W-MSA的全称为Windows Multi-head Self-Attention,相较于MSA而言,引入了Widnwos机制。其对比图如下:
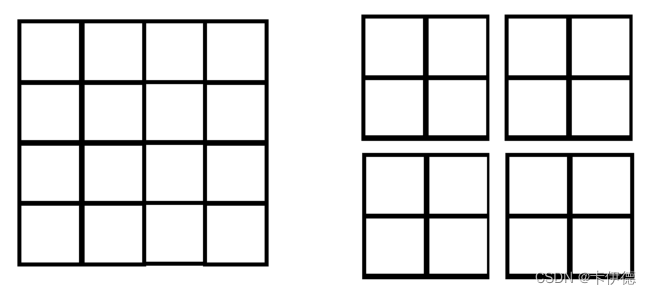
左边为传统的MSA,也是ViT中的核心模块,这种机制是分别计算了每一个像素与其他像素的相关性;
右边W-MSA模块,该模块相较于MSA而言,是将所有的像素划分为多个窗口,然后窗口内部计算每个像素与其他像素的相关性。因此,该方法存在缺点:窗口间缺少信息交互。
3.1 Shifted Window
该方法是用来解决W-MSA模块无法实现窗口间信息交互缺点, 该模块图如下:
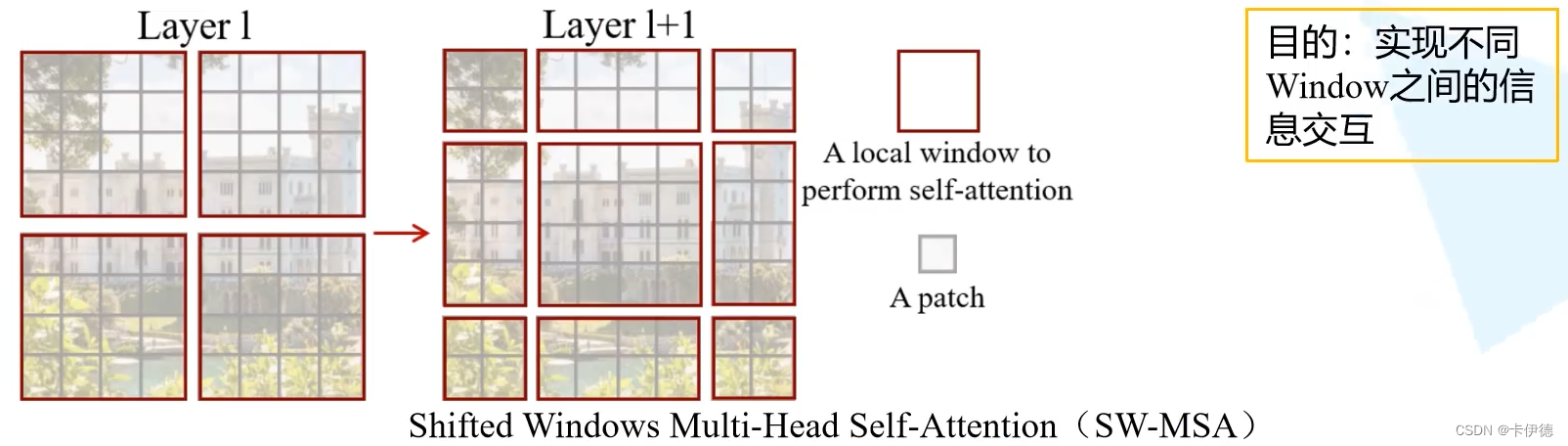
上图表示,在第一个图(第l层)执行完W-MSA时,得到上图左边的结果,则在下一层(第l+1)层须执行Shifted Windows Multi-Head Self-Attention(SW-MSA),得到上图右边的结果,从而实现窗口间信息交流。与W-MSA相比,区别在于划分窗口时不在时等大小的窗口,而是将划分窗口同时向右和向下便宜x个像素。其动态图如下:

图中黑色为像素块,黄色为用来划分窗口的线,原本为能够将图片等分为4个4*4的线,划分结果为上图第l层的图;经过shifted window后,窗口线分别向右和向下平移了两个像素块,即为滑动后的窗口线,划分结果为上图第l+1层的图。
经过以上方法划分之后,即可得到上图中第l+1层的结果。因此,第l+1层 在计算第一行第二个块的注意力信息时则会计算第l层的第一行的两个窗口之间的信息,实现两个不同窗口的交互;其他的也是同样的逻辑,从而实现不同窗口间的信息交互。
3.2 计算量优化
在SW-MSA方法中,将特征划分为多个不规则的块,则增加了计算量,因为W-MSA模块将模型划分为4个等大小的块,而SW-MSA将模型分为9个块,因此模型计算量加大。为此,设计了重新排列了不同的块,具体如下:
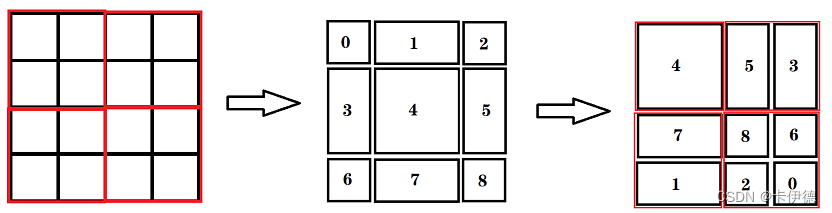
在上图中,左边为W-MSA得划分方法,中间为shifted window划分后的块,每个块进行了0-8的编号。为了减少计算量,首先将1和2两块移到最下方7和8的下面,然后,将3和6移动到右边5和8的右边,最后,将0移动到最右下角。这样可以间接的划分为新得四块,如上图右边红色所圈部分所示,从而保持和W-MSA(左边红色所圈部分)相同得计算量。
但使用该方法后,不难发现,在计算5和3时,会将5和3作为一个整体来计算,然而,5和3是两个不同得窗口。因此,需要设计一种新的计算方法来解决,其解决方法如下:
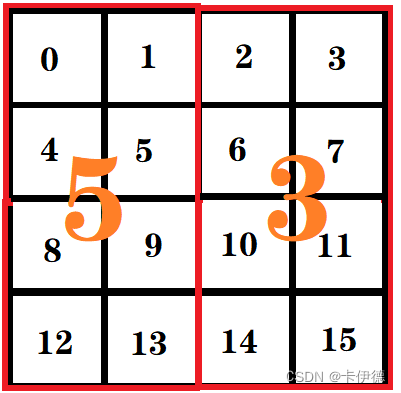
在计算模块5的注意力信息时,和原始的MSA计算方法相同,需要计算每一个像素的q、k、v,然后用q和所有其他像素的k进行匹配计算。就第0像素而言,其q0需要和k0、k1、k2、……、k15进行匹配(其中kn就是第n个像素对应的k值),从而得到16个权重值x(0,0)、x(0,1)、x(0,2)、……、x(0,15)。其中x(a, b)表示第a个元素的query值和第b个元素key值进行匹配计算。最后,在使用注意力公式,分别和每个像素的value值进行计算,并执行softmax()后,即可得到最终的16个注意力值。
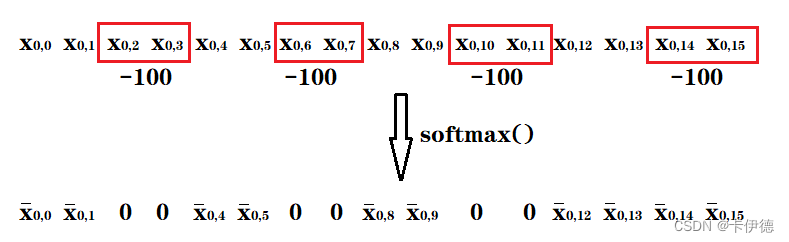
在以上计算中不难发现,在计算第0个像素的注意力信息时,同时引入了模块3中的第2、3、6、7、…、15像素,这将造成一定误差。为解决该问题,原文在计算注意力时,在执行softmax之前,分别将模块3像素对应的注意力值分别减去100,使得softmax后,模块5中每个像素在和第2、3、6、7、…、15像素进行匹配计算时,其权重全为0,只有模块5中的注意力权重为非0值,从而实现模块3对模块5的影响。其计算过程如图所示:
最后,将移动的块还原为原来的位置,如将模块1和2放回最上面。保持原特征图不变。
4. 模型参数
以下展示了Swin Transformer的模型参数,分为四中不同规模:Tiny、Small、Base、Larger。
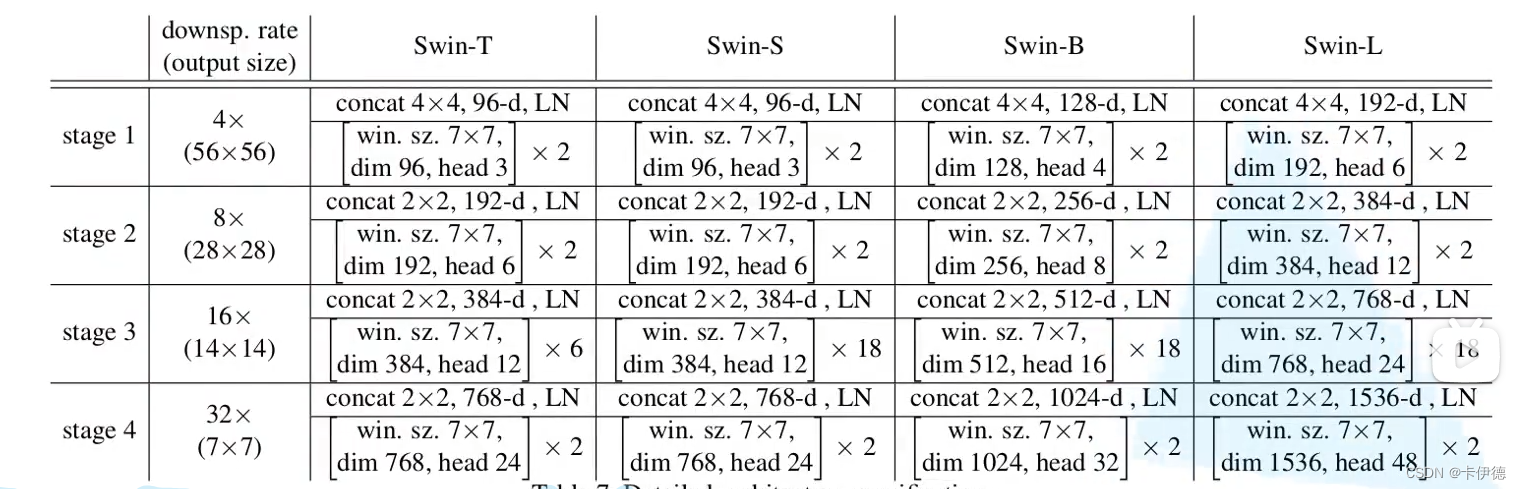
如Swin-T:concat为Patch Partition和Patch Merging操作,4×4表明高和宽变为原来的1/4,96-d表示输出通道为96维。下面×2表示堆叠两个Swin Transformer Block,窗口大小维7×7,输出通道维度为96,多头注意力机制的头数为3,其他的都类似。需要注意的是,在堆叠Swin Transformer Block时,含SW-MSA的块和含W-MSA的块是成对进行的,因此每一个stage的堆叠数都是偶数。(即就是第一块是W-MSA的Block时,则下一个块必须为SW-MSA)
参考博客:https://blog.csdn.net/qq_37541097/article/details/121119988


![题解:P7952 [✗✓OI R1] 天动万象](https://cdn.luogu.com.cn/upload/image_hosting/h78t6evt.png)