引用类型和值类型(一)
关于引用类型和值类型的区别经常听到这样一个说法:“值类型分配在栈上,引用类型分配在堆上”。这个回答并不完全正确,或者说这不是值类型和应用类型真正的差别。官方文档给出的定义:引用类型的变量存储对其数据(对象)的引用,而值类型的变量直接包含其数据。可以理解为值类型的实例直接包含他所有的数据,他们就是值本身,而引用类型的实例包含只是指向数据的指针。所有的类都是引用类型,结构体和枚举是值类型。
内存结构
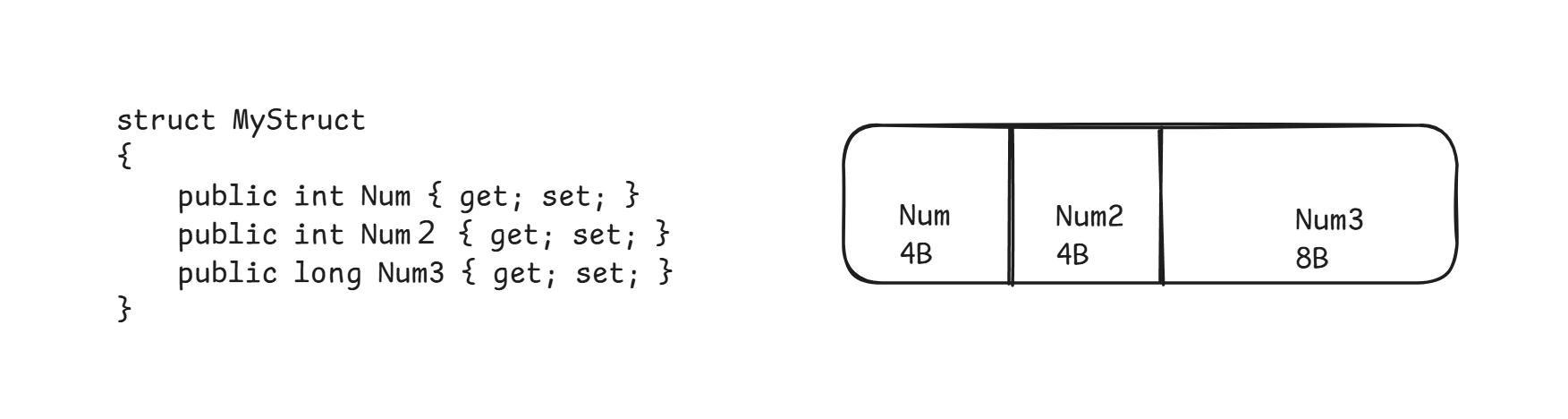
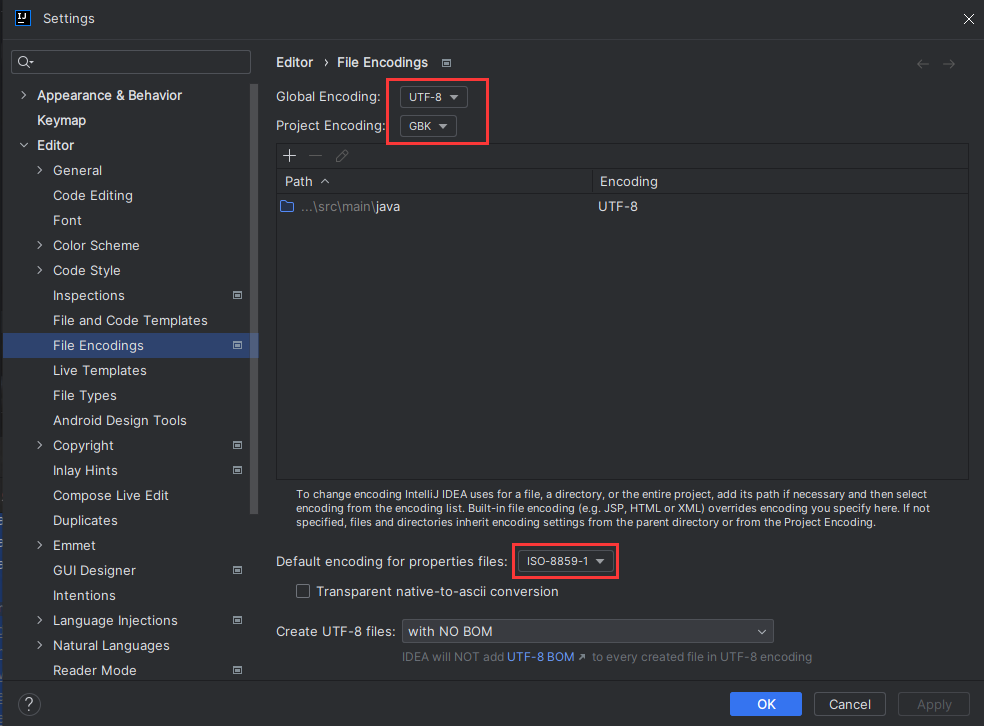
值类型的内存结构比较简单,其实例仅仅包含数据。下图展示的实在64位中的内存布局。32位中long类型的长度位和int的长度一致都是32字节(4字节)。
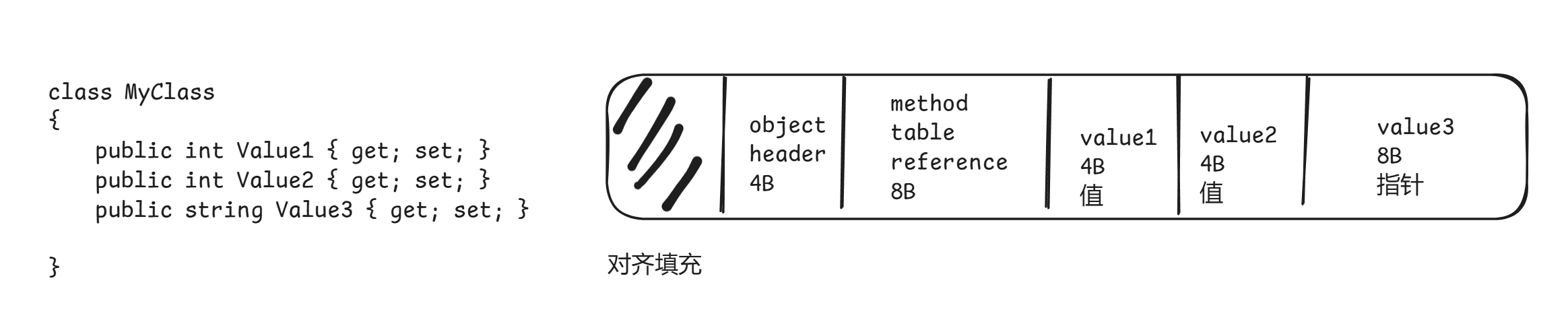
引用类型内存结构包含一下部分:
-
对象头(objcet header):所有平台只会使用4字节,64位会额外占用4字节用于内存对齐。
-
高一位:如果是string类型,用于标记是否包含大于等于0x80的字符(是否包含非ASCII字符)。其他类型用于标记CLR是否检查了此对象
-
高二位:如果是string类型用于标记是否需要特殊的排序方式,如果只包含ASCII字符会转换到int进行排序。这两位可以用于标记是否抑制运行时对象的析构函数(Finalizer),析构函数用于在对象被垃圾回收之前执行一些清理操作,由GC自动管理,抑制不必要的析构函数调用,可以减少垃圾回收的开销。string类型就没有析构函数,也无引用其他对象。
-
高三位:用于标记是否是固定对象,固定的对象GC不会进行移动,主要用于直接访问内存地址的非托管代码交互(强制要求)。
-
高四位:用于标记对象是否通过自旋获取了线程锁。当一个线程成功通过自旋获取锁时,这个位会被设置为1。自旋锁:循环中反复检查锁的状态,直到获取到锁或达到某个限制。
-
高五位:用于标记是否包含同步索引块或Hash值。这里一个常问的面试题就是值类型是否可以作为锁对象(通常问的 值类型是否可以被lock)?此处的lock是.NET提供混合锁(Monitor),混合锁结合了自旋锁和传统的阻塞锁(如互斥锁)的优点:短时间内减少上下文切换的开销,同时在长时间等待时避免CPU资源的浪费。获取锁时候会检查对象头中的是否包含同步索引块,如果没有同步索引块,会创建同步索引块,修改此处标记为包含同步索引块。所以只有引用类型可以作为锁对象。
-
高六位:标记对象是否包含Hash值。
-
-
类型信息(method table reference):一个指向CLR保存类型数据的内存地址的指针(64位下8字节,32位下4字节)。在阻塞GC(非后台GC)的标记方式中,存活对象会标记最后一位为1。
-
字段值:对数据的引用,要求至少有一个(如果没有字段称为数据占位符),如果是值类型直接是数据,引用类型则是指针。
32位下的最小对象: 4字节的头部,4字节的类型信息(一个指针),4字节的数据占位符(一个指针大小)。
64位下的最小对象:8字节头部,8字节的类型信息(一个指针),8字节的数据占位符(一个指针大小)。
下图展示了在64位下的引用类型内存布局。
生命周期和存储位置
“值类型分配在栈上,引用类型分配在堆上”这句话到底对吗?我们先简单的过一下栈和堆的区别。
栈(Stack) 栈是一种后进先出(LIFO,Last In First Out)的数据结构,用于存储局部变量和方法调用信息。栈的特点包括:
-
快速分配和释放:栈上的内存分配和释放非常快,因为它只需要移动栈指针。
-
用于保存函数调用的数据,当方法调用时,局部变量被压入栈中;当方法返回时,局部变量被弹出栈外。
-
一个线程一个函数栈,线程间不可以共享。
-
有限大小:栈的大小是有限的,通常由操作系统或运行时环境决定,.NET 中一个线程默认的函数栈在Windows和Linux下大小为1MB,macOS为512KB,可以在创建线程时候指定大小。如果栈空间不足,会导致栈溢出(Stack Overflow)。
// 创建一个栈大小为2MB的线程
Thread thread = new Thread(new ThreadStart(ThreadMethod), 2 * 1024 * 1024);
堆(Heap) 堆是一种动态内存分配区域。堆的特点包括:
-
较慢的分配和释放。每次分配和释放都需要额外的操作,C++中堆分配需要使用new,释放需要delete。
-
一个进程内的所有线程共享一个内存堆。
-
垃圾回收:CLR使用垃圾回收(Garbage Collection)机制自动管理堆上的内存,释放不再使用的对象。
生命周期
我们知道一个局部变量和方法参数的生命周期和作用域是有限的,通常只在定义它们的代码块内有效,当变量超出作用域时,它们的实例被销毁,内存就需要被释放。可以理解为:只在一个函数内使用的数据,会随着函数进行分配,函数返回的时候他就会释放。
值类型的是个独立的存在,他们的值就是他们本身,值类型的实例和他们包含的数据生存期一样长。
引用类型的值存储位置的指针,当作用域结束的时候,变量的实例(存储的指针)出栈,但是指针指向数据(一般在堆上)此时没有被GC。引用类型实例所包含的值的生存期和实例无关。
最佳情况下数据在不使用的时候就应该立即被释放,但是达到这个状态非常不易。无垃圾回收的语言需要程序员手动的编写代进行回收,此时空指针和内存泄漏就成了易犯的问题。Rust通过复杂的所有权、借用和生命周期来实现,这也带了更陡峭的学习成本。
.NET中的堆分配使用的new关键字,释放则由GC来处理。下面是一个引用类型变量的构建和Release下编译的IL代码。 newobj:在托管堆上为新对象分配内存,调用指定类型的构造函数来初始化新对象。
var myClass = new MyClass { Num = 1 };
IL_0000: newobj instance void MyClass::.ctor() // 创建一个新的 MyClass 实例并调用其构造函数
IL_0005: dup // 复制堆栈顶部的 MyClass 实例
IL_0006: ldc.i4.1 // 将整数值 1 加载到堆栈
IL_0007: callvirt instance void MyClass::set_Num(int32) // 调用 MyClass 实例的 set_Num 方法,传入值 1
IL_000c: stloc.0 // 将 MyClass 实例存储在本地变量 0 中
堆分配和栈分配
值类型的实例就是其值,放在栈上既可以无需在堆中分配内存,销毁时也会一起出栈无需GC,这会带了更好的性能和内存使用率。为了能存储更大的数据和匹配的生存期,将引用类型放在堆中也是合理的选择。
下面会基于各种情况进行分析:
-
局部变量和方法参数:生存期可控和明显,方法结束时即可释放。值类型类型被存放在栈中,引用类型的实例会存放在栈中,值在堆中。
-
闭包中的局部变量:当一个局部变量被闭包捕获时,CLR会将该变量提升到堆上,以确保它在闭包的整个生命周期内保持有效,所以都会分配在堆中。
-
引用类型的字段:作为引用类型的实例生存期比作用域要长,不适合存放在栈中,如果一个值类型作为一个引用类型的字段会和引用类型的实例一起存放在堆中。
-
值类型的字段:和父级实例保持一致,一起在堆或栈中。
-
数组:分配在堆中,值类型直接存储数据本身,内联的。引用类型是数组是外联的,分配和释放比会带来更高的消耗。
-
静态字段:在程序所驻留的应用程序域的生存期内,静态类的实例会一直保留在内存中。需要保存在堆中。
-
评价堆栈:评价堆栈用于临时存储操作数和计算结果。此时实例会存在寄存器中。
-
强制存放在栈中:ref struct会分配在栈上,限制较多,都是为了保证其在栈上分配。
可以看出,CLR会尽可能的分配数据在栈和寄存器中,带了更好的性能。总结就是:引用类型指针指向的数据一定是存放在堆中。值类型和引用类型局部变量和方法参数会存储在栈上。位于堆上数据的一部分的时候,存储在堆上。评价堆栈处理中的时候存储在CPU的寄存器中。
在Go语言中,逃逸分析决(编译时)定了分配在堆还是栈中。当函数的外部没有引用的时候,会优先存放在栈中。如果一个局部变量被函数返回指针的时候就是一个典型的内存逃逸,当然在栈空间不足和类型为interface(Go语言中的动态类型)的时候也会产生逃逸。
引用传递和值传递
C# 中的参数默认按值传递给函数。 这意味着将变量的副本会传递到方法。 对于值类型,值的副本将传递到方法。 对于引用 类型,引用的副本将传递到方法。引用传递的会直接传递引用类型的值和值类型的地址到方法。
下面结合官方文档解释:
值传递值类型:
-
如果方法分配参数以新的实例,则这些更改在调用方是不可见的
-
如果方法修改参数的属性,则这些更改在调用方是不可见的
值类型在按值传递给方法的时候,传递的是值的副本 ,所以方法中修改的值的副本无法影响到原本的值。
值传递引用类型:
-
如果方法分配参数以新的实例,则这些更改在调用方是不可见的:
引用类型在按值传递给方法的时候,传递的是引用的副本,但是副本和本身都是引用的同一个对象,指向同一块内存,所以在方法中做属性或者状态的变更,调用方是可见的。
-
如果方法修改参数的属性,则这些更改在调用方是可见的:
如果把副本指向一个新的引用,这时只是修改了副本指向的引用,并不会修改到原本数据引用的对象,此时调用方是不可见修改的。
这个例子中,声明了引用类型MyClass和值类型MyStruct ,ChangeNumb方法修改Numb为3,New方法指向一个新的Numb为2的示例。验证了四种情况的输出。
var myClass = new MyClass { Num = 1 };
var myStruct = new MyStruct { Num = 1 };
ClassNew(myClass, 2);
Console.WriteLine($"myClass.Num: {myClass.Num}");
ClassChangeNumb(myClass, 3);
Console.WriteLine($"myClass.Num: {myClass.Num}");
StructNew(myStruct, 2);
Console.WriteLine($"myStruct.Num: {myStruct.Num}");
StructChangeNumb(myStruct, 2);
Console.WriteLine($"myStruct.Num: {myStruct.Num}");
// 输出
// myClass.Num: 1
// myClass.Num: 3
// myStruct.Num: 1
// myStruct.Num: 1
// 引用类型 方法修改参数的属性
void ClassChangeNumb(MyClass myClass, int numb)
{
myClass.Num = numb;
}
// 引用类型 方法分配参数以新的实例
void ClassNew(MyClass myClass, int numb)
{
myClass = new MyClass { Num = numb };
}
// 值类型 方法分配参数以新的实例
void StructNew(MyStruct myStruct, int numb)
{
myStruct = new MyStruct { Num = numb };
}
// 值类型 方法修改参数的属性
void StructChangeNumb(MyStruct myStruct, int numb)
{
myStruct.Num = numb;
}
class MyClass
{
public int Num { get; set; }
}
struct MyStruct
{
public int Num { get; set; }
}
按引用传递值类型时:
-
如果方法分配参数以新的实例,则这些更改在调用方是可见的。
-
如果方法修改参数所引用对象的状态,则这些更改在调用方是可见的。
按引用传递引用类型时:
-
如果方法分配参数以新的实例,则这些更改在调用方是可见的。
-
如果方法修改参数的属性,则这些更改在调用方是可见的。
var myClass = new MyClass { Num = 1 };
var myStruct = new MyStruct { Num = 1 };
ClassNew(ref myClass, 2);
Console.WriteLine($"myClass.Num: {myClass.Num}");
ClassChangeNumb(ref myClass, 3);
Console.WriteLine($"myClass.Num: {myClass.Num}");
StructNew(ref myStruct, 2);
Console.WriteLine($"myStruct.Num: {myStruct.Num}");
StructChangeNumb(ref myStruct, 2);
Console.WriteLine($"myStruct.Num: {myStruct.Num}");
// 输出
// myClass.Num: 2
// myClass.Num: 3
// myStruct.Num: 2
// myStruct.Num: 2
// 引用类型 方法修改参数的属性
void ClassChangeNumb(ref MyClass myClass, int numb)
{
myClass.Num = numb;
}
// 引用类型 方法分配参数以新的实例
void ClassNew(ref MyClass myClass, int numb)
{
myClass = new MyClass { Num = numb };
}
// 值类型 方法分配参数以新的实例
void StructNew(ref MyStruct myStruct, int numb)
{
myStruct = new MyStruct { Num = numb };
}
// 值类型 方法修改参数的属性
void StructChangeNumb(ref MyStruct myStruct, int numb)
{
myStruct.Num = numb;
}
class MyClass
{
public int Num { get; set; }
}
struct MyStruct
{
public int Num { get; set; }
}
虽然值类型无需额外的内存分配和销毁工作,但是数据较大时进行值传递带来的性能损耗可能大于堆分配。可以使用引用传递值类型来解决这个问题。当数据较小时候,编译器的内联编辑,会合并两个方法,从某种角度上避免了值传递的复制。这个大小的限制大约是24字节。
值传递更好还是引用类型
装箱和拆箱
值类型和引用类型在内存结构差距主要在多了对象头和类型信息。当我们把值类型转换到引用类型的时候就要给他加上对象头和类型信息。这就是装箱。C#中的所有类型的基类是object,装箱也是转到object。
装箱的过程:
-
分配内存:在托管堆上分配内存以存储值类型的副本。
-
复制值:将值类型的值复制到新分配的堆内存中。
-
返回引用:返回指向该堆内存的引用。
拆箱的代价比装箱要低的多,就是获取指针。
此处引用CLR via C#的例子:来看看这个代码发生几次装箱
var v = 5;
object c = v;
v = 123;
Console.WriteLine(v+","+c);
IL_0000: ldc.i4.5
IL_0001: stloc.0 // v
// [4 1 - 4 14]
IL_0002: ldloc.0 // v
IL_0003: box [System.Runtime]System.Int32
IL_0008: stloc.1 // c
// [5 1 - 5 9]
IL_0009: ldc.i4.s 123 // 0x7b
IL_000b: stloc.0 // v
// [6 1 - 6 28]
IL_000c: ldloca.s v
IL_000e: call instance string [System.Runtime]System.Int32::ToString()
IL_0013: ldstr ","
IL_0018: ldloc.1 // c
IL_0019: brtrue.s IL_001e
IL_001b: ldnull
IL_001c: br.s IL_0024
IL_001e: ldloc.1 // c
IL_001f: callvirt instance string [System.Runtime]System.Object::ToString()
IL_0024: call string [System.Runtime]System.String::Concat(string, string, string)
IL_0029: call void [System.Console]System.Console::WriteLine(string)
从IL代码可以看出只在第二行代码进行了装箱。而书中告诉我们发生了三次装箱,那是因为在书中变量v到string的过程使用了box,而此处用了System.Int32::ToString()。编译器对此处做了优化。书中使用的环境是.net framework 4.5。



CSP-S 2024 查漏补缺](https://img2024.cnblogs.com/blog/3322276/202408/3322276-20240825221807403-928502409.png)