DocKylin: A Large Multimodal Model for Visual Document Understanding with Efficient Visual Slimming
arxiv:http://arxiv.org/abs/2406.19101
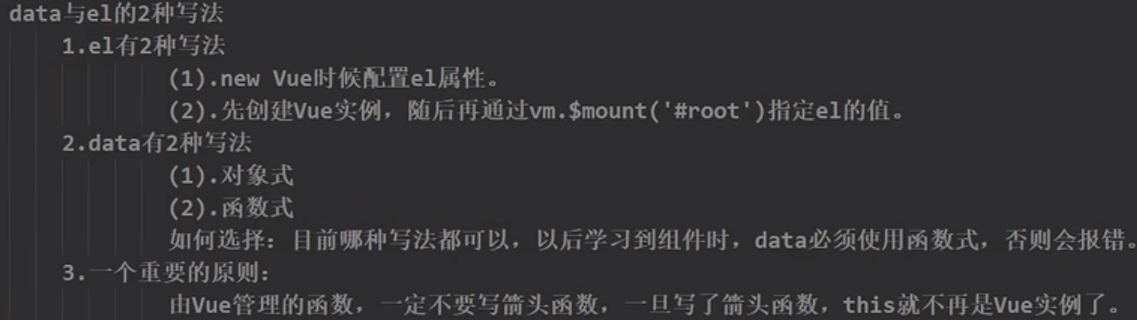
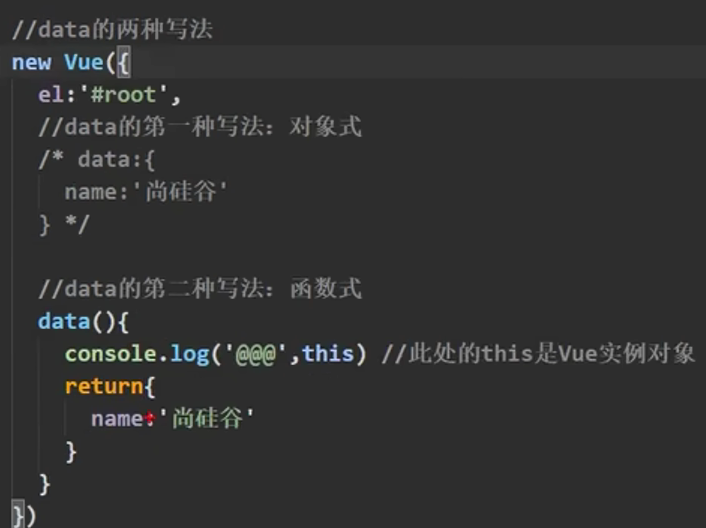
视觉处理器+LLM:视觉处理器:Swin Transformer
创新点:通过:1、去除图片冗余像素;2、去除冗余token。来减小模型中的视觉处…
B
可以直接统计每条边两个点的情况即可,不用DFS。 F
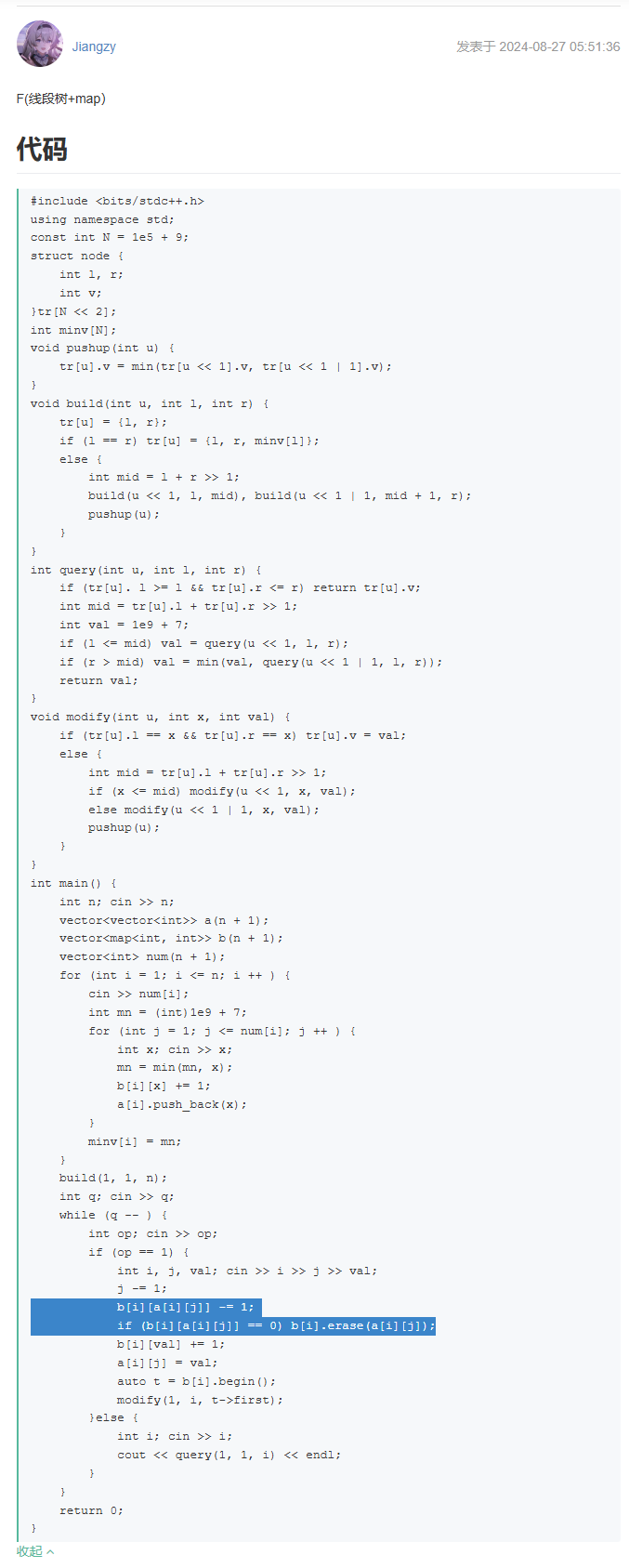
写法和这个差不多。可以用map、set、统计这些方法,计算动态的一个数组的最大数。
可以直接用map统计就行,map已经自动给你排好序了(从小到大)。1 #include <bits/stdc++.h>2 using namespace std;3 #define LL lo…