-
1.总览
-
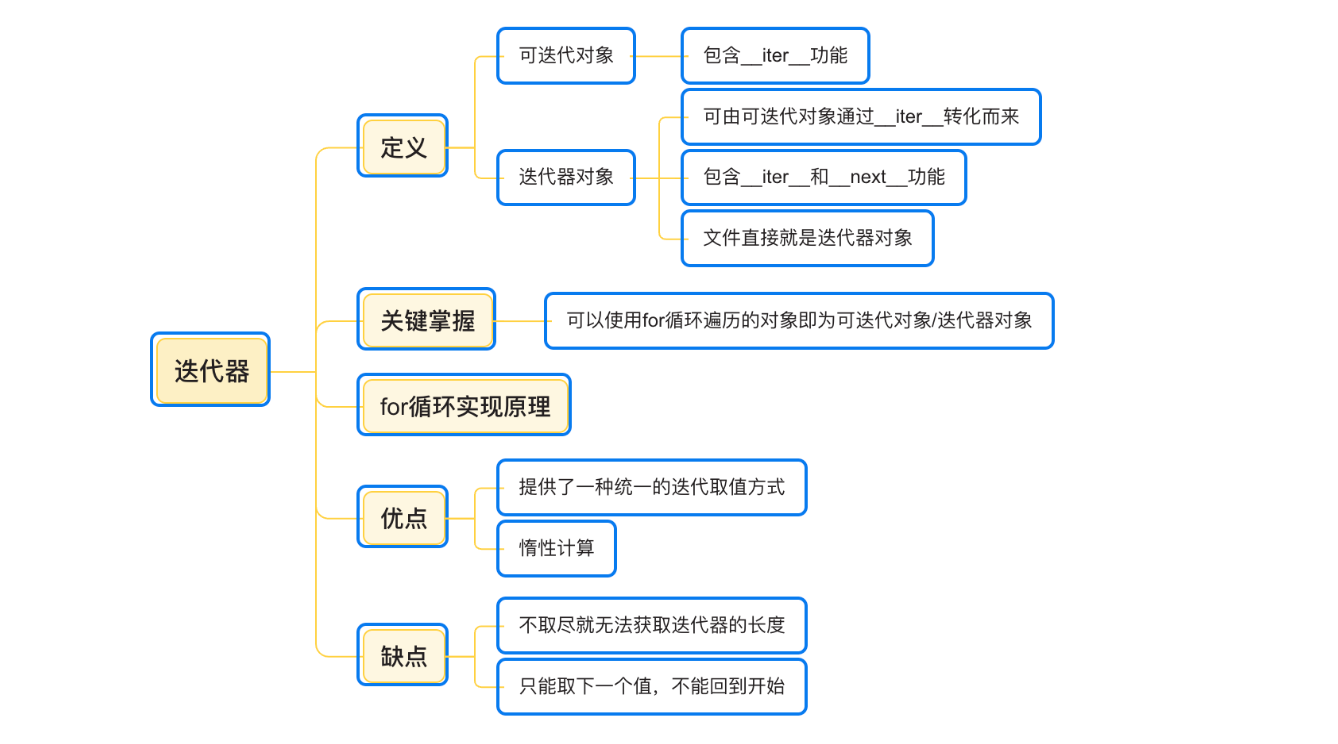
2.迭代器介绍
- 2.1:迭代器是一个实现了迭代协议的对象,它可以让我们遍历一个容器中的所有元素,而不需要知道容器的内部结构,迭代器可以用于遍历列表,元祖,字典,集合等容器类型;
- 2.2:迭代器的工作原理是通过实现两个方法:iter()和__next__()方法,iter()方法返回迭代器对象本身,next()方法每次调用都会返回容器中的下一个元素,直到容器中的所有元素都被遍历完毕后,再调用__next__()方法就会抛出Stopiteration异常;
-
3.for循环底层原理
# 可迭代对象 === 容器
list01 = [11,22,33,44]# 迭代过程
# for item in list01:
# print(item)# 迭代原理
# 面试题:for循环的原理是什么?
# 可以被for的条件时什么?
# 答:必须具备__iter__方法
# 1.获取迭代器
iterator = list01.__iter__()
# 2.循环获取每一个元素
while True:try:item = iterator.__next__()print(item)# 3.遇到异常停止迭代except StopIteration:break
-
3.1:可以直接用作for循环的数据类型有:1、集合数据类型,如list,tuple,dict,set,str等;2、generator,包含生成器和带yeild的generator方法。这些用作for循环的对象统称为可迭代对象:iterable;而可以被next()函数调用并且不断返回下一个值的对象称为迭代器:iterator。
-
3.2:list,dict,str等虽然是iterable,却不是iterator
注:为什么list,dict,str等数据类型不是iterator?因为python的iterator对象表示的是一个数据流,iterator对象可以被next函数调用并且不断返回下一个数据,直到没有数据抛出Stopiteration错误,可以把这个数据流看做是一个有序序列,但我们却不能提前知道序列的长度,只能通过next函数实现下一个数据,所以iterator的计算是惰性的。 -
4.自定义迭代器
"""
迭代器:
"""
class Skill:passclass SkillIterator:def __init__(self,target):self.__target = targetself.__index = 0def __next__(self):# 如果没有数据了,抛出异常if self.__index > len(self.__target)-1:raise StopIteration# 返回下一个数据temp = self.__target[self.__index]self.__index += 1return tempclass SkillManger:def __init__(self):self.__skills = []def add_skill(self,skill):self.__skills.append(skill)def __iter__(self):# 创建一个迭代器对象,并传递需要被迭代的数据return SkillIterator(self.__skills)manger = SkillManger()
manger.add_skill(Skill())
manger.add_skill(Skill())
manger.add_skill(Skill())# for item in manger:
# print(item)iterator = manger.__iter__()
while True:try:item = iterator.__next__()print(item)except StopIteration:break
- 5.迭代器的优缺点
- 优点
- 为序列和非序列类型提供了一种统一的迭代取值方式。
- 惰性计算:
- 迭代器对象表示的是一个数据流,可以只在需要时才去调用next来计算出一个值
- 就迭代器本身来说,同一时刻在内存中只有一个值,因而可以存放无限大的数据流,
- 而对于其他容器类型,如列表,需要把所有的元素都存放于内存中,受内存大小的限制,可以存放的值的个数是有限的。
- 缺点
- 除非取尽,否则无法获取迭代器的长度
- 只能取下一个值,不能回到开始,更像是‘一次性的’,迭代器产生后的唯一目标就是重复执行next方法直到值取尽,否则就会停留在某个位置,等待下一次调用next;
- 若是要再次迭代同个对象,你只能重新调用iter方法去创建一个新的迭代器对象,如果有两个或者多个循环使用同一个迭代器,必然只会有一个循环能取到值。
- 优点