- 概
- Adam-mini
- 代码
Zhang Y., Chen C., Li Z., Ding T., Wu C., Ye Y., Luo Z. and Sun R. Adam-mini: Use fewer learning rates to gain more. arXiv preprint, 2024.
概
作者提出一种简化的 optimizer, 在取得和 Adam 相媲美的性能的同时, 只需要一半的内存开销.
Adam-mini
-
我们知道, Adam 有两个动量:
\[m \leftarrow (1 - \beta_1) \cdot g + \beta_1 \cdot m \in \mathbb{R}^d, \\ v \leftarrow (1 - \beta_2) \cdot g^2 + \beta_2 \cdot v \in \mathbb{R}^d. \]其中 \(m\) 指定了下降的方向, 而 \(1 / \sqrt{v}\) 则为每个元素的下降制定了特别的学习率.
-
虽然这么做使得训练更加平稳和快速, 但是为了训练我们需要缓存 2x 模型大小的量, 这个在当下特别是大模型盛行的现在可能不是那么好使的. 因此, 本文希望设计一个更加轻量化的优化器.
-
和之前的一些策略类似, 本文的出发点是能不能让一些元素共享一个学习率, 而不是单独设置, 假设我们有 block 从 \(b=1, \ldots, B\), 则 Adam-mini 给每个 block 设置
\[v_b \leftarrow (1 - \beta)_2 \cdot \text{mean}(g_b^2) + \beta_2 \cdot v \in \mathbb{R}. \] -
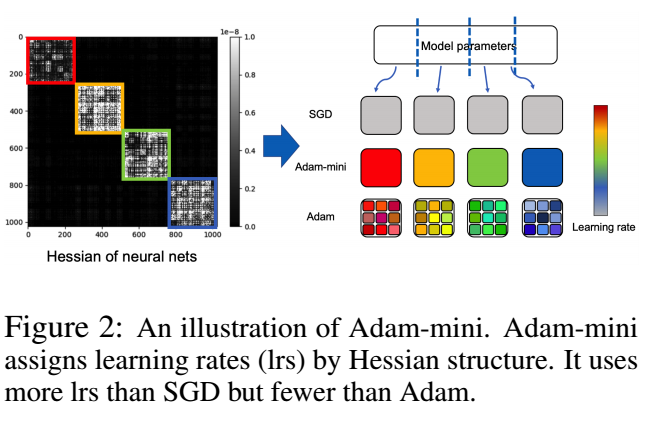
这个思路其实一些之前的方法也尝试过, 但是效果并不好, 会有比较大的性能的损耗. 本文的方案启发自 here, 这里面发现, 像 Transformer 这类模型, 每个 block (Query/Key/Value/Embedding) 的 Hessian 矩阵的谱很不相同, 这意味着, 为如果我们在圈定 block 的时候把这些打包在一起, 就会产生一个较差的结果.

-
所以, 作者认为, 理想情况是 (作者做了很多实验来验证这一点), 神经网络中模块一直分解到所对应的 hessian 矩阵不再出现如上图所示的分块的时候为止.
-
当然了这么搞是比较麻烦的. 粗略一点的, 作者有如下的建议:
- transformer 中的 query/key 的每个 head 单独成一个 block;
- transformer 中的 value 单独成一个 block, 因为作者发现 value 对应的 hessian 矩阵以及不能分解了 (即使是多头的);
- embedding 依旧按照原本 adam 进行训练 (因为 embedding 层不是每个都在训练中得到训练的);
- 其它的 block 可以按照 PyTorch 的默认划分

代码
[official]