目录
- 概
- DCN-v2
Wang R., Shivanna R., Cheng D. Z., Jain S., Lin D., Hong L. and Chi E. D. DCN V2: Improved deep & cross network and practical lessons for web-scale learning to rank systems, 2020.
概
DCN 的升级版.
DCN-v2
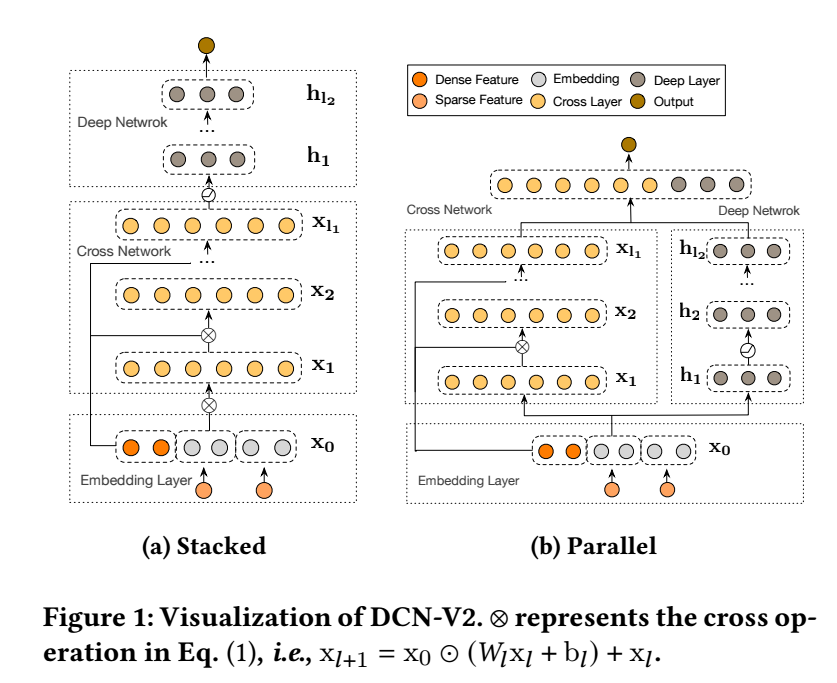
-
DCN-v2 的 cross/deep 的结合方式上有上述两种, 具体的好坏和数据有关系.
-
相较于 DCN, DCN-v2 的主要改进在于 cross network 部分:
\[x_{l+1} = x_0 \odot (W_l x_l + b_l) + x_l. \]这里 \(W_l \in \mathbb{R}^{d \times d}\), 之前的 DCN 是 \(W_l \in \mathbb{R}^{1 \times d}\).
-
特别的, 作者发现, 这种方式学出来的 \(W\) 通常是低秩的, 所以对于 \(W_l\) 做了进一步的改进:
\[W_l = U_l V_l^T, \quad U_l, V_l \in \mathbb{R}^{d \times r}, \quad r \ll d, \quad r \ll d. \]
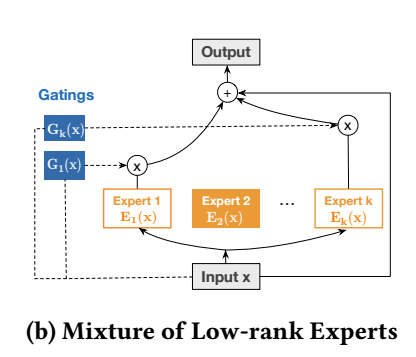
- 同时, 引入 MoE 机制:\[x_{l+1} = \sum_{i=1}^K G_i(x_l) E_i(x_l) + x_l, \]其中 \(G_i(\cdot)\) 得到对第 i 个专家的权重 (通过 sigmoid, softmax 等实现), \(E_i\) 则定义如下:\[E_i(x_l) = x_0 \odot \big(U_l^i \cdot g(C_l^i \cdot g({V_l^i}^T x_l)) + b_l \big). \]这是对在压缩到低维空间后通过非线性激活函数 \(g(\cdot)\) 和 \(C_l^i\) 仅进一步的转换.