简介
模拟退火算法(Simulated Annealing, SA) 是一种概率型全局优化算法,它受到物理退火过程的启发。在固体材料的退火过程中,材料被加热到一定温度后缓慢冷却,其内部结构逐渐趋于稳定,最终达到能量最低的平衡状态。模拟退火算法正是模仿这一过程,用于寻找数学问题中的全局最优解。
特点
- 跳出局部最优:通过一定概率接受较差解,算法能够跳出局部最优陷阱。
- 全局搜索能力:高温度下的大范围搜索使得算法具有较好的全局搜索能力。
- 自适应性:随着温度的降低,搜索过程逐渐聚焦于解空间中的优质区域。
模拟退火与梯度下降的区别
应用上的区别
模拟退火:适用于解决复杂的优化问题,特别是当问题具有多个局部最优解时。它可以用于连续或离散的优化问题。
梯度下降:主要用于机器学习和深度学习中的参数优化,特别是在目标函数是连续且可微的情况下。
特点上的区别
模拟退火:通过概率接受更差的解,可以跳出局部最优,但计算成本可能较高,因为它可能需要多次迭代才能找到好的解。
梯度下降:通常收敛速度快,但在面对非凸优化问题时可能会陷入局部最优解。
基本思想
- 初始状态:算法从某个初始解开始,通常是一个随机解。
- 温度参数:设定一个初始温度,这个温度参数控制着算法搜索解空间的随机性。
- 迭代过程:在每次迭代中,算法在当前解的邻域内随机选择一个新的解,步幅与当前温度有关,温度越大,步幅越大。
- 接受准则:如果新解比当前解更优,那么接受新解作为当前解。如果新解更差,以一定的概率接受新解,这个概率随着解的质量下降而降低,且随着温度的降低而减小。这个概率通常由以下公式决定:$ P(accept worse solution)=exp(− \frac{ΔE}{k·T}) $
其中:- $ ΔE $ 是新解的能量与当前解能量的差值(在优化问题中,可以理解为目标函数值的差值)。
- $ k $ 是一个常数,通常在模拟退火中可以设为1。
- $ T $ 是当前的系统温度。
- 降温过程:在一定的迭代次数后降低温度,使搜索过程逐渐集中到更优解的区域。
算法步骤
- 初始化:选择一个初始解和初始温度。
- 迭代:对每一个温度值,重复以下过程直到满足终止条件:
- 产生一个新解。
- 计算新解与当前解的目标函数值差。
- 如果新解更优或随机概率接受准则允许,则接受新解。
- 降温:根据预设的降温方案降低温度。
- 终止:当温度降至某一阈值或达到最大迭代次数时,算法终止。
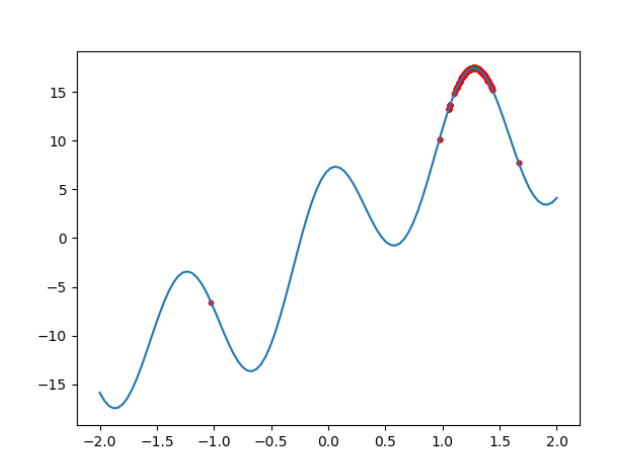
运行截图
Full Code
import math
import random
import numpy as np
import matplotlib.pyplot as pltT = 1.0 # 初始温度
delta = 0.99 # 变化率
eps = 1e-3 # 出口阈值
k = 1.0 # 计算是否接受更差解时的系数kT = k * T # k与T的乘积W = 2 # 定义域半径(-W, W)# 函数f(x)
f = lambda x: 11 * np.sin(x) + 7 * np.cos(5 * x)# 初始解为定义域内的随机数
x0 = random.uniform(-W, W)
# 计算部分
while T > eps:x1 = x0 + T * 2 * random.uniform(-W, W)while x1 > W or x1 < -W:# 确保x1落在定义域内x1 = x0 + T * 2 * random.uniform(-W, W)f0 = f(x0)f1 = f(x1)if f1 > f0: # 新解更优,无条件接受x0 = x1elif math.exp((f1 - f0) / kT) > random.random(): # 概率接受更差解x0 = x1T *= delta# 绘制点plt.scatter(x0, f(x0), c='r', s=10) # 过程点为红色# 绘图部分
X = np.linspace(-W, W, 100)
plt.plot(X, f(X), label="func")
plt.scatter(x0, f(x0), c='g', s=10) # 最终点为绿色
plt.show()