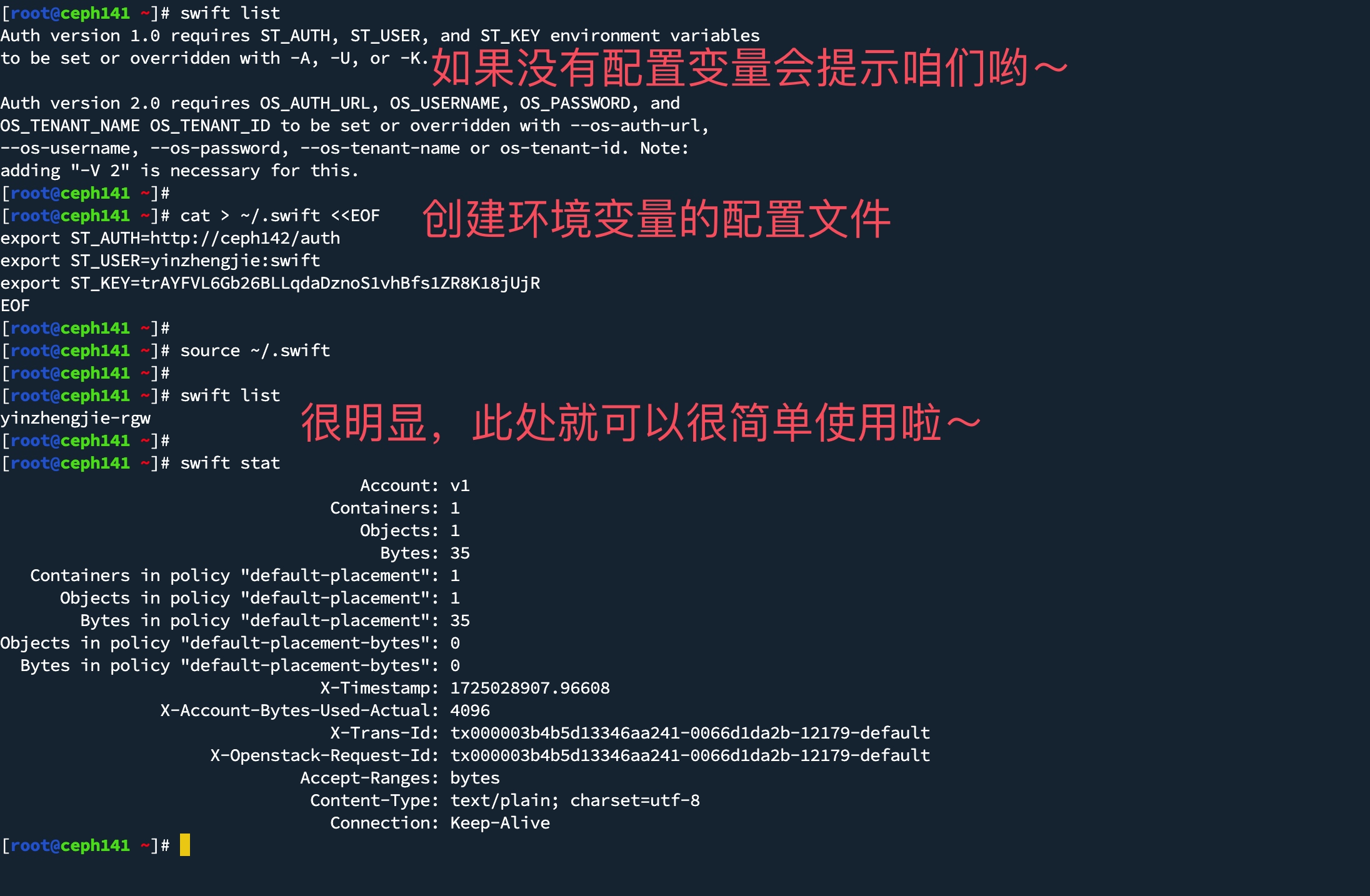
这个题目是什么意思呢?简单来说就是在一个数组中找出两个元素,使其和为我们设定的值,并且每个元素只能用一次。
如下图具体示例:

到这里不知道你是否已经有解题思路了呢?
解法一:双层循环
我第一反应就是双层循环,直接暴力破解。因为题目要求每个元素只能使用一次,并且已经计算过的也没必要再次计算,因此内层循环索引起始可以以外层索引+1作为起始点,具体代码如下:
public static int[] TwoSumForFor(int[] nums, int target) {for (var i = 0; i < nums.Length; i++){for (var j = i + 1; j < nums.Length; j++){if (nums[i] + nums[j] == target){return [i, j];}}}return []; }
我们直接验证一下,通过了:
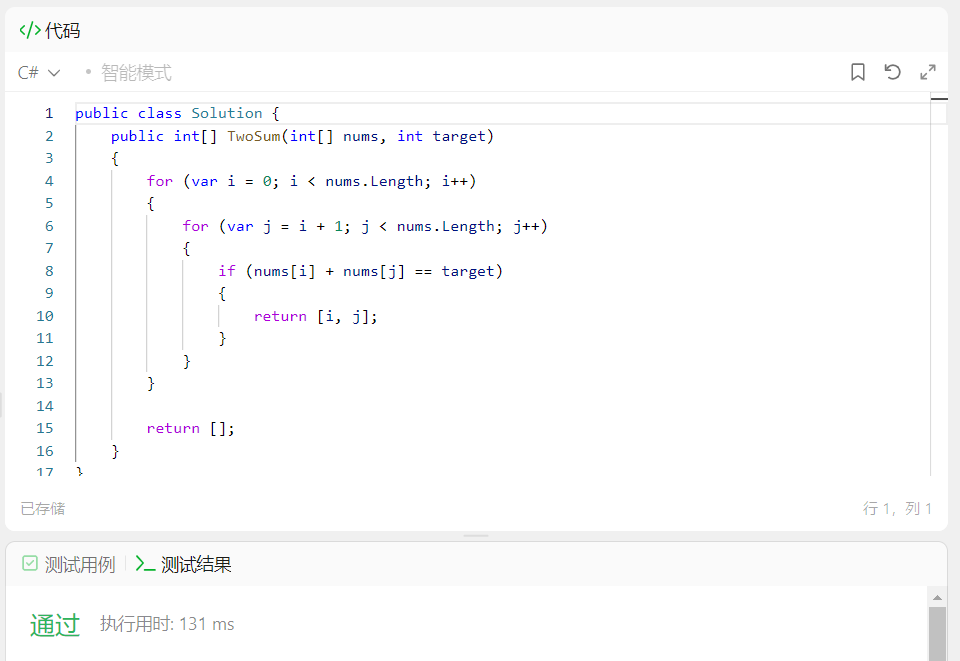
因为是双层循环因此算法时间复杂度是:O(N2),因为没有引用额外的空间因此空间复杂度是:O(1)。
注:上面的[] ,[i, j]是C#12版本新增功能,是数组简洁表达语法。
解法二:双层循环+左右开弓
如果想在双层循环基础上继续优化算法要怎么办?
我们就按正常思维逻辑来梳理一下双层循环干了什么,外层循环:表示第一个加数,并且从第一个数到最后一个数循环一遍;内层循环:表示第二个加数,其作用就是使第一个加数按从前到后的顺序和其后面的每一个数加一遍。既然如此那能不能从前往后计算的同时也从后往前计算呢?显然使可以的,代码如下:
public static int[] TwoSumForForBidirectional(int[] nums, int target) {for (var i = 0; i < nums.Length; i++){var front = nums[i];var backIndex = nums.Length - 1 - i;var back = nums[backIndex];for (var j = i + 1; j < nums.Length; j++){if (front + nums[j] == target){return [i, j];}if (back + nums[j - 1] == target){return [j - 1, backIndex];}}}return []; }
运行结果如下:
理想情况下可能会提升一倍的效率,但是细心的朋友应该发现,平台上的运行结果,比双层循环还长了3ms,不过感觉这个平台结果不是很准,下面我们用基准测试,对两个方法进行测试,我们随机构建长度为2000的数组,并把目标数随机放到不同位置,测试10000次。
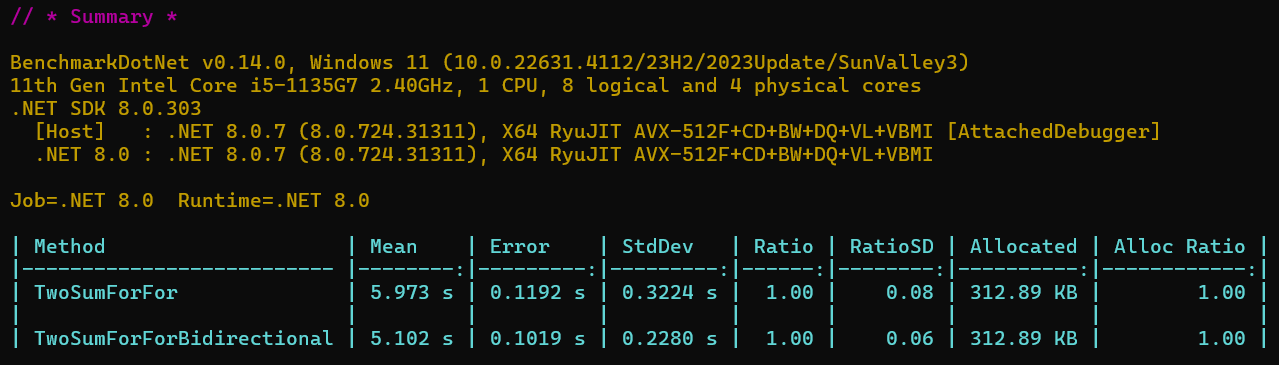
从基准测试的结果来看,整体上并没有提升多少性能。这是因为这个算法本质上时间复杂度还是:O(N2),因此并没有真正起到优化的作用,只有特定的数据分别可能才会有相对较好的表现,这个算法就当作给我们提供了一种解题思路吧。
解法三:单层循环+LastIndexOf
既然左右开弓不行,我们换一个思路,想办法去掉一层循环。
首先外层循环需要保留,因为需要把每个元素都计算一遍,因此我们从内层循环下手。想想题目,是要找到两个数使其和为目标值,那么我们是否可以在循环第一个数时候,通过目标值计算出我们要找的第二个值,看看这个值是否存在,如果存在,则完成算法,否则继续循环直到找到为止。按照这个思路我立马想到C#里的IndexOf和LastIndexOf方法,直接上代码:
public static int[] TwoSumForLastIndexOf(int[] nums, int target){for (var i = 0; i < nums.Length; i++){var j = Array.LastIndexOf(nums, target - nums[i], nums.Length - 1, nums.Length - 1 - i);if (j >= 0 && j != i){return [i, j];}}return [];}
运行结果如下:
注:Array.LastIndexOf<T>(T[] array, T value, int startIndex, int count)方法可以指定从什么地方开始查找,查找多少个数。
同样我们再做一次基准测试做对比。
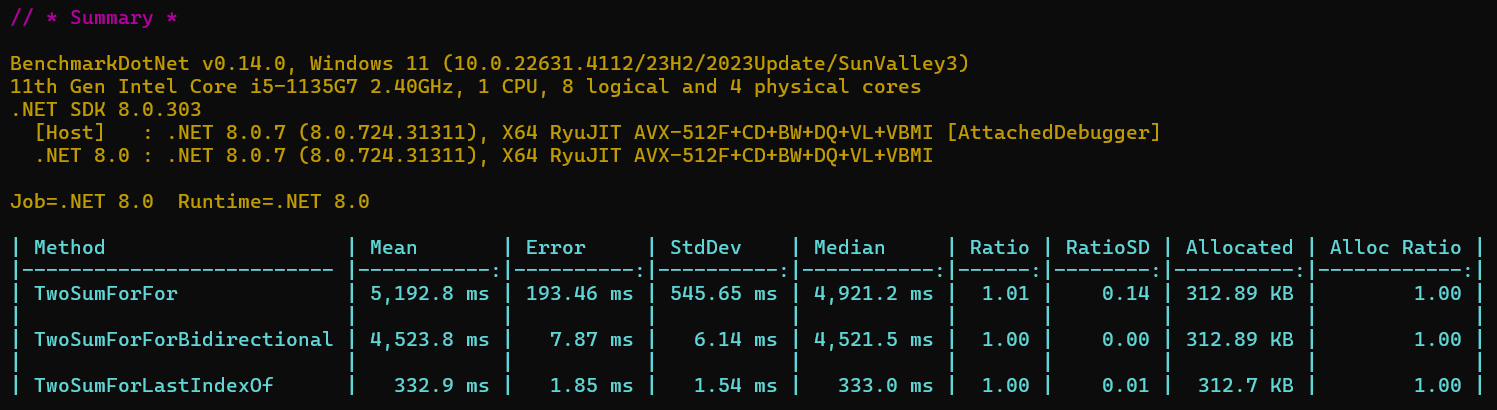
可以发现这一版本算法性能大幅提升,但是我们细想一下,LastIndexOf方法本质还是在数组中找一个元素,最坏的情况还是要把整个数组遍历一遍,只能说C#本身做了很好的优化使其性能很高,但是从算法时间复杂度的角度来看,其仍然是 O(N) 的,也就是说这一版本算法时间复杂度还是O(N2)。
解法四:单层循环+字典(哈希)
哪到底如何才能把O(N)的集合查找时间复杂度优化了呢?如果能改造到O(1) 就好了,顺着这个思路还真想到了一种数据结构-哈希表,可以做到O(1) 的查找时间复杂度。
在C#中可以使用Dictionary字典类型,数据结构选好了,下面就是怎么用的问题,key存什么?value存什么?
再次回忆一下题目要求,是找到两个数使其和为目标值,假设x+y=target,x为第一个数,并且外层循环第一个数,那么当处理数据x时,同时能得到y=target-x,如果数组中后面存在值为y的元素,是不是就意味着这对[x,y]就是我们要找的值,因此我们可以在处理x时,把y=target-x和x所在索引记录下来,正好分别对应Dictionary的key和value。代码如下:
public static int[] TwoSumDictionary(int[] nums, int target){var dic = new Dictionary<int, int>();for (var i = 0; i < nums.Length; i++){if (dic.TryGetValue(nums[i], out var value)){return [value, i];}dic.TryAdd(target - nums[i], i);}return [];}
执行结果如下
运行正确,我们再来用基准测试对比一下。
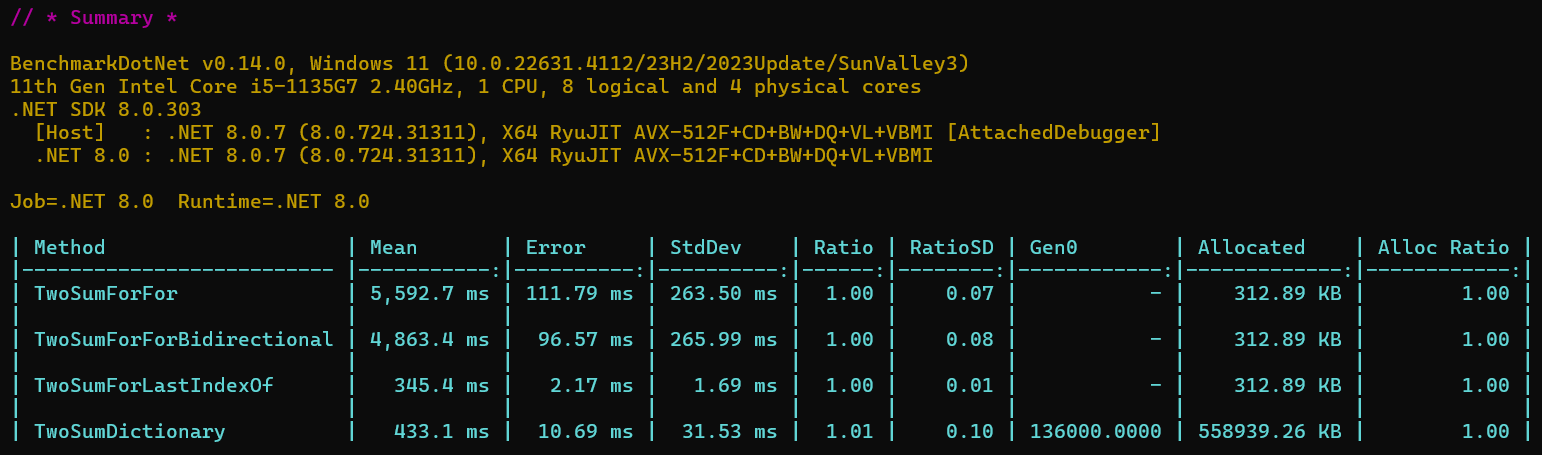
结果和我们预想竟然不一样,还没有LastIndexOf方法效果好,哪里出了问题呢?
下面我们对这两种方法单独做一次全方面的基准测试对比,对每个方法分别用数组长度为100,1000,10000三种情况,各进行10000次测试。结果如下:
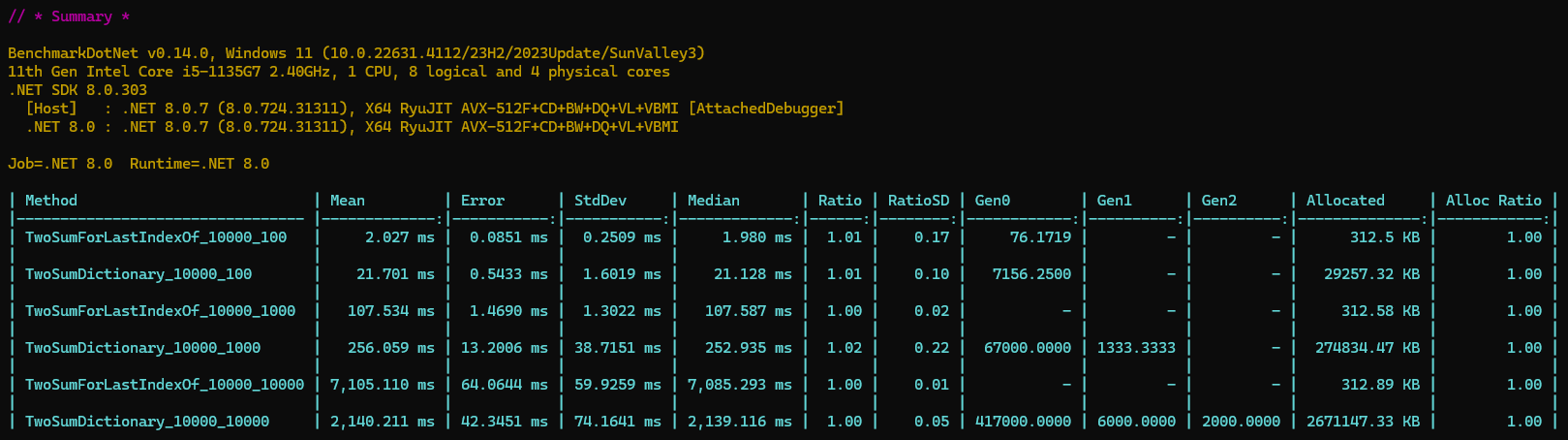
可以发现,只有当数组长度越来越大的时候,哈希表方案优势才慢慢体现出来。
我们再来分析一下这个算法复杂度,首先外层循环时间复杂度为O(N) ,字典操作时间复杂度为O(1),因此整体时间复杂度为O(N) 。因为字典需要额外的存储空间并且最大长度为数组长度减1,因此空间就复杂度为O(N) 。这是经典的以空间换时间方案。
从上面的对比不难发现,即使再好的方案也有其使用场景,数据量的大小,空间的大小都会制约着算法方案的选择,因此需要我们因时制宜选出最合适的方案。
没有最好只有最合适。
注:测试方法代码以及示例源码都已经上传至代码库,有兴趣的可以看看。https://gitee.com/hugogoos/Planner