一、常见网络攻击1.1 网络攻击概述 1.2 网络攻击方式 1.3 网络攻击检测 二、安全运营SOP2.1 攻击告警初判 2.2 攻击地址封禁 2.3 攻击告警研判 2.4 应急响应处置 2.5 附SOP流程图 三、网络攻击防范3.1 减少对外暴露面 3.2 系统上线前提测 3.3 供应商安全管理3.4 正确使用安全产品 3.5 开设对外收洞渠道3.6 漏洞情报及预警响应
原创 我的安全视界观
在开篇《安全事件运营SOP【1】安全事件概述》中,介绍了安全事件的定义、分级、处置原则及处置流程。
当发生某类安全事件时,该如何快速处置❓
以及如何保证不同人员处置的效果都达标❓
安全事件的种类虽然繁多,但是处理起来并非无据可循。为了解决上述两个问题,同时提升工作效率和降低安全风险。
经过大量的运营处置实践,总结出以下常见的处置标准操作程序(SOP)。
本文将从攻击、检测处置和防范三个维度,分别对应介绍网络攻击方式、事件运营SOP及防范措施。
由于作者所处平台及个人视野有限,总结出的SOP虽然经过大量重复的操作、总结及提炼,但仍会存在错误或不足,请读者同行们不吝赐教,这也是分享该系列实践的初衷。

一、常见网络攻击
1.1 网络攻击概述
互联网上每天都充斥着各种网络安全攻击,如漏洞扫描、已知漏洞利用、DDoS攻击、CC攻击、网络爬虫等。本文介绍的网络攻击SOP主要指边界突破阶段,针对应用系统使用到的一些攻击手法,比如web渗透、供应链攻击等。
1.2 网络攻击方式
就web渗透而言,实际涉及到的漏洞,范围远不止字面意思上的应用系统层面。
因为应用系统不可能单凭自身就可以运行,渗透又是一系列的操作,至少还包括:
【敏感信息探测】:从外部视角看对攻击有用的信息,如端口开放扫描、源码备份文件扫描、应用服务框架识别、Swagger存在敏感信息泄露;
【已知漏洞攻击】:通常是使用漏洞扫描器(单一漏洞/综合漏洞)对目标系统进行扫描,根据漏洞检测规则发现已知漏洞,并进行利用导致系统被攻击。漏洞如果按照不同层面可分为基础层的系统及服务配置类漏洞,如基础环境的已知可利用漏洞、未授权类漏洞、弱账密类漏洞;应用层面的(即开发编写代码带来的安全问题),如SQL注入、Java反序列化命令执行、文件上传等漏洞;基于业务场景的漏洞发现和利用,如已注册用户枚举、任意账号密码重置、短信/邮件炸弹、短信/邮件纵向炸弹等。
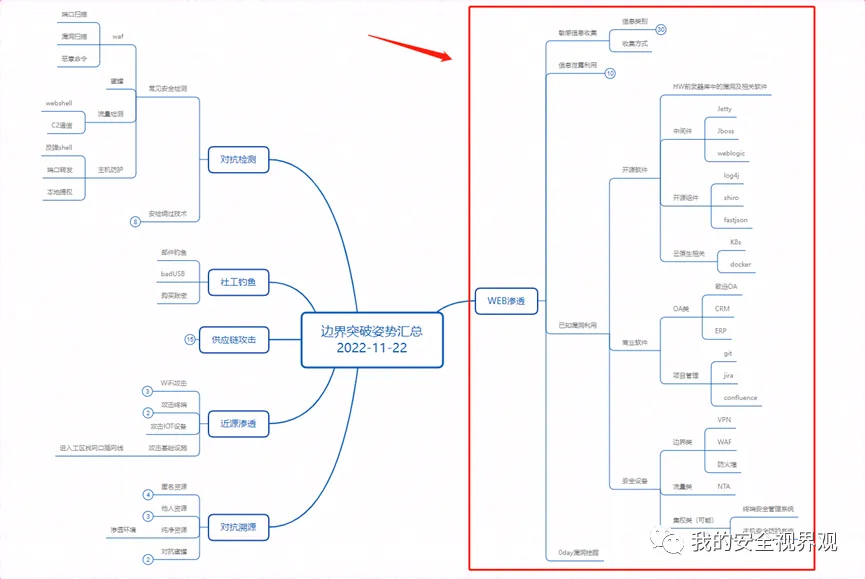
在攻击技术日新月异的今天,供应链攻击一跃成为最热门的方式,包括对人员账号、软件和硬件的攻击。此处主要想提及对软件的投毒,由于软件产品基本都是开源组件+自研代码的组装,部分语言的存储仓库、社区管理不严格及GitHub自由开放等特性,攻击者可能上传恶意包并诱导他人进行下载。
从安全运营的角度看,最常见的就是:
【非法外连攻击】:开发使用的开源组件被投毒,应用所在服务器被远控涉及到的metasploit行为、CobaltStrike行为等。
1.3 网络攻击检测
在攻击检测方面,除了传统的基于特征、异常、误用,机器学习和威胁情报等也得到了广泛应用。
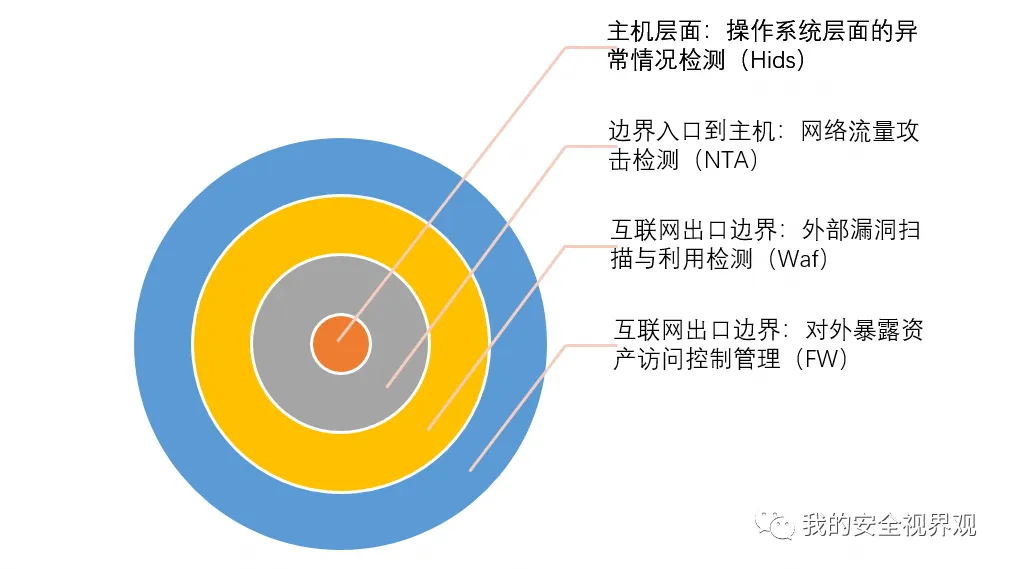
在企业的安全建设中不可或缺以上检测能力,通常体现在以下四类安全产品(每一类,列举一种产品加以说明):
FW:对应用上外网权限、对外暴露权限实现管控;
Waf:对应用层的漏洞探测、利用进行检测及阻断;
NTA:对网络流量进行安全分析,引入威胁情报提升已知攻击检测能力;
HIDS:对主机层面如登录、进程异常等进行安全检测,往往作为最后一道防线。
二、安全运营SOP
网络攻击安全事件的处置,需要从攻击行为、攻击来源、攻击成功与否的状态等多个方面进行考量,不同情况的组合采取的措施略有差异。
比如在排出非公司资产的情况下,攻击源来自外网且发起大量扫描,则需在FW墙上进行封禁,再判断是否攻击成功;若攻击源是内网(已经被突破边界,如供应链投毒的场景),则应该进行网络、账号等权限的下线,并立即对源地址进行应急响应。
简而言之,在面对网络攻击事件时,有如下处置步骤:
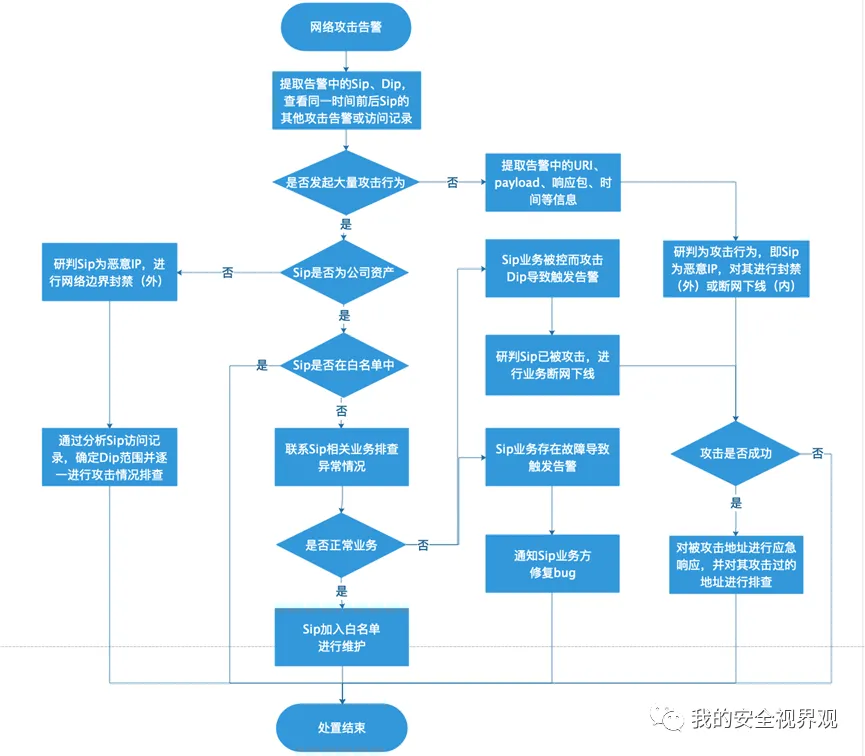
2.1 攻击告警初判
从告警信息中提取攻击时间、源IP(Sip)、目的IP(Dip)、协议等基础信息,以时间为维度查看告警前后一段时间内,Sip对哪些地址做过攻击或扫描,以及攻击是否成功。
2.2 攻击地址封禁
若Sip对一个或多个Dip发起大量攻击(例如扫描),则需进行封禁处置。但在封禁之前,需要判断Sip是否为公司资产、是否在白名单中、是否为正常业务。若不是公司的资产,则在公网边界进行封禁并对Dip进行排查;若属于公司资产且在白名单中,则应检查是否为安全检测规则、安全运营策略等导致的误报。若属于公司资产但不在白名单中,则需联系业务或终端Owner确定是否正常行为,若是正常或本人行为,则对业务进行加白或对相关owner进行通报(尤其是在安全公司中,渗透测试需要授权,未授权的行为属于违规事件);若是非业务或本人行为,则需立即开展业务故障排查、断网下线、溯源分析等应急响应动作。
2.3 攻击告警研判
若Sip没有发起大量攻击,也需要对安全事件进行分析。从告警中提取URI、payload、查看响应包状态等,甚至从日志、流量中提取更多上下文信息辅助分析攻击成功状态。
2.4 应急响应处置
若是攻击成功,则应立即断网下线,同时分别以Sip和Dip为基点,对整个攻击链进行溯源分析、后门清除等应急响应动作。
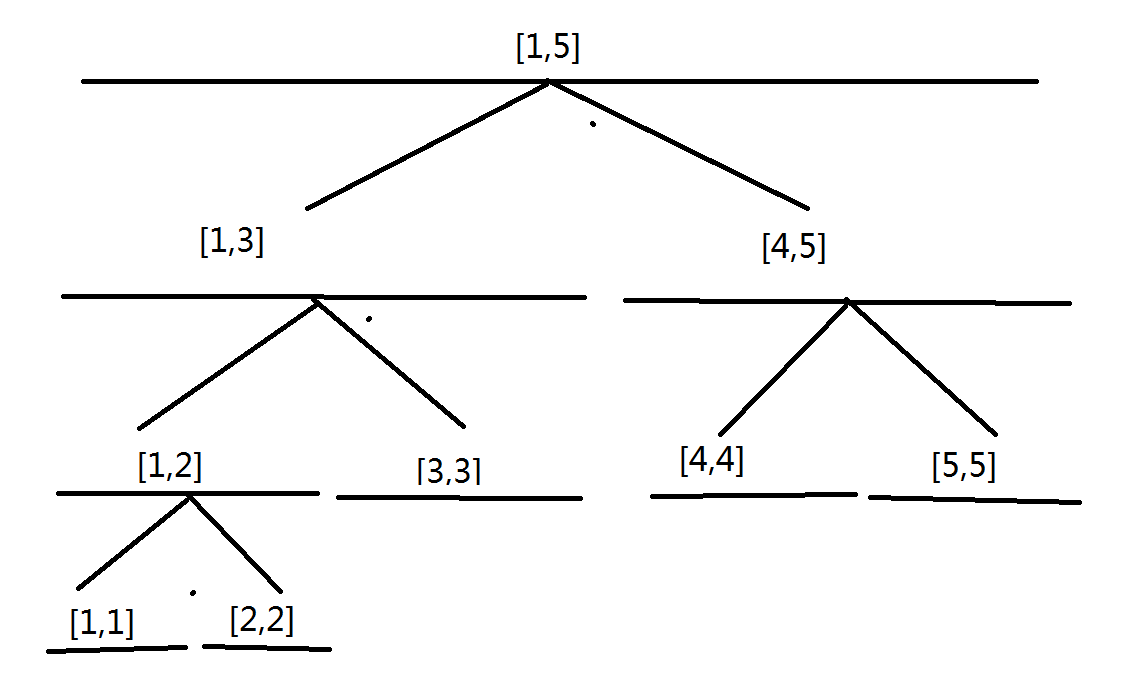
2.5 附SOP流程图
2.1 – 2.4的处置流程,如下图所示:
三、网络攻击防范
防范网络攻击是一门安全管理与技术融合应用的学科,涉猎范围较广,实现方法也有很多。
但从ROI或仅从效果的角度来考虑,以下六种的较为有效&高效:
3.1 减少对外暴露面
暴露面指从互联网就能访问到的系统或使用的系统服务,具化为域名、IP、端口、API等网络资产,减少它们对外的暴露情况降低被攻击的可能性。
管住公网出口:所有的内网地址均用NAT转化,统一形成几个出口对外暴露,通过使用负载均衡或防火墙进行收口管控。互联网侧资产监控:在外网部署资产扫描的节点,对公司所有的网段、域名和多级子域名进行全端口扫描及服务识别,7*24h的进行资产监控。关于网段和域名的收集,实际的业务场景中除了传统IDC,可能还有国内/外不同云厂商的地址,在最初的扫描前应该确定网段和域名范围。互联网侧高危端口监控:高危端口包括21、22、23、873、1080、1433、1521、3306、6379、7001等端口,其对应的服务可能存在弱口令、未授权、已知高危漏洞等风险,常常被攻击者所关注。需要注意的是服务的端口号是可以修改的,在一些企业中懂技术的人员通常会将远程连接的端口如22做映射为2200,以逃过信息安全部的限制或检测。互联网侧高危API监控:敏感信息泄露、管理后台、密码找回、短信发送等接口,可能会存在安全问题,也常是攻击者喜欢寻找的点位。通过对应用日志进行关键字搜索,比如管理后台可能的url为/admin、/manage、/login等。
3.2 系统上线前提测
在系统上线发布前,嵌入安全活动如:白盒测试、黑盒测试和渗透测试,对系统进行安全自检,推进暴露出的安全漏洞或隐患修复。其中比较关键的是安全卡点,通常没有业务方会花时间来进行安全测试,只有在发布流程中嵌入检查点才会有效:
内网发布系统:申请内网域名前,检查是否进行安全提测及是否通过;
外网发布系统:申请外网域名映射前,检查是否进行安全提测及是否通过;
已经发布系统:收集线上业务应用日志,对API资产进行监控。若出现API异常新增,就触发web漏洞漏洞扫描器进行扫描。
3.3 供应商安全管理
供应链攻击的主要战场是其产品,对于安全水位高的企业而言,供应商的系统可能就是安全短板。如:服务部署在本地,中控服务在供应商侧,由于供应商中控服务失陷而导致被攻;服务部署在本地,与供应商系统无关联,仍旧会由于供应商被攻击而导致被攻击…
对于供应商产品的安全管理,业内其实已经有很多实践,如检查其产品的安全性报告(安全测试/代码审计/渗透测试)、要求其提供对外端口通信矩阵、提供系统框架及开源组件、系统上线前进行安全提测、签署应急响应协议保障其在运营阶段提供应急服务…这些都是有效的措施,但有时还是难以避免被攻击。目前做的比较好的应该是华为,对供应商进行赋能,并考量供应商自身的网络安全建设情况及产品研发流程的安全。
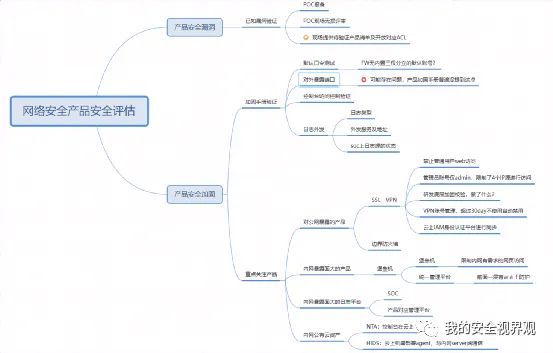
3.4 正确使用安全产品
想必每个企业都应该在用网络安全产品,但是否会用或用得好,估计得打个问号。从乙方中的甲方安全从业人员来看,常态化的使用安全产品、跟进告警并进行分析才是最好的打开方式,另外也别让安全产品带来额外的攻击面(尤其是边界类)。
【基于白盒产品安全能力验证】:保证产品发挥效果的最佳实践方法。以安全告警及有效性运营为例,设计出关心/常用的安全功能并准备场景进行测试。
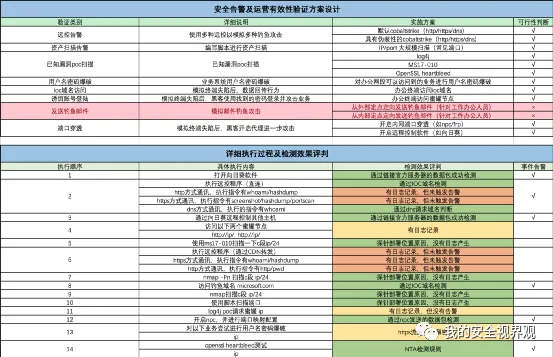
【产品自身安全加固能力验证】:保障产品不被攻击的最佳实践方法。关注安全产品的历史漏洞修复情况、安全加固情况及重点产品(集控类&边界类)加强防护措施落地情况。
3.5 开设对外收洞渠道
SRC作为企业安全团队对外宣传、接收漏洞的官方渠道,既起到沟通桥梁的作用,又可以通过接收到的漏洞反向优化安全防护策略。建设SRC早的企业,各类规则完善、人气高,基本拥有一群稳定的白帽子为其挖洞,白帽子也对业务越来越熟悉,也能发现更多有质量的安全漏洞。对于新建的SRC,则需要通过不断的运营活动来提升行业影响力,吸引更多的白帽子加入。
【 SRC建立】:包括门户建立、漏洞接收范围确定、奖励机制确定等。
一是门户的建立,作为一个对外的门户,可以自研也可以通过国内的一些漏洞平台建立企业SRC,漏洞平台的好处是有一定的白帽子基础、运营机制,相比较自研会更加高效快速上线,但也存在定制化功能和效果不佳的弊端。若是自研,可借助开源的程序进行修改,比如SRCMS、腾讯xSRC(开源版)。值得注意的是,如果使用开源方案,则需要持续关注平台本身的漏洞情况,目前已经被发现不少安全漏洞。
二是确定漏洞接收范围,仅限于主域名的子域名,还是包括所有与公司相关的资产漏洞?SRC经常会接收到内部已知管理资产外的资产漏洞,白帽子的能力不容小觑,为避免发生争执需要提前明确。
三是设置有明显区别的漏洞奖励机制,可根据资产重要性、漏洞利用直接造成的影响、漏洞利用条件等进行评判。比如核心系统可利用前台SQL注入漏洞的评级,应该比核心系统管理员之后可利用的SQL注入和一般系统前台可利用SQL注入高,对应的奖励机制也会更高。对于奖励机制,直接进行RMB奖励会更吸引白帽子的参与度。
【SRC活动】:漏洞接收数量直接取决于参与白帽子的数量,衍生开可能涉及到平台影响力、奖励机制等因素。白帽子拉新、白帽子促活、每逢佳节奖金翻倍、月/季/年度额外奖励…需要有规划、有吸引力的发起线上或线下活动,保持和白帽子的联系。
【其他事项】:把跟白帽子的关系处理当做一项正式运营工作,给予白帽子感谢与尊重;注重在安全圈内的品牌,加入生态圈,与其他SRC一起活动,能吸引更多白帽子;制定内部漏洞审核和修复效率,别让线上漏洞暴露太久,也别让白帽子等待太久。
3.6 漏洞情报及预警响应
与攻击者比速度,在被已知/较新漏洞攻击前,自行先完成发现、修复或防护工作。
主要涉及两部分工作:
一、预警监测输出高危漏洞POC:通过从安全媒介、软件官网、国内外漏洞平台、社交软件等途径,实时获取漏洞情报信息、漏洞利用信息等,尤其应该关注重大保障活动前的“漏洞弹药”,并编写对应的POC在内/外部发起扫描。
二、联动资产优先发现互联网资产:无论是漏洞的发现,亦或是漏洞的修复,均需要明确存在漏洞的资产归属情况。基于资产(操作系统/应用/组件)进行漏洞扫描,可以提升扫描效率、降低网络流量;基于资产(重要级别/网络位置)进行漏洞修复判断,可以提高互联网侧的漏洞修复速率;基于资产(使用人/运维负责人/安全负责人)进行漏洞修复推动,可以提高整体的漏洞修复率。