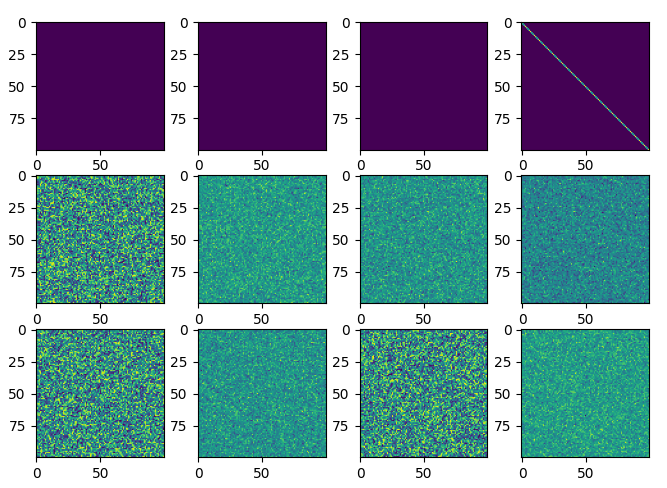
深度学习训练的时候,一个好的初始化结果能使模型更容易收敛,Pytorch提供了一些初始化函数。
import torch import torch.nn as nn import matplotlib.pyplot as pltclass Model(nn.Module):def __init__(self):super(Model, self).__init__()self.a = nn.Parameter(torch.zeros(100,100)) def forward(self, x):return self.a + xnet = Model() par_list=[] for par in net.parameters():par_list.append(par.detach().clone().numpy())nn.init.ones_(par) par_list.append(par.detach().clone().numpy())nn.init.constant_(par,10)par_list.append(par.detach().clone().numpy())nn.init.eye_(par)par_list.append(par.detach().clone().numpy())nn.init.uniform_(par, a=0, b=1)par_list.append(par.detach().clone().numpy())nn.init.normal_(par,mean=0, std=1)par_list.append(par.detach().clone().numpy())nn.init.orthogonal_(par, gain=1)par_list.append(par.detach().clone().numpy())nn.init.sparse_(par, sparsity=0.1, std=0.01)par_list.append(par.detach().clone().numpy())nn.init.xavier_uniform_(par, gain=1)par_list.append(par.detach().clone().numpy())nn.init.xavier_normal_(par, gain=1)par_list.append(par.detach().clone().numpy())nn.init.kaiming_uniform_(par)par_list.append(par.detach().clone().numpy())nn.init.kaiming_normal_(par)par_list.append(par.detach().clone().numpy())for i,par in enumerate(par_list):plt.subplot(3,4,i+1)plt.imshow(par)plt.show()
结果可视化如下: