只有理解了,才能在超越经验的情况下,生成出合理的内容
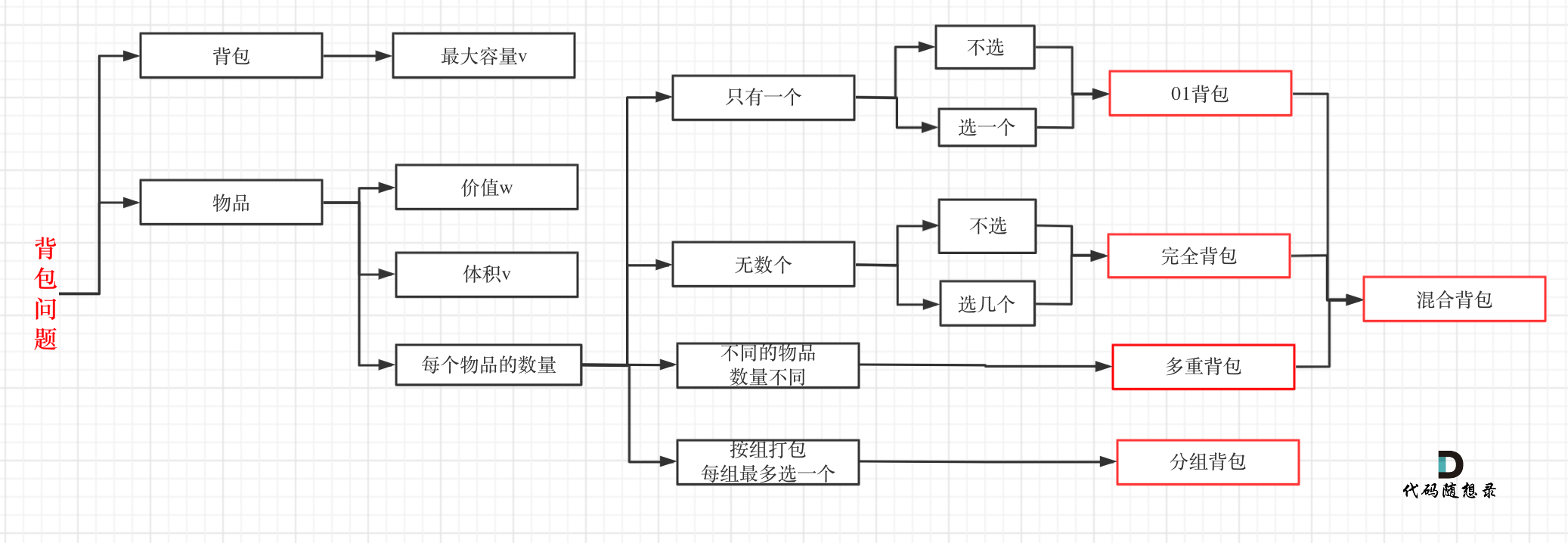
编解码

encoder-decoder结构
- 什么是“码”?
剥离形式的表示(各种语言的不同),剩下的语义关系(上下文语义)
- “码”的要求:1、数字化 2、语义关系的距离
分词器和one-hot编码在2不足
需要找到一个纬度高,但是又没那么高的空间(潜空间),去协助完成编解码的工作
思路:对one-hot编码进行降维
- 矩阵和空间变换

- word2vec(解决单个词,单个token语义的问题)
训练出体现语义的嵌入矩阵

W将one-hot编码投射到潜空间,W' 将潜空间中的词向量还原成one-hot码
attention机制
word2vec解决了单个词,单个token语义的问题。注意力机制要解决的是许多词组合在一起后,整体体现出来的语义

“美女”在不同情况下:(1)美女,加个微信吧。 (2)美女,麻烦让一下。
注意力机制需要解决的就是要识别出因为上下文关联而对词典(word2vec)中原本客观的语义进行调整和改变的幅度。
看A'V
- V表示从词典中查出来的token的客观语义
- A'表示因为上下文关联而产生的修改系数
为什么A'就能表示因为上下文关联而产生的修改系数?

Q和K相乘得到的A是输入的这一组词向量自己和自己之间的相互关系
A'(经过softmax归一后)和V相乘是用这个相互关系来修正V的词向量
为什么要有Q和K两个矩阵?为什么不能用一个矩阵训练?
二次型

“概率论难”的评论——评论者的语义理解和视频制作者的设定语义出现差别
理解:让q和k能够承担设定语义(为下文做铺垫的语义)和表达语义(基于上文的语义表达)两部分的功能
解码器如何解决seq2seq问题?
对于翻译问题,如何实现中文编码后解码出来的英语单词向量维度不同的问题
方法:生成(解码)的时候,一个一个地生成(利用RNN的思路)

postional encoding
postional encoding的作用?
保证输入的一组词向量在并行计算的同时还能保证他们的先后顺序
使用了绝对位置编码(针对数据进行修饰,直接让数据携带了位置信息)


Multi-Head Self-Attention


多头注意力能够识别出跨语段的语义,而不仅仅局限于周围
Appendix
- 从概率角度理解除以根号dk
把数据根据他们的相对关系进行归一

- (self)attention、transformer其他版本
1.1 注意力机制
一维情况:

二维情况:

以点积模型为例



1.2 自注意力机制
Q、K、V都为X时

1.3 Transformer模型
先对X做不同的线性变换(三个W矩阵)再 输入

- 相对位置编码
绝对位置编码直接让数据携带信息,而相对位置编码让注意力得分A矩阵增加位置信息

- Auto Encoder(自编码器)
“自”的意思:自己训练自己

能够把输入进行过滤,进行特征提取,通过重建图像和原始图像的损失进行训练

- Variational Auto Encoder(变分自编码器)
Auto:不再把输入映射到固定的变量上,而是映射到一个分布上(比如混合高斯GMM)


KL散度,描述学习的分布和高斯分布之间的相似性
“将一个字符串拆散了再重组”
attention机制
核心思想:通过加权求和解决context的理解,本质上就是在不同的上下文下专注不同的信息。
- RNN结构

- encoder-decoder模型
两个RNN组合,形成encoder-decoder模型
先对一句话编码,再解码,从而实现机器翻译

缺陷:但是统一压缩成相同长度的编码c的做法,会导致翻译精度下降
- attention
通过每个时间,输入不同的c解决encoder-decoder问题


通过attention的引入,打破了只能利用encoder形成单一向量的限制。attention让每一时刻,模型都能动态地看到全局信息。
缺陷:依然还存在RNN的时序依赖
- self-attention
既然模型本身已经对全部输入进行了打分,所以去除RNN中的时序依赖

encoder编码阶段,利用attention机制计算每个单词与其他所有单词之间的关联

加入前馈神经网络

decoder不仅看之前产生的输出,也要看encoder产生的输出

transformer
1、基础知识
1、总体架构图
依靠self-attention

attention(Q, K, V):
Q来自于前一个解码器层,K、V来自于编码器的输出

编码器处理输入向量,将输出转化为attention向量K和V,
解码器解码阶段,即考虑K、V,又考虑与其他向量的关系
2、左侧

- 使用算法将单词向量化
- 嵌入位置信息,变成统一长度(底下绿色的向量)
- encoder将绿色作为输入,通过前馈网络发送到下一个编码器

self-attention计算公式:

效果:和X相比,Z中掺入了上下文信息

- 线性层和softmax层将输出向量转化为单词

参考:
[1] https://www.bilibili.com/video/BV1XH4y1T76e/?spm_id_from=333.1007.top_right_bar_window_history.content.click&vd_source=0bc656b59467691987b3a096498b7112 " 编解码、词嵌入"
[2] https://www.bilibili.com/video/BV1dt4y1J7ov/ " 注意力QKV矩阵运算"
个人想法
中译英翻译模型
Transformer训练翻译模型时候(比如中译英),训练过程是先将中文的通过Transformer架构中的编码器部分进行编码,将各个token映射到潜在向量空间,与此同时将平行英文译文在Transformer架构中的编码器部分(实际上也包含了编码器部分)先进行编码,然后将二者的token同时送入多头注意力机制模块部分进行训练,通过反向传播调整来使Transformer架构中的编码器部分的参数矩阵和Transformer架构中的编码器部分的前半部分(也实际上是编码器)的参数矩阵的系数改变,使得前者对中文编码后和后者对英文编码后得到的潜在向量空间相一致。这样训练出来的模型使用编码器对要翻译的整个中文语段进行编码,然后英文根据已经生成的译文进行编码,通过计算差异,推测出英文接下来要生成什么词添加到译文中,可以使得在相同的潜在向量空间中的中文语段向量和已经生成的译文的英文语段向量更接近,从而实现自回归生成英文译文,并且保持了语义的高度一致。
- 编码器和解码器的作用:在Transformer模型中,编码器负责处理输入序列(在这个例子中是中文句子),而解码器负责生成输出序列(英文句子)。编码器将输入序列的每个token转换为一系列的潜在向量,这些向量捕捉了token的语义信息以及它们之间的关系。
- 多头注意力机制:编码器和解码器都使用了多头注意力机制,这使得模型能够在处理序列时考虑到不同位置的信息。在解码器中,还有一个特殊的注意力机制,称为“编码器-解码器注意力”(也就是交叉注意力),它允许解码器注意输入序列(中文句子)的相关部分,以便更好地生成输出序列(英文句子)。
- 训练过程:在训练过程中,模型会接收到中文句子和对应的英文翻译。中文句子首先通过编码器进行编码,而英文翻译则同时通过编码器和解码器进行处理。模型的目标是最大化正确翻译的概率,这是通过最小化预测英文单词与实际英文单词之间的损失函数(如交叉熵损失)来实现的。
- 反向传播和参数更新:通过反向传播算法,模型根据损失函数的梯度来更新其参数(包括编码器和解码器中的权重矩阵)。这个过程会不断重复,直到模型收敛到一个最小化损失的点。
- 自回归生成:在推理阶段(即模型部署使用时),模型会逐个生成英文单词。解码器会根据已经生成的英文单词和编码器的输出来预测下一个单词,这个过程是自回归的,因为每个新生成的单词都会影响到后续单词的生成。
- 潜在向量空间的一致性:训练的目标是使得模型能够学习到一个一致的潜在向量空间,在这个空间中,语义上相似的中文和英文句子被映射到相近的向量。这样,模型就能够基于中文句子的编码来推测出合适的英文翻译。
自动补全模型
编码器
在自动补全模型中,编码器的任务是将用户输入的前缀转换成一个高维的潜在表示。这个潜在表示捕捉了前缀的语义信息,使得模型能够理解输入的上下文。编码器通过自注意力机制处理输入序列,这样每个位置的输出都能够考虑到整个输入序列的信息。
解码器
解码器负责生成补全选项。在训练阶段,解码器接收编码器的输出作为上下文信息,并使用自回归的方式生成一系列可能的补全选项。解码器同样使用自注意力机制来关注输入序列的不同部分,并且使用编码器-解码器注意力来确保生成的序列与输入序列的相关部分保持一致。
训练数据
在训练自动补全模型时,我们需要一个包含输入前缀和对应补全选项的数据集。每个训练样本通常包含一个输入前缀和一个或多个正确的补全选项。
- 编码输入前缀:将输入前缀通过编码器进行编码,得到一个或多个潜在向量,这些向量代表了输入前缀的语义信息。
- 初始化解码器状态:解码器的初始状态通常设置为编码器输出的最后一个隐藏状态,这样解码器就能够利用整个输入前缀的信息。
- 生成补全选项:解码器开始生成补全选项。在每个时间步,解码器会根据之前的输出和编码器的上下文信息来预测下一个单词或字符。
- 计算损失:对于每个生成的补全选项,计算其与实际补全选项之间的损失。这个损失通常是交叉熵损失,它衡量模型预测的概率分布与实际标签的匹配程度。
- 反向传播和参数更新:根据计算出的损失,使用反向传播算法来更新模型的参数,以减少损失并提高模型的预测准确性。
- 迭代训练:重复上述步骤,直到模型在训练数据上的表现达到满意的水平。
预测过程
在模型训练完成后,当用户输入一个前缀时,模型会使用相同的编码器和解码器结构来生成补全选项。解码器会根据输入前缀的编码和已经生成的单词来预测下一个最可能的单词或字符。
编码器:他是谁
Transformer:整个场景表达了怎样的语义,(他是否满足这个语义,他在这个语义场景中扮演什么)
long long ago, .....





![[图文直播]基于ZFile和MinIO搭建私有网盘](https://img2023.cnblogs.com/blog/3485711/202409/3485711-20240901163234831-2006360717.png)