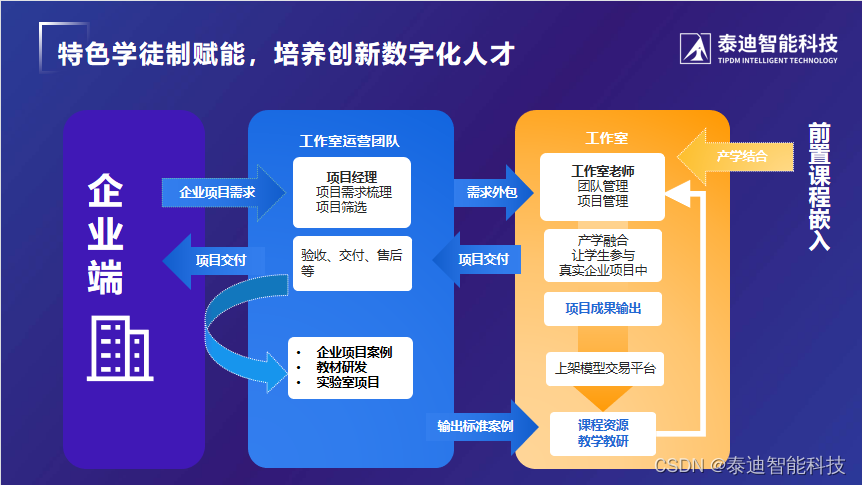
一文带领你好好认识一下企业级别的缓存技术解决方案的运作原理和开发实战(数据更新场景策略和方案分析)
- 数据更新场景
- Cache Aside Pattern
- 策略思想
- 具体操作分析
- 失效(Invalidation)
- 命中(Cache Hit)
- 更新(Update)
- 两个待分析的问题
- Cache Aside Pattern为什么不是更新缓存,而是失效(删除)缓存?
- 失效数据方案
- Cache Aside Pattern在数据更新的时候是采用先更新数据库,再失效缓存
- 先更新缓存再更新数据库
- 优化数据懒加载
- 以下是改进的建议
- 失效缓存和更新数据库的顺序问题
- 先失效缓存再更新数据库
- 解决方案
- 采用延时双删
- 异步删除处理机制
- Write/Read Through 缓存透写/透读
- 在写透写/读透读模式下
- 读写模式的有点机制
- Write Behind Cache Pattern 后写缓存模式
- 注意要点
- 总结分析
- 彩蛋案例
数据更新场景
在引入缓存后,数据会同时存放在缓存和数据库两个地方。因此,当需要更新数据时,需要确保这两个地方都能够得到更新,并且不同的更新时序可能会产生不同的结果。在业界,已经形成了多种解决数据更新问题的模式,例如Cache Aside Pattern和Read/Write Through等。
Cache Aside Pattern
Cache-Aside Pattern(缓存旁路模式) 是一种常用的缓存更新策略,可以提高系统的性能和可靠性。以下是Cache-Aside Pattern的主要流程:

-
读取数据:当应用程序需要获取数据时,首先会检查缓存中是否已经存在所需数据。如果数据存在于缓存中,则应用程序直接从缓存中读取数据,无需访问底层数据存储系统。
-
缓存未命中:如果数据不存在于缓存中,即缓存未命中,应用程序会查询底层数据存储系统来获取数据,并将数据存储到缓存中以备后续读取。
-
更新数据:当应用程序需要更新数据时,它首先会更新底层数据存储系统中的数据。然后,应用程序会使缓存失效,即从缓存中删除相应的数据。
-
下次读取:在下次读取该数据时,应用程序会重新执行步骤1和步骤2,将更新后的数据加载到缓存中。
策略思想
Cache-Aside Pattern的关键思想是将读操作和写操作分开处理,这种策略在数据读取频繁、数据更新相对较少的场景中非常适用。
- 读操作优先从缓存中获取数据,减少对底层数据存储系统的访问,从而提高系统的性能。
- 写操作会更新底层数据存储系统,并使缓存失效,以保持数据的一致性。
具体操作分析
失效(Invalidation)
- 当应用程序需要获取数据时,首先会尝试从缓存中查找数据。
- 如果缓存中不存在该数据(即缓存失效),应用程序会从数据库中读取数据。
- 读取成功后,应用程序会将数据放入缓存,以便后续访问。
命中(Cache Hit)
- 当应用程序需要获取数据时,首先会尝试从缓存中查找数据。
- 如果缓存中存在该数据(即缓存命中),应用程序会直接从缓存中返回数据,避免了对数据库的访问。
更新(Update)
- 当数据需要更新时,首先将更新操作应用到数据库中。
- 如果更新成功,再将缓存中对应的数据失效(即从缓存中删除),以便下次访问时能够重新从数据库中读取最新的数据。
通过使用缓存旁路模式,可以有效地提高系统的性能和响应速度。缓存可以减少对数据库的访问次数,从而减轻数据库的负载,并且在缓存命中时可以快速返回数据,减少网络延迟。同时,通过合理管理缓存的失效和更新,可以保证缓存中的数据与数据库中的数据保持一致性。
注意,在使用Cache-Aside Pattern时,应用程序需要考虑缓存和底层数据存储系统之间的一致性问题,以及缓存失效带来的性能损失。可以使用一些技术手段来解决这些问题,例如基于时间的缓存失效策略、使用缓存锁定来处理多个请求同时更新缓存等。
两个待分析的问题
- Cache Aside Pattern为什么不是更新缓存,而是失效(删除)缓存?
- Cache Aside Pattern在数据更新的时候是采用先更新数据库,再失效缓存。
Cache Aside Pattern为什么不是更新缓存,而是失效(删除)缓存?

如上图所示,假设A、B两个线程,A先更新数据库后 B再更新数据库,然后分别进行更新缓存,但是B先更新缓存成功,A后更新缓存成功,这样就导致数据库是最新的数据但是缓存中是旧的脏数据。而如果失效缓存数据的话,可以保证下一次读请求回源到数据库将最新的数据载入到缓存中,避免脏数据的问题。因此,针对数据更新缓存采用失效的方式进行处理
失效数据方案
根据上述情况,可以采取以下步骤来解决数据更新缓存的问题:
-
在A线程更新数据库后,立即使B线程的缓存数据失效。可以通过设置一个标志位或者发送一个通知来实现。
-
在B线程更新数据库之前,检查缓存数据是否已经失效。如果缓存数据已经失效,则直接更新数据库并更新缓存。
-
如果缓存数据未失效,B线程需要等待一段时间,等待A线程的缓存更新完成。可以使用一些同步机制,如锁或信号量来实现。
-
在等待一段时间后,B线程再次检查缓存数据是否已经失效。如果缓存数据已经失效,则直接更新数据库并更新缓存。
通过以上步骤,可以确保在数据更新时,先使缓存数据失效,然后再更新数据库和缓存,从而避免脏数据的问题。这样下一次读请求将会从数据库中获取最新的数据,并将其载入到缓存中。
Cache Aside Pattern在数据更新的时候是采用先更新数据库,再失效缓存
双写不同数据源很容易导致数据不一致的问题。
当A线程先更新数据库,然后B线程再更新数据库,接着分别更新缓存时,如果B线程先更新缓存成功,而A线程后更新缓存成功,那么数据库中的数据就是最新的,但缓存中却是旧的脏数据。为了避免这种情况发生,可以采用失效缓存的方式处理。
通过失效缓存数据,可以确保下一次读请求从数据库中获取最新的数据并将其加载到缓存中,以避免出现脏数据的问题。这种方式能够提高数据一致性,但在并发情况下,同时写数据库和更新缓存仍然存在双写不成功的可能性,这将在后续章节中进一步讨论。
总之,为了保证数据的一致性,建议在数据更新时使用失效缓存的方式进行处理,确保下一次读请求能够获取到最新的数据。
先更新缓存再更新数据库

先更新缓存再更新数据库也存在一些弊端。下面是其中一些可能的问题:
-
数据丢失风险:如果在更新缓存成功后,但在更新数据库之前发生错误或中断,那么数据更新将会失败,导致数据库中的数据与缓存中的数据不一致。这可能导致数据丢失的风险。
-
系统可用性降低:由于先要更新缓存,然后再更新数据库,整个过程需要两次数据库操作。如果其中一次操作失败或延迟,整个数据更新过程将会更加复杂和耗时。这可能导致系统的可用性下降。
-
竞态条件:如果多个并发操作同时尝试更新缓存和数据库,可能会导致竞态条件。例如,如果两个操作同时读取了旧数据到缓存中,然后同时进行写入,最终可能会发生数据不一致的情况。
-
错误处理复杂性:先更新缓存再更新数据库会增加错误处理的复杂性。如果在更新缓存时发生错误,需要有一种机制来回滚或撤销这次更新。这增加了系统的复杂性和维护成本。
因此,在设计数据更新方案时,需要综合考虑数据一致性、可用性和系统复杂性等方面的因素。一种常用的做法是在更新数据库后立即更新缓存,以确保数据的一致性。
优化数据懒加载
优化数据懒加载,避免不必要的计算开销:如果某些缓存值需要进行复杂计算才能得出,每次更新数据时都更新缓存可能会导致大量计算性能的浪费,特别是在一段时间内没有读取该缓存数据的情况下。为了更符合数据懒加载的概念并降低计算开销,在读请求到来时再进行计算可能是更好的选择。
以下是改进的建议
-
延迟缓存更新:在数据更新时,不立即更新相关缓存值,而是延迟到读请求到达时进行计算和更新。这样可以最大限度地避免不必要的计算开销。
-
设置缓存过期时间:为每个缓存设置适当的过期时间。如果在过期时间内没有读取该缓存数据,就不进行更新。只有当有读请求到来时,再根据需要进行计算和更新缓存。
-
使用缓存命中率监控:监控缓存的命中率,即缓存被读取的频率。如果某个缓存的命中率较低,说明该缓存可能是不必要的,可以考虑取消或延迟更新该缓存。
-
考虑基于事件的更新:将缓存更新与特定事件关联,只有在事件触发时才进行计算和更新相关缓存。这样可以确保在需要更新缓存时才进行计算,避免不必要的计算开销。
通过采取上述措施,可以更好地遵循数据懒加载的原则,减少不必要的计算开销,提高系统性能和资源利用率。
失效缓存和更新数据库的顺序问题
在处理数据更新后缓存失效的情况下,针对数据库和缓存更新的时序可以归纳为以下几种情况:
先失效缓存再更新数据库
当缓存数据更新机制中先失效缓存再更新数据库时,可能会导致以下问题:
-
数据读取延迟:由于缓存失效后,下一次读取数据需要从数据库中获取,可能会增加读取的延迟,特别是在高并发的情况下。这会影响系统的响应时间和用户体验。
-
数据不一致性:如果在缓存失效之后,但在更新数据库之前,有其他请求读取了旧的缓存数据,那么就会导致数据不一致的问题。因为这些请求读取到的是失效的缓存数据,而不是最新的数据库数据。
-
频繁的数据库操作:由于缓存失效后立即更新数据库,可能会导致频繁的数据库操作。这会增加数据库的负载和资源消耗,可能影响系统的性能和稳定性。

如果请求1的线程在失效缓存后,请求2的线程读请求发现缓存数据为空时,从数据库中读取旧值放入缓存,会导致脏数据的问题确实存在。这是因为在缓存失效期间,B线程读请求发生,缓存尚未更新,所以读取到的是旧值。
解决方案
为了解决这些问题,可以考虑使用更智能的缓存策略,例如:
-
更新数据库后再失效缓存:先更新数据库,确保数据的一致性,然后再失效相关缓存,以便下一次读取时能获取最新的数据。
-
使用缓存更新队列:将需要更新数据库的操作放入队列中,然后按顺序处理。这样可以确保数据库的操作顺序和数据一致性,并减少频繁的数据库操作。
-
引入缓存同步机制:在更新数据库之前,先将缓存标记为过期状态,在更新完成后再重新加载缓存。这样可以避免读取到过期的缓存数据。
-
更新缓存时加锁:在线程A失效缓存并更新数据库时,可以通过加锁的方式确保其他线程不能读取脏数据。只有当更新完成后,其他线程才能继续读取缓存数据。
-
延迟失效策略:在线程A失效缓存后,在更新数据库之前,可以设置一个较短的延迟时间,让线程B等待一段时间再进行读取操作。这样可以增加线程A完成更新的机会,减少读取脏数据的概率。
-
引入版本号或时间戳:在缓存数据中引入一个版本号或时间戳,当读请求发生时,比较请求的时间戳和缓存数据的时间戳,如果时间较新,则不再读取数据库,避免读取脏数据。
需要根据具体的业务场景和需求选择合适的缓存更新策略,以提高系统的性能和数据一致性。
采用延时双删
针对这种情况,可以采用延时双删的策略来有效避免。伪代码如下:
cache.delKey(key);
db.update(data);
Thread.sleep(xxx);
cache.delKey(key);
这种策略主要在写请求完成数据库更新后,休眠一段时间,然后再次删除可能由读请求引入的脏数据,从而最大限度地减少脏数据的存在。
然而,需要注意的是这种延时双删方式需要线程休眠,会降低系统的吞吐量,并不是一种优雅的解决方式。另外,如果数据库采用主从架构,读取的数据也有可能是主从未同步完成时导致的脏数据。
异步删除处理机制
针对这个问题,还可以考虑采用异步删除的方式。即,在写请求完成数据库更新后,不立即进行删除操作,而是异步地进行删除处理。这样可以避免线程休眠,提高系统的吞吐量,并且在一定程度上解决了主从未同步的问题。
另外,设置缓存的过期时间也是一种解决方案。通过设定适当的过期时间,当缓存过期后,系统会自动载入最新的数据,并且需要系统能够容忍一段时间的数据不一致性。
Write/Read Through 缓存透写/透读
在Cache Aside模式中,对于数据库和缓存的更新逻辑由调用方自行控制,这显然是一个相当复杂的过程。而在写透写/读透读模式中,对于调用方而言,缓存是整个数据存储的接口,而不需要关心缓存背后的数据库更新,数据库的更新由缓存统一管理,对于调用方来说,只需要与缓存进行交互,整个过程是透明的。
在写透写/读透读模式下
当调用方要更新数据时,首先会将数据写入缓存。缓存在收到写请求之后,会负责将数据更新到数据库,并确保数据的一致性。读取数据时,调用方也直接通过缓存进行读取,如果缓存中不存在所需数据,缓存会自动从数据库中获取。这样,调用方就可以将缓存作为数据存储的唯一接口,而不需要直接与数据库进行交互。
读写模式的有点机制
使用写透写/读透读模式可以简化调用方的代码逻辑,减少数据访问的复杂性。同时,由于缓存统一管理数据库的更新,可以提高系统的性能和吞吐量。然而,需要注意的是,缓存和数据库之间的数据一致性需要得到保证,可能需要采用一些额外的机制来解决缓存与数据库之间的同步问题。

总结起来,写透写/读透读模式将缓存作为整个数据存储的接口,统一管理数据库的更新,可以简化调用方的代码逻辑,并提高系统的性能。在实际使用中,需要根据具体的需求和场景,综合考虑数据一致性、性能需求以及系统复杂性等因素,选择合适的缓存策略。
Write Behind Cache Pattern 后写缓存模式
后写缓存模式是在数据更新时直接更新缓存数据,并建立异步任务去更新数据库。这种异步方式使得请求响应速度快,系统的吞吐量也会显著提升。然而,由于是异步更新数据库,数据一致性的保障会相对较弱。如果更新数据库失败,就会永远导致系统产生脏数据。因此,需要精心设计系统的重试策略。此外,如果异步服务出现故障,还需要考虑如何持久化更新的数据,以便在服务重启后能够快速恢复。

在更新数据库时,由于存在并发多任务,还需要考虑并发写是否会导致脏数据问题,因此需要追溯每次更新数据的时序。使用这种模式需要考虑的细节很多,设计出一套良好的方案并不容易。
注意要点
尽管后写缓存模式可以提升系统性能,但需要注意以下几点。
首先,由于数据一致性的风险,需要谨慎权衡是否可以容忍脏数据的出现。其次,需要考虑并发写引发的脏数据问题,可能需要采取适当的并发控制措施。最后,需要设计合理的重试策略和数据持久化方案,以应对异步更新和服务故障导致的问题。
后写缓存模式可以提高系统性能,但在数据一致性、并发写控制、重试策略和数据持久化等方面需要投入较大的设计和实现工作。在实际应用中,需要根据具体情况权衡利弊,并综合考虑系统需求、资源情况和可靠性要求等因素,选择合适的缓存模式。
总结分析
最新的数据应该放置在数据库中。
缓存的目的是为了提升系统性能,通过利用内存的高速读取来提高系统吞吐量,并减轻数据库的压力。缓存的存在可以使得部分读请求无需到达数据库层,从而提高响应速度。然而,这也带来了一个问题,即数据存在于缓存和数据库这两个位置,所以在数据更新时需要考虑将“正确的数据放置在哪个最可信的存储介质上”,这需要结合业务性质在两个数据存储介质中进行选择。
在缓存除模式中,可以选择先更新数据库,然后使缓存失效(Cache Aside Pattern),这样可以确保最新和最准确的数据一定会存储在数据库中。这种方式可以保证数据库中的核心业务数据是可信的,但会导致更新逻辑更复杂,系统处理更新的耗时更长。对于非核心数据的更新,可以选择后写缓存模式(Write Behind Cache Pattern),只需更新缓存即可,以实现快速响应。然而,这种方式容易导致数据不一致,即数据库中的数据不一定是最可信的数据。
因此,不同的更新策略实际上是权衡最新数据放置的位置和系统性能的一种平衡。需要根据业务场景做出折衷选择。在核心业务数据的更新中,优先选择将最新数据放置在数据库中,以确保数据的可信性。而对于非核心数据的更新,可以考虑使用缓存来提高系统性能,但需要注意数据一致性的问题。
彩蛋案例
在这里,我向大家推荐一本关于JVM优化和调优的实战系列书籍,《深入浅出Java虚拟机 — JVM原理与实战》。这本书是最新出版的,内容涵盖了与我们当前工作和开发实例密切相关的技术和实战案例。通过学习这本书,我们可以深入了解Java虚拟机的原理,并通过实践掌握优化和调优的技巧。我诚挚地推荐这本书给大家,相信它将为我们的工作和技术发展带来巨大的收益。希望大家能够抽出时间多多学习一下这本宝贵的资料。
【当当-点击链接】【京东-点击链接】