介绍
LinkedList同时实现了List接口和Deque接口,也就是说它既可以看作一个顺序容器,又可以看作一个队列(Queue),同时又可以看作一个栈(Stack)。这样看来,LinkedList简直就是个全能冠军。当你需要使用栈或者队列时,可以考虑使用LinkedList,一方面是因为Java官方已经声明不建议使用Stack类,更遗憾的是,Java里根本没有一个叫做Queue的类(它是个接口名字,无法直接创建)。关于栈或队列,现在的首选是ArrayDeque,它有着比LinkedList(当作栈或队列使用时)有着更好的性能。
对于频繁的插入或删除元素的操作,建议使用LinkedList类,效率较高;底层使用双向链表存储
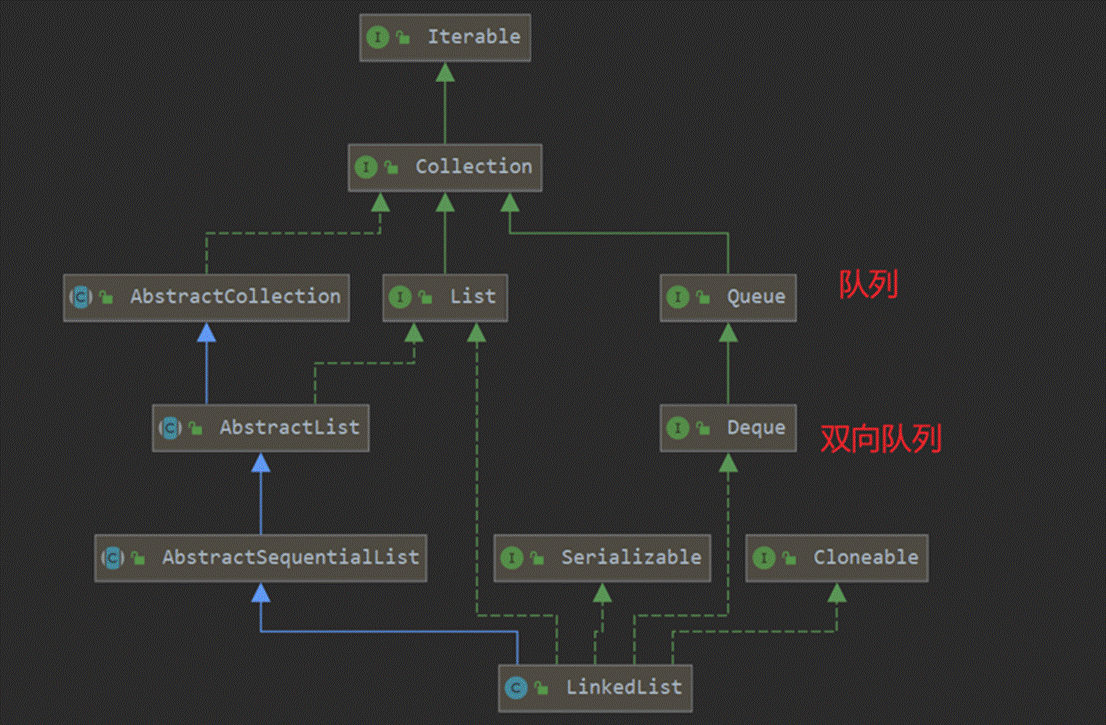
//存储链表的第一个节点
transient Node<E> first;//存储链表的最后一个节点
transient Node<E> last;
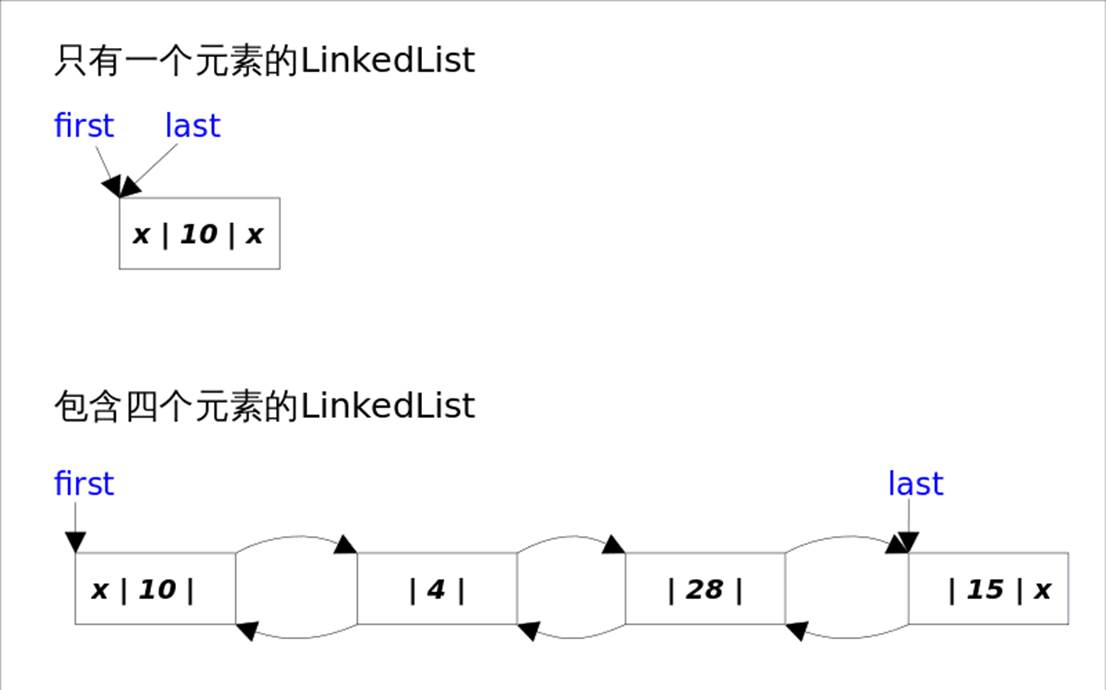
LinkedList的实现方式决定了所有跟下标相关的操作都是线性时间,而在首段或者末尾删除元素只需要常数时间。为追求效率LinkedList没有实现同步(synchronized),如果需要多个线程并发访问,可以先采用Collections.synchronizedList()方法对其进行包装。
底层实现
底层数据结构
LinkedList底层通过双向链表实现。双向链表的每个节点用内部类Node表示。LinkedList通过first和last引用分别指向链表的第一个和最后一个元素。注意这里没有所谓的哑元(也就是没有虚拟变量),当链表为空的时候first和last都指向null。
transient int size = 0;/*** Pointer to first node.* Invariant: (first == null && last == null) ||* (first.prev == null && first.item != null)*/
transient Node <E> first;/*** Pointer to last node.* Invariant: (first == null && last == null) ||* (last.next == null && last.item != null)*/
transient Node <E> last;
其中Node是私有的内部类:
private static class Node <E> {E item;Node <E> next;Node <E> prev;Node(Node <E> prev, E element, Node <E> next) {this.item = element;this.next = next;this.prev = prev;}
}
构造函数
/*** Constructs an empty list.*/public LinkedList() {}/*** Constructs a list containing the elements of the specified* collection, in the order they are returned by the collection's* iterator.** @param c the collection whose elements are to be placed into this list* @throws NullPointerException if the specified collection is null*/public LinkedList(Collection <? extends E> c) {this();addAll(c);}
getFirst(), getLast()
获取第一个元素, 和获取最后一个元素:
/*** Returns the first element in this list.** @return the first element in this list* @throws NoSuchElementException if this list is empty*/
public E getFirst() {final Node <E> f = first;if (f == null)throw new NoSuchElementException();return f.item;
}/*** Returns the last element in this list.** @return the last element in this list* @throws NoSuchElementException if this list is empty*/
public E getLast() {final Node <E> l = last;if (l == null)throw new NoSuchElementException();return l.item;
}
get方法
get方法是根据索引获取元素的
public E get(int index) {checkElementIndex(index);return node(index).item;
}//找到具体索引位置的 Node
Node <E> node(int index) {// assert isElementIndex(index);//类似二分法,size >> 1 即元素数量的一半if (index < (size >> 1)) { //索引小于一半,就从头开始找Node <E> x = first;for (int i = 0; i < index; i++)x = x.next;return x;} else { //否则就从尾部开始找Node <E> x = last;for (int i = size - 1; i > index; i--)x = x.prev;return x;}
}
removeFirst(), removeLast(), remove(e), remove(index)
remove()方法也有两个版本
-
删除跟指定元素相等的第一个元素remove(Object o)
-
删除指定下标处的元素remove(int index)
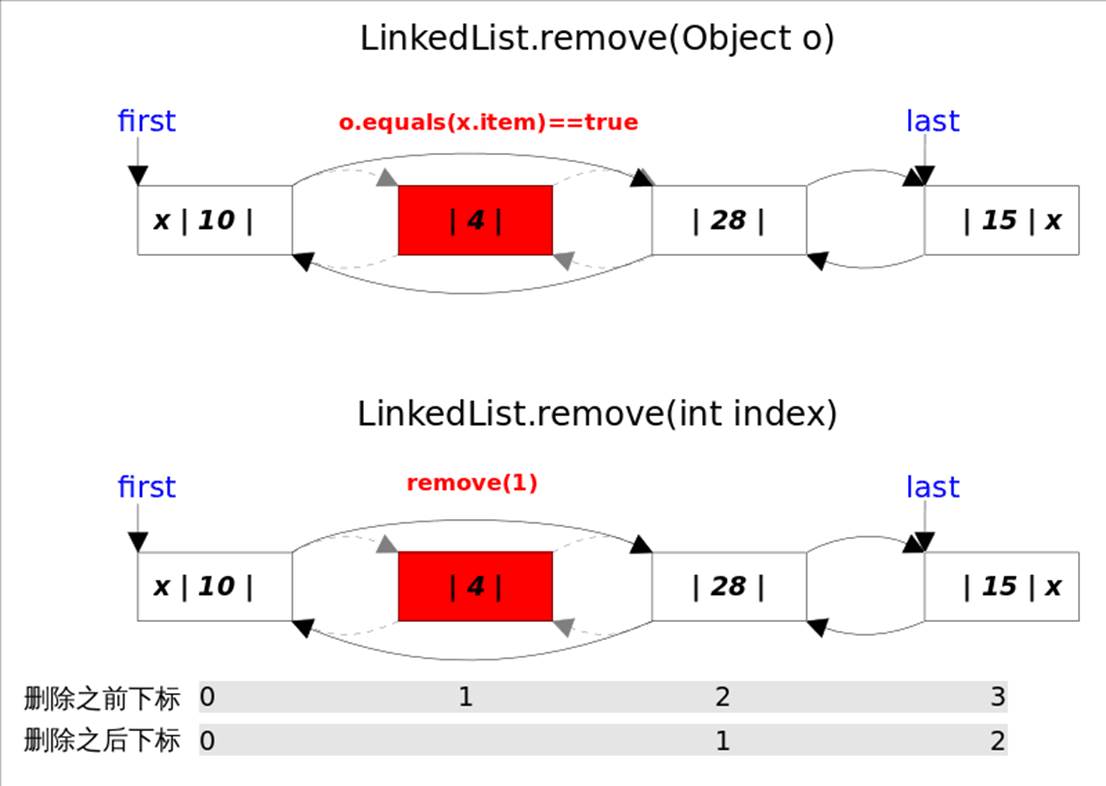
删除元素:指的是删除第一次出现的这个元素, 如果没有这个元素,则返回false;判断的依据是equals方法, 如果equals,则直接unlink这个node;
由于LinkedList可存放null元素,故也可以删除第一次出现null的元素;
public boolean remove(Object o) {if (o == null) {for (Node <E> x = first; x != null; x = x.next) {if (x.item == null) {unlink(x);return true;}}} else {for (Node <E> x = first; x != null; x = x.next) {if (o.equals(x.item)) {unlink(x);return true;}}}return false;
}/*** Unlinks non-null node x.*/
E unlink(Node <E> x) {// assert x != null;final E element = x.item;final Node <E> next = x.next;final Node <E> prev = x.prev;if (prev == null) { // 第一个元素first = next;} else {prev.next = next;x.prev = null;}if (next == null) { // 最后一个元素last = prev;} else {next.prev = prev;x.next = null;}x.item = null; // GCsize--;modCount++;return element;
}
linklist是有序的,可重复存储数据的,并且可以存储null值,但remove方法在找到需要删除的元素时,就return了,因此只能删除找到的第一个元素
LinkedList<String> list = new LinkedList();
list.add("1");
list.add(null);
list.add(null);
list.add("1");
System.out.println(list);
list.remove(null);
list.remove("1");
System.out.println(list);
//输出:
[1, null, null, 1]
[null, 1]
add方法
add()方法有两个版本:
-
add(E e),该方法在LinkedList的末尾插入元素,因为有last指向链表末尾,在末尾插入元素的花费是常数时间。只需要简单修改几个相关引用即可;
-
add(int index, E element),该方法是在指定下表处插入元素,需要先通过线性查找找到具体位置,然后修改相关引用完成插入操作。
public boolean add(E e) {linkLast(e);//默认add方法是在尾部插入元素return true;
}void linkLast(E e) {final Node<E> l = last;//旧的尾部元素final Node<E> newNode = new Node<>(l, e, null);last = newNode;//尾部元素为 newNodeif (l == null)//说明集合中没有元素first = newNode;elsel.next = newNode;//旧的尾部元素 指向 newNode,即添加newNodesize++;modCount++;
}//同理。链表头部添加元素private void linkFirst(E e) {final Node<E> f = first;final Node<E> newNode = new Node<>(null, e, f);first = newNode;if (f == null)last = newNode;elsef.prev = newNode;size++;modCount++;
}
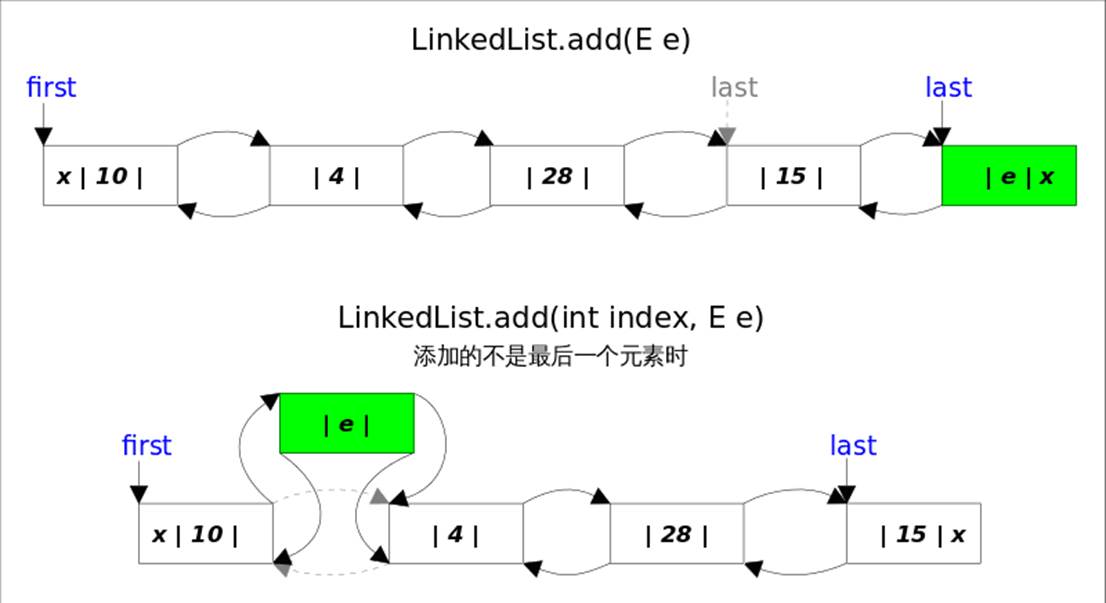
add(int index, E element),当index==size时,等同于add(E e); 如果不是,则分两步:
- 先根据index找到要插入的位置,即node(index)方法;
- 修改引用,完成插入操作。
public void add(int index, E element) {checkPositionIndex(index);if (index == size)linkLast(element);elselinkBefore(element, node(index));
}
上面代码中的node(int index)函数有一点小小的trick,因为链表双向的,可以从开始往后找,也可以从结尾往前找,具体朝那个方向找取决于条件index < (size >> 1),也即是index是靠近前端还是后端。从这里也可以看出,linkedList通过index查询元素的效率没有arrayList高。
Node <E> node(int index) {// assert isElementIndex(index);if (index < (size >> 1)) {Node <E> x = first;for (int i = 0; i < index; i++)x = x.next;return x;} else {Node <E> x = last;for (int i = size - 1; i > index; i--)x = x.prev;return x;}
}
addAll()
addAll(index, c) 实现方式并不是直接调用add(index,e)来实现,主要是因为效率的问题,另一个是fail-fast中modCount只会增加1次;
public boolean addAll(Collection <? extends E> c) {return addAll(size, c);}public boolean addAll(int index, Collection <? extends E> c) {checkPositionIndex(index);Object[] a = c.toArray();int numNew = a.length;if (numNew == 0)return false;Node <E> pred, succ;if (index == size) {succ = null;pred = last;} else {succ = node(index);pred = succ.prev;}for (Object o: a) {@SuppressWarnings("unchecked") E e = (E) o;Node <E> newNode = new Node <> (pred, e, null);if (pred == null)first = newNode;elsepred.next = newNode;pred = newNode;}if (succ == null) {last = pred;} else {pred.next = succ;succ.prev = pred;}size += numNew;modCount++;return true;}
clear()
这里是将node之间的引用关系都变成null,这样GC可以在年轻代回收元素了
public void clear() {// Clearing all of the links between nodes is "unnecessary", but:// - helps a generational GC if the discarded nodes inhabit// more than one generation// - is sure to free memory even if there is a reachable Iteratorfor (Node <E> x = first; x != null;) {Node <E> next = x.next;x.item = null;x.next = null;x.prev = null;x = next;}first = last = null;size = 0;modCount++;
}
注意:有些同学可能注意到这里的判定条件是x != null,但是 LinkedList 是可以设置null值的,那是不是当链表中有null的元素,并且爱clear遍历到元素为null时,条件 x != null就为false了,那就不会继续执行,也就是后续的元素都无法置为空了?
实际上不是的,这里的x != null是没有这个元素,而LinkedList 中可以设置null值是指,x.item = null ,也就是有Node,但是Node的item属性为null
Positional Access 方法
通过index获取元素
public E get(int index) {checkElementIndex(index);return node(index).item;}
将某个位置的元素重新赋值:
public E set(int index, E element) {checkElementIndex(index);Node <E> x = node(index);E oldVal = x.item;x.item = element;return oldVal;
}
将元素插入到指定index位置:
public void add(int index, E element) {checkPositionIndex(index);if (index == size)linkLast(element);elselinkBefore(element, node(index));}
删除指定位置的元素:
public E remove(int index) {checkElementIndex(index);return unlink(node(index));}
其它位置的方法:
private boolean isElementIndex(int index) {return index >= 0 && index < size;}private boolean isPositionIndex(int index) {return index >= 0 && index <= size;}private String outOfBoundsMsg(int index) {return "Index: " + index + ", Size: " + size;}private void checkElementIndex(int index) {if (!isElementIndex(index))throw new IndexOutOfBoundsException(outOfBoundsMsg(index));}private void checkPositionIndex(int index) {if (!isPositionIndex(index))throw new IndexOutOfBoundsException(outOfBoundsMsg(index));}
查找操作
查找操作的本质是查找元素的下标:
查找第一次出现的index, 如果找不到返回-1;
public int indexOf(Object o) {int index = 0;if (o == null) {for (Node <E> x = first; x != null; x = x.next) {if (x.item == null)return index;index++;}} else {for (Node <E> x = first; x != null; x = x.next) {if (o.equals(x.item))return index;index++;}}return -1;
}
查找最后一次出现的index, 如果找不到返回-1;
public int lastIndexOf(Object o) {int index = size;if (o == null) {for (Node <E> x = last; x != null; x = x.prev) {index--;if (x.item == null)return index;}} else {for (Node <E> x = last; x != null; x = x.prev) {index--;if (o.equals(x.item))return index;}}return -1;}
LinkedList 存在的性能问题
-
从速度的角度:ArrayDeque 基于数组实现双端队列,而 LinkedList 基于双向链表实现双端队列,数组采用连续的内存地址空间,通过下标索引访问,链表是非连续的内存地址空间,通过指针访问,所以在寻址方面数组的效率高于链表。
-
从内存的角度:虽然 LinkedList 没有扩容的问题,但是插入元素的时候,需要创建一个 Node 对象, 换句话说每次都要执行 new 操作,当执行 new 操作的时候,其过程是非常慢的,会经历两个过程:类加载过程 、对象创建过程。
-
类加载过程
-
会先判断这个类是否已经初始化,如果没有初始化,会执行类的加载过程
-
类的加载过程:加载、验证、准备、解析、初始化等等阶段,之后会执行 <cinit> 方法,初始化静态变量,执行静态代码块等等
-
-
对象创建过程
-
如果类已经初始化了,直接执行对象的创建过程
-
对象的创建过程:在堆内存中开辟一块空间,给开辟空间分配一个地址,之后执行初始化,会执行 <init>方法,初始化普通变量,调用普通代码块
-
-
关于作者
来自一线程序员Seven的探索与实践,持续学习迭代中~
本文已收录于我的个人博客:https://www.seven97.top
公众号:seven97,欢迎关注~