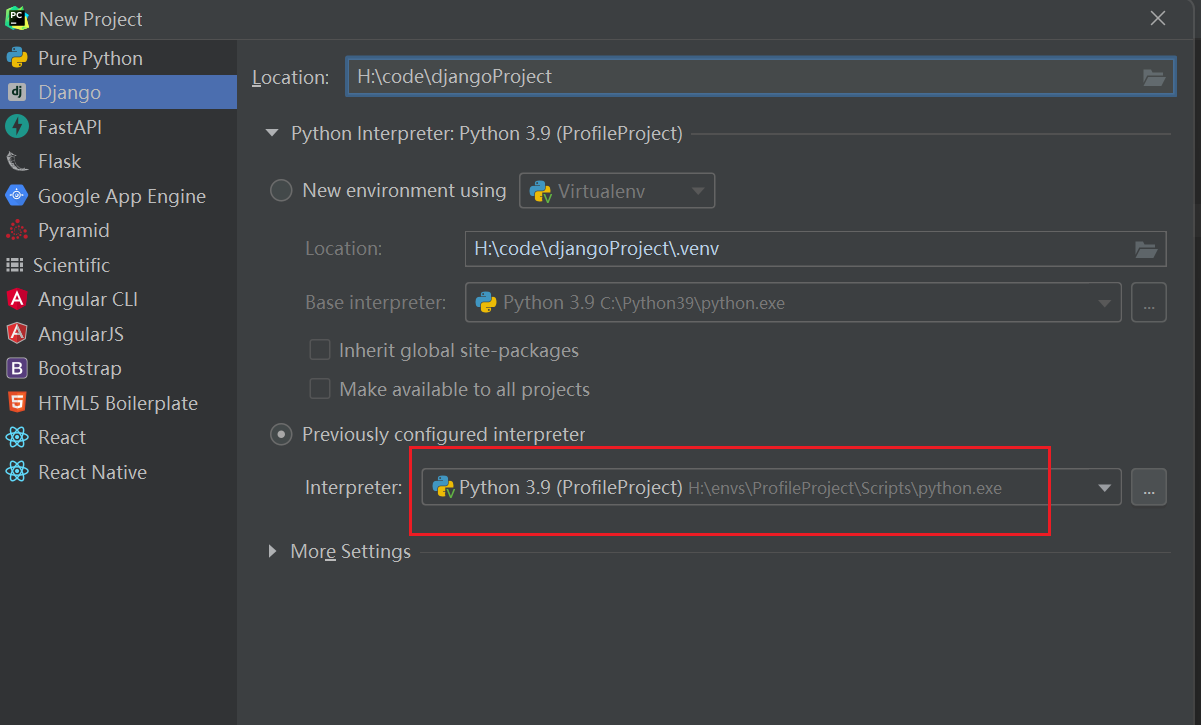
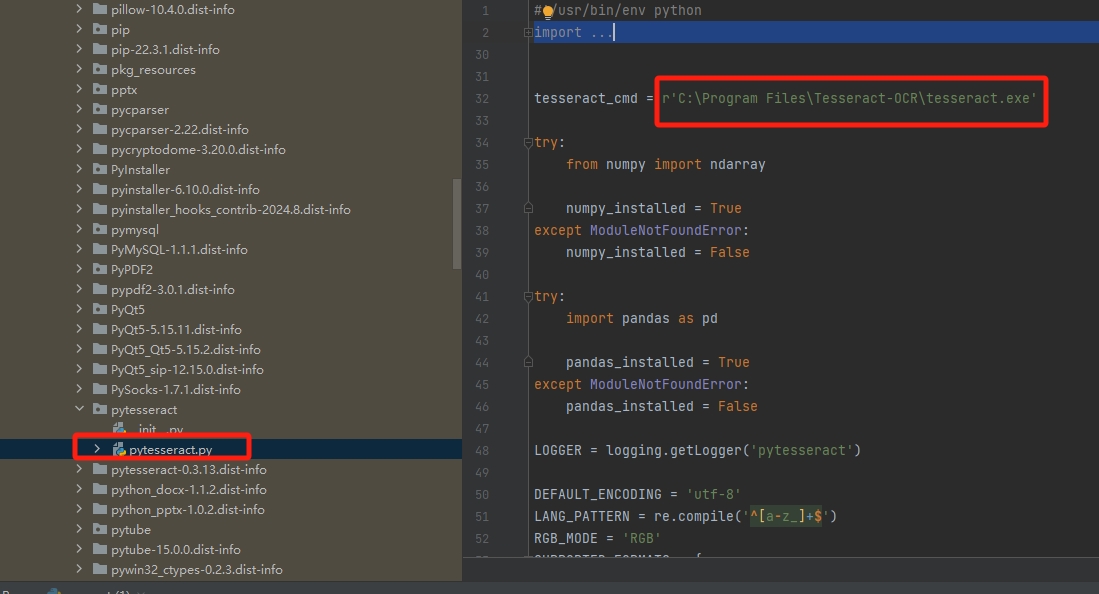
步骤一:先安装tesseract-ocr-w64-setup-5.4.0.20240606 (安装记得语言包只安装需要的即可)
步骤二:将安装目录添加到系统环境变量中
(网上很多这一步之后就说可以运行程序了其实不然,一直报错没有添加到环境变量中)
步骤三:
第四步:可以正常运行啦
==========================================================================================
from PyPDF2 import PdfReader
from docx import Document
import pytesseract
from PIL import Image
import io
def pdf_to_word_with_ocr(pdf_path, word_path):
import os
# 检查文件是否存在
if not os.path.exists(pdf_path):
raise FileNotFoundError(f"指定的文件 {pdf_path} 不存在。")
# 创建Word文档对象
doc = Document()# 打开PDF文件
reader = PdfReader(pdf_path)# 遍历PDF中的每一页
for page_number, page in enumerate(reader.pages):# 尝试提取页面文本text = page.extract_text()if text:# 如果能直接提取到文本,就添加到Word文档中doc.add_paragraph(text)else:# 如果页面没有文本,尝试使用OCR提取图像中的文本images = page.imagesif images:for image_index, img in enumerate(images):# 将图像数据从PDF中提取出来image = Image.open(io.BytesIO(img.data))# 使用OCR识别图像中的文本ocr_text = pytesseract.image_to_string(image, lang='chi_sim')doc.add_paragraph(f"第{page_number+1}页, 图像{image_index+1}: {ocr_text}")else:# 如果页面既没有文本也没有图像,添加一个占位符doc.add_paragraph(f"第{page_number+1}页无文本或图像。")# 保存Word文档
doc.save(word_path)
使用函数
pdf_path = '45.pdf'
word_path = 'output.docx'
pdf_to_word_with_ocr(pdf_path, word_path)


![[MySQL]B+树能存储多少数据](https://img2024.cnblogs.com/blog/1533409/202409/1533409-20240904225031138-767558854.png)