.\flux\demo_gr.py
# 导入操作系统相关模块
import os
# 导入时间相关模块
import time
# 从 io 模块导入 BytesIO 类
from io import BytesIO
# 导入 UUID 生成模块
import uuid# 导入 PyTorch 库
import torch
# 导入 Gradio 库
import gradio as gr
# 导入 NumPy 库
import numpy as np
# 从 einops 模块导入 rearrange 函数
from einops import rearrange
# 从 PIL 库导入 Image 和 ExifTags
from PIL import Image, ExifTags
# 从 transformers 库导入 pipeline 函数
from transformers import pipeline# 从 flux.cli 模块导入 SamplingOptions 类
from flux.cli import SamplingOptions
# 从 flux.sampling 模块导入多个函数
from flux.sampling import denoise, get_noise, get_schedule, prepare, unpack
# 从 flux.util 模块导入多个函数
from flux.util import configs, embed_watermark, load_ae, load_clip, load_flow_model, load_t5# 设置 NSFW (不适宜工作) 图像的分类阈值
NSFW_THRESHOLD = 0.85# 定义获取模型的函数
def get_models(name: str, device: torch.device, offload: bool, is_schnell: bool):# 加载 T5 模型,长度限制根据是否为 schnell 模型决定t5 = load_t5(device, max_length=256 if is_schnell else 512)# 加载 CLIP 模型clip = load_clip(device)# 加载流动模型,根据是否卸载来决定使用 CPU 还是设备model = load_flow_model(name, device="cpu" if offload else device)# 加载自编码器模型,同样根据是否卸载来决定使用 CPU 还是设备ae = load_ae(name, device="cpu" if offload else device)# 创建 NSFW 分类器管道nsfw_classifier = pipeline("image-classification", model="Falconsai/nsfw_image_detection", device=device)# 返回加载的模型和分类器return model, ae, t5, clip, nsfw_classifier# 定义 FluxGenerator 类
class FluxGenerator:# 类的初始化函数def __init__(self, model_name: str, device: str, offload: bool):# 将设备字符串转换为 torch.device 对象self.device = torch.device(device)# 是否卸载的标志self.offload = offload# 模型名称self.model_name = model_name# 判断是否为 schnell 模型self.is_schnell = model_name == "flux-schnell"# 获取模型及相关组件self.model, self.ae, self.t5, self.clip, self.nsfw_classifier = get_models(model_name,device=self.device,offload=self.offload,is_schnell=self.is_schnell,)# 使用 torch 的推理模式生成图像@torch.inference_mode()def generate_image(self,width,height,num_steps,guidance,seed,prompt,init_image=None,image2image_strength=0.0,add_sampling_metadata=True,# 定义创建演示的函数
def create_demo(model_name: str, device: str = "cuda" if torch.cuda.is_available() else "cpu", offload: bool = False):# 初始化 FluxGenerator 对象generator = FluxGenerator(model_name, device, offload)# 判断是否为 schnell 模型is_schnell = model_name == "flux-schnell"# 创建一个 Gradio 应用的 UI 布局with gr.Blocks() as demo:# 添加标题 Markdown 文本,显示模型名称gr.Markdown(f"# Flux Image Generation Demo - Model: {model_name}")# 创建一行布局with gr.Row():# 创建一列布局with gr.Column():# 创建一个文本框用于输入提示prompt = gr.Textbox(label="Prompt", value="a photo of a forest with mist swirling around the tree trunks. The word \"FLUX\" is painted over it in big, red brush strokes with visible texture")# 创建一个复选框用于选择是否启用图像到图像转换do_img2img = gr.Checkbox(label="Image to Image", value=False, interactive=not is_schnell)# 创建一个隐藏的图像输入框init_image = gr.Image(label="Input Image", visible=False)# 创建一个隐藏的滑块,用于调整图像到图像转换的强度image2image_strength = gr.Slider(0.0, 1.0, 0.8, step=0.1, label="Noising strength", visible=False)# 创建一个可折叠的高级选项区域with gr.Accordion("Advanced Options", open=False):# 创建滑块用于设置图像宽度width = gr.Slider(128, 8192, 1360, step=16, label="Width")# 创建滑块用于设置图像高度height = gr.Slider(128, 8192, 768, step=16, label="Height")# 创建滑块用于设置步骤数,根据是否快速模式设置初始值num_steps = gr.Slider(1, 50, 4 if is_schnell else 50, step=1, label="Number of steps")# 创建滑块用于设置指导强度guidance = gr.Slider(1.0, 10.0, 3.5, step=0.1, label="Guidance", interactive=not is_schnell)# 创建一个文本框用于输入种子值seed = gr.Textbox(-1, label="Seed (-1 for random)")# 创建一个复选框用于选择是否将采样参数添加到元数据add_sampling_metadata = gr.Checkbox(label="Add sampling parameters to metadata?", value=True)# 创建一个生成按钮generate_btn = gr.Button("Generate")# 创建另一列布局with gr.Column():# 创建一个图像框用于显示生成的图像output_image = gr.Image(label="Generated Image")# 创建一个数字框用于显示使用的种子seed_output = gr.Number(label="Used Seed")# 创建一个文本框用于显示警告信息warning_text = gr.Textbox(label="Warning", visible=False)# 创建一个文件框用于下载高分辨率图像download_btn = gr.File(label="Download full-resolution")# 定义一个函数,用于更新图像到图像转换的可见性def update_img2img(do_img2img):return {init_image: gr.update(visible=do_img2img),image2image_strength: gr.update(visible=do_img2img),}# 当复选框状态变化时,调用更新函数do_img2img.change(update_img2img, do_img2img, [init_image, image2image_strength])# 设置生成按钮的点击事件,调用生成图像的函数并设置输入和输出generate_btn.click(fn=generator.generate_image,inputs=[width, height, num_steps, guidance, seed, prompt, init_image, image2image_strength, add_sampling_metadata],outputs=[output_image, seed_output, download_btn, warning_text],)# 返回创建的 Gradio 应用布局return demo
# 当脚本作为主程序运行时执行以下代码
if __name__ == "__main__":# 导入 argparse 模块用于处理命令行参数import argparse# 创建 ArgumentParser 对象,用于解析命令行参数parser = argparse.ArgumentParser(description="Flux")# 添加 --name 参数,指定模型名称,默认值为 "flux-schnell",并限制选择范围parser.add_argument("--name", type=str, default="flux-schnell", choices=list(configs.keys()), help="Model name")# 添加 --device 参数,指定设备,默认值为 "cuda"(如果有 GPU 可用),否则为 "cpu"parser.add_argument("--device", type=str, default="cuda" if torch.cuda.is_available() else "cpu", help="Device to use")# 添加 --offload 参数,标志位,指示是否在不使用时将模型移到 CPUparser.add_argument("--offload", action="store_true", help="Offload model to CPU when not in use")# 添加 --share 参数,标志位,指示是否创建一个公共链接以共享演示parser.add_argument("--share", action="store_true", help="Create a public link to your demo")# 解析命令行参数,并将结果存储在 args 对象中args = parser.parse_args()# 使用解析出的参数创建 demo 对象demo = create_demo(args.name, args.device, args.offload)# 启动 demo,是否共享由 --share 参数决定demo.launch(share=args.share)
.\flux\demo_st.py
# 导入操作系统相关功能
import os
# 导入正则表达式处理功能
import re
# 导入时间处理功能
import time
# 从 glob 模块导入 iglob,用于生成匹配特定模式的文件路径
from glob import iglob
# 从 io 模块导入 BytesIO,用于处理字节流
from io import BytesIO# 导入 streamlit 库,用于创建 Web 应用
import streamlit as st
# 导入 PyTorch 库,用于深度学习模型
import torch
# 从 einops 库导入 rearrange,用于张量的重排
from einops import rearrange
# 从 fire 库导入 Fire,用于将命令行参数绑定到函数
from fire import Fire
# 从 PIL 库导入 ExifTags 和 Image,用于图像处理
from PIL import ExifTags, Image
# 从 st_keyup 库导入 st_keyup,用于捕捉键盘事件
from st_keyup import st_keyup
# 从 torchvision 库导入 transforms,用于图像转换
from torchvision import transforms
# 从 transformers 库导入 pipeline,用于各种预训练模型的管道
from transformers import pipeline# 设置 NSFW 内容的阈值
NSFW_THRESHOLD = 0.85# 使用 Streamlit 缓存模型加载函数的结果,以提高性能
@st.cache_resource()
def get_models(name: str, device: torch.device, offload: bool, is_schnell: bool):# 加载 T5 模型,最大长度取决于是否使用 Schnell 模式t5 = load_t5(device, max_length=256 if is_schnell else 512)# 加载 CLIP 模型clip = load_clip(device)# 加载流模型,设备可能是 CPU 或 GPUmodel = load_flow_model(name, device="cpu" if offload else device)# 加载自动编码器模型,设备可能是 CPU 或 GPUae = load_ae(name, device="cpu" if offload else device)# 加载 NSFW 分类器,用于图像内容检测nsfw_classifier = pipeline("image-classification", model="Falconsai/nsfw_image_detection", device=device)# 返回模型、自动编码器、T5、CLIP 和 NSFW 分类器return model, ae, t5, clip, nsfw_classifier# 获取用户上传的图像,返回处理后的张量
def get_image() -> torch.Tensor | None:# 允许用户上传 JPG、JPEG 或 PNG 格式的图像image = st.file_uploader("Input", type=["jpg", "JPEG", "png"])# 如果没有上传图像,返回 Noneif image is None:return None# 打开图像文件并转换为 RGB 模式image = Image.open(image).convert("RGB")# 定义图像转换操作,将图像转为张量,并进行归一化transform = transforms.Compose([transforms.ToTensor(),transforms.Lambda(lambda x: 2.0 * x - 1.0),])# 应用转换,将图像处理为张量,并增加一个维度img: torch.Tensor = transform(image)return img[None, ...]# 主函数,用于运行应用逻辑
@torch.inference_mode()
def main(device: str = "cuda" if torch.cuda.is_available() else "cpu",offload: bool = False,output_dir: str = "output",
):# 根据用户选择的设备创建 PyTorch 设备对象torch_device = torch.device(device)# 获取配置中的模型名称列表names = list(configs.keys())# 让用户选择要加载的模型name = st.selectbox("Which model to load?", names)# 如果未选择模型或未勾选加载模型的复选框,则返回if name is None or not st.checkbox("Load model", False):return# 判断是否使用 Schnell 模式is_schnell = name == "flux-schnell"# 获取所需的模型和分类器model, ae, t5, clip, nsfw_classifier = get_models(name,device=torch_device,offload=offload,is_schnell=is_schnell,)# 判断是否执行图像到图像的转换do_img2img = (st.checkbox("Image to Image",False,disabled=is_schnell,help="Partially noise an image and denoise again to get variations.\n\nOnly works for flux-dev",)and not is_schnell)# 如果需要图像到图像转换if do_img2img:# 获取用户上传的图像init_image = get_image()# 如果没有上传图像,显示警告信息if init_image is None:st.warning("Please add an image to do image to image")# 让用户输入噪声强度image2image_strength = st.number_input("Noising strength", min_value=0.0, max_value=1.0, value=0.8)# 如果上传了图像,显示图像尺寸if init_image is not None:h, w = init_image.shape[-2:]st.write(f"Got image of size {w}x{h} ({h*w/1e6:.2f}MP)")# 让用户选择是否调整图像大小resize_img = st.checkbox("Resize image", False) or init_image is Noneelse:# 如果不进行图像到图像转换,初始化图像和图像调整标志init_image = Noneresize_img = Trueimage2image_strength = 0.0# 允许进行打包和转换到潜在空间# 根据用户输入的宽度值计算实际宽度,确保宽度为16的倍数width = int(16 * (st.number_input("Width", min_value=128, value=1360, step=16, disabled=not resize_img) // 16))# 根据用户输入的高度值计算实际高度,确保高度为16的倍数height = int(16 * (st.number_input("Height", min_value=128, value=768, step=16, disabled=not resize_img) // 16))# 根据用户输入的步数值设置步数,默认值为4(如果是"schnell"模式),否则为50num_steps = int(st.number_input("Number of steps", min_value=1, value=(4 if is_schnell else 50)))# 根据用户输入的引导值设置引导参数,默认为3.5,"schnell"模式下禁用此输入guidance = float(st.number_input("Guidance", min_value=1.0, value=3.5, disabled=is_schnell))# 根据用户输入的种子值设置种子,"schnell"模式下禁用此输入seed_str = st.text_input("Seed", disabled=is_schnell)# 如果种子值是有效的十进制数,则将其转换为整数;否则,设置种子为None,并显示提示信息if seed_str.isdecimal():seed = int(seed_str)else:st.info("No seed set, set to positive integer to enable")seed = None# 根据用户选择是否保存样本,设置保存样本的选项save_samples = st.checkbox("Save samples?", not is_schnell)# 根据用户选择是否将采样参数添加到元数据中,设置此选项add_sampling_metadata = st.checkbox("Add sampling parameters to metadata?", True)# 默认提示文本,用于生成图像default_prompt = ("a photo of a forest with mist swirling around the tree trunks. The word "'"FLUX" is painted over it in big, red brush strokes with visible texture')# 获取用户输入的提示文本,默认值为default_prompt,并设置300毫秒的防抖延迟prompt = st_keyup("Enter a prompt", value=default_prompt, debounce=300, key="interactive_text")# 构造输出文件名的路径,并检查输出目录是否存在output_name = os.path.join(output_dir, "img_{idx}.jpg")if not os.path.exists(output_dir):# 如果输出目录不存在,则创建目录,并初始化索引为0os.makedirs(output_dir)idx = 0else:# 如果输出目录存在,获取所有匹配的文件名,并计算下一个可用的索引fns = [fn for fn in iglob(output_name.format(idx="*")) if re.search(r"img_[0-9]+\.jpg$", fn)]if len(fns) > 0:idx = max(int(fn.split("_")[-1].split(".")[0]) for fn in fns) + 1else:idx = 0# 创建一个 PyTorch 随机数生成器对象rng = torch.Generator(device="cpu")# 如果 session_state 中没有“seed”项,则初始化种子if "seed" not in st.session_state:st.session_state.seed = rng.seed()# 定义增加种子值的函数def increment_counter():st.session_state.seed += 1# 定义减少种子值的函数(种子值不能小于0)def decrement_counter():if st.session_state.seed > 0:st.session_state.seed -= 1# 创建一个采样选项对象,用于后续处理opts = SamplingOptions(prompt=prompt,width=width,height=height,num_steps=num_steps,guidance=guidance,seed=seed,)# 如果应用名为“flux-schnell”,则显示带有按钮的列来增加或减少种子值if name == "flux-schnell":cols = st.columns([5, 1, 1, 5])with cols[1]:st.button("↩", on_click=increment_counter)with cols[2]:st.button("↪", on_click=decrement_counter)# 获取会话状态中的样本(如果存在),并显示图像及其相关信息samples = st.session_state.get("samples", None)if samples is not None:st.image(samples["img"], caption=samples["prompt"])st.download_button("Download full-resolution",samples["bytes"],file_name="generated.jpg",mime="image/jpg",)st.write(f"Seed: {samples['seed']}")
# 定义应用程序入口函数
def app():# 调用 Fire 函数并传入 main 作为参数Fire(main)# 如果脚本是主程序(而不是被导入),则执行 app() 函数
if __name__ == "__main__":app()
![FLUX.1 [dev] Grid](../assets/dev_grid.jpg)
FLUX.1 [dev] is a 12 billion parameter rectified flow transformer capable of generating images from text descriptions.
For more information, please read our blog post.
Key Features
- Cutting-edge output quality, second only to our state-of-the-art model
FLUX.1 [pro]. - Competitive prompt following, matching the performance of closed source alternatives.
- Trained using guidance distillation, making
FLUX.1 [dev]more efficient. - Open weights to drive new scientific research, and empower artists to develop innovative workflows.
- Generated outputs can be used for personal, scientific, and commercial purposes, as described in the flux-1-dev-non-commercial-license.
Usage
We provide a reference implementation of FLUX.1 [dev], as well as sampling code, in a dedicated github repository.
Developers and creatives looking to build on top of FLUX.1 [dev] are encouraged to use this as a starting point.
API Endpoints
The FLUX.1 models are also available via API from the following sources
- bfl.ml (currently
FLUX.1 [pro]) - replicate.com
- fal.ai
ComfyUI
FLUX.1 [dev] is also available in Comfy UI for local inference with a node-based workflow.
Limitations
- This model is not intended or able to provide factual information.
- As a statistical model this checkpoint might amplify existing societal biases.
- The model may fail to generate output that matches the prompts.
- Prompt following is heavily influenced by the prompting-style.
Out-of-Scope Use
The model and its derivatives may not be used
- In any way that violates any applicable national, federal, state, local or international law or regulation.
- For the purpose of exploiting, harming or attempting to exploit or harm minors in any way; including but not limited to the solicitation, creation, acquisition, or dissemination of child exploitative content.
- To generate or disseminate verifiably false information and/or content with the purpose of harming others.
- To generate or disseminate personal identifiable information that can be used to harm an individual.
- To harass, abuse, threaten, stalk, or bully individuals or groups of individuals.
- To create non-consensual nudity or illegal pornographic content.
- For fully automated decision making that adversely impacts an individual's legal rights or otherwise creates or modifies a binding, enforceable obligation.
- Generating or facilitating large-scale disinformation campaigns.
License
This model falls under the FLUX.1 [dev] Non-Commercial License.
![FLUX.1 [schnell] Grid](../assets/schnell_grid.jpg)
FLUX.1 [schnell] is a 12 billion parameter rectified flow transformer capable of generating images from text descriptions.
For more information, please read our blog post.
Key Features
- Cutting-edge output quality and competitive prompt following, matching the performance of closed source alternatives.
- Trained using latent adversarial diffusion distillation,
FLUX.1 [schnell]can generate high-quality images in only 1 to 4 steps. - Released under the
apache-2.0licence, the model can be used for personal, scientific, and commercial purposes.
Usage
We provide a reference implementation of FLUX.1 [schnell], as well as sampling code, in a dedicated github repository.
Developers and creatives looking to build on top of FLUX.1 [schnell] are encouraged to use this as a starting point.
API Endpoints
The FLUX.1 models are also available via API from the following sources
- bfl.ml (currently
FLUX.1 [pro]) - replicate.com
- fal.ai
ComfyUI
FLUX.1 [schnell] is also available in Comfy UI for local inference with a node-based workflow.
Limitations
- This model is not intended or able to provide factual information.
- As a statistical model this checkpoint might amplify existing societal biases.
- The model may fail to generate output that matches the prompts.
- Prompt following is heavily influenced by the prompting-style.
Out-of-Scope Use
The model and its derivatives may not be used
- In any way that violates any applicable national, federal, state, local or international law or regulation.
- For the purpose of exploiting, harming or attempting to exploit or harm minors in any way; including but not limited to the solicitation, creation, acquisition, or dissemination of child exploitative content.
- To generate or disseminate verifiably false information and/or content with the purpose of harming others.
- To generate or disseminate personal identifiable information that can be used to harm an individual.
- To harass, abuse, threaten, stalk, or bully individuals or groups of individuals.
- To create non-consensual nudity or illegal pornographic content.
- For fully automated decision making that adversely impacts an individual's legal rights or otherwise creates or modifies a binding, enforceable obligation.
- Generating or facilitating large-scale disinformation campaigns.
.\flux\src\flux\api.py
# 导入标准库中的 io 模块,用于处理):"""Manages an image generation request to the API.Args:prompt: Prompt to samplewidth: Width of the image in pixelheight: Height of the image in pixelname: Name of the modelnum_steps: Number of network evaluationsprompt_upsampling: Use prompt upsamplingseed: Fix the generation seedvalidate: Run input validationlaunch: Directly launches requestapi_key: Your API key if not provided by the environmentRaises:ValueError: For invalid inputApiException: For errors raised from the API"""# 如果需要验证输入if validate:# 检查模型名称是否有效if name not in ["flux.1-pro"]:raise ValueError(f"Invalid model {name}")# 检查宽度是否是 32 的倍数elif width % 32 != 0:raise ValueError(f"width must be divisible by 32, got {width}")# 检查宽度是否在合法范围内elif not (256 <= width <= 1440):raise ValueError(f"width must be between 256 and 1440, got {width}")# 检查高度是否是 32 的倍数elif height % 32 != 0:raise ValueError(f"height must be divisible by 32, got {height}")# 检查高度是否在合法范围内elif not (256 <= height <= 1440):raise ValueError(f"height must be between 256 and 1440, got {height}")# 检查步骤数量是否在合法范围内elif not (1 <= num_steps <= 50):raise ValueError(f"steps must be between 1 and 50, got {num_steps}")# 创建请求 JSON 对象,包含所有必需的参数self.request_json = {"prompt": prompt,"width": width,"height": height,"variant": name,"steps": num_steps,"prompt_upsampling": prompt_upsampling,}# 如果指定了种子,将其添加到请求 JSON 中if seed is not None:self.request_json["seed"] = seed# 初始化实例变量self.request_id: str | None = Noneself.result: dict | None = Noneself._image_bytes: bytes | None = Noneself._url: str | None = None# 如果没有提供 API 密钥,则从环境变量中获取if api_key is None:self.api_key = os.environ.get("BFL_API_KEY")else:# 否则使用提供的 API 密钥self.api_key = api_key# 如果需要立即发起请求if launch:self.request()def request(self):"""Request to generate the image."""# 如果已经有请求 ID,则不再发起请求if self.request_id is not None:return# 发起 POST 请求以生成图像response = requests.post(f"{API_ENDPOINT}/v1/image",headers={"accept": "application/json","x-key": self.api_key,"Content-Type": "application/json",},json=self.request_json,)# 解析响应为 JSONresult = response.json()# 如果响应状态码不是 200,抛出 API 异常if response.status_code != 200:raise ApiException(status_code=response.status_code, detail=result.get("detail"))# 存储请求 IDself.request_id = response.json()["id"]# 定义一个方法来等待生成完成并检索响应结果def retrieve(self) -> dict:"""等待生成完成并检索响应"""# 如果 request_id 为空,则调用请求方法生成请求 IDif self.request_id is None:self.request()# 循环等待直到结果可用while self.result is None:# 发送 GET 请求以获取结果response = requests.get(f"{API_ENDPOINT}/v1/get_result",headers={"accept": "application/json","x-key": self.api_key,},params={"id": self.request_id,},)# 将响应内容转换为 JSON 格式result = response.json()# 检查返回结果中是否包含状态字段if "status" not in result:# 如果没有状态字段,抛出 API 异常raise ApiException(status_code=response.status_code, detail=result.get("detail"))# 如果状态是“Ready”,则将结果保存到实例变量elif result["status"] == "Ready":self.result = result["result"]# 如果状态是“Pending”,则等待 0.5 秒再重试elif result["status"] == "Pending":time.sleep(0.5)# 如果状态是其他值,抛出 API 异常else:raise ApiException(status_code=200, detail=f"API returned status '{result['status']}'")# 返回最终结果return self.result# 定义一个属性方法,返回生成的图像字节@propertydef bytes(self) -> bytes:"""生成的图像字节"""# 如果图像字节为空,则从 URL 获取图像数据if self._image_bytes is None:response = requests.get(self.url)# 如果响应状态码是 200,则保存图像字节if response.status_code == 200:self._image_bytes = response.content# 否则抛出 API 异常else:raise ApiException(status_code=response.status_code)# 返回图像字节return self._image_bytes# 定义一个属性方法,返回图像的公共 URL@propertydef url(self) -> str:"""检索图像的公共 URL"""# 如果 URL 为空,则调用 retrieve 方法获取结果并保存 URLif self._url is None:result = self.retrieve()self._url = result["sample"]# 返回图像的 URLreturn self._url# 定义一个属性方法,返回 PIL 图像对象@propertydef image(self) -> Image.Image:"""加载图像为 PIL Image 对象"""return Image.open(io.BytesIO(self.bytes))# 定义一个方法来将生成的图像保存到本地路径def save(self, path: str):"""将生成的图像保存到本地路径"""# 获取 URL 的文件扩展名suffix = Path(self.url).suffix# 如果路径没有扩展名,则将扩展名添加到路径中if not path.endswith(suffix):path = path + suffix# 创建保存路径的父目录(如果不存在)Path(path).resolve().parent.mkdir(parents=True, exist_ok=True)# 将图像字节写入指定路径with open(path, "wb") as file:file.write(self.bytes)
# 确保只有在直接运行该脚本时才执行以下代码
if __name__ == "__main__":# 从 fire 库中导入 Fire 类from fire import Fire# 使用 Fire 类启动命令行界面,传入 ImageRequest 作为处理对象Fire(ImageRequest)
.\flux\src\flux\cli.py
# 导入操作系统相关模块
import os
# 导入正则表达式模块
import re
# 导入时间模块
import time
# 从 dataclasses 模块导入 dataclass 装饰器
from dataclasses import dataclass
# 从 glob 模块导入 iglob 函数,用于文件名模式匹配
from glob import iglob# 导入 PyTorch 库
import torch
# 从 einops 模块导入 rearrange 函数,用于张量重排
from einops import rearrange
# 从 fire 模块导入 Fire 类,用于命令行接口
from fire import Fire
# 从 PIL 模块导入 ExifTags 和 Image,用于处理图片和元数据
from PIL import ExifTags, Image# 从 flux.sampling 模块导入采样相关函数
from flux.sampling import denoise, get_noise, get_schedule, prepare, unpack
# 从 flux.util 模块导入实用工具函数
from flux.util import (configs, embed_watermark, load_ae, load_clip,load_flow_model, load_t5)
# 从 transformers 模块导入 pipeline,用于加载预训练模型
from transformers import pipeline# 设置 NSFW(不适宜工作)内容的阈值
NSFW_THRESHOLD = 0.85# 定义一个数据类,用于存储采样选项
@dataclass
class SamplingOptions:# 用户提示文本prompt: str# 图像宽度width: int# 图像高度height: int# 生成图像的步骤数量num_steps: int# 引导强度guidance: float# 随机种子,可选seed: int | None# 解析用户输入的提示,并根据选项更新 SamplingOptions
def parse_prompt(options: SamplingOptions) -> SamplingOptions | None:# 提示用户输入下一个提示user_question = "Next prompt (write /h for help, /q to quit and leave empty to repeat):\n"# 使用说明文本usage = ("Usage: Either write your prompt directly, leave this field empty ""to repeat the prompt or write a command starting with a slash:\n""- '/w <width>' will set the width of the generated image\n""- '/h <height>' will set the height of the generated image\n""- '/s <seed>' sets the next seed\n""- '/g <guidance>' sets the guidance (flux-dev only)\n""- '/n <steps>' sets the number of steps\n""- '/q' to quit")# 循环读取用户输入,直到输入不以斜杠开头while (prompt := input(user_question)).startswith("/"):# 处理以 "/w" 开头的命令,设置宽度if prompt.startswith("/w"):# 如果命令中没有空格,提示无效命令并继续if prompt.count(" ") != 1:print(f"Got invalid command '{prompt}'\n{usage}")continue# 解析命令中的宽度值并设置为16的倍数_, width = prompt.split()options.width = 16 * (int(width) // 16)# 打印设置的宽度和高度,以及总像素数print(f"Setting resolution to {options.width} x {options.height} "f"({options.height *options.width/1e6:.2f}MP)")# 处理以 "/h" 开头的命令,设置高度elif prompt.startswith("/h"):# 如果命令中没有空格,提示无效命令并继续if prompt.count(" ") != 1:print(f"Got invalid command '{prompt}'\n{usage}")continue# 解析命令中的高度值并设置为16的倍数_, height = prompt.split()options.height = 16 * (int(height) // 16)# 打印设置的宽度和高度,以及总像素数print(f"Setting resolution to {options.width} x {options.height} "f"({options.height *options.width/1e6:.2f}MP)")# 处理以 "/g" 开头的命令,设置指导值elif prompt.startswith("/g"):# 如果命令中没有空格,提示无效命令并继续if prompt.count(" ") != 1:print(f"Got invalid command '{prompt}'\n{usage}")continue# 解析命令中的指导值_, guidance = prompt.split()options.guidance = float(guidance)# 打印设置的指导值print(f"Setting guidance to {options.guidance}")# 处理以 "/s" 开头的命令,设置种子值elif prompt.startswith("/s"):# 如果命令中没有空格,提示无效命令并继续if prompt.count(" ") != 1:print(f"Got invalid command '{prompt}'\n{usage}")continue# 解析命令中的种子值_, seed = prompt.split()options.seed = int(seed)# 打印设置的种子值print(f"Setting seed to {options.seed}")# 处理以 "/n" 开头的命令,设置步骤数elif prompt.startswith("/n"):# 如果命令中没有空格,提示无效命令并继续if prompt.count(" ") != 1:print(f"Got invalid command '{prompt}'\n{usage}")continue# 解析命令中的步骤数_, steps = prompt.split()options.num_steps = int(steps)# 打印设置的步骤数print(f"Setting seed to {options.num_steps}")# 处理以 "/q" 开头的命令,退出循环elif prompt.startswith("/q"):print("Quitting")return Noneelse:# 如果命令不以已知前缀开头,提示无效命令并显示用法if not prompt.startswith("/h"):print(f"Got invalid command '{prompt}'\n{usage}")print(usage)# 如果输入不为空,将其设置为提示if prompt != "":options.prompt = prompt# 返回更新后的选项对象return options
@torch.inference_mode()
def main(name: str = "flux-schnell",width: int = 1360,height: int = 768,seed: int | None = None,prompt: str = ("a photo of a forest with mist swirling around the tree trunks. The word "'"FLUX" is painted over it in big, red brush strokes with visible texture'),device: str = "cuda" if torch.cuda.is_available() else "cpu",num_steps: int | None = None,loop: bool = False,guidance: float = 3.5,offload: bool = False,output_dir: str = "output",add_sampling_metadata: bool = True,
):"""Sample the flux model. Either interactively (set `--loop`) or run for asingle image.Args:name: Name of the model to loadheight: height of the sample in pixels (should be a multiple of 16)width: width of the sample in pixels (should be a multiple of 16)seed: Set a seed for samplingoutput_name: where to save the output image, `{idx}` will be replacedby the index of the sampleprompt: Prompt used for samplingdevice: Pytorch devicenum_steps: number of sampling steps (default 4 for schnell, 50 for guidance distilled)loop: start an interactive session and sample multiple timesguidance: guidance value used for guidance distillationadd_sampling_metadata: Add the prompt to the image Exif metadata"""# Initialize an NSFW image classification pipeline with the specified model and devicensfw_classifier = pipeline("image-classification", model="Falconsai/nsfw_image_detection", device=device)# Check if the specified model name is validif name not in configs:available = ", ".join(configs.keys())raise ValueError(f"Got unknown model name: {name}, chose from {available}")# Set the PyTorch device based on the provided device stringtorch_device = torch.device(device)# Determine the number of sampling steps based on the model nameif num_steps is None:num_steps = 4 if name == "flux-schnell" else 50# Adjust height and width to be multiples of 16 for compatibilityheight = 16 * (height // 16)width = 16 * (width // 16)# Construct the output file path and handle directory and index managementoutput_name = os.path.join(output_dir, "img_{idx}.jpg")if not os.path.exists(output_dir):os.makedirs(output_dir)idx = 0else:fns = [fn for fn in iglob(output_name.format(idx="*")) if re.search(r"img_[0-9]+\.jpg$", fn)]if len(fns) > 0:idx = max(int(fn.split("_")[-1].split(".")[0]) for fn in fns) + 1else:idx = 0# Initialize components for the sampling processt5 = load_t5(torch_device, max_length=256 if name == "flux-schnell" else 512)clip = load_clip(torch_device)model = load_flow_model(name, device="cpu" if offload else torch_device)ae = load_ae(name, device="cpu" if offload else torch_device)# Create a random number generator and sampling optionsrng = torch.Generator(device="cpu")opts = SamplingOptions(prompt=prompt,width=width,height=height,num_steps=num_steps,guidance=guidance,seed=seed,)# If loop mode is enabled, adjust the options based on the promptif loop:opts = parse_prompt(opts)# 当 opts 不为 None 时持续循环while opts is not None:# 如果 opts 中没有种子,则生成一个新的种子if opts.seed is None:opts.seed = rng.seed()# 打印生成过程的种子和提示print(f"Generating with seed {opts.seed}:\n{opts.prompt}")# 记录当前时间以计算生成时间t0 = time.perf_counter()# 准备输入噪声数据x = get_noise(1,opts.height,opts.width,device=torch_device,dtype=torch.bfloat16,seed=opts.seed,)# 将种子置为 None 以防止重复使用opts.seed = None# 如果需要将模型移至 CPU,清理 CUDA 缓存,并将模型移动到指定设备if offload:ae = ae.cpu()torch.cuda.empty_cache()t5, clip = t5.to(torch_device), clip.to(torch_device)# 准备输入数据,包括将 T5 和 CLIP 模型的输出、噪声以及提示整理成输入inp = prepare(t5, clip, x, prompt=opts.prompt)# 获取时间步的调度timesteps = get_schedule(opts.num_steps, inp["img"].shape[1], shift=(name != "flux-schnell"))# 如果需要将模型移至 CPU,清理 CUDA 缓存,并将模型移动到 GPUif offload:t5, clip = t5.cpu(), clip.cpu()torch.cuda.empty_cache()model = model.to(torch_device)# 对初始噪声进行去噪处理x = denoise(model, **inp, timesteps=timesteps, guidance=opts.guidance)# 如果需要将模型移至 CPU,清理 CUDA 缓存,并将自动编码器的解码器移至当前设备if offload:model.cpu()torch.cuda.empty_cache()ae.decoder.to(x.device)# 将潜在变量解码到像素空间x = unpack(x.float(), opts.height, opts.width)with torch.autocast(device_type=torch_device.type, dtype=torch.bfloat16):x = ae.decode(x)# 记录解码处理时间t1 = time.perf_counter()# 格式化输出文件名fn = output_name.format(idx=idx)print(f"Done in {t1 - t0:.1f}s. Saving {fn}")# 将图像数据带入 PIL 格式并保存x = x.clamp(-1, 1)x = embed_watermark(x.float())x = rearrange(x[0], "c h w -> h w c")# 从 numpy 数组创建 PIL 图像对象img = Image.fromarray((127.5 * (x + 1.0)).cpu().byte().numpy())# 进行 NSFW 内容检测nsfw_score = [x["score"] for x in nsfw_classifier(img) if x["label"] == "nsfw"][0]# 如果 NSFW 分数低于阈值,则保存图像及其 EXIF 元数据if nsfw_score < NSFW_THRESHOLD:exif_data = Image.Exif()exif_data[ExifTags.Base.Software] = "AI generated;txt2img;flux"exif_data[ExifTags.Base.Make] = "Black Forest Labs"exif_data[ExifTags.Base.Model] = nameif add_sampling_metadata:exif_data[ExifTags.Base.ImageDescription] = promptimg.save(fn, exif=exif_data, quality=95, subsampling=0)# 增加图像索引idx += 1else:print("Your generated image may contain NSFW content.")# 如果设置了循环,则解析新的提示并继续,否则退出循环if loop:print("-" * 80)opts = parse_prompt(opts)else:opts = None
# 定义主函数
def app():# 使用 Fire 库将 main 函数作为命令行接口Fire(main)# 检查是否为主模块运行
if __name__ == "__main__":# 调用 app 函数app()
.\flux\src\flux\math.py
# 导入 PyTorch 库和 einops 的 rearrange 函数
import torch
from einops import rearrange
from torch import Tensor# 注意力机制函数
def attention(q: Tensor, k: Tensor, v: Tensor, pe: Tensor) -> Tensor:# 对 q 和 k 应用相对位置编码q, k = apply_rope(q, k, pe)# 使用缩放点积注意力计算输出x = torch.nn.functional.scaled_dot_product_attention(q, k, v)# 重新排列输出张量的维度x = rearrange(x, "B H L D -> B L (H D)")# 返回处理后的张量return x# 相对位置编码函数
def rope(pos: Tensor, dim: int, theta: int) -> Tensor:# 确保维度是偶数assert dim % 2 == 0# 计算尺度因子scale = torch.arange(0, dim, 2, dtype=torch.float64, device=pos.device) / dim# 计算 omega 值omega = 1.0 / (theta**scale)# 通过爱因斯坦求和计算输出out = torch.einsum("...n,d->...nd", pos, omega)# 创建旋转矩阵out = torch.stack([torch.cos(out), -torch.sin(out), torch.sin(out), torch.cos(out)], dim=-1)# 重新排列旋转矩阵的维度out = rearrange(out, "b n d (i j) -> b n d i j", i=2, j=2)# 转换为 float 类型并返回return out.float()# 应用相对位置编码的辅助函数
def apply_rope(xq: Tensor, xk: Tensor, freqs_cis: Tensor) -> tuple[Tensor, Tensor]:# 重新排列 q 和 k 的维度并转换为 float 类型xq_ = xq.float().reshape(*xq.shape[:-1], -1, 1, 2)xk_ = xk.float().reshape(*xk.shape[:-1], -1, 1, 2)# 计算 q 和 k 的编码输出xq_out = freqs_cis[..., 0] * xq_[..., 0] + freqs_cis[..., 1] * xq_[..., 1]xk_out = freqs_cis[..., 0] * xk_[..., 0] + freqs_cis[..., 1] * xk_[..., 1]# 恢复原始维度并返回return xq_out.reshape(*xq.shape).type_as(xq), xk_out.reshape(*xk.shape).type_as(xk)
.\flux\src\flux\model.py
# 从 dataclasses 模块导入 dataclass 装饰器
from dataclasses import dataclass# 导入 PyTorch 和相关模块
import torch
from torch import Tensor, nn# 从 flux.modules.layers 模块导入特定的类
from flux.modules.layers import (DoubleStreamBlock, EmbedND, LastLayer,MLPEmbedder, SingleStreamBlock,timestep_embedding)# 定义包含模型参数的类
@dataclass
class FluxParams:# 输入通道数in_channels: int# 输入向量维度vec_in_dim: int# 上下文输入维度context_in_dim: int# 隐藏层大小hidden_size: int# MLP 比例mlp_ratio: float# 头数num_heads: int# 网络深度depth: int# 单流块的深度depth_single_blocks: int# 轴维度列表axes_dim: list[int]# theta 参数theta: int# 是否使用 QKV 偏置qkv_bias: bool# 是否使用引导嵌入guidance_embed: bool# 定义 Flux 模型类
class Flux(nn.Module):"""Transformer 模型用于序列上的流匹配。"""# 初始化方法def __init__(self, params: FluxParams):super().__init__()# 保存参数self.params = params# 输入通道数self.in_channels = params.in_channels# 输出通道数与输入通道数相同self.out_channels = self.in_channels# 确保隐藏层大小可以被头数整除if params.hidden_size % params.num_heads != 0:raise ValueError(f"Hidden size {params.hidden_size} must be divisible by num_heads {params.num_heads}")# 计算位置编码维度pe_dim = params.hidden_size // params.num_heads# 确保轴维度总和与位置编码维度匹配if sum(params.axes_dim) != pe_dim:raise ValueError(f"Got {params.axes_dim} but expected positional dim {pe_dim}")# 隐藏层大小self.hidden_size = params.hidden_size# 头数self.num_heads = params.num_heads# 初始化位置嵌入层self.pe_embedder = EmbedND(dim=pe_dim, theta=params.theta, axes_dim=params.axes_dim)# 初始化图像输入线性层self.img_in = nn.Linear(self.in_channels, self.hidden_size, bias=True)# 初始化时间嵌入层self.time_in = MLPEmbedder(in_dim=256, hidden_dim=self.hidden_size)# 初始化向量嵌入层self.vector_in = MLPEmbedder(params.vec_in_dim, self.hidden_size)# 初始化引导嵌入层(如果需要的话)self.guidance_in = (MLPEmbedder(in_dim=256, hidden_dim=self.hidden_size) if params.guidance_embed else nn.Identity())# 初始化文本输入线性层self.txt_in = nn.Linear(params.context_in_dim, self.hidden_size)# 创建双流块的模块列表self.double_blocks = nn.ModuleList([DoubleStreamBlock(self.hidden_size,self.num_heads,mlp_ratio=params.mlp_ratio,qkv_bias=params.qkv_bias,)for _ in range(params.depth)])# 创建单流块的模块列表self.single_blocks = nn.ModuleList([SingleStreamBlock(self.hidden_size, self.num_heads, mlp_ratio=params.mlp_ratio)for _ in range(params.depth_single_blocks)])# 初始化最终层self.final_layer = LastLayer(self.hidden_size, 1, self.out_channels)# 前向传播方法def forward(self,img: Tensor,img_ids: Tensor,txt: Tensor,txt_ids: Tensor,timesteps: Tensor,y: Tensor,guidance: Tensor | None = None,) -> Tensor: # 定义返回类型为 Tensor 的函数# 检查 img 和 txt 张量是否都具有 3 个维度if img.ndim != 3 or txt.ndim != 3:raise ValueError("Input img and txt tensors must have 3 dimensions.")# 对输入的 img 张量进行初步处理img = self.img_in(img)# 计算时间步嵌入向量,并通过 self.time_in 处理vec = self.time_in(timestep_embedding(timesteps, 256))# 如果启用了指导嵌入,则处理指导嵌入if self.params.guidance_embed:if guidance is None:raise ValueError("Didn't get guidance strength for guidance distilled model.")# 将指导嵌入向量添加到 vec 中vec = vec + self.guidance_in(timestep_embedding(guidance, 256))# 将其他向量添加到 vec 中vec = vec + self.vector_in(y)# 对 txt 张量进行处理txt = self.txt_in(txt)# 将 txt_ids 和 img_ids 按维度 1 拼接ids = torch.cat((txt_ids, img_ids), dim=1)# 计算位置编码pe = self.pe_embedder(ids)# 对 double_blocks 中的每个块进行处理for block in self.double_blocks:img, txt = block(img=img, txt=txt, vec=vec, pe=pe)# 将 txt 和 img 张量按维度 1 拼接img = torch.cat((txt, img), 1)# 对 single_blocks 中的每个块进行处理for block in self.single_blocks:img = block(img, vec=vec, pe=pe)# 截取 img 张量,去掉前面的 txt 部分img = img[:, txt.shape[1] :, ...]# 最终处理 img 张量,返回结果img = self.final_layer(img, vec) # (N, T, patch_size ** 2 * out_channels)return img
.\flux\src\flux\modules\autoencoder.py
# 从 dataclasses 模块导入 dataclass 装饰器
from dataclasses import dataclass# 导入 PyTorch 库
import torch
# 从 einops 模块导入 rearrange 函数
from einops import rearrange
# 从 torch 库导入 Tensor 和 nn 模块
from torch import Tensor, nn# 定义 AutoEncoder 的参数数据类
@dataclass
class AutoEncoderParams:resolution: int # 图像分辨率in_channels: int # 输入通道数ch: int # 基本通道数out_ch: int # 输出通道数ch_mult: list[int] # 通道数的增减比例num_res_blocks: int # 残差块数量z_channels: int # 潜在通道数scale_factor: float # 缩放因子shift_factor: float # 偏移因子# 定义 swish 激活函数
def swish(x: Tensor) -> Tensor:# 使用 sigmoid 函数调节 x 的激活值return x * torch.sigmoid(x)# 定义注意力块类
class AttnBlock(nn.Module):def __init__(self, in_channels: int):super().__init__()self.in_channels = in_channels# 初始化归一化层self.norm = nn.GroupNorm(num_groups=32, num_channels=in_channels, eps=1e-6, affine=True)# 初始化用于计算注意力的卷积层self.q = nn.Conv2d(in_channels, in_channels, kernel_size=1)self.k = nn.Conv2d(in_channels, in_channels, kernel_size=1)self.v = nn.Conv2d(in_channels, in_channels, kernel_size=1)self.proj_out = nn.Conv2d(in_channels, in_channels, kernel_size=1)# 注意力机制函数def attention(self, h_: Tensor) -> Tensor:# 归一化输入h_ = self.norm(h_)# 计算 q, k, vq = self.q(h_)k = self.k(h_)v = self.v(h_)# 获取 q, k, v 的维度b, c, h, w = q.shape# 重排列 q, k, vq = rearrange(q, "b c h w -> b 1 (h w) c").contiguous()k = rearrange(k, "b c h w -> b 1 (h w) c").contiguous()v = rearrange(v, "b c h w -> b 1 (h w) c").contiguous()# 应用缩放点积注意力h_ = nn.functional.scaled_dot_product_attention(q, k, v)# 将输出重排列为原始维度return rearrange(h_, "b 1 (h w) c -> b c h w", h=h, w=w, c=c, b=b)# 前向传播函数def forward(self, x: Tensor) -> Tensor:# 添加注意力机制后的输出到原始输入return x + self.proj_out(self.attention(x))# 定义残差块类
class ResnetBlock(nn.Module):def __init__(self, in_channels: int, out_channels: int):super().__init__()self.in_channels = in_channelsout_channels = in_channels if out_channels is None else out_channelsself.out_channels = out_channels# 初始化归一化层和卷积层self.norm1 = nn.GroupNorm(num_groups=32, num_channels=in_channels, eps=1e-6, affine=True)self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=1, padding=1)self.norm2 = nn.GroupNorm(num_groups=32, num_channels=out_channels, eps=1e-6, affine=True)self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=1, padding=1)# 如果输入和输出通道数不同,初始化快捷连接if self.in_channels != self.out_channels:self.nin_shortcut = nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=1, padding=0)# 前向传播函数def forward(self, x):h = x# 通过第一层归一化、激活和卷积h = self.norm1(h)h = swish(h)h = self.conv1(h)# 通过第二层归一化、激活和卷积h = self.norm2(h)h = swish(h)h = self.conv2(h)# 如果输入和输出通道数不同,应用快捷连接if self.in_channels != self.out_channels:x = self.nin_shortcut(x)# 返回残差连接的结果return x + h# 定义下采样类
class Downsample(nn.Module):def __init__(self, in_channels: int):super().__init__()# 在 torch conv 中没有非对称填充,必须手动处理self.conv = nn.Conv2d(in_channels, in_channels, kernel_size=3, stride=2, padding=0)# 前向传播函数,接受一个 Tensor 作为输入def forward(self, x: Tensor):# 定义 padding 的大小,分别是右边 1、下边 1pad = (0, 1, 0, 1)# 对输入 Tensor 进行 padding,填充值为 0x = nn.functional.pad(x, pad, mode="constant", value=0)# 将 padding 过的 Tensor 通过卷积层x = self.conv(x)# 返回卷积后的结果return x
# 定义上采样模块,继承自 nn.Module
class Upsample(nn.Module):def __init__(self, in_channels: int):super().__init__()# 创建卷积层,用于对输入特征图进行卷积操作self.conv = nn.Conv2d(in_channels, in_channels, kernel_size=3, stride=1, padding=1)def forward(self, x: Tensor):# 对输入特征图进行双线性插值上采样,扩大尺寸为原来的2倍x = nn.functional.interpolate(x, scale_factor=2.0, mode="nearest")# 对上采样后的特征图应用卷积层x = self.conv(x)# 返回处理后的特征图return x# 定义编码器模块,继承自 nn.Module
class Encoder(nn.Module):def __init__(self,resolution: int,in_channels: int,ch: int,ch_mult: list[int],num_res_blocks: int,z_channels: int,):super().__init__()self.ch = chself.num_resolutions = len(ch_mult)self.num_res_blocks = num_res_blocksself.resolution = resolutionself.in_channels = in_channels# 输入层卷积,用于初始化特征图self.conv_in = nn.Conv2d(in_channels, self.ch, kernel_size=3, stride=1, padding=1)curr_res = resolutionin_ch_mult = (1,) + tuple(ch_mult)self.in_ch_mult = in_ch_multself.down = nn.ModuleList()block_in = self.chfor i_level in range(self.num_resolutions):block = nn.ModuleList()attn = nn.ModuleList()# 设置每层的输入和输出通道数block_in = ch * in_ch_mult[i_level]block_out = ch * ch_mult[i_level]for _ in range(self.num_res_blocks):# 添加残差块到当前层block.append(ResnetBlock(in_channels=block_in, out_channels=block_out))block_in = block_outdown = nn.Module()down.block = blockdown.attn = attnif i_level != self.num_resolutions - 1:# 添加下采样层down.downsample = Downsample(block_in)curr_res = curr_res // 2self.down.append(down)# 中间层,包括两个残差块和一个注意力块self.mid = nn.Module()self.mid.block_1 = ResnetBlock(in_channels=block_in, out_channels=block_in)self.mid.attn_1 = AttnBlock(block_in)self.mid.block_2 = ResnetBlock(in_channels=block_in, out_channels=block_in)# 输出层,包括归一化和卷积层self.norm_out = nn.GroupNorm(num_groups=32, num_channels=block_in, eps=1e-6, affine=True)self.conv_out = nn.Conv2d(block_in, 2 * z_channels, kernel_size=3, stride=1, padding=1)def forward(self, x: Tensor) -> Tensor:# 对输入特征图进行下采样hs = [self.conv_in(x)]for i_level in range(self.num_resolutions):for i_block in range(self.num_res_blocks):h = self.down[i_level].block[i_block](hs[-1])if len(self.down[i_level].attn) > 0:h = self.down[i_level].attn[i_block](h)hs.append(h)if i_level != self.num_resolutions - 1:hs.append(self.down[i_level].downsample(hs[-1]))# 中间处理h = hs[-1]h = self.mid.block_1(h)h = self.mid.attn_1(h)h = self.mid.block_2(h)# 输出处理h = self.norm_out(h)h = swish(h)h = self.conv_out(h)# 返回最终处理后的特征图return h# 定义解码器模块,继承自 nn.Module
class Decoder(nn.Module):def __init__(self,ch: int,out_ch: int,ch_mult: list[int],num_res_blocks: int,in_channels: int,resolution: int,z_channels: int,):# 调用父类的初始化方法super().__init__()# 保存输入通道数self.ch = ch# 保存多分辨率通道数的数量self.num_resolutions = len(ch_mult)# 保存残差块的数量self.num_res_blocks = num_res_blocks# 保存图像分辨率self.resolution = resolution# 保存输入通道数self.in_channels = in_channels# 计算最终分辨率的缩放因子self.ffactor = 2 ** (self.num_resolutions - 1)# 计算最低分辨率下的输入通道数和分辨率block_in = ch * ch_mult[self.num_resolutions - 1]curr_res = resolution // 2 ** (self.num_resolutions - 1)# 定义潜在变量 z 的形状self.z_shape = (1, z_channels, curr_res, curr_res)# z 到 block_in 的卷积层self.conv_in = nn.Conv2d(z_channels, block_in, kernel_size=3, stride=1, padding=1)# 中间层模块self.mid = nn.Module()self.mid.block_1 = ResnetBlock(in_channels=block_in, out_channels=block_in)self.mid.attn_1 = AttnBlock(block_in)self.mid.block_2 = ResnetBlock(in_channels=block_in, out_channels=block_in)# 上采样模块self.up = nn.ModuleList()for i_level in reversed(range(self.num_resolutions)):block = nn.ModuleList()attn = nn.ModuleList()# 当前分辨率下的输出通道数block_out = ch * ch_mult[i_level]for _ in range(self.num_res_blocks + 1):# 添加残差块block.append(ResnetBlock(in_channels=block_in, out_channels=block_out))block_in = block_outup = nn.Module()up.block = blockup.attn = attnif i_level != 0:# 添加上采样层up.upsample = Upsample(block_in)curr_res = curr_res * 2# 将上采样模块插入列表开头,保持顺序一致self.up.insert(0, up)# 输出归一化层self.norm_out = nn.GroupNorm(num_groups=32, num_channels=block_in, eps=1e-6, affine=True)# 输出卷积层self.conv_out = nn.Conv2d(block_in, out_ch, kernel_size=3, stride=1, padding=1)def forward(self, z: Tensor) -> Tensor:# 将 z 传入 conv_in 层h = self.conv_in(z)# 通过中间层h = self.mid.block_1(h)h = self.mid.attn_1(h)h = self.mid.block_2(h)# 上采样过程for i_level in reversed(range(self.num_resolutions)):for i_block in range(self.num_res_blocks + 1):h = self.up[i_level].block[i_block](h)if len(self.up[i_level].attn) > 0:h = self.up[i_level].attn[i_block](h)if i_level != 0:# 上采样h = self.up[i_level].upsample(h)# 结束层h = self.norm_out(h)h = swish(h)h = self.conv_out(h)# 返回最终输出return h
# 定义对角高斯分布的神经网络模块
class DiagonalGaussian(nn.Module):# 初始化方法,定义是否采样及分块维度def __init__(self, sample: bool = True, chunk_dim: int = 1):super().__init__()# 是否进行采样self.sample = sample# 进行分块操作的维度self.chunk_dim = chunk_dim# 前向传播方法def forward(self, z: Tensor) -> Tensor:# 将输入张量 z 按指定维度 chunk_dim 划分为两个张量 mean 和 logvarmean, logvar = torch.chunk(z, 2, dim=self.chunk_dim)if self.sample:# 如果需要采样,计算标准差并从标准正态分布中生成随机样本std = torch.exp(0.5 * logvar)return mean + std * torch.randn_like(mean)else:# 否则只返回均值return mean# 定义自编码器的神经网络模块
class AutoEncoder(nn.Module):# 初始化方法,定义编码器、解码器及高斯分布def __init__(self, params: AutoEncoderParams):super().__init__()# 创建编码器实例,传入相应参数self.encoder = Encoder(resolution=params.resolution,in_channels=params.in_channels,ch=params.ch,ch_mult=params.ch_mult,num_res_blocks=params.num_res_blocks,z_channels=params.z_channels,)# 创建解码器实例,传入相应参数self.decoder = Decoder(resolution=params.resolution,in_channels=params.in_channels,ch=params.ch,out_ch=params.out_ch,ch_mult=params.ch_mult,num_res_blocks=params.num_res_blocks,z_channels=params.z_channels,)# 创建对角高斯分布实例self.reg = DiagonalGaussian()# 设置缩放因子和偏移因子self.scale_factor = params.scale_factorself.shift_factor = params.shift_factor# 编码方法,将输入 x 进行编码并调整缩放和偏移def encode(self, x: Tensor) -> Tensor:# 通过编码器获取 z,随后通过对角高斯分布进行处理z = self.reg(self.encoder(x))# 对 z 进行缩放和偏移z = self.scale_factor * (z - self.shift_factor)return z# 解码方法,将 z 解码为输出def decode(self, z: Tensor) -> Tensor:# 对 z 进行逆操作,恢复到编码前的尺度z = z / self.scale_factor + self.shift_factor# 使用解码器进行解码return self.decoder(z)# 前向传播方法,执行编码和解码def forward(self, x: Tensor) -> Tensor:# 先编码再解码return self.decode(self.encode(x))
.\flux\src\flux\modules\conditioner.py
# 从 PyTorch 和 Transformers 库导入必要的模块
from torch import Tensor, nn
from transformers import (CLIPTextModel, CLIPTokenizer, T5EncoderModel,T5Tokenizer)# 定义一个用于获取文本嵌入的类 HFEmbedder,继承自 nn.Module
class HFEmbedder(nn.Module):# 初始化方法def __init__(self, version: str, max_length: int, **hf_kwargs):# 调用父类的初始化方法super().__init__()# 判断是否使用 CLIP 模型,根据版本名进行判断self.is_clip = version.startswith("openai")# 设置最大长度self.max_length = max_length# 根据是否使用 CLIP 模型选择输出的键self.output_key = "pooler_output" if self.is_clip else "last_hidden_state"# 如果使用 CLIP 模型if self.is_clip:# 从预训练模型加载 tokenizerself.tokenizer: CLIPTokenizer = CLIPTokenizer.from_pretrained(version, max_length=max_length)# 从预训练模型加载 HF 模块self.hf_module: CLIPTextModel = CLIPTextModel.from_pretrained(version, **hf_kwargs)else:# 如果使用 T5 模型# 从预训练模型加载 tokenizerself.tokenizer: T5Tokenizer = T5Tokenizer.from_pretrained(version, max_length=max_length)# 从预训练模型加载 HF 模块self.hf_module: T5EncoderModel = T5EncoderModel.from_pretrained(version, **hf_kwargs)# 将模型设置为评估模式,并且不计算梯度self.hf_module = self.hf_module.eval().requires_grad_(False)# 前向传播方法,处理输入文本并返回嵌入def forward(self, text: list[str]) -> Tensor:# 使用 tokenizer 对文本进行编码batch_encoding = self.tokenizer(text,truncation=True, # 对超长文本进行截断max_length=self.max_length, # 设置最大长度return_length=False, # 不返回文本长度return_overflowing_tokens=False, # 不返回溢出的标记padding="max_length", # 填充到最大长度return_tensors="pt", # 返回 PyTorch 张量)# 使用 HF 模块进行前向传播计算outputs = self.hf_module(input_ids=batch_encoding["input_ids"].to(self.hf_module.device), # 将输入 ID 移动到模型所在设备attention_mask=None, # 不使用注意力掩码output_hidden_states=False, # 不返回隐藏状态)# 返回指定键对应的输出return outputs[self.output_key]
.\flux\src\flux\modules\layers.py
# 导入数学库
import math
# 从 dataclasses 模块导入 dataclass 装饰器
from dataclasses import dataclass# 导入 PyTorch 库
import torch
# 从 einops 库导入 rearrange 函数
from einops import rearrange
# 从 torch 库导入 Tensor 和 nn 模块
from torch import Tensor, nn# 从 flux.math 模块导入 attention 和 rope 函数
from flux.math import attention, rope# 定义一个嵌入类,用于处理 N 维数据
class EmbedND(nn.Module):def __init__(self, dim: int, theta: int, axes_dim: list[int]):super().__init__()# 初始化维度、角度和轴维度self.dim = dimself.theta = thetaself.axes_dim = axes_dimdef forward(self, ids: Tensor) -> Tensor:# 获取输入 Tensor 的最后一维大小n_axes = ids.shape[-1]# 对每个轴应用 rope 函数并在-3维上连接emb = torch.cat([rope(ids[..., i], self.axes_dim[i], self.theta) for i in range(n_axes)],dim=-3,)# 在第1维上增加一个维度return emb.unsqueeze(1)# 定义时间步嵌入函数,创建正弦时间步嵌入
def timestep_embedding(t: Tensor, dim, max_period=10000, time_factor: float = 1000.0):"""创建正弦时间步嵌入。:param t: 一维 Tensor,包含每批次元素的索引,可以是小数。:param dim: 输出的维度。:param max_period: 控制嵌入的最小频率。:return: 一个 (N, D) 维的 Tensor,表示位置嵌入。"""# 根据时间因子缩放输入 Tensort = time_factor * t# 计算半维度half = dim // 2# 计算频率freqs = torch.exp(-math.log(max_period) * torch.arange(start=0, end=half, dtype=torch.float32) / half).to(t.device)# 计算嵌入args = t[:, None].float() * freqs[None]embedding = torch.cat([torch.cos(args), torch.sin(args)], dim=-1)# 如果维度是奇数,追加零向量if dim % 2:embedding = torch.cat([embedding, torch.zeros_like(embedding[:, :1])], dim=-1)# 如果 t 是浮点类型,将嵌入转换为 t 的类型if torch.is_floating_point(t):embedding = embedding.to(t)return embedding# 定义一个 MLP 嵌入器类
class MLPEmbedder(nn.Module):def __init__(self, in_dim: int, hidden_dim: int):super().__init__()# 初始化输入层、激活函数和输出层self.in_layer = nn.Linear(in_dim, hidden_dim, bias=True)self.silu = nn.SiLU()self.out_layer = nn.Linear(hidden_dim, hidden_dim, bias=True)def forward(self, x: Tensor) -> Tensor:# 执行前向传递,经过输入层、激活函数和输出层return self.out_layer(self.silu(self.in_layer(x)))# 定义 RMSNorm 类
class RMSNorm(torch.nn.Module):def __init__(self, dim: int):super().__init__()# 初始化尺度参数self.scale = nn.Parameter(torch.ones(dim))def forward(self, x: Tensor):# 将输入转换为浮点数x_dtype = x.dtypex = x.float()# 计算均方根归一化rrms = torch.rsqrt(torch.mean(x**2, dim=-1, keepdim=True) + 1e-6)# 应用归一化和尺度参数return (x * rrms).to(dtype=x_dtype) * self.scale# 定义 QKNorm 类
class QKNorm(torch.nn.Module):def __init__(self, dim: int):super().__init__()# 初始化查询和键的归一化self.query_norm = RMSNorm(dim)self.key_norm = RMSNorm(dim)def forward(self, q: Tensor, k: Tensor, v: Tensor) -> tuple[Tensor, Tensor]:# 对查询和键进行归一化q = self.query_norm(q)k = self.key_norm(k)# 返回归一化后的查询、键以及原始值return q.to(v), k.to(v)# 定义自注意力机制类
class SelfAttention(nn.Module):def __init__(self, dim: int, num_heads: int = 8, qkv_bias: bool = False):super().__init__()# 设置头的数量和每个头的维度self.num_heads = num_headshead_dim = dim // num_heads# 初始化查询、键、值线性变换层self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)# 初始化归一化层self.norm = QKNorm(head_dim)# 初始化投影层self.proj = nn.Linear(dim, dim)# 前向传播函数,接受输入张量和位置编码,返回处理后的张量def forward(self, x: Tensor, pe: Tensor) -> Tensor:# 将输入张量通过 qkv 层,生成查询、键、值的联合表示qkv = self.qkv(x)# 重新排列 qkv 张量,将其拆分成查询 (q)、键 (k)、值 (v),并根据头数 (num_heads) 分组q, k, v = rearrange(qkv, "B L (K H D) -> K B H L D", K=3, H=self.num_heads)# 对查询、键和值进行归一化处理q, k = self.norm(q, k, v)# 计算注意力权重并应用于值,得到加权后的输出x = attention(q, k, v, pe=pe)# 通过 proj 层将注意力结果映射到输出空间x = self.proj(x)# 返回最终的输出张量return x
# 定义一个包含三个张量的结构体 ModulationOut
@dataclass
class ModulationOut:shift: Tensorscale: Tensorgate: Tensor# 定义一个继承自 nn.Module 的 Modulation 类
class Modulation(nn.Module):# 初始化方法,设置维度和是否双倍def __init__(self, dim: int, double: bool):super().__init__()self.is_double = double # 存储是否为双倍标志self.multiplier = 6 if double else 3 # 根据标志设置 multiplierself.lin = nn.Linear(dim, self.multiplier * dim, bias=True) # 定义线性层# 前向传播方法,处理输入张量并返回结果def forward(self, vec: Tensor) -> tuple[ModulationOut, ModulationOut | None]:# 应用激活函数后,进行线性变换,并将结果按 multiplier 切分out = self.lin(nn.functional.silu(vec))[:, None, :].chunk(self.multiplier, dim=-1)# 返回切分后的结果,前半部分和后半部分(如果是双倍)return (ModulationOut(*out[:3]), # 前三部分ModulationOut(*out[3:]) if self.is_double else None, # 后三部分(如果是双倍))# 定义一个继承自 nn.Module 的 DoubleStreamBlock 类
class DoubleStreamBlock(nn.Module):# 初始化方法,设置隐藏层大小、注意力头数、MLP 比例等def __init__(self, hidden_size: int, num_heads: int, mlp_ratio: float, qkv_bias: bool = False):super().__init__()mlp_hidden_dim = int(hidden_size * mlp_ratio) # 计算 MLP 隐藏层维度self.num_heads = num_heads # 存储注意力头数self.hidden_size = hidden_size # 存储隐藏层大小self.img_mod = Modulation(hidden_size, double=True) # 定义图像模调模块self.img_norm1 = nn.LayerNorm(hidden_size, elementwise_affine=False, eps=1e-6) # 定义图像的第一层归一化self.img_attn = SelfAttention(dim=hidden_size, num_heads=num_heads, qkv_bias=qkv_bias) # 定义图像的自注意力模块self.img_norm2 = nn.LayerNorm(hidden_size, elementwise_affine=False, eps=1e-6) # 定义图像的第二层归一化self.img_mlp = nn.Sequential( # 定义图像的 MLP 网络nn.Linear(hidden_size, mlp_hidden_dim, bias=True), # 第一层线性变换nn.GELU(approximate="tanh"), # 激活函数nn.Linear(mlp_hidden_dim, hidden_size, bias=True), # 第二层线性变换)self.txt_mod = Modulation(hidden_size, double=True) # 定义文本模调模块self.txt_norm1 = nn.LayerNorm(hidden_size, elementwise_affine=False, eps=1e-6) # 定义文本的第一层归一化self.txt_attn = SelfAttention(dim=hidden_size, num_heads=num_heads, qkv_bias=qkv_bias) # 定义文本的自注意力模块self.txt_norm2 = nn.LayerNorm(hidden_size, elementwise_affine=False, eps=1e-6) # 定义文本的第二层归一化self.txt_mlp = nn.Sequential( # 定义文本的 MLP 网络nn.Linear(hidden_size, mlp_hidden_dim, bias=True), # 第一层线性变换nn.GELU(approximate="tanh"), # 激活函数nn.Linear(mlp_hidden_dim, hidden_size, bias=True), # 第二层线性变换)# 前向传播函数,处理图像和文本输入,返回更新后的图像和文本def forward(self, img: Tensor
# 定义一个 DiT 模块,其中包含并行的线性层以及调整的调制接口
class SingleStreamBlock(nn.Module):"""A DiT block with parallel linear layers as described inhttps://arxiv.org/abs/2302.05442 and adapted modulation interface."""def __init__(self,hidden_size: int,num_heads: int,mlp_ratio: float = 4.0,qk_scale: float | None = None,):super().__init__()# 初始化隐藏层维度和注意力头的数量self.hidden_dim = hidden_sizeself.num_heads = num_headshead_dim = hidden_size // num_heads# 计算缩放因子self.scale = qk_scale or head_dim**-0.5# 计算 MLP 层的隐藏维度self.mlp_hidden_dim = int(hidden_size * mlp_ratio)# 定义用于 QKV 和 MLP 输入的线性层self.linear1 = nn.Linear(hidden_size, hidden_size * 3 + self.mlp_hidden_dim)# 定义用于投影和 MLP 输出的线性层self.linear2 = nn.Linear(hidden_size + self.mlp_hidden_dim, hidden_size)# 定义归一化层self.norm = QKNorm(head_dim)# 定义层归一化层self.hidden_size = hidden_sizeself.pre_norm = nn.LayerNorm(hidden_size, elementwise_affine=False, eps=1e-6)# 定义激活函数和调制层self.mlp_act = nn.GELU(approximate="tanh")self.modulation = Modulation(hidden_size, double=False)def forward(self, x: Tensor, vec: Tensor, pe: Tensor) -> Tensor:# 通过调制层计算调制因子mod, _ = self.modulation(vec)# 对输入进行预归一化并应用调制x_mod = (1 + mod.scale) * self.pre_norm(x) + mod.shift# 将线性层的输出分割为 QKV 和 MLP 输入qkv, mlp = torch.split(self.linear1(x_mod), [3 * self.hidden_size, self.mlp_hidden_dim], dim=-1)# 重新排列 QKV 张量,并进行归一化q, k, v = rearrange(qkv, "B L (K H D) -> K B H L D", K=3, H=self.num_heads)q, k = self.norm(q, k, v)# 计算注意力attn = attention(q, k, v, pe=pe)# 计算 MLP 流中的激活,拼接结果并通过第二个线性层output = self.linear2(torch.cat((attn, self.mlp_act(mlp)), 2))# 将原始输入与输出加权和相加return x + mod.gate * output# 定义最后一层的网络模块
class LastLayer(nn.Module):def __init__(self, hidden_size: int, patch_size: int, out_channels: int):super().__init__()# 定义最终的层归一化self.norm_final = nn.LayerNorm(hidden_size, elementwise_affine=False, eps=1e-6)# 定义线性层将隐藏维度映射到最终输出通道self.linear = nn.Linear(hidden_size, patch_size * patch_size * out_channels, bias=True)# 定义自适应层归一化调制self.adaLN_modulation = nn.Sequential(nn.SiLU(), nn.Linear(hidden_size, 2 * hidden_size, bias=True))def forward(self, x: Tensor, vec: Tensor) -> Tensor:# 通过调制层计算 shift 和 scaleshift, scale = self.adaLN_modulation(vec).chunk(2, dim=1)# 归一化输入并应用 shift 和 scalex = (1 + scale[:, None, :]) * self.norm_final(x) + shift[:, None, :]# 通过线性层计算最终输出x = self.linear(x)return x
.\flux\src\flux\sampling.py
# 导入数学库
import math
# 导入 Callable 类型
from typing import Callable# 导入 PyTorch 库
import torch
# 从 einops 导入 rearrange 和 repeat 函数
from einops import rearrange, repeat
# 从 torch 导入 Tensor 类型
from torch import Tensor# 从 model 模块导入 Flux 类
from .model import Flux
# 从 modules.conditioner 模块导入 HFEmbedder 类
from .modules.conditioner import HFEmbedder# 生成噪声的函数
def get_noise(num_samples: int, # 生成的样本数量height: int, # 高度width: int, # 宽度device: torch.device, # 计算设备dtype: torch.dtype, # 数据类型seed: int, # 随机种子
):return torch.randn(num_samples, # 样本数量16, # 通道数# 允许打包的高度和宽度2 * math.ceil(height / 16),2 * math.ceil(width / 16),device=device, # 指定设备dtype=dtype, # 指定数据类型generator=torch.Generator(device=device).manual_seed(seed), # 使用指定种子初始化随机生成器)# 准备数据的函数
def prepare(t5: HFEmbedder, clip: HFEmbedder, img: Tensor, prompt: str | list[str]) -> dict[str, Tensor]:bs, c, h, w = img.shape # 获取批量大小、通道数、高度和宽度if bs == 1 and not isinstance(prompt, str): # 如果批量大小为1且提示不是字符串bs = len(prompt) # 设置批量大小为提示列表的长度# 调整图像形状以适应后续处理img = rearrange(img, "b c (h ph) (w pw) -> b (h w) (c ph pw)", ph=2, pw=2)if img.shape[0] == 1 and bs > 1: # 如果批量大小为1且实际批量大于1img = repeat(img, "1 ... -> bs ...", bs=bs) # 复制图像以适应批量大小img_ids = torch.zeros(h // 2, w // 2, 3) # 创建图像ID的零张量img_ids[..., 1] = img_ids[..., 1] + torch.arange(h // 2)[:, None] # 设置行IDimg_ids[..., 2] = img_ids[..., 2] + torch.arange(w // 2)[None, :] # 设置列IDimg_ids = repeat(img_ids, "h w c -> b (h w) c", b=bs) # 将ID张量重复以适应批量大小if isinstance(prompt, str): # 如果提示是字符串prompt = [prompt] # 将提示转换为列表txt = t5(prompt) # 使用 t5 模型处理文本提示if txt.shape[0] == 1 and bs > 1: # 如果文本的批量大小为1且实际批量大于1txt = repeat(txt, "1 ... -> bs ...", bs=bs) # 复制文本以适应批量大小txt_ids = torch.zeros(bs, txt.shape[1], 3) # 创建文本ID的零张量vec = clip(prompt) # 使用 clip 模型处理文本提示if vec.shape[0] == 1 and bs > 1: # 如果向量的批量大小为1且实际批量大于1vec = repeat(vec, "1 ... -> bs ...", bs=bs) # 复制向量以适应批量大小return {"img": img, # 返回处理后的图像"img_ids": img_ids.to(img.device), # 返回图像ID,转移到图像所在设备"txt": txt.to(img.device), # 返回处理后的文本,转移到图像所在设备"txt_ids": txt_ids.to(img.device), # 返回文本ID,转移到图像所在设备"vec": vec.to(img.device), # 返回处理后的向量,转移到图像所在设备}# 计算时间移位的函数
def time_shift(mu: float, sigma: float, t: Tensor):return math.exp(mu) / (math.exp(mu) + (1 / t - 1) ** sigma) # 计算时间移位值# 获取线性函数的函数
def get_lin_function(x1: float = 256, y1: float = 0.5, x2: float = 4096, y2: float = 1.15 # 默认参数值
) -> Callable[[float], float]: # 返回一个接受浮点数并返回浮点数的函数m = (y2 - y1) / (x2 - x1) # 计算线性函数的斜率b = y1 - m * x1 # 计算线性函数的截距return lambda x: m * x + b # 返回线性函数# 获取调度时间的函数
def get_schedule(num_steps: int, # 步骤数量image_seq_len: int, # 图像序列长度base_shift: float = 0.5, # 基础偏移量max_shift: float = 1.15, # 最大偏移量shift: bool = True, # 是否应用偏移
) -> list[float]: # 返回浮点数列表# 生成从1到0的时间步长timesteps = torch.linspace(1, 0, num_steps + 1)# 如果启用了偏移if shift:# 基于线性估算估计 mumu = get_lin_function(y1=base_shift, y2=max_shift)(image_seq_len)timesteps = time_shift(mu, 1.0, timesteps) # 应用时间移位return timesteps.tolist() # 返回时间步长的列表# 去噪函数
def denoise(model: Flux, # 模型# 模型输入img: Tensor, # 输入图像img_ids: Tensor, # 图像IDtxt: Tensor, # 处理后的文本txt_ids: Tensor, # 文本IDvec: Tensor, # 处理后的向量# 采样参数timesteps: list[float], # 时间步长guidance: float = 4.0, # 引导强度
):# 为每个图像创建引导向量guidance_vec = torch.full((img.shape[0],), guidance, device=img.device, dtype=img.dtype)# 遍历当前时间步和前一个时间步的配对for t_curr, t_prev in zip(timesteps[:-1], timesteps[1:]):# 创建一个张量 t_vec,其形状与 img 的第一个维度相同,值为 t_curr,数据类型和设备与 img 相同t_vec = torch.full((img.shape[0],), t_curr, dtype=img.dtype, device=img.device)# 使用当前时间步 t_vec 及其他参数调用模型,获得预测结果 predpred = model(img=img,img_ids=img_ids,txt=txt,txt_ids=txt_ids,y=vec,timesteps=t_vec,guidance=guidance_vec,)# 更新 img,增加预测结果 pred 和时间步差 (t_prev - t_curr) 的乘积img = img + (t_prev - t_curr) * pred# 返回更新后的 imgreturn img
# 定义一个函数,用于对 Tensor 进行重排列,调整维度
def unpack(x: Tensor, height: int, width: int) -> Tensor:# 使用 rearrange 函数重排列 Tensor 的维度return rearrange(x,# 指定输入维度和输出维度的转换规则"b (h w) (c ph pw) -> b c (h ph) (w pw)",# 根据输入的 height 和 width 计算重排列后的维度h=math.ceil(height / 16),w=math.ceil(width / 16),ph=2,pw=2,)
.\flux\src\flux\util.py
# 导入操作系统模块
import os
# 从 dataclasses 模块导入 dataclass 装饰器,用于创建数据类
from dataclasses import dataclass# 导入 PyTorch 库,用于张量操作和深度学习
import torch
# 从 einops 库导入 rearrange 函数,用于重排列和转换张量
from einops import rearrange
# 从 huggingface_hub 库导入 hf_hub_download 函数,用于下载模型文件
from huggingface_hub import hf_hub_download
# 从 imwatermark 库导入 WatermarkEncoder 类,用于在图像中嵌入水印
from imwatermark import WatermarkEncoder
# 从 safetensors 库导入 load_file 函数,并重命名为 load_sft,用于加载安全张量文件
from safetensors.torch import load_file as load_sft# 从 flux.model 模块导入 Flux 类和 FluxParams 类,用于模型定义和参数配置
from flux.model import Flux, FluxParams
# 从 flux.modules.autoencoder 模块导入 AutoEncoder 类和 AutoEncoderParams 类,用于自动编码器定义和参数配置
from flux.modules.autoencoder import AutoEncoder, AutoEncoderParams
# 从 flux.modules.conditioner 模块导入 HFEmbedder 类,用于条件嵌入
from flux.modules.conditioner import HFEmbedder# 定义一个数据类 ModelSpec,用于保存模型的各种规格和参数
@dataclass
class ModelSpec:# 定义模型参数params: FluxParams# 定义自动编码器参数ae_params: AutoEncoderParams# 定义检查点路径(可以为 None)ckpt_path: str | None# 定义自动编码器路径(可以为 None)ae_path: str | None# 定义模型仓库 ID(可以为 None)repo_id: str | None# 定义流文件仓库 ID(可以为 None)repo_flow: str | None# 定义自动编码器仓库 ID(可以为 None)repo_ae: str | None# 定义配置字典 configs,包含不同模型的规格
configs = {# 配置 "flux-dev" 模型的规格"flux-dev": ModelSpec(# 设置模型仓库 IDrepo_id="black-forest-labs/FLUX.1-dev",# 设置流文件仓库 IDrepo_flow="flux1-dev.safetensors",# 设置自动编码器仓库 IDrepo_ae="ae.safetensors",# 从环境变量获取检查点路径ckpt_path=os.getenv("FLUX_DEV"),# 设置 Flux 模型参数params=FluxParams(in_channels=64,vec_in_dim=768,context_in_dim=4096,hidden_size=3072,mlp_ratio=4.0,num_heads=24,depth=19,depth_single_blocks=38,axes_dim=[16, 56, 56],theta=10_000,qkv_bias=True,guidance_embed=True,),# 从环境变量获取自动编码器路径ae_path=os.getenv("AE"),# 设置自动编码器参数ae_params=AutoEncoderParams(resolution=256,in_channels=3,ch=128,out_ch=3,ch_mult=[1, 2, 4, 4],num_res_blocks=2,z_channels=16,scale_factor=0.3611,shift_factor=0.1159,),),# 配置 "flux-schnell" 模型的规格"flux-schnell": ModelSpec(# 设置模型仓库 IDrepo_id="black-forest-labs/FLUX.1-schnell",# 设置流文件仓库 IDrepo_flow="flux1-schnell.safetensors",# 设置自动编码器仓库 IDrepo_ae="ae.safetensors",# 从环境变量获取检查点路径ckpt_path=os.getenv("FLUX_SCHNELL"),# 设置 Flux 模型参数params=FluxParams(in_channels=64,vec_in_dim=768,context_in_dim=4096,hidden_size=3072,mlp_ratio=4.0,num_heads=24,depth=19,depth_single_blocks=38,axes_dim=[16, 56, 56],theta=10_000,qkv_bias=True,guidance_embed=False,),# 从环境变量获取自动编码器路径ae_path=os.getenv("AE"),# 设置自动编码器参数ae_params=AutoEncoderParams(resolution=256,in_channels=3,ch=128,out_ch=3,ch_mult=[1, 2, 4, 4],num_res_blocks=2,z_channels=16,scale_factor=0.3611,shift_factor=0.1159,),),
}# 定义函数 print_load_warning,用于打印加载警告信息
def print_load_warning(missing: list[str], unexpected: list[str]) -> None:# 如果缺少的键和意外的键都存在,则分别打印它们的数量和列表if len(missing) > 0 and len(unexpected) > 0:print(f"Got {len(missing)} missing keys:\n\t" + "\n\t".join(missing))print("\n" + "-" * 79 + "\n")print(f"Got {len(unexpected)} unexpected keys:\n\t" + "\n\t".join(unexpected))# 如果只有缺少的键存在,则打印它们的数量和列表elif len(missing) > 0:print(f"Got {len(missing)} missing keys:\n\t" + "\n\t".join(missing))# 如果意外的键数量大于0elif len(unexpected) > 0:# 打印意外的键数量和它们的列表print(f"Got {len(unexpected)} unexpected keys:\n\t" + "\n\t".join(unexpected))
# 定义加载模型的函数,指定模型名称、设备和是否从 HF 下载
def load_flow_model(name: str, device: str | torch.device = "cuda", hf_download: bool = True):# 打印初始化模型的消息print("Init model")# 获取配置文件中的检查点路径ckpt_path = configs[name].ckpt_path# 如果检查点路径为空且需要从 HF 下载if (ckpt_path is Noneand configs[name].repo_id is not Noneand configs[name].repo_flow is not Noneand hf_download):# 从 HF 下载模型文件ckpt_path = hf_hub_download(configs[name].repo_id, configs[name].repo_flow)# 根据是否有检查点路径选择设备with torch.device("meta" if ckpt_path is not None else device):# 初始化模型并设置数据类型为 bfloat16model = Flux(configs[name].params).to(torch.bfloat16)# 如果有检查点路径,加载模型状态if ckpt_path is not None:print("Loading checkpoint")# 加载检查点并转为字符串设备sd = load_sft(ckpt_path, device=str(device))# 加载状态字典,并检查缺失或意外的参数missing, unexpected = model.load_state_dict(sd, strict=False, assign=True)print_load_warning(missing, unexpected)# 返回模型return model# 定义加载 T5 模型的函数,指定设备和最大序列长度
def load_t5(device: str | torch.device = "cuda", max_length: int = 512) -> HFEmbedder:# 创建 HFEmbedder 对象,使用 T5 模型并设置最大序列长度和数据类型return HFEmbedder("google/t5-v1_1-xxl", max_length=max_length, torch_dtype=torch.bfloat16).to(device)# 定义加载 CLIP 模型的函数,指定设备
def load_clip(device: str | torch.device = "cuda") -> HFEmbedder:# 创建 HFEmbedder 对象,使用 CLIP 模型并设置最大序列长度和数据类型return HFEmbedder("openai/clip-vit-large-patch14", max_length=77, torch_dtype=torch.bfloat16).to(device)# 定义加载自动编码器的函数,指定名称、设备和是否从 HF 下载
def load_ae(name: str, device: str | torch.device = "cuda", hf_download: bool = True) -> AutoEncoder:# 获取配置文件中的自动编码器路径ckpt_path = configs[name].ae_path# 如果路径为空且需要从 HF 下载if (ckpt_path is Noneand configs[name].repo_id is not Noneand configs[name].repo_ae is not Noneand hf_download):# 从 HF 下载自动编码器文件ckpt_path = hf_hub_download(configs[name].repo_id, configs[name].repo_ae)# 打印初始化自动编码器的消息print("Init AE")# 根据是否有检查点路径选择设备with torch.device("meta" if ckpt_path is not None else device):# 初始化自动编码器ae = AutoEncoder(configs[name].ae_params)# 如果有检查点路径,加载自动编码器状态if ckpt_path is not None:# 加载检查点并转为字符串设备sd = load_sft(ckpt_path, device=str(device))# 加载状态字典,并检查缺失或意外的参数missing, unexpected = ae.load_state_dict(sd, strict=False, assign=True)print_load_warning(missing, unexpected)# 返回自动编码器return ae# 定义水印嵌入器类
class WatermarkEmbedder:def __init__(self, watermark):# 初始化水印和比特位数self.watermark = watermarkself.num_bits = len(WATERMARK_BITS)# 初始化水印编码器self.encoder = WatermarkEncoder()# 设置水印比特数据self.encoder.set_watermark("bits", self.watermark)# 定义一个可调用对象的 `__call__` 方法,用于给输入图像添加预定义的水印def __call__(self, image: torch.Tensor) -> torch.Tensor:"""Adds a predefined watermark to the input imageArgs:image: ([N,] B, RGB, H, W) in range [-1, 1]Returns:same as input but watermarked"""# 将图像的像素值从范围 [-1, 1] 线性映射到 [0, 1]image = 0.5 * image + 0.5# 检查图像张量的形状是否是 4 维 (即 batch size 和通道数)squeeze = len(image.shape) == 4if squeeze:# 如果是 4 维,给图像增加一个额外的维度,变成 5 维image = image[None, ...]# 获取图像的 batch sizen = image.shape[0]# 将图像从 torch 张量转换为 numpy 数组,并调整形状和通道顺序image_np = rearrange((255 * image).detach().cpu(), "n b c h w -> (n b) h w c").numpy()[:, :, :, ::-1]# torch (b, c, h, w) in [0, 1] -> numpy (b, h, w, c) [0, 255]# watermarking libary expects input as cv2 BGR format# 遍历每张图像,为每张图像应用水印编码for k in range(image_np.shape[0]):image_np[k] = self.encoder.encode(image_np[k], "dwtDct")# 将图像从 numpy 数组转换回 torch 张量,恢复原始的形状和设备image = torch.from_numpy(rearrange(image_np[:, :, :, ::-1], "(n b) h w c -> n b c h w", n=n)).to(image.device)# 将图像的像素值从 [0, 255] 归一化到 [0, 1]image = torch.clamp(image / 255, min=0.0, max=1.0)if squeeze:# 如果之前添加了额外的维度,则将其移除,恢复原始形状image = image[0]# 将图像的像素值从 [0, 1] 转换回 [-1, 1] 范围image = 2 * image - 1# 返回处理后的图像return image
# 固定的 48 位消息,随机选择的
WATERMARK_MESSAGE = 0b001010101111111010000111100111001111010100101110
# bin(x)[2:] 将 x 转换为二进制字符串(去掉前缀 '0b'),然后用 int 将每一位转换为 0 或 1
WATERMARK_BITS = [int(bit) for bit in bin(WATERMARK_MESSAGE)[2:]]
# 使用提取的位创建 WatermarkEmbedder 对象
embed_watermark = WatermarkEmbedder(WATERMARK_BITS)
.\flux\src\flux\__init__.py
# 尝试从当前包的 `_version` 模块导入 `version` 和 `version_tuple`
try:from ._version import version as __version__ # type: ignore # type: ignore 用于忽略类型检查器的警告from ._version import version_tuple
# 如果导入失败(模块不存在),则设置默认的版本信息
except ImportError:__version__ = "unknown (no version information available)" # 设置版本号为未知version_tuple = (0, 0, "unknown", "noinfo") # 设置版本元组为未知# 导入 Path 类以便处理文件路径
from pathlib import Path# 设置包的名称,将包名中的下划线替换为短横线
PACKAGE = __package__.replace("_", "-")
# 获取当前文件所在目录的路径
PACKAGE_ROOT = Path(__file__).parent
.\flux\src\flux\__main__.py
# 从同一目录下的 cli 模块导入 app 函数
from .cli import app# 如果当前模块是主程序,则执行 app 函数
if __name__ == "__main__":app()


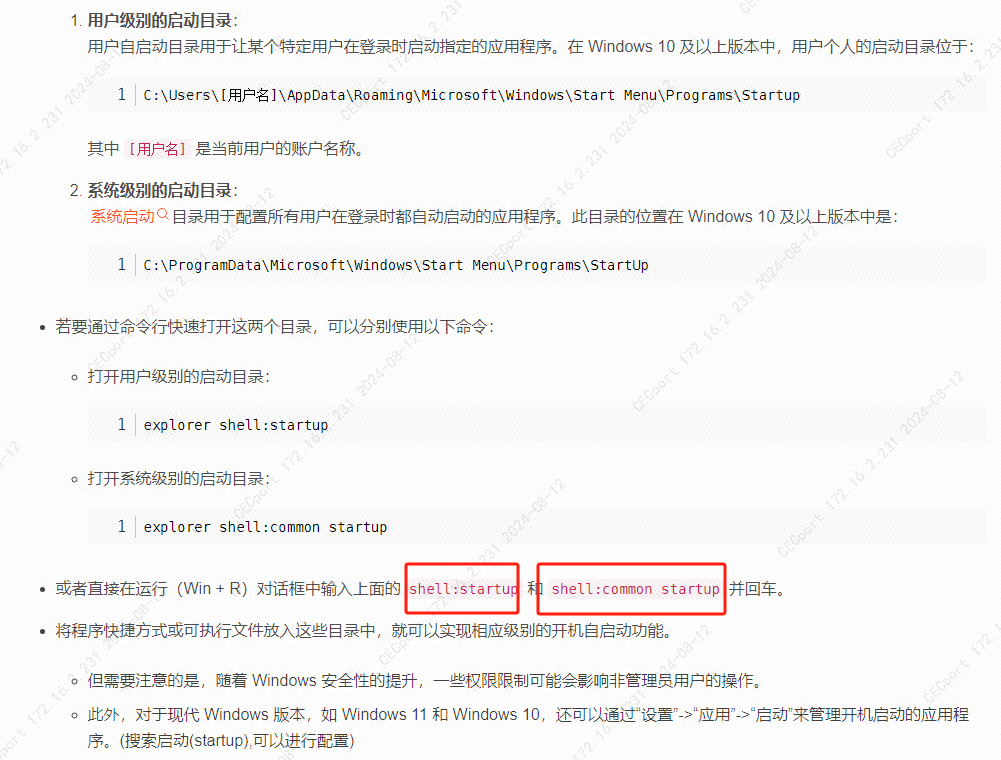
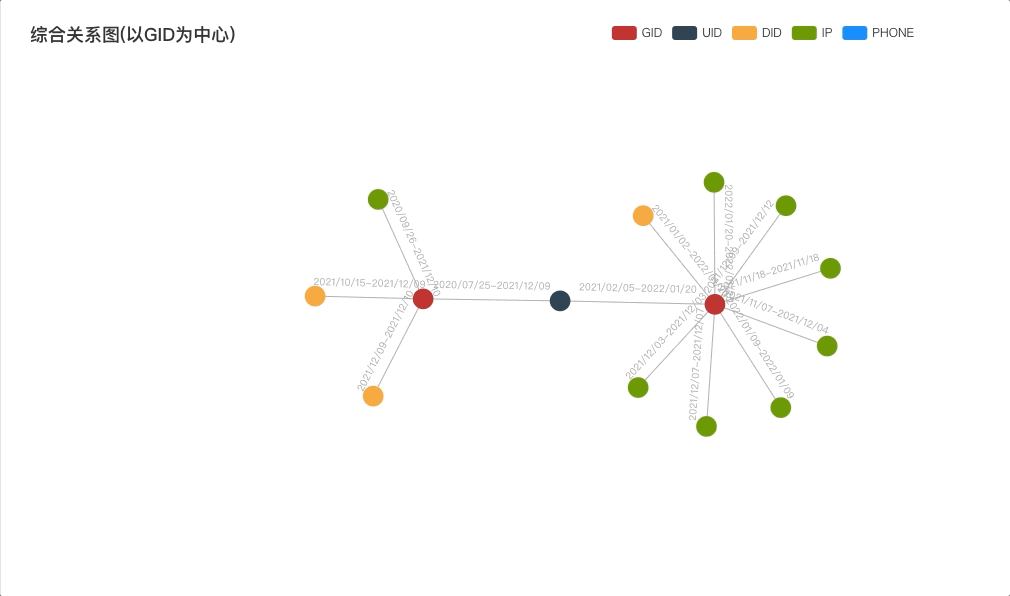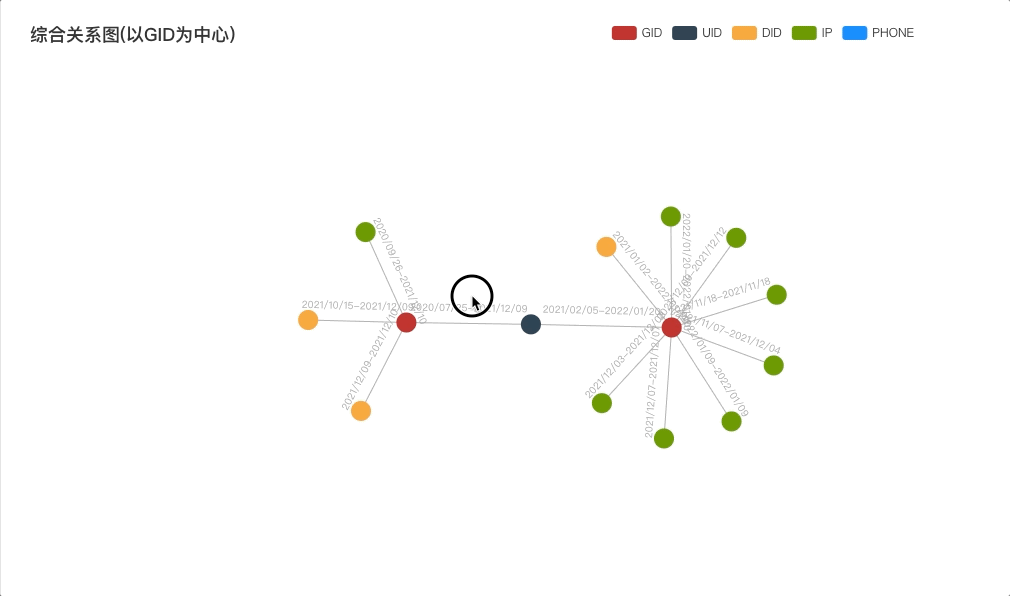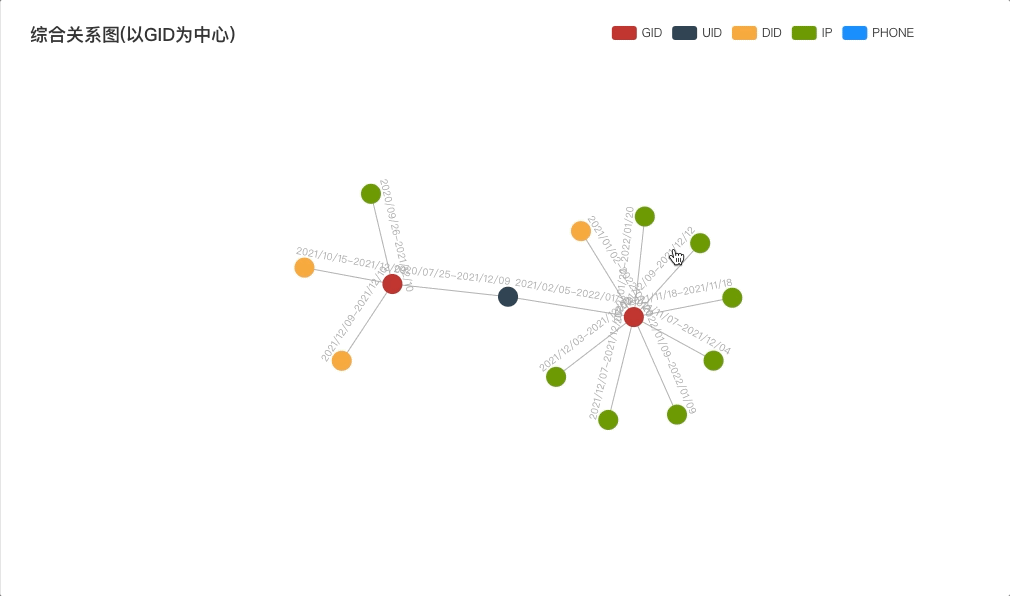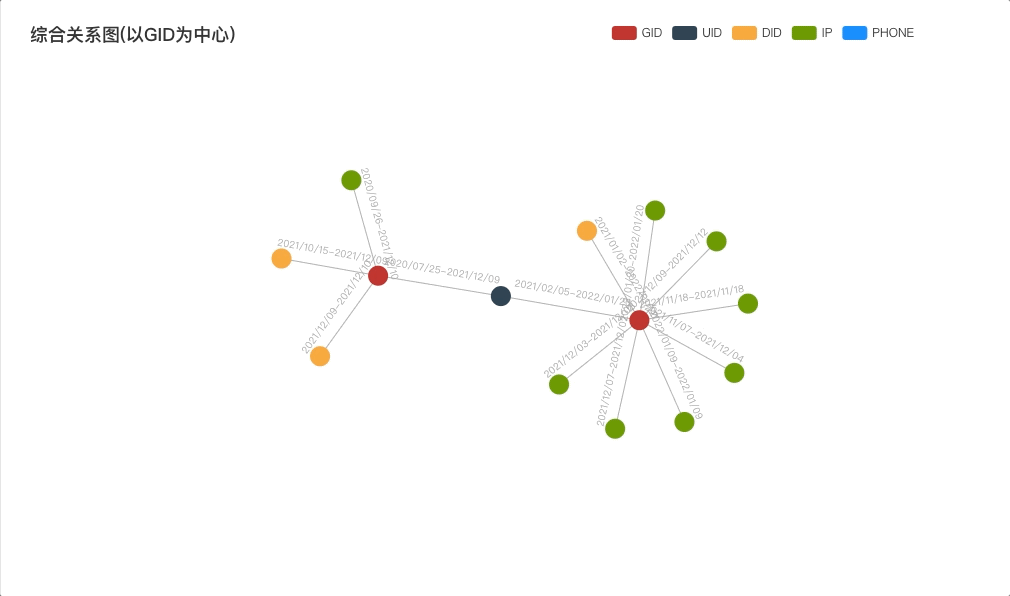

![C#中的类名对应python中的为[类名]](https://img2024.cnblogs.com/blog/518940/202409/518940-20240905110146429-1943082068.png)