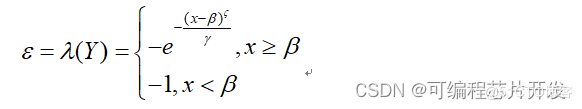IDGenRec: LLM-RecSys Alignment with Textual ID Learning论文阅读笔记
Abstract
为了使 LLM 与推荐需求更好地结合,我们提出了 IDGenRec,使用人类语言标记将每个项目表示为唯一、简洁、语义丰富、平台无关的文本 ID。这是通过与基于 LLM 的推荐器一起训练文本 ID 生成器来实现的,从而将个性化推荐无缝集成到自然语言生成中。值得注意的是,由于用户历史记录是用自然语言表达的,并且与原始数据集分离,我们的方法为基础生成推荐模型提供了可能性。
Introduction
传统方法将推荐视为一种检索(候选选择)和排序过程,而生成式推荐则将其解释为一种直接的文本到文本生成任务:用户的历史记录以文本提示的形式表达,而目标推荐则以自然语言的形式生成。然而,与只阅读和生成人类语言标记的 NLP 任务不同,推荐平台中的项目是一个不断增长的宇宙中的单个实体。因此,如何将项目编码为语言标记(即项目 ID),使其能够轻松地集成到文本到文本范式中,是生成式推荐研究中一个独特而关键的问题。
如果推荐系统中的项目也完全使用人类词汇来表示,每个项目都由一组特定的自然语言标记来描述,那么 LLM 的能力就能更贴近推荐系统的要求。这样,通过在特定于推荐的语料库中进行训练,LLMs 就能学习到真正与推荐相关的知识,从而大大提高模型在推荐任务中的准确性和通用性。
因此,我们认为生成式推荐中理想的 ID 应具备以下特性: 1) 它们应该是由经过预训练的 LLMs 最初处理过的标记组成的文本 ID;2) 它们应该有意义、信息量大并适合推荐目的;3) 生成的 ID 应该简短而唯一,能够有效地识别推荐项目。然而,在现有的项目信息中,显然无法找到满足如此严格要求的 ID。因此,在本文中,我们提出训练一种 ID 生成器,为每个项目自动学习符合上述标准的文本 ID。新框架被命名为 IDGenRec,它将 ID 生成视为另一个文本到文本的过程。
ID 生成器也是一个语言模型,它获取项目的元数据(即关于项目的所有可用文本信息)并生成合格的文本 ID。因此,用户的历史记录和推荐的目标项目都可以用自然语言表示,没有任何 “非文本化 ”的标记,因此适合用于训练基于 LLM 的生成式推荐器。整个过程如图 2 所示。值得注意的是,通过考虑用户历史记录中的所有项目文本,同一 ID 生成器还可以生成另一个文本 ID,作为用户的 ID,代表用户偏好的 “高级轮廓”。用户 ID 的创建是可选的,我们将在实验中提供消融研究结果。

这项工作面临着许多挑战,我们在论文中提出了相关的策略来解决这些问题,包括:
标识生成器应能理解可能包含不必要信息的冗长元数据,并能生成涵盖对推荐非常重要的项目关键细节的标记。为此,我们选择了一个最初为文章标签生成而训练的 T5 模型,并根据推荐目标对其进行了微调
生成的 ID 既要简短又要唯一,适合用于识别推荐项目。然而,自动生成的 ID 并不总是能满足唯一性标准,尤其是随着项目数量的增加。因此,我们提出了一种多样化的 ID 生成算法,以确保每个项目都有一个唯一的 ID。
由于该框架依赖于两个 LLM--ID 生成器和基础推荐器--之间的协作,因此需要精心设计的训练策略来实现它们之间的无缝协作。我们提出了另一种训练策略,即异步训练基于 LLM 的 ID 生成器和基础推荐器,确保它们学习到的知识完全一致。
与判别方法相比,生成模型有几个优点。这些优势包括:将检索和排序过程转化为更精简的生成过程,无需逐一计算项目得分,以及充分利用预先训练的生成式 LLM 中蕴含的丰富知识。
Method
如第 2.1 节所述,我们首先介绍了生成过程,包括如何构建提示以及如何将生成的 ID 整合到文本到文本格式中。然后,在第 2.2 和 2.3 节中,我们将介绍如何利用项目的元数据生成 ID,并采用不同的 ID 生成算法来确保 ID 的唯一性。有了这些生成的 ID,我们将在第 2.4 节中介绍基础推荐系统。最后,在第 2.5 节中,我们演示了如何根据推荐目标交替训练 ID 生成器和推荐器,以确保它们协同有效地工作。
生成过程
这块描述了一下示意图的内容
ID生成器
ID 生成器是一个生成模型,可利用项目的元信息生成项目 ID。元信息包括与物品相关的所有文本数据,包括与推荐目的相关和不相关的方面。这些信息的潜在元素可能包括物品的标题、类别、价格、一般描述、创建时间、受欢迎程度、位置等。具体内容主要取决于平台和数据集。虽然元信息通常以键值字典格式呈现,但我们在处理过程中会将其转换为纯文本
考虑一个项目,其简单描述是一长串代词 𝒘 = [𝑤1,𝑤2, ... ,𝑤𝑚]。代词嵌入将根据模型参数从𝒘 生成,并与位置嵌入相结合,然后再输入语言模型。由于与位置嵌入相结合的过程在大型语言模型中很常见,因此在其余公式中将省略这一过程。ID 生成器的输出将是一组简洁的 ID 标记𝒅 = [𝑑1,𝑑2,...,𝑑𝑛],其中𝑛 ≪𝑚。在生成物品 ID 的每个标记时,模型都会同时考虑物品的整个普通描述和之前生成的 ID 单元。因此,生成 ID 的概率表示为
\(p(d_1,\cdots,d_n)=\prod_{i=1}^np_\theta(d_i|d_{<i},w)\)
多样ID生成
生成的 ID 有两个主要特性: 1) ID 应该有合理的长度,2) ID 应该是唯一的。然而,这两个属性在某种程度上是相互矛盾的:当 ID 生成器生成一组长度较短的 ID 时,更有可能产生重复的 ID。因此,我们提出了一种算法,以确保生成的 ID 既简短又唯一。该算法的核心理念从根本上说是基于句子生成中常用的多样化波束搜索(DBS)。它是标准波束搜索的一种变体,旨在生成更多样化的序列集。DBS 将波束分成若干组,并引入多样性惩罚(表示为𝜆)作为超参数,以阻止在同一组中选择相似的序列。𝜆的值越高,多样性越高;𝜆的值越低,模型的概率权重越大,可能导致输出的多样性越低。
ID 生成器采用 DBS 生成 ID。为确保生成 ID 的唯一性,该算法每次生成 𝑘 组 ID,并将每个生成的 ID 与一组已有的 ID 进行比较。如果检测到重复,算法就会增加波束搜索的多样性惩罚。这种惩罚的增加会一直持续到生成唯一的 ID,或者直到分集惩罚达到预设的最大阈值。在最大惩罚不足以生成唯一 ID 的情况下,算法会延长允许的 ID 长度,并用初始分集惩罚重复这一过程。算法 1 详细说明了这一过程。

基础推荐
在生成项目 ID 并将其纳入提示模板后,系统对完成的提示进行标记化,并将其输入基于 LLM 的推荐器。然后,推荐器以自回归方式生成目标推荐项目 ID 的标记。
为确保解码后的 ID 与实际存在的项目相对应,我们采用了一种受限序列解码策略。更具体地说,我们使用前缀树来存储所有生成的候选 ID。每个新生成的标记都受到之前生成的标记的约束,确保生成过程只考虑数据集中可能构成现有候选 ID 的标记。假设完成的输入提示表示为一个标记序列 𝒙 = [𝑥1, 𝑥2, - - , 𝑥𝑛] 。在这种情况下,基础推荐模型的目标是生成 𝒚 = [𝑦1, 𝑦2, - - , 𝑦𝑛],其中 𝒚 是数据集中真实项目的 ID。我们将 V (𝑦<𝑖) 定义为词汇表中有效标记的子集,它受到以先前生成的标记为节点的前缀树的限制。解码器生成每个标记的过程定义为
\(p(y_i|y_{<i},x)=\begin{cases}p_\phi(y_i|y_{<i},x)&\text{if}y_i\in\mathcal{V}(y_{<i}),\\0&\text{otherwise.}\end{cases}\)
因此,推荐目标项目 [𝑦1, - - - , 𝑦𝑛] 的概率为:
\(p(y_1,\cdots,y_n)=\prod_{i=1}^np_\phi(y_i|y_{<i},x,V(y_{<i}))\)
交替训练
训练 ID 生成器和基础推荐器是两项独立但又相互依存的任务。对 ID 生成器进行训练是为了生成基础推荐器可以轻松解读的最佳 ID。与此同时,基础推荐器会调整其参数,以增强对项目的正确推荐,每个项目都由其当前生成的 ID 表示。同时训练这两个组件可能会导致训练过程不稳定。因此,我们建议交替进行 ID 生成器和基础推荐器的训练,并通过指定次数的迭代进行。这种方法包括在基础推荐器的两个训练阶段之间异步更新 ID,以实现更好的集成和性能。
ID 生成器和基础推荐器都是通过最小化最终预测与ground-truth目标项目 ID 相比的负对数似然来训练的。
训练基础推荐器
在基础推荐器的每一轮训练中,我们都会使用当时的 ID 生成器为所有项目预先计算项目 ID。对于训练数据中的每个用户,用户历史记录中物品的当前 ID 会被填入采样模板,以完成输入提示𝒙。然后,基础推荐器 𝒙 采用普通教师强迫策略进行训练,即根据前一个标记的地面实况值计算下一个标记的损失:
\(\mathcal{L}_{\mathrm{rec}}=-\sum_{i=1}^{|\boldsymbol{y}|}\log P_\omega(y_i|y_{<\boldsymbol{i}},\boldsymbol{x})\)
训练ID生成器
在这个训练过程中,基础推荐器的所有参数都是固定的,只有 ID 生成器会被更新。目标是让 ID 生成器生成适合基础推荐模型的 ID。
由于 ID 生成器的输出是一组离散的代币(ID),因此本质上是不可分的。这给使用基于梯度的优化技术训练模型带来了挑战,因为梯度无法流回这些离散输出。为了规避这一问题,对于用户历史记录中的每个条目,我们计算 ID 生成器在所有词汇中对每个标记的输出对数,记为\(\mathrm{Logits}_{\phi}(\mathcal{V})\),其中 𝜙 是 ID 生成器模型,V 是词汇。然后,我们通过基础推荐模型的参数来计算 ID 每个标记的平均嵌入,记为\(\mathrm{Emb}_\omega(\mathrm{Logits}_\phi(\mathcal{V})),\)其中,\(\omega\)是基础推荐模型。这就为生成的 ID 创建了一个连续、可微分的表示。然后,这些 ID 嵌入会直接插值到嵌入层相关位置的提示模板中。我们使用 \(Emb_{interp}\) 来表示这个完成的输入嵌入。这样,ID 生成器就可以在推荐输出计算出的损失的指导下得到训练。这一过程可表述为
\(\mathcal{L}_{\mathrm{id}}=-\sum_{i=1}^{|\boldsymbol{y}|}\log P_\omega\left(y_i\mid y_{<i},\mathrm{Emb}_{\mathrm{interp}}\right)\)
其中:\(\mathrm{Emb}_{\mathrm{interp}}=\mathrm{Insert}\left(\mathrm{Emb}_{\omega}\left(\mathrm{prompt}\right),\mathrm{Emb}_{\omega}\left(\mathrm{Logits}_{\phi}(\mathcal{V})\right)\right)\)
基础推荐模型(即阶梯)的参数是固定的,损失只会反向传播到 ID 生成器(即𝜙),从而确保生成的 ID 能够以基础推荐模型能够有效解释的格式捕捉到每个项目的基本特征(由其元信息决定)。
模型初始化
我们选择 T5作为 ID 生成器和基础推荐器的骨干,主要有两个原因: 1) 保持模型的简洁性,因为本文的目的不是对 LLM 结构进行广泛的实证研究,而是专注于 ID 生成这一核心概念;2) 确保与之前同样基于 T5 的生成式推荐作品进行公平比较,从而证明推荐能力的提高完全来自于更优雅的 ID 选择。
总结
这篇文章的重点在于给每个物品生成一个独立且能够代表物品信息的ID,为此使用LLM作为ID生成器并且使用DBS来保证ID生成的多样化。然后将这些ID输入到用于推荐的LLM基础推荐器上用于最后的推荐。然后就是在训练的时候采用交替训练的策略。
这篇文章有点难懂,需要反复多读几遍