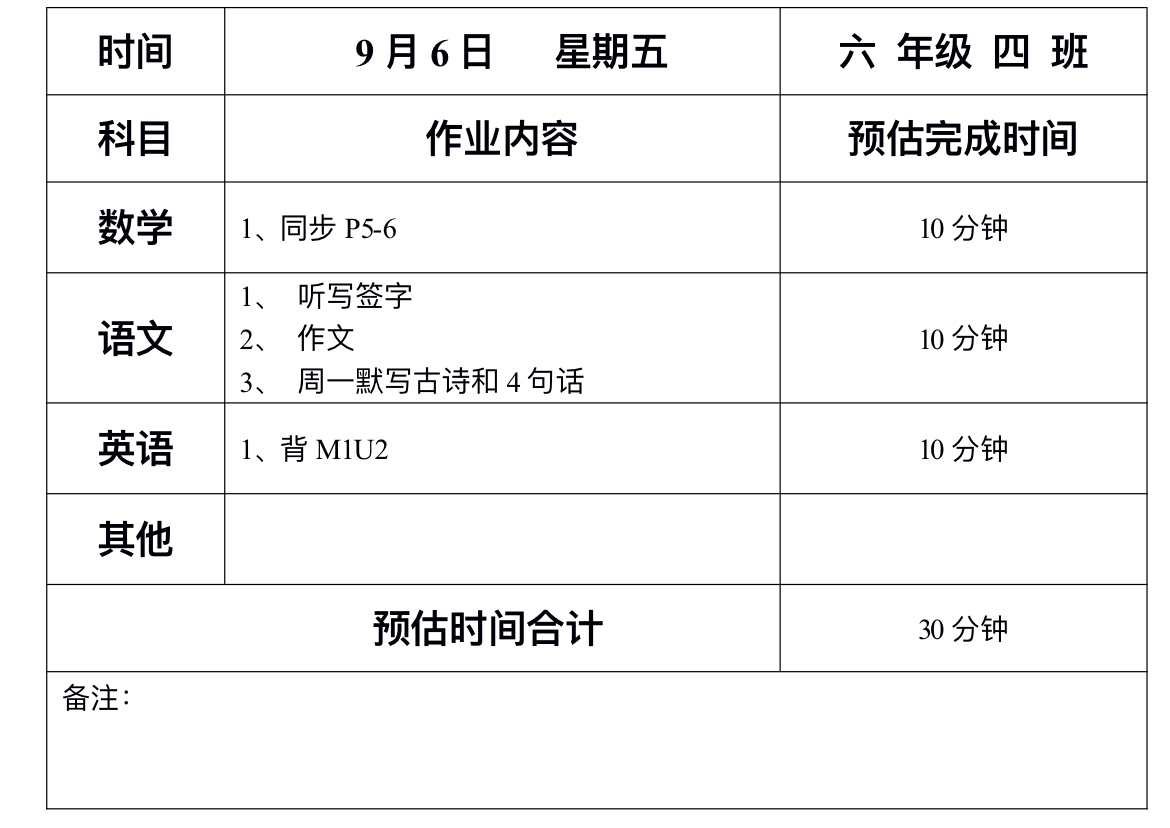
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 10 | |
| Estimate | 估计这个任务需要多少时间 | 300 | |
| Development | 开发 | 150 | |
| Analysis | 需求分析 (包括学习新技术) | 50 | |
| Design Spec | 生成设计文档 | 10 | |
| Design Review | 设计复审 | 20 | |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 10 | |
| Design | 具体设计 | 20 | |
| Coding | 具体编码 | 100 | |
| Code Review | 代码复审 | 50 | |
| Test | 测试(自我测试,修改代码,提交修改) | 30 | |
| Reporting | 报告 | 20 | |
| Test Report | 测试报告 | 10 | |
| Size Measurement | 计算工作量 | 5 | |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 5 | |
| 总计 | 600 |
设计思路
使用python语言对orig.txt文件和orig_add.txt文件进行论文查重,对待相同的字符串进行记录,按照orig_add.txt对orig.txt的盗用率为重复率即公式:
重复率=(orig.txt和orig_add.txt的相同字符个数)/(orig_add.txt中的字符总个数)
设计环境
win11 python3.7.0
设计需求分析
- 设计一个论文查重算法,给出一个原文文件和一个在这份原文上经过了增删改的抄袭版论文的文件,在答案文件中输出其重复率
- 要求输入输出采用文件输入输出,规范如下:
从命令行参数给出:论文原文的文件的绝对路径。
从命令行参数给出:抄袭版论文的文件的绝对路径。
从命令行参数给出:输出的答案文件的绝对路径。
设计算法
向量空间模型
相似性度量
实现与测试
在命令行用python指令运行

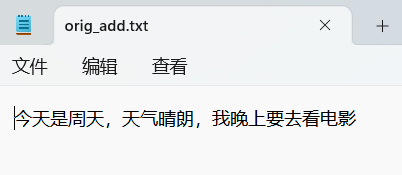
orig.txt
orig_add.txt
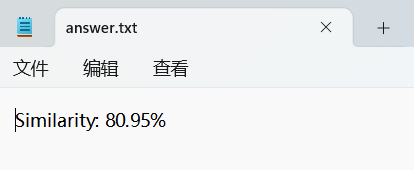
answer.txt
性能分析
- 代码:
import cProfile
import re
cProfile.run('re.compile("foo|bar")')
代码思想
- 用python定义三个函数
-
load(file_path):用来读取文件
-
calculate_similarity(orig_text,orig_add_text):用来计算覆盖率
-
main():主函数
-
在主函数里面先调用load函数,来分别读取三个文件
-
之后将源文件和抄袭文件进行查重计算
-
最后将计算结果存放到ans.txt文件中
-
计算模块接口部分的性能改进:使用更高效的算法或数据结构、减少不必要的内存分配或回收、优化循环或条件判断等。