### 卷积神经网络模型
卷积神经网络(简称 CNN)是一种专为图像输入而设计的网络。它最明显的特征就是具有三个层次,卷积层,池化层,全连接层。
借用一张图,下图很好的表示了什么是卷积(提取特征),什么是池化(减少数据量),而全连接层就是一个简单普通的神经网络。

如下代码,该代码定义了一个卷积神经网络。其中仅有一个简单的函数前向传播`forward函数`,这个函数的功能其实就是输入数据,给出预测,并不复杂。
1 from numpy import argmax, vstack 2 from sklearn.metrics import accuracy_score 3 from torch.nn import Module, Conv2d, ReLU, MaxPool2d, Linear, CrossEntropyLoss, Softmax 4 from torch.nn.init import kaiming_uniform_, xavier_uniform_ 5 from torch.optim import SGD 6 from torch.utils.data import DataLoader 7 from torchvision.datasets import MNIST 8 from torchvision.transforms import Compose, ToTensor, Normalize 9 10 11 # 定义模型 12 class CNN(Module): 13 def __init__(self, n_channels): 14 # 模型属性 15 super(CNN, self).__init__() 16 # 隐藏层1。采用了Conv2d函数,n_channels输入数据的通道(彩色RGB图像为3),out_channels即输出的通道数量,kernel_size卷积核的大小 17 self.hidden1 = Conv2d(n_channels, 32, kernel_size=(3, 3)) 18 kaiming_uniform_(self.hidden1.weight, nonlinearity='relu') # 初始化权重 19 self.act1 = ReLU() # 激活函数 20 # 池化层1。二维最大池化(Max Pooling)层,kernel_size池化窗口的大小,stride池化窗口的滑动步长 21 self.pool1 = MaxPool2d((2, 2), stride=(2, 2)) 22 # 隐藏层2 23 self.hidden2 = Conv2d(32, 32, kernel_size=(3, 3)) 24 kaiming_uniform_(self.hidden2.weight, nonlinearity='relu') 25 self.act2 = ReLU() 26 # 池化层2 27 self.pool2 = MaxPool2d((2, 2), stride=(2, 2)) 28 # 全连接层 29 self.hidden3 = Linear(5 * 5 * 32, 100) 30 kaiming_uniform_(self.hidden3.weight, nonlinearity='relu') 31 self.act3 = ReLU() 32 # 输出层 33 self.hidden4 = Linear(100, 10) 34 xavier_uniform_(self.hidden4.weight) 35 self.act4 = Softmax(dim=1) 36 37 # 前向传播 38 def forward(self, X): 39 # 输入到隐藏层1 40 X = self.hidden1(X) 41 X = self.act1(X) 42 X = self.pool1(X) 43 # 输入到隐藏层2 44 X = self.hidden2(X) 45 X = self.act2(X) 46 X = self.pool2(X) 47 # 扁平化 48 X = X.view(-1, 4 * 4 * 50) 49 # 输入到隐藏层3 50 X = self.hidden3(X) 51 X = self.act3(X) 52 # 输入到输出层 53 X = self.hidden4(X) 54 X = self.act4(X) 55 return X
然后准备数据,开始划分训练集和测试集
# 准备数据集 def prepare_data(path):# 定义标准化trans = Compose([ToTensor(), Normalize((0.1307,), (0.3081,))])# 加载数据集train = MNIST(path, train=True, download=True, transform=trans)test = MNIST(path, train=False, download=True, transform=trans)# 创建 DataLoadertrain_dl = DataLoader(train, batch_size=64, shuffle=True)test_dl = DataLoader(test, batch_size=1024, shuffle=False)return train_dl, test_dl
所准备是数据如下图,是一种手写数字,通过识别图片分析来得到答案

然后我们就要看是训练模型了
# 训练模型 def train_model(train_dl, model):criterion = CrossEntropyLoss() # 损失函数# 定义优化器,SGD(随机梯度下降),lr学习率,momentum动量,用于加速 SGD 在相关方向上的收敛,并抑制震荡optimizer = SGD(model.parameters(), lr=0.01, momentum=0.9)# 枚举 epochsfor epoch in range(10):# 枚举 mini batchesfor i, (inputs, tragets) in enumerate(train_dl):# 梯度清零 optimizer.zero_grad()# 计算模型输出yhat = model(inputs)# 计算损失loss = criterion(yhat, tragets)# 反向传播,通过pytorch的自动求导系统(Autograd)间接地影响模型的参数 loss.backward()# 升级模型权重,然后优化器根据反向传播所存储的数据来优化optimizer.step()
训练完模型,还要评估一下模型
# 评估模型 def evaluate_model(test_dl, model):predictions, actuals = list(), list()for i, (inputs, tragets) in enumerate(test_dl):# 在测试集上评估模型yhat = model(inputs)# 转化为 numpy 数据类型yhat = yhat.detach().numpy()actual = tragets.numpy()# 转化为类标签yhat = argmax(yhat, axis=1)# 为 stack 格式化数据集actual = actual.reshape(len(actual), 1)yhat = yhat.reshape(len(yhat), 1)# 保存 predictions.append(yhat)actuals.append(actual)predictions, actuals = vstack(predictions), vstack(actuals)# 计算准确度acc = accuracy_score(actuals, predictions)return acc
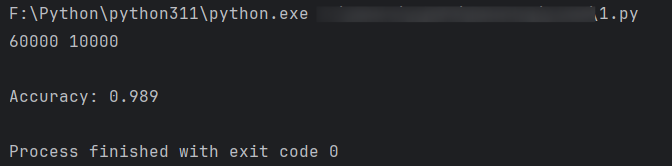
最后我们利用如下代码开始运行
# 准备数据 path = './' train_dl, test_dl = prepare_data(path) print(len(train_dl.dataset), len(test_dl.dataset)) # 定义网络 model = CNN(1) train_model(train_dl, model) acc = evaluate_model(test_dl, model) print('Accuracy: %.3f' % acc)
### 多层感知机模型
1 from numpy import vstack, argmax 2 from pandas import read_csv 3 from sklearn.metrics import accuracy_score 4 from sklearn.preprocessing import LabelEncoder 5 from torch import Tensor 6 from torch.nn import Module, Linear, ReLU, Softmax, CrossEntropyLoss 7 from torch.nn.init import kaiming_uniform_, xavier_uniform_ 8 from torch.optim import SGD 9 from torch.utils.data import Dataset, random_split, DataLoader 10 11 12 # 数据集定义 13 class CSVDataset(Dataset): 14 # 导入数据集 15 def __init__(self, path): 16 # 导入数据集 17 df = read_csv(path, header=None) 18 # 设置神经网络的输入与输出 19 self.X = df.values[:, :-1] 20 self.y = df.values[:, -1] 21 # 确保输入数据是浮点数 22 self.X = self.X.astype('float32') 23 # 使用浮点型标签编码原输出 24 self.y = LabelEncoder().fit_transform(self.y) 25 26 # 定义获取数据集长度的方法 27 def __len__(self): 28 return len(self.X) 29 30 # 定义获取某一行数据的方法 31 def __getitem__(self, idx): 32 return [self.X[idx], self.y[idx]] 33 34 # 在类内部定义划分训练集和测试集的方法 35 def get_splits(self, n_test = 0.33): 36 # 确定训练集和测试集的尺寸 37 test_size = round(len(self.X) * n_test) 38 train_size = len(self.X) - test_size 39 # 根据尺寸划分训练集和测试集并返回 40 return random_split(self, [train_size, test_size]) 41 42 43 # 模型定义 44 class MLP(Module): 45 # 定义模型属性 46 def __init__(self, n_inputs): 47 super(MLP, self).__init__() 48 # 隐藏层1(输入) 49 self.hidden1 = Linear(n_inputs, 10) 50 kaiming_uniform_(self.hidden1.weight, nonlinearity='relu') 51 self.act1 = ReLU() 52 # 隐藏层2 53 self.hidden2 = Linear(10, 8) 54 kaiming_uniform_(self.hidden2.weight, nonlinearity='relu') 55 self.act2 = ReLU() 56 # 隐藏层3(输出) 57 self.hidden3 = Linear(8, 3) 58 xavier_uniform_(self.hidden3.weight) 59 self.act3 = Softmax(dim=1) 60 61 # 前向传播 62 def forward(self, X): 63 # 输入 64 X = self.hidden1(X) 65 X = self.act1(X) 66 # 隐藏层2 67 X = self.hidden2(X) 68 X = self.act2(X) 69 # 输出 70 X = self.hidden3(X) 71 X = self.act3(X) 72 return X 73 74 75 # 准备数据集 76 def prepare_data(path): 77 # 导入数据集 78 dataset = CSVDataset(path) 79 train, test = dataset.get_splits() 80 train_dl = DataLoader(train, batch_size=32, shuffle=True) 81 test_dl = DataLoader(test, batch_size=1024, shuffle=False) 82 return train_dl, test_dl 83 84 # 训练模型 85 def train_model(train_dl, model): 86 # 定义优化器 87 criterion = CrossEntropyLoss() 88 optimizer = SGD(model.parameters(), lr=0.01, momentum=0.9) 89 # 枚举 epochs 90 for epoch in range(500): 91 # 枚举 mini batches 92 for i, (inputs, targets) in enumerate(train_dl): 93 # 梯度清除 94 optimizer.zero_grad() 95 # 计算模型输出 96 yhat = model(inputs) 97 # 计算损失 98 loss = criterion(yhat, targets) 99 # 反向传播 100 loss.backward() 101 # 更新 102 optimizer.step() 103 104 def evaluate_model(test_dl, model): 105 predictions, actuals = list(), list() 106 for i, (inputs, targets) in enumerate(test_dl): 107 # 在测试集上评估模型 108 yhat = model(inputs) 109 # 转化为 numpy 数据类型 110 yhat = yhat.detach().numpy() 111 actual = targets.numpy() 112 # 转化为类标签 113 yhat = argmax(yhat, axis=1) 114 # 为 stacking reshape 矩阵 115 actual = actual.reshape((len(actual), 1)) 116 yhat = yhat.reshape((len(yhat), 1)) 117 # 保存 118 predictions.append(yhat) 119 actuals.append(actual) 120 predictions, actuals = vstack(predictions), vstack(actuals) 121 # 计算准确度 122 acc = accuracy_score(actuals, predictions) 123 return acc 124 125 # 对一行数据进行类预测 126 def predict(row, model): 127 # 转换源数据 128 row = Tensor([row]) 129 # 做出预测 130 yhat = model(row) 131 # 转化为 numpy 数据类型 132 yhat = yhat.detach().numpy() 133 return yhat 134 135 # 准备数据 136 path = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/iris.csv' 137 train_dl, test_dl = prepare_data(path) 138 print(len(train_dl), len(test_dl)) 139 # 定义网络 140 model = MLP(4) 141 # 训练模型 142 train_model(train_dl, model) 143 # 评估模型 144 acc = evaluate_model(test_dl, model) 145 print('Accuracy: %.3f' % acc) 146 # 进行单个预测 147 row = [5.1,3.5,1.4,0.2] 148 yhat = predict(row, model) 149 print('Predicted: %s (class=%d)' % (yhat, argmax(yhat)))
这个就比较简单了,最简单的感知机(最简单的两层神经网络),这里只不过是多层的感知机。它的思想还是比较好理解的,主要是如何针对不同的应用来实现它