动态卷积学习
n个静态卷积核的线性混合,加权使用它们输入相关的注意力,表现出比普通卷积更优越的性能。然而,它将卷积参数的数量增加了n倍,因此并不是参数高效的。这导致不能探索n>100的设置(比典型设置n<10大一个数量级),推动动态卷积性能边界提升的同时享受参数的高效性。为此,论文提出了KernelWarehouse,通过利用卷积参数在同一层内部以及邻近层之间的依赖关系重新定义了“卷积核”、“组装卷积核”和“注意力函数”的基本概念。来源:晓飞的算法工程笔记 公众号,转载请注明出处
论文: KernelWarehouse: Rethinking the Design of Dynamic Convolution

- 论文地址:https://arxiv.org/abs/2406.07879
- 论文代码:https://github.com/OSVAI/KernelWarehouse
Introduction
卷积是卷积神经网络(ConvNets)中的关键操作。在卷积层中,普通卷积 \(\mathbf{y} = \mathbf{W}*\mathbf{x}\) 通过由一组卷积滤波器定义的相同卷积核 \(\mathbf{W}\) 应用于每个输入样本 \(\mathbf{x}\) 来计算输出 \(\mathbf{y}\) 。为简洁起见,将“卷积核”简称为“核”并省略偏置项。尽管常规卷积的有效性已经通过在许多计算机视觉任务上通过各种ConvNet架构进行广泛验证,但最近在高效ConvNet架构设计方面的进展表明,被称为CondConv和DY-Conv的动态卷积取得了巨大的性能提升。
动态卷积的基本思想是用 \(n\) 个相同维度的卷积核的线性混合来取代常规卷积中的单个核, \(\mathbf{W}=\alpha_{1}\mathbf{W}_1+...+\alpha_{n}\mathbf{W}_n\) ,其中 \(\alpha_{1},...,\alpha_{n}\) 是由一个依赖于输入的注意力模块生成的标量注意力。受益于 \(\mathbf{W}_1,...,\mathbf{W}_n\) 的加法性质和紧凑的注意力模块设计,动态卷积提高了特征学习能力,而与普通卷积相比只增加了少量的乘加成本。然而,它将卷积参数的数量增加了 \(n\) 倍,因为现代ConvNet的卷积层占据了绝大部分参数,这导致了模型大小的大幅增加。目前还很少有研究工作来缓解这个问题。DCD通过矩阵分解学习基础核和稀疏残差,以逼近动态卷积。这种逼近放弃了基本的混合学习范式,因此当 \(n\) 变大时无法保持动态卷积的表征能力。ODConv提出了一个改进的注意力模块,沿不同维度动态加权静态卷积核,而不是单个维度,这样可以在减少卷积核数量的情况下获得具有竞争力的性能。但是,在相同的 \(n\) 设置下,ODConv的参数比原始动态卷积多。最近,有研究直接使用了流行的权重修剪策略,通过多个修剪和重新训练阶段来压缩DY-Conv。
简而言之,基于线性混合学习范式的现有动态卷积方法在参数效率方面存在局限。受此限制,卷积核数量通常设置为 \(n=8\) 或 \(n=4\) 。然而,一个显而易见的事实是,采用动态卷积构建的ConvNet的增强容量来源于通过注意机制增加每个卷积层的卷积核数量 \(n\) 。这导致了所需模型大小和容量之间的基本冲突。因此,论文重新思考了动态卷积的设计,旨在协调这种冲突,使其能够在参数效率的同时探索动态卷积性能边界,即能够设置更大的核数 \(n>100\) (比典型设置 \(n<10\) 大一个数量级)。需要注意的是,对于现有的动态卷积方法, \(n>100\) 意味着模型大小将大约比使用普通卷积构建的基础模型大100倍以上。
为了实现这一目标,论文提出了一种更通用的动态卷积形式,称为KernelWarehouse,主要受到现有动态卷积方法的两个观察的启发:(1)它们将常规卷积层中的所有参数视为静态核,将卷积核数量从1增加到 \(n\) ,并使用其注意模块将 \(n\) 个静态核组装成线性混合核。虽然直观有效,但它们没有考虑卷积层内部静态核之间的参数依赖关系;(2)它们为ConvNet的各个卷积层分配不同的 \(n\) 个静态核集合,忽略了相邻卷积层之间的参数依赖关系。与现有方法形成鲜明对比的是,KernelWarehouse的核心理念是利用ConvNet中同一层和相邻层的卷积参数依赖关系,重新构成动态卷积,以实现在参数效率和表示能力之间取得大幅度改进的权衡。
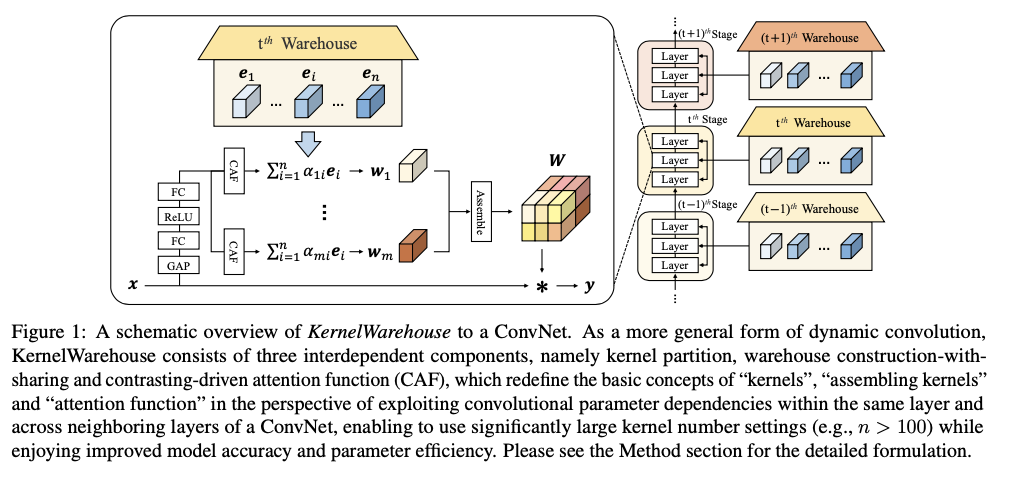
KernelWarehouse由三个组件组成,分别是核分区、仓库的构建与共享和对比驱动的注意函数,它们之间紧密相互依赖。核分区利用同一卷积层内的参数依赖关系,重新定义了线性混合中的“核”,以较小的局部尺度而不是整体尺度来定义。仓库构建与共享利用相邻卷积层之间的参数依赖关系,重新定义了跨同一阶段卷积层的“组装核”,并生成了一个包含 \(n\) 个局部核(例如 \(n=108\) )的大型仓库,用于跨层线性混合共享。对比驱动的注意函数用于解决在具有挑战性的 \(n>100\) 设置下,跨层线性混合学习范式下的注意力优化问题,重新定义了“注意力函数”。在给定不同的卷积参数预算下,KernelWarehouse提供了很高的灵活性,允许以足够大的 \(n\) 值来很好地平衡参数效率和表示能力。
作为普通卷积的即插即用替代品,KernelWarehouse可以轻松应用于各种类型的ConvNet架构,通过对ImageNet和MS-COCO数据集进行大量实验证实了KernelWarehouse的有效性。一方面,轮你问展示了与现有动态卷积方法相比,KernelWarehouse实现了更优越的性能(例如,在ImageNet数据集上,使用KernelWarehouse训练的ResNet18|ResNet50|MobileNetV2|ConvNeXT-Tiny模型达到了76.05%|81.05%|75.92%|82.55%的top-1准确率,为动态卷积研究创造了新的性能纪录)。另一方面,论文展示了KernelWarehouse的三个组件对于模型准确性和参数效率的性能提升至关重要,而且KernelWarehouse甚至可以在减小ConvNet的模型大小同时提高模型准确性(例如,论文的ResNet18模型相对于基准模型减少了65.10%的参数,仍实现了2.29%的绝对top-1准确率增益),并且也适用于Vision Transformers(例如,论文的DeiT-Tiny模型达到了76.51%的top-1准确率,为基准模型带来了4.38%的绝对top-1准确率增益)。
Method
Motivation and Components of KernelWarehouse
对于一个卷积层,设 \(\mathbf{x} \in \mathbb{R}^{h \times w \times c}\) 为输入,具有 \(c\) 个特征通道, \(\mathbf{y} \in \mathbb{R}^{h \times w \times f}\) 为输出,具有 \(f\) 个特征通道,其中 \(h \times w\) 表示通道大小。普通卷积 \(\mathbf{y} = \mathbf{W}*\mathbf{x}\) 使用一个静态卷积核 \(\mathbf{W} \in \mathbb{R}^{k \times k \times c \times f}\) ,包含 \(f\) 个具有空间大小 \(k \times k\) 的卷积滤波器。动态卷积通过一个由注意力模块 \(\phi(x)\) 生成的 $ \alpha_{1},...,\alpha_{n}$ 权重的 \(n\) 个相同维度的静态卷积核 \(\mathbf{W}_1,...,\mathbf{W}_n\) 的线性混合取代普通卷积中的 \(\mathbf{W}\) 定义为:
正如之前讨论的那样,由于参数效率的缺点,通常将核数量 \(n\) 设置为 \(n<10\) 。论文的主要动机是重新制定这种线性混合学习范式,使其能够探索更大的设置,例如 \(n>100\) (比典型设置 \(n<10\) 大一个数量级),以推动动态卷积性能边界的提升,同时享受参数效率。为此,KernelWarehouse具有三个关键组成部分:核分区、仓库的构建与共享和对比驱动的注意力函数。
Kernel Partition
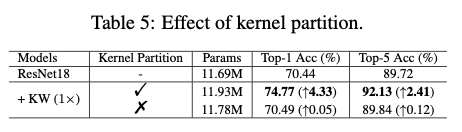
核分区的主要思想是通过利用同一个卷积层内的参数依赖性来减少核维度。具体而言,对于一个普通的卷积层,将静态卷积核 \(\mathbf{W}\) 沿着空间和通道维度依次划分为 \(m\) 个不相交的部分 \(\mathbf{w}_1\) ,..., \(\mathbf{w}_m\) ,称为"核单元",其具有相同的维度。为简洁起见,在这里省略了定义核单元维度的过程。核分区可以被定义为:
在核分区之后,将核单元 \(\mathbf{w}_1\) ,..., \(\mathbf{w}_m\) 视为"局部核",并定义一个包含 \(n\) 个核单元 \(\mathbf{E}=\{\mathbf{e}_1,...,\mathbf{e}_n\}\) 的"仓库",其中 \(\mathbf{e}_1\) ,..., \(\mathbf{e}_n\) 的维度与 \(\mathbf{w}_1\) ,..., \(\mathbf{w}_m\) 相同。然后,每个核单元 \(\mathbf{w}_1\) ,..., \(\mathbf{w}_m\) 都可以视为仓库 \(\mathbf{E}=\{\mathbf{e}_1,...,\mathbf{e}_n\}\) 的一个线性混合:
其中, \(\alpha_{i1}\) ,..., \(\alpha_{in}\) 是由注意力模块 \(\phi(x)\) 生成的依赖于输入的标量注意力。最后,普通卷积层中的静态卷积核 \(\mathbf{W}\) 被其对应的 \(m\) 个线性混合所取代。
由于核分区的存在,核单元 \(\mathbf{w_i}\) 的维度可以远小于静态卷积核 \(\mathbf{W}\) 的维度。例如,当 \(m=16\) 时,核单元 \(\mathbf{w_i}\) 中的卷积参数数量仅为静态卷积核 \(\mathbf{W}\) 的1/16。在预定的卷积参数预算 \(b\) 下,相比于现有的将线性混合定义为 \(n\) (例如 \(n=4\) )的"整体核"的动态卷积方法,这使得仓库很容易设置更大的 \(n\) 值(例如 \(n=64\) )。
Warehouse Construction-with-Sharing
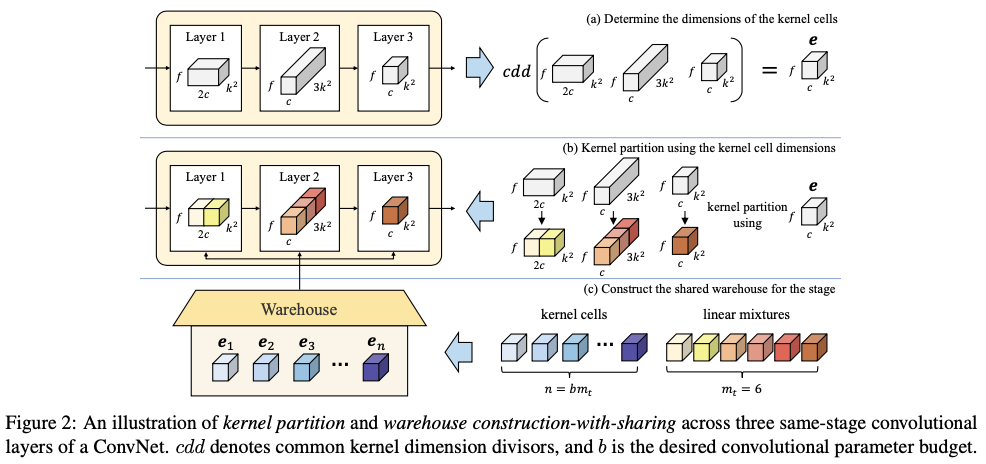
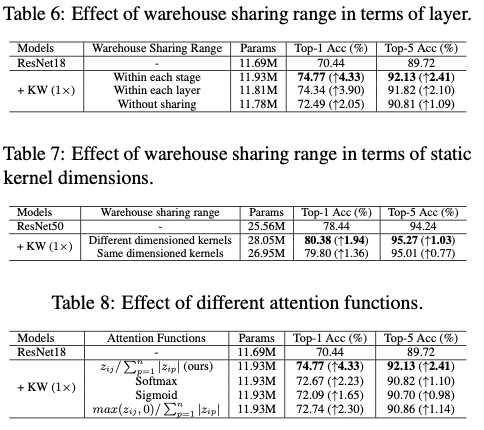
仓库的构建与共享的主要思想是通过简单地利用相邻卷积层之间的参数依赖关系,进一步改进基于仓库的线性混合学习公式,图2展示了核分区和仓库构建与共享的过程。具体而言,对于ConvNet的同阶段的 \(l\) 个卷积层,通过使用相同的核单元维度来构建一个共享仓库 \(\mathbf{E}=\{\mathbf{e}_1,...,\mathbf{e}_n\}\) 进行核分区。这不仅允许共享仓库具有较大的 \(n\) 值(例如 \(n=188\) ),与层特定的仓库(例如 \(n=36\) )相比,还可以提高表示能力。由于ConvNet的模块化设计机制(即可通过简单的值设定来控制阶段整体维度的缩放),可以简单地为所有同阶段的 \(l\) 个静态卷积核使用公共的维度除数(类似公约数的概念),作为统一的核单元维度来进行核分区。从而自然地确定了同阶段每个卷积层的核单元数量 \(m\) ,以及在给定期望的卷积参数预算 \(b\) 时共享仓库的 \(n\) 。。
-
Convolutional Parameter Budget
对于普通的动态卷积,相对于正常卷积来说,卷积参数预算 \(b\) 始终等于核数量。即 \(b==n\) ,且 \(n>=1\) 。当设置一个较大的 \(n\) 值,例如 \(n=188\) 时,现有的动态卷积方法得到的 \(b=188\) ,导致ConvNet主干模型大小增加约188倍。而对于KernelWarehouse,这些缺点得到了解决。设 \(m_{t}\) 为ConvNet同阶段的 \(l\) 个卷积层中核单元的总数(当 \(l=1\) 时, \(m_{t}=m\) )。那么,相对于正常卷积,KernelWarehouse的卷积参数预算可以定义为 \(b=n/m_{t}\) 。在实现中,使用相同的 \(b\) 值应用于ConvNet的所有卷积层,这样KernelWarehouse可以通过改变 \(b\) 值来轻松调整ConvNet的模型大小。与正常卷积相比:(1)当 \(b<1\) 时,KernelWarehouse倾向于减小模型大小;(2)当 \(b=1\) 时,KernelWarehouse倾向于获得相似的模型大小;(3)当 \(b>1\) 时,KernelWarehouse倾向于增加模型大小。
-
Parameter Efficiency and Representation Power
有趣的是,通过简单地改变 \(m_{t}\) (由核分区和仓库构建与共享控制),可以得到适当且较大的 \(n\) 值,以满足所需的参数预算 \(b\) ,为KernelWarehouse提供表示能力保证。由于这种灵活性,KernelWarehouse可以在不同的卷积参数预算下,在参数效率和表示能力之间取得有利的权衡。
Contrasting-driven Attention Function
在上述的表述中,KernelWarehouse的优化与现有的动态卷积方法在三个方面有所不同:(1)使用线性混合来表示密集的局部核单元,而不是整体的核(2)仓库中的核单元数量显著较大( \(n>100\) vs. \(n<10\) )(3)一个仓库不仅被共享用于表示ConvNet的特定卷积层的 \(m\) 个核单元,还被共享用于表示其他 \(l-1\) 个相同阶段的卷积层的每个核单元。然而,对于具有这些优化特性的KernelWarehouse,论文发现常见的注意力函数失去了其效果。因此,论文提出了对比驱动的注意力函数(CAF)来解决KernelWarehouse的优化问题。对于静态核 \(\mathbf{W}\) 的第 \(i\) 个核单元,设 \(z_{i1},...,z_{in}\) 为由紧凑型SE注意力模块 \(\phi(x)\) 的第二个全连接层生成的特征logits,则CAF定义为:
其中, \(\tau\) 是一个从 \(1\) 线性减少到 \(0\) 的温度参数,在训练初期阶段使用; \(\beta_{ij}\) 是一个二元值(0或1)用于初始化注意力; \(\frac{z_{ij}}{\sum^{n}_{p=1}{|z_{ip}|}}\) 是一个归一化函数。
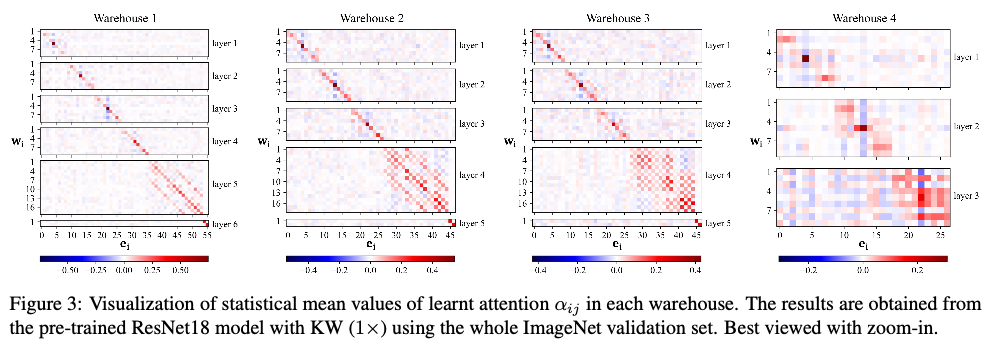
CAF依赖于两个巧妙的设计原则:(1)第一项确保在训练开始时,共享仓库中的初始有效核单元( \(\beta_{ij}=1\) )被均匀地分配到ConvNet的所有 \(l\) 个相同阶段的卷积层的不同线性混合中;(2)第二项使得注意力既可以是负值也可以是正值,不同于常见的注意力函数总是产生正的注意力。这鼓励优化过程学习在共享同一仓库的 \(l\) 个相同阶段卷积层上的所有线性混合中形成对比度和多样性的注意力分布(如图3所示),从而保证提高模型性能。
在CAF初始化阶段, \(l\) 个相同阶段卷积层中的 \(\beta_{ij}\) 的设置应确保共享仓库能够:(1)在 \(b\geq1\) 时,对于每个线性混合至少分配一个指定的核单元( \(\beta_{ij}=1\) );(2)在 \(b<1\) 时,对于每个线性混合至多分配一个特定的核单元( \(\beta_{ij}=1\) )。论文采用一个简单的策略,在同阶段的 \(l\) 个卷积层的每组线性混合( \(m_{t}\) 个权重)中分配共享仓库中的全部 \(n\) 个核单元之一,且不重复。当 \(n < m_{t}\) 时,一旦 \(n\) 个核单元被使用完,让剩余的线性混合始终使 \(\beta_{ij}=0\)。
Visualization Examples of Attentions Initialization Strategy
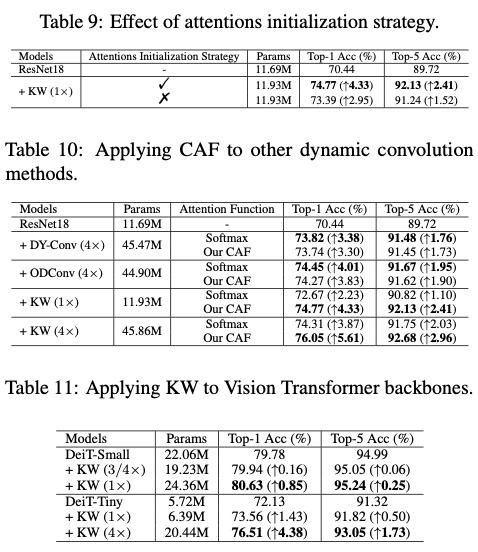
使用 \(\tau\) 和 \(\beta_{ij}\) 的注意力初始化策略来构建KernelWarehouse模型。在训练的早期阶段,这个策略强制标量注意力是one-hot的形式,以建立核单元和线性混合之间的一对一关系。为了更好地理解这个策略,分别提供了KW( \(1\times\) )、KW( \(2\times\) )和KW( \(1/2\times\) )的可视化示例。
-
Attentions Initialization for KW (\(1\times\))
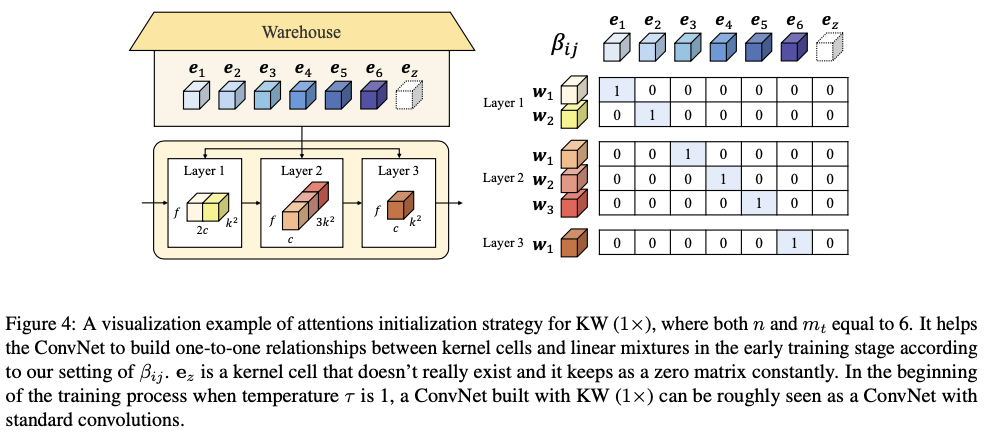
在图4中展示了KernelWarehouse( \(1\times\) )的注意力初始化策略的可视化示例。在此示例中,一个仓库 \(\mathbf{E}=\{\mathbf{e}_{1},\dots,\mathbf{e}_{6},\mathbf{e}_{z}\}\) 被共享给3个相邻的卷积层,它们的核维度分别为 \(k\times k \times 2c \times f\) , \(k\times 3k \times c \times f\) 和 \(k\times k \times c \times f\) 。这些核单元的维度都是 \(k\times k \times c \times f\) 。请注意,核单元 \(\mathbf{e}_{z}\) 实际上并不存在,它一直保持为一个零矩阵。它仅用于注意力归一化,而不用于汇总核单元。这个核单元主要用于当 \(b<1\) 时的注意力初始化,不计入核单元数量 \(n\) 。在训练的早期阶段,根据设定的 \(\beta_{ij}\) ,明确强制每个线性混合与一个特定的核单元建立关系。如图4所示,将仓库中的 \(\mathbf{e}_{1},\dots,\mathbf{e}_{6}\) 中的一个分配给每个3个卷积层中的6个线性混合,没有重复。因此,在训练过程的开始阶段,当温度 \(\tau\) 为1时,使用KW( \(1\times\) )构建的ConvNet大致可以看作是一个标准卷积的ConvNet。
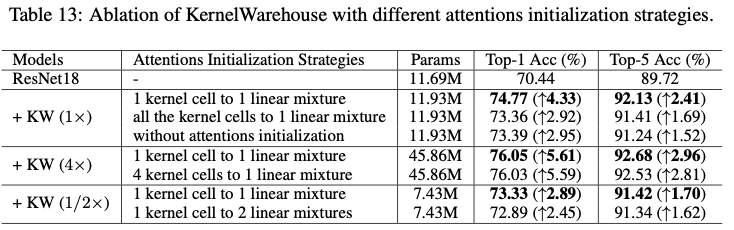
这里,论文将其与另一种替代方案进行了比较。在这种替代策略中,将所有 \(\beta_{ij}\) 设为1,强制每个线性混合与所有核单元均等地建立关系。全连接策略展示了与不使用任何注意力初始化策略的KernelWarehouse相似的表现,而论文提出的策略在top-1增益方面优于它1.41%。
-
Attentions Initialization for KW (\(2\times\))
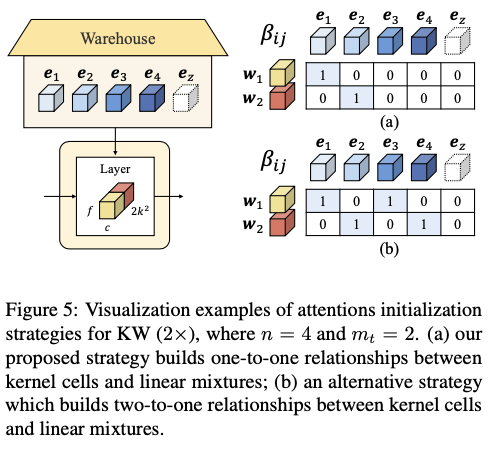
对于 \(b>1\) 的KernelWarehouse,采用与KW( \(1\times\) )中使用的相同的注意力初始化策略。图5a展示了KW( \(2\times\) )的注意力初始化策略的可视化示例。为了建立一对一的关系,将 \(\mathbf{e}_{1}\) 分配给 \(\mathbf{w}_{1}\) ,将 \(\mathbf{e}_{2}\) 分配给 \(\mathbf{w}_{2}\) 。当 \(b>1\) 时,另一种合理的策略是将多个核单元分配给每个线性混合,而且不重复分配,如图5b所示。使用基于KW( \(4\times\) )的ResNet18主干网络来比较这两种策略。根据表13中的结果,可以看到一对一策略表现更好。
-
Attentions Initialization for KW (\(1/2\times\))
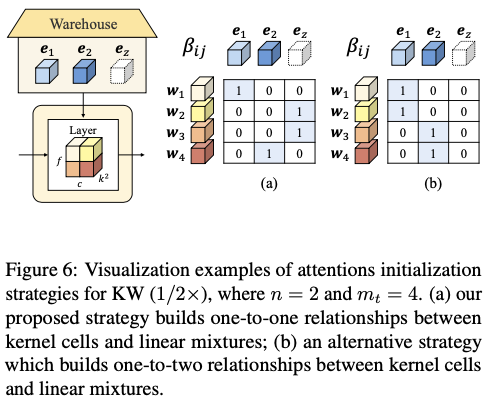
对于 \(b<1\) 的KernelWarehouse,核单元的数量少于线性混合的数量,这意味着不能采用 \(b\geq1\) 中使用的相同策略。因此,只将仓库中的总共 \(n\) 个核单元分别分配给 \(n\) 个线性混合,而且不重复分配。将 \(\mathbf{e}_{z}\) 分配给所有剩余的线性混合。图6a展示了KW( \(1/2\times\) )的可视化示例。当温度 \(\tau\) 为1时,使用KW( \(1/2\times\) )构建的ConvNet可以大致看作是一个具有分组卷积(groups=2)的ConvNet。论文还提供了我们提出的策略和另一种替代策略的比较结果,该替代策略将 \(n\) 个核单元中的一个分配给每两个线性混合,而且不重复分配。如表13所示,一对一策略再次取得了更好的结果,表明为 \(b<1\) 引入额外的核 \(\mathbf{e}_{z}\) 可以帮助ConvNet学习到更合适的核单元和线性混合之间的关系。当将一个核单元分配给多个线性混合时,ConvNet无法很好地平衡它们之间的关系。
Design Details of KernelWarehouse
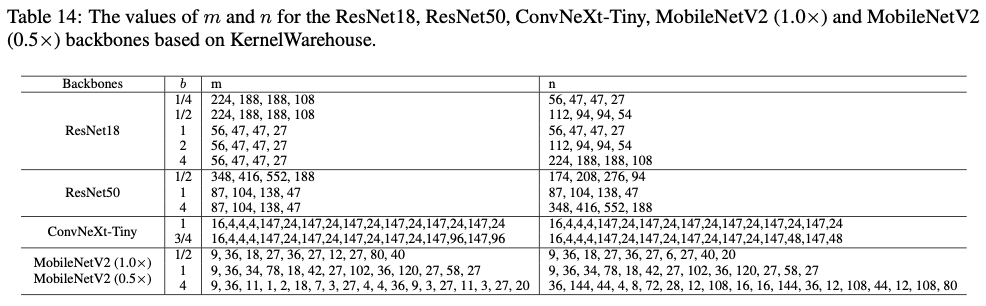
训练模型的每个相应的 \(m\) 和 \(n\) 的值在表14中提供。请注意, \(m\) 和 \(n\) 的值根据设置的核单元维度、共享仓库的层以及 \(b\) 自然确定。

算法1展示了给定一个ConvNet主干网络和所需的卷积参数预算 \(b\) 时,KernelWarehouse的实现。
-
Design details of Attention Module of KernelWarehouse
在现有的动态卷积方法中,KernelWarehouse也采用了一种紧凑的SE类型结构作为注意力模块 \(\phi(x)\) (如图1所示),用于生成对仓库中的核单元进行加权的注意力。对于任何具有静态核 \(\mathbf{W}\) 的卷积层,按通道的全局平均池化(GAP)操作开始,将输入 \(\mathbf{x}\) 映射为特征向量,然后经过一个全连接(FC)层,修正线性单元(ReLU),另一个FC层和一个对比驱动的注意力函数(CAF)。第一个FC层将特征向量的长度缩减为原来的1/16,第二个FC层并行生成 \(m\) 组 \(n\) 个特征logits,最终由我们的CAF逐组进行归一化。
-
Design details of KernelWarehouse on ResNet18
在KernelWarehouse中,一个仓库被分享给所有相同阶段的卷积层。虽然这些层最初根据其输入特征图的分辨率被划分到不同的阶段,但在KernelWarehouse中,这些层根据其核维度被划分到不同的阶段。在论文的实现中,通常将每个阶段的第一层(或前两层)重新分配到前一个阶段。

表15展示了基于KW( \(1\times\) )的ResNet18主干网络的一个示例。通过重新分配层,可以避免由于最大公共维度因子造成的所有其他层都必须根据单个层进行划分的情况。对于ResNet18主干网络,将KernelWarehouse应用于除第一层以外的所有卷积层。在每个阶段,相应的仓库被共享给其所有的卷积层。对于KW( \(1\times\) )、KW( \(2\times\) )和KW( \(4\times\) ),使用静态核的最大公共维度因子作为核分割的统一核单元维度。对于KW( \(1/2\times\) )和KW( \(1/4\times\) ),使用最大公共维度因子的一半。
-
Design details of KernelWarehouse on ResNet50
对于ResNet50主干网络,将KernelWarehouse应用于除前两层以外的所有卷积层。在每个阶段,相应的仓库被共享给其所有的卷积层。对于KW( \(1\times\) )和KW( \(4\times\) ),使用静态核的最大公共维度因子作为核分割的统一核单元维度。对于KW( \(1/2\times\) ),使用最大公共维度因子的一半。
-
Design details of KernelWarehouse on ConvNeXt-Tiny
对于ConvNeXt主干网络,将KernelWarehouse应用于所有的卷积层。将ConvNeXt-Tiny主干网络第三阶段的9个Block划分为具有相等块数的三个阶段。在每个阶段中,相应的三个仓库分别共享给点卷积层、深度卷积层和下采样层。对于KW( \(1\times\) ),使用静态核的最大公共维度因子作为核分割的统一核单元维度。对于KW( \(3/4\times\) ),将KW( \(1/2\times\) )应用于ConvNeXt主干网络后两个阶段的点卷积层,使用最大公共维度因子的一半。对于其他层,使用最大公共维度因子的KW( \(1\times\) )。
-
Design details of KernelWarehouse on MobileNetV2
对于基于KW( \(1\times\) )和KW( \(4\times\) )的MobileNetV2(\(1.0 \times\))和MobileNetV2(\(0.5 \times\))主干网络,将KernelWarehouse应用于所有的卷积层。对于基于KW( \(1\times\) )的MobileNetV2(\(1.0 \times\),\(0.5 \times\)),在每个阶段,相应的两个仓库分别共享给点卷积层和深度卷积层。对于基于KW( \(4\times\) )的MobileNetV2(\(1.0 \times\),\(0.5 \times\)),在每个阶段,相应的三个仓库分别共享给深度卷积层、通道扩展的点卷积层和通道减少的点卷积层,使用静态核的最大公共维度因子作为核分割的统一核单元维度。对于基于KW( \(1/2\times\) )的MobileNetV2(\(1.0 \times\))和MobileNetV2(\(0.5 \times\)),考虑到注意力模块和分类器层的参数以减少总参数数量。将KernelWarehouse应用于所有深度卷积层、最后两个阶段的点卷积层和分类器层。为点卷积层设置 \(b=1\) ,而对于其他层设置 \(b=1/2\) 。对于深度卷积层,使用静态核的最大公共维度因子作为核分割的统一核单元维度。对于点卷积层,使用最大公共维度因子的一半。对于分类器层,使用维度为 \(1000 \times 32\) 的核单元维度。
Discussion
需要注意的是,采用多分支组卷积的分裂与合并策略已经广泛应用于许多ConvNet架构中。虽然KernelWarehouse在核分区中也使用了参数分割的思想,但重点和动机与它们明显不同。此外,由于使用普通卷积,KernelWarehouse也可以用来提高它们的性能。
根据其公式,当在核分区中统一设置 \(m=1\) (即每个仓库中的所有核单元都具有与普通卷积中的静态核 \(\mathbf{W}\) 相同的维度)并且在仓库共享中设置 \(l=1\) (即每个仓库仅用于特定的卷积层)时,KernelWarehouse将退化为普通的动态卷积。因此,KernelWarehouse是动态卷积的一种更通用形式。
在公式中,KernelWarehouse的三个关键组成部分密切相互依赖,它们的联合正则化效应导致了在模型准确性和参数效率方面显著提高的性能,这一点在实验部分通过多个剔除实验证明了。
Experiments
Image Classification on ImageNet Dataset
-
ConvNet Backbones
选择了来自MobileNetV2、ResNet和ConvNeXt的五种ConvNet骨干网络进行实验,包括轻量级和较大的架构。
-
Experimental Setup
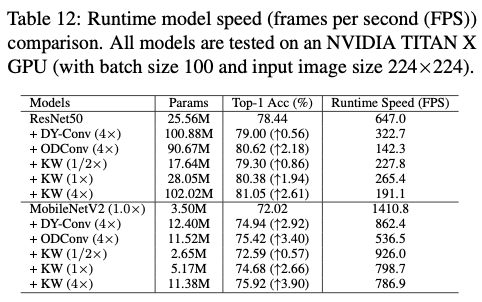
在实验中,与相关方法进行了多种比较,以证明其有效性。首先,在ResNet18骨干网络上,与各种最先进的基于注意力的方法进行了比较,包括:(1)SE、CBAM和ECA,这些方法专注于特征重新校准;(2)CGC和WeightNet,这些方法专注于调整卷积权重;(3)CondConv、DY-Conv、DCD和ODConv,这些方法专注于动态卷积。其次,选择DY-Conv和ODConv作为关键参考方法,因为它们是最优秀的动态卷积方法,与论文的方法最密切相关。在除了ConvNeXt-Tiny之外的所有其他ConvNet骨干网络上,将KernelWarehouse与它们进行比较(因为在ConvNeXt上没有公开可用的实现)。为了进行公平的比较,所有方法都使用相同的训练和测试设置,使用公共代码实现。在实验中,使用 \(b\times\) 来表示相对于正常卷积的每个动态卷积方法的卷积参数预算。
-
Results Comparison with Traditional Training Strategy
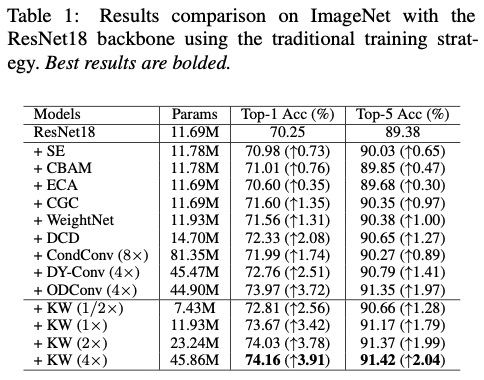
-
Results Comparison with Advanced Training Strategy
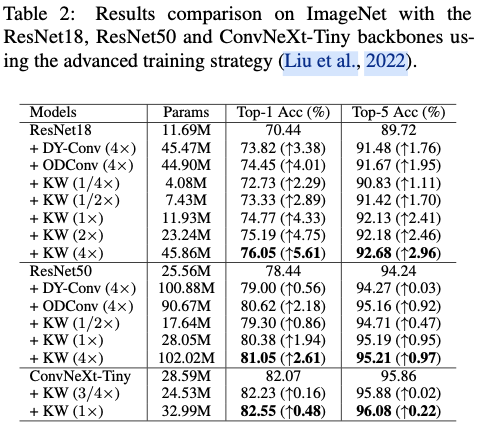
-
Results Comparison on MobileNets
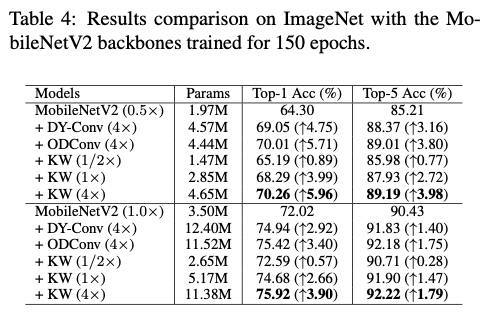
Detection and Segmentation on MS-COCO Dataset
为了评估通过论文方法训练的分类骨干模型对下游目标检测和实例分割任务的泛化能力,在MS-COCO数据集上进行了比较实验。
-
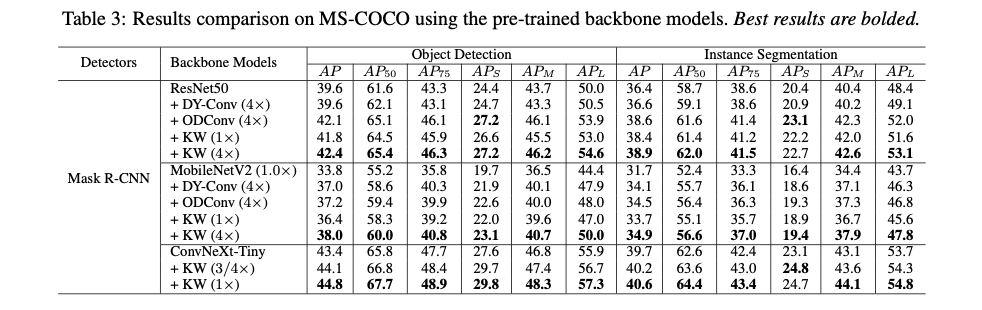
Experimental Setup
采用Mask R-CNN作为检测框架,并使用不同的动态卷积方法构建了ResNet50和MobileNetV2( \(1.0\times\) )作为骨干网络,并在ImageNet数据集上进行了预训练。然后,所有模型都在MS-COCO数据集上使用标准的 \(1\times\) 调度进行训练。为了进行公平比较,对所有模型采用相同的设置,包括数据处理流程和超参数。
-
Results Comparison
Ablation Studies
如果本文对你有帮助,麻烦点个赞或在看呗~
更多内容请关注 微信公众号【晓飞的算法工程笔记】