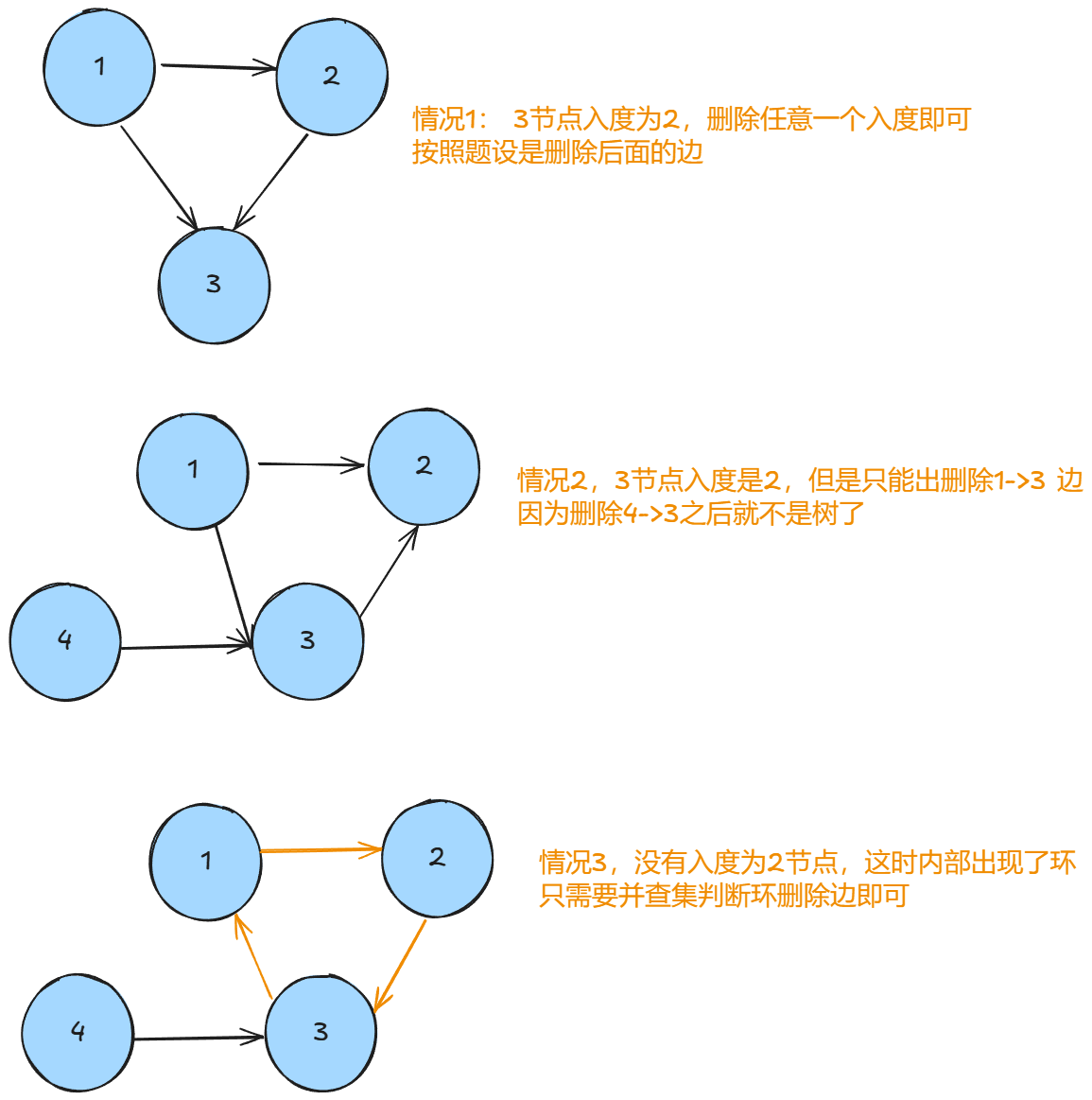
yolo v1-v5与目标检测
深度学习经典检测方法概述
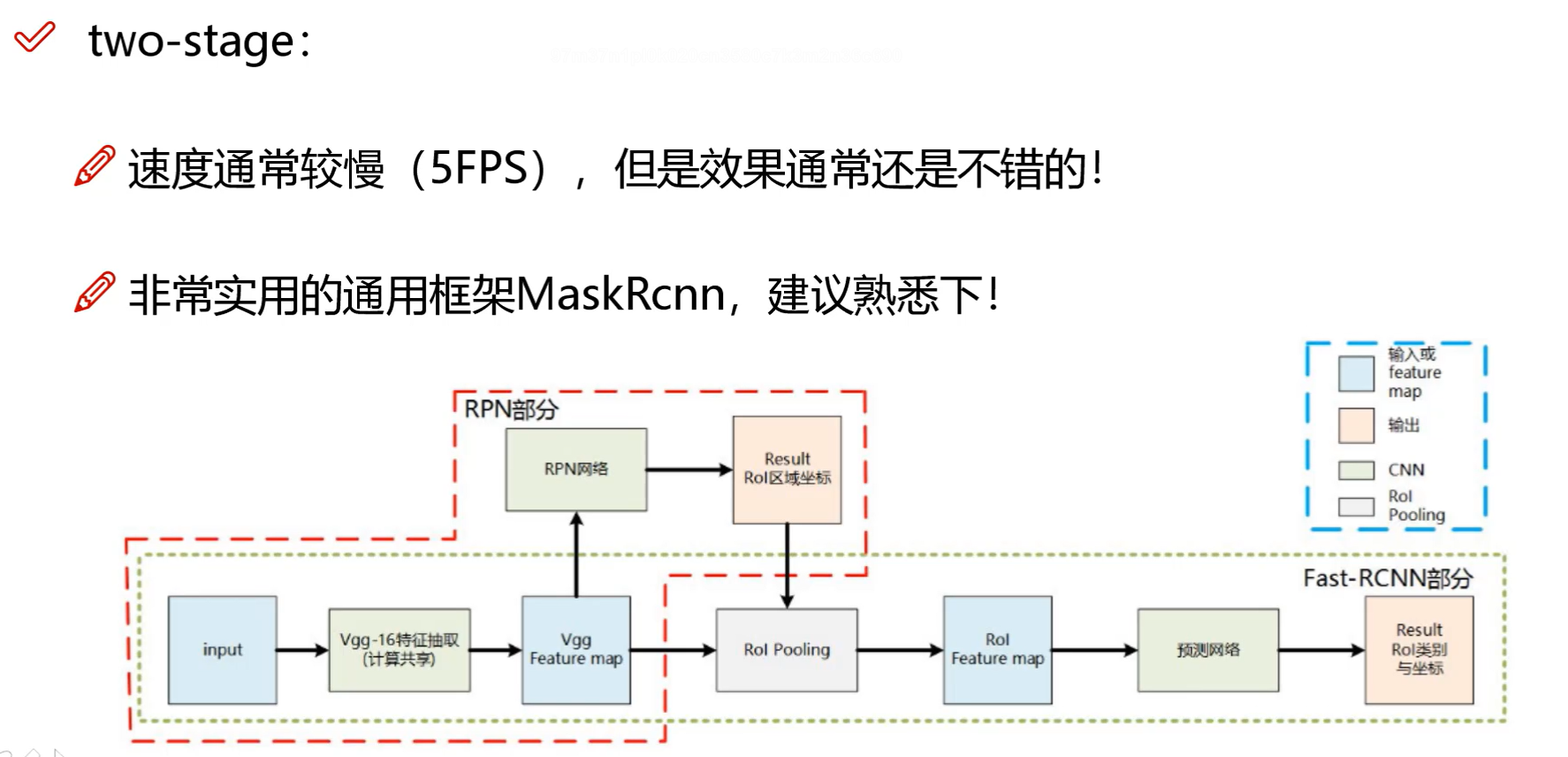
目标检测的两种方法

从yolov1开始讲解,v2,v3都是在此基础上
单阶段目标检测,需要输出的就是四个值(x,y,w,h) 这样看起来很像是一个回归任务

而双阶段目标检测,是先选出候选区域,在进行预测,具体细节可以看完之前文章,物体检测Faster Rcnn系列
不同阶段算法优缺点分析
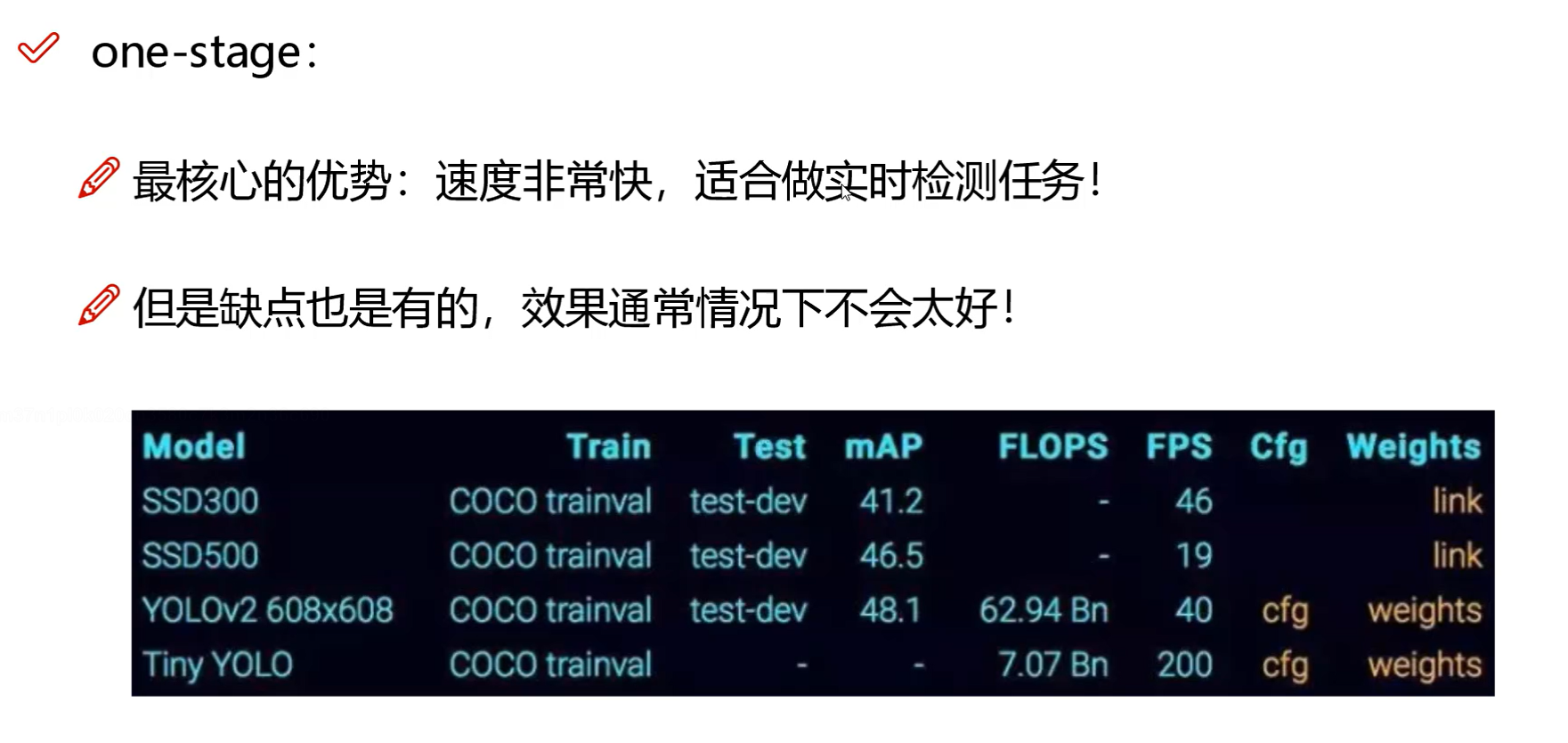
在使用yolo的时候可以自己去控制网络的复杂度,网络越复杂,速度越慢
fps:网络每秒可以处理(检测)多少帧 (多少张图片),即每秒内可以处理的图片数量,假设目标网络处理1帧要0.01s,此时FPS就是1/0.01=100。
IoU指标计算

map值

查准率和查全率是机器学习里的内容,大家都不陌生

AP(Average Precision)——不同召回率上的平均precision,在某个类别下的检测,在检测出正确目标之前,是不是出现了很多判断失误。AP越高,说明检测失误越少。对于所有类别的AP求平均就得到mAP了。详细介绍

将每张测试图片进行检测后,会得到一系列预测边界框集合,然后将这个预测边界框集合按照置信度降序排序。对于某一张测试图片,我们先计算该图片上人脸类别的预测边界框和真实的边界框的重叠度(IOU),当重叠度(IOU)大于设定的阈值(一般为0.5,可以自己设置)则将该边界框记作真正例(TP),否则记为假正例(FP)。
首先按照置信度进行降序排序,之后计算不同召回率(Recall)下的精准率(Precision)值。
0.9时,TP=1,FP=0。 Precision=1,Recall = TP / GT(总真实框数)= 1/3
0.8时,Precision=1/2,Recall = TP / GT(总真实框数)= 1/3
0.7 时 Precision=2/3 ,Recall = TP / GT(总真实框数)= 2/3
每一个置信度,我们都能算出对应的精度和召回率。这样我们就有了一组Precision、Recall值[(1,1/3),(1/2,1/3),(2/3,2/3)]。
详细解析

mAP越大越好
YOLO-V1整体思想与网络架构

yolov1是16年的产品

首先就是把图片划分了n×n的网格,取对象的中点,然后将这个对象分配给包含对象中点的格子。对象检测中存在的一个问题是每个格子只能检测出一个对象,如果你想让一个格子检测出多个对象,你可以这么做,就是使用anchor box这个概念,如果行人的中点和汽车的中点几乎在同一个地方,两者都落入到同一个格子中。所以对于那个格子,如果 y 输出这个向量(图片下的)你可以检测这三个类别,行人、汽车和摩托车,它将无法输出检测结果,所以我必须从两个检测结果中选一个。而anchor box的思路是,这样子,预先定义两个不同形状的anchor box,或者anchor box形状,你要做的是把预测结果和这两个anchor box关联起来。一般来说,你可能会用更多的anchor box,可能要5个甚至更多,但对于这个,我们就用两个anchor box,这样介绍起来简单一些。关于yolo详细原理可以看我之前文章

谁的IoU大,最后微调谁

在v1版本中,input大小是固定的,你对你的图像可以resize到448×448,通道改为3

前面的cov层就是提取特征,应该后面的版本中有改进,这里就不详细介绍,主要看后面几层,最后得到的7×7×30,7×7是指网格数量,30是每个网格有三十个值(这一点我之前文章有介绍)

前面的两个5,5就是B1 ,B2,后面20说明是预测类别有20个
至于计算机怎么知道,这30个值是什么意思,这就需要损失函数来了,通过定义损失函数,计算机就可以明白这些值的含义

定义损失函数

这里w和h加根号原因是

对于大小不同的物体,1单位偏差,对于大物体可能没有什么影响,但是对于小物体(2个单位大小),1单位大小的偏差,影响很大。所以这样就可以让它更重视一点比较小的物体,大物体粗糙一点问题不大,
 $$
y=\sqrt{\smash[b]{x}}
$$
$$
y=\sqrt{\smash[b]{x}}
$$
x越小变化越明显,所以对较小的w更加敏感
对于置信度的损失函数有两部分,

因为样本中检测的 物体少,而背景(无检测物体较多),因此正负样本比例不均衡,如果不设置权重,负样本(无目标图像)对结果影响较重。
所以损失函数就是这三种误差相加。

yolov1小物体比较难检测,还有重叠在一起的物体很难检测,一个位置有一个狗,又有一只猫。三就是如果一个物体有多个标签(狗,哈士奇)

YOLO-V2改进细节详解
yolov2论文

每一个cov后都加上一个bn


v2使用了DarkNet网络(借鉴了VGG和ResNet)

最后图像相当于原始图片

v2最后输出的特征框13×13,v1是7×7,v2的网格比v1大
基于聚类来选择先验框尺寸

faster-rnn中先选框都是自己事先设定的,不一定符合数据集
v2基于聚类来选择先验框尺寸,比如COCO数据集中有100万个真实的数据框

比如使用k-means聚成5类,每一个类都有一个中心点,中心点是实际的值(h,w)
这里注意距离的定义不是欧式距离(因为欧式距离可能和框的大小有关),而是用1-IOU

v1中每个格产生2种框,v2每个格产生5种框

引入anchor,mAP没有什么变换,因为虽然预测框多了,但是不一定准确,不过recall值提升了。
偏移量计算和坐标还原

v2中进行的改进

$C_x,C_y$就是原本格子的位置,比如3,3,那么中心点就是3+$\sigma(t_y)$,由于$\sigma(t_y)$位于0-1之间,所以最终预测的$b_x,b_y$不会超出这个格子,偏移不至于太多。
$p_h,p_w$是已知条件,聚类选择出来的框,是真实值和特征图的映射,真实值可能是(120,100)但是特征图只有13×13,$p_h,p_w$就是这个缩放。
总的来说v2中的偏移不是直接偏移,而是相对偏移,因此不会像v1那样学的预测框偏的很远。
感受野的作用
在卷积神经网络中,感受野(Receptive Field)是指特征图上的某个点能看到的输入图像的区域,即特征图上的点是由输入图像中感受野大小区域的计算得到的。神经元感受野的值越大表示其能接触到的原始图像范围就越大,也意味着它可能蕴含更为全局,语义层次更高的特征;相反,值越小则表示其所包含的特征越趋向局部和细节


之前可能听说过这么一种说法,比如人脸识别,刚开始cov1可能是是检测一些线条,cov2可能就是检测眼睛,cov3可能就是人脸,这就是因为感受野越来越大。


计算公式
你在论文中可能很少见上面说的这种7×7大的卷积核,这是为什么呢。

7×7×C,这个C是输入图像的通道数。使用小的卷积核除了参数少,每一次cov后都有bn,这样效果会更好
特征融合改进

最后一层的特征图可能丢失小目标,因此需要配合前面的特征图(感受野比较小),因为最后的检测结果想要大小通吃。
最终结果就是倒数第二层拆分的四个512和最后一层的1024拼接在一起,512×4+1024=3072。
此外输入的图像不一定都是一样的大小,这里就需要多尺度

经过一定epoch,改变输入图像大小,这样训练的模型有更好的适应能力,既可以在小分辨率检测检测到,也能在大分辨率情况下检测。
yolov3核心网络模型
v3版本改进概述

YOLOv3不像v2对许多细节进行改进,而是对网络结构进行了改进

v1中先验框有2种,v2有5种,v3中有9种。softmax是返回概率最高的结果,但是有些任务不一定非要输出某一个结果,比如多标签任务,比如一个物体不知有一个标签是动物,还是哺乳动物,还是狗,一个物体可以打多个标签。比如满足100个类中的两三个。
其实这里的改进就是把多分类改为很多个二分类。
多scale方法改进与特征融合
v2中为了兼顾大小物体的检测,把前面的特征图和最后的特征图拼接到一起,但这样做效果其实不是特别好,因为术业有专攻,前面擅长检测小物体和后面擅长大物体简单拼接到一起做一个任务,不如让他们各自做自己擅长的工作。

前面的特征图感受野比较小,就预测小目标,后面的特征图感受野比较大就预测大目标。每一个scale都有三个box(预选框)。注意这里的52×52和26×26并不是直接就把前面的特征图拿来预测,还需要参考后面的特征图。
经典变换方法对比分析

左边的图像金字塔在之前比较流行,但是在yolo中就不太合适,因为需要把图像改变分辨率分三次输入,yolo特点就是速度快,mAP可以稍微低一点点。右图就是v1

左边就是每个特征图各自预测自己 的。但是这样效果并不好,13×13的特征图可以很好的预测大目标,但是26×26和52×52的未必能很好的预测中小目标,因为缺乏全局的信息。所以可以把13×13的特征图进行上采样(线性差值),变成26×26然后和26×26的特征图进行融合。
残差连接方法

yolov3虽然说效果很好,其实是融合了好多当时比较好的思想,这些思想并不是他自己提出来的,是其他人文章任务中用到的,他不过是把这些思想融入到自己的大模型中,使得效果更好。残差块的思想就是至少不比原来差,比如20个残差块,只要有5个有提升,那就比之前性能好。

这里预测中目标时,对最后一次特征图上采样,然后卷积得到26×26×256加上前面特征图的26×26×512,256+512=768。

先验框设计改进

13×13就是网格数,v3有三种13,26,52。3是三个预选框,85由三部分组成,80+4+1,4是x,y,w,h,1是confidence置信度,80是80个类别。

v3进行聚类后选出9中先验框,大的先验框分给13×13的特征图。而v2中是每个格子不管大小都是5个先验框

softmax层改进

softmax预测值越接近1损失越小。v3中每一个类进行二分类,是或不是。最后设置一个阈值,比如0.7,大于0.7的都表示有

项目实战基于V3版本
yolov3.cfg中
1 route层

-4表示与倒数第四层的拼接。

2 shortcut层


-3表示与往上第三层(从下到上),直接简单相加,不是维度拼接。
3 yolo层
因为和v2一样没有全连接层,输入图像可以任意大小(可以被32整除)
其他的就不详细介绍了(v3用的比较少了),感兴趣的可以看我的github项目
进阶建议论文+源码(论文中有表明代码地址的)
YOLO-V4

因为yolo的作者(v1-v3)发现美国把yolov3算法用于军方,这不是作者希望看见的事情,所以就不再更新了。v4的作者可以说是劳模了,把当下流行的算法全部融合到yolov4里了

之前像google和facebook这些大厂发的文章动不动就是TPU,显存要求也特别高,这些设备的性能感觉就不是一般人能用的
数据增强策略分析BOF

马赛克数据增强,四张图像分别做上面的图像增强,然后拼接在一起。在之前的任务中,如果只有一张显卡,那么你的batchsize很难做的很大,但是现在一张图片就相当于4张图片了。

还有就是随机值代替图像区域,和随机隐藏图像的一些位置

DropBlock与标签平滑方法

之前的dropout感觉并没有增加太多的游戏难度,根据周围的像素点还是可以推断出目标

最后一点叫做标签平滑

就是不让标签这么绝对了,让网络学习过程中不是总是100%,留一点点余地,这样可以使网络抗过拟合能力稍微更强一点 。做法也很简单,指定一个参数,比如上图的0.1

损失函数遇到的问题

不相交的情况下IOU=0,那么会出现梯度消失的情况。

但是注意,GIOU适用于不重叠的情况。
CIOU损失函数定义

看起来DIOU已经相当不错了,但是v4里用的也不是DIOU,而是CIOU

v主要就是计算真实值和预测值之间的一个长宽比是否一致。
NMS细节改进
之前用NMS(非极大值抑制)删除多余的框

现在剔除候选框,除了考虑IOU又加上了中心点距离

SOFT-NMS和NMS的区别是,如果有很大的交并比不会直接删除,而是给它降分,比如绿色的候选框之前置信度是0.8,可能会降为0.4,这样就可能使我们的召回率更高一点。
SPP与CSP网络结构
之前主要是在数据层面做的改进,接下来更重点的是在网络结果上又做了哪些升级


注意yolo里的spp和何凯明大神提出的不同,这里的SPP虽然也叫SPP,但是作用更多的是实现局部特征和全局特征的featherMap级别的融合
接下来的CSP比较重要了,v3里面使用的是Resnet的思想,而v4中引入了CSP,CSP不仅可以和Resnet组合也可以和其他网络组合

特征图切分成两块的好处就是,特征图维度越高计算量越大,现在channel一分为二,计算量也减少了
SAM注意力机制模块

第一部分的channel
比如32×32×256的特征图,256个特征图的重要程度是一样的吗,比如用softmax对256个通道得到[0.6,0.3,0.5......]然后×在原来的特征图中,就好像有点加权的意思。然后在同一个channel中,不同位置的重要程度可能也不一样
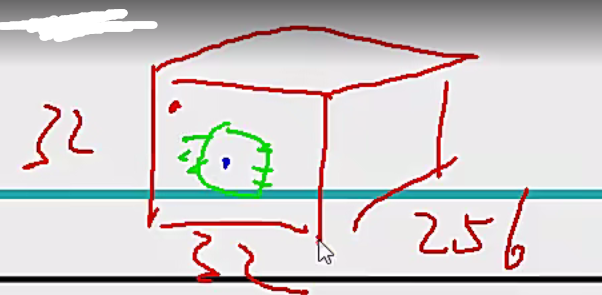
比如在这个channel里可能这里面蓝色的位置重要程度比红色的高。但是这样引入了很多的额外计算,v4中使用的是SAM,也就是只使用了位置的注意力,没有使用channel那部分

PAN模块解读

FPN就是高层特征和底层特征进行融合,但是缺点是只能高层特征和底层融合,没有低层和高层的融合,没有从下往上的

v4中的PAN也做了一点小改动

激活函数与整体架构总结
激活函数也有改动,yolov4里用的不是relu激活函数而是Mish

然后还有一些后处理方法,前面有说过yolo预测不是坐标的绝对值而是相对于网格的百分比,所以预测值都在0-1之间。如果坐标就在边界怎么办,我们知道sigmoid函数想取到1,坐标值需要非常非常大

整体网络架构

YOLO-V5
v5不像之前的yolo每一代都对应一篇论文,v5更偏工程性,v5算法和v4基本一样,只是进行一些微调,这里有一个yolov5的项目,可以先跑一下,然后再看源码是怎么做的
参数设置
源码解读,首先在train.py下的167行打个断点


path就是之前配置好的图像路径,imgz就是图像宽度,augment要不要做数据增强,hyp是训练过程的超参数

rect就是矩形策略,训练数据的时候传进来的数据都是正方形,比如32×32,24×24,800×800,但原始数据肯定不是正方形,比如原始数据是长方形w×h,为了使其成为正方形,需要padding0 ,
但是我们可不可以不resize成正方形,直接拿长方形进行训练呢。但是后面会详细介绍
cache_image是缓存,每次训练数据都要从路径用opencv去读,读标签,我们能不能把所有要读的东西都换存下来,下次直接加载。
single_cls,只有单类别的时候用到,单类别的时候把标签置0
stride就是输入到输出降采样的比例
读数据标签
接着往里走

这就是开始读数据,接着往下走

mosaic就是之前讲的,四张拼成一张
408行的 create_datasubset, extract_bounding_boxes, labels_loaded = False, False, False
是你有接下来的任务,比如检测到框后,需不需要把框中的特征提取出来,做后续操作
数据增强mosaic
接着往下走getitem里就定义了数据增强操作mosaic(四张拼成一张)

跳进去看load_mosaic函数,

可以发现拼图的时候,四张图不是各占四分之一,而是可能像右边这样

yc,xc是中心点坐标,indices是随机选择的另外三张图片下标(除了第一张0,又选择了32,15,63)拼成一张。

图像拼过来,如果图像小(红色),就填充,如果大(绿色),max(xc-w,0)就取0,多余的部分不要了
因为图像位置变换了,标签的值也要改变

padw,padh就是相对拼成后的图的左上角位置.
越界后,目标框也要修改,绿色是大图,红色是原先的图(越界)里面的小红框是目标检测框,越界的地方要修改


然后对调整后的大图还可以进行数据增强,比如旋转平移等(yolov5里是用opencv做的没使用torch里自带的transform)

网络结构
首先介绍一个网络结构可视化工具(软件和网页版)
1.配置好netron详情或者直接使用网页版
2.安装好onnx,pip install onnx即可
3.转换得到onnx文件,脚本原始代码中已经给出(models下的export.py)
4.打开onnx文件进行可视化展示(.pt文件展示效果不如onnx)
我们需要把模型文件.pt转换成.onnx yolov5已经给我们提供了转换的方法,就是models下的export.py。在export.py设置Edit Configurations
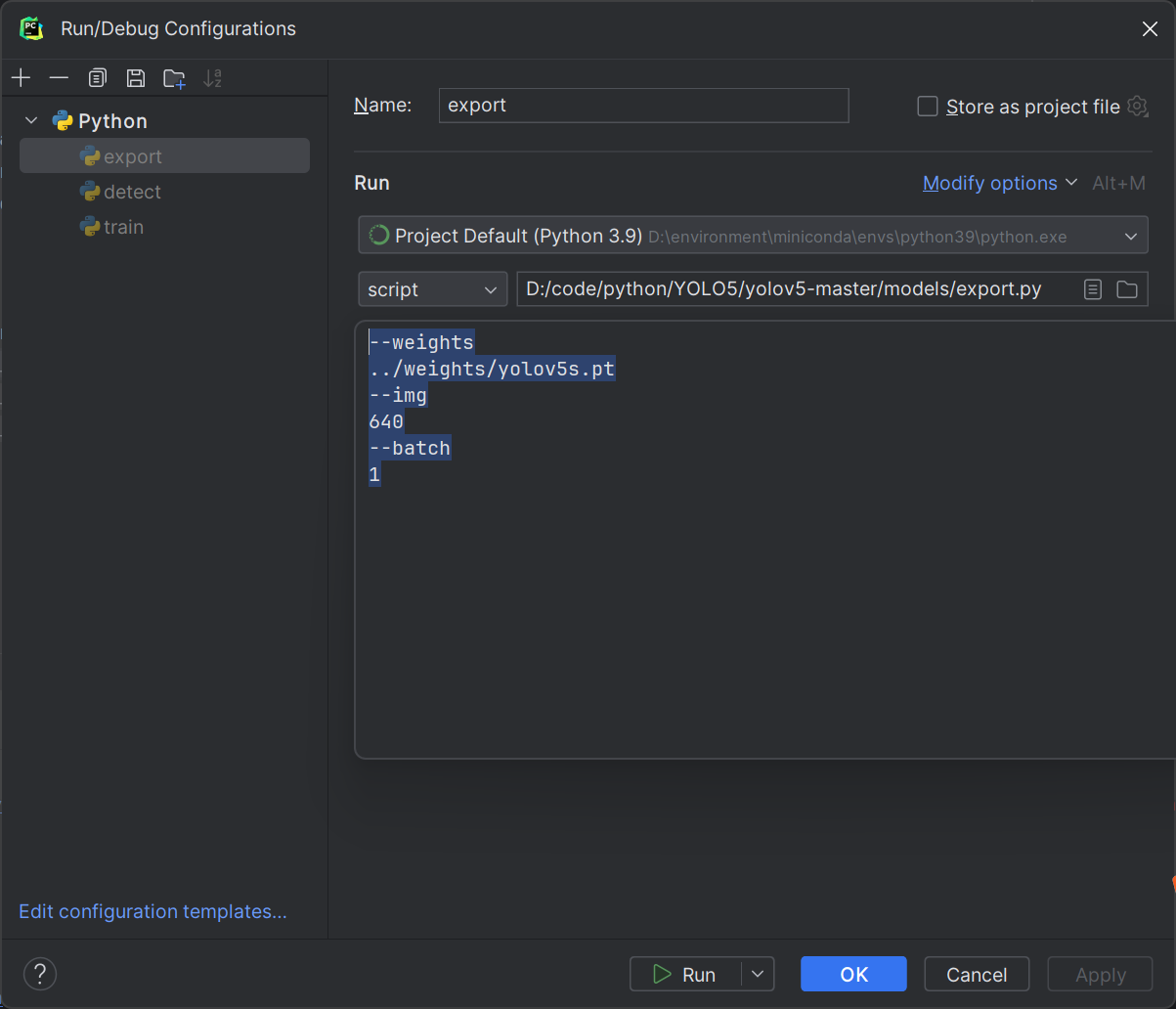
--weights
../weights/yolov5s.pt
--img
640
--batch
1
使用网页版打开yolov5s.onnx

网络配置文件在models下,比如yolov5s.yaml

number为1的不会处理,但是9会×1/3。
width_multiple表示卷积核的个数,

也就是我们实际只能得到32个特征图

[from, number, module, args]
from表示输入是什么,-1表示上一层。
number表示做几层,别忘了乘上depth_multiple
module就是这一层的名字
args表示参数,channel和卷积核的个数,stride
回到刚才的网络结构图,点击images可以显示具体信息

focus层的目的就是加速,原始图像H和W比较大,卷积计算比较耗时


卷积后面还跟一个add和clip,因为v5中使用的激活函数是Hardswish

接着往下走

BottleneckCSP的number虽然为3,但是还要乘上depth_multiple。所有最终结果是1
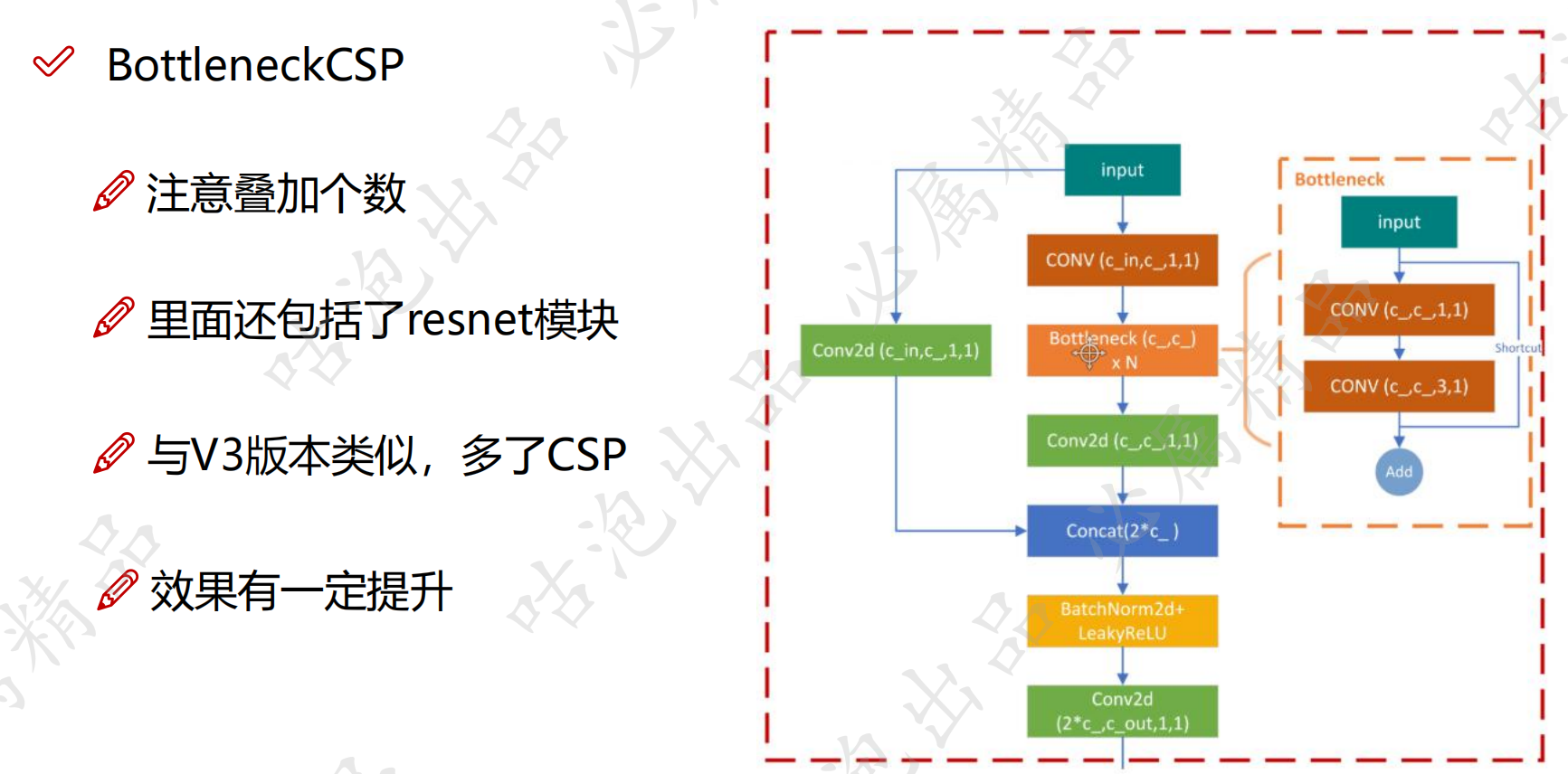
BottleneckCSP不仅仅做了csp,还在Bottleneck里有一个残差的结构
models下有个文件yolo.py在这里进行模型的初始化,common.py中是具体模块的实现
spp层

5,9,13指的是选择多大一个区域进行maxpooling,划分成3×3网格,5×5,13×13
在common.py下的spp类下的forward方法打上断点

它这个kernel_size和padding的设置刚好保证特征图大小不变。下面是spp层的网络结构

再次强调这里的spp和何凯明大神提出的不同,这里的SPP虽然也叫SPP,但是作用更多的是实现局部特征和全局特征的featherMap级别的融合
head层
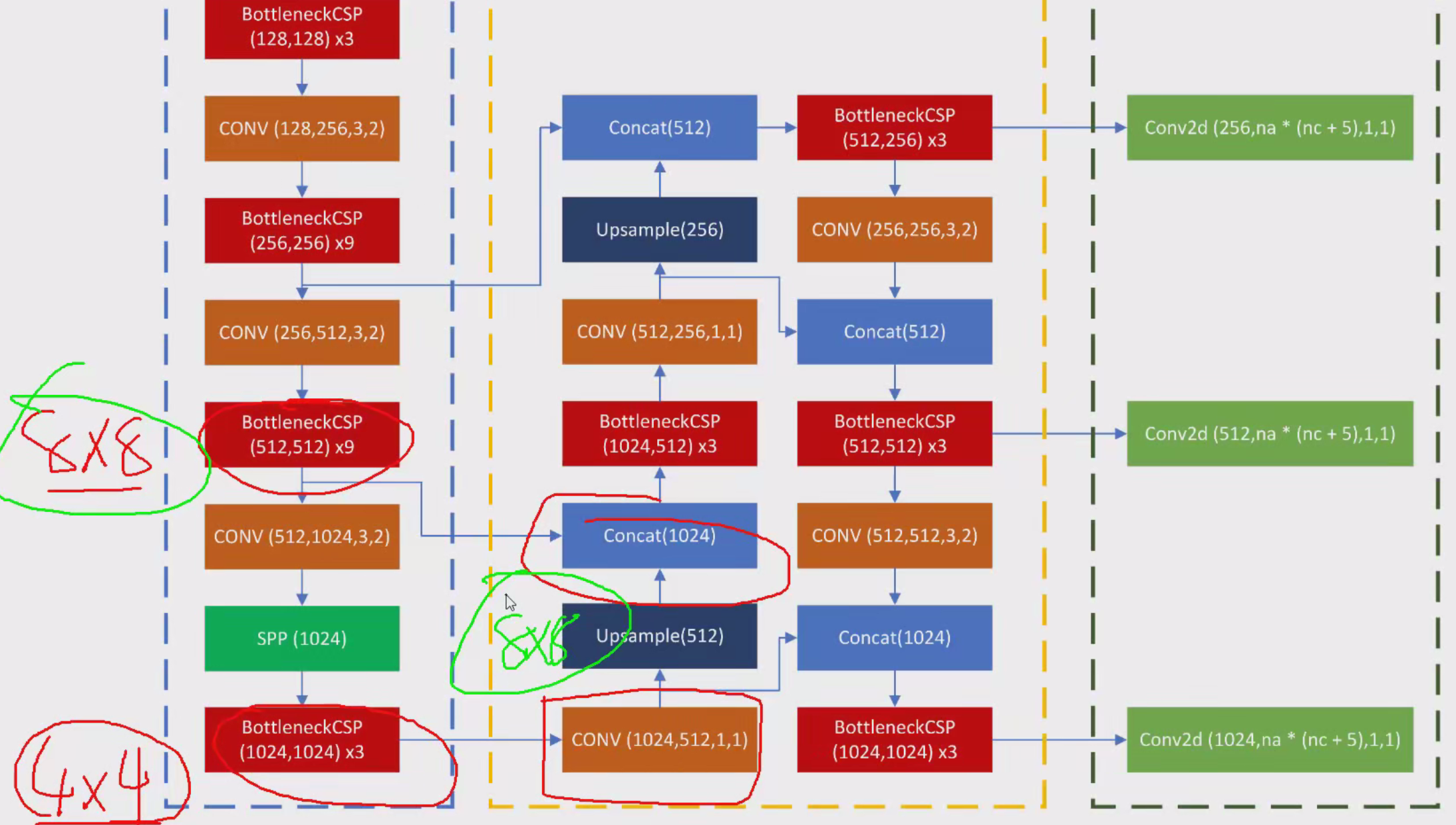
左边的蓝色框的就是之前讲的特征提取部分,最后的BottleneckCSP经过卷积后上采样和前面的BottleneckCSP在channel上拼接。那我们不仅想让高层特征和低层拼接,还想让低层和高层拼接,那需要从新跑一遍左边的网络吗?那样是不是计算量太大了,所以,我们在黄色框里直接接着走了一遍

这样从上到下,从下到上都包括了。
最后右边的绿框就是检测头,v3里面也有,na是anchors个数,nc是类别数,5(置信度+4个坐标值)
你可以在yolo.py下加一行代码,输出特征层大小,看看每一步的流程

最后的detect连接位置不同,分别是17层,20,23

超参数解读
yolov5-master\data下有一些配置文件hyp.scratch.yaml

命令行参数介绍
train.py下的
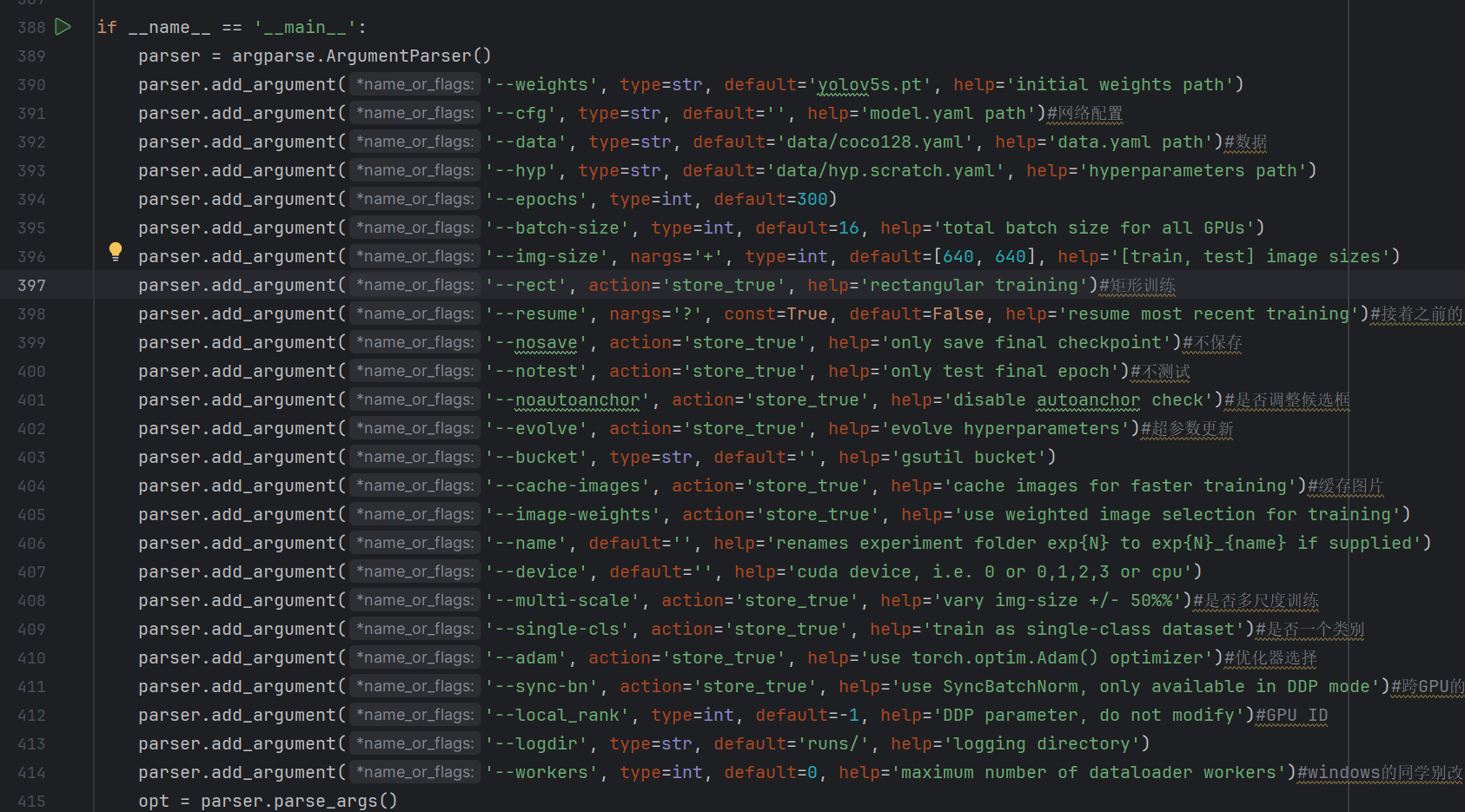
--weights 就是要不要用别人训练好的参数接着训练
--cfg 网络配置结构
--data 数据
--hyp 刚才上面的超参数
--img-size 把输入图像resize成多大,默认640×640
--resume 要不要接着之前的训练,代码在训练过程会保留日志文件,可以指定接着之前的哪次训练
--image-weights 数据样本不平衡,有哦类别多有的类别少,可以指定类别权重项
--local_rank 多卡的时候指定GPU id
--logdir 指定日志文件
训练流程

yolov5有个run文件夹

label.png标签分布情况
train_batch0.jpg中间训练的结果

最好提前下载好模型文件
接着往下走,需不需要做迁移学习,冻住一些层,但是yolov5好像不需要,即使你的数据集很小,训练效果也还不错

下面nbs的意思是,64/batchsize=4,正常情况是一个batchsize更新一次,但这里是做四次batchsize才更新一次参数

yolov5考虑了很多种情况,单机多卡,多机多卡

接着往下走

pytorch1.6版本以上内置了混合精度方法,fp32与fp16混合 提速比较多。

v5项目地址