Yolo第Y2周:如何正确解读YOLO算法训练结果的各项指标
- 🍨 本文为🔗IT男的一人企业中的学习记录博客
- 🍖 原作者:[IT男的一人企业]
上一篇《详解YOLO检测算法的训练参数》讲了该如何设置参数训练。这一篇说说模型训练完,怎么看它训练的好不好。这就像开车跑长途,5个小时跑完600百公里,得有数据说下车况好不好。
使用YOLO进行目标检测训练之后,会在runs\detect\train下生成一些训练过程和结论文件:
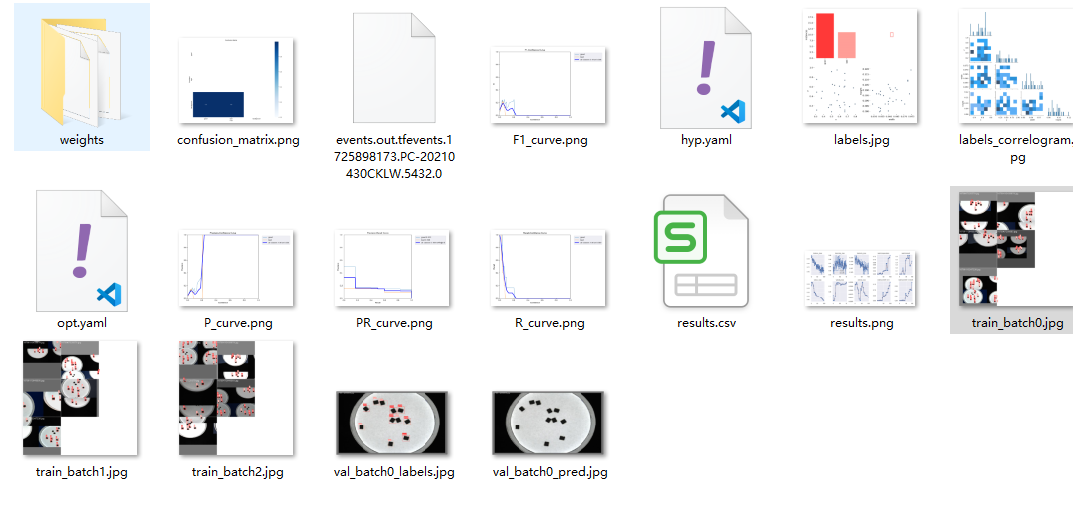
那些名字里带batch的图片,是不同批次的图像预测结果。它们可视化了模型在训练过程中对数据的处理情况。这点在上一篇中已经讲过了。今天重点说说有关结论性的东西。
看到上面的一堆图表和曲线,很多人有点懵。这很像我们去医院体检后,医院给了一堆血常规、尿常规的检查单。
看着这些单子,我们居然不知道身体到底哪里出了问题。这时,我们需要去找医生“翻译”一下。其实,每个行业都是这样的。就像是上面开头的那些图表和曲线,也需要算法程序员解释后,大家才能明白。
我不得不说算法的评价指标设计巧妙,十分周详。通过了解下面的内容,不仅可以获得算法相关认识,对于普遍事物的评价规则和考核体系也会有启发意义。
下面我们就来逐一说明。
weights文件夹:最终的仙丹
这里面是模型权重文件,也就是最终炼丹炉里训练出来的仙丹。里面有俩文件best.pt和last.pt。
-
best.pt是整个训练过程中,性能最好的模型权重文件。最终我们要的就是这个文件。我们可以拿它进行实际业务的AI预测或继续微调。 -
last.pt是最后一次训练的模型权重文件。一般来说,训练越久效果也越好。但有时它也会和best.pt不一致。这意味着最后一次训练的结果,并不是最好的。从这俩文件生成的时间差异,可以看出一些端倪。这是最简单的诊断参考。
results.png:训练总图要略
这张图片包含训练过程中的各种评估指标,比如损失函数、精度、召回率、mAP等的图表绘制。这个图表可以直观地看到模型训练过程中性能的变化情况。
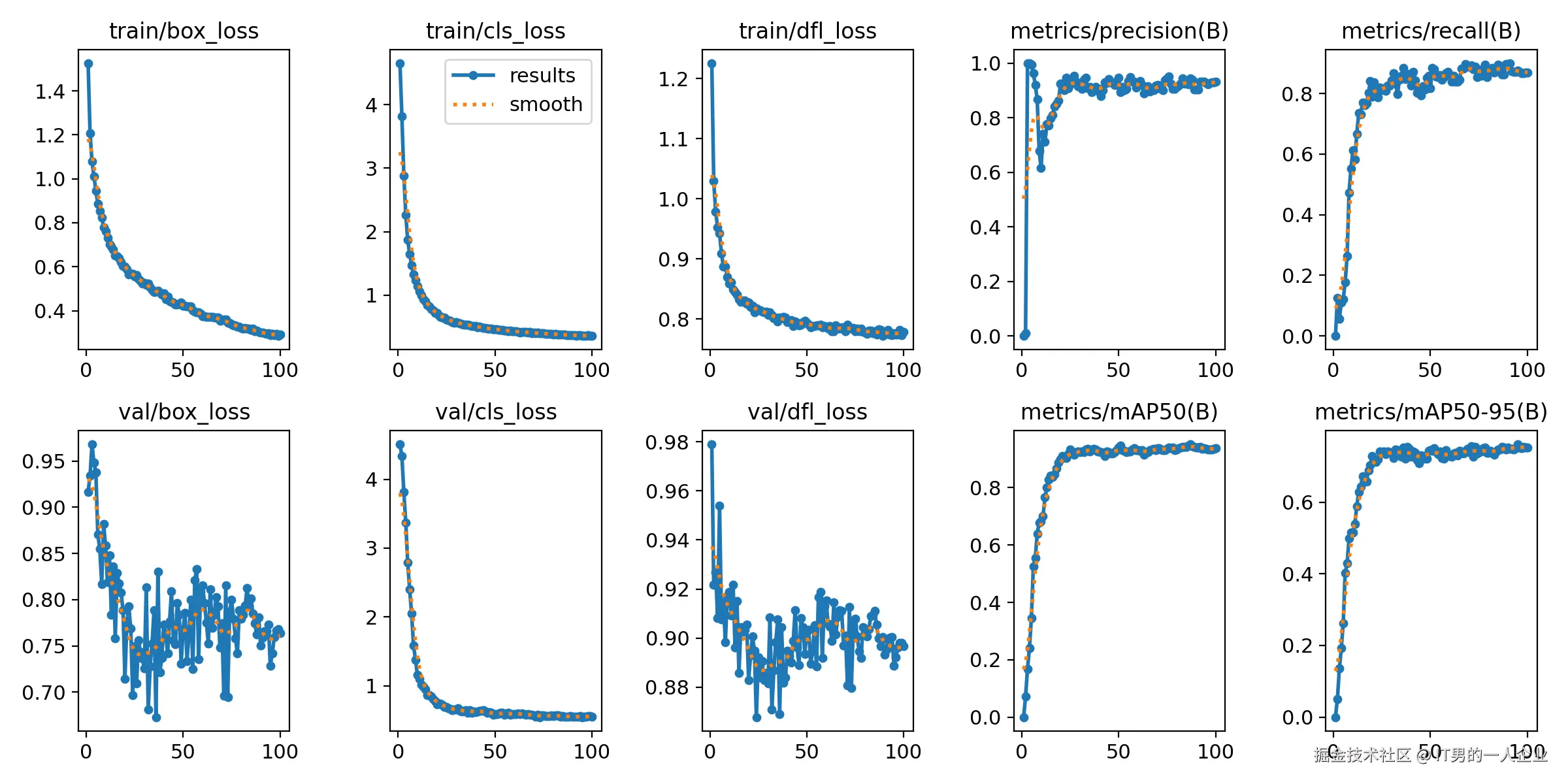
来来来,不用担惊,莫要受怕,咱们一一道来。
loss系列:打明牌的能力
我们先看前3列:
train/box_loss和val/box_losstrain/cls_loss和val/cls_losstrain/dfl_loss和val/dfl_loss
这几组前面的train表示训练集,val是验证集。训练集是用于训练学习的,相当于书本的例题。而验证集则用于考试,相当于试卷的试题。学得好不一定就考得好,主要还得看考题是不是有关联性。不过他们更重要的相同点,好像在于都有loss。
loss是算法中一个常见的概念。翻译成“损失”这个词,其实很形象。生活中,对于能量转化,我们常常用到损失。我们说100单位的电能转化为80单位的动能,能量损失了20%。如果实现了百分百转化,那么损失就是0。
应用到算法中也一样。在有监督训练中,我们是先标记再训练。其实这就是打明牌,本身就知道问题和答案。

对于训练集和验证集,AI本身是知道这个区域标的是什么,位置在哪儿。因此,它会先猜测结论,然后跟正确答案做对比。它的猜测行为称为“推理”或者“预测”。它自己的推理结果和人工标记的答案之间的差异,称为“损失”。那么,损失越小越好,损失为0则说明AI的推理和正确答案之间没有差异,即预测100%命中。
我们看下图,这次训练过程也是如此。这几个train系列的loss都是降低的,X轴表示训练轮次,Y轴表示损失的值。
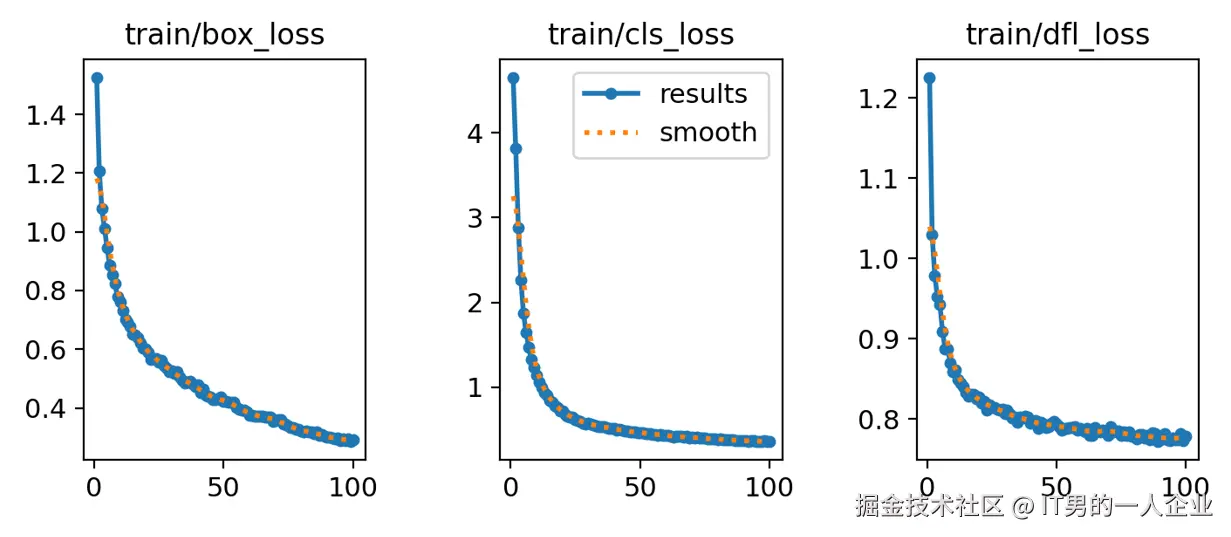
我们看到loss的值都是降低,这说明很好。但是第一个box_loss好像还有下降的趋势。但是中间的cls_loss在50轮时就已经趋于稳定了,而dfl_loss好像在75轮附近才慢慢稳定。
这些指标都代表什么?有什么意义呢?
box_loss 边界框损失:衡量画框
box_loss全称是bounding box loss,表示边界框损失。它表明AI通过训练和学习之后,对于边界框的预测和标准答案之间的损失。

正常情况下,随着训练的进行,损失是越降越低的。如果它是长期忽高忽低,或者一直不明显收敛,那说明训练存在问题。如果box_loss的损失不断降低,而后持续稳定,则说明训练没有问题,也没有必要再投入资源训练了。
但是box_loss表现优秀,仅仅说明它对物体区域(画框)的识别情况。就算这一项100分,整体效果也不一定就好。因为光会画框意义不大,我们还要知道框里的物体是什么。
于是就引入另一个cls_loss指标。
cls_loss 分类损失:判断框里的物体
它叫分类损失,全称为classification loss。它衡量的是预测类别和真实类别之间的差异。
我们看下面的图,它不但框出了物体。而且标注出了这个框里是人,那个框里是车,哪个是细菌,哪个是垃圾。

对于框里物体是什么的评价,就用到了cls_loss指标。从这里可以看出,其实目标检测技术,已经包含了图片分类的技术。图片分类很基础,它的损失收敛得最快,仅仅训练几十次就稳定了。
如果你认为它仅凭哪个区域、什么物体两项指标就结束了,那么确实是小看YOLO算法了。它还有第三项细化指标dfl_loss。
dfl_loss 分布式焦点损失:精益求精
dfl_loss全称是Distribution Focal Loss,中文名称为“分布式焦点损失”。 它辅助box_loss,提供额外的信息,通过对边界框位置的概率分布进行优化,进一步提高模型对边界框位置的细化和准确度。
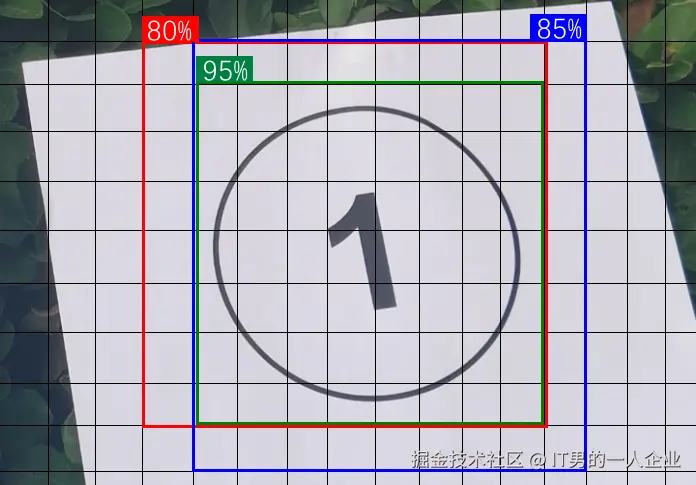
如上图所示,AI模型成功预测出了①的位置。但是红、蓝、绿3个框中的①,好像哪个都没错。因此dfl_loss提供了一个可信度,表明哪一个焦点跟标准答案相比,会更加精确。
验证集:学得好,不一定考得好
上面是训练集的loss。下面说说验证集的loss。
从规范上讲,验证集和训练集是永远不见面的。这么做是为了验证AI是否真正学到了数据的特征和精髓,而非是靠死记硬背所见过的数据。
也就是说模型在经过几番训练集数据的学习之后,将面对从来没有见过的验证集数据。它将给出预测答案,然后再去对照标准答案。两个答案的差异,就是验证集的损失。
看下面这个验证集曲线的趋势。
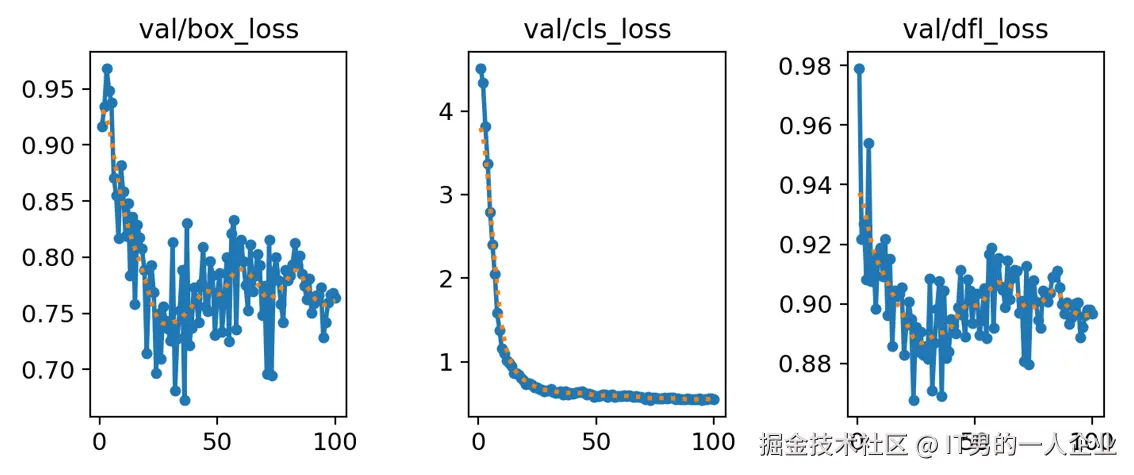
相比训练集的平滑趋势,验证集似乎是有些反复。
其实,这是一种常见现象。只要验证集损失没有显著上升,整体趋势在变好,且与训练集损失的差距不是特别大,这一般是正常的。
不过,要留意以下细节:
- 样本数据的变异:验证集可能包含一些与训练集不同风格的样本,这会导致损失不稳定。好比你拿着泰迪狗做识别训练,最后让模型去认识哈士奇狗,模型有点迷糊,拿不准。
- 模型的过拟合:如果验证集的样本数据正常。模型在训练集上的损失表现很好,但是验证集表现不稳定。那么可能是模型记住了训练集的细节,也就是过于死记硬背,只抓住形没有抓住神。这叫过拟合。
如果遇到比较严重的问题,或者你感觉有问题,该怎么办呢?
可以调整超参数,比如调小学习率,或者使用提前停止策略来防止过拟合。也可以调整batch大小,增加一个批次数量,让它见多识广。
同时,增加训练数据量或使用数据增强技术,可以使模型更好地泛化,减少验证损失的波动。
大家不要小看验证集的指标,这是衡量模型效果的第一道关卡。因为训练集的结果指标顶多算是自娱自乐,这有点像学校内部的月考、期末考试。而验证集则更像是高考。因此,对于验证集的检测,还有更多指标。
精度和召回率:又准又全的考量
results.png的后两列是同一类指标,咱们一块说说
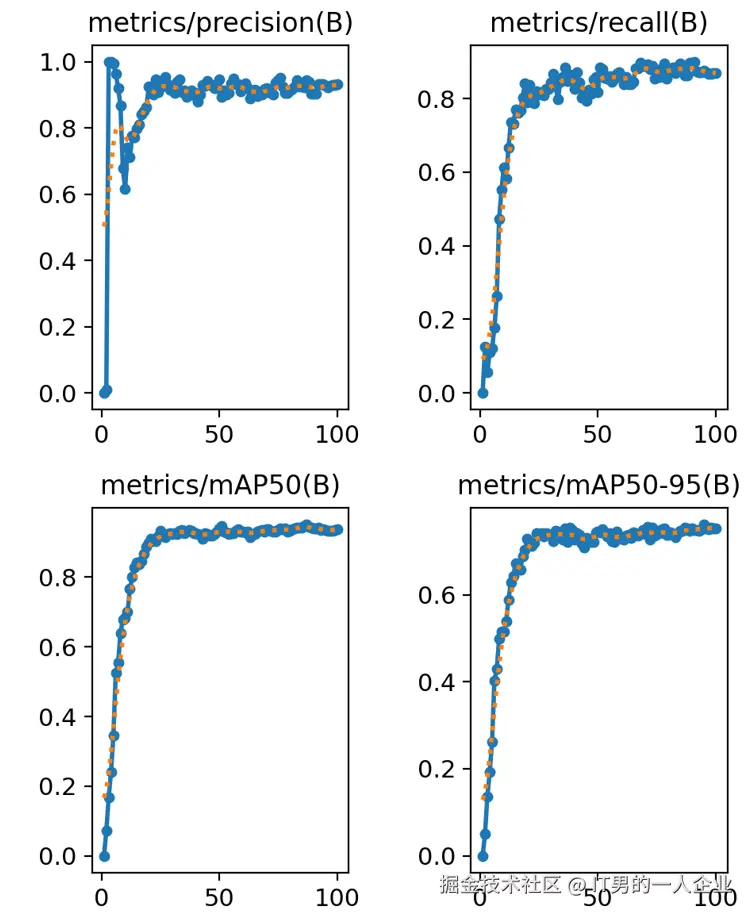
之所以说他们是同一类,看表头就知道,他们的名字前面带metrics,后面带(B)。
metrics表示模型是在验证集上的评估指标。(B)呢,在目标检测任务中表示Bounding Box,即边界框的检测结果。
首先看左上角的第一个precision。precision是精度,或者称为“精确率”。请注意,是精确率,不是准确率。准确率有专门的名词accuracy。两者不一样。
准确率表示预测正确的占比。比如1000件产品中,900件合格。我的AI模型全都找出来了,这时准确率是100%。
准确率存在一个问题,尤其对于少数个体而言不公平。比如预测绝症,100个人预测对了90个人是健康的,预测错了10个病危的人。虽然准确率是90%,但这属于严重事故。于是,精确率的可以解决这个问题。
精确率会从100个里随便抽出10条数据,如果预测错了5个,那么精确率就是50%。高准确率保证的是多数都正确,而高精确率是保证每一个都不出错。
我们看到第一个精确率的图表,大约30轮左右趋于稳定了,而且向1(100%)靠拢。这说明效果不错。
精确率就没有问题吗?也有问题!
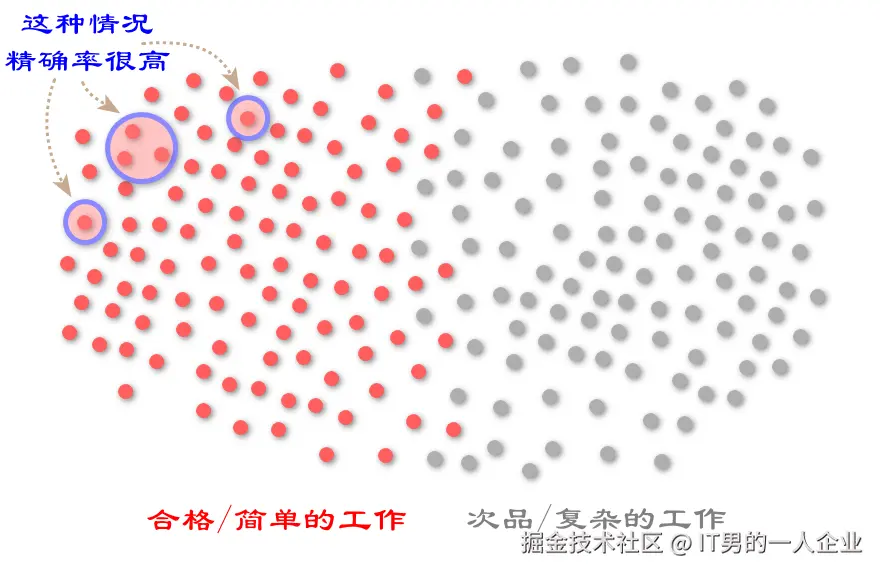
精确率考核的是出错率,只要不出错,哪怕只干好一件事,也是100%。如果精确率指标它挑活干,那么就完犊子了。工作、生活中也有这类情况,就是拣着好做的工作去做,结果干得很漂亮。
因此,这时又引入了另一个指标,也就是第二幅图中的召回率recall。召回率的口号是:“宁可做错一千,绝不漏掉一个”。鼓励大家抢着做,谁眼里没活就打低分。这样就解决了那些少干活、拣活干的情况。
其实召回率recall和精确率precision是矛盾的。两者的值很难都高。因为既要脏活、累活、杂活都揽下,还要不允许出错。这对于机器或者人类都是很大的挑战。
但是,考核指标就是要这样的。就要想尽一切办法堵住漏洞。我们看第二幅图中召回率也是在提高的,这说明检测范围在不断扩大,大约在0.8处浮动。因此从前两张图我们可以说,这次训练precision精度是0.9,召回率recall为0.8。
关于P(precision)和R(recall)之间的数据趋势,这里面也有具体的图示。
runs\detect\train下面有P_curve.png,这是每项精度的曲线。
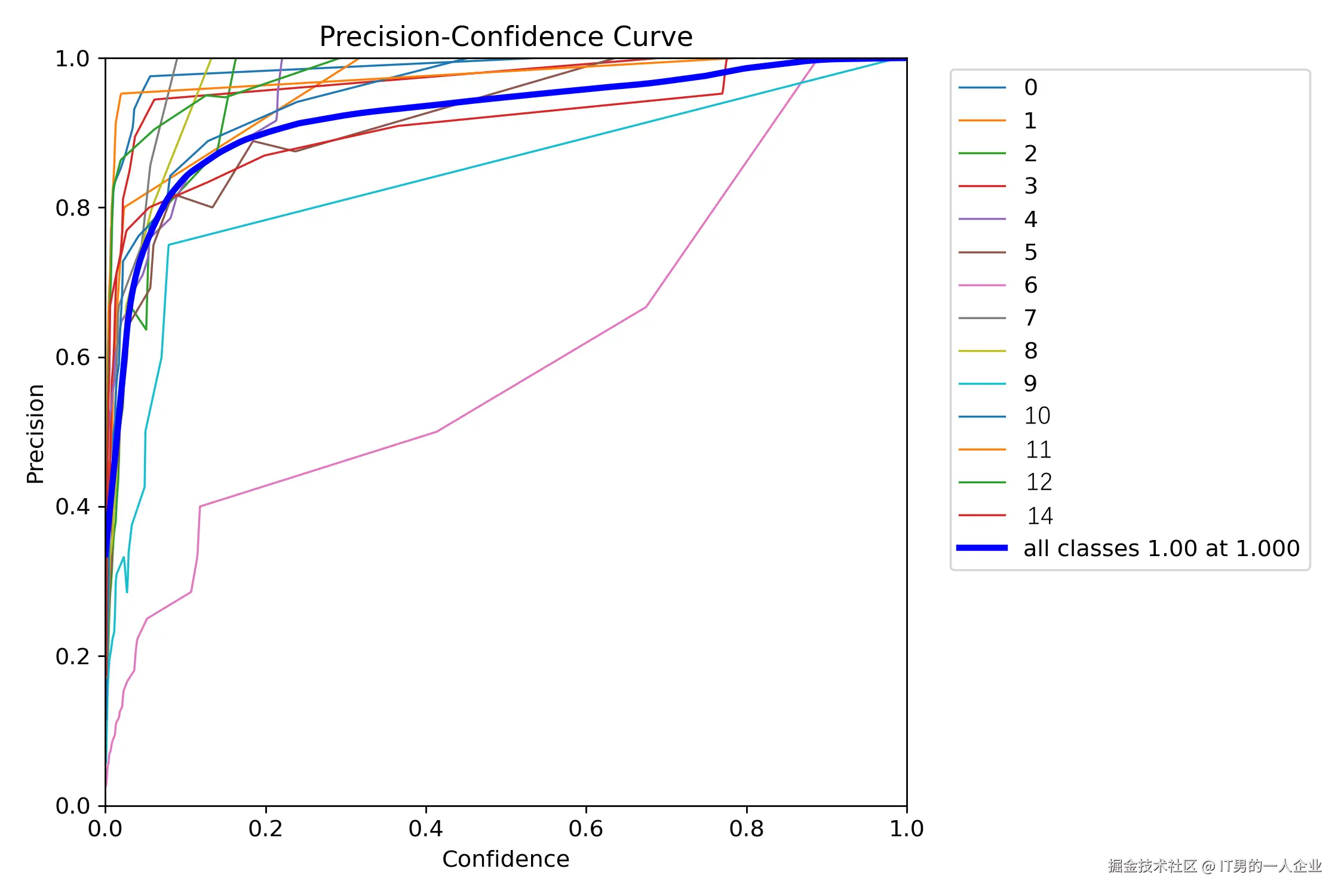
我这里面是检测从0到14,共15项物体。这类曲线可以看出每一项物体的具体表现。我们可以从单个表现来了解哪一类检测效果好,哪一类检测效果差。从图中看,粉色的线条,对应分类为6的目标,效果比较差。
R_curve.png这是每项召回率的曲线。
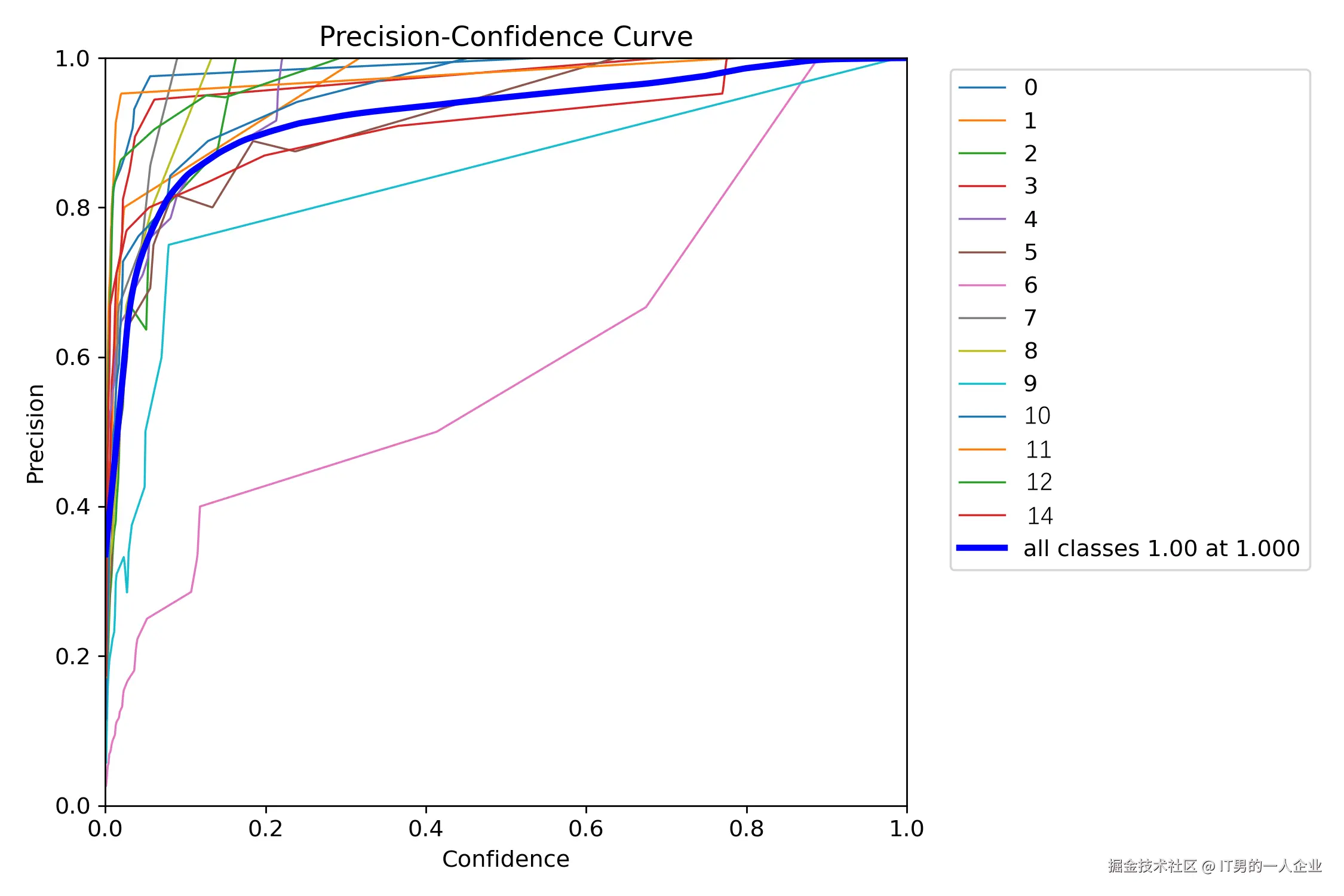
而PR_curve.png则是两者互相妥协的曲线。这个PR图怎么看呢?越接近正方形效果越好。都接近正方形,说明整体效果又准又全。
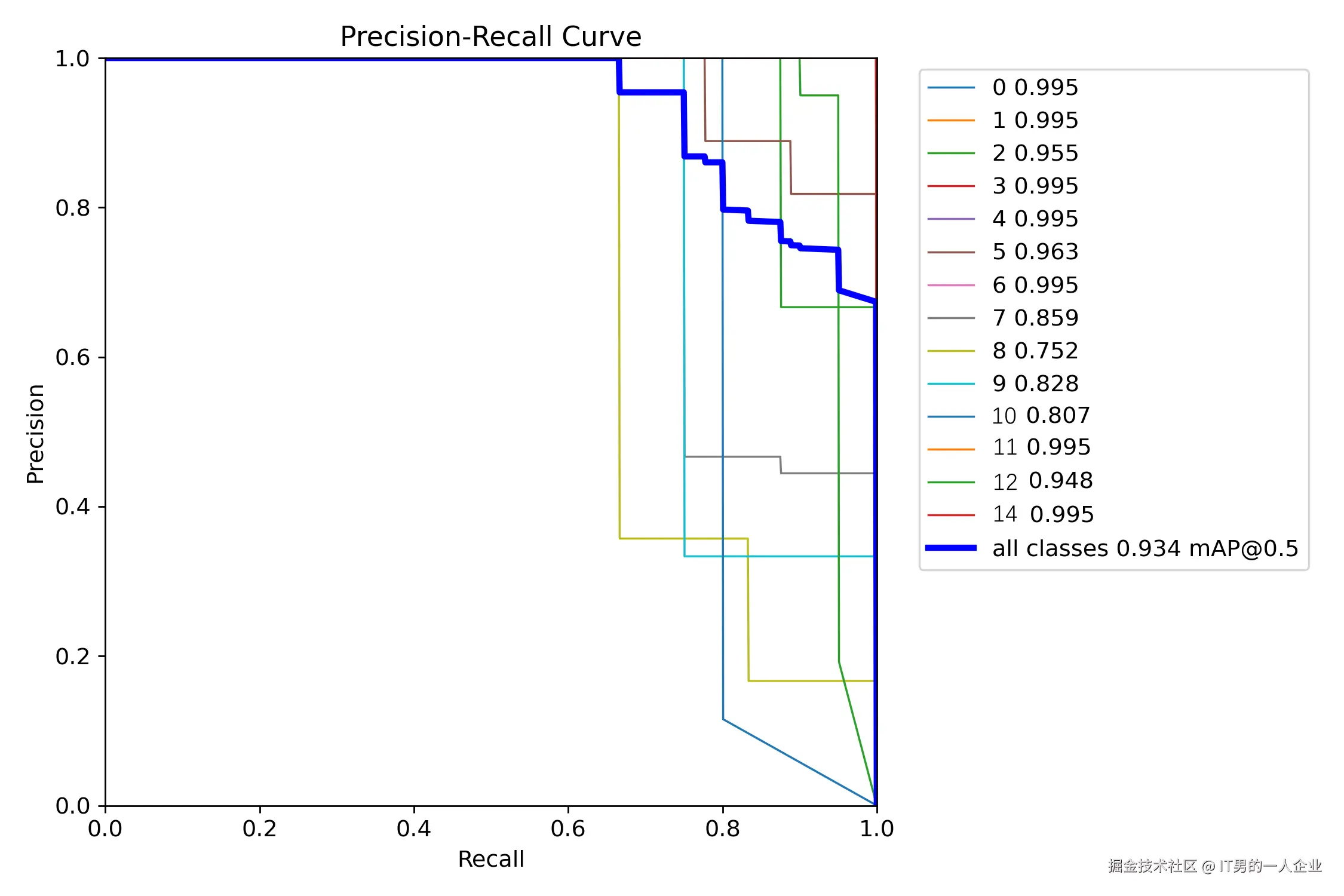
看上图,蓝色总线接近正方形。但是具体到分类为8的目标,有些拖后腿。
results.png系列还剩两张图片,那就是mAP50与mAP50-95。这俩是一类(也是看名称很像)。
mAP50要拆开看,拆成mAP-50,mAP表示mean Average Precision,称为平均精度。50则是在IoU阈值为50%的情况下的值。
额……我好像又得讲讲什么是IoU了。它不是I Love You的意思,其实是Intersection over Union,是目标检测中用于衡量预测边界框与真实边界框重叠程度的指标。
如果你熟悉YOLO,那么肯定知道它的特点就是You Only Look Once(你仅需看一遍)。这项优势也导致它出现很多备选框。
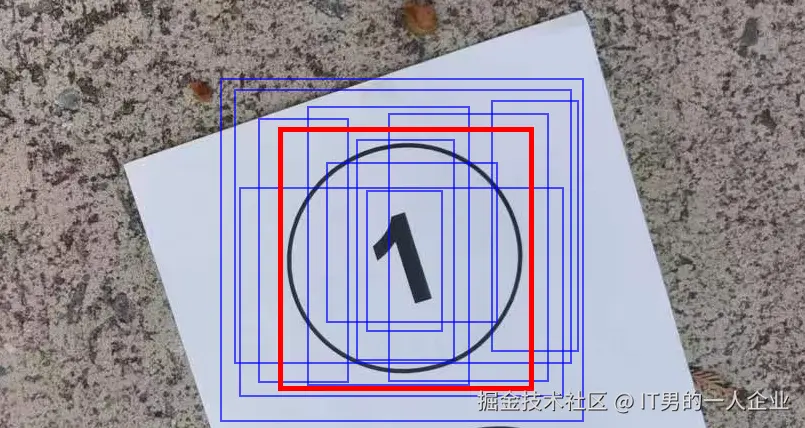
这些个预测出的框框儿,可能是物体的全部,也可能只是中心部分,还或许仅仅是物体的一个角。不管如何,这都是算法通过学习特征计算出来的。谁是谁非,看你怎么选择。
如果预测出的面积(蓝框)能占到实际区域(红框)的50%以上,那么我们就说IoU为50。重合度能到50%,其实能说明AI大体猜中了。因为IoU为100就是完全重合。
mAP50是重合度以50%为界限的平均精度。而mAP50-95则是IoU阈值从50%到95%范围内的平均值。这个更加严格一些。因此,我们看到图里面mAP50-95的值确实也低一些。
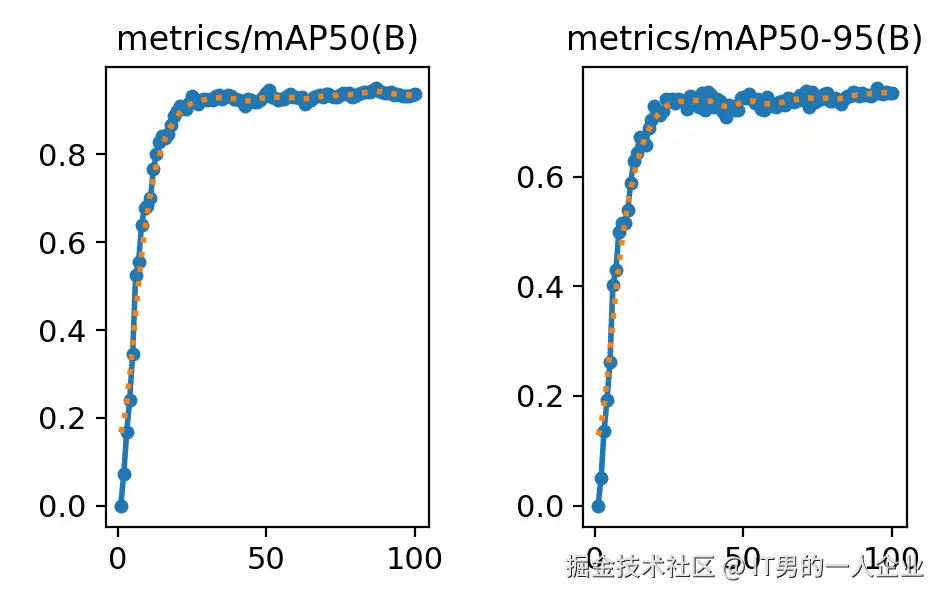
从这里能看出啥信息呢?
mAP50这个指标相对宽松,能够展示模型在较低严格度下的整体性能。它更适用于那些对定位要求不是特别严格的应用场景。
mAP50-95则意味着在严格的IoU条件下也能准确检测和定位目标。它适用于那些对定位要求较高的应用场景,如自动驾驶、医疗影像分析等。
因此,完全看你的需求。如果觉得现在的模型识别效果不好,对精度要求又不高能大体定位就行,其实可以调低IoU的值。反正,各类表现都告诉你了。
results.csv:图表里的数据明细
runs\detect\train下有一个results.csv表格文件。其实这是上面刚刚讲的很多图表的数字版本。
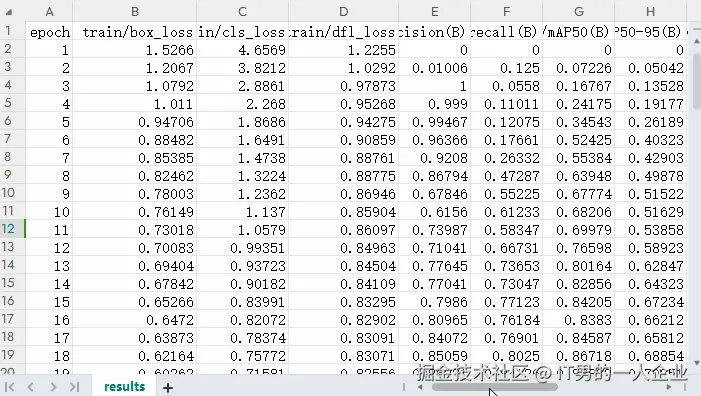
如果你想查询某次训练某项指标的具体值,可以从这个表格中查找。
如果results.png图不小心删除了,可以通过这个csv再生成,下面是代码:
viewresults.py
from utils.plots import plot_results
plot_results(file='C:/Yolo/project_chip_detection/yolov5/runs/train/exp6/results.csv',dir='') # 这里改成自己的results.csv目录即可
labels系列:分类标签的分布
上面说了,我这里面是从0到14,共检测15项物体。那么关于这15项物体的分布情况,我们可以从labels.jpg查看。
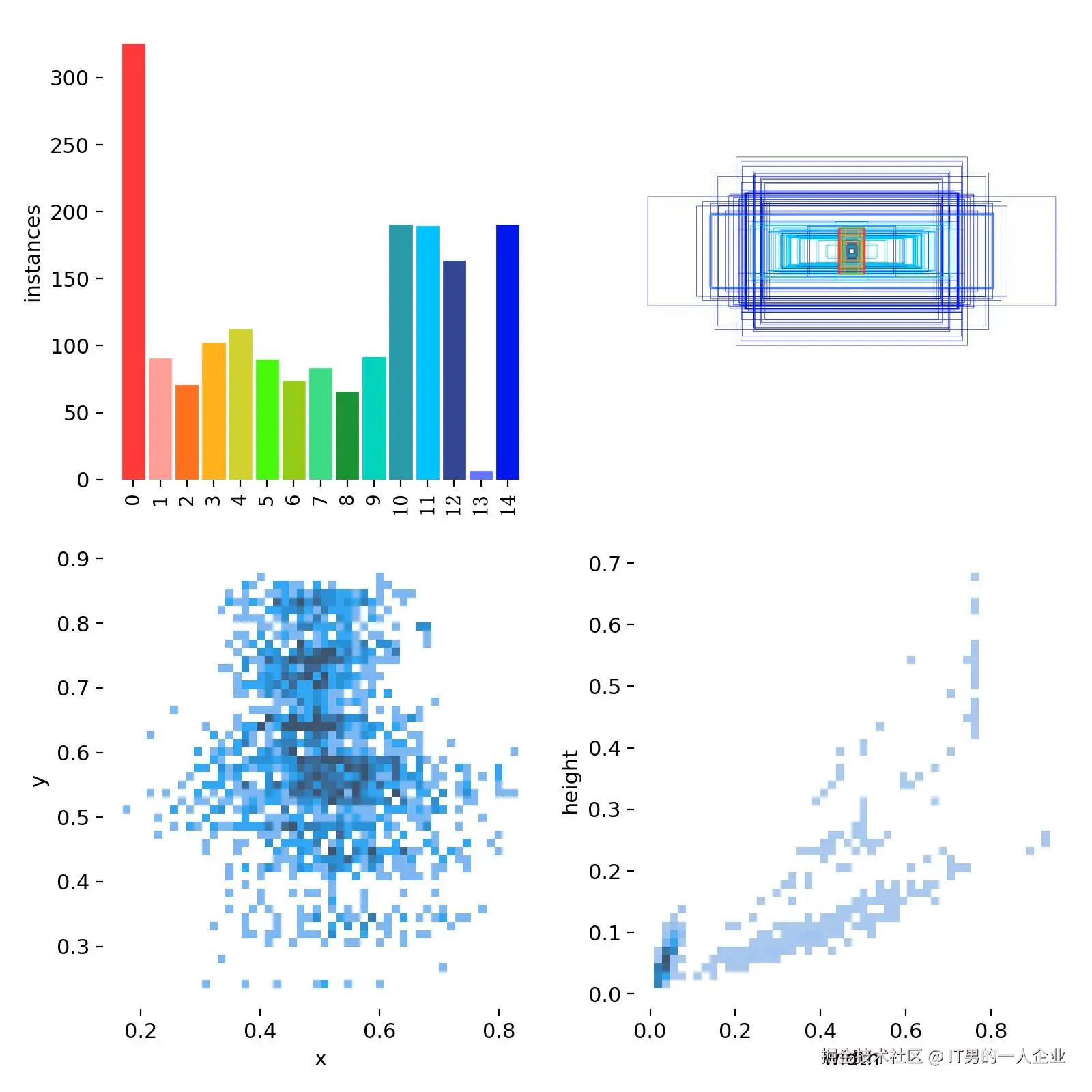
看上图第一项,很明显有一个问题。那就是第13分类的样本数太少。这也导致比如上面的P曲线、R曲线没有第13分类的信息(没注意可以滑上去再看看)。这是因为样本过少,被淹没、忽略了。
下面是是混淆矩阵的归一化版本,对应的图片是confusion_matrix_normalized.png。这里可以更清晰地展示模型在各类别上的性能表现。我们也可以看到第13类别数据为空。
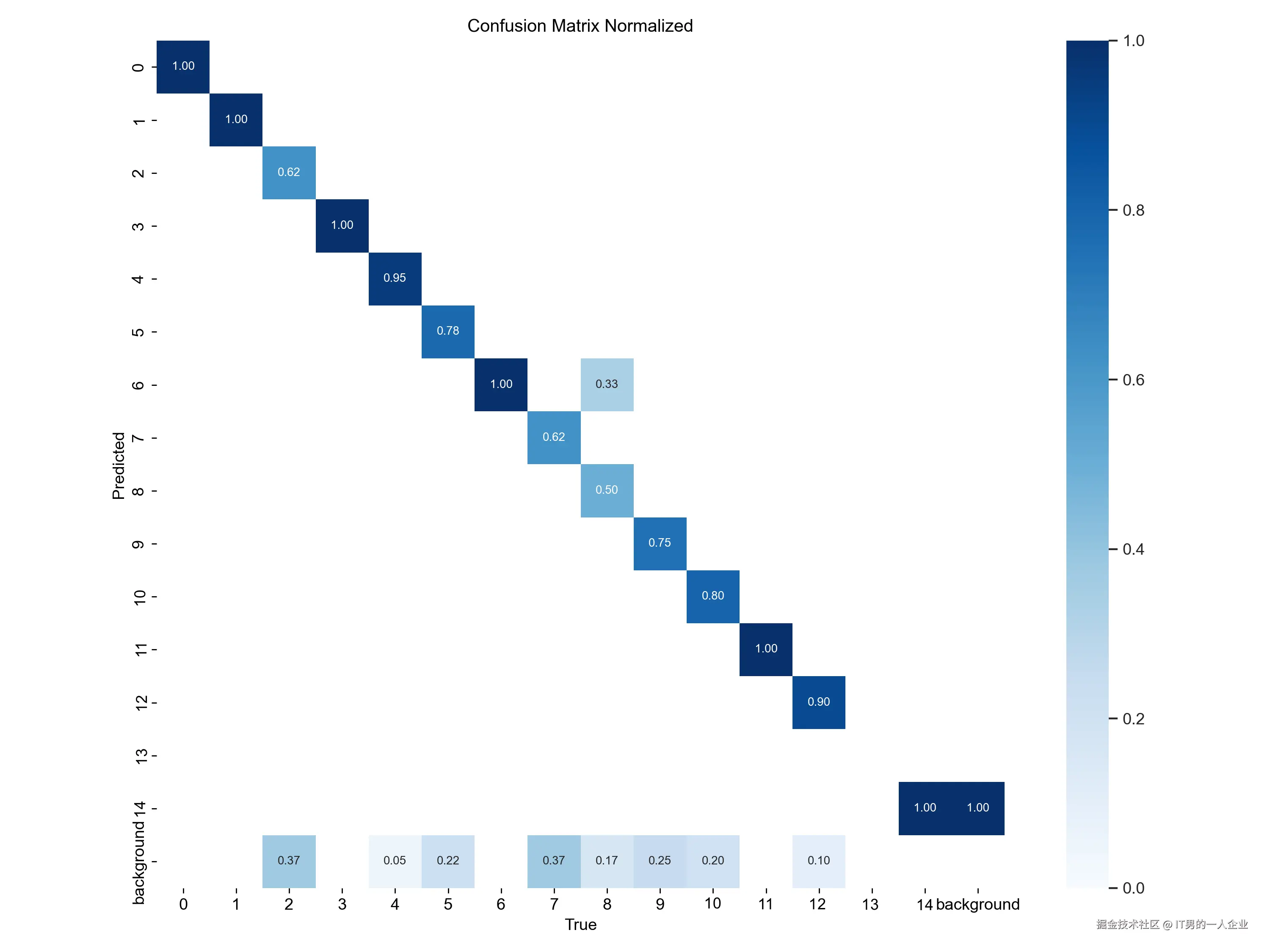
好了。就讲这么多吧。这已经可以反映出90%的问题了。至于其他的文件和结果,那就更加专业了,一般用不到。能关注的一般都是业内的人,不用我讲。不了解的人,就算我费功夫说一番也很难理解。还不如不知道。
最后,我想解释一下,为什么医疗、算法、建筑等行业都会用一些指标作为评测结果。就比如本文开头所说的去医院看病,用血常规作为某项健康指标,而不是医生直接说这个人健康或者不健康。算法也是这样,这么多精度、召回率等指标,为什么不直接说模型好用还是不好用呢?
首先,不同的人,他的关注点不同。大家需要通过多个指标进行自己的个性化评估。老板关注模型准不准,但是算法工程师更关注为什么不准。因此,只能给出指标,让不同人自己去整理关注的结论。
其次,理工科要基于实验的客观数据。你的结论需要有科学依据,使用具体指标是实验验证的基础。这种方法是基于数据的客观评价,而不是主观判断。
最后,方便进行量化分析。差,差到什么程度。好,好到什么水平。指标可以进行统计分析、趋势分析和比较研究,提供科学的依据和支持。
以上就是我对YOLO算法训练后结果的常见分析。