软工个人项目-论文查重
| 这个作业属于哪个课程 | 广工计院计科34班软工 |
|---|---|
| 这个作业要求在哪里 | https://edu.cnblogs.com/campus/gdgy/CSGrade22-34/homework/13229 |
| 这个作业的目标 | 个人独立完成论文查重代码,进一步了解项目开发的流程,学会运用工具分析消除警告,运用性能分析工具进行改进提高 |
GitHub地址
一、需求
题目:论文查重
描述如下:
设计一个论文查重算法,给出一个原文文件和一个在这份原文上经过了增删改的抄袭版论文的文件,在答案文件中输出其重复率。
- 原文示例:今天是星期天,天气晴,今天晚上我要去看电影。
- 抄袭版示例:今天是周天,天气晴朗,我晚上要去看电影。
要求输入输出采用文件输入输出,规范如下:
- 从命令行参数给出:论文原文的文件的绝对路径。
- 从命令行参数给出:抄袭版论文的文件的绝对路径。
- 从命令行参数给出:输出的答案文件的绝对路径。
我们提供一份样例,课堂上下发,上传到班级群,使用方法是:orig.txt是原文,其他orig_add.txt等均为抄袭版论文。
注意:答案文件中输出的答案为浮点型,精确到小数点后两位
二、PSP表
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 40 |
| Estimate | 估计这个任务需要多少时间 | 30 | 35 |
| Development | 开发 | ||
| - Analysis | - 需求分析 (包括学习新技术) | 90 | 120 |
| - Design Spec | - 生成设计文档 | 60 | 65 |
| - Design Review | - 设计复审 | 30 | 25 |
| - Coding Standard | - 代码规范 (为目前的开发制定合适的规范) | 20 | 20 |
| - Design | - 具体设计 | 60 | 65 |
| - Coding | - 具体编码 | 200 | 240 |
| - Code Review | - 代码复审 | 40 | 45 |
| - Test | - 测试(自我测试,修改代码,提交修改) | 50 | 60 |
| Reporting | 报告 | ||
| - Test Report | - 测试报告 | 20 | 30 |
| - Size Measurement | - 计算工作量 | 10 | 10 |
| - Postmortem & Process Improvement Plan | - 事后总结, 并提出过程改进计划 | 20 | 25 |
| 合计 | 660 | 780 |
三、模块接口的设计和实现过程
1. 文件读取模块 (read_file)
- 接口设计
- 输入:
file_path(文件路径)。 - 输出:文件的内容(字符串),或者在发生错误时返回
None。
- 输入:
2. 文本预处理模块 (preprocess_text)
-
输入:
text(原始文本)。 -
输出:处理后的分词列表。
-
使用正则表达式
re.sub(r"[^\w\s]", "", text)去除标点符号、转义字符和其他特殊字符,只保留文字和空格,确保文本干净,避免噪声影响分词。
3. 余弦相似度计算模块 (calculate_cosine_similarity)
-
输入:
tokens1和tokens2(两个分词列表)。 -
输出:两篇文章的余弦相似度值。
-
使用
gensim.corpora.Dictionary来构建词典,将分词结果映射到向量空间模型(VSM)。 -
利用
gensim.similarities.Similarity模块计算余弦相似度。
4. 结果保存模块 (save_result)
- 输入:
result_path(保存结果的文件路径),similarity_score(计算得到的相似度)。 - 输出:无,直接将相似度结果写入指定文件。
5. 命令行参数解析与主流程控制 (main)
- 通过
argparse.ArgumentParser获取用户输入的文件路径,包括原文、抄袭文和结果保存路径。 - 实现了整个程序的主流程,包括:读取文件、预处理文本、计算相似度、保存结果等。
独到之处
使用 jieba 库进行中文分词,特别适合处理中文文本中的复杂词语分界问题。
使用了 gensim 库,其性能和扩展性在处理大规模文本相似度问题上优越。
结合命令行参数和异常处理,用户可以根据需要指定不同文件路径,且在程序运行过程中有详细的错误提示,便于排查问题。
四、计算模块接口部分的性能改进
性能分析

使用python的第三方库line_profiler实现
read_file()
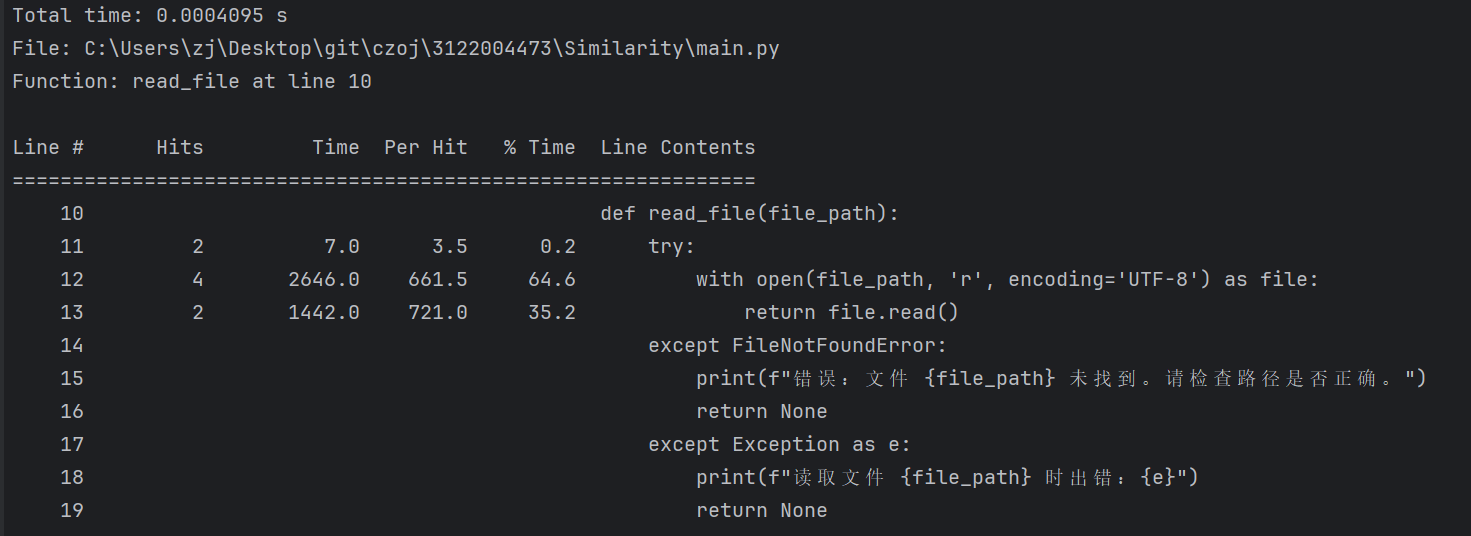
preprocess_text()

calculate_cosine_similarity()
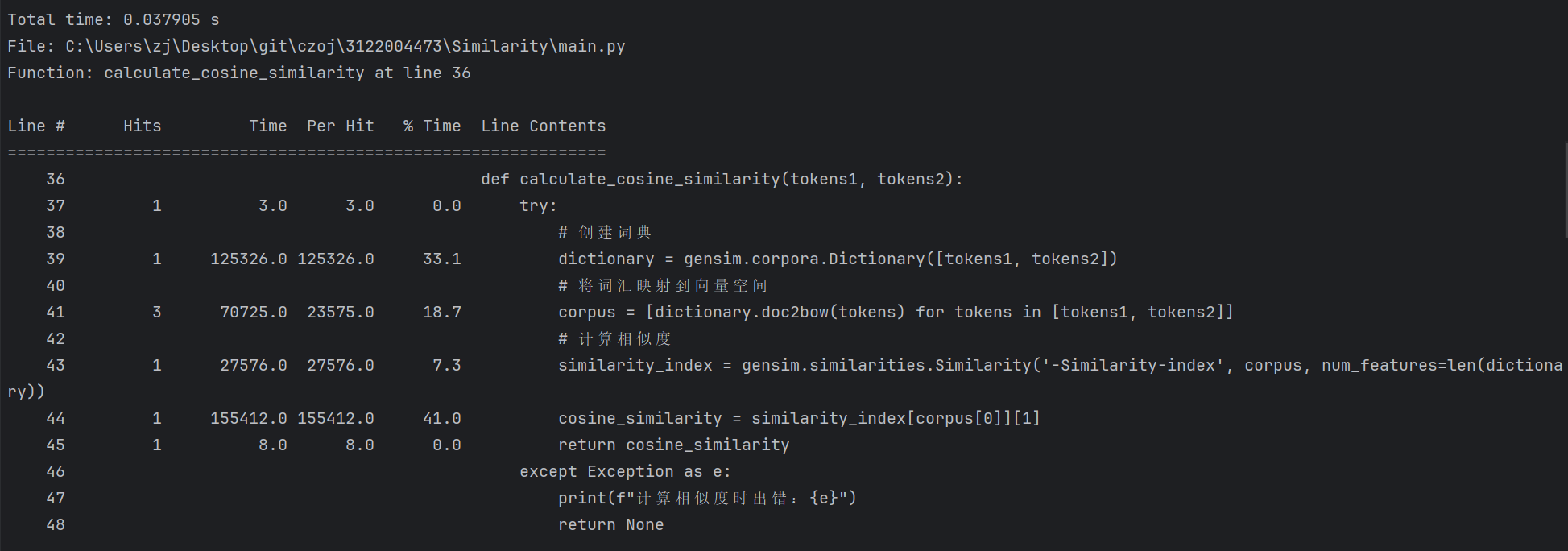
save_result()
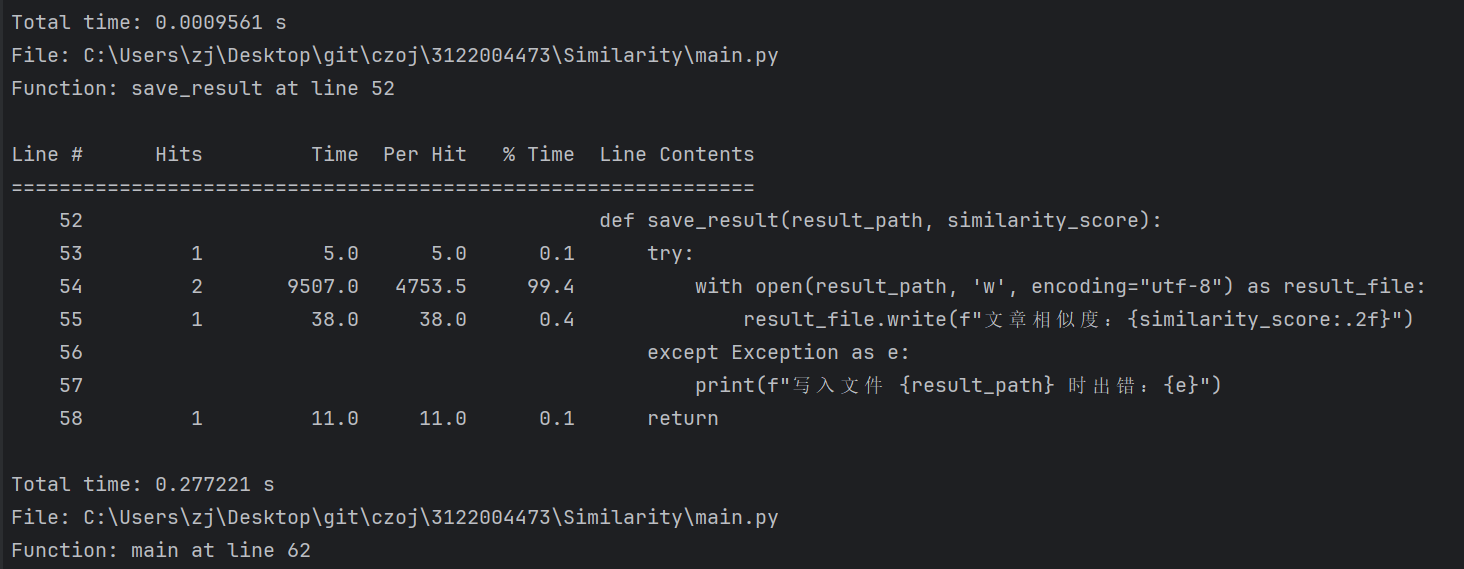
main()
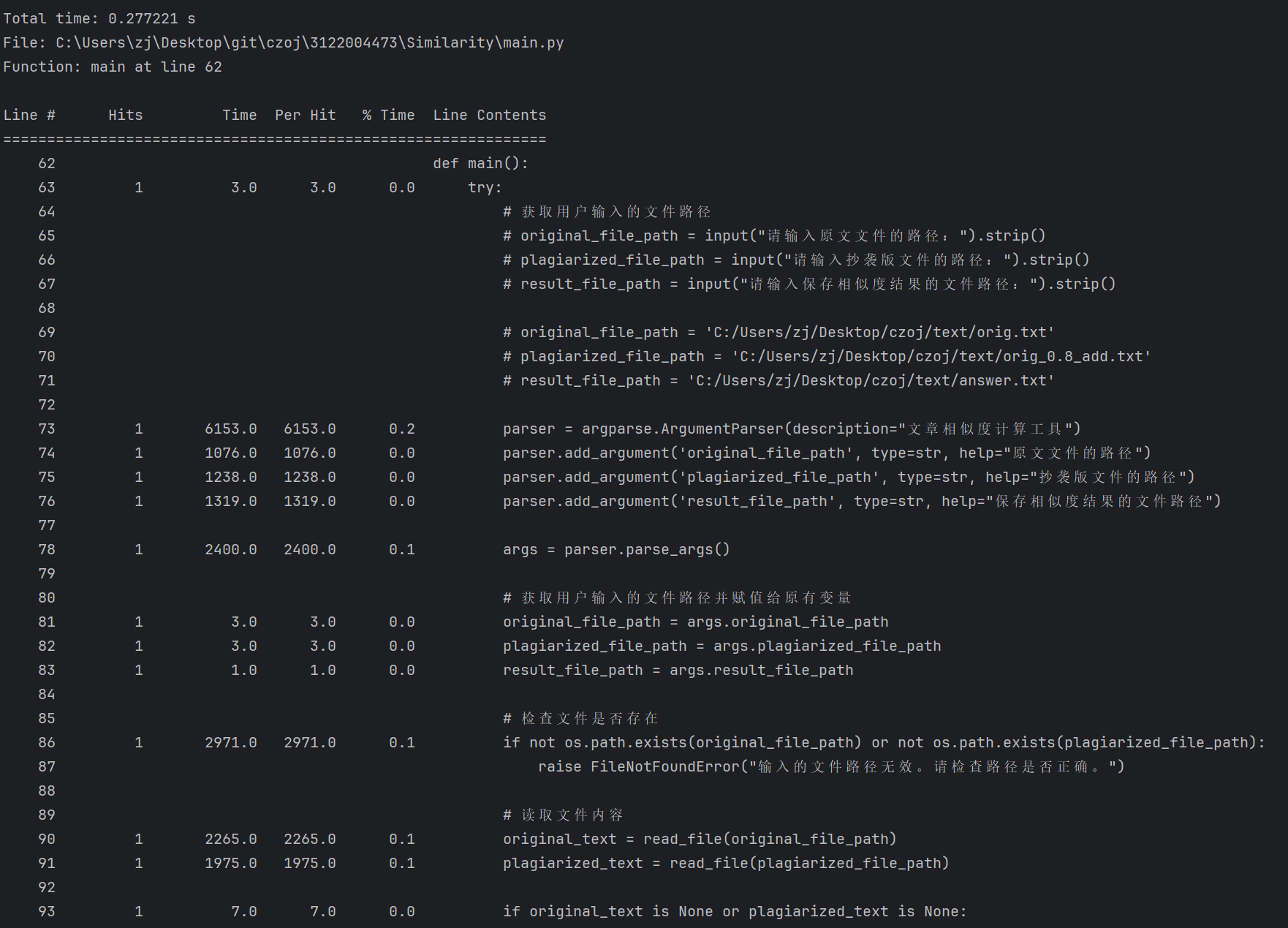
我们可以得到函数preprocess_text()的用时最长,并且耗时达到0.233673 s
性能改进
正则表达式优化:当前使用的正则表达式 re.sub(r"[^\w\s]", "", text) 在大文本上可能效率不高。可以使用预编译的正则表达式来减少重复编译的开销。
五、模块部分单元测试展示
1.单元测试代码
import unittest
import jieba
import os
import re
from main import read_file, preprocess_text, calculate_cosine_similarity, save_resultclass TestSimilarityFunctions(unittest.TestCase):def setUp(self):# 创建两个测试文本self.test_text1 = "这是一个用于测试的文本。"self.test_text2 = "这个文本和第一个文本有一些相似之处。"self.empty_text = ""self.similarity_score_path = "test_similarity_score.txt"# 创建测试文件with open("test_file1.txt", "w", encoding="utf-8") as f1:f1.write(self.test_text1)with open("test_file2.txt", "w", encoding="utf-8") as f2:f2.write(self.test_text2)with open("empty_file.txt", "w", encoding="utf-8") as f3:f3.write(self.empty_text)def tearDown(self):# 删除测试文件os.remove("test_file1.txt")os.remove("test_file2.txt")os.remove("empty_file.txt")if os.path.exists(self.similarity_score_path):os.remove(self.similarity_score_path)def test_read_file(self):# 测试读取文件功能content1 = read_file("test_file1.txt")content2 = read_file("test_file2.txt")self.assertEqual(content1, self.test_text1)self.assertEqual(content2, self.test_text2)# 测试读取空文件content = read_file("empty_file.txt")self.assertEqual(content, self.empty_text)# 测试读取不存在的文件content = read_file("nonexistent_file.txt")self.assertIsNone(content)def test_preprocess_text(self):# 测试文本预处理功能tokens1 = preprocess_text(self.test_text1)tokens2 = preprocess_text(self.test_text2)# 输出实际分词结果以调试print("分词结果1:", tokens1)print("分词结果2:", tokens2)# 手动检查jieba分词的实际结果test_text1_cleaned = re.sub(r"[^\w\s]", "", self.test_text1)test_text2_cleaned = re.sub(r"[^\w\s]", "", self.test_text2)expected_tokens1 = jieba.lcut(test_text1_cleaned)expected_tokens2 = jieba.lcut(test_text2_cleaned)# 断言实际预处理结果与分词结果一致self.assertEqual(tokens1, expected_tokens1)self.assertEqual(tokens2, expected_tokens2)# 测试空文本empty_tokens = preprocess_text(self.empty_text)self.assertEqual(empty_tokens, [])def test_calculate_cosine_similarity(self):# 测试余弦相似度计算tokens1 = preprocess_text(self.test_text1)tokens2 = preprocess_text(self.test_text2)similarity_score = calculate_cosine_similarity(tokens1, tokens2)# 验证相似度是否为合理范围(0到1之间)self.assertGreaterEqual(similarity_score, 0.0)self.assertLessEqual(similarity_score, 1.0)# 测试两个完全相同的文本identical_tokens = preprocess_text(self.test_text1)similarity_score_identical = calculate_cosine_similarity(identical_tokens, identical_tokens)self.assertAlmostEqual(similarity_score_identical, 1.0, places=4)# 测试空文本和非空文本的相似度empty_tokens = preprocess_text(self.empty_text)similarity_score_with_empty = calculate_cosine_similarity(empty_tokens, tokens1)self.assertEqual(similarity_score_with_empty, 0.0)def test_save_result(self):# 测试保存相似度结果到文件similarity_score = 0.85save_result(self.similarity_score_path, similarity_score)with open(self.similarity_score_path, 'r', encoding="utf-8") as f:content = f.read()self.assertEqual(content, "文章相似度:0.85")# 测试保存到无权限文件路径(模拟异常情况)try:save_result("/invalid_path/test_similarity_score.txt", similarity_score)except Exception as e:self.assertIsInstance(e, Exception)if __name__ == '__main__':unittest.main()
2测试结果图
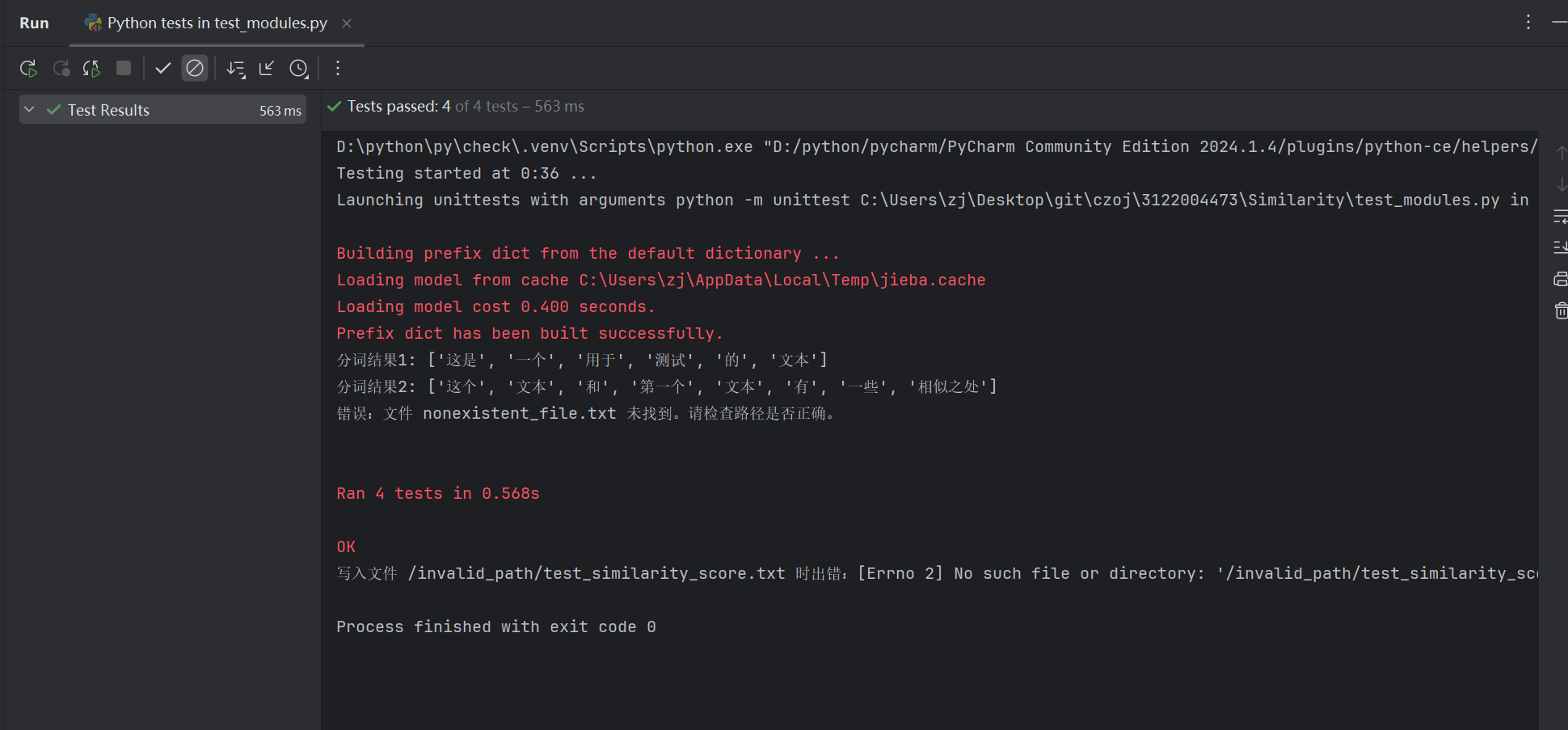
3.测试数据与测试函数构造思路
①测试文件的读取功能 (test_read_file)
思路:
目标:验证 read_file 函数在读取不同文件内容时能否返回正确的结果,尤其在文件存在、内容为空以及文件不存在等情况下。
测试数据设计:
test_file1.txt 和 test_file2.txt:两个带有不同内容的测试文件。
empty_file.txt:一个内容为空的文件,用于测试函数处理空文件的能力。
nonexistent_file.txt:模拟一个不存在的文件路径,用于验证函数处理文件路径无效的情况。
检查点:
验证 read_file 是否返回文件的实际内容。
验证空文件是否返回空字符串。
验证读取不存在的文件时,函数是否返回 None。
②测试文本预处理功能 (test_preprocess_text)
思路:
目标:验证 preprocess_text 函数是否能正确去除标点符号、特殊字符,并使用 jieba 进行分词,特别是在空文本和正常文本输入时的表现。
测试数据设计:
self.test_text1 和 self.test_text2:这两个文本用于测试一般情况下的分词效果。
self.empty_text:空字符串,用于测试空文本是否返回空分词结果。
检查点:
验证 preprocess_text 是否正确移除标点符号和特殊字符。
使用 jieba.lcut 手动分词进行对比,确保函数的输出与 jieba 分词结果一致。
确保对空文本的处理返回空列表。
独特之处:
输出分词结果供调试使用,以便在输出不符预期时帮助定位问题。
③测试余弦相似度计算功能 (test_calculate_cosine_similarity)
思路:
目标:验证 calculate_cosine_similarity 函数是否能正确计算两个分词结果之间的余弦相似度,且在不同文本、相同文本及空文本情况下返回合理的结果。
测试数据设计:
self.test_text1 和 self.test_text2:用于测试两个不同文本之间的相似度计算。
self.test_text1 与自身比较:用于测试相同文本的相似度,应返回接近 1.0 的值。
空文本:验证空文本与其他文本的相似度,结果应为 0.0。
检查点:
验证相似度结果是否在合理范围(0.0 - 1.0)。
检查两个相同文本的相似度是否接近 1.0。
确保空文本与非空文本比较时相似度为 0.0。
④测试结果保存功能 (test_save_result)
思路:
目标:验证 save_result 函数能否正确将相似度结果保存到指定的文件中,测试普通文件路径和异常情况下(如无效路径)的表现。
测试数据设计:
相似度得分 (similarity_score = 0.85):用来测试是否能正确写入文件。
self.similarity_score_path:用于保存测试结果的路径,测试能否成功写入文件并读取结果验证。
无效文件路径 (/invalid_path/test_similarity_score.txt):用于测试写入文件失败的处理(模拟文件路径无权限等问题)。
检查点:
检查文件内容是否与预期一致(即 "文章相似度:0.85")。
在无效路径下写入文件时,检查函数是否抛出适当的异常。
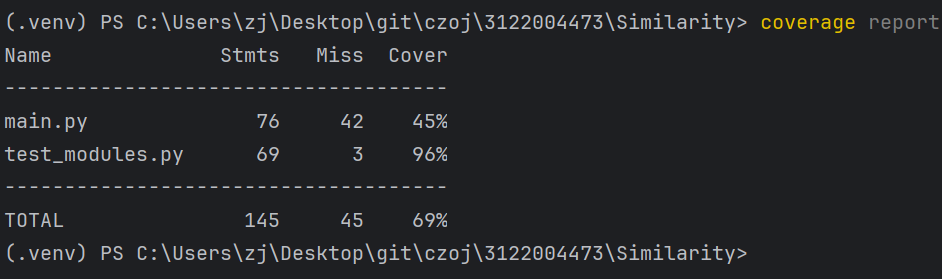
4.覆盖率
六、模块部分异常处理说明
1. read_file 函数的异常处理
def read_file(file_path):try:with open(file_path, 'r', encoding='UTF-8') as file:return file.read()except FileNotFoundError:print(f"错误:文件 {file_path} 未找到。请检查路径是否正确。")return Noneexcept Exception as e:print(f"读取文件 {file_path} 时出错:{e}")return None
FileNotFoundError: 捕获文件不存在的情况,提示用户检查路径,避免程序崩溃,返回None。- 通用异常 (
Exception): 捕获其他可能的文件读取错误(如权限问题等),输出错误信息并返回None。
2. calculate_cosine_similarity 函数的异常处理
def calculate_cosine_similarity(tokens1, tokens2):try:# 创建词典并计算余弦相似度dictionary = gensim.corpora.Dictionary([tokens1, tokens2])corpus = [dictionary.doc2bow(tokens) for tokens in [tokens1, tokens2]]similarity_index = gensim.similarities.Similarity('-Similarity-index', corpus, num_features=len(dictionary))cosine_similarity = similarity_index[corpus[0]][1]return cosine_similarityexcept Exception as e:print(f"计算相似度时出错:{e}")return None
- 通用异常 (
Exception): 捕获所有在计算余弦相似度过程中可能发生的错误,如词典生成或相似度计算错误,输出错误信息并返回None。
3. save_result 函数的异常处理
def save_result(result_path, similarity_score):try:with open(result_path, 'w', encoding="utf-8") as result_file:result_file.write(f"文章相似度:{similarity_score:.2f}")except Exception as e:print(f"写入文件 {result_path} 时出错:{e}")return
- 通用异常 (
Exception): 捕获文件写入时的所有异常(如路径错误或权限问题),输出错误信息并继续执行
![[极客大挑战 2019]LoveSQL 1](https://img2024.cnblogs.com/blog/3518346/202409/3518346-20240912233041539-1835399771.png)




![[NLP/AIGC] 大语言模型:零一万物](https://blog-static.cnblogs.com/files/johnnyzen/cnblogs-qq-group-qrcode.gif?t=1679679148)