1 概述 : RAG
RAG 技术的概念、起源
大家每天都会看到各种 RAG 框架、论文和开源项目,也都知道 RAG (Retrieval-Augmented Generation) 是检索增强型生成。
但大家还记得 RAG 这个概念源自哪里吗?
RAG 概念来自 Facebook AI Research在 2020 年的一篇论文:
《** Retrieval-Augmented Generation forKnowledge-Intensive NLP Tasks **》
https://arxiv.org/pdf/2005.11401
为什么2020年提出,如今才火起来,很大部分原因是由于基线大模型能力变强,让大模型+知识库的方式,可以回答的问题确实能够满足企业的相当部分需求。
- 内容小结
- RAG概念:
RAG(Retrieval-Augmented Generation)是检索增强型生成,来源于Facebook AI Research 2020年的一篇论文,用于知识密集型NLP任务。
- 兴起原因:
基线大模型能力的增强使得大模型+知识库的方式可以满足企业部分需求,从而推动了RAG概念的普及。
关键技术:文本分块策略
文本分块算法的产生背景
- 文本分块技术的产生背景、意义
遇到很多人在使用RAG功能时,都知道一些概念,大概知道怎么做,拿到原始文档,导到系统中,进行自动分块,自动embedding,结果召回效果并不好。
这时候有些人可能会抱怨功能不行,然后探索怎样才能达到好的效果,这时候我们注意到原始文档的分块对于检索是非常重要的。
- RAG 开发者在使用RAG框架时,最常常疑惑:如何制定正确的分块策略?
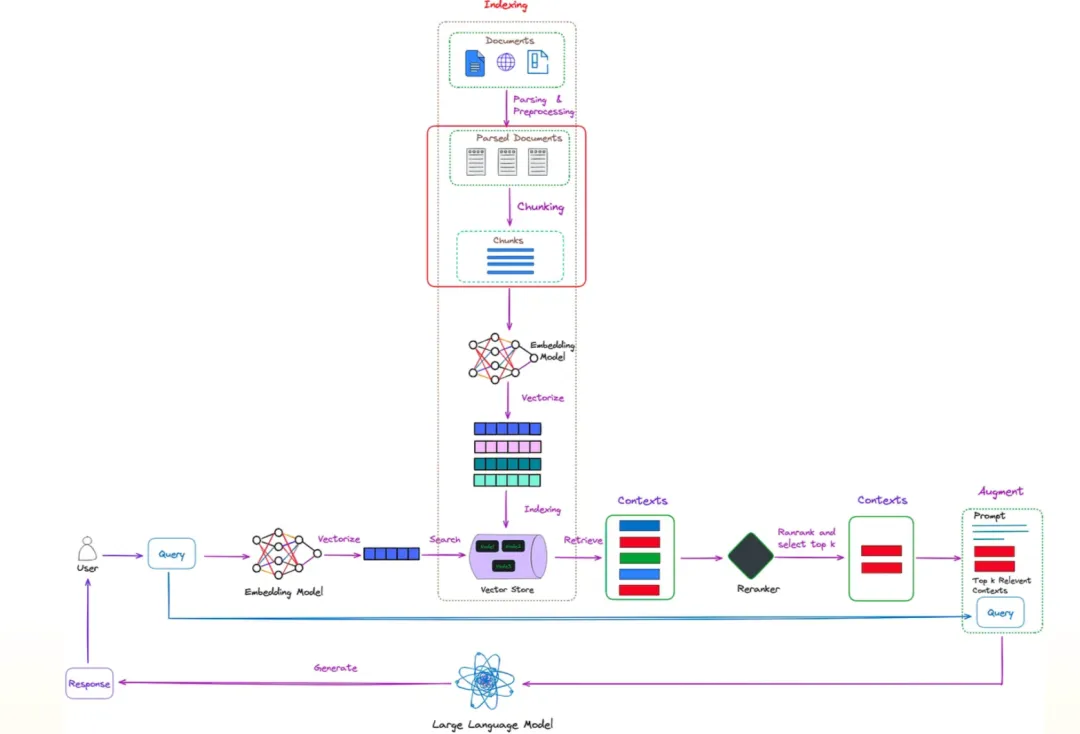
文本分块的作用 / 为什么要文本分块?
- 文本分块的定义:
从技术角度来说,“分块”是指将大量文档分割成更小、更易于管理的部分,以便模型有效地检索和处理。
分块策略至关重要,原因如下:
- 相关性和精确度:
适当分块的文档可确保检索到的信息与查询高度相关。
如果分块太大,它们可能包含大量不相关的信息,从而稀释有用的内容。
相反,如果分块太小,它们可能会错过更广泛的背景,导致响应准确但不够全面。
- 效率和性能:
区块的大小和结构会影响检索过程的效率。
较小的区块可以更快地检索和处理,从而减少系统的整体延迟。
但是,需要取得平衡,因为太多的小区块可能会使检索系统不堪重负并对性能产生负面影响。
- 生成质量:
生成的输出质量在很大程度上取决于检索到的输入。
分块良好的文档可确保RAG生成器能够访问连贯且上下文丰富的信息,从而产生更具信息性、连贯性和上下文恰当的响应。
- 可扩展性:
随着语料库规模的增长,分块变得更加重要。
经过深思熟虑的分块策略可确保系统能够有效扩展,管理更多文档,而不会显著降低检索速度或检索质量。
不同的领域和查询类型可能需要不同的分块策略。灵活的分块方法允许 RAG 系统适应各种领域和信息需求,从而最大限度地提高其在不同应用程序中的有效性。
文本分块的具体算法
从简单到复杂的分块
我们在使用Llamindex、Langchain等框架时,都提供了一些封装好的分块技术。

固定大小分块
- 这是最粗暴、最简单的文本分块方法。它将文本分解为指定字符数的块,而不考虑其内容或结构。
递归分块
- 虽然固定大小分块更容易实现,但它没有考虑文本的结构。
递归分块提供了一种替代方案。
在此方法中,我们使用一组分隔符以分层和迭代的方式将文本划分为较小的块。
如果首次尝试拆分文本未产生所需大小的块,则该方法将使用不同的分隔符对生成的块进行递归调用,直到达到所需的块大小。
Langchain 框架提供了RecursiveCharacterTextSplitter类,它使用默认分隔符(“\n\n”、“\n”、“ “, ”)拆分文本。
基于文档的分块
- 在这种分块方法中,我们根据文档的固有结构对其进行拆分。这种方法考虑了内容的流程和结构,但对于缺乏清晰结构的文档可能不那么有效。
带有Markdown的文档
- Langchain提供MarkdownTextSplitter类来分割以markdown为分隔符的文档。
使用 Python/JS 的文档
- Langchain 提供 PythonCodeTextSplitter 来根据类、函数等拆分 Python 程序,并且我们可以将语言提供给RecursiveCharacterTextSplitter 类的 from_language 方法。
包含表格的文档
- 处理表格时,基于 1 级和 2 级的拆分可能会丢失行和列之间的表格关系。
- 为了保留这种关系,请以语言模型可以理解的方式格式化表格内容(例如,使用HTML 中的标签、以“;”分隔的 CSV 格式等)。
- 在语义搜索期间,直接从表格中匹配嵌入可能具有挑战性。
- 开发人员通常在提取后总结表格,生成该摘要的嵌入,并将其用于匹配。
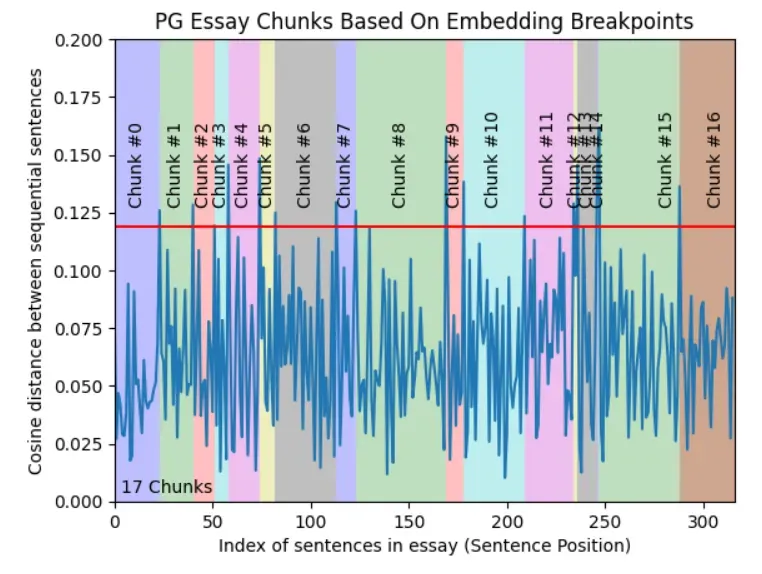
语义分块
- 以上三个层次都涉及文档的内容和结构,并且需要保持块大小的恒定值。
- 此分块方法旨在从嵌入中提取语义含义,然后评估这些块之间的语义关系。
- 核心思想是将语义相似的块放在一起。
LumberChunker
- 我们在实际使用过程中,有些人想将长篇的文章甚至小说导入RAG中,基于长篇叙述文档分割,这边论文提供了一个方法:
《Long-Form Narrative Document Segmentation》 https://arxiv.org/pdf/2406.17526
使用LumberChunker
- LumberChunker 是一种利用 LLM 将文档动态分割成语义独立的块的方法。
它以迭代方式提示 LLM 识别一组连续段落中内容开始转变的点。
这种方法基于一个前提:当内容块的大小可以变化时,检索效率会提高,因为这样可以更好地捕捉内容的语义独立性。
-
LumberChunker通过迭代地提示LLM,在一系列连续段落中识别内容开始转变的点,从而确保每个块在上下文中是连贯的,但与相邻块有所区别。 -
LumberChunker遵循一个三步流程:
首先,按段落对文档进行分割。
其次,通过追加连续的块,创建一个组(Gi),直到超过预定义的标记计数θ。
最后,将Gi作为上下文输入到Gemini,Gemini确定显著内容转变开始出现的ID,从而定义了Gi+1的开始和当前块的结束。
这个过程在整个文档中循环重复。
LumberChunker也有不足:
- 尽管它在性能上更优,但它需要使用LLM,这使得它在成本和速度上比传统方法要更高、更慢。
- LumberChunker专门设计用于叙事文本,对于高度结构化的文本,可能不是最优解决方案。
最佳实践
- 网友经验[1]:
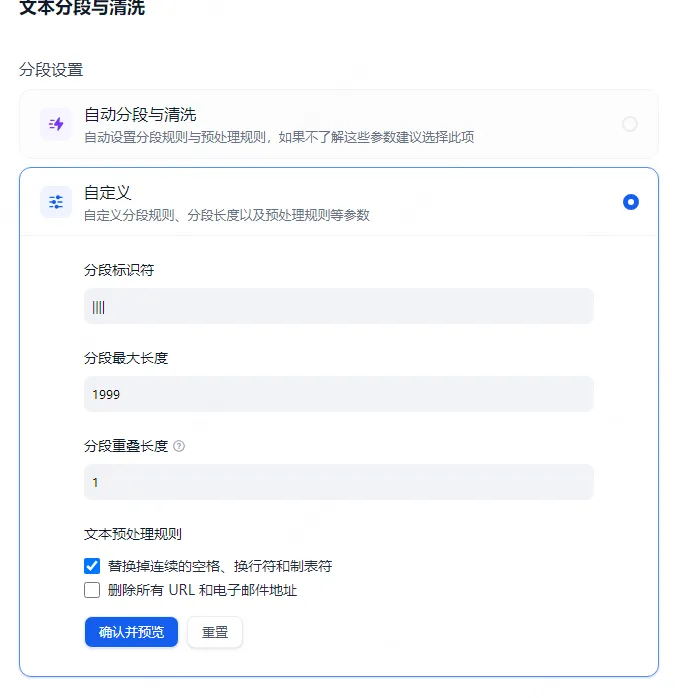
首先,在上传文档的时候需要对文档进行处理,将文档相关的内容做为一段,每段之间使用特殊符号分隔,例如“||||”;
然后,在自定义参数中按照上述配置。虽然这样,前期工作会比较复杂,但是这样处理之后检索的效率会高很多。
- 分块技术作为RAG中不可或缺的一环,选择一个合适自己知识库的分块方式,尤其重要。
理解和利用这些方法可以优化文本处理和分析,从而提高 RAG 模型和类似任务的性能。
X 参考文献
- RAG中的文本分块技术 - Weixin/TCTP
- 《Retrieval-Augmented Generation forKnowledge-Intensive NLP Tasks 》
- 《Long-Form Narrative Document Segmentation》