前几天师弟在机器学习领域看到了一个对样本选择的方法,目的是从特征的角度均匀选择样本。如下图所示,首先初始化将样本的特征进行加和并归一化,迭代取出样本(取值最大的那个样本,再令样本的值乘以1-样本的值更新所有样本)。这般便可以从理论上均匀的取到不同分布的样本,于是猜想如果这样的方法用于深度学习的样本选择,是否可以弥补batch随机选择样本的“缺陷”。我也认为这很合理,值得一试!

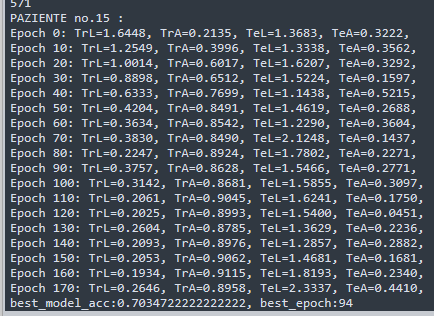
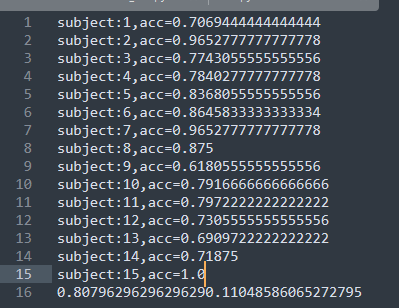
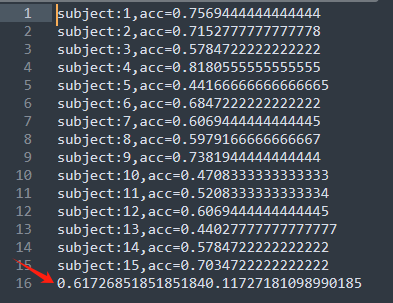
我花了一整个下午实现这个方法,下方图片中,中间的是采用原来随机的方法,左右两幅图是采用上面的方法。实验结果很差,甚至在训练集上都不能过拟合,妥妥的陷入了局部。但是没有道理呀,理论上我们的方法比随机的采样更加具有合理性,应该更能让模型均衡地学习到东西。
思索再三,还是上网搜索得到信息“使用固定的batch进行训练,可能会导致模型陷入局部最优”。那么就疑惑了,dataloader中shuffle=True难道就不是固定的了吗?你别说,事实上每一个epoch,dataloader都会重新随机采样。使用下面代码进行验证:
import torch from torch.utils.data import DataLoader, Dataset import random import numpy as np def seed_torch(seed=12):random.seed(seed)np.random.seed(seed)torch.manual_seed(seed)torch.cuda.manual_seed(seed)torch.cuda.manual_seed_all(seed) # 多GPU训练或分布式训练中torch.backends.cudnn.benchmark = Falsetorch.backends.cudnn.deterministic = True seed_torch()# 创建自定义数据集 class CustomDataset(Dataset):def __init__(self, data):self.data = datadef __len__(self):return len(self.data)def __getitem__(self, idx):return self.data[idx]# 创建包含10个数据样本的数据集 data = torch.arange(10) # 数据为 [0, 1, 2, ..., 9] dataset = CustomDataset(data)# 设置 DataLoader,batch_size=2, shuffle=True dataloader = DataLoader(dataset, batch_size=2, shuffle=True)# 运行多个 epoch 来验证每个 epoch 的 batch 顺序是否不同 num_epochs = 3 for epoch in range(num_epochs):print(f"Epoch {epoch + 1}:")for batch in dataloader:print(batch.tolist()) # 输出 batch 中的元素print('-' * 30)''' 输出结果: Epoch 1: [3, 1] [7, 0] [8, 2] [5, 6] [4, 9] ------------------------------ Epoch 2: [2, 6] [5, 8] [9, 0] [1, 3] [4, 7] ------------------------------ Epoch 3: [9, 5] [4, 7] [8, 0] [3, 1] [2, 6] ------------------------------ '''
结果就是,我们之前讨论方法存在问题,直接使用上面的算法会固定batch的生成,从而造成模型陷入局部解。但是理论上,随机取样本仍然可能存在样本不平衡的情况,或许半随机+半均匀采样结合起来才能避免二者问题。