什么是 CPU 上下文?
多个进程竞争 CPU 会导致平均负载( Load Average)升高,但是进程在竞争 CPU 的时候并没有真正运⾏,为什么还会导致系统的负载升⾼呢?原因就在于CPU 上下⽂切换。Linux 是⼀个多任务操作系统,它⽀持远⼤于 CPU 数量的任务同时运⾏。当然,这些任务实际上并不是真的在同时运⾏,而是
因为系统在很短的时间内,将 CPU 轮流分配给它们,造成多任务同时运⾏的错觉。⽽在每个任务运⾏前,CPU 都需要知道任务从哪⾥加载、⼜从哪⾥开始运⾏,也就是说,需要系统事先帮它设置好 CPU 寄存器和程序计数器(Program Counter,PC)。CPU 寄存器,是 CPU 内置的容量⼩、但速度极
快的内存。⽽程序计数器,则是⽤来存储 CPU 正在执⾏的指令位置、或者即将执⾏的下⼀条指令位置。它们都是 CPU 在运⾏任何任务前,必须的依赖环境,因此也被叫做 CPU 上下⽂。
什么是 CPU 上下文切换?
CPU 上下⽂切换,就是先把前⼀个任务的 CPU 上下⽂(也就是 CPU 寄存器和程序计数器)保存起来,然后加载新任务的上下⽂到这些寄存器和程序计数器,最后再跳转到程序计数器所指的新位置,运⾏新任务。⽽这些保存下来的上下⽂,会存储在系统内核中,并在任务重新调度执⾏时再次加载进来。
这样就能保证任务原来的状态不受影响,让任务看起来还是连续运⾏。
CPU 上下文切换类型
根据任务的不同,CPU 的上下⽂切换就可以分为⼏个不同的场景,也就是
- 进程上下⽂切换
- 线程上下⽂切换
- 中断上下⽂切换
进程上下⽂切换
Linux 按照特权等级,把进程的运⾏空间分为内核空间和⽤户空间,分别对应着下图中, CPU 特权等级的 Ring 0 和 Ring 3。
- 内核空间(Ring 0)具有最⾼权限,可以直接访问所有资源;
- ⽤户空间(Ring 3)只能访问受限资源,不能直接访问内存等硬件设备,必须通过系统调⽤陷⼊到内核中,才能访问这些特权资源。
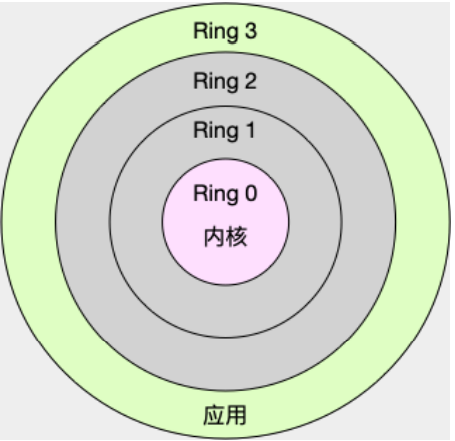
换个⻆度看,也就是说,进程既可以在⽤户空间运⾏,⼜可以在内核空间中运⾏。进程在⽤户空间运⾏时,被称为进程的⽤户态,⽽陷⼊内核空间的时候,被称为进程的内核态。从⽤户态到内核态的转变,需要通过系统调⽤来完成。⽐如,当我们查看⽂件内容时,就需要多次系统调⽤来完成:
- ⾸先调⽤open() 打开⽂件
- 然后调⽤ read() 读取⽂件内容
- 接着调⽤ write() 将内容写到标准输出
- 最后再调⽤ close() 关闭⽂件。
系统调⽤的过程会发⽣ CPU 上下⽂的切换。CPU 寄存器⾥原来⽤户态的指令位置,需要先保存起来。接着,为了执⾏内核态代码,CPU 寄存器需要更新为内核态指令的新位置。最后才是跳转到内核态运⾏内核任务。⽽系统调⽤结束后,CPU寄存器需要恢复原来保存的⽤户态,然后再切换到⽤户空间,
继续运⾏进程。所以,⼀次系统调⽤的过程,其实是发⽣了两次 CPU 上下⽂切换。不过,需要注意的是,系统调⽤过程中,并不会涉及到虚拟内存等进程⽤户态的资源,也不会切换进程。这跟我们通常所说的进程上下⽂切换是不⼀样的:
- 进程上下⽂切换,是指从⼀个进程切换到另⼀个进程运⾏。
- 系统调⽤过程中⼀直是同⼀个进程在运⾏。
所以,系统调⽤过程通常称为特权模式切换,⽽不是上下⽂切换。但实际上,系统调⽤过程中,CPU 的上下⽂切换还是⽆法避免的。
进程上下⽂切换跟系统调的区别
进程是由内核来管理和调度的,进程的切换只能发⽣在内核态。所以,进程的上下⽂不仅包括了虚拟内存、栈、全局变量等⽤户空间的资源,还包括了内核堆栈、寄存器等内核空间的状态。因此,进程的上下⽂切换就⽐系统调⽤时多了⼀步:在保存当前进程的内核状态和CPU寄存器之前,需要先把该进
程的虚拟内存、栈等保存下来;⽽加载了下⼀进程的内核态后,还需要刷新进程的虚拟内存和⽤户栈。如下图所示,保存上下⽂和恢复上下⽂的过程并不是“免费”的,需要内核在 CPU 上运⾏才能完成。

根据 Tsuna 的测试报告,每次上下⽂切换都需要⼏⼗纳秒到数微秒的 CPU 时间。如果是在进程上下⽂切换次数较多的情况下,很容易导致 CPU 将⼤量时间耗费在寄存器、内核栈以及虚拟内存等资源的保存和恢复上,进⽽⼤⼤缩短了真正运⾏进程的时间。这也正是上⼀节中我们所讲的,导致平均负载升
⾼的⼀个重要因素。另外,Linux 通过 TLB(Translation Lookaside Buffer)来管理虚拟内存到物理内存的映射关系。当虚拟内存更新后,TLB 也需要刷新,内存的访问也会随之变慢。特别是在多处理器系统上,缓存是被多个处理器共享的,刷新缓存不仅会影响当前处理器的进程,还会影响共享缓存的
其他处理器的进程。
什么时候会切换进程上下⽂
显然,进程切换时才需要切换上下⽂,换句话说,只有在进程调度的时候,才需要切换上下⽂。Linux 为每个 CPU 都维护了⼀个就绪队列,将活跃进程(即正在运⾏和正在等待CPU的进程)按照优先级和等待 CPU 的时间排序,然后选择最需要CPU 的进程,也就是优先级最⾼和等待CPU时间最⻓的进程
来运⾏。那么,进程在什么时候才会被调度到 CPU 上运⾏呢?最容易想到的⼀个时机,就是进程执⾏完终⽌了,它之前使⽤的CPU会释放出来,这个时候再从就绪队列⾥,拿⼀个新的进程过来运⾏。其实还有很多其他场景,也会触发进程调度
- 为了保证所有进程可以得到公平调度,CPU时间被划分为⼀段段的时间⽚,这些时间⽚再被轮流分配给各个进程。这样,当某个进程的时间⽚耗尽了,就会被系统挂起,切换到其它正在等待 CPU 的进程运⾏。
- 进程在系统资源不⾜(⽐如内存不⾜)时,要等到资源满⾜后才可以运⾏,这个时候进程也会被挂起,并由系统调度其他进程运⾏。
- 当进程通过睡眠函数 sleep 这样的⽅法将⾃⼰主动挂起时,⾃然也会重新调度。
- 当有优先级更⾼的进程运⾏时,为了保证⾼优先级进程的运⾏,当前进程会被挂起,由⾼优先级进程来运⾏。
- 发⽣硬件中断时,CPU上的进程会被中断挂起,转⽽执⾏内核中的中断服务程序。
了解这⼏个场景是⾮常有必要的,因为⼀旦出现上下⽂切换的性能问题,它们就是幕后凶⼿。
线程上下⽂切换
说完了进程的上下⽂切换,我们再来看看线程相关的问题。线程与进程最⼤的区别在于:
- 线程是调度的基本单位
- 进程则是资源拥有的基本单位
说⽩了,所谓内核中的任务调度,实际上的调度对象是线程;⽽进程只是给线程提供了虚拟内存、全局变量等资源。所以,对于线程和进程,我们可以这么理解:
- 当进程只有⼀个线程时,可以认为进程就等于线程。
- 当进程拥有多个线程时,这些线程会共享相同的虚拟内存和全局变量等资源。这些资源在上下⽂切换时是不需要修改的。
另外,线程也有⾃⼰的私有数据,⽐如栈和寄存器等,这些在上下⽂切换时也是需要保存的。这么⼀来,线程的上下⽂切换其实就可以分为两种情况:
- 第⼀种, 前后两个线程属于不同进程。此时,因为资源不共享,所以切换过程就跟进程上下⽂切换是⼀样。
- 第⼆种,前后两个线程属于同⼀个进程。此时,因为虚拟内存是共享的,所以在切换时,虚拟内存这些资源就保持不动,只需要切换线程的私有数据、寄存器等不共享的数据。
所以虽然同为上下⽂切换,但同进程内的线程切换,要⽐多进程间的切换消耗更少的资源,⽽这,也正是多线程代替多进程的⼀个优势。
中断上下⽂切换
除了前⾯两种上下⽂切换,还有⼀个场景也会切换 CPU 上下⽂,那就是中断。为了快速响应硬件的事件,中断处理会打断进程的正常调度和执⾏,转⽽调⽤中断处理程序,响应设备事件。⽽在打断其他进程时,就需要将进程当前的状态保存下来,这样在中断结束后,进程仍然可以从原来的状态恢复运
⾏。跟进程上下⽂不同,中断上下⽂切换并不涉及到进程的⽤户态。所以,即便中断过程打断了⼀个正处在⽤户态的进程,也不需要保存和恢复这个进程的虚拟内存、全局变量等⽤户态资源。中断上下⽂,其实只包括内核态中断服务程序执⾏所必需的状态,包括CPU 寄存器、内核堆栈、硬件中断参数
等。对同⼀个 CPU 来说,中断处理⽐进程拥有更⾼的优先级,所以中断上下⽂切换并不会与进程上下⽂切换同时发⽣。同样道理,由于中断会打断正常进程的调度和执⾏,所以⼤部分中断处理程序都短⼩精悍,以便尽可能快的执⾏结束。另外,跟进程上下⽂切换⼀样,中断上下⽂切换也需要消耗
CPU,切换次数过多也会耗费⼤量的 CPU,甚⾄严重降低系统的整体性能。所以,当你发现中断次数过多时,就需要注意去排查它是否会给你的系统带来严重的性能问题。
⼩结
不管是哪种场景导致的上下⽂切换,你都应该知道:
- CPU 上下⽂切换,是保证 Linux 系统正常⼯作的核⼼功能之⼀,⼀般情况下不需要我们特别关注。
- 但过多的上下⽂切换,会把CPU时间消耗在寄存器、内核栈以及虚拟内存等数据的保存和恢复上,从⽽缩短进程真正运⾏的时间,导致系统的整体性能⼤幅下降。