目录
- 一、引言
- 二、ArrayList
- 2.1 ArrayList是什么?
- 2.2 ArrayList的历史由来
- 2.3 ArrayList的使用好处
- 2.4 ArrayList的底层原理
- 2.5 ArrayList的操作方法及代码示例
- 三、LinkedList
- 3.1 LinkedList是什么?
- 3.2 LinkedList的历史由来
- 3.3 LinkedList的使用好处
- 3.4. LinkedList的底层原理
- 3.5 LinkedList的操作方法及代码示例
- 四、表格对比二者区别
- 五、相关面试题
一、引言
ArrayList和LinkedList是Java集合框架中常用的两种列表实现。它们都实现了List接口,提供了类似于数组的数据结构,可以按照索引访问和操作元素,以及支持动态调整大小。然而,两者在内部实现和性能方面有所不同。
在本文中,我们将探讨ArrayList和LinkedList的内部实现原理、常用操作的性能特点以及适用场景的选择依据。通过了解它们的区别和使用场景,你将能够更加理解和灵活地运用它们来满足不同的开发需求。
二、ArrayList
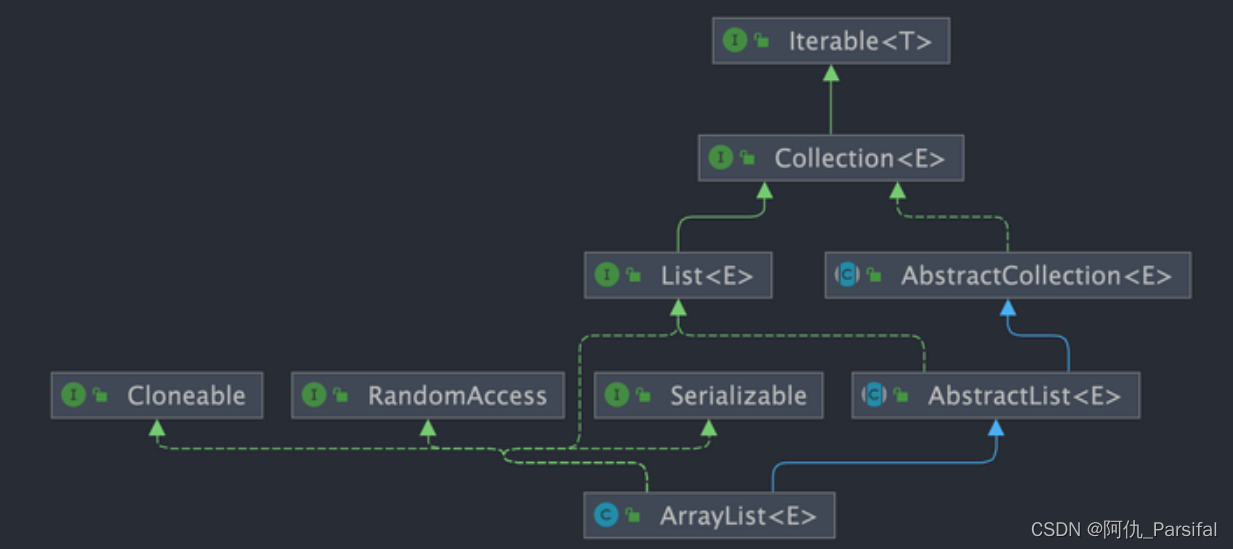
2.1 ArrayList是什么?
ArrayList是Java集合框架中的一种实现类,它实现了List接口,提供了一个动态数组的实现。
2.2 ArrayList的历史由来
ArrayList的历史由来可以追溯到Java 1.2版本。在早期的Java版本中,Java提供了Vector(向量)类来表示动态数组。然而,Vector类的设计存在一些性能和同步问题,因此Java开发团队决定引入一个新的类来替代Vector,即ArrayList。
ArrayList的设计目标是提供一种高效的动态数组实现,以满足开发者在处理大量数据时的需求。相比于Vector,ArrayList具有更好的性能和可扩展性。它可以动态调整大小,支持随机访问,同时还提供了一系列的常用操作方法,如添加、删除、查找等。
2.3 ArrayList的使用好处
- 快速访问: 由于ArrayList实现了动态数组,可以通过索引非常快速地访问和修改元素。
- 方便的插入和删除: ArrayList可以通过调整数组大小来实现元素的插入和删除操作,这样不会导致其他元素的移动。
- 可变大小: ArrayList的大小是可变的,可以根据需要动态调整。
2.4 ArrayList的底层原理
ArrayList是基于数组实现的动态数组,它的底层原理主要包括以下几个要点:
1、内部数组:ArrayList使用一个内部数组来存储元素。这个数组是一个连续的内存块,通过索引可以直接访问元素。默认情况下,ArrayList会初始化一个初始大小的数组,当元素数量超过数组大小时,会自动进行扩容。
2、动态扩容:当ArrayList的元素数量超过数组大小时,会触发自动扩容操作。ArrayList通过创建一个更大的新数组,并将原数组的元素复制到新数组中来实现扩容。通常情况下,新数组的大小会是原数组大小的一倍,以实现平均时间复杂度为O(1)的插入操作。
3、连续内存:由于ArrayList使用连续的内存,因此在进行元素的插入和删除操作时,可能需要进行大量的元素移动。例如,在数组的中间位置插入一个元素会导致插入位置后面的所有元素都向后移动一个位置。同样地,删除一个元素可能需要将后面的所有元素向前移动一个位置。这种情况下,插入和删除操作的时间复杂度为O(n),其中n是数组中的元素数量。
4、随机访问:由于ArrayList是基于数组实现的,所以支持高效的随机访问。通过索引,可以以O(1)的时间复杂度直接访问数组中的元素。
2.5 ArrayList的操作方法及代码示例
import java.util.ArrayList;public class ArrayListExample {public static void main(String[] args) {// 创建ArrayListArrayList<String> arrayList = new ArrayList<>();// 添加元素arrayList.add("Apple");arrayList.add("Banana");arrayList.add("Orange");// 获取元素String firstElement = arrayList.get(0);System.out.println("第一个元素是:" + firstElement); // Output: 第一个元素是:Apple// 修改元素arrayList.set(1, "Grapes");System.out.println("修改后的元素是:" + arrayList); // Output: 修改后的元素是:[Apple, Grapes, Orange]// 删除元素arrayList.remove(2);System.out.println("删除后的元素是:" + arrayList); // Output: 删除后的元素是:[Apple, Grapes]}
}
三、LinkedList
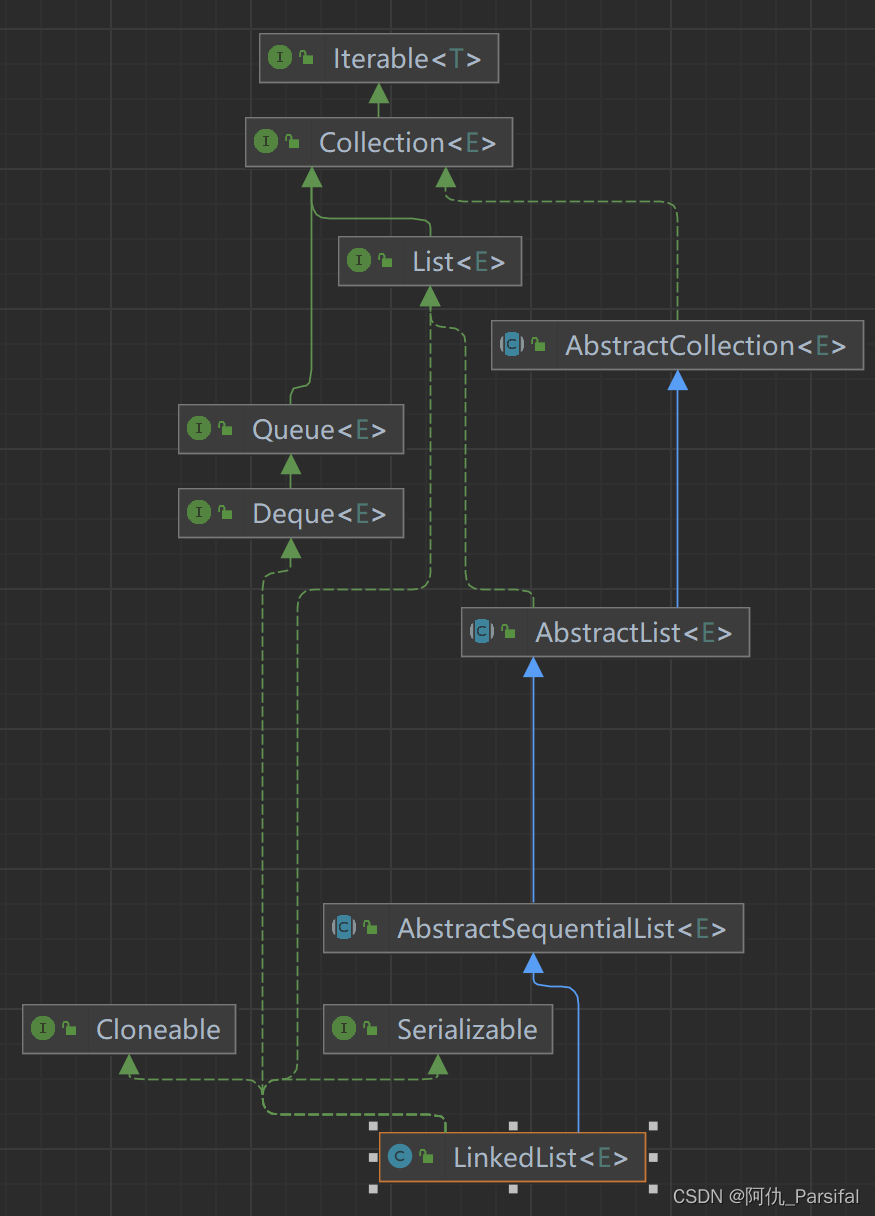
3.1 LinkedList是什么?
LinkedList是Java中的一个双向链表实现的类,同样也实现了List接口。LinkedList的节点包含了对前一个节点和后一个节点的引用,允许以O(1)的时间复杂度在任意位置插入和删除元素。
3.2 LinkedList的历史由来
链表(LinkedList)的历史由来可以追溯到计算机科学的早期。链表是一种基本的数据结构,用于在内存中组织和管理数据。链表最早在20世纪60年代被引入到计算机科学中,作为一种替代数组的数据结构。
3.3 LinkedList的使用好处
- 高效的插入和删除操作: 由于LinkedList是双向链表的实现,插入和删除操作只需要改变节点之间的引用,不需要像ArrayList那样调整数组大小。
- 非常适合频繁的插入和删除操作: LinkedList对于频繁的插入和删除操作表现更加高效。
- 实现了Queue和Deque接口: LinkedList还实现了Queue和Deque接口,可以作为队列和双端队列使用。
3.4. LinkedList的底层原理
LinkedList内部通过双向链表来存储元素。每个节点包含了一个元素和对前一个节点和后一个节点的引用。底层原理主要包括以下几个要点:
1、节点类:LinkedList中的每个元素被封装成一个节点对象,这个节点对象包含了数据和两个指针,即前驱指针和后继指针。通过前驱指针和后继指针,可以在链表中实现元素的插入、删除和访问操作。
2、头节点和尾节点:LinkedList中有两个特殊的节点,即头节点和尾节点。头节点是链表的第一个节点,尾节点是链表的最后一个节点。它们分别通过头指针和尾指针指向链表的首尾。
3、双向链表:每个节点都包含一个指向前一个节点的指针和一个指向后一个节点的指针,这样的链表结构就是双向链表。双向链表可以实现双向遍历,即可以从头节点向后一个个遍历,也可以从尾节点向前一个个遍历。
4、插入操作:在LinkedList进行插入操作时,会创建一个新的节点对象,并调整相邻节点的指针指向。例如,在链表的中间位置插入一个元素,需要先创建一个新的节点对象,然后将新节点的前驱指针指向插入位置的前一个节点,将新节点的后继指针指向插入位置的后一个节点,最后调整相邻节点的指针指向新节点。
5、删除操作:在LinkedList进行删除操作时,会通过调整相邻节点的指针指向来删除指定节点。例如,在链表中删除一个节点,只需要将被删除节点的前驱指针指向被删除节点的后一个节点,将被删除节点的后继指针指向被删除节点的前一个节点,最后将被删除节点对象回收。
3.5 LinkedList的操作方法及代码示例
import java.util.LinkedList;public class LinkedListExample {public static void main(String[] args) {// 创建LinkedListLinkedList<String> linkedList = new LinkedList<>();// 添加元素linkedList.add("Apple");linkedList.add("Banana");linkedList.add("Orange");// 获取元素String firstElement = linkedList.getFirst();System.out.println("第一个元素是:" + firstElement); // Output: 第一个元素是:Apple// 修改元素linkedList.set(1, "Grapes");System.out.println("修改后的元素是:" + linkedList); // Output: 修改后的元素是:[Apple, Grapes, Orange]// 删除元素int elementToRemove = 20;boolean removeResult = linkedList.remove(Integer.valueOf(elementToRemove));if (removeResult) {System.out.println("成功删除元素:" + elementToRemove);} else {System.out.println("无法删除元素:" + elementToRemove);}System.out.println("修改后的链表:" + linkedList);}
}
四、表格对比二者区别

五、相关面试题
-
ArrayList和LinkedList的区别是什么?
答:ArrayList是基于数组实现的,它在内存中是连续存储的,支持对元素的随机访问和快速插入/删除操作。LinkedList是基于链表实现的,它在内存中的元素是通过指针连接的,支持高效的插入/删除操作,但随机访问元素的性能较差。 -
如何选择ArrayList或LinkedList?
答:如果需要频繁执行随机访问元素的操作,并且对于插入和删除操作的性能要求不高,可以选择ArrayList。如果需要频繁执行插入和删除操作,而对于随机访问的需求不太高,可以选择LinkedList。 -
ArrayList和LinkedList的插入和删除操作的时间复杂度是多少?
答:对于ArrayList,插入和删除操作的时间复杂度是O(n),因为在数组中需要移动元素。对于LinkedList,插入和删除操作的时间复杂度是O(1),因为只需修改指针即可。 -
ArrayList和LinkedList的查找操作的时间复杂度是多少?
答:对于ArrayList,查找操作的时间复杂度是O(1),因为可以通过索引直接访问数组中的元素。对于LinkedList,查找操作的时间复杂度是O(n),因为需要从头节点开始遍历链表找到目标元素。 -
在什么情况下应该使用ArrayList,而在什么情况下应该使用LinkedList?
答:当需要频繁执行随机访问元素的操作或者仅需要在末尾进行插入和删除时,应该使用ArrayList。当需要频繁执行插入和删除操作,或者需要在其他位置插入和删除元素时,应该使用LinkedList。 -
ArrayList和LinkedList在空间复杂度方面有什么区别?
答:ArrayList的空间复杂度是O(n),其中n是存储的元素数量,因为它需要一个连续的数组来存储元素。LinkedList的空间复杂度也是O(n),但在实际使用中,它可能更占用内存,因为除了存储元素本身外,还需要额外的指针来连接元素。
如果本篇博客对您有一定的帮助,请您留下宝贵的三连:留言+点赞+收藏哦。