事情起因
最近一段时间我们公司有个项目是做视力筛查的,平时都是正常的,但是最近这两天突然会时不时地卡顿一下,一卡就是几分钟。
排查过程
1.查看日志
卡顿首先是排查日志,日志报的是feign调用学生服务超时,进到学生服务查看时,看到日志报的是事务超时
2.继续排查,既然是事务超时,查看mysql锁
select * from performance_schema.data_lock_waits另外还有个复杂的查询sql就不贴了,反正就是没有查到锁,可能也是查的时候已经锁释放了。
然后查看innodb日志
show engine innodb status发现没有输出结果,搞半天不知道啥原因(后来发现是navicat的原因,结果没显示全)
3.查看代码
简单走读一下代码,发现主要卡顿的那个接口代码里用了@Transational注解,而且这个接口里包含了多个feign调用,这个显然不太合理。如果feign调用慢,会增加事务的提交时间。但是这是另外一个问题,因为被锁超时的是学生服务,不是调用它的视力服务。而学生服务里代码很简单,就是简单的查询。因此仍未查到根源,继续排查
4.查看磁盘io
后来还发现一个现象,就是偶尔超时的不只是那个接口,还有其他的表查询和接口,以及clickhouse的查询也有慢的(clickhouse是另外一个服务在调用的)。
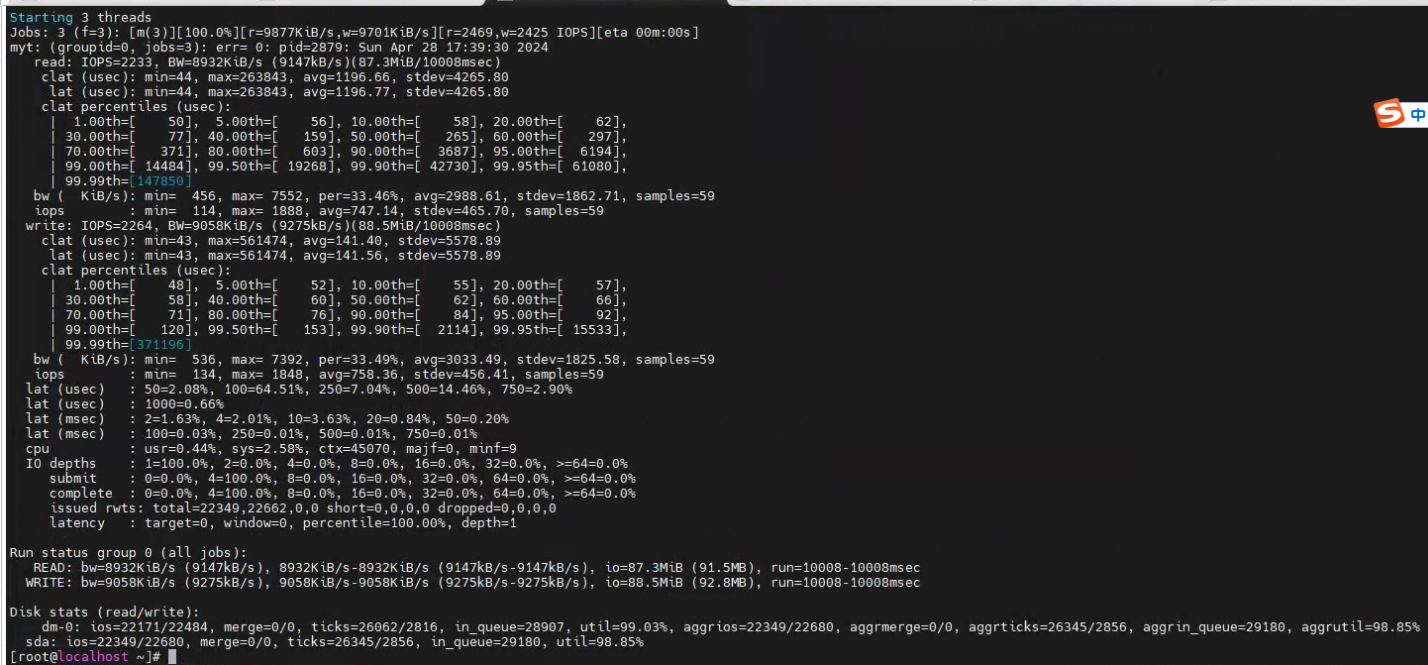
由于曾经数字家医那个项目也曾出现过类似的现象,是由于更新和插入操作太多,造成间歇性卡顿,并且那边服务器的磁盘性能也不是很好(那边最后是通过减少大量的业务增改操作来解决的),所以这边我第一时间也是查看了磁盘io,我用fio测试工具测试的结果如下:
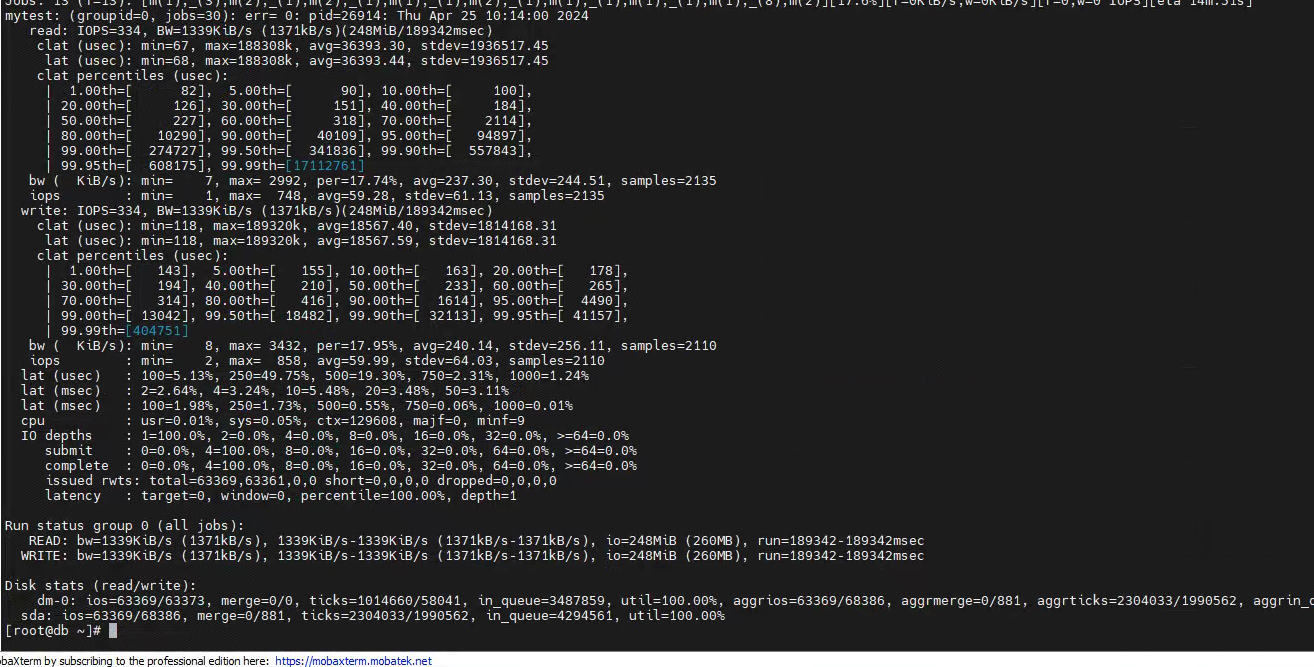
可以看到磁盘io最低的时候iops已经到了1,平均也才几十。
虽然看到磁盘io很差,但是由于当时考虑磁盘更换麻烦,而且并没有磁盘io差导致卡顿的先例,所以也是先记下了这个问题,继续从其他方面入手排查
这里附上测试的命令
fio -filename=test.log -direct=1 -iodepth 1 -thread -rw=randrw -ioengine=psync -bs=4k -size=1G -numjobs=4 -runtime=10 -group_reporting -name=mytestfilename 读写的文件,会自动创建,不要用已存在的文件,它会往里写二进制数据,这个参数一定不能为空,不然坐等删库跑路吧
-rw=randrw 代表是随机读写
-numjobs=4 代表是开启4个线程一起操作
-runtime=10 是执行10秒,这个可以稍微大一点5.分开部署clickhouse和mysql
上面的迹象让我感觉是不是clickhouse和mysql部署在一起导致互相竞争资源,并且当时这台服务器只有4G内存。于是向客户申请了一台单独的机器部署clickhouse,并升级了配置。部署完以后第二天发现还是会发生卡顿现象,于是继续排查
6.查看慢日志
既然看不了innodb日志,就看一下慢日志
慢日志里有很多的下面这种日志
# Time: 2024-04-24T16:43:54.679098+08:00
# User@Host: edu_health_app[edu_health_app] @ [172.16.5.183] Id: 330916
# Query_time: 50.073778 Lock_time: 0.000000 Rows_sent: 0 Rows_examined: 0
SET timestamp=1713948184;
commit;
# Time: 2024-04-24T16:51:16.271288+08:00
# User@Host: edu_health_app[edu_health_app] @ [172.16.5.183] Id: 330914
# Query_time: 180.347378 Lock_time: 0.000000 Rows_sent: 0 Rows_examined: 0
SET timestamp=1713948495;
commit;
# Time: 2024-04-24T16:51:16.271384+08:00
# User@Host: edu_health_app[edu_health_app] @ [172.16.5.183] Id: 330916
# Query_time: 179.729376 Lock_time: 0.000000 Rows_sent: 0 Rows_examined: 0
SET timestamp=1713948496;
commit;
# Time: 2024-04-24T16:51:16.271453+08:00
# User@Host: edu_health_app[edu_health_app] @ [172.16.5.183] Id: 330915
# Query_time: 174.483131 Lock_time: 0.000000 Rows_sent: 0 Rows_examined: 0
SET timestamp=1713948501;
commit;
# Time: 2024-04-24T16:51:16.271494+08:00
# User@Host: edu_health_app[edu_health_app] @ [172.16.5.183] Id: 330845
# Query_time: 168.485559 Lock_time: 0.000000 Rows_sent: 0 Rows_examined: 0
SET timestamp=1713948507;
commit;以及时间很长的查询(我删除了大部分内容):
# Time: 2024-04-25T15:18:07.672106+08:00
# User@Host: edu_health_app[edu_health_app] @ [172.16.5.183] Id: 193
# Query_time: 152.159829 Lock_time: 0.000003 Rows_sent: 0 Rows_examined: 0
SET timestamp=1714029335;
INSERT INTO tb_exam_eyesight ( id,creator,
operator,
is_deleted ) VALUES ( 1374268092235520,624545294563164160,
624545294563164160,
0 );
# Time: 2024-04-25T15:18:07.672148+08:00
# User@Host: edu_health_app[edu_health_app] @ [172.16.5.183] Id: 195
# Query_time: 179.016619 Lock_time: 0.000001 Rows_sent: 0 Rows_examined: 0
SET timestamp=1714029308;
INSERT INTO tb_exam_eyesight ( id,creator,
operator,
is_deleted ) VALUES ( 1374267870420736,500024611083403264,
500024611083403264,
0 );可以看到这些sql的Query_time都很长,但是Lock_time却很少,说明并不是被其他sql锁住了,而是本身的执行时间长(这些sql很多都是插入语句,以及根据主键更新的,所以没有性能问题)。
还有#Time都是一样的,几乎在同一时间完成。那说明sql都在等待什么东西释放,考虑过后感觉很像redo log的刷脏页,就是所谓的mysql抖动。
7.更改mysql配置
把innodb_io_capacity(控制刷脏页的速度,建议设置成磁盘的iops)从默认200改成了100,因为上面看到磁盘io性能差,如果这个值太高反而会降低刷脏页速度
把sync_binlog和innodb_flush_log_at_trx_commit尝试调整成了0,减少磁盘io,加快速度
后面发现还是没什么用。(后来想想其实根本不可能是这种情况,因为我们业务量很少,一天也新增不了多少数据,一万条都不到)
8.装监控
无奈,先装上监控试试,原先客户环境配置太低,也装不了监控,现在客户把资源放开了,装上监控也是条不错的路子,于是装了grafana和skywalking,以及手动写的监控脚本(sar命令实现的)
持续观察发现磁盘io使用率动不动就飙升到100%,而且在卡顿的时候去看就是维持在100%,于是我觉得还是磁盘io有问题。
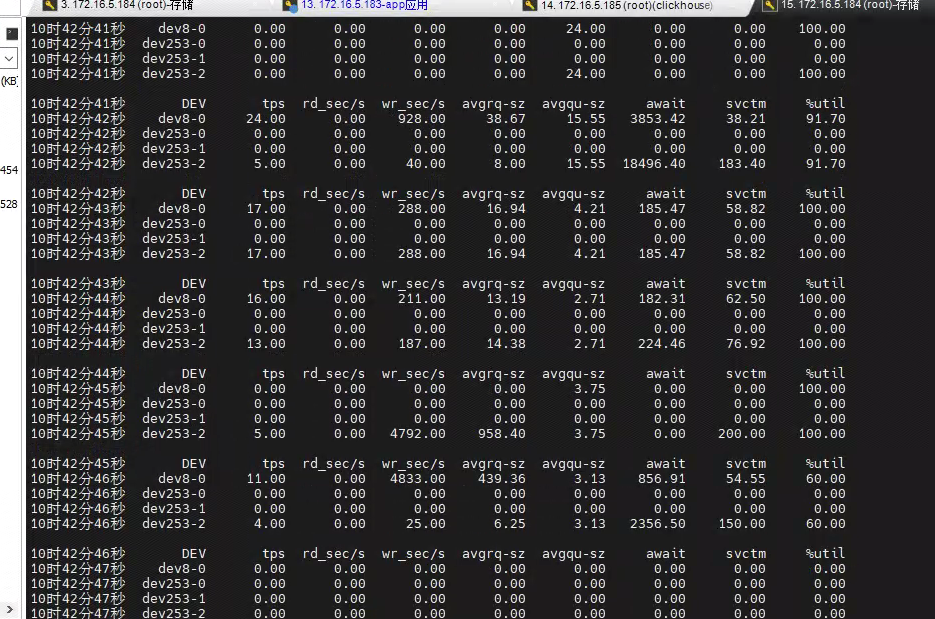
9.换磁盘
由于原先换服务器是在同一台服务器上的,因此做不到隔离磁盘,于是向客户申请换一个不在同一台物理机的磁盘,原本以为很麻烦,没想到客户有超融合服务器,直接切换一下就切换到新物理机上了,都不影响业务。
顺利切换以后观察了一下午,再没出现过卡顿问题。至此问题解决,问题也确诊为磁盘性能问题了。
总结
磁盘性能差导致服务性能的情况很少见,但从这次经历也收获了一些经验,如果磁盘性能有问题,从以下几个征兆就可以看出来了:
- 磁盘io性能测试结果很差,iops基本在200以下,偶尔会到个位数,那肯定不正常了
- 如果有多个服务,多个服务同时受影响,比如这次clickhouse和mysql同时报超时
- mysql多个慢查询同时完成(慢日志里可以看到)
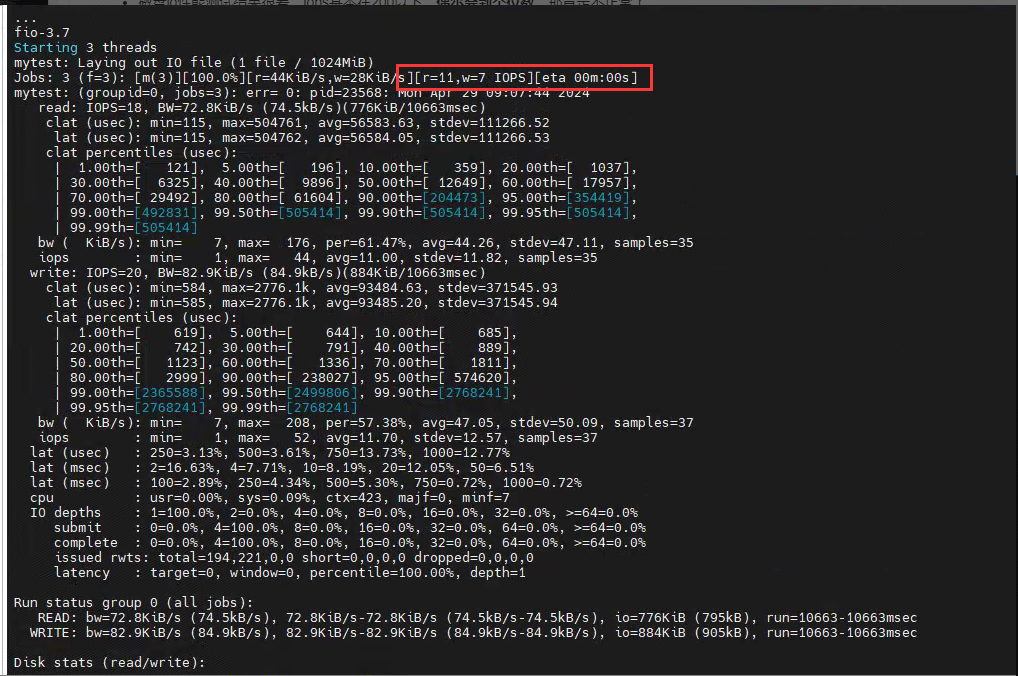
最后我又去测了一下磁盘差的那台服务器和正常的服务器,看最上面的r和w就行,差的时候已经到个位数了,有时候甚至是0。对比图如下:
io有问题的服务器:
io正常的服务器: