时间紧任务重,可能有误,烦请指正 QwQ
题目内代码可能有些许错误,应该不大影响查看吧,这个难改就不改哩
第1题 (2分)
在Linux系统中,如果你想显示当前工作目录的路径,应该使用哪个命令?( )
A. pwd
B. cd
C. ls
D. echo
pwd可以显示当前的工作路径
cd表示切换工作路径
ls表示列出当前工作路径下的所有文件和目录
echo表示将输入的字符串进行标准输出
第2题 (2分)
假设一个长度为n 的整数数组中每个元素值互不相同,且这个数组是无序的。要找到这个数组中最大元素的时间复杂度是多少?( )
A. O(n)
B. O(logn)
C. O(nlogn)
D. O(1)
无序数组找最大值
打擂台,\(O(n)\)
第3题 (2分)
在 C++ 中,以下哪个函数调用会造成栈溢出?( )
A. int foo() { return 0; }
B. int bar() { int x = 1; return x; }
C. void baz() { int a[1000]; baz(); }
D. void qux() { return ; }
明显 C 选项递归没有设置边界,并且每一层递归都开了一个无用的数组,会造成栈溢出
第4题 (2分)
在一场比赛中,有 10 名选手参加,前三名将获得金、银、铜牌。若不允许并列、且每名选手只能获得一枚奖牌,则不同的颁奖方式共有多少种?( )
A. 120
B. 720
C. 504
D. 1000
相当于从 10 名选手中选出三名,然后分配金银铜牌
选出顺序不同所表示的方案也是不同的,所以求的是排列数
\(A_{10}^3 = 720\)
第5题 (2分)
下面哪个数据结构最适合实现先进先出(FIFO)的功能?( )
A. 栈
B. 队列
C. 线性表
D. 二叉搜索树
先进先出为队列
第6题 (2分)
已知 f(1)=1,且对于 n >= 2 有 f(n) = f(n - 1) + f(⌊n/2⌋),则 f(4) 的值为( )
A. 4
B. 5
C. 6
D. 7
发现在 \(n \ge 2\) 时,递推式只跟下标比自己小的项有关系,因此顺序递推即可
\(f(1) = 1\)
\(f(2) = f(1) + f(1) = 2\)
\(f(3) = f(2) + f(1) = 3\)
\(f(4) = f(3) + f(2) = 5\)
第7题 (2分)
假设有一个包含 n 个顶点的无向图,且该图是欧拉图,以下关于该图的描述中哪一项不一定正确?
A. 所有顶点的度数均为偶数
B. 该图连通
C. 该图存在一个欧拉回路
D. 该图的边数是奇数
首先发现 AB 两个选项同时成立时,与 C 选项是等价的
欧拉图就是拥有欧拉回路的图
只拥有欧拉通路,不拥有欧拉回路的图叫做半欧拉图
所以 ABC 三个选项必选
至于 D 选项,造一个 4 个点 4 条边组成的环,明显可以排除
第8题 (2分)
对数组进行二分查找的过程中,以下哪个条件必须满足?( )
A. 数组必须是有序的
B. 数组必须是无序的
C. 数组长度必须是2的幂
D. 数组中的元素必须是整数
因为二分查找要根据中间项来确定答案在哪一边
所以二分查找的前提条件是数组必须有序
第9题 (2分)
考虑一个自然数 n 以及一个模数 m。你需要计算 n 的逆元(即 n 在模 m 意义下的乘法逆元)。下列哪种算法最为适合?( )
A. 使用暴力法依次尝试
B. 使用扩展欧几里得算法
C. 使用快速幂法
D. 使用线性筛法
如果题目中有说明 \(m\) 是质数,那么可以根据费马小定理推出 \(n^{-1} \equiv n^{m-2}(\bmod m)\),这时候是可以借助快速幂算法求解的
但题目并没有给定这个限制,因此费马小定理不能直接套用,只能借助扩展欧几里得求解线性同余方程来求逆元
扩展欧几里得还可以用于判断逆元是否存在,即 \(n, m\) 互质时才存在逆元
第10题 (2分)
在设计一个哈希表时,为了减少冲突,需要使用适当的哈希函数和冲突解决策略。已知某哈希表中有 n 个键值对,装的装载因子为 α (0 < α <= 1)。在使用开放地址法解决冲 突的过程中,最坏情况下查找一个元素的时间复杂度为( )。
A. O(1)
B. O(logn)
C. O(1/(1−α))
D. O(n)
开放地址法也可以当作线性探测法
装载因子表示表中元素个数与表长度的比值,在 \((0, 1]\) 之间说明一定存在元素,且每个元素一定能找到对应的存入位置
想查找一个元素,最坏情况下就是表被全部占满了,并且在存入时每个元素都被哈希到了同一个位置上,然后按顺序往后线性探测,一个个存进后面第一个空位上
然后在查找时,每次想找一个数字,就得像插入过程一样,从前往后一个一个找,所以最坏情况就是 \(O(n)\) 把整张哈希表找一遍才找到对应数字
第11题 (2分)
假设有一棵 h 层的完全二叉树,该树最多包含多少个结点?( )
A. 2^h-1
B. 2^(h+1)-1
C. 2^h
D. 2^(h+1)
\(h\) 层的完全二叉树包含的结点总数应当是 \(2^0 + 2^1 + 2^2 + \dots + 2^{h-1} = 2^h - 1\)
第12题 (2分)
设有一个 10 个顶点的完全图,每两个顶点之间都有一条边。有多少个长度为 4 的环?( )
A. 120
B. 210
C. 630
D. 5040
考虑先从 \(10\) 个点中选出 \(4\) 个点,求组合方案,即 \(C_{10}^4 = 210\)
对于任意四个点,需要考虑其圆排列总数,即 \((4-1)! = 6\),但因为是图论题,因此顺时针和逆时针当作相同的方案,因此排列数应该是 \(\dfrac{(4-1)!}2 = 3\)
或者直接列举,假设四个点是 ABCD,明显能组成的不同环排列有 ABCD, ACBD, ACDB 三种
最终答案即 \(210 \times 3 = 630\) 种
第13题 (2分)
对于一个整数 n ,定义 f(n) 为 n 的各位数字之和。问使 f(f(x)) = 10 的最小自然数 x 是多少?( )
A. 29
B. 199
C. 299
D. 399
满足 \(f(x) = 10\) 的 \(x\) 从小到大有 \(19, 28, 37, 46, 55, \dots\)
考虑 \(19\),再套一层,也就是找 \(f(x) = 19\) 的 \(x\),发现最小的 \(x\) 就是 \(199\)
(或者,反正这是一道选择题而不是填空题,直接从小往大一个个选项试一遍就行)
第14题 (2分)
设有一个长度为 n 的 01 字符串。其中有 k 个 1。每次操作可以交换相邻两个字符,在最坏情况下将这 k 个 1 移到字符串最右边所需要的交换次数是多少?( )
A. k
B. k*(k-1)/2
C. (n-k)*k
D. (2n-k-1)*k/2
相当于给 01 串进行一个排序,每次交换相邻两个字符,可以当作让逆序对数减少 1
所以交换次数就等于 01 串的逆序对数
为了让逆序对数最多,肯定是让 1 全在左,0 全在右
左边 \(k\) 个 1 和右边 \(n-k\) 个 0 组成的逆序对总数即 \(k \times (n-k)\)
第15题 (2分)
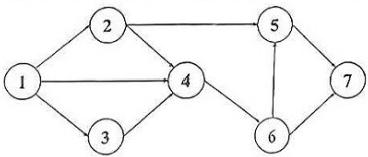
如图是一张包含 7 个顶点的有向图,如果要删除其中一些边,使得从节点 1 到节点 7 没有可行路径,且删除的边数最少,请问总共有多少种可行的删除边的集合?( )
A. 1
B. 2
C. 3
D. 4
明显最少删除的边数为 2
这题可以假设先删一条边,然后画出剩下的图中的强连通分量,然后考虑方案数,会更方便一些
删法分别为:
- \(5-7, 6-7\)
- \(4-6, 5-7\)
- \(2-5, 4-6\)
- \(1-2, 4-6\)
第16题 (11.5 分)
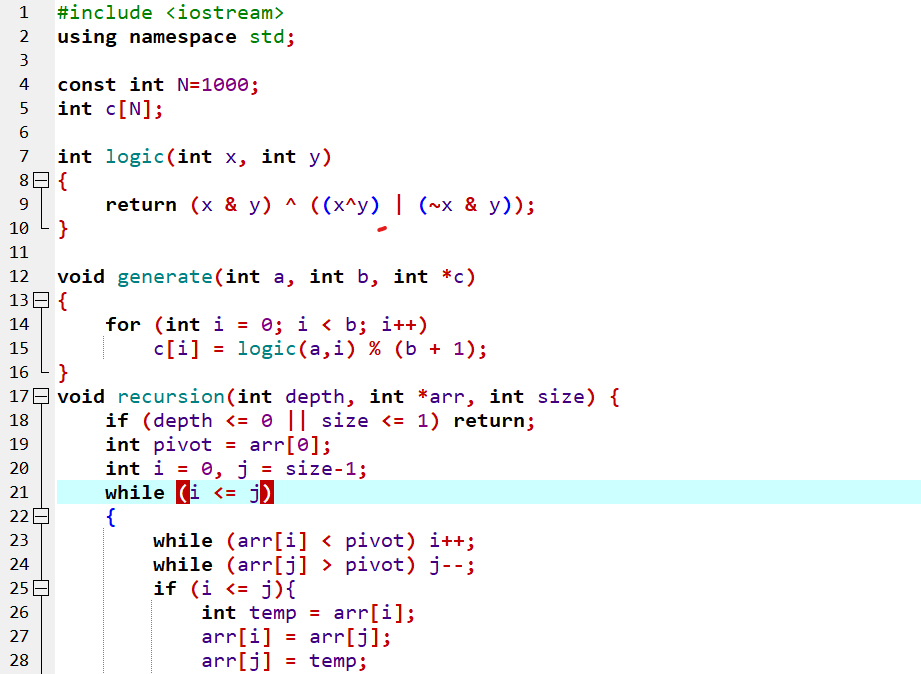

首先发现
logic函数有点麻烦,但内部全都是位运算,所以不妨针对每一位,先画出真值表|
x|y|x&y|x^y|~x&y|(x^y)|(~x&y)|logic|
| ---- | ---- | ----- | ----- | ------ | -------------- | ------- |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 1 | 0 | 1 | 1 | 1 | 1 |
| 1 | 0 | 0 | 1 | 0 | 1 | 1 |
| 1 | 1 | 1 | 0 | 0 | 0 | 1 |明显
logic函数是按位或运算然后考虑代码,
generate就是生成 \(b\) 个数字放在 \(c\) 数组的下标 \(0\sim b-1\) 的位置上,其中c[i] = (a | i) % (b + 1)
recursion函数就是快排模板,但是加了个深度限制depth,也就是说这个快排如果到达指定深度,即使没排完也会结束
第16 - 1题(1.5 分)
当 1000 ≥ d ≥ b 时,输出的序列是有序的。
A.对
B.错
当 \(b \le d \le 1000\) 时,因为数字数量 \(b\) 比限制深度 \(d\) 要小,并且快排在最坏情况下其实也就是有多少数字就递归多少层(\(O(n^2)\) 出现的情况)
因此这个深度限制就跟没有一样
不论什么情况,快排都一定会执行结束,到最后所有数字都会有序
第16 - 2题(1.5 分)
当输入"5 5 1" 时,输出为 "1 1 5 5 5"。
A.对
B.错
首先根据数据生成五个数字,如果只看按位或,得到的数是
5 5 7 7 5但
generate函数中位运算完成后会对 \(b+1\) 取模,因此得到的数是5 5 1 1 5因为 \(d=1\),因此快排只执行一次,模拟一遍快排
5 5 1 1 5 i j执行两个 while5 5 1 1 5 i ji <= j 成立,交换,然后 i++, j--5 5 1 1 5 i j执行两个 while5 5 1 1 5 i ji <= j 成立,交换,然后 i++, j--5 1 1 5 5ij执行两个 while5 1 1 5 5j ii <= j 不成立,结束发现最终答案是
5 1 1 5 5
第16 - 3题(1.5 分)
假设数组 c 长度无限制,该程序所实现的算法的时间复杂度是 O(b) 的。
A.对
B.错
时间复杂度主要还是取决于快排,但注意本题还有一个深度限制
如果深度限制 \(d\) 较小,那么时间复杂度应该是 \(O(b \times d)\)
如果深度限制 \(d\) 较大,最好情况下时间复杂度是 \(O(b \log b)\),最坏情况下就是 \(O(b^2)\)
第16 - 4题(3 分)
函数 int logic(int x, int y) 的功能是( )。
A.按位与
B.按位或
C.按位异或
D.以上都不是
根据上面的分析,
logic函数是按位或
第16 - 5题(4 分)
当输入为 "10 100 100" 时,输出的第 100 个数是( )。
A.91
B.94
C.95
D.98
首先考虑到 \(96 = 64 + 32 = 2^6 + 2^5\)
也就是说 \(96_{10} = 1100000_2\)
那么 \(95_{10} = 1011111_2\)
又因为 \(10_{10} = 1010_2\)
发现 \(95\) 的后五位都是 \(1\),所以 \(95\) 以下的所有数字都按位或上 \(10\) 之后得到的数字大小都不会超过 \(95\)
而 \(96, 97, 98, 99\) 这四个整数,按位或 \(10\) 之后一定都超过了 \(100\),因此对 \(b+1 = 101\) 取模后的结果就变小了
所以生成的数字最大值就是 \(95\)
而本题给定的数字中 \(b = d\),所以深度限制可以忽略,快排一定能够把所有数字都排完,因此第 \(100\) 个数就是生成过程中出现的最大的数字,即 \(95\)
第17题 (14 分)
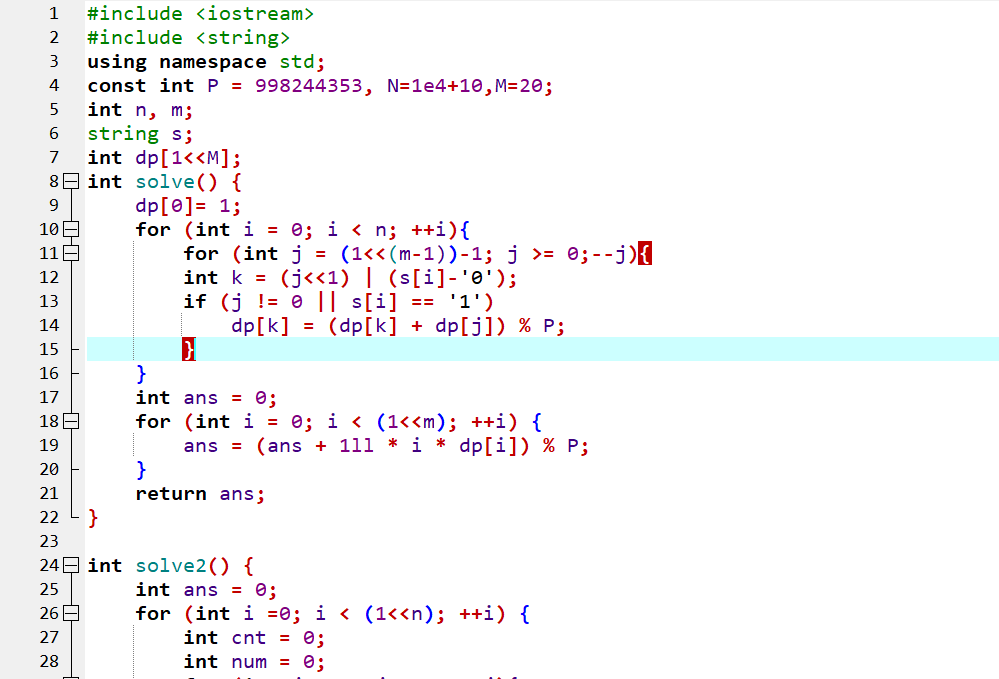
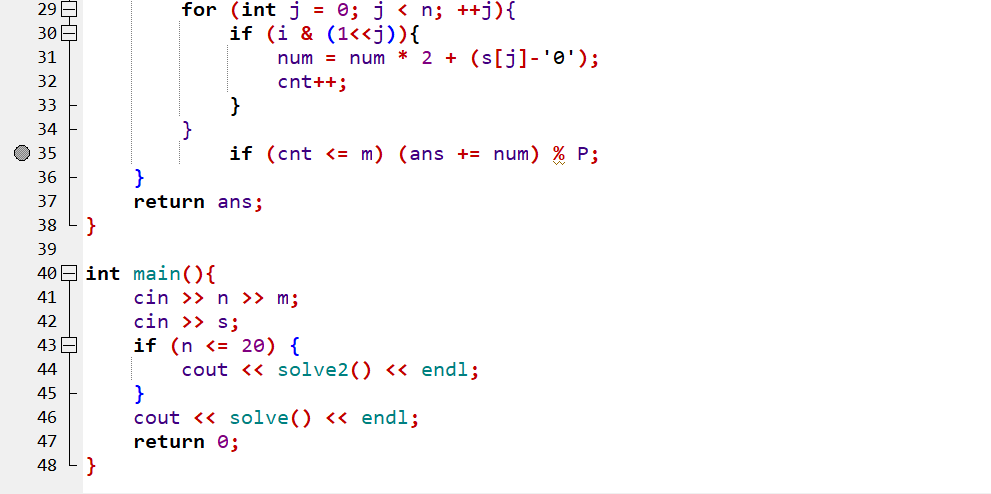
假设输入的 s 是包含 n 个字符的 01 串,完成下面的判断题和单选题:
本题先从
solve2函数入手,观察到 \(i\) 循环从 \(0\) 到 \(2^n-1\),也就是把所有位数为 \(n\) 的二进制都枚举了一遍,然后 \(j\) 循环从 \(0\) 到 \(n\),i & (1 << j)即判断 \(i\) 的 \(2^j\) 这一位上是否为 \(1\),如果是 \(1\) 就执行num = num * 2 + (s[j] - '0')并且cnt++先单独看
num = num * 2 + (s[j] - '0')这一句,相当于把 \(i\) 的二进制上为 \(1\) 的那些位置的字符单独取出,然后二进制数位拼接成一个新数字,再结合前面 \(i\) 循环的枚举,不难看出这里相当于是把字符串的每个子序列都单独提了出来,当作一个二进制数,然后转为十进制的num变量
cnt++则相当于是在统计当前取出的这个子序列的长度当
cnt <= m时,会把num加到ans里所以不难发现,
solve2就是在把字符串中所有长度不超过 \(m\) 的子序列全部取出来,当作二进制数,转为十进制后再全部相加
然后看
solve函数,有了上面的推导,我们不妨猜想这个函数和前面那个函数所求的内容应该有所关联看 \(14\) 行的
k = (j << 1) | (s[i] - '0'),因为字符串是一个 01 串,所以这句话不妨转化为k = j * 2 + (s[i] - '0'),发现也就是在 \(j\) 的基础上,把s[i]代表的数字拼到 \(j\) 的二进制后面然后在
j != 0 || s[i] == '1'时,执行了dp[k] += dp[j],也就是避免了从 \(0\) 转移到 \(0\) 的情况,不难看出dp[k]应该是在计数,统计的是选出的子序列二进制为 \(k\) 的方案总数。因此在 \(j\) 的方案后面拼上一个s[i]变成 \(k\) 这个数字后,\(k\) 的总方案数就会加上 \(j\) 原本的方案数然后 \(21\) 行,
i * dp[i]就是在把值和数量乘起来相加,相当于就是在求所有二进制数为 \(i\) 的数字总和,这和solve2函数是相同的唯一的不同点在于,该函数不能从 \(0\) 转移到 \(0\),因此选出的子序列第一个数必须为 \(1\)
综上,
solve函数就是在把字符串中所有长度不超过 \(m\) **且开头为 \(1\) **的子序列全部取出来,当作二进制数,转为十进制后再全部相加
第17 - 1题(1.5 分)
假设数组 dp 长度无限制,函数 solve() 所实现的算法的时间复杂度是 O(n*2^m)。
A.对
B.错
明显根据循环可以得出时间复杂度为 \(O(n\times 2^m)\)
第17 - 2题(1.5 分)
输入 "11 2 10000000001" 时,程序输出两个数 32 和 23。
A.对
B.错
相当于在找所有长度不超过 \(2\) 的子序列当作二进制数后的总和
当长度为 \(1\),对答案有贡献的子序列只有
1,出现了 \(2\) 次当长度为 \(2\),对答案有贡献的子序列有
01/10/11,出现次数分别为 \(9, 9, 1\) 次对于
solve2函数,因为该函数允许第一个选出的数为 \(0\),因此答案为 \(1_2 \times 2 + 01_2 \times 9 + 10_2 \times 9 + 11_2 \times 1 = 2 + 9 + 18 + 3 = 32\)对于
solve1函数,因为该函数不允许第一个选出的数为 \(0\),因此排除01的情况,答案为 \(1_2 \times 2 + 10_2 \times 9 + 11_2 \times 1 = 23\)
第17 - 3题(2 分)
在 n≤10 时,solve() 的返回值始终小于 4^10。
A.对
B.错
不论对于哪个函数,在字符串全为 \(1\),且 \(n = m\) 时一定可以取得最大值
因此假设 \(n = m = 10, s = 1111111111\)
答案为 \(C_{10}^1 \times 1 + C_{10}^2 \times 3 + C_{10}^3 \times 7 + \dots + C_{10}^{10} \times 1023 = 58025 \lt 4^{10}\)
第17 - 4题(3 分)
当 n=10 且 m=10 时,有多少种输入使得两行的结果完全一致?
A.1024
B.11
C.10
D.0
如果两个函数结果一致,只能说明不存在任何以 \(0\) 开头的子序列
也就是说所有 \(0\) 都必须出现在 \(1\) 之后
在 \(n = m = 10\) 时,方案只有 \(11\) 种:
00000000001000000000110000000011100000001111000000- \(\dots\)
1111111111
第17 - 5题(3 分)
当 n <= 6 时,solve() 的最大可能返回值为( )。
A.65
B.211
C.665
D.2059
同上面最后一道判断,最大可能返回值即字符串全 \(1\) 的情况
\(C_6^1 \times 1_2 + C_6^2 \times 11_2 + C_6^3 \times 111_2 + \dots + C_6^6 \times 111111_2 = 665\)
第17 - 6题(3 分)
若 n = 8,m = 8,solve 和 solve2 的返回值的最大可能的差值为( )。
A.1477
B.1995
C.2059
D.2187
两个函数的差值就等于以 \(0\) 开头的子序列对答案的贡献
在 \(n=m=8\) 时,为了能让子序列当作二进制时的权值尽可能大,因此此时字符串方案应该是
01111111考虑不同长度子序列的数量及其贡献:
- 长度为 \(2\) 时,选 \(1\) 个 \(1\),答案为 \(C_7^1 \times 01_2\)
- 长度为 \(3\) 时,选 \(2\) 个 \(1\),答案为 \(C_7^2 \times 011_2\)
- 长度为 \(4\) 时,选 \(3\) 个 \(1\),答案为 \(C_7^3 \times 0111_2\)
- \(\dots\)
- 长度为 \(8\) 时,选 \(7\) 个 \(1\),答案为 \(C_7^7 \times 01111111_2\)
最终答案即总和,求解可得 \(2059\)
第18题 (14.5 分)



这是一道树上双哈希 + 埃氏筛的题目
首先关注
init函数
p数组就是埃氏筛,表示每个位置的数字是否是素数p1[i]表示 \(B1^i \bmod P1\)p2[i]表示 \(B2^i \bmod P2\)然后观察
H这个结构体的内部,其中有三个成员变量h1, h2, l初始化函数中,
l = 1恒成立,h1和h2会根据传入的b不同而出现差值为 \(1\) 的区别在加法运算符的重载函数中,发现加法得到的
l为两个结构体的l相加,而h1和h2两成员变量的变化过程相似对于
h1,相当于将加法左侧结构体的h1乘上 \(B1^{\text{右侧结构体的 l}}\) 之后,再加上右侧结构体的h1明显这里
B1表示的就是哈希的底数,l表示哈希多项式的长度(即数字个数),加法操作相当于是把两个哈希多项式合并在了一起,因此左侧的多项式每一项都需要乘上 底数 的 右侧多项式项数 次方,再把右侧多项式加上因此
h1和h2两个数字只是在不同哈希底数和模数下得到的两个哈希值,这里做的是双哈希然后等号的运算符重载函数只是为了判断两个哈希值是否相等,小于号则定义了哈希结构体的排序方法
最后回到
solve函数,这个for循环是倒着做的,根据h[i] = H(p[i])可以发现,初始时h[i]只会出现两种情况:
- 一种是 \(i\) 是质数时,
h1 = K1+1 = 1,h2 = K2+1 = 14,l = 1- 一种是 \(i\) 不是质数时,
h1 = K1 = 0,h2 = K2 = 13,l = 1然后观察第 59 和 61 行的转移,发现
h[i]的变化只会跟h[2 * i]和h[2 * i + 1]这两个位置有关系通过 \(i, 2i, 2i+1\) 三个数字的关系,不难想到数组模拟二叉树时的编号顺序,\(2i\) 和 \(2i+1\) 分别是 \(i\) 的左右儿子
因此第 \(58\) 行
2 * i + 1 <= n就是表示 \(i\) 有左右儿子,而第 \(60\) 行2 * i <= n表示 \(i\) 只有左儿子然后发现在左右儿子都存在时,
h[i] = h[2*i] + h[i] + h[2*i+1],先左儿子,再根结点,再右儿子;当只有左儿子时,h[i] = h[2*i] + h[i],即先左儿子,再根节点所以哈希过程就是把当前子树的中序遍历序列给哈希掉
后面
h[1].h1就是根结点的哈希值最后的排序+去重,输出去重后不同哈希结构体的数量,其实就是在求二叉树上存在多少棵不同的子树
第18 - 1题(1.5 分)
假设程序运行前能自动将 maxn 改为 n+1,所实现的算法的时间复杂度是 O(n log n)。
A.对
B.错
埃氏筛的时间复杂度为 \(O(n\log\log n)\),排序函数的时间复杂度是 \(O(n\log n)\),排序函数的时间复杂度级别更高,所以整体时间复杂度为 \(O(n\log n)\)
第18 - 2题(1.5 分)
时间开销的瓶颈是 init() 函数。
A.对
B.错
同上一题,时间复杂度取决于排序函数,所以瓶颈在
solve函数
第18 - 3题(1.5 分)
若修改常数 B1 或 K1 的值,该程序可能会输出不同的结果。
A.对
B.错
修改常数 B1 或 K1,相当于把第一个哈希值的哈希过程给修改了
第 64 行输出的是整棵树的第一个哈希值,因此这个值很可能会发生变化
第18 - 4题(3 分)
在 solve() 函数中,h[] 的合并顺序可以看作是:
A.二叉树的 BFS 序
B.二叉树的先序遍历
C.二叉树的中序遍历
D.二叉树的后序遍历
根据上面的分析,
h的合并可以看作是在合并子树的中序遍历序列的哈希多项式
第18 - 5题(3 分)
输入 "10",输出的第一行是( )?
A.83
B.424
C.54
D.110101000
问的是输出的第一行,因此需要求出根结点
h1的值但根据上面的分析,根结点
h1的哈希值其实就是整棵树每个结点h1的中序遍历序列的哈希值这个哈希值乘的底数是 \(B1 = 2\),一开始每个结点
h1的值取决于该结点所在编号的数字是否是素数,如果是则为 \(1\),不是则为 \(0\)所以
h1最终的结果可以简单看作是整棵树中序遍历序列当作二进制数,转为十进制之后的结果我们可以先把 \(n=10\) 时的这棵树画出来,其中黑色数字表示编号,蓝色数字表示
h1的初始值
这棵树的中序遍历为 \(8,4,9,2,10,5,1,6,3,7\),对应的值分别是 \(0,0,0,1,0,1,0,0,1,1\)
将 \(0001010011\) 转为二进制,得 \(83\)
第18 - 6题(4 分)
(4分)输出 "16",输出的第二行是( )?
A.7
B.9
C.10
D.12
第二行表示的是有多少个不同的哈希结构体,换句话说也就是这棵树上有多少棵本质不同的子树
将 \(n=16\) 的树画出,蓝色数字表示
h1的初始值
接下来以每个结点作为根结点,看一遍有多少棵本质不同的子树即可
下面打勾的就是本质不同的子树的根结点方案之一,总共 \(10\) 种
第19题 (15 分)
(序列合并)有两个长度为 N 的单调不降序列 A 和 B,序列的每个元素都是小于 10^9 的非负整数。在 A 和 B 中各取一个数相加可以得到 N^2 个和,求其中第 K 小的和。上述参数满足 N <= 10^5 和 1 <= K <= N^2。


首先可以考虑完成
upper_bound函数,这其实是一个 STL 函数,但这里让你手动实现其内部的二分。upper_bound(l, r, x)函数的含义是在一段连续地址 \([l, r)\) 中查找出第一个 \(\gt x\) 的位置。但如果说你比较担心这道题的upper_bound和我们平时接触的二分函数含义不一样,可以先看下面的分析:
根据题意,要找到排名为 \(k\) 的和,因此考虑二分答案
mid,然后找出有多少个和是不超过mid的,根据得到的数量来判断答案要往大了找还是往小了找先看第五个空,这里的条件一旦满足就会执行
l = mid + 1,说明答案一定大于此时的mid,所以可以判断是因为<= mid的和的数量严格小于k,即get_rank(mid) < k然后就可以推导出
get_rank(sum)这个函数就是在求<= sum的和的数量。只需要对于每个a[i],求出有多少个b[j]满足a[i] + b[j] <= sum,移项得b[j] <= sum - a[i],因此只需要在b数组里找不超过sum - a[i]的数字有多少个就可以,所以第 26 行代码应该要通过upper_bound函数找到b数组中> sum - a[i]的第一个地址,然后减去b的首地址,才能够获得想要的答案所以从这里可以推出
upper_bound(l, r, x)是在一段连续地址 \([l, r)\) 中二分查找出第一个 \(\gt x\) 的位置,注意左闭右开
第19 - 1题(3 分)
①处应填
A.an-a
B.an-a-1
C.ai
D.ai+1
这里是 upper_bound 函数的右边界,因为要进行二分,所以
r一开始应该表示的是这段左闭右开的地址内共有多少个数字,即尾地址an减首地址a
第19 - 2题(3 分)
②处应填
A.a[mid] > ai
B.a[mid] >= ai
C.a[mid] < ai
D.a[mid] <= ai
不妨先看 else,想想什么时候会让
l = mid + 1因为现在要找第一个
> ai的数字,所以只有当当前位置的数字a[mid] <= ai时,才能断定答案一定在mid右侧所以反过来,if 里就应该填
a[mid] > ai
第19 - 3题(3 分)
③处应填
A.a+l
B.a+l+1
C.a+l-1
D.an-l
最后要返回一个地址,所以应该是从首地址
a开始往后移动l/r个位置的地址其实这里写法有很多,像是
a + l、a + r、&a[l]、&a[r]都可以
第19 - 4题(3 分)
④处应填
A.a[n-1]+b[n-1]
B.a[n]+b[n]
C.2 * maxn
D.maxn
solve函数二分的是最终答案,如果 \(k = n^2\),那么答案就是最大和,应该是两数组最大值之和,即a[n-1] + b[n-1]
第19 - 5题(3 分)
⑤处应填
A.get_rank(mid) < k
B.get_rank(mid) <= k
C.get_rank(mid) > k
D.get_rank(mid) >= k
详见上面的分析
第20 题 (15 分)
(次短路)
已知一个有 n 个点 m 条边的有向图 G,并且给定图中的两个点 s 和 t,求次短路(长度严格大于最短路的最短路径)。如果不存在,输出一行 "-1"。如果存在,输出两行,第一行表示次短路的长度,第二行表示次短路的一个方案。


(一道模板次短路算法题,但写法略微抽象了些,但也还好)
首先明确什么是次短路:除了最短路以外的最短路(除最优解以外的最优解就是次优解)
所以次短路算法的总体逻辑就是在最短路算法的基础上分类讨论
假设现在正在进行最短路算法的松弛,假设 \(a\) 到 \(b\) 有一条长度为 \(w\) 的边,现在要根据 \(a\) 的答案来更新 \(b\) 的答案:
- 如果
dis[b] > dis[a] + c,说明现在能够借助 \(a\) 来松弛 \(b\) 的最短路答案,目前走到 \(b\) 点的最优解变成了从 \(a\) 点经过 \(a \rightarrow b\) 这条边过来,所以在这一步松弛之前的dis[b]有可能作为 \(b\) 点的次优解- 如果
dis[b] < dis[a] + c,说明现在无法借助 \(a\) 来松弛 \(b\) 的最短路答案,但此时从 \(a\) 点经过 \(a \rightarrow b\) 这条边过来的方案也是有可能作为 \(b\) 点的次优解的- 如果
dis[b] == dis[a] + c,题干中有提到次短路是“长度严格大于最短路的最短路径”,所以相等的情况不用管整个算法就是在这个分类讨论的基础上执行的,在所有可能的次优解中找一个长度最小的方案,就是次短路
接下来看代码本身
add函数很明显是链式前向星加一条 \(a\rightarrow b\) 的长度为 \(c\) 的边
out函数是找到次短路之后输出这条路径的递归函数然后观察
main函数,所有点的下标都 \(-1\) 后变成 \(0 \sim n-1\) 的范围了,然后进入solve函数,一个普通的 Dijkstra 堆优化写法,然后只要队列不为空就不断松弛出去,重点在于第 37、38 行和第 46 到 51 行这一段先看第 37、38 行,
dis2和pre2两个指针分别指向了dis + n和pre + n的位置,这也是为什么dis和pre数组要开两倍空间,相当于前面 \(0 \sim n-1\) 的下标给自己用,而后面 \(n \sim 2n-1\) 的下标交给了dis2和pre2两个指针用。所以可以猜测dis2和pre2就是用来记录次短路的答案和路径的就相当于这里建立了一张分层图,\(0 \sim n-1\) 在正常跑最短路,而 \(n \sim 2n-1\) 则是记录上一层每个对应的点的次短路,同一个点在两层间的编号差值为 \(n\)
然后看 47 行的参数传递格式,可以知道
upd(a, b, d, q)相当于是把松弛的过程写成了一个函数,在看 \(a\) 到 \(b\) 这两个点的最短路能否更新为 \(d\),通过函数返回值来判断是否成功松弛如果成功松弛,根据上面的分类讨论,原本到 \(b\) 点的答案就成了次优解,所以第一个空这里
b < n就是在判断现在 \(b\) 这个点是否还在求最短路的这一层,如果是,则可以更新 \(b\) 的次短路;如果不是,说明这一次松弛本来就是在更新 \(b\) 的次短路,就不用管了而如果没有成功松弛,根据上面的分类讨论,当前从 \(a\) 出发的这种方案可能成为次优解,所以第四个空就是在这种情况下更新 \(b\) 的次短路的
最后如果说存在次短路,则从第二层的终点
n+t开始往回找出整条路径,递归输出即可
第20 - 1题(3 分)
①处应填
A.upd(pre[b], n + b, dis[b], q)
B.upd(a, n + b, d, q)
C.upd(pre[b], b, dis[b], q)
D.upd(a, b, d, q)
根据上面的分析,这里是在 \(b\) 进行松弛之前,把它原本的最短路当作次短路来更新答案的
原本到 \(b\) 的最短路的前一个点可以通过
pre[b]得到,变成次短路后就应该成为第二层的点,即 \(n+b\),此时次短路长度为dis[b]
第20 - 2题(3 分)
②处应填
A.make_pair(-d, b)
B.make_pair(d, b)
C.make_pair(b, d)
D.make_pair(-b, d)
这里就是考 Dijkstra 堆优化情况下,优先队列要怎么放元素
pair 会默认根据 first 关键词从小到大排,first 相同时按照 second 从小到大排
但因为代码里的优先队列是用的大根堆,所以会按 first 从大到小排先
而 Dijkstra 堆优化更多的是用小根堆来求出距离起点最近的未访问过的点进行松弛
所以为了能在大根堆中实现小根堆的功能,这里应该把 first 关键词取反,并且 first 关键词表示当前点与起点之间的距离,second 关键词表示当前点的编号
所以这里的 make_pair 的参数为 \(-d\) 和 \(b\)
第20 - 3题(3 分)
③处应填
A.0xff
B.0x1f
C.0x3f
D.0x7f
这里是在初始化
dis数组,即记录最短路的答案数组,一般是要初始化成一个无穷大的数字的因为
int类型最大只能存到 \(2^{31} - 1\),所以memset函数不能直接使用0xff,所以排除 A因为
dis数组在松弛过程中会和某条边的长度相加求和,所以如果直接用0x7f有概率超出范围,一般也不用,排除 D正常情况下都是选
0x3f最为保险,但这题请注意第 74 行(上面截图里是第 72 行)以及第 7 行代码中的inf的定义最后在终点次短路为
inf时,直接判断不存在,因此我们memset应该这个无穷大的数字设置为与inf相同\(522133279_{10} = 1f1f1f1f_{16}\)
所以这题只能选 B
第20 - 4题(3 分)
④处应填
A.upd(a, n + b, dis[a] + c, q)
B.upd(n + a, n + b, dis2[a] + c, q)
C.upd(n + a, b, dis2[a] + c, q)
D.upd(a, b, dis[a] + c, q)
根据上面的分析,这里是在松弛失败之后,把当前从 \(a\) 到 \(b\) 且经过长度为 \(c\) 的边的这种方案当作次优解,来更新次短路的
所以这里很明显就是从 \(a\) 出发,到 \(b\) 点对应的次优解点 \(n+b\),尝试更新答案为
dis[a] + c
第20 - 5题(3 分)
⑤处应填
A.pre2[a%n]
B.pre[a%n]
C.pre2[a]
D.pre[a%n]+1
第 58 行的 else 表示的是 \(a\) 点现在是次短路这一层中的点,所以我们应该从
pre2数组里把 \(a\) 点的上一个点找出来明显现在 \(a \ge n\) 是成立的,所以不能直接写
pre2[a],不然会越界,只能把 \(a\) 先转回原本的编号,可以用a % n也可以直接a - n所以这个空答案有多种,可以是
pre2[a % n],可以是pre2[a - n],也可以直接是pre[a]