Local模式
- 不需要其他任何节点资源就可以在本地执行Spark代码的环境,一般用于教学,调试,演示等
- 在IDEA中运行代码的环境称之为开发环境
1、解压缩文件
- 将spark-3.0.0-bin-hadoop3.2.tgz文件上传到Linux并解压缩,放置在指定位置,路径中不要包含中文或空格
- 压缩文件放在'/opt/software/',解压缩文件放在'/opt/module/'
[user@hadoop102 software]$ tar -zxvf spark-3.0.0-bin-hadoop3.2.tgz -C /opt/module/
2、启动Local环境
(1)进入解压缩后的路径,执行如下指令
[user@hadoop102 module]$ cd spark-3.0.0-bin-hadoop3.2/
[user@hadoop102 spark-3.0.0-bin-hadoop3.2]$ bin/spark-shell
(2)启动成功后,可以输入网址进行Web UI监控页面访问
http://192.168.10.102:4040/jobs/
3、命令行工具
- 在/opt/module/hadoop-3.1.3/路径下有一个SEVENTEEN.txt文件,对该文件进行字符计数
scala> sc.textFile("/opt/module/hadoop-3.1.3/SEVENTEEN.txt").flatMap(line=>line.split(" ")).map(word=>(word,1)).reduceByKey(_+_).collect
res4: Array[(String, Int)] = Array((are,1), (we,1), (hello,1), (very,1), (you,2), (name,1), (say,1), (meet,1), (to,1), (nice,2), (seventeen,2), (the,1))
4、退出本地模式
- 按键Ctrl+C或输入Scala指令
:quit
5、提交应用
[user@hadoop102 spark-3.0.0-bin-hadoop3.2]$ bin/spark-submit \
> --class org.apache.spark.examples.SparkPi \
> --master local[2] \
> ./examples/jars/spark-examples_2.12-3.0.0.jar \
> 10
- --class表示要执行程序的主类,此处可以更换为自己写的应用程序
- --master local[2]部署模式,默认为本地模式,数字表示分配的虚拟CPU核数量
- spark-examples_2.12-3.0.0.jar运行的应用类所在的jar包,实际使用时,可以设定为自己打的jar包
- 数字10表示程序的入口参数,用于设定当前应用的任务数量
Standalone模式
- 只使用Spark自身节点运行的集群模式,也就是所谓的独立部署(Standalone)模式
- Spark的Standalone模式体现了经典的master-slave模式
- 集群规划
| 虚拟机102 | 虚拟机103 | 虚拟机104 | |
|---|---|---|---|
| Spark | Worker Master | Worker | Worker |
1、修改文件配置
(1)进入解压后路径的conf目录,修改slaves.template文件名为slaves
[user@hadoop102 conf]$ mv slaves.template slaves
(2)修改slaves文件,添加work节点
[user@hadoop102 conf]$ vim slaves
hadoop102
hadoop103
hadoop104
(3)修改spark-env.sh.template文件名为spark-env.sh
[user@hadoop102 conf]$ mv spark-env.sh.template spark-env.sh
(4)修改spark-env.sh文件,添加JAVA_HOME环境变量和集群对应的master节点
export JAVA_HOME=/opt/module/jdk1.8.0_212
SPARK_MASTER_HOST=hadoop102
SPARK_MASTER_PORT=7077
(5)分发spark-3.0.0-bin-hadoop3.2目录
xsync spark-3.0.0-bin-hadoop3.2/
2、启动集群
(1)执行脚本命令
[user@hadoop102 spark-3.0.0-bin-hadoop3.2]$ sbin/start-all.sh
(2)查看三台服务器运行进程
[user@hadoop102 spark-3.0.0-bin-hadoop3.2]$ jpsall
=============== hadoop102 ===============
6449 Jps
6291 Master
6377 Worker
=============== hadoop103 ===============
4679 Worker
4733 Jps
=============== hadoop104 ===============
7725 Worker
7790 Jps
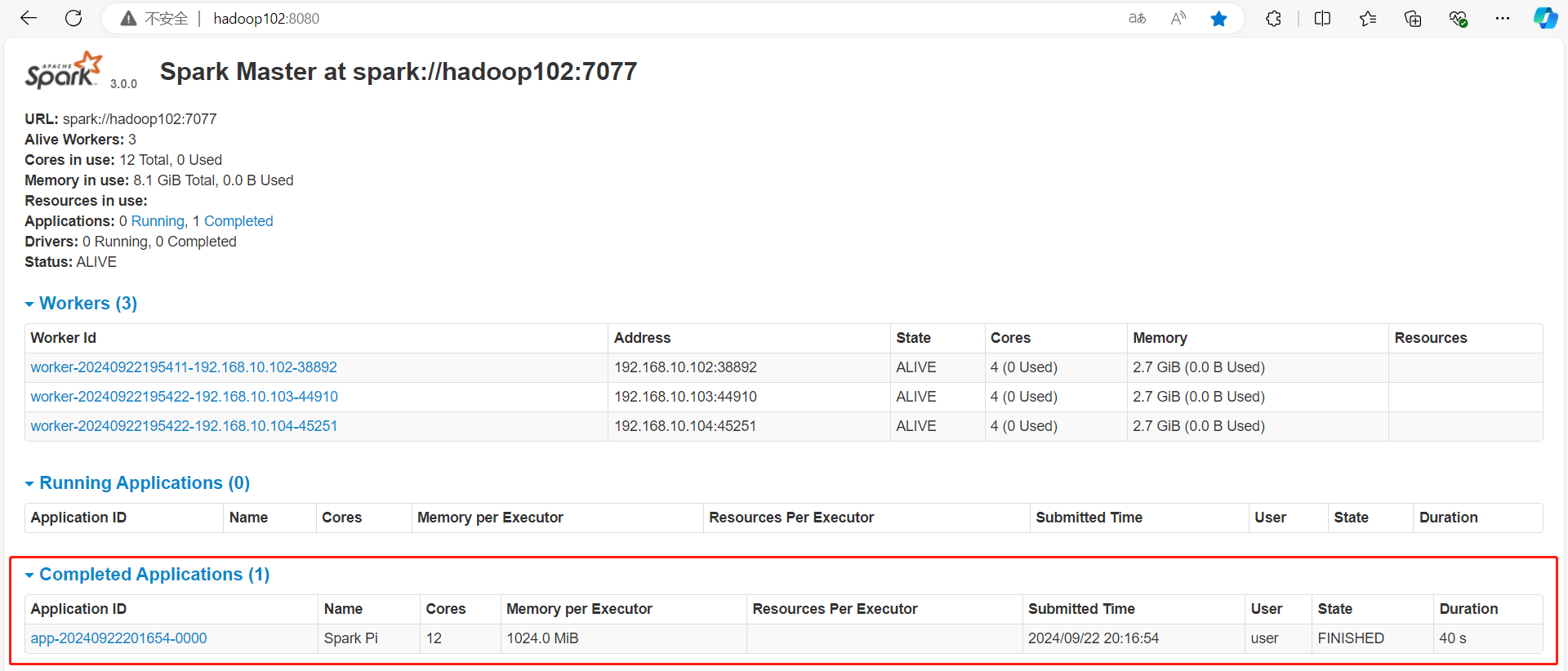
(3)查看Master资源监控Web UI界面
http://hadoop102:8080/
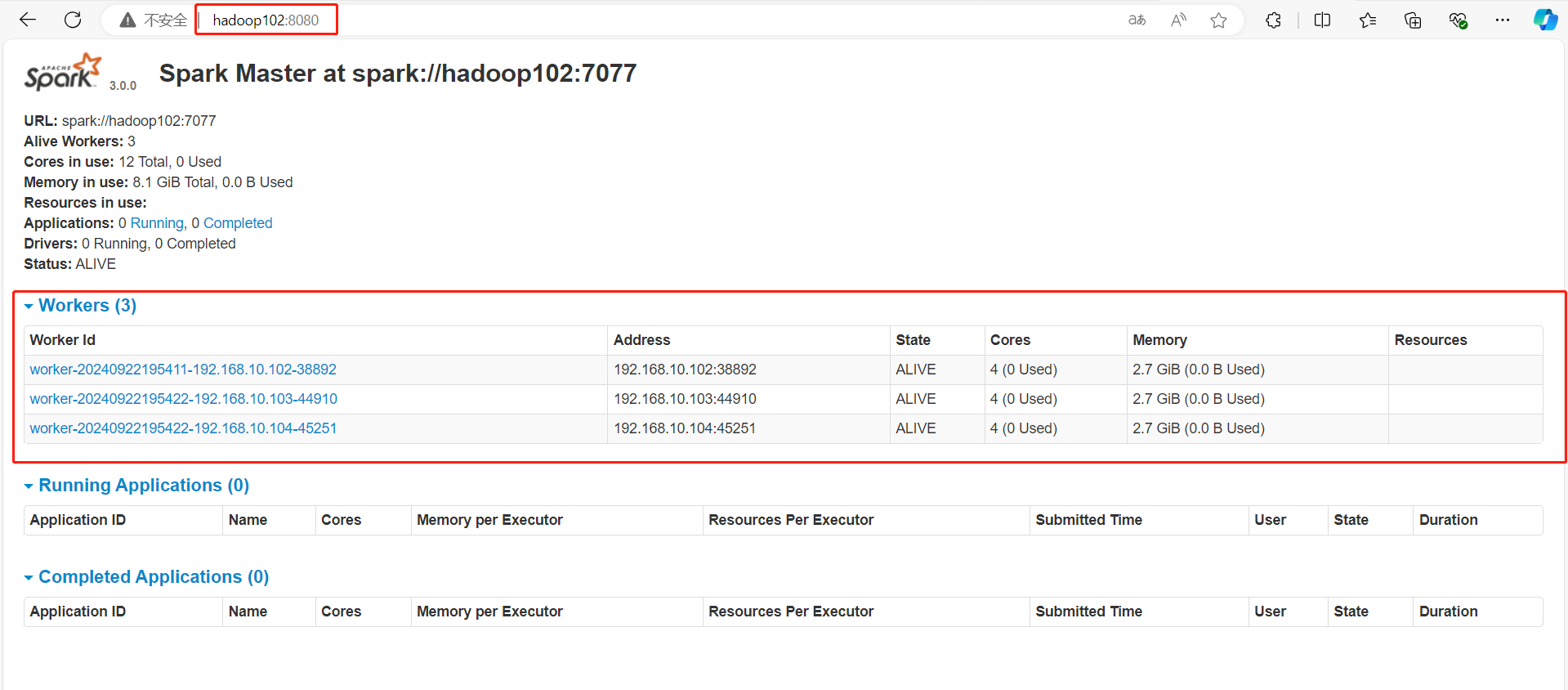
3、提交应用
[user@hadoop102 spark-3.0.0-bin-hadoop3.2]$ bin/spark-submit \
> --class org.apache.spark.examples.SparkPi \
> --master spark://hadoop102:7077 \
> ./examples/jars/spark-examples_2.12-3.0.0.jar \
> 10
- --class表示要执行程序的主类
- --master spark://hadoop102:7077独立部署模式,连接到Spark集群
- spark-examples_2.12-3.0.0.jar运行的应用类所在的jar包
- 数字10表示程序的入口参数,用于设定当前应用的任务数量
- Web界面