在现代电信行业中,订单中心作为核心业务系统之一,承担着处理客户订单、管理订单状态、与各个业务系统进行交互等重要职责。其订单中心的高效运作直接关系到客户体验和业务连续性。为了满足不断增长的业务需求和日益复杂的运营环境,运营商需要自身的订单中心架构具备高可用性及强大的容灾能力。
双活架构作为常见的高可用方案,允许两个数据中心同时提供服务并实现数据的实时同步。当一个数据中心发生故障时,另一个数据中心能够无缝接管其工作,确保业务不中断。这种架构不仅提高了系统的稳定性和可靠性,还能大幅减少灾难恢复的时间和成本。
本文将着重分享某头部运营商订单中心在实现双活架构过程中的最佳实践,提供详细的技术细节和实际案例。通过介绍项目实施过程中的技术细节,提供类似场景需求的方案参考。
运营商订单中心的需求分析
需求背景
随着信息技术的发展以及各行各业数字化转型的加速,近些年来,三大运营商纷纷布局“能力中台”,以提升运营效率和快速响应业务需求。公众中台作为该运营商面向公众客户市场的核心赋能平台,通过横向整合业务、市场、运营和交付等能力,全面提升公众业务运营的效率。其目标是加速资源供给与产品创新,提供卓越的用户线上线下一致体验,实现营销网与交付网的贯通,构建线上线下一体化的客户价值运营体系。架构层面,打破传统的烟囱式,采用“平台+应用”的云化架构模式,实现能力复用、流程拉通和数据共享,全面赋能前端应用。
其中,MongoDB 数据库作为核心组件,广泛应用于该公众中台的多个业务模块,尤其在订单中心所覆盖的订单数据查询、客服订单查询和审单列表查询等场景中发挥了关键作用。为提高系统的高可用性,公众中台需要构建异地双活架构,确保 MongoDB 数据库具备异地双集群部署、双集群双写和数据双向同步能力。
数据双向同步的挑战
在原有设计下,该订单中心的客户数据存在于两个 MongoDB 集群之间,需要实现数据的双向同步。然而,这种双向同步设计面临以下挑战:
- 数据循环同步问题:数据的双向同步无法避免数据循环同步的问题,这会导致一条数据变更被无限次放大,最终导致数据的持续不稳定,并耗尽系统资源。
- 数据一致性问题:在双向同步过程中,由于更新延迟等原因,可能会导致两个数据中心的数据不一致,进而影响业务的正常运作。
- 系统性能问题:在高并发的业务场景下,数据的双向同步可能会增加系统的负载,影响系统的整体性能。
为此,订单中心的双活架构需要具备以下技术特性:
- 高可用性:保证两个数据中心在任何一个出现故障时,另一个数据中心能够无缝接管,确保业务不中断。
- 实时数据同步:实现数据在两个数据中心之间的实时同步,确保数据的一致性和及时性。
- 循环同步避免机制:在双向同步过程中,必须设计有效的机制来避免数据循环同步的问题,确保数据同步的稳定性和可靠性。
- 性能优化:在高并发场景下,保证系统性能的稳定,避免由于同步任务导致的系统资源耗尽。
需求描述
有 A, B 两机房,各自部署一套 MongoDB 集群,其中 A1 业务修改 A 机房数据, B1 业务修改 B 机房数据, 由 T1 任务完成 A => B 的数据同步, 由 T2 任务完成 B => A 的数据同步, 并保证:
- 由 业务方 修改的数据, 需要能够及时同步到对机房
- 由 同步任务 修改的数据, 要避免再次返回应用到本机房
- 在 同步任务 断点回放时, 不产生数据问题
直接创建任务不进行任何修改, 会导致如下情况:
- A 机房, 对一条记录, 连续产生两条更新, U1, U2, 并同步在 B 机房产生 U1, U2 更新
- B 机房产生的更新, 同样会被反向同步到 A 机房
- 由于更新延迟, 在 A 机房接收到 U1 的修改时, 自身已经处于 U2 状态, 因此会再次经历 U1 U2 的调整
- 以上 1-3 步骤会持续进行, 永不停止
通过上述需求分析,明确了订单中心在实现双活架构过程中面临的主要挑战和技术需求。下一步将详细介绍具体的技术实现方案,包括架构设计、数据同步机制和性能优化方案等内容,以确保系统的高可用性和数据一致性。
集群架构方案
双活整体架构
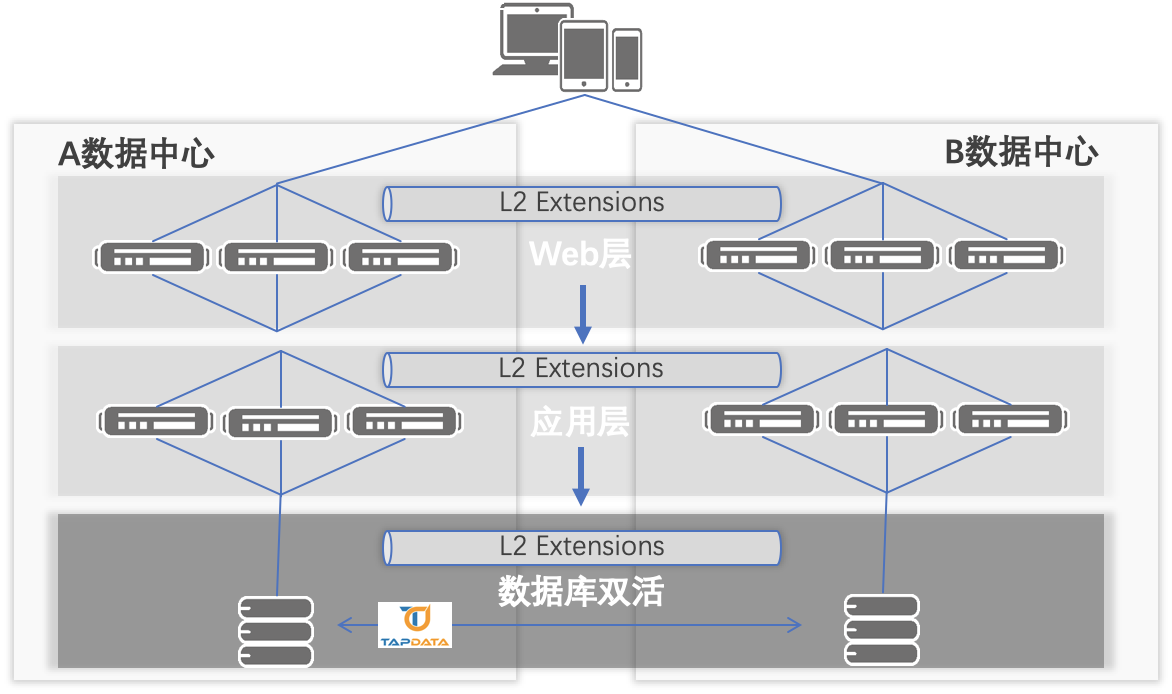
- 应用按区域
- A、B 两中心分别对外提供写入入口
- 应用按区域向不同入口请求写入
- MongoDB 提供数据库高可用
- MongoDB 分片集群每个分片节点采用副本集架构,作为数据库高可用解决方案
- 同时在两中心各部署一套相同架构的 MongoDB 集群,确保每个中心数据库保持持续提供服务状态
- Tapdata 提供数据同步
- 确保两数据中心,数据库数据一致性
- Tapdata 部署在 A 中心
- 保证 A 中心 <-> Tapdata <-> B 中心数据库访问通畅
双活部署架构


架构说明
- MongoDB(蓝色):订单中心MongoDB数据库双活集群
- Tapdata Management:负责软件各模块调度和网页控制台展现。
- Tapdata Flow Engine:负责数据同步、清洗、多表关联、聚合计算等。
- MongoDB(绿色):Tapdata 数据库,中间缓存结果。
工作模式
场景说明:
当 DC A 不可用时,Tapdata 集群也不可用
需要人工干预恢复:
- 所有业务切到 DC B 写入
- 恢复 DC A 服务器
- 恢复 DC A MongoDB Cluster
- 恢复 DC A tapdata
- 重新启动 DC A tapdata 任务
风险:
- 当 DC A 发生不可用时,部分传输数据未写入 DC B Mongo
- 这部分数据会在 DB B 丢失,但在 DC A 中
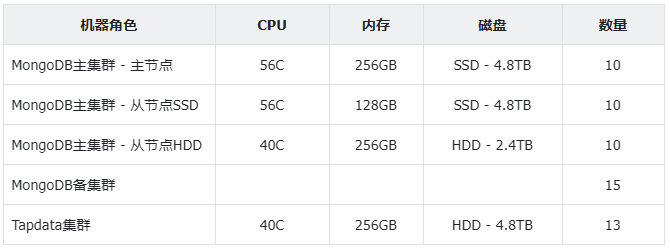
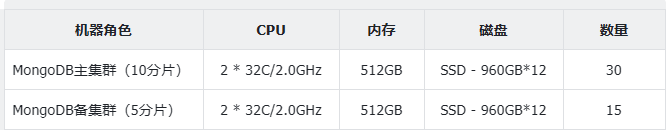
所需资源
北京中心
陕西中心
TapData 实施方案
在构建该订单中心双活架构的过程中,TapData 作为核心的数据同步和管理工具,承担了跨数据中心的数据一致性维护任务。为了确保系统的高可用性与数据的一致性,以下将详细介绍该项目中的具体实施方案,包括各个关键步骤的具体操作与技术要点。
- 数据源配置
源端数据库
-
配置充足的 Oplog 存储空间,至少需要容纳 24 * 7 小时的 Oplog。 具体操作,见修改 Oplog 大小。
-
根据权限管控需求选择下述步骤,创建用于数据同步/开发任务的账号并授予权限。
-
由于分片服务器不会向 config 数据库获取用户权限,因此,当源库为分片集群架构时,您需要在每个分片的主节点上创建相应的用户并授予权限。
-
授予指定库的读权限
use admin db.createUser({ "user" : "tapdata", "pwd" : "my_password", "roles" : [ { "role" : "clusterMonitor", "db" : "admin" }, { "role" : "read", "db" : "order" }, { "role" : "read", "db" : "local" }, { "role" : "read", "db" : "config" } ] } -
授予所有库的读权限。
use admin db.createUser({ "user" : "tapdata", "pwd" : "my_password", "roles" : [ { "role" : "clusterMonitor", "db" : "admin" }, { "role" : "readAnyDatabase", "db" : "admin" } ] }
-
-
在设置 MongoDB URI 时,推荐将写关注级别设置为大多数,即 w=majority,否则可能因 Primary 节点异常宕机导致的数据丢失文档。
-
源库为集群架构时,为提升数据同步性能,Tapdata 将会为每个分片创建一个线程并读取数据,在配置数据同步/开发任务前,您还需要执行下述操作。
- 关闭源库的均衡器(Balancer),避免块迁移对数据一致性的影响。具体操作,见如何停止平衡器。
- 清除源库中,因块迁移失败而产生的孤立文档,避免 _id 冲突。具体操作,见如何清理孤立文档。
目标端数据库
详情参见文档:MongoDB | Tapdata 文档中心
- 授予指定库的写权限,并授予 clusterMonitor 角色以供数据验证使用,示例如下:
`use admin
db.createUser({
"user" : "tapdata",
"pwd" : "my_password",
"roles" : [
{
"role" : "clusterMonitor",
"db" : "admin"
},
{
"role" : "readWrite",
"db" : "order"
},
{
"role" : "read",
"db" : "local"
}
]
}`
2.** 初始化同步**
- oc_order集合使用mongodump逻辑导出的方式对数据进行初始化。由于磁盘限制,按照CREATE_DATE字段进行分段导出。
- 由于其余集合较小,可以直接使用Tapdata工具进行初始化同步。
环境准备
-
[陕西]清空已有的测试数据
/home/mongodb/app/mongodb-linux-x86_64-3.4.24/bin/mongo --host 10.173.2.115:20000 use order db.dropDatabase() -
[陕西]创建集合及其相应的片键索引
use order // 表order.oc_order创建索引 db.oc_order.createIndex({ "ORDER_ID" : "hashed"}) // 表order.oc_order_dispatch创建索引 db.oc_order_dispatch.createIndex({ "ORDER_ID" : "hashed"}) // 表order.oc_order_low_efficientcy创建索引 db.oc_order_low_efficientcy.createIndex({ "ORDER_ID" : "hashed"}) // 表order.oc_order_pic创建索引 db.oc_order_pic.createIndex({ "PIC_KEY" : "hashed"}) // 表order.oc_order_activate创建索引 db.oc_order_activate.createIndex({ "ORDER_ID" : "hashed"})
-
[陕西]对集合进行分片
use order // 实现数据库order分片功能 mongos> sh.enableSharding("order") // 以"ORDER_ID"作为分片键对集合oc_order进行分片 mongos> sh.shardCollection("order.oc_order",{"ORDER_ID":"hashed"}) // 以"ORDER_ID"作为分片键对集合oc_order_low_efficientcy进行分片 mongos> sh.shardCollection("order.oc_order_low_efficientcy",{"ORDER_ID":"hashed"}) // 以"PIC_KEY"作为分片键对集合oc_order_pic进行分片 mongos> sh.shardCollection("order.oc_order_pic",{"PIC_KEY":"hashed"}) // 以"ORDER_ID"作为分片键对集合oc_order_activate进行分片 mongos> sh.shardCollection("order.oc_order_activate",{"ORDER_ID":"hashed"}) // 以"ORDER_ID"作为分片键对集合oc_order_dispatch进行分片 mongos> sh.shardCollection("order.oc_order_dispatch",{"ORDER_ID":"hashed"}) -
[北京][陕西]关闭均衡器
`/home/mongodb/app/mongodb-linux-x86_64-enterprise-rhel70-3.4.24/bin/mongo --host 10.191.241.218:20000
sh.stopBalancer()
sh.isBalancerRunning()
sh.getBalancerState()`
`/home/mongodb/app/mongodb-linux-x86_64-3.4.24/bin/mongo --host 10.173.2.115:20000
sh.stopBalancer()
sh.isBalancerRunning()
sh.getBalancerState()`
- [陕西]检查集群状态
sh.status()
- [陕西]回滚操作
use order db.dropDatabase()
北京中心集群数据导出
-
小于20210901--10.173.2.108服务器上操作
nohup /home/mongodb/app/mongodb-linux-x86_64-3.4.24/bin/mongodump --host 10.191.241.128:20000 -u monit -p 'Monit#3' --db order -c oc_order --authenticationDatabase admin -q '{"CREATE_DATE": {"$lt":"2021-09-01"}}' --readPreference='{mode: "secondary", tagSets: [ { "type": "ssd" } ]}' -o /data/oc_order/ > dumpbf0901.log & -
大于等于20210901小于20220201--10.173.2.110服务器上操作
nohup /home/mongodb/app/mongodb-linux-x86_64-3.4.24/bin/mongodump --host 10.191.241.128:20000 -u monit -p 'Monit#3' --db order -c oc_order --authenticationDatabase admin -q '{"CREATE_DATE": {"$gte":"2021-09-01"},"CREATE_DATE": {"$lt":"2022-02-01"}}' --readPreference='{mode: "secondary", tagSets: [ { "type": "ssd" } ]}' -o /data/oc_order/ > dumpbf220201.log &
- 大于等于20220201小于20220801--10.173.2.112服务器上操作
nohup /home/mongodb/app/mongodb-linux-x86_64-3.4.24/bin/mongodump --host 10.191.241.128:20000 -u monit -p 'Monit#3' --db order -c oc_order --authenticationDatabase admin -q '{"CREATE_DATE": {"$gte":"2022-02-01"},"CREATE_DATE": {"$lt":"2022-08-01"}}' --readPreference='{mode: "secondary", tagSets: [ { "type": "ssd" } ]}' -o /data/oc_order/ > dumpbf20220801.log &
- 大于等于20220801小于20230201--10.173.2.113服务器上操作
nohup /home/mongodb/app/mongodb-linux-x86_64-3.4.24/bin/mongodump --host 10.191.241.128:20000 -u monit -p 'Monit#3' --db order -c oc_order --authenticationDatabase admin -q '{"CREATE_DATE": {"$gte":"2022-08-01"},"CREATE_DATE": {"$lt":"2023-02-01"}}' --readPreference='{mode: "secondary", tagSets: [ { "type": "ssd" } ]}' -o /data/oc_order/ > dumpbf230201.log &
- 大于等于20230201--10.173.2.114服务器上操作
nohup /home/mongodb/app/mongodb-linux-x86_64-3.4.24/bin/mongodump --host 10.191.241.128:20000 -u monit -p 'Monit#3' --db order -c oc_order --authenticationDatabase admin -q '{"CREATE_DATE": {"$gte":"2023-02-01"}}' --readPreference='{mode: "secondary", tagSets: [ { "type": "ssd" } ]}' -o /data/oc_order/ > dumpaf230201.log &
陕西中心集群数据导入
- 小于20210901--10.173.2.108服务器上操作
nohup /home/mongodb/app/mongodb-linux-x86_64-3.4.24/bin/mongorestore --host 10.173.2.115:20000 --numInsertionWorkersPerCollection=8 -u monit -p 'Monit#3' --db order -c oc_order --authenticationDatabase admin /data/oc_order/order/oc_order.bson > restorebf210901.log 2>&1 &
- 大于等于20210901小于20220201--10.173.2.110服务器上操作
nohup /home/mongodb/app/mongodb-linux-x86_64-3.4.24/bin/mongorestore --host 10.173.2.115:20000 --numInsertionWorkersPerCollection=8 -u monit -p 'Monit#3' --db order -c oc_order --authenticationDatabase admin /data/oc_order/order/oc_order.bson > restorebf220201.log 2>&1 &
- 大于等于20220201小于20220801--10.173.2.112服务器上操作
nohup /home/mongodb/app/mongodb-linux-x86_64-3.4.24/bin/mongorestore --host 10.173.2.115:20000 --numInsertionWorkersPerCollection=8 -u monit -p 'Monit#3' --db order -c oc_order --authenticationDatabase admin /data/oc_order/order/oc_order.bson > restorebf220801.log 2>&1 &
- 大于等于20220801小于20230201--10.173.2.113服务器上操作
nohup /home/mongodb/app/mongodb-linux-x86_64-3.4.24/bin/mongorestore --host 10.173.2.115:20000 --numInsertionWorkersPerCollection=8 -u monit -p 'Monit#3' --db order -c oc_order --authenticationDatabase admin /data/oc_order/order/oc_order.bson > restorebf230201.log 2>&1 &
- 大于等于20230201--10.173.2.114服务器上操作
nohup /home/mongodb/app/mongodb-linux-x86_64-3.4.24/bin/mongorestore --host 10.173.2.115:20000 --numInsertionWorkersPerCollection=8 -u monit -p 'Monit#3' --db order -c oc_order --authenticationDatabase admin /data/oc_order/order/oc_order.bson > restoreaf230201.log 2>&1 &
- 集群状态检查
sh.status() db.printSlaveReplicationInfo()
- 回滚操作
use order db.dropDatabase()
- 实时同步
初始化同步完成后,可以配置 TapData 进行实时数据同步,以确保两个数据中心之间的数据实时一致。在此阶段,TapData 将实时捕获并同步 A 中心和 B 中心的 MongoDB 数据库中的数据变更,确保两个数据中心之间的数据持续保持一致。
实时同步是确保源数据库和目标数据库之间数据一致性的重要步骤,尤其是在高并发和复杂业务场景下。通过实时同步,订单中心的数据能够在不同的数据中心之间进行及时传输和更新,确保所有业务系统使用的都是最新的数据。TapData 在实时同步中发挥了核心作用,通过创建数据复制任务并设置增量同步点,系统能够实现数据的无缝同步。在执行实时同步时,还需要考虑可能出现的流量过大问题,并制定相应的应对措施,确保系统的稳定性和数据同步的连续性。
接下来将详细介绍如何配置和管理实时同步任务,以及应对流量过大情况的操作步骤。
操作步骤
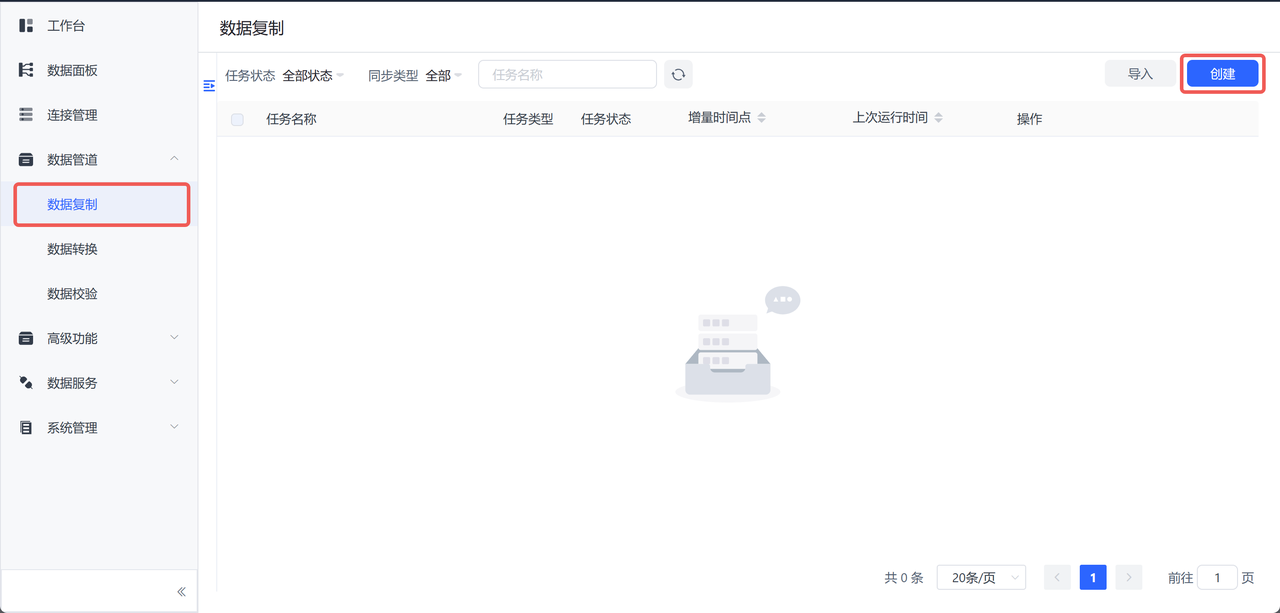
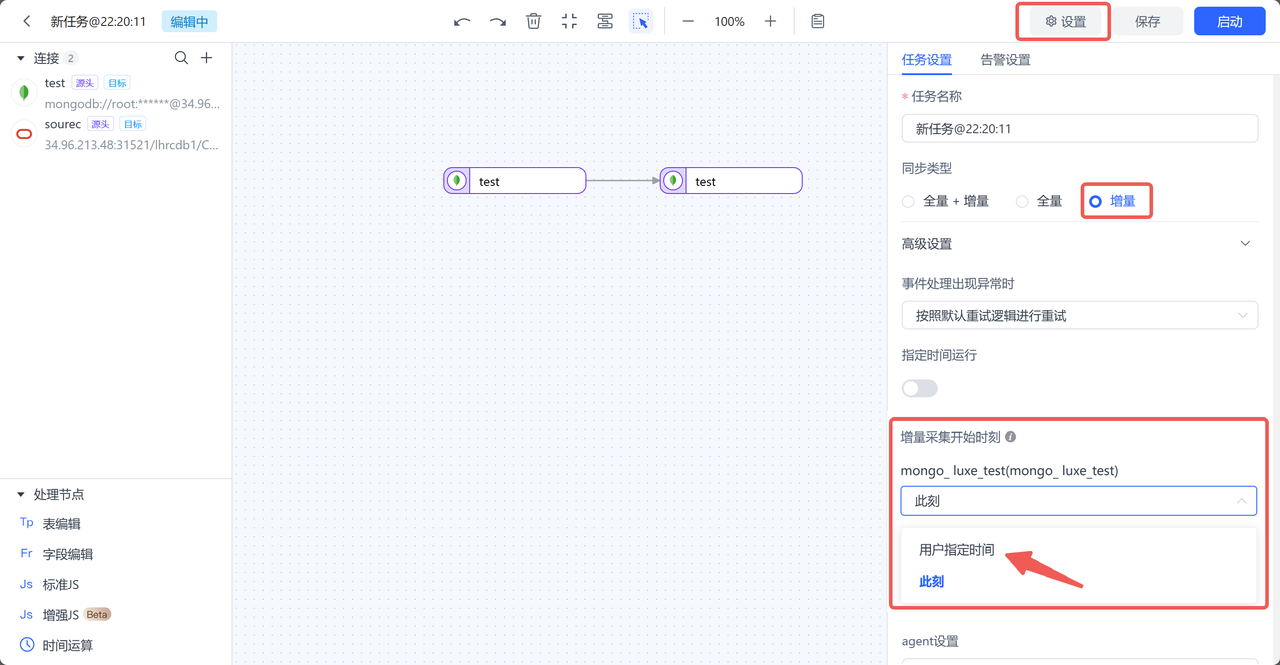
- 创建 TapData 数据复制任务
- 任务设置:增量
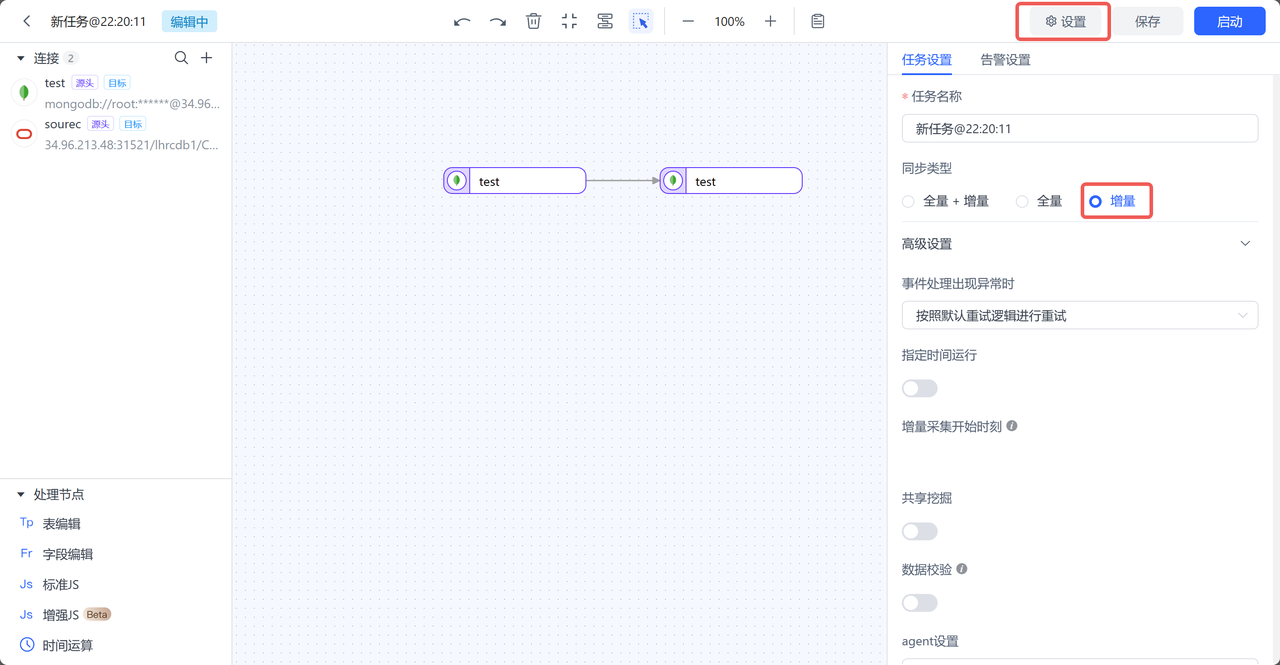
- 设置增量同步时间点为最后一次初始化导出的数据时间点
- 保存任务
- 启动任务
流量过大处理
- 停止同步任务
`#登录到服务器查看状态
cd /data/tapdata_v1.51.1
./tapdata status
强制停止所有服务
./tapdata stop -f
./tapdata status`
- kill掉Tapdata同步进程
登录到tapdata服务器 ps -ef|grep tapdata kill -9 $pid
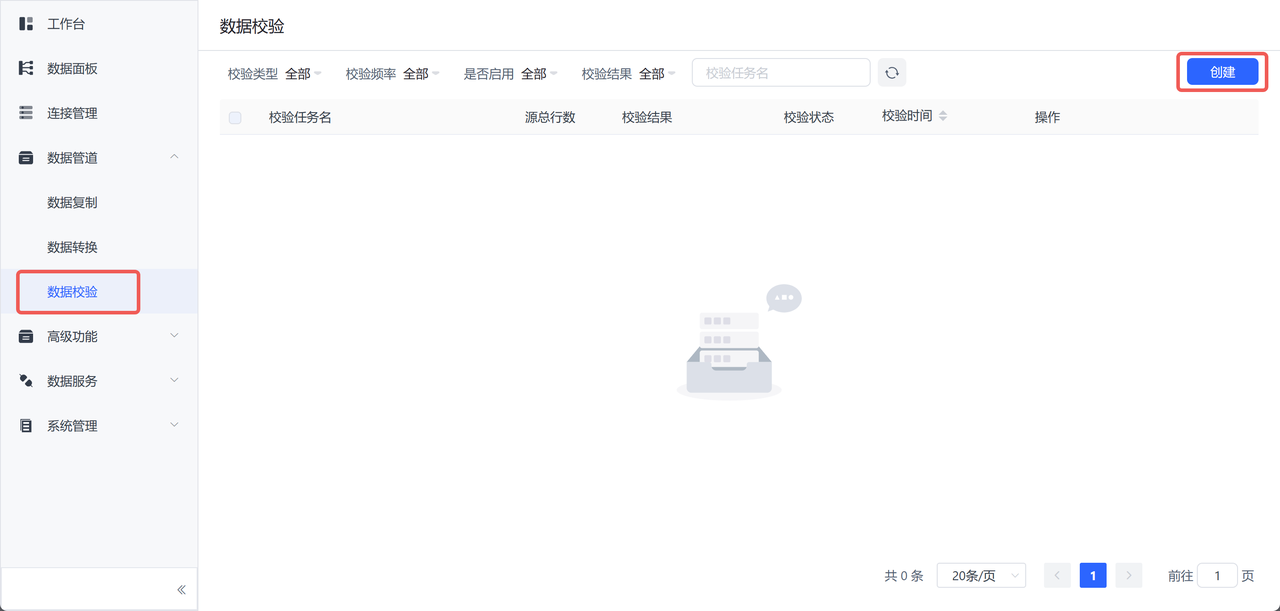
4. 数据校验
在实时同步运行过程中,定期进行数据校验,确保两个数据中心的数据库始终保持一致。数据校验的目的是检测和修复因网络延迟、系统故障等原因导致的数据不一致问题,是确保数据同步任务成功执行的关键步骤,通过对比源数据库与目标数据库的数据,验证同步的准确性和完整性。
在 TapData 实施方案中,数据校验功能可以帮助用户快速检测并解决可能出现的数据不一致问题。特别是在双活架构中,数据的实时同步任务上,数据校验能够确保两个数据中心的数据保持一致,避免因数据不一致导致的业务中断。以下是具体操作示例:
- 通过 TapData 的数据校验功能中的条数校验进行快速检查
- 对一定时间范围内的数据进行抽查以检验一致性
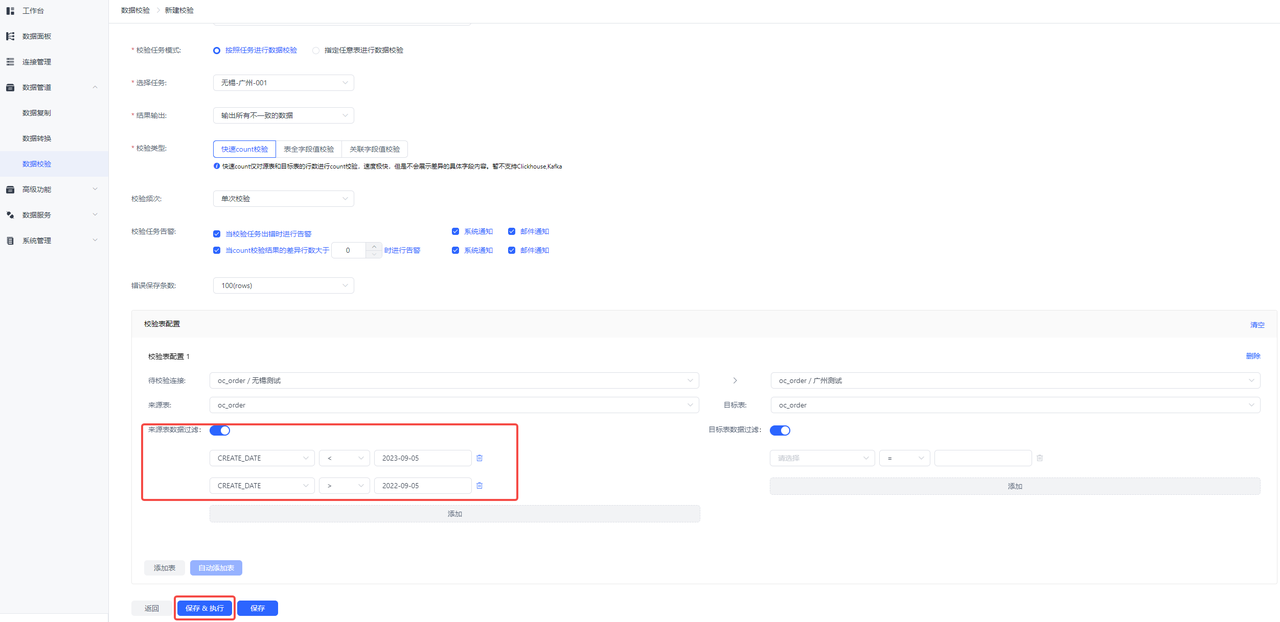
基于此,该运营商成功实现了订单中心的高可用、高性能双活架构,确保业务的连续性和数据的一致性,为客户提供更加稳定和高效的服务。
双活场景演练
双活架构在确保系统高可用性和数据一致性方面扮演着关键角色,但在实际运行中,可能会遇到各种数据同步和写入的挑战。为了验证和优化双活架构的稳定性,必须进行多种场景演练。这些测试不仅有助于发现潜在的问题,还可以通过配置和功能调整来优化系统的响应和恢复能力。
下面将通过对多种典型场景的分析和演练,帮助团队识别潜在问题,并通过合理的配置和机制优化,确保系统在不同情况下都能保持业务的连续性和数据的一致性。
- 业务成功写入数据库,TapData 未正确同步到目标
中心 A:DCA
中心 B:DCB
同步任务 A:JobA,A -> B
同步任务 B:JobB,B -> A
业务 A 向 DCA 写入数据:DataA
业务 B 向 DCB 写入数据:DataB
10:00,启动 JobA,JobB
10:30,有一笔订单 Order1(oid=1,status=create) 向 DCA 写入,且成功写入。
10:31,JobA 由于某种原因未将 Order1 正确同步到 DCB 中。
10:32,业务 B 在 DCB 查询不到 Order1
这里可以通过 tapdata 的“任务自动重试”及“断点续传”来避免因为某种原因未同步到目标数据库的情况。
可能原因
- 因为网络抖动,导致这笔订单未成功同步到 DCB。
- 解决方案:自动重试。(默认 1 分钟重试 1 次,一共重试 5 次,可配置)
- 因为数据库故障、高可用等行为,导致同步任务中断,这笔订单未成功写入 DCB。
- 解决方案:断点续传。在数据库恢复后,可直接启动,在中断的日志点继续同步。
验证
1 分钟查询 1 次 DCB,最终可以在 DCB 查询到 Order1
- 正常双活运行情况下
中心 A:DCA
中心 B:DCB
同步任务 A:JobA,A -> B
同步任务 B:JobB,B -> A
业务 A 向 DCA 写入数据:DataA
业务 B 向 DCB 写入数据:DataB
10:00, 启动 JobA,JobB
10:30, 有一笔订单 Order1(oid=1,status=create) 写入 DCA,通过 JobA 同步到 DCB
10:31,业务 B 可以在 DCB 访问到 Order1
10:32,业务 B 在 DCB 对 Order1 进行数据更新,修改 status=active
10:33,业务 A 在 DCA 可以查询到 Order1(status=active)
总结与延展
在本案例中,我们详细探讨了双活架构在实现高可用性和数据一致性方面的最佳实践。关键要点包括:
- 双活架构设计:通过在两个数据中心部署相同的 MongoDB 集群和 Tapdata 同步引擎,实现数据的实时双向同步,确保任一数据中心发生故障时,另一个数据中心能够无缝接管,确保业务不中断。
- 数据同步机制:设计有效的循环同步避免机制和数据一致性检查机制,解决数据循环同步和数据一致性问题,确保系统的稳定性和可靠性。
- 性能优化措施:在高并发业务场景下,通过优化同步任务、合理配置 MongoDB 和 Tapdata 集群资源,确保系统的整体性能。
- 风险控制:通过详细的故障处理方案和数据恢复机制,确保在数据中心故障时能够快速恢复,减少业务中断时间和数据丢失风险。
最佳实践
- 数据同步策略设计
在双向数据同步的设计中,建议采用数据标识机制,确保每条数据的变更都有明确的来源标识,防止数据循环同步问题。同步任务的设计应包括清晰的逻辑判断,确保同步过程中的数据一致性。 - 断点回放和容错机制
同步任务应具备断点回放功能,以确保在任务中断后可以从中断点继续执行,避免数据不一致问题。容错机制的设计对于提高系统的可靠性至关重要,应在设计初期予以充分考虑。 - 高并发场景下的性能优化
在高并发业务场景中,建议采用多线程和批处理技术提高同步效率。系统应具备动态调优能力,能够根据实际业务负载情况进行调整,确保同步任务的高效执行。 - 实时监控与预警
建立全面的实时监控系统,对数据同步过程中的各项性能指标进行监控,及时发现和处理异常情况。预警机制应能够在问题发生前发出警报,提前进行干预,确保系统的稳定运行。
5.** 系统测试和演练**
定期进行系统测试和演练,模拟各种故障场景,验证系统的高可用性和容灾能力。通过不断的测试和演练,及时发现和解决潜在问题,提高系统的可靠性和稳定性。 - 文档和知识分享
在项目实施过程中,及时记录各种问题和解决方案,形成详细的文档。通过知识分享和经验总结,不仅提升团队的整体技术水平,也为后续项目提供宝贵的参考。
该方案的成功实施不仅提升了该订单中心的业务连续性和数据可靠性,还为更多构建高可用性和容灾能力的系统架构的类似需求提供了经验和参考。未来,我们将继续优化和提升双活架构的性能和稳定性,以应对更加复杂和多变的业务需求。
【推荐阅读】
- 如何高效整合分散数据,构建统一的实时数据平台?
- 流式处理 vs 批处理,新数据时代的数据处理技术该如何选择?
- TapData 医疗美容行业数字化白皮书上线
- 战略资讯 | TapData 牵手思想科技,开启数据管理新篇章!