项目地址:https://github.com/skyzh/mini-lsm
个人实现地址:https://gitee.com/cnyuyang/mini-lsm
Summary

在本章中,您将:
- 实现
tiered合并策略并在压缩模拟器上对其进行模拟。 - 将
tiered合并策略纳入系统。
我们在本章所讲的tiered合并和RocksDB的universal合并是一样的。我们将互换使用这两个术语。
要将测试用例复制到启动器代码中并运行它们,
cargo x copy-test --week 2 --day 3
cargo x scheck
Task 1-Universal Compaction
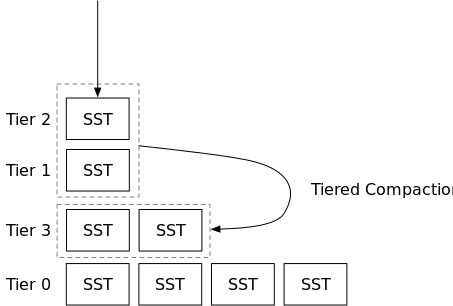
在本章中,您将实现RocksDB的universal合并,它是tiered合并家族的合并策略。与simple leveled合并策略类似,在此合并策略中,我们只使用文件数量作为指标。当我们触发合并任务时,我们总是在合并任务中包含一个完整的排序run(层)。
Task 1.0-Precondition
在此任务中,您需要修改:
src/compact/tiered.rs在
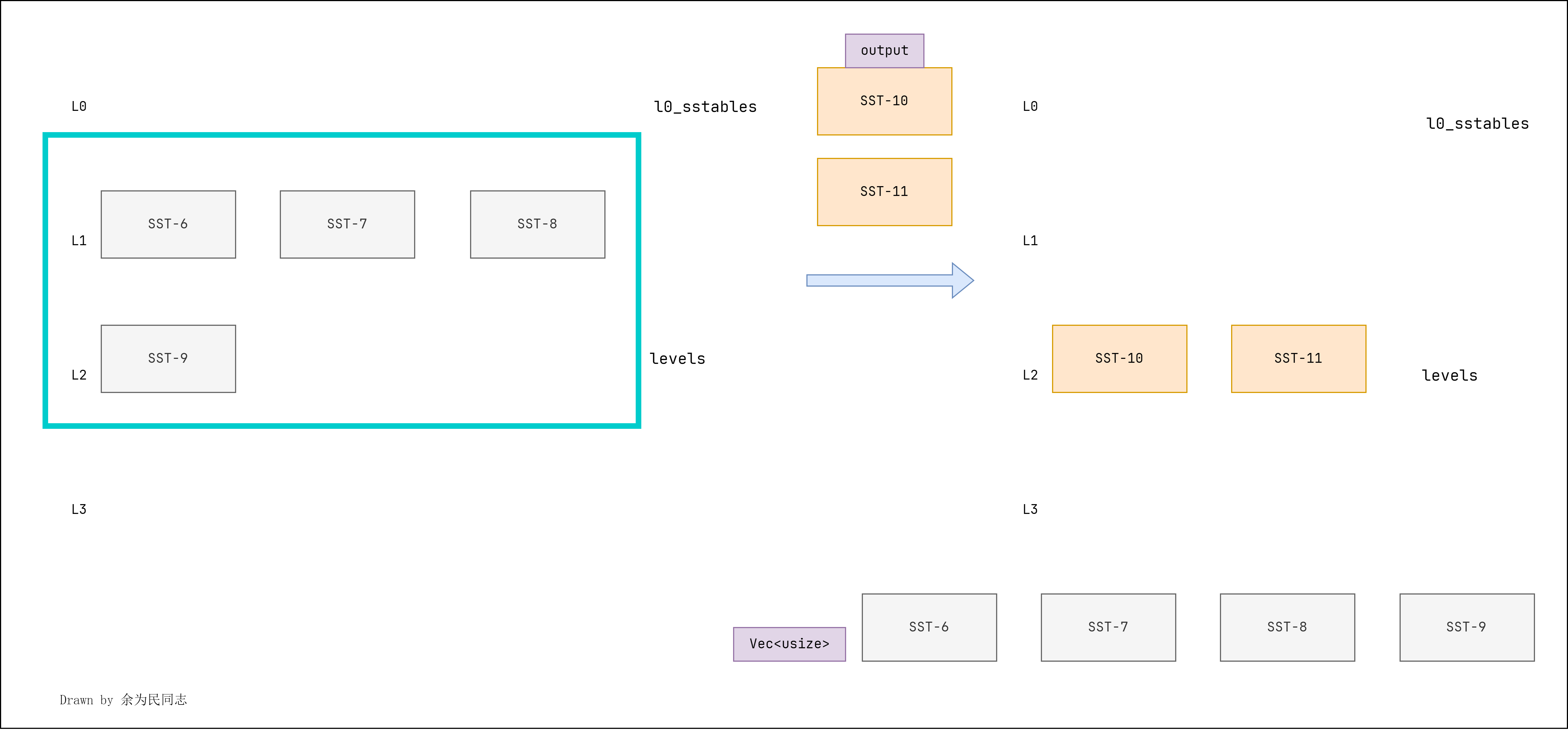
universal合并中,我们不使用LSM状态下的L0 SST。相反,我们直接将新的SST转储到单个排序run(称为层)。在LSM状态中,levels现在将包括所有层,其中最小的索引是最新转储的SST。levels数组中的每个元素存储一个元组:级别ID(用作层ID)和该级别中的SST。每次转储L0 SST时,都应该将SST转储到放置在向量前面的层中。compaction模拟器根据第一个SST id生成层id,您应该在您的实现中执行相同的操作。只有在层数(排序run数)大于
num_tiers时,universal合并才会触发任务。否则,它不会触发任何合并。
该子任务就是在generate_compaction_task函数中先判断_snapshot.levels数组的大小是否大于num_tiers。若不大于则无需进行任务合并操作。
pub fn generate_compaction_task(&self,_snapshot: &LsmStorageState,
) -> Option<TieredCompactionTask> {if _snapshot.levels.len() < self.options.num_tiers {return None}None
}
Task 1.1-Triggered by Space Amplification Ratio
universal合并的第一个触发因素是空间放大比。正如我们在概述章节中所讨论的,空间放大可以通过engine_size/last_level_size来估计。在我们的实现中,我们通过除最后一级之外的所有级别大小之和/最后一级大小来计算空间放大比,从而可以将比值缩放为[0,+inf]而不是[1, +inf]。这也与RocksDB的实现是一致的。当
除最后一级之外的所有级别大小之和/最后一级大小 >= max_size_amplification_percent * 100%时,我们将需要触发一个完整的合并。实现了这个触发器之后,就可以运行合并模拟器了。您将看到:
cargo run --bin compaction-simulator tiered--- After Flush --- L3 (1): [3] L2 (1): [2] L1 (1): [1] --- Compaction Task --- compaction triggered by space amplification ratio: 200 L3 [3] L2 [2] L1 [1] -> [4, 5, 6] --- After Compaction --- L4 (3): [3, 2, 1]有了这个触发器,我们只有在达到空间放大比的时候才会触发完全压缩。在模拟结束时,您将看到:
--- After Flush --- L73 (1): [73] L72 (1): [72] L71 (1): [71] L70 (1): [70] L69 (1): [69] L68 (1): [68] L67 (1): [67] L40 (27): [39, 38, 37, 36, 35, 34, 33, 32, 31, 30, 29, 28, 27, 26, 25, 24, 23, 22, 13, 14, 15, 16, 17, 18, 19, 20, 21]合并模拟器中的
num_tiers设置为3。然而,LSM状态中的层远远不止3层,这导致了很大的读放大。当前触发合并机制只能减少空间放大。我们需要在合并算法中添加新的触发器,以减少读取放大。
generate_compaction_task
- 统计除最后一级之外的所有级别大小之和,因为每个SST的大小都是固定的,所以可以近似的使用数量代替大小计算
- 计算除最后一级之外的所有级别大小之和/最后一级大小,若大于阈值,则创建新的合并任务
pub fn generate_compaction_task(&self,_snapshot: &LsmStorageState,
) -> Option<TieredCompactionTask> {// Task 1.0-Preconditionif _snapshot.levels.len() < self.options.num_tiers {return None;}// Task 1.1-Triggered by Space Amplification Ratiolet levels_num = _snapshot.levels.len();let last_level_size = _snapshot.levels[levels_num - 1].1.len();let mut engine_size = 0;for (index, level) in _snapshot.levels.iter().enumerate() {if index == levels_num - 1 {break;}engine_size += level.1.len();}println!("levels_num:{}, last_level_size:{}, engine_size:{}", levels_num, last_level_size, engine_size);if engine_size as f64 / last_level_size as f64 >= self.options.max_size_amplification_percent as f64 / 100.0f64 {return Some(TieredCompactionTask { tiers: _snapshot.levels.clone(), bottom_tier_included: true });}None
}
apply_compaction_result
- 将此前的都清空删除,新合并的SST放置到最底层
pub fn apply_compaction_result(&self,_snapshot: &LsmStorageState,_task: &TieredCompactionTask,_output: &[usize],
) -> (LsmStorageState, Vec<usize>) {let mut snapshot = _snapshot.clone();let mut files_to_remove = Vec::new();let tiered_id = _output.first().unwrap();if _task.bottom_tier_included {snapshot.levels.clear();}for levels in _task.tiers.iter() {files_to_remove.extend(levels.clone().1)}snapshot.levels.insert(0, (*tiered_id, _output.to_vec()));(snapshot, files_to_remove)
}
如图展示前两次的情况,第一次触发合并:

第二次触发合并:

可以看到后续触发合并的条件越来越苛刻,以至于层数过多,这将导致读放大。因为每一层都需要进行一次IO。
通过运行合并模拟器可以看到最后转储50个SST后的结果,可以看到存在24层:
=== Iteration 49 ===
--- After Flush ---
L89 (1): [89]
L88 (1): [88]
L87 (1): [87]
L86 (1): [86]
L85 (1): [85]
L84 (1): [84]
L83 (1): [83]
L82 (1): [82]
L81 (1): [81]
L80 (1): [80]
L79 (1): [79]
L78 (1): [78]
L77 (1): [77]
L76 (1): [76]
L75 (1): [75]
L74 (1): [74]
L73 (1): [73]
L72 (1): [72]
L71 (1): [71]
L70 (1): [70]
L69 (1): [69]
L68 (1): [68]
L67 (1): [67]
L40 (27): [39, 38, 37, 36, 35, 34, 33, 32, 31, 30, 29, 28, 27, 26, 25, 24, 23, 22, 13, 14, 15, 16, 17, 18, 19, 20, 21]
--- Compaction Task ---
--- Compaction Task ---
levels_num:24, last_level_size:27, engine_size:23
no compaction triggered
--- Statistics ---
Write Amplification: 89/50=1.780x
Maximum Space Usage: 54/50=1.080x
Read Amplification: 24x
Task 1.2-Triggered by Size Ratio
下一个触发器是大小比触发器。对于所有层,如果有一个层n的
所有之前层的大小/此层>= (100 + size_ratio) * 100%,我们将合并所有n层。我们只在要合并的层超过min_merge_width的情况下执行此合并。使用此触发器,您将在合并模拟器中观察到以下内容:
L207 (1): [207] L204 (3): [203, 202, 201] L186 (15): [185, 178, 179, 180, 181, 182, 183, 184, 158, 159, 160, 161, 162, 163, 164] L114 (31): [113, 98, 99, 100, 101, 102, 103, 104, 105, 106, 107, 108, 109, 110, 111, 112, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56]将有更少的1-SST层,并且合并算法将保持这些层按大小比从较小到较大的大小。但是,当处于LSM状态的SST更多时,仍然会有超过num_tiers层的情况。为了限制层数,我们需要另一个触发器。
generate_compaction_task函数新增触发条件
// Task 1.2-Triggered by Size Ratio
let mut previous_tiers_size = 0;
for (index, level) in _snapshot.levels.iter().enumerate() {if (index + 1) < self.options.min_merge_width {previous_tiers_size += level.1.len();continue;}let this_tier = level.1.len();if previous_tiers_size as f64 / this_tier as f64 >= (self.options.size_ratio as f64 + 100.0f64) / 100.0f64 {println!("previous_tiers_size:{}, this_tier:{}, n:{}", previous_tiers_size, this_tier, index + 1);return Some(TieredCompactionTask {tiers: _snapshot.levels.iter().take(index + 1).cloned().collect::<Vec<_>>(),bottom_tier_included: index == levels_num - 1,});}previous_tiers_size += level.1.len();
}
实现第二个触发器后,除了往最底层合并外,也能触发前n层进行合并:

Task 1.3:-Reduce Sorted Runs
如果前面的触发器都没有产生合并任务,那么我们将进行一次合并以减少层数。我们将简单地将前面几层压缩为一层,以便最终状态将具有正好num_tiers层(如果在压缩期间没有刷新SST)。
启用此压缩后,您将看到:
L427 (1): [427] L409 (18): [408, 391, 392, 393, 394, 395, 396, 397, 398, 399, 400, 401, 402, 403, 404, 405, 406, 407] L208 (31): [207, 192, 193, 194, 195, 196, 197, 198, 199, 200, 201, 202, 203, 204, 205, 206, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71, 72]所有的合并结果都不会超过num_tiers层。
注意:这部分我们不提供细粒度的单元测试。您可以运行合并模拟器,并与参考解决方案的
输出进行比较,以查看您的实现是否正确。
generate_compaction_task函数新增触发条件,就是在最后返回的时候,判断当前层级个数是否大于num_tiers。如果大于就将前面几个层级进行合并。
if _snapshot.levels.len() == self.options.num_tiers {return None;
}
// Task 1.3:-Reduce Sorted Runs
let nums = _snapshot.levels.len() - self.options.num_tiers + 1;
println!("Reduce Sorted Runs, levels size: {}, num_tiers:{}, nums:{}", _snapshot.levels.len(), self.options.num_tiers, nums);
return Some(TieredCompactionTask {tiers: _snapshot.levels.iter().take(nums).cloned().collect::<Vec<_>>(),bottom_tier_included: false,
});
Task2-Integrate with the Read Path
在此任务中,您需要修改:
src/compact.rs src/lsm_storage.rs由于
tiered合并不使用LSM状态的L0级别,所以应该直接将memtable转储到新的层,而不是作为L0 SST。可以通过self.compaction_controller.flush_to_l0()来知道是否要刷新到L0。您可以使用第一个输出SST id作为新排序运行的级别/层ID。您还需要修改您的合并过程,以为tiered合并作业构造合并迭代器。
lsm_storage.rs将force_flush_next_imm_memtable函数中的force_flush_next_imm_memtable修改为:
if self.compaction_controller.flush_to_l0() {// In leveled compaction or no compaction, simply flush to L0snapshot.l0_sstables.insert(0, sst.sst_id());
} else {// In tiered compaction, create a new tiersnapshot.levels.insert(0, (sst.sst_id(), vec![sst.sst_id()]));
}
compact.rs修改compact函数,实现CompactionTask::Tiered分支,因为tired合并中只有排好序的run所以实现比较简单:
CompactionTask::Tiered(TieredCompactionTask { tiers, .. }) => {let mut iters = Vec::with_capacity(tiers.len());for (_, tier_sst_ids) in tiers {let mut ssts = Vec::with_capacity(tier_sst_ids.len());for id in tier_sst_ids.iter() {ssts.push(snapshot.sstables.get(id).unwrap().clone());}iters.push(Box::new(SstConcatIterator::create_and_seek_to_first(ssts)?));}self.compact_generate_sst_from_iter(MergeIterator::create(iters),_task.compact_to_bottom_level(),)
},
相关阅读
Universal Compaction - RocksDB Wiki