这是我参与创作者计划的第1篇文章
大家好,因为对AI大模型很感兴趣,相信很多兄弟们跟我一样,所以最近花时间了解了一些,有一些总结 分享给大家,希望对各位有所帮助;
本文主要是目标是 讲解如何在本地 搭建一个简易的AI问答系统,主要用java来实现,也有一些简单的python知识;网上很多例子都是以 ChatGPT来讲解的,但因为它对国内访问有限制,OpeAi连接太麻烦,又要虚拟账号注册账号啥的,第一步就劝退了,所以选择了 llama和qwen替代,但是原理都是一样的;
相关概念了解:
(一)大语言模型 LLM
大型语言模型(LLM,Large Language Models),是近年来自然语言处理(NLP)领域的重要进展。这些模型由于其庞大的规模和复杂性,在处理和生成自然语言方面展现了前所未有的能力。
关于LLM的一些关键点:
LLM的出现标志着NLP领域的一个新时代,它们不仅在学术研究中产生了深远的影响,也在商业应用中展现出了巨大的潜力。
(二)Embedding
在自然语言处理(NLP)和机器学习领域中,"embedding" 是一种将文本数据转换成数值向量的技术。这种技术将单词、短语、句子甚至文档映射到多维空间中的点,使得这些点在数学上能够表示它们在语义上的相似性或差异。
Embeddings 可以由预训练模型生成,也可以在特定任务中训练得到。常见的 embedding 方法包括:
Embeddings 的主要优点在于它们能够捕捉词汇之间的复杂关系,如同义词、反义词以及词义的细微差别。此外,它们还能够处理多义词问题,即一个词在不同上下文中可能有不同的含义。
在实际应用中,embeddings 被广泛用于多种 NLP 任务,如文本分类、情感分析、命名实体识别、机器翻译、问答系统等。通过使用 embeddings,机器学习模型能够理解和处理自然语言数据,从而做出更加准确和有意义的预测或决策。
(三)向量数据库
向量数据库是一种专门设计用于存储和查询高维向量数据的数据库系统。这种类型的数据库在处理非结构化数据,如图像、文本、音频和视频的高效查询和相似性搜索方面表现出色。与传统的数据库管理系统(DBMS)不同,向量数据库优化了对高维空间中向量的存储、索引和检索操作。
以下是向量数据库的一些关键特点和功能:
向量数据库在多个领域得到应用,包括推荐系统、图像和视频检索、自然语言处理(NLP)以及生物信息学。一些知名的向量数据库项目包括FAISS(由Facebook AI Research开发)、Pinecone、Weaviate、Qdrant、Milvus等。
(四)RAG
文章题目中的 "智能问答" 其实专业术语 叫 RAG;
在大模型(尤其是大型语言模型,LLMs)中,RAG 指的是“Retrieval-Augmented Generation”,即检索增强生成。这是一种结合了 检索(Retrieval)和生成(Generation)技术的人工智能方法, 主要用于增强语言模型在处理需要外部知识或实时信息的任务时的表现;
RAG 是 "Retrieval-Augmented Generation" 的缩写,即检索增强生成。这是一种结合了检索(Retrieval)和生成(Generation)两种技术的人工智能模型架构。RAG 最初由 Facebook AI 在 2020 年提出,其核心思想是在生成式模型中加入一个检索组件,以便在生成过程中利用外部知识库中的相关文档或片段。
在传统的生成模型中,如基于Transformer的模型,输出完全依赖于模型的内部知识,这通常是在大规模语料库上进行预训练得到的。然而,这些模型可能无法包含所有特定领域或最新更新的信息,尤其是在处理专业性较强或时效性较高的问题时。
RAG 架构通过从外部知识源检索相关信息来增强生成过程。当模型需要生成响应时,它会首先查询一个文档集合或知识图谱,找到与输入相关的上下文信息,然后将这些信息与原始输入一起送入生成模型,从而产生更加准确和丰富的内容。
工作原理
基本流程:
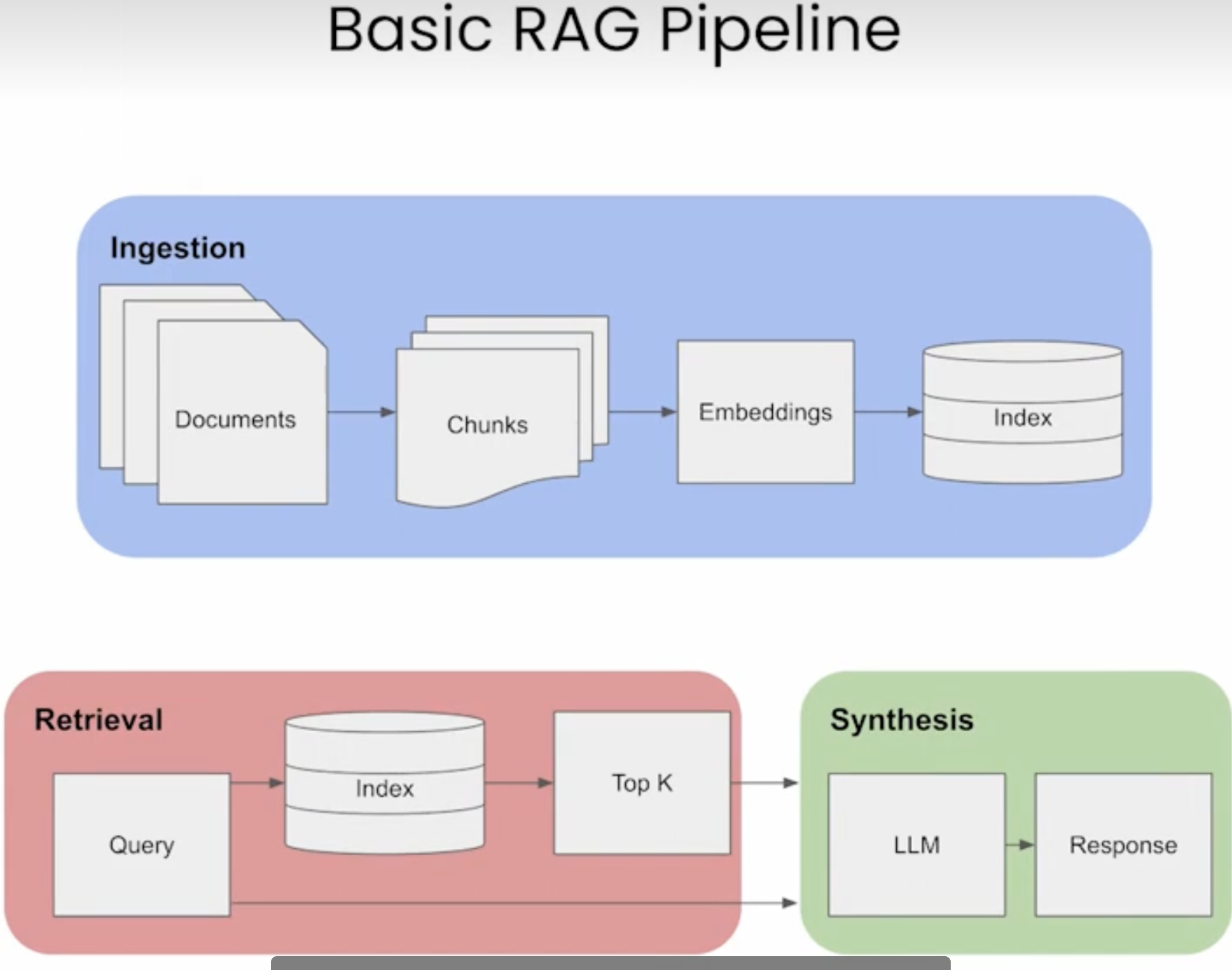
RAG的优势:
RAG 可以应用于多种场景,包括但不限于:
RAG 架构的一个重要组成部分是检索组件,它通常使用向量相似度搜索技术,如倒排索引或基于神经网络的嵌入空间搜索。这使得模型能够在大规模文档集合中快速找到最相关的部分。
AI 应用开发框架
(一)Langchain
官网:https://www.langchain.com/langchain
LangChain不是一个大数据模型,而是一款可以用于开发类似AutoGPT的AI应用的开发工具,LangChain简化了LLM应用程序生命周期的各个阶段,且提供了 开发协议、开发范式,并 拥有相应的平台和生态;
LangChain 是一个由 Harrison Chase 创立的框架,专注于帮助开发者使用语言模型构建端到端的应用程序。它特别设计来简化与大型语言模型(LLMs)的集成,使得创建由这些模型支持的应用程序变得更加容易。LangChain 提供了一系列工具、组件和接口,可以用于构建聊天机器人、生成式问答系统、摘要工具以及其他基于语言的AI应用。
LangChain 的核心特性包括:
(二)LangChain4J
上面说的 LangChain 是基于python 开发的,而 LangChain4J 是一个旨在为 Java 开发者提供构建语言模型应用的框架。受到 Python 社区中 LangChain 库的启发,LangChain4J 致力于提供相似的功能,但针对 Java 生态系统进行了优化。它允许开发者轻松地构建、部署和维护基于大型语言模型的应用程序,如聊天机器人、文本生成器和其他自然语言处理(NLP)任务。
主要特点:
主要功能:
1.LLM 适配器:允许你连接到各种语言模型,如 OpenAI 的 GPT-3 和 GPT-4,Anthropic 的 Claude 等。
2.Chains 构建:提供一种机制来定义和执行一系列操作,这些操作可以包括调用模型、数据检索、转换等,以完成特定的任务。
3.Agent 实现:支持创建代理(agents),它们可以自主地执行任务,如回答问题、完成指令等。
4.Prompt 模板:提供模板化的提示,帮助指导模型生成更具体和有用的回答。
5.工具和记忆:允许模型访问外部数据源或存储之前的交互记录,以便在会话中保持上下文。
6.模块化和可扩展性:使开发者能够扩展框架,添加自己的组件和功能。
本地问答系统搭建环境准备
(一)用 Ollama 启动一个本地大模型

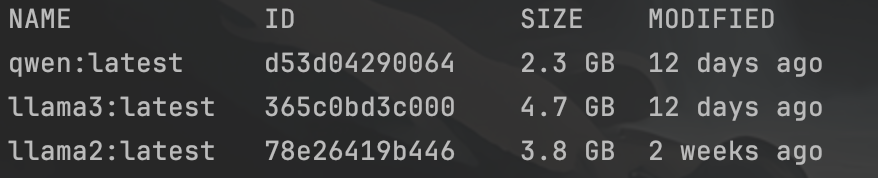
下载完成后,通过 ollma list 可以查看 已下载的大模型;
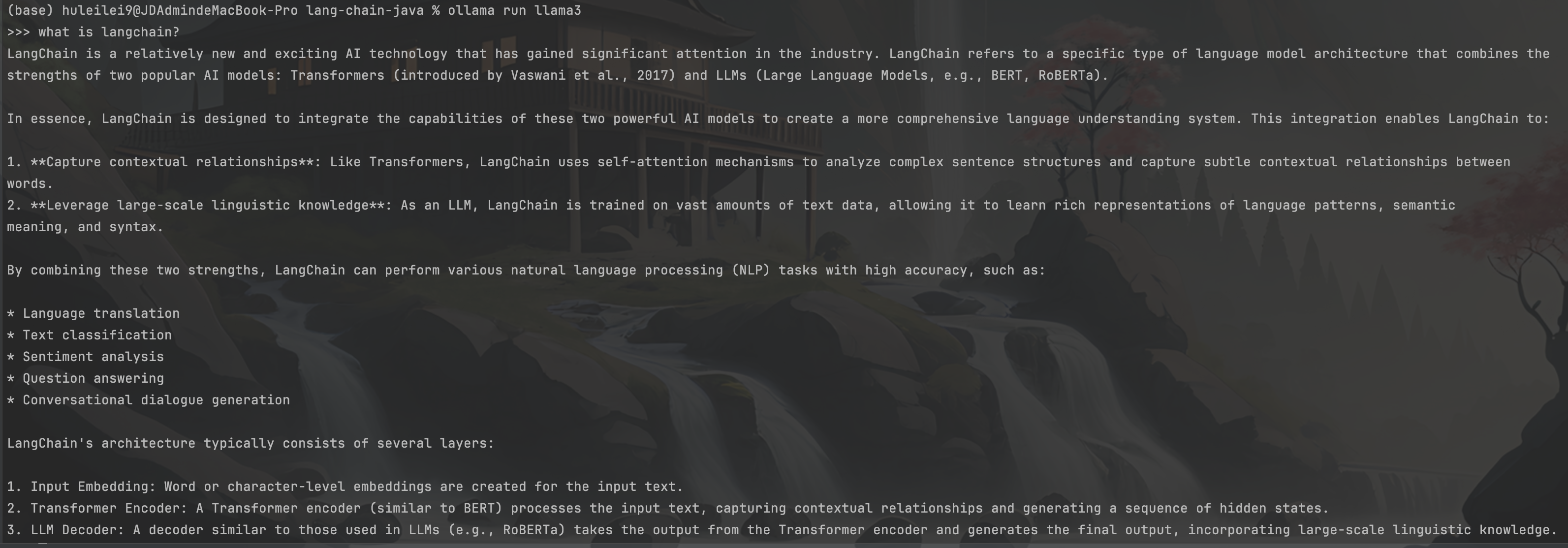
确认下载完成后,用命令行 :ollma run 模型名称,来启动大模型;启动后,可以立即输入内容与大模型进行对话,如下:
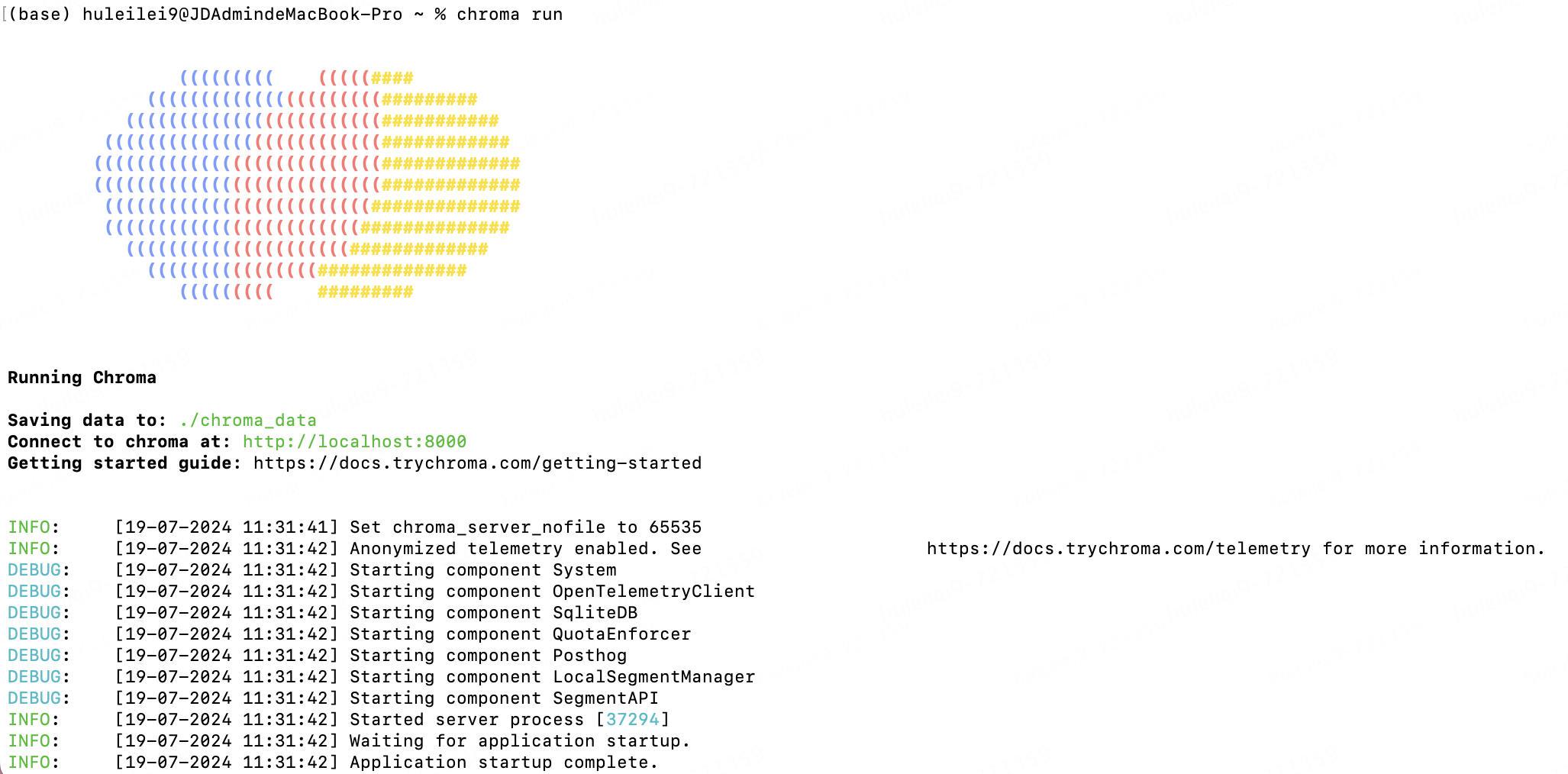
(二)启动 本地向量数据库 chromadb
Chroma 是一款 AI 原生开源矢量数据库,它内置了入门所需的一切,可在本地运行,是一款很好的入门级向量数据库。
用java 实现 本地AI问答功能
(一)核心maven依赖:
<properties><maven.compiler.source>8</maven.compiler.source><maven.compiler.target>8</maven.compiler.target><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding><langchain4j.version>0.31.0</langchain4j.version>
</properties><dependencies><!-- langchain4j --><dependency><groupId>dev.langchain4j</groupId><artifactId>langchain4j-core</artifactId><version>${langchain4j.version}</version></dependency><dependency><groupId>dev.langchain4j</groupId><artifactId>langchain4j</artifactId><version>${langchain4j.version}</version></dependency><dependency><groupId>dev.langchain4j</groupId><artifactId>langchain4j-open-ai</artifactId><version>${langchain4j.version}</version></dependency><dependency><groupId>dev.langchain4j</groupId><artifactId>langchain4j-embeddings</artifactId><version>${langchain4j.version}</version></dependency><dependency><groupId>dev.langchain4j</groupId><artifactId>langchain4j-chroma</artifactId><version>${langchain4j.version}</version></dependency><!-- ollama --><dependency><groupId>dev.langchain4j</groupId><artifactId>langchain4j-ollama</artifactId><version>${langchain4j.version}</version></dependency>