四足机器人的运动控制方法研究
1.传统运动控制
- 基于模型的控制方法
目前,在四足机器人研究领域内应用最广泛的控制方法就是基于模型的控制方法,其中主要包括基于虚拟模型控制(Virtual Model Control,VMC)方法 、基于零力矩点(Zero Moment Point,ZMP) 的控制方法、弹簧负载倒立摆算法(Spring Loaded Inverted Pendulum,SLIP) 等。这些控制方法的控制流程大同小异,首先都是要建立四足机器人的动力学模型,通过复杂且繁琐的数学推导,最后得出四足机器人足端落点的期望值。这些方法均需要科研人员熟悉并精通四足机器人的运动学模型方法,而且需要研究人员手动调整参数来进行控制,其控制过程极其繁琐。
- 基于中枢模式发生器
基于中枢模式发生器(Central Pattern Generator,CPG)控制方法,其灵感来自于生物学领域 。在各类高等动物的脊髓中,都普遍存在中枢模式发生器。从生物学的意义上讲,恰恰就是脊髓里面的中枢模式发生器控制着动物的各种节律,中枢模式发生器会形成各种周期性的刺激信号,这些生物学信号控制着所对应肌肉的节律性收缩。基于此,日本的 Kimura 科研团队提出了该方法,即构造多个振荡器函数,通过这些函数来生成周期性的关节运动轨迹,进而通过运动学建模反解出关节角度等信息,最终实现四足机器人的运动控制
- 基于模型预测的控制方法
基于模型预测的控制(Model Predictive Control,MPC) 方法是一种较为传统的运动控制方法
这种控制方法通过预测未来一段时间内的动态模型,进而对当下时刻的控制方法进行优化。具体而言,该方法首先获取四足机器人机身上的各种传感器所感受到的信息,然后将这些状态信息数字化处理,然后将其转换成一个在数学上的求解最优值的问题,之后将解出来的结果反馈给四足机器人,最后在下一个时间采样点再进行上面的循环。
2.基于强化学习的运动控制方法
DRL 深度强化学习
该方法使用近端策略优化(Proximal Policy Optimization,PPO)强化学习算法训练四足仿生机器人的运动,包括基本的前行、跑步和各种高难度的杂技动作。
3.马尔科夫决策过程
(Markov Decesion Process MDP)
马尔可夫过程可以将强化学习中的策略更新学习以及与环境变量之间的交互过程用数学概率模型的方式表示出来。
MDP 由四个要素组成,分别为“S,A,R,P”。其中,符号 S 表示状态、符号 A 表示动作、符号 R 表示奖励反馈,符号 P 表示状
态转移矩阵。
4.深度强化学习
Deep reinforcement Learning (DRL)深度强化学习
5.DH参数法
6.PPO
PPO(Proximal Policy Optimization)近端策略优化算法是一种在强化学习领
域广泛使用的算法
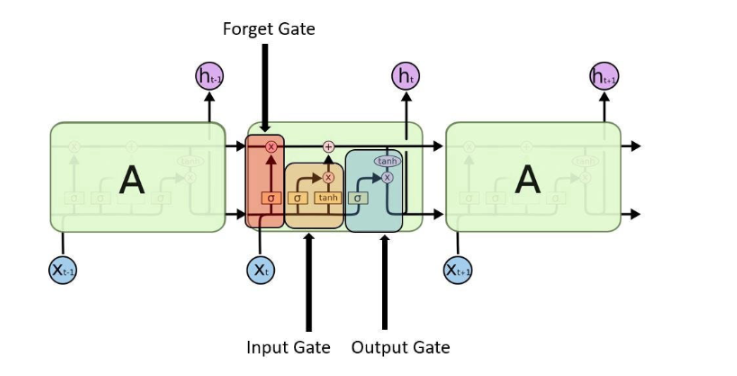
7.LSTM
8.DDPG和SAC
- DDPG(Deep Deterministic Policy Gradient)是一种结合了策略梯度和函数逼近技术的深度强化学习算法
- SAC(Soft Actor-Critic)是一种基于 Actor-Critic 框架的深度强化学习算法,专为解决连续动作空间的问题所设计
9.URDF
采用 URDF(Unified Robot Description Format)格式文件来构建机器人模型



![电影《749局》迅雷BT下载/百度云下载资源[MP4/2.12GB/5.35GB]超清版](https://img2024.cnblogs.com/blog/3514446/202410/3514446-20241001142111253-1293388443.jpg)
![电影《749局》迅雷百度云下载资源4K分享[1.16GB/2.72GBMKV]高清加长版【1280P已完结】](https://img2024.cnblogs.com/blog/3514446/202410/3514446-20241001142336788-1614095886.jpg)


![[rCore学习笔记 028] Rust 中的动态内存分配](https://img2024.cnblogs.com/blog/3071041/202410/3071041-20241001133558797-252701878.png)



