 算法学习心得,源码均为Python实现
算法学习心得,源码均为Python实现目录
- 绪论
- 数据结构
- 算法
- 算法的特征
- 算法的评价
- 算法的时间复杂度
- 算法的空间复杂度
- 递归
- 汉诺塔问题(递归调用)
- 查找排序
- 二分查找
- 检查排序是否完成
- 冒泡排序
- 选择排序
- 插入排序
- 希尔排序(高级版插入排序)
- 快速排序
- 堆排序(二叉树)
- python中内置好的堆排序函数
- 利用堆排序解决topk问题
- 归并排序
- 六种排序方法的总结
- 计数排序
- 桶排序(高级版计数排序)
- 基数排序
- 数据结构
- 线性表
- 列表(即顺序表)
- 栈(后进先出)
- 顺序栈
- 链式栈
- 栈的应用
- 迷宫问题(找的不一定是最短路径)
- 十进制转化为其他进制
- 队列(先进先出)
- 顺序队列
- 基础队列类
- 循环队列类
- 内置队列
- 链式队列
- 队列的应用
- 迷宫问题(求的是最短路径)
- 顺序队列
- 链表
- 单链表
- 单链表的创建
- 双链表
- 双链表的创建
- 链表与数组的差别
- 单链表
- 哈希表
- 哈希表(开辟的一系列连续的地址即数组)
- 哈希函数(计算输入的值在哈希表中对应下标的函数)
- 哈希冲突(对于不同的输入哈希函数输出的结果可能相同)
- 树和二叉树
- 基本概念
- 二叉树(度为2的树)
- 二叉树的性质
- 完全二叉树
- 满二叉树
- 存储方式
- 二叉树的创建
- 层次按序创建
- 函数前序创建
- 二叉树的遍历
- 递归遍历代码
- 非递归遍历代码
- 哈夫曼树
- 哈夫曼编码
- 代码
- 二叉搜索树
- 基本操作
- 代码
- AVL树(平衡二叉搜索树)
- 二分递归代码
- 树和森林
- 基本概念
- 性质
- 存储
- 二叉树的转换
- 树和森林的转换
- 树的遍历
- 森林的遍历
- KMP匹配算法
- 图
- 基本概念
- 图的定义
- 图的相关概念
- 图的相关性质
- 邻接矩阵
- 邻接矩阵的实现
- 邻接矩阵的优劣
- 邻接表
- 邻接表的实现
- 特点
- 库的调用
- 图的遍历
- 深度优先遍历
- 广度优先遍历
- BFS与DFS算法比较
- 最小生成树
- Prim算法
- Kruskal算法
- 算法比较
- 最短路径
- 迪杰斯特拉算法
- 弗洛伊德算法
- AOV网
- 拓扑排序
- AOE网
- 关键路径
- 基本概念
- 贪心算法
- 找零问题
- 代码
- 分数背包问题
- 代码
- 拼接最大数字问题
- 代码
- 活动选择问题
- 代码
- 找零问题
- 动态规划(DP算法)
- 钢管切割问题
- 代码
- 最长公共子序列问题
- 代码
- 钢管切割问题
- 欧几里得算法(求最大公约数)
- 应用
- RSA加密算法
- 面向对象
- 设计模式
- 创建型模式
- 简单工厂模式
- 工厂方法模式
- 抽象工厂模式
- 建造者模式
- 单例模式
- 小结
- 结构型模式
- 适配器模式
- 桥模式
- 组合模式
- 外观模式
- 代理模式
- 行为型模式
- 责任链模式
- 观察者模式
- 模板方法模式
- 策略模式
- 创建型模式
绪论
数据结构
数据的两种结构逻辑结构和存储结构(物理结构)
- 逻辑结构
- 线性结构
- 线性表
- 队列
- 栈
- 非线性结构
- 树形结构
- 图状结构
- 集合结构
- 线性结构
- 存储结构
- 顺序存储结构
- 链式存储结构
算法
算法是解决某一特定问题的指定描述
算法的特征
- 有穷性
- 确定性(唯一性)
- 可行性
- 输入
- 输出
算法的评价
- 正确性
- 可读性
- 健壮性
- 效率和低存储
算法的时间复杂度
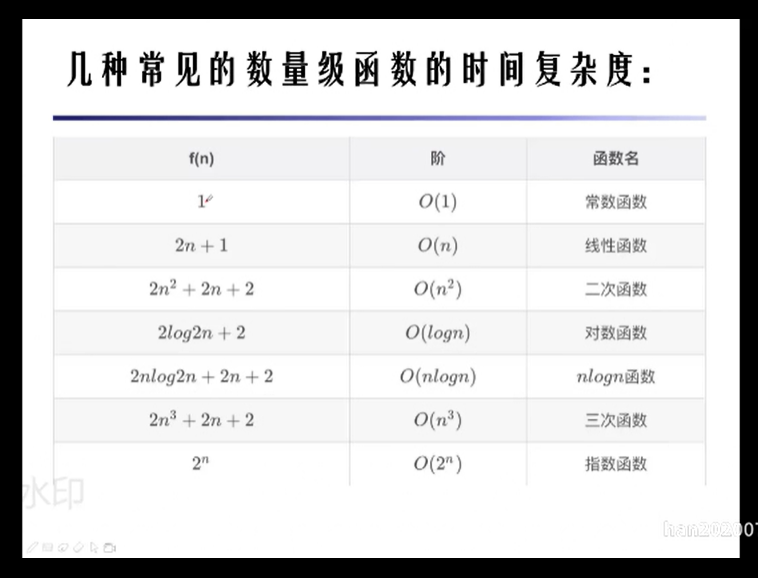
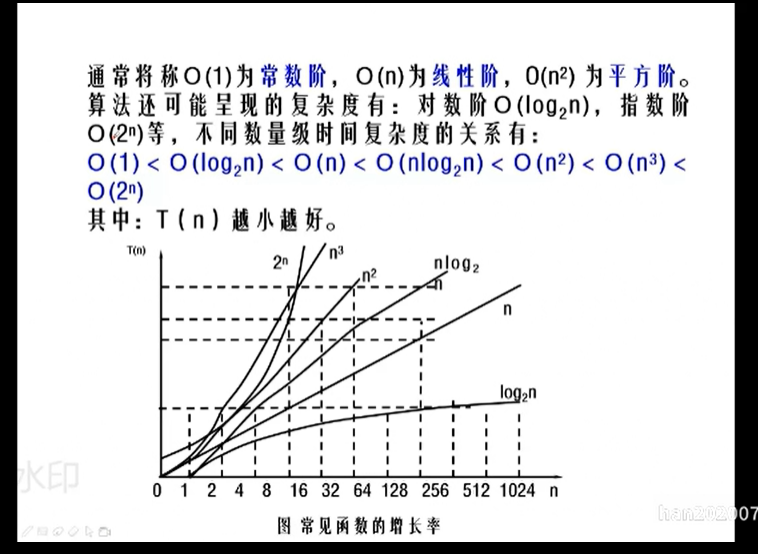
算法的空间复杂度
和时间复杂度相比不那么重要,一般算法采取的措施为用空间换时间,即用一部分的空间消耗来缩短计算时间。
递归
汉诺塔问题(递归调用)
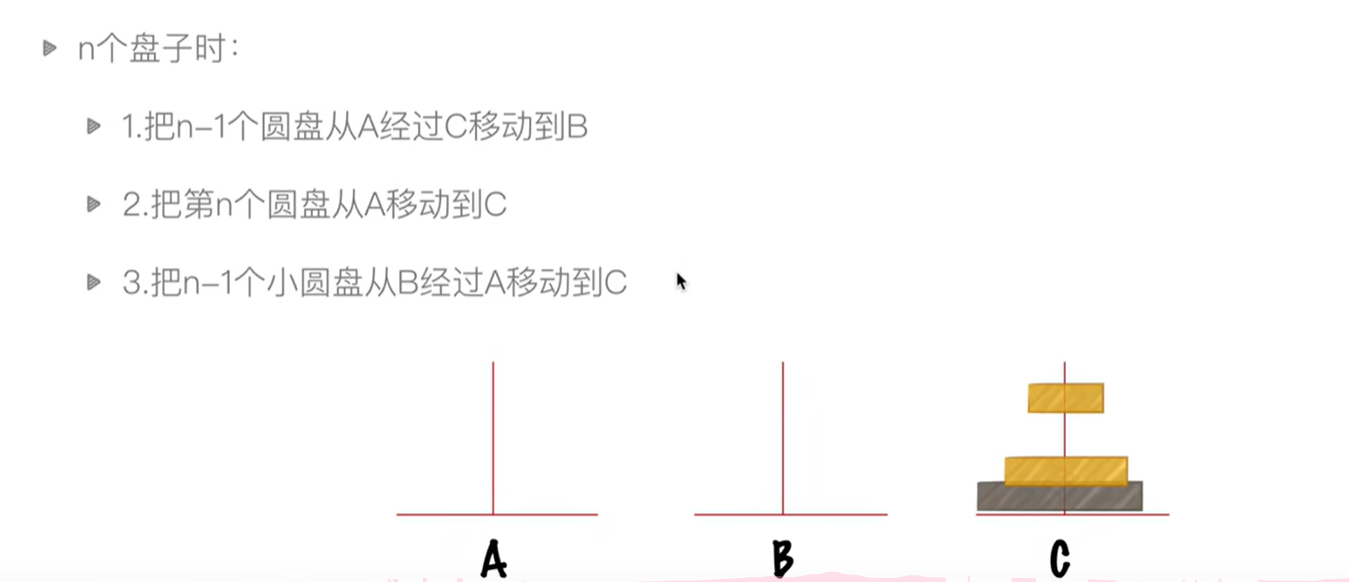
# 汉诺塔算法
def HanNoTa(n, a, b, c):if n > 0:HanNoTa(n - 1, a, c, b)print(f"moving form {a} to {c}")HanNoTa(n - 1, b, a, c)HanNoTa(3,"A","B","C")
查找排序
二分查找
# 二分查找
def binary_search(li, val, key=1):list_li = list(zip(list(range(len(li))), li))if key == 1:list_li = sorted(list_li, key=lambda x: x[1])left = 0right = len(list_li) - 1while left <= right:mid = (left + right) // 2if list_li[mid][1] == val:return list_li[mid][0]elif list_li[mid][1] > val:right = mid - 1else:left = mid + 1else:return Nonea = [1, 5, 6, 2, 1, 4, 2, 6, 2, 3]
b = [1, 2, 3, 4, 5, 6, 7, 8]
ind = binary_search(a, 3)
print(ind)
ind = binary_search(b, 5, 0)
print(ind)
检查排序是否完成
def check(li, reverse=False):if reverse == False:for i in range(len(li) - 1):if li[i] > li[i + 1]:return Falseelse:return Trueelif reverse == True:for i in range(len(li) - 1):if li[i] < li[i + 1]:return Falseelse:return True
冒泡排序
# 冒泡排序
import randomdef bubble_sort(li: list):for i in range(len(li) - 1):exchange = Falsefor j in range(len(li) - i - 1):if li[j] > li[j + 1]:li[j], li[j + 1] = li[j + 1], li[j]exchange = Trueif not exchange:returnli = [random.randint(0, 10000) for _ in range(10)]
print(li)
bubble_sort(li)
print(li)
选择排序
# 选择排序
import randomdef select_sort(li):for i in range(len(li) - 1):min_loc = ifor j in range(i + 1, len(li)):if li[j] < li[min_loc]:min_loc = jif min_loc != i:li[i], li[min_loc] = li[min_loc], li[i]li = [random.randint(0, 10000) for _ in range(10)]
print(li)
select_sort(li)
print(li)
插入排序
# 插入排序
import randomdef insert_sort(li):for i in range(1, len(li)):tmp = li[i]j = i - 1while j >= 0 and tmp < li[j]:li[j + 1] = li[j]j -= 1li[j + 1] = tmpli = [random.randint(0, 10000) for _ in range(10)]
print(li)
insert_sort(li)
print(li)
希尔排序(高级版插入排序)
# 希尔排序
import random
import copy
import timedef insert_sort_gap(li, gap):for i in range(gap, len(li)):tmp = li[i]j = i - gapwhile j >= 0 and tmp < li[j]:li[j + gap] = li[j]j -= gapli[j + gap] = tmpdef shell_sort(li):d = len(li) // 2while d >= 1:insert_sort_gap(li, d)d //= 2li = list(range(10000))
random.shuffle(li)
li1 = copy.deepcopy(li)
print(li)
print(li1)
start = time.time()
shell_sort(li)
end = time.time()
print(end - start)
print(li1)
start = time.time()
insert_sort_gap(li1, 1)
end = time.time()
print(end - start)
print(li)
print(li1)
快速排序
# 快速排序
import random
import time
# import sys
# sys.setrecursionlimit(100000) # 设置递归最大深度def partition(li, left, right):tmp = li[left] # 记录下最左边的数while left < right: # 找到记录下的数的最合适的位置while left < right and li[right] >= tmp: # 从右边找比tmp小的数的位置right -= 1li[left] = li[right] # 把右边较大的值写到左边的位置上while left < right and li[left] <= tmp: # 从左边找比tmp大的数的位置left += 1li[right] = li[left] # 把左边较小的值写到右边的位置上li[left] = tmp # 把记录下的数写到合适的位置return left # 返回找到的位置def _quick_sort(li, left, right): # 递归调用if left < right: # 至少两个元素才进行递归调用mid = partition(li, left, right)_quick_sort(li, left, mid - 1)_quick_sort(li, mid + 1, right)def quick_sort(li):_quick_sort(li, 0, len(li) - 1)li = [random.randint(0, 10000) for _ in range(10000)]
print(li)
start = time.time()
quick_sort(li)
end = time.time()
print(li)
print(end - start)
堆排序(二叉树)
# 堆排序
import random
import time
def sift(li, low, high):""":param li:列表:param low: 堆的根节点的位置:param high: 堆的最后一个元素的位置:return: None"""i = low # 最开始指向根节点j = 2 * i + 1 # j为根节点的左孩子tmp = li[low] # 把堆顶元素存起来while j <= high: # 建立大根堆if j + 1 <= high and li[j + 1] > li[j]: # 如果右孩子存在并且比左孩子大j = j + 1 # j指向右孩子if li[j] > tmp: # 如果孩子节点大于父亲节点li[i] = li[j] # 孩子节点元素调整到父亲节点的位置i = j # 指针下移j = 2 * i + 1else: # 因为tmp比孩子节点更大,找到合适的位置li[i] = tmp # 找到根节点合适的位置并放入breakelse:li[i] = tmp # 把tmp放到叶子节点上def heap_sort(li):n = len(li)for i in range((n - 2) // 2, -1, -1):# i表示建堆的时候调整的部分的根的下标sift(li, i, n - 1)# 建堆完成for i in range(n - 1, -1, -1):# i指向当前堆的最后一个元素li[0], li[i] = li[i], li[0] # 将最后一个元素与堆顶元素交换位置sift(li, 0, i - 1) # i-1是新的highli = [random.randint(0, 10000) for _ in range(10000)]
print(li)
start = time.time()
heap_sort(li)
end = time.time()
print(li)
print(end - start)
python中内置好的堆排序函数
# python中内置好的堆排序
import heapq
import randomli = [i for i in range(100)]
random.shuffle(li) # 打乱列表
print(li)
heapq.heapify(li) # 建堆
for i in range(len(li)):print(heapq.heappop(li), end=",") # 弹出一个堆中最小的元素
利用堆排序解决topk问题
# 利用堆排序解决topk问题
import random
import timedef sift(li, low, high):""":param li:列表:param low: 堆的根节点的位置:param high: 堆的最后一个元素的位置:return: None"""i = low # 最开始指向根节点j = 2 * i + 1 # j为根节点的左孩子tmp = li[low] # 把堆顶元素存起来while j <= high: # 建立小根堆if j + 1 <= high and li[j + 1] < li[j]: # 如果右孩子存在并且比左孩子小j = j + 1 # j指向右孩子if li[j] < tmp: # 如果孩子节点小于父亲节点li[i] = li[j] # 孩子节点元素调整到父亲节点的位置i = j # 指针下移j = 2 * i + 1else: # 因为tmp比孩子节点更小,找到合适的位置li[i] = tmp # 找到根节点合适的位置并放入breakelse:li[i] = tmp # 把tmp放到叶子节点上def topk(li, k):heap = li[0:k]for i in range((k - 2) // 2, -1, -1): # 建立小根堆sift(heap, i, k - 1)for i in range(k, len(li) - 1): # 遍历if li[i] > heap[0]:heap[0] = li[i]sift(heap, 0, k - 1)for i in range(k - 1, -1, -1): # 对结果排序heap[0], heap[i] = heap[i], heap[0]sift(heap, 0, i - 1)return heapli = [i for i in range(10000)]
random.shuffle(li)
print(topk(li, 10))
归并排序
# 归并排序
import randomdef merge(li, low, mid, high): # 对列表中mid左右两边的子列表进行排序i = lowj = mid + 1ltmp = []while i <= mid and j <= high: # 左右两个子列表都有数if li[i] < li[j]:ltmp.append(li[i])i += 1else:ltmp.append(li[j])j += 1while i <= mid:ltmp.append(li[i])i += 1while j <= high:ltmp.append(li[j])j += 1li[low:high + 1] = ltmpdef _merge_sort(li, low, high):if low < high: # 至少有两个元素,递归mid = (low + high) // 2_merge_sort(li, low, mid)_merge_sort(li, mid + 1, high)merge(li, low, mid, high)def merge_sort(li):_merge_sort(li, 0, len(li) - 1)li = [i for i in range(1000)]
random.shuffle(li)
print(li)
merge_sort(li)
print(li)
六种排序方法的总结
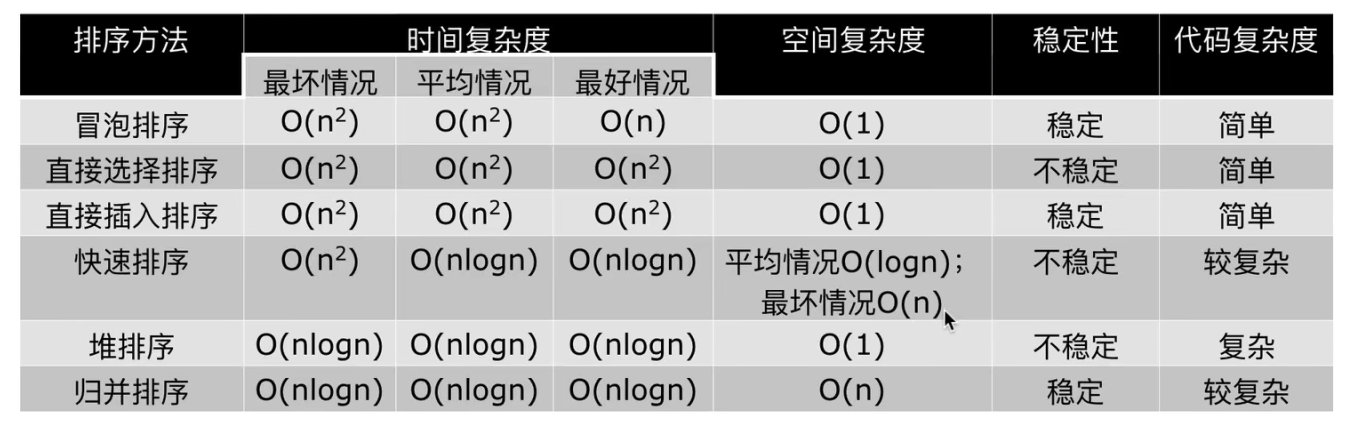
计数排序
# 计数排序
import randomdef count_sort(li: list):count = [0 for _ in range(min(li), max(li) + 1)]min_num = min(li)for val in li:count[val - min_num] += 1li.clear()for ind, val in enumerate(count):for i in range(val):li.append(ind + min_num)li = list(range(-9, 21))
random.shuffle(li)
print(li)
count_sort(li)
print(li)
桶排序(高级版计数排序)
# 桶排序
import randomdef bucket_sort(li: list):max_num = max(li)n = max_num // 100if n == 0:n = 1buckets = [[]]else:buckets = [[] for _ in range(n)]for var in li:i = min(var // (max_num // n), n - 1) # i表示var放到几号桶里buckets[i].append(var)for j in range(len(buckets[i]) - 1, 0, -1): # 保持桶内的顺序if buckets[i][j] < buckets[i][j - 1]:buckets[i][j], buckets[i][j - 1] = buckets[i][j - 1], buckets[i][j]else:breakli.clear()for buc in buckets:li.extend(buc)return lili = list(range(200))
li1 = list(range(200))
random.shuffle(li)
print(li == li1)
bucket_sort(li)
print(li)
print(li == li1)
基数排序
# 基数排序
import randomdef radix_sort(li: list):max_num = max(li)it = 0while 10 ** it <= max_num: # 求最大数的位数buckets = [[] for _ in range(10)] # 创建桶for var in li: # 把数放入桶中digit = (var // 10 ** it) % 10 # 依次取每个数的位数buckets[digit].append(var)li.clear()for buc in buckets:li.extend(buc)it += 1li = [random.randint(0, 10000) for _ in range(1000)]
print(li)
radix_sort(li)
print(li)
print(check(li))
数据结构
线性表
- 顺序表
- 链表
列表(即顺序表)
- 列表内的每个节点储存的元素为地址,所以列表内部可以时任意数据类型
- 列表是动态分配存储空间,列表长度不够的时候,python底层会为列表重新开辟一个更大的空间,并把原先列表中存储的地址复制到新开辟的空间中
栈(后进先出)
顺序栈
列表(li)结构可以实现栈
- 进栈:li.append
- 出栈:li.pop
- 取栈顶:li[-1]
class Stack:def __init__(self):self.stack = []def push(self, element):self.stack.append(element)def pop(self):if len(self.stack) > 0:return self.stack.pop()else:return Nonedef get_pop(self):if len(self.stack) > 0:return self.stack[-1]else:return Nonedef is_empty(self):return len(self.stack) == 0stack = Stack()
stack.push(1)
stack.push(2)
stack.push(3)
print(stack.pop())
print(stack.pop())
print(stack.is_empty())
print(stack.pop())
print(stack.is_empty())
print(stack.pop())
链式栈
class stack_linked():def __init__(self, Node=None):self.head = Nodedef create(self, val):if not self.head:self.head = ListNode(val)def push(self, val):if not self.head:self.head = ListNode(val)returnnode = ListNode(val)node.next = self.headself.head = nodedef pop(self):val = self.headself.head = self.head.nextreturn valstack = stack_linked()
stack.push(5)
stack.push(6)
print(stack.pop().val)
print(stack.head.val)
栈的应用
迷宫问题(找的不一定是最短路径)
map = [[1, 1, 1, 1, 1, 1, 1, 1, 1, 1],[1, 0, 0, 1, 0, 0, 0, 1, 0, 1],[1, 0, 0, 1, 0, 0, 0, 1, 0, 1],[1, 0, 0, 0, 0, 1, 1, 0, 0, 1],[1, 0, 1, 1, 1, 0, 0, 0, 0, 1],[1, 0, 0, 0, 1, 0, 0, 0, 0, 1],[1, 0, 1, 0, 0, 0, 1, 0, 0, 1],[1, 0, 1, 1, 1, 0, 1, 1, 0, 1],[1, 1, 0, 0, 0, 0, 0, 0, 0, 1],[1, 1, 1, 1, 1, 1, 1, 1, 1, 1]
]
dirs = [lambda x, y: (x + 1, y),lambda x, y: (x, y + 1),lambda x, y: (x - 1, y),lambda x, y: (x, y - 1)
]def map_path(x1, y1, x2, y2):stack = []stack.append((x1, y1))map[x1][y1]=2while len(stack) > 0:curNode = stack[-1]if curNode[0] == x2 and curNode[1] == y2:for p in stack:print(p)return Truefor dir in dirs:nextNode = dir(curNode[0], curNode[1])if map[nextNode[0]][nextNode[1]] == 0:stack.append(nextNode)map[nextNode[0]][nextNode[1]] = 2breakelse:map[nextNode[0]][nextNode[1]] = 2stack.pop()else:print("没有路")return Falsemap_path(1, 1, 8, 8)
for i in map:print(i)
十进制转化为其他进制
# 十进制转化为其他进制
def base_conversion(val, base):li = []while val != 0:li.append(val % base)val = val // baseli.reverse()s = ''.join(map(str,li))return sprint(base_conversion(120, 2))
队列(先进先出)
列表(li)可以实现队列
- 入队:li.append
- 出队:li.pop(0)
- 取队头:li[0]
顺序队列
基础队列类
class Queue:def __init__(self):self.queue = []def push(self, element):self.queue.append(element)def is_empty(self):return len(self.queue) == 0def pop(self):if not self.is_empty():return self.queue.pop(0)else:return Nonedef get_top(self):return self.queue[0]queue = Queue()
queue.push(1)
queue.push(2)
queue.push(3)
print(queue.is_empty())
print(queue.pop())
print(queue.get_top())
print(queue.pop())
print(queue.pop())
print(queue.pop())
print(queue.is_empty())
循环队列类
class Queue:def __init__(self, size=100):self.queue = [0 for _ in range(size)]self.size = sizeself.rear = 0self.front = 0def push(self, element):if not self.is_filled():self.rear = (self.rear + 1) % self.sizeself.queue[self.rear] = elementelse:raise IndexError("Queue is filled")def pop(self):if not self.is_empty():self.front = (self.front + 1) % self.sizereturn self.queue[self.front]raise IndexError("Queue is empty")def get_top(self):if not self.is_empty():return self.queue[self.rear]else:return Nonedef is_empty(self):return self.rear == self.frontdef is_filled(self):return (self.rear + 1) % self.size == self.frontqueue=Queue(5)
print(queue.is_empty())
queue.push(1)
queue.push(2)
queue.push(3)
queue.push(4)
print(queue.is_filled())
print(queue.get_top())
print(queue.pop())
print(queue.pop())
print(queue.pop())
print(queue.pop())
print(queue.pop())
内置队列
from collections import deque # 双向队列q = deque([1, 2, 3, 4], 4)
q.append(5) # 队尾进
print(q.popleft()) # 队首出q.clear()
q.appendleft(1) # 队首进
q.appendleft(2)
q.appendleft(3)
print(q.pop()) # 队尾出
print(q.pop())
print(q.pop())
链式队列
class Node():def __init__(self, val=0):self.val = valself.next = Noneclass queue_linked():def __init__(self):self.front = Noneself.rear = Nonedef push(self, val):node = Node(val)if self.front is None:self.front = nodeself.rear = nodeelse:self.rear.next = nodeself.rear = self.rear.nextdef pop(self):if self.front == self.rear and self.front:node = self.frontself.front = self.rear = Nonereturn nodeelse:if not self.front:returnnode = self.frontself.front = self.front.nextreturn nodedef peek(self):if not self.is_empty():return self.front.valelse:returndef is_empty(self):if self.front and self.rear:return Falseelse:return Truedef show(self):p = self.frontwhile p:print(p.val, end=" ")p = p.nextprint()queue = queue_linked()
queue.push(1)
queue.push(2)
queue.push(3)
print(queue.pop().val)
print(queue.pop().val)
print(queue.pop().val)
# print(queue.peek())
queue.show()
队列的应用
迷宫问题(求的是最短路径)
map = [[1, 1, 1, 1, 1, 1, 1, 1, 1, 1],[1, 0, 0, 1, 0, 0, 0, 1, 0, 1],[1, 0, 0, 1, 0, 0, 0, 1, 0, 1],[1, 0, 0, 0, 0, 1, 1, 0, 0, 1],[1, 0, 1, 1, 1, 0, 0, 0, 0, 1],[1, 0, 0, 0, 1, 0, 0, 0, 0, 1],[1, 0, 1, 0, 0, 0, 1, 0, 0, 1],[1, 0, 1, 1, 1, 0, 1, 1, 0, 1],[1, 1, 0, 0, 0, 0, 0, 0, 0, 1],[1, 1, 1, 1, 1, 1, 1, 1, 1, 1]
]dirs = [lambda x, y: (x + 1, y),lambda x, y: (x, y + 1),lambda x, y: (x - 1, y),lambda x, y: (x, y - 1)
]def print_path(path, map):curNode = path[-1]realpath = []while curNode[2] != -1:realpath.append(curNode[0:2])map[curNode[0]][curNode[1]] = 2curNode = path[curNode[2]]realpath.append(curNode[0:2])map[curNode[0]][curNode[1]] = 2realpath.reverse()for node in realpath:print(node)from collections import deque
import copydef map_path_shortest(x1, y1, x2, y2, map):map1 = copy.deepcopy(map)queue = deque()queue.append((x1, y1, -1))path = []while len(queue) > 0:curNode = queue.popleft()path.append(curNode)if curNode[0] == x2 and curNode[1] == y2:print_path(path, map)return Truefor di in dirs:nextNode = di(curNode[0], curNode[1])if map1[nextNode[0]][nextNode[1]] == 0:queue.append((nextNode[0], nextNode[1], len(path) - 1))map1[nextNode[0]][nextNode[1]] = 2else:print("没有路")return Falsemap_path_shortest(1, 1, 8, 8, map)
for i in map:print(i)
链表
单链表
单链表的创建
class ListNode:def __init__(self, val=0, next=None):self.val = valself.next = nextclass LinkedList:class LinkListIterator:def __init__(self, node):self.node = nodedef __next__(self):if self.node:cur_node = self.nodeself.node = cur_node.nextreturn cur_node.valelse:raise StopIterationdef __iter__(self):return selfdef __init__(self, iterable=None):self.head = Noneself.tail = Noneif iterable:self.extend(iterable)def append(self, obj):s = ListNode(obj)if not self.head:self.head = sself.tail = selse:self.tail.next = sself.tail = sdef extend(self, iterable):for obj in iterable:self.append(obj)def find(self, obj):for n in self:if n == obj:return Trueelse:return Falsedef create(self, li: list):self.head = ListNode(li[0])self.tail = self.headfor element in li[1:]:node = ListNode(element)self.tail.next = nodeself.tail = nodereturn self.headdef create_head(self, li: list):self.head = ListNode(li[0])self.tail = self.headfor element in li[1:]:node = ListNode(element)node.next = self.headself.head = nodereturn self.headdef show(self):Node = self.headwhile Node != None:print(Node.val, end='\t')Node = Node.nextprint()def get_length(self):if self.head is None:return 0count = 1node = self.headwhile node != self.tail:count += 1node = node.nextreturn countdef get_value(self, index):""":type index: int:rtype: int"""if index < 0 or index >= self.get_length():return -1cur = self.head.nextwhile index:cur = cur.nextindex -= 1return cur.valdef get_index(self, value):count = 0cur = self.headwhile cur:if cur.val == value:breakcount += 1cur = cur.nextelse:return -1return countdef addAtIndex(self, index, val):""":type index: int:type val: int:rtype: None"""if index <= 0:node = ListNode(val)node.next = self.headself.head = nodereturnelif index >= self.get_length():self.tail.next = ListNode(val)self.tail = self.tail.nextreturnnode = ListNode(val)cur = self.headpre = Nonewhile index:pre = curcur = cur.nextindex -= 1node.next = pre.nextpre.next = nodedef deleteAtIndex(self, index):""":type index: int:rtype: None"""if index < 0 or index >= self.get_length():returnif index == 0:self.head = self.head.nextreturnpre = self.headwhile index > 1:pre = pre.nextindex -= 1pre.next = pre.next.nextdef deleteAtValue(self, value):""":type index: int:rtype: None"""if self.head.val == value:self.head = self.head.nextreturncur = self.headwhile cur.next:if cur.next.val == value:breakcur = cur.nextelse:returncur.next = cur.next.nextdef __iter__(self):return self.LinkListIterator(self.head)def __repr__(self):return "<<" + ",".join(map(str, self)) + ">>"li = LinkedList([1, 2, 3, 5, 6, 3])
li.show()
print(li.get_length())
print(li.get_index(6))
li.addAtIndex(7, 4)
li.show()
li.deleteAtValue(3)
li.show()
print(li.get_index(4))
class ListNode:def __init__(self, val=0, next=None):self.val = valself.next = nextclass MyLinkedList(object):def __init__(self):self.head = ListNode()self.size = 0 # 设置一个链表长度的属性,便于后续操作,注意每次增和删的时候都要更新def get(self, index):""":type index: int:rtype: int"""if index < 0 or index >= self.size:return -1cur = self.head.nextwhile (index):cur = cur.nextindex -= 1return cur.valdef addAtHead(self, val):""":type val: int:rtype: None"""new_node = ListNode(val)new_node.next = self.head.nextself.head.next = new_nodeself.size += 1def addAtTail(self, val):""":type val: int:rtype: None"""new_node = ListNode(val)cur = self.headwhile (cur.next):cur = cur.nextcur.next = new_nodeself.size += 1def addAtIndex(self, index, val):""":type index: int:type val: int:rtype: None"""if index < 0:self.addAtHead(val)returnelif index == self.size:self.addAtTail(val)returnelif index > self.size:returnnode = ListNode(val)pre = self.headwhile (index):pre = pre.nextindex -= 1node.next = pre.nextpre.next = nodeself.size += 1def deleteAtIndex(self, index):""":type index: int:rtype: None"""if index < 0 or index >= self.size:returnpre = self.headwhile (index):pre = pre.nextindex -= 1pre.next = pre.next.nextself.size -= 1
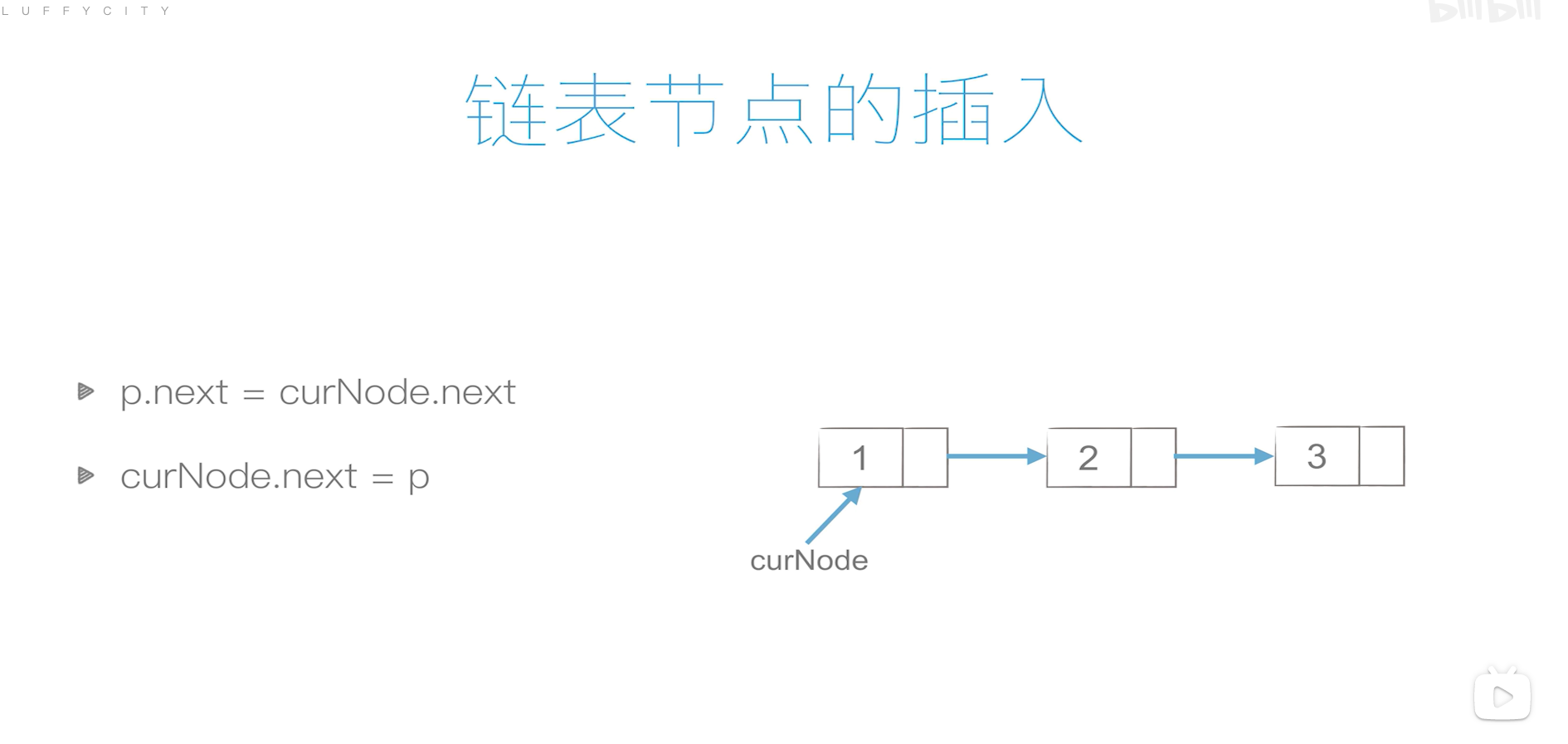
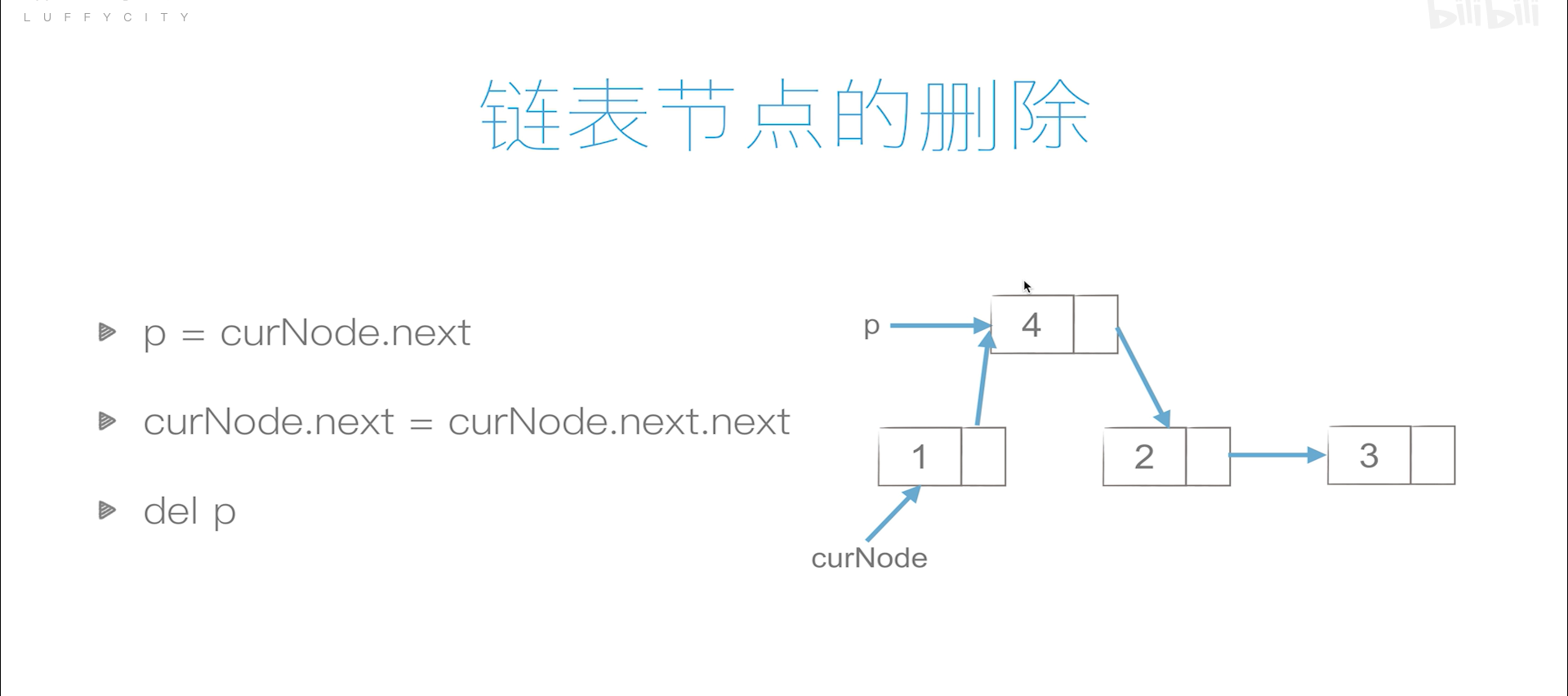
双链表
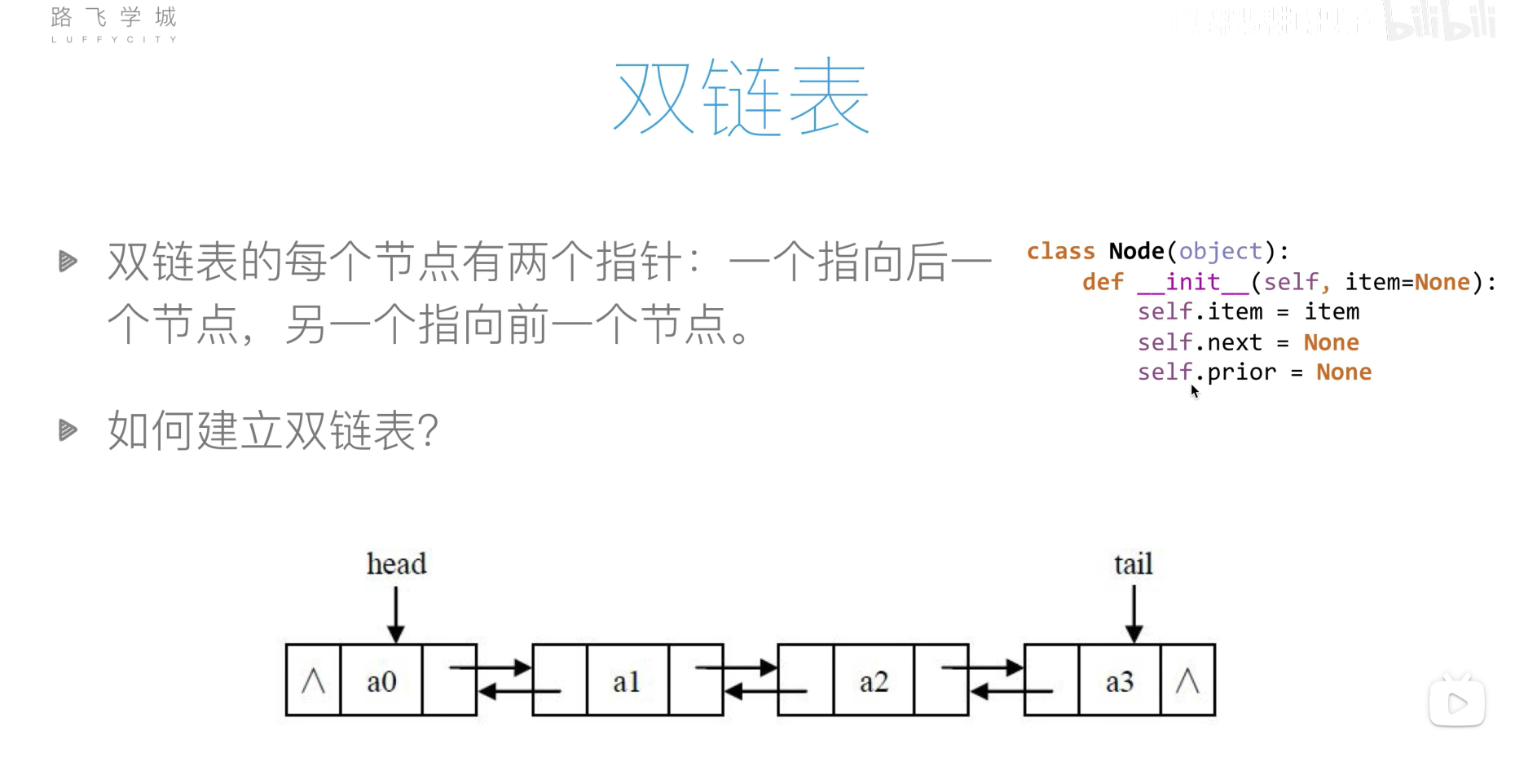
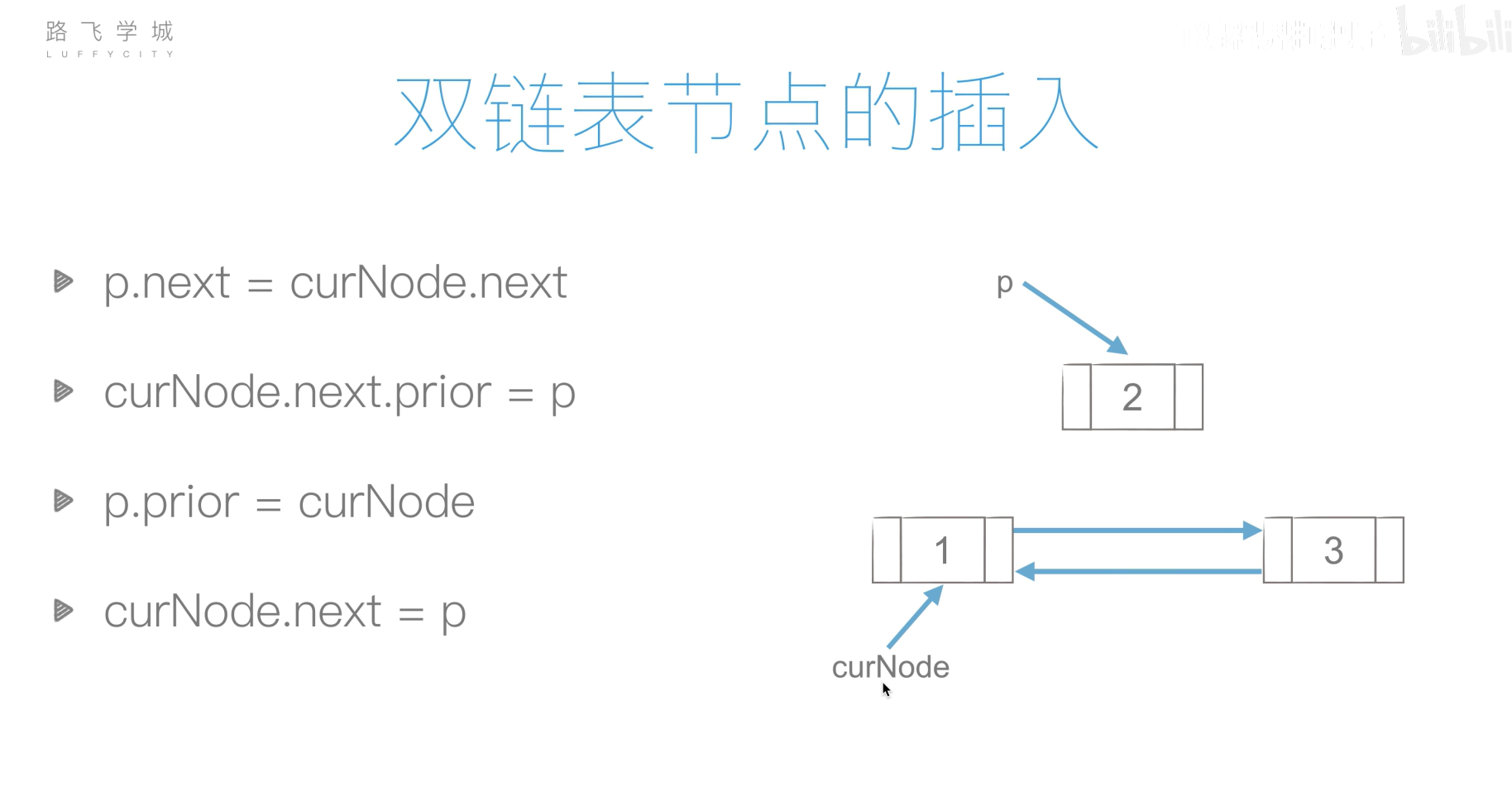
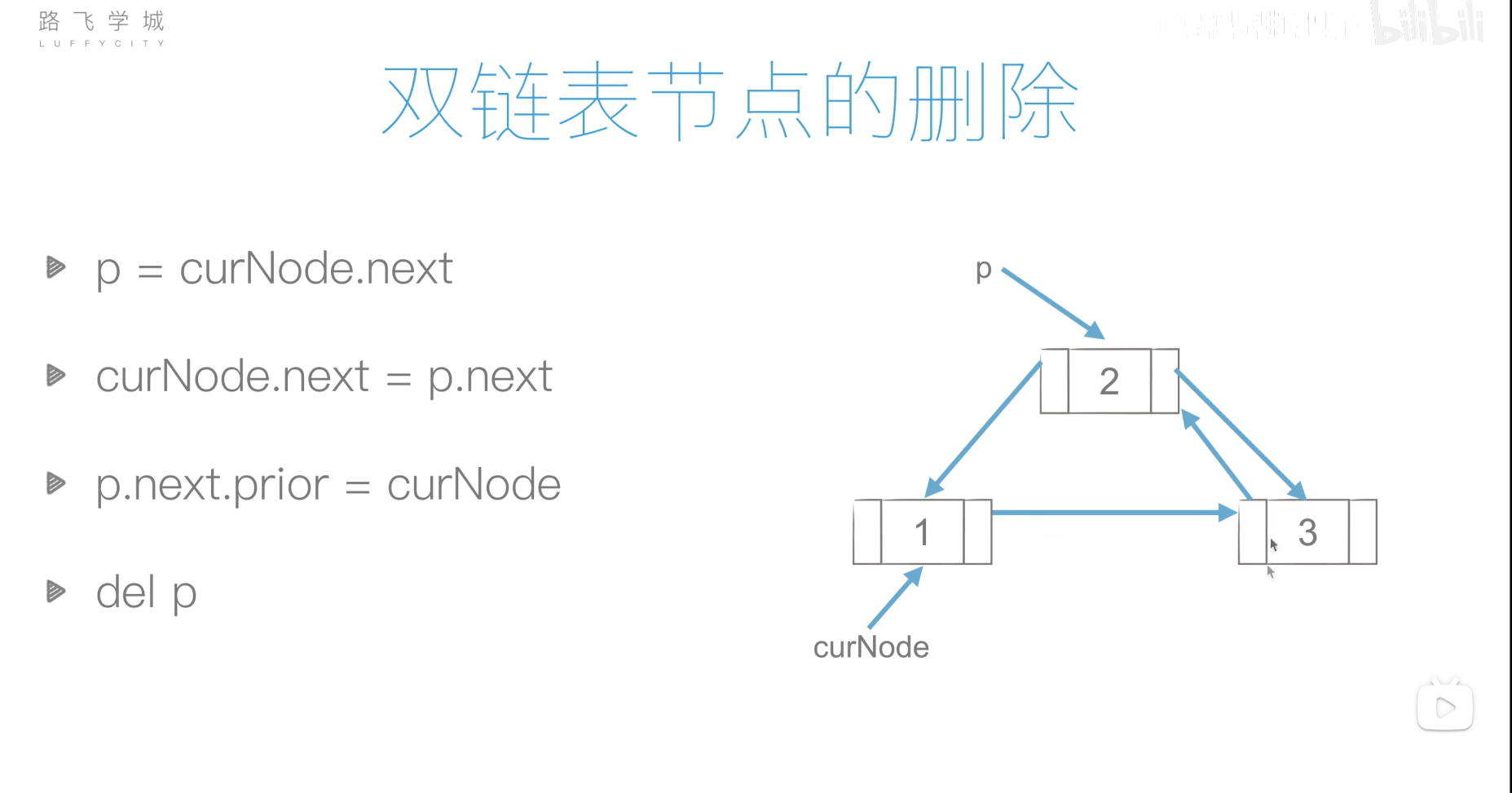
双链表的创建
class Node:def __init__(self, val):self.val = valself.prev = Noneself.next = Noneclass MyLinkedListDouble:def __init__(self):self._head, self._tail = Node(0), Node(0) # 虚拟节点self._head.next, self._tail.prev = self._tail, self._headself._count = 0 # 添加的节点数def _get_node(self, index: int) -> Node:# 当index小于_count//2时, 使用_head查找更快, 反之_tail更快if index >= self._count // 2:# 使用prev往前找node = self._tailfor _ in range(self._count - index):node = node.prevelse:# 使用next往后找node = self._headfor _ in range(index + 1):node = node.nextreturn nodedef get(self, index: int) -> int:"""Get the value of the index-th node in the linked list. If the index is invalid, return -1."""if 0 <= index < self._count:node = self._get_node(index)return node.valelse:return -1def addAtHead(self, val: int) -> None:"""Add a node of value val before the first element of the linked list.After the insertion, the new node will be the first node of the linked list."""self._update(self._head, self._head.next, val)def addAtTail(self, val: int) -> None:"""Append a node of value val to the last element of the linked list."""self._update(self._tail.prev, self._tail, val)def addAtIndex(self, index: int, val: int) -> None:"""Add a node of value val before the index-th node in the linked list.If index equals to the length of linked list, the node will be appended to the end of linked list.If index is greater than the length, the node will not be inserted."""if index < 0:index = 0elif index > self._count:returnnode = self._get_node(index)self._update(node.prev, node, val)def _update(self, prev: Node, next: Node, val: int) -> None:"""更新节点:param prev: 相对于更新的前一个节点:param next: 相对于更新的后一个节点:param val: 要添加的节点值"""# 计数累加self._count += 1node = Node(val)prev.next, next.prev = node, nodenode.prev, node.next = prev, nextdef deleteAtIndex(self, index: int) -> None:"""Delete the index-th node in the linked list, if the index is valid."""if 0 <= index < self._count:node = self._get_node(index)# 计数-1self._count -= 1node.prev.next, node.next.prev = node.next, node.prev
链表与数组的差别
- 链表
- 优点:插入删除操作较快,内存可以动态分配
- 缺点:查找操作较慢
- 数组
- 优点:结构简单,查找操作快
- 缺点:插入删除操作较慢,内存不能动态分配
哈希表
python中的集合,字典结构在底层都是用的哈希表来实现的
哈希表(开辟的一系列连续的地址即数组)
哈希函数(计算输入的值在哈希表中对应下标的函数)
哈希冲突(对于不同的输入哈希函数输出的结果可能相同)
- 解决哈希冲突的方法
- 线性探测法:如果地址冲突,那么它所存放的位置在哈希表中加一
- 二次探测法:利用二次函数,计算冲突时,应该存储的位置
- 拉链存储法:哈希表的每个节点存储的是链表
-
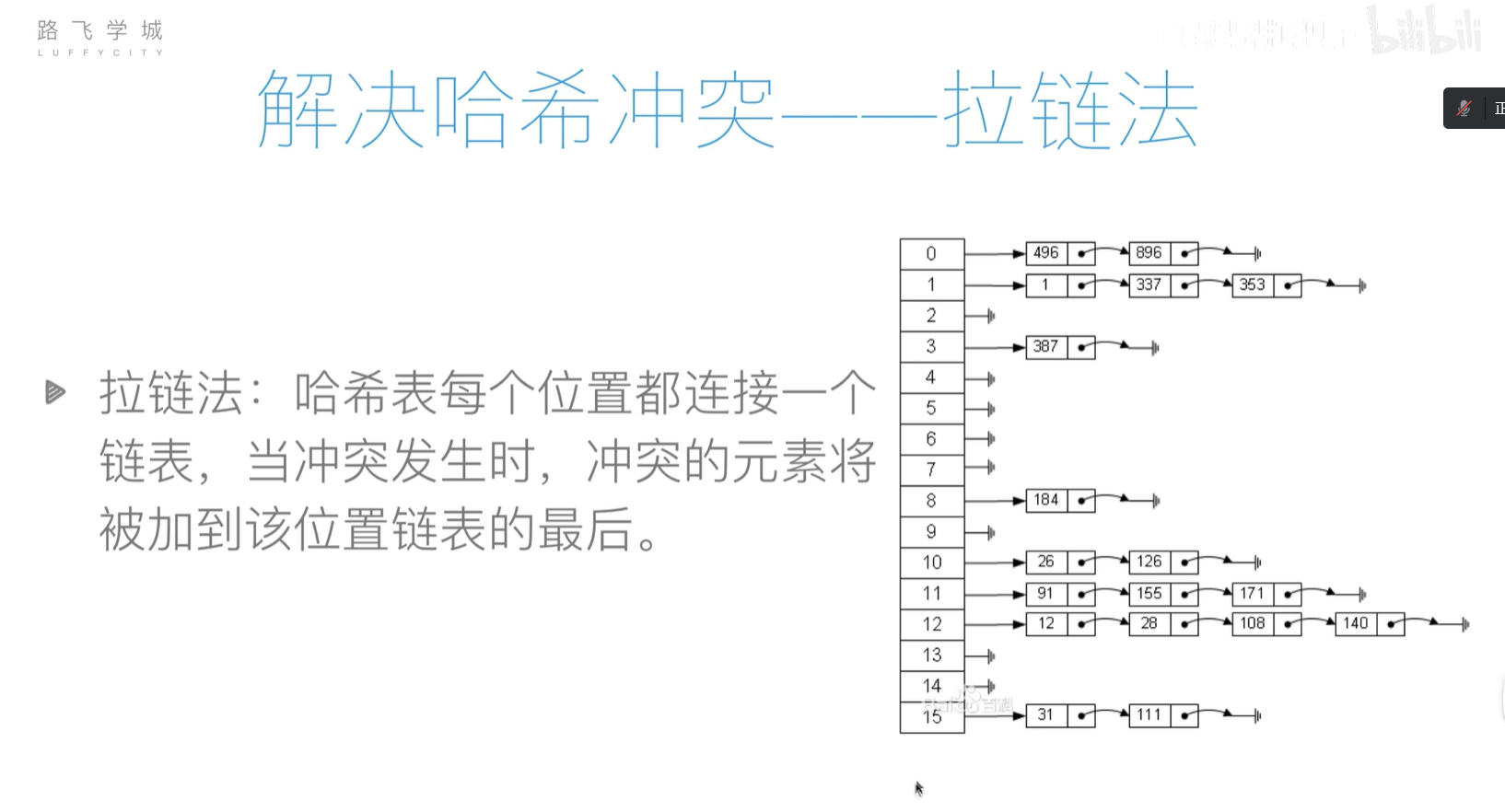
树和二叉树
基本概念
- 根节点
- 叶子节点
- 树的深度
- 节点的度
- 树的度
- 父亲节点
- 孩子节点(左孩子/右孩子)
- 子树
二叉树(度为2的树)
二叉树的性质
-
对于非空二叉树,如果叶子节点树为n0,度为2的节点数为n2,则有n0=n2+1
-
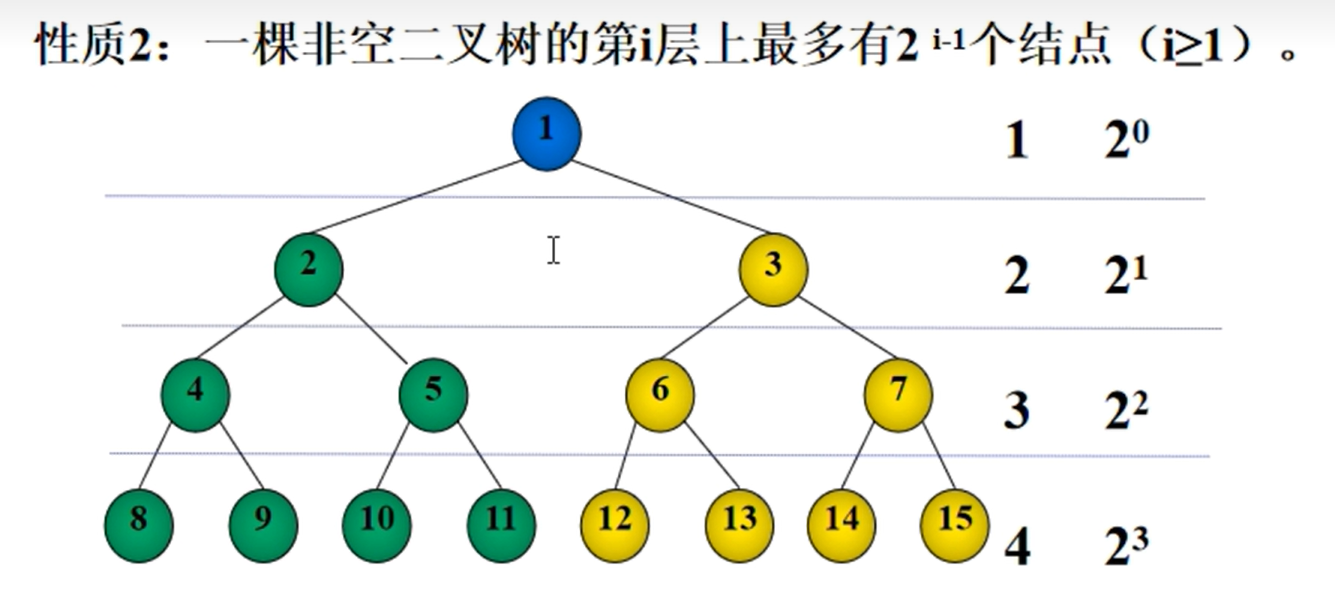
对于非空二叉树的第i层上最多有2i-1个节点(满二叉树)
-
一颗深度为k的二叉树中,最多有2k-1个节点(满二叉树)
-
具有n个节点的完全二叉树的深度为:$\lfloor log_2n \rfloor+1$
-
如果对于一颗有n个节点的完全二叉树的节点按层序编号,则对任意节点i(1<=i<=n)
-
如果i=1,则节点i时二叉树的根节点,如果i>1,则其父亲节点为$\lfloor i/2 \rfloor$
-
如果$2i\leq n$,则其左孩子是节点2i,否则i无左孩子,为叶子节点
-
如果$2i+1\leq n$,其右孩子是节点2i+1,否则节点i无右孩子
-

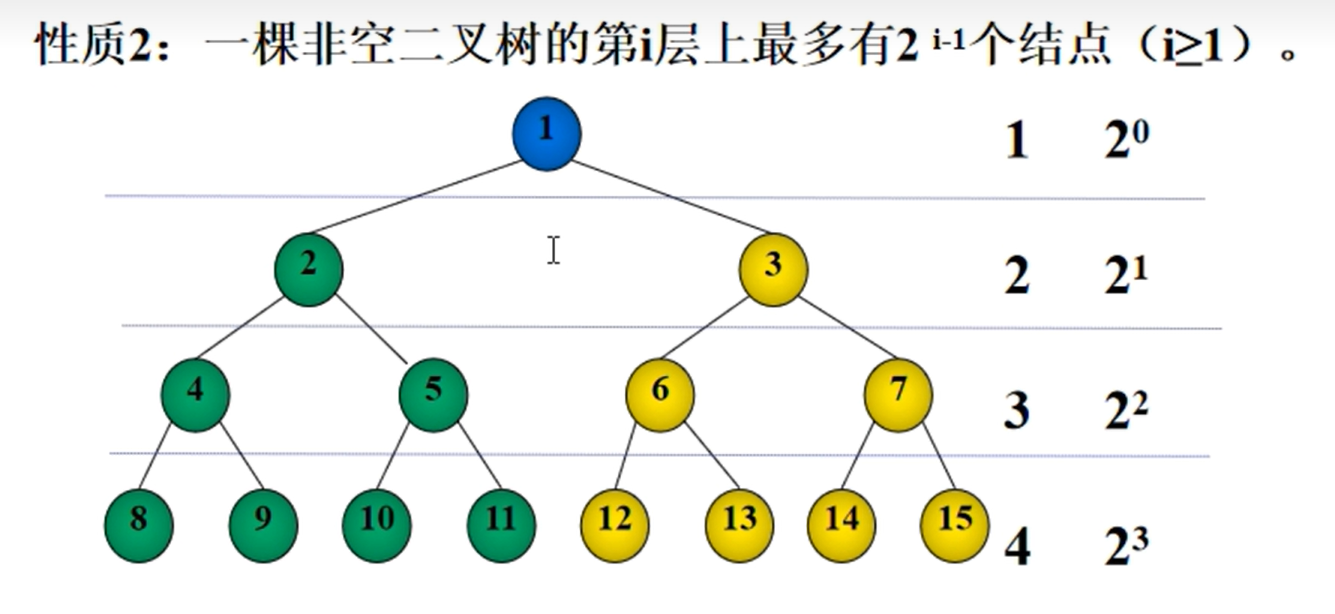
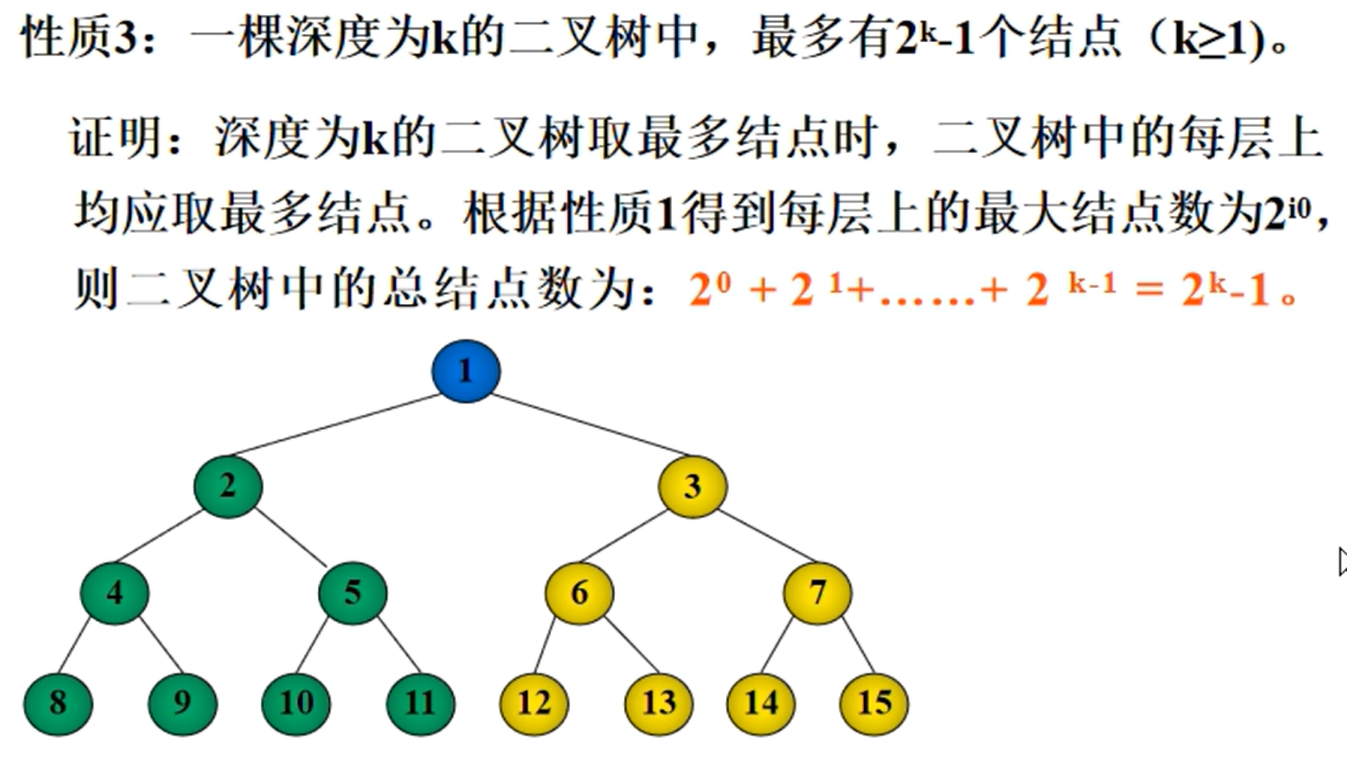
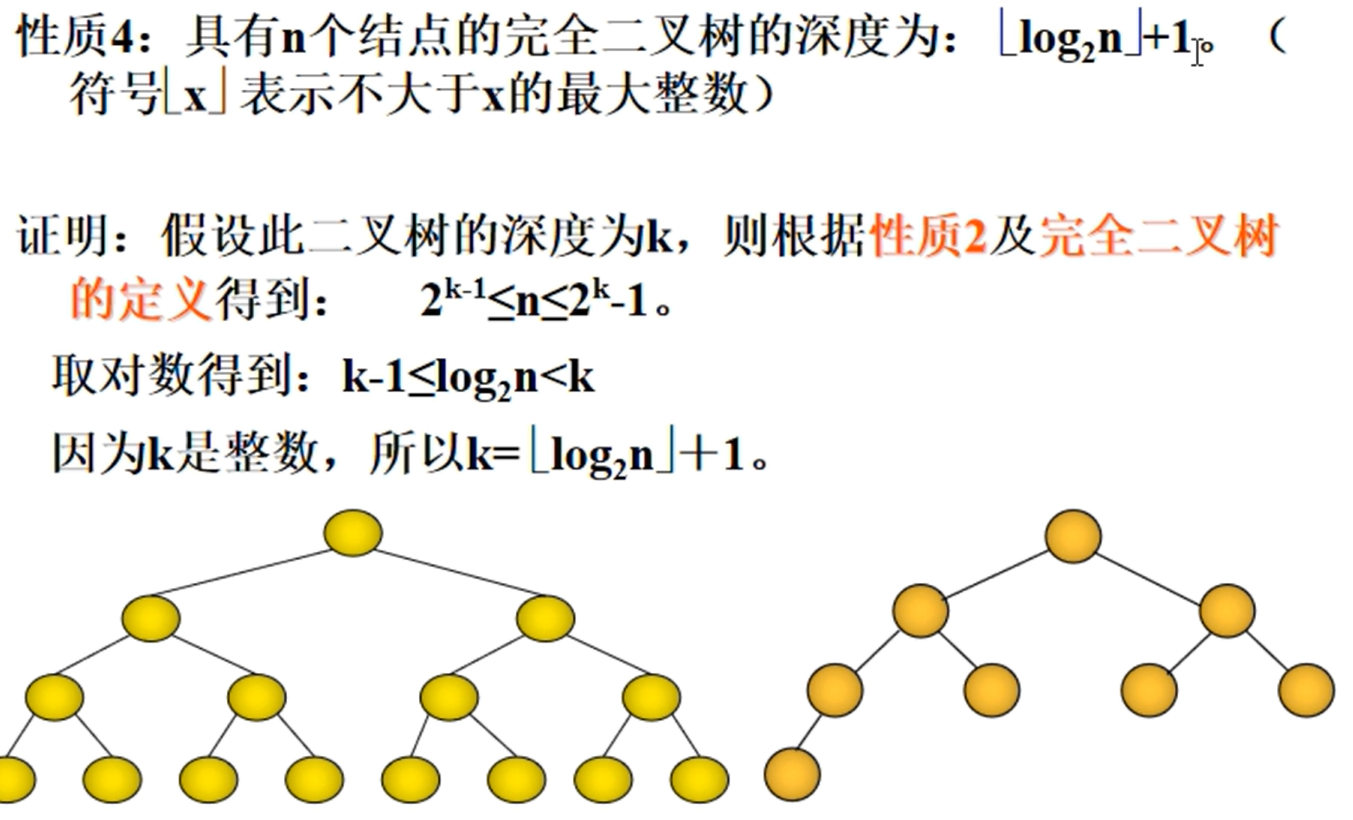
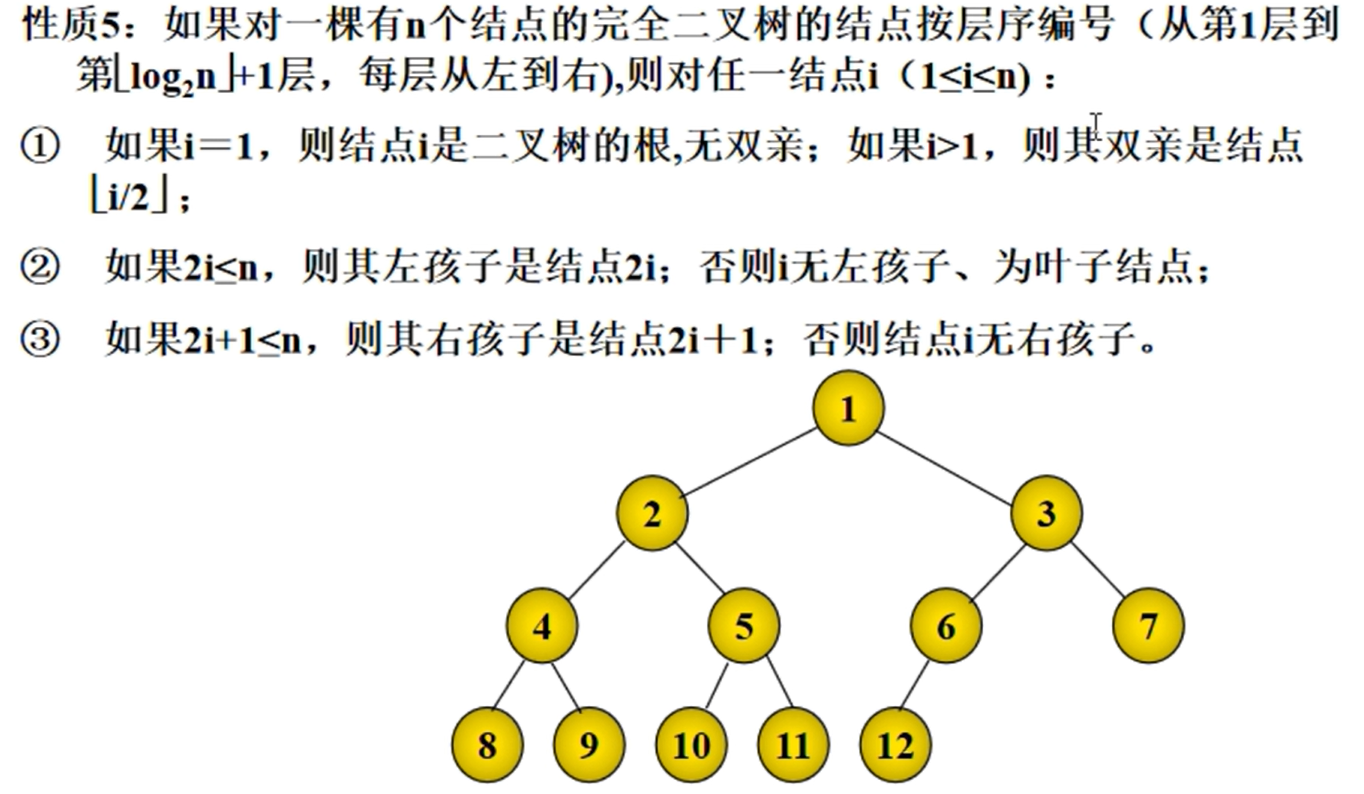
完全二叉树
满二叉树
存储方式
-
顺序存储(用列表或者数组储存)(一般适用于完全二叉树)
-
链式存储
-
列表存储

二叉树的创建
层次按序创建
class TreeNode:def __init__(self, val=0, left=None, right=None):self.val = valself.left = leftself.right = rightclass Tree(object):def __init__(self, li=None):self.root = Noneself.lt = []if li:self.extend(li)def extend(self, li: list): # 层次添加创建for i in li:self.add(i)self.clear()def add(self, number):# if number is None:# self.lt.pop(0)# returnnode = TreeNode(number) # 将输入的数字节点化,使其具有左右孩子的属性if self.root == None:self.root = nodeself.lt.append(self.root)else:while self.lt:point = self.lt[0] # 依次对左右孩子未满的节点分配孩子if point.val == None:self.lt.pop(0)continueif point.left == None:point.left = nodeself.lt.append(point.left) # 该节点后面作为父节点也是未满的,也要加入到列表中。returnif point.right == None:point.right = nodeself.lt.append(point.right) # 与左孩子同理self.lt.pop(0) # 表示该节点已拥有左右孩子,从未满列表中去除returndef clear(self): # 清除值为None的节点def level_order_traversal(root: TreeNode):queue = deque()queue.append(root)while len(queue) > 0:node = queue.popleft()if node.left and node.left.val == None:node.left = Noneif node.left:queue.append(node.left)if node.right and node.right.val == None:node.right = Noneif node.right:queue.append(node.right)level_order_traversal(self.root)def show(self): # 前序遍历输出def dfs(root):if not root:returnprint(root.val, end=" ")dfs(root.left)dfs(root.right)dfs(self.root)def search(self, val):def searchdata(T, val):if T == None:return Noneif T.val == val:return Telse:p = searchdata(T.left, val)if p != None:return pp = searchdata(T.right, val)if p != None:return preturn searchdata(self.root, val)
函数前序创建
def creat_binary_tree(input_list=[]):# 构建二叉树# param input_list:输入数列# 当我们在函数中传入的数列不存在或者传入的数列中元素的个数等于0时,表示是一棵空树# 此时不需要操作,直接返回None即可if input_list is None or len(input_list) == 0:return None# 结点中的数据等于列表中的第一个元素,每次pop出去一个元素,后面的元素会往前走一个位置# 这样可以保证元素的一次弹出val = input_list.pop(0)# 当弹出的元素是None时,表示该节点为空,直接返回Noneif val is None:return None# 通过刚才定义的TreeNode类新建nodenode = TreeNode(val)# node的左孩子等于弹出的结点,即input_list.pop(0)弹出的元素node.left = creat_binary_tree(input_list)# node的右孩子等于弹出的结点,即input_list.pop(0)弹出的元素node.right = creat_binary_tree(input_list)# 返回node结点return node
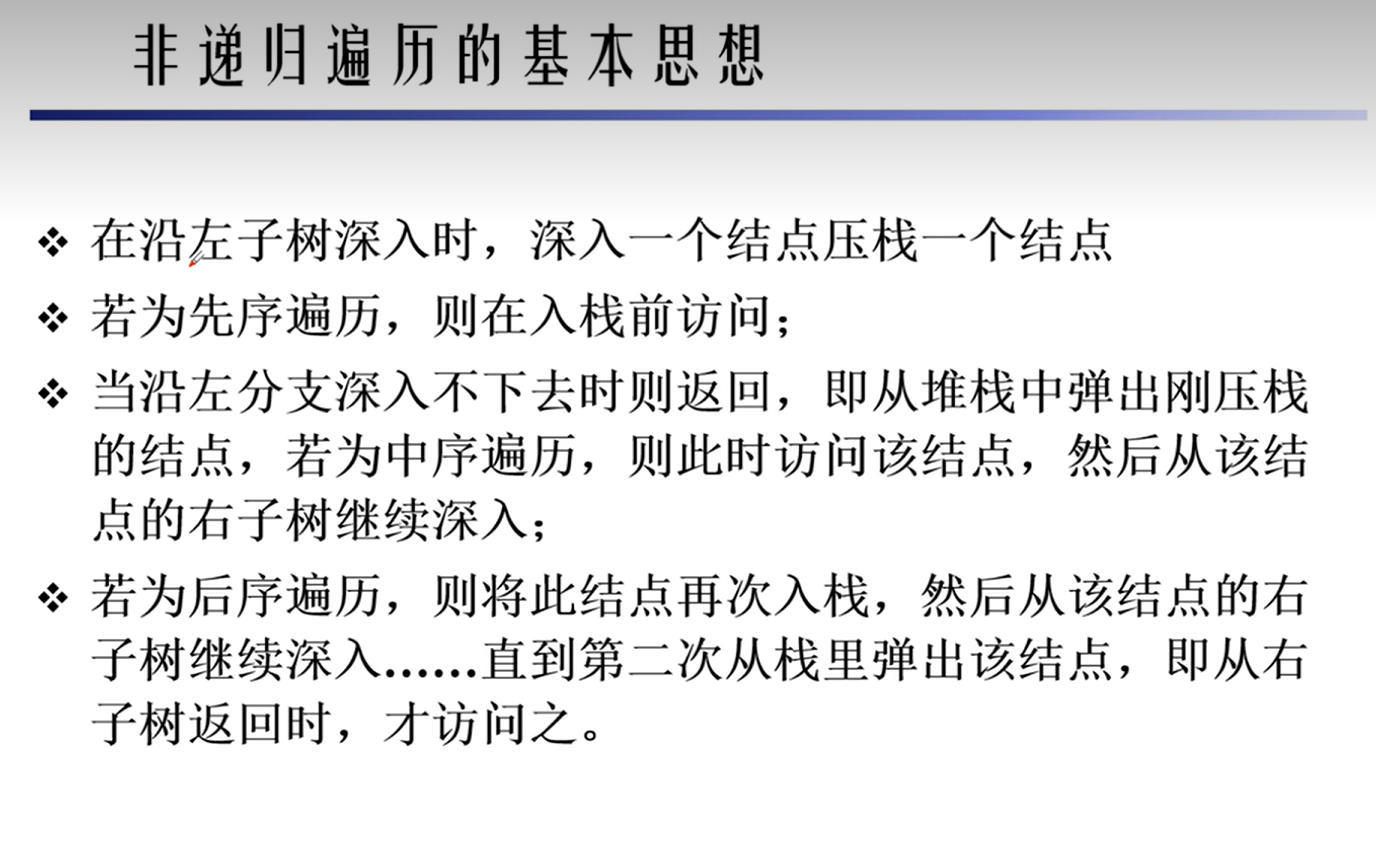
二叉树的遍历
- 递归遍历
- 非递归遍历
- 前序遍历
- 中序遍历
- 后序遍历
- 层次遍历
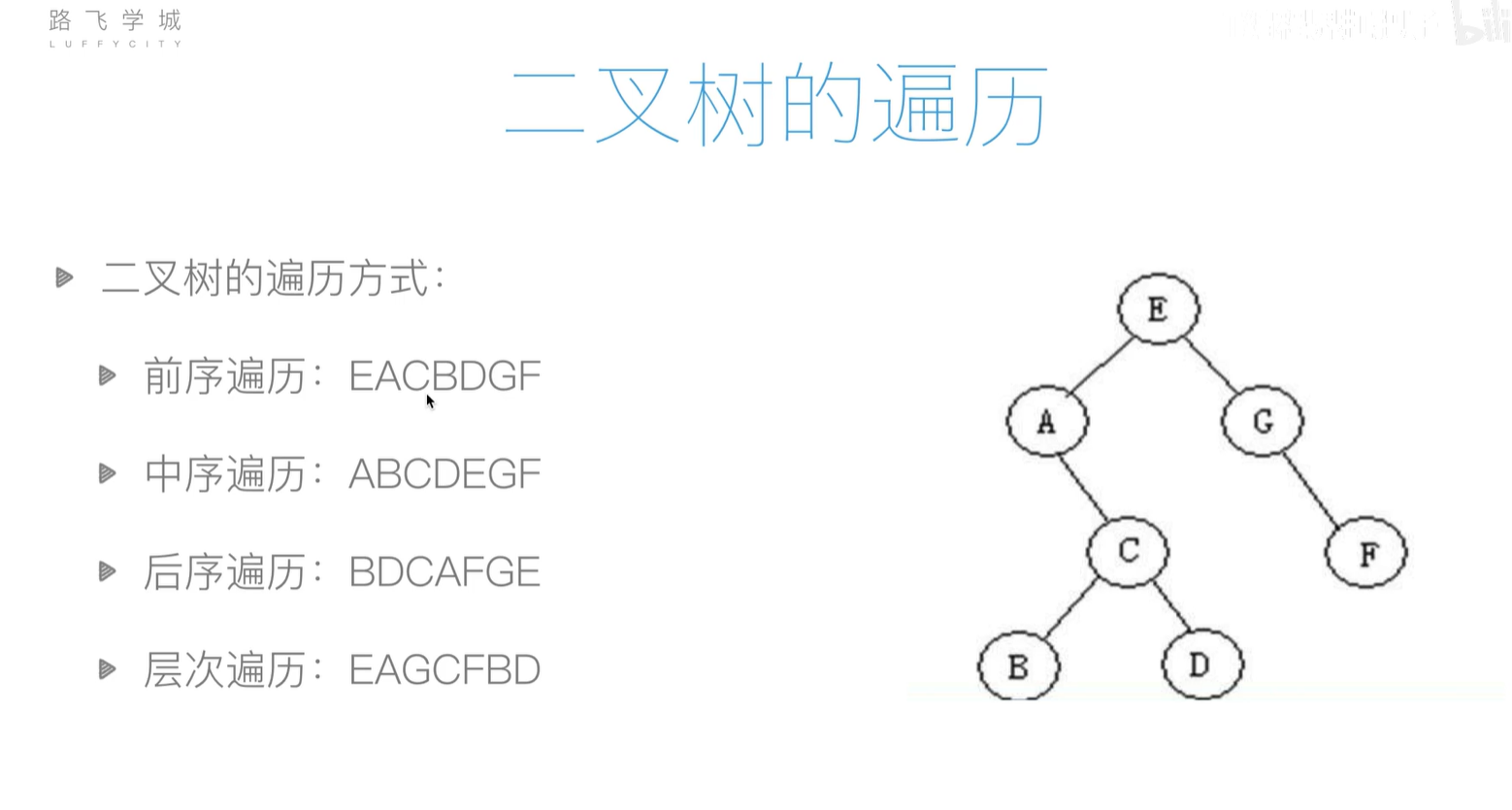
递归遍历代码
def pre_order_traversal(node):# 前序遍历# param node:二叉树节点# 当node为空表示为一棵空树,不需要进行前序遍历直接返回即可if node is None:return# 此时node不为空,直接打印node的val域print(node.val, end=" ")# 递归的先序遍历node的左孩子pre_order_traversal(node.left)# 递归的先序遍历node的左孩子pre_order_traversal(node.right)return node#
def in_order_traversal(node):# 中序遍历# param node:二叉树节点if node is None:return# 递归的中序遍历node的左孩子in_order_traversal(node.left)# 打印节点的值print(node.val, end=" ")# 递归的中序遍历node的左孩子in_order_traversal(node.right)return nodedef post_order_traversal(node):# 后序遍历# param node:二叉树节点if node is None:return# 递归的后序遍历node的左孩子post_order_traversal(node.left)# 递归的后序遍历node的左孩子post_order_traversal(node.right)# 打印节点的值print(node.val, end=" ")return nodefrom collections import deque, Counterdef level_order_traversal(root: TreeNode):queue = deque()queue.append(root)while len(queue) > 0:node = queue.popleft()print(node.val, end=" ")if node.left:queue.append(node.left)if node.right:queue.append(node.right)
非递归遍历代码
def preorderTraversal(root: TreeNode) -> List[int]:# 根结点为空则返回空列表if not root:return []stack = [root]result = []while stack:node = stack.pop()# 中结点先处理result.append(node.val)# 右孩子先入栈if node.right:stack.append(node.right)# 左孩子后入栈if node.left:stack.append(node.left)return result# 中序遍历-迭代-LC94_二叉树的中序遍历def inorderTraversal(root: TreeNode) -> List[int]:if not root:return []stack = [] # 不能提前将root结点加入stack中result = []cur = rootwhile cur or stack:# 先迭代访问最底层的左子树结点if cur:stack.append(cur)cur = cur.left# 到达最左结点后处理栈顶结点else:cur = stack.pop()result.append(cur.val)# 取栈顶元素右结点cur = cur.rightreturn result# 后序遍历-迭代-LC145_二叉树的后序遍历def postorderTraversal(root: TreeNode) -> List[int]:if not root:return []stack = [root]result = []while stack:node = stack.pop()# 中结点先处理result.append(node.val)# 左孩子先入栈if node.left:stack.append(node.left)# 右孩子后入栈if node.right:stack.append(node.right)# 将最终的数组翻转return result[::-1]
哈夫曼树
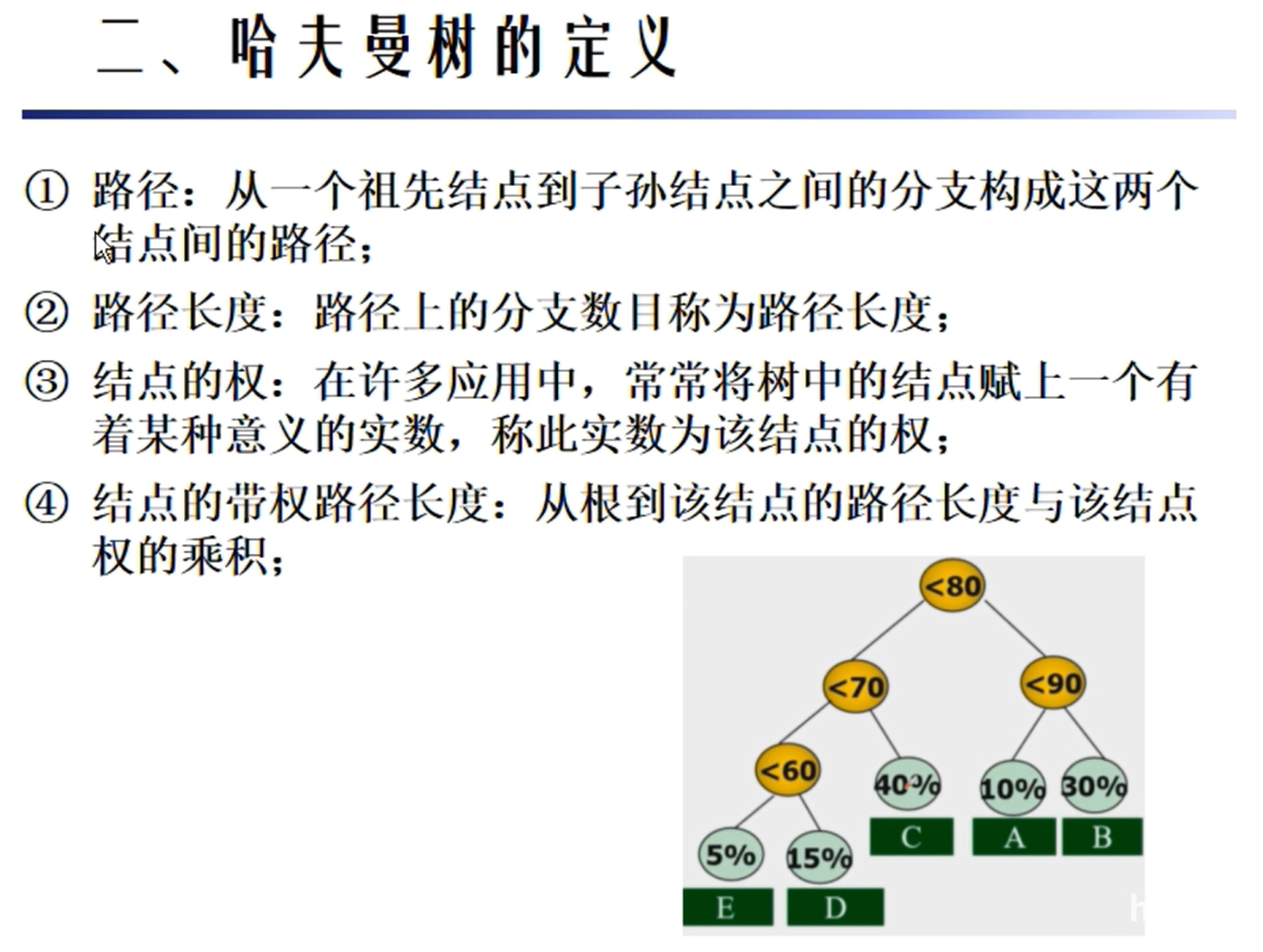
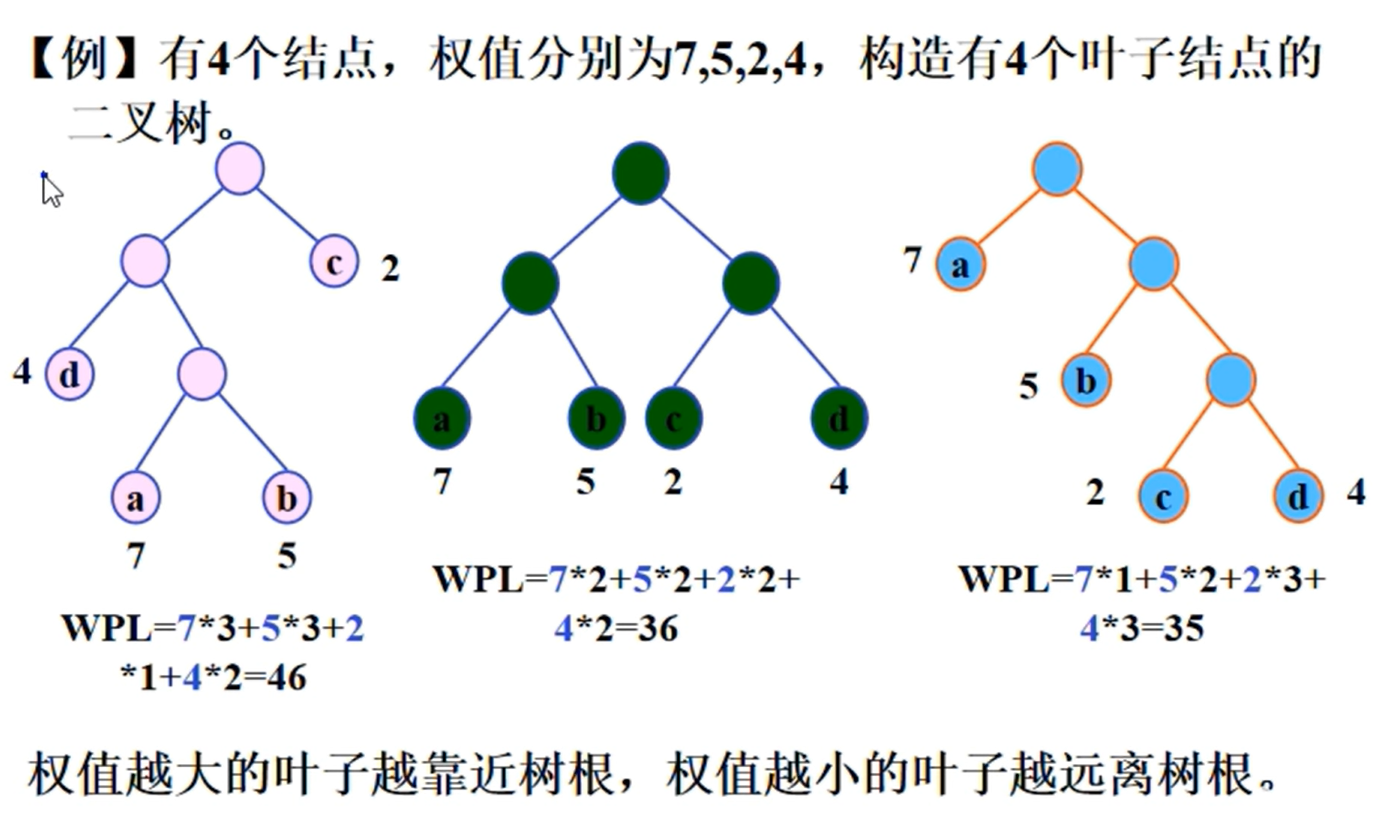

哈夫曼编码
代码
class HuffmanNode:def __init__(self, val=0):self.val = valself.left = Noneself.right = Noneself.parent = Noneclass HuffmanTree:def __init__(self, head=None):self.head = headself.lst = []self.huffman_code = Nonedef create(self, li: list):res = []for i in li:res.append(HuffmanNode(i))self.lst = res[:]while len(res) > 1:res.sort(key=lambda item: item.val)node_left = res.pop(0)node_right = res.pop(0)node_father = HuffmanNode(node_left.val + node_right.val)node_father.left = node_leftnode_father.right = node_rightnode_left.parent = node_fathernode_right.parent = node_fatherres.append(node_father)res[0].parent = Noneself.head = res[0]def encoding(self):if self.head is None:returnhuffman_code = [''] * len(self.lst)for i in range(len(self.lst)):node = self.lst[i]while node != self.head:if node.parent.left == node:huffman_code[i] = "0" + huffman_code[i]else:huffman_code[i] = "1" + huffman_code[i]node = node.parentself.huffman_code = huffman_codehuffmantree = HuffmanTree()
huffmantree.create([2, 4, 5, 7])
level_order_traversal(huffmantree.head)
huffmantree.encoding()
print(huffmantree.huffman_code)
二叉搜索树
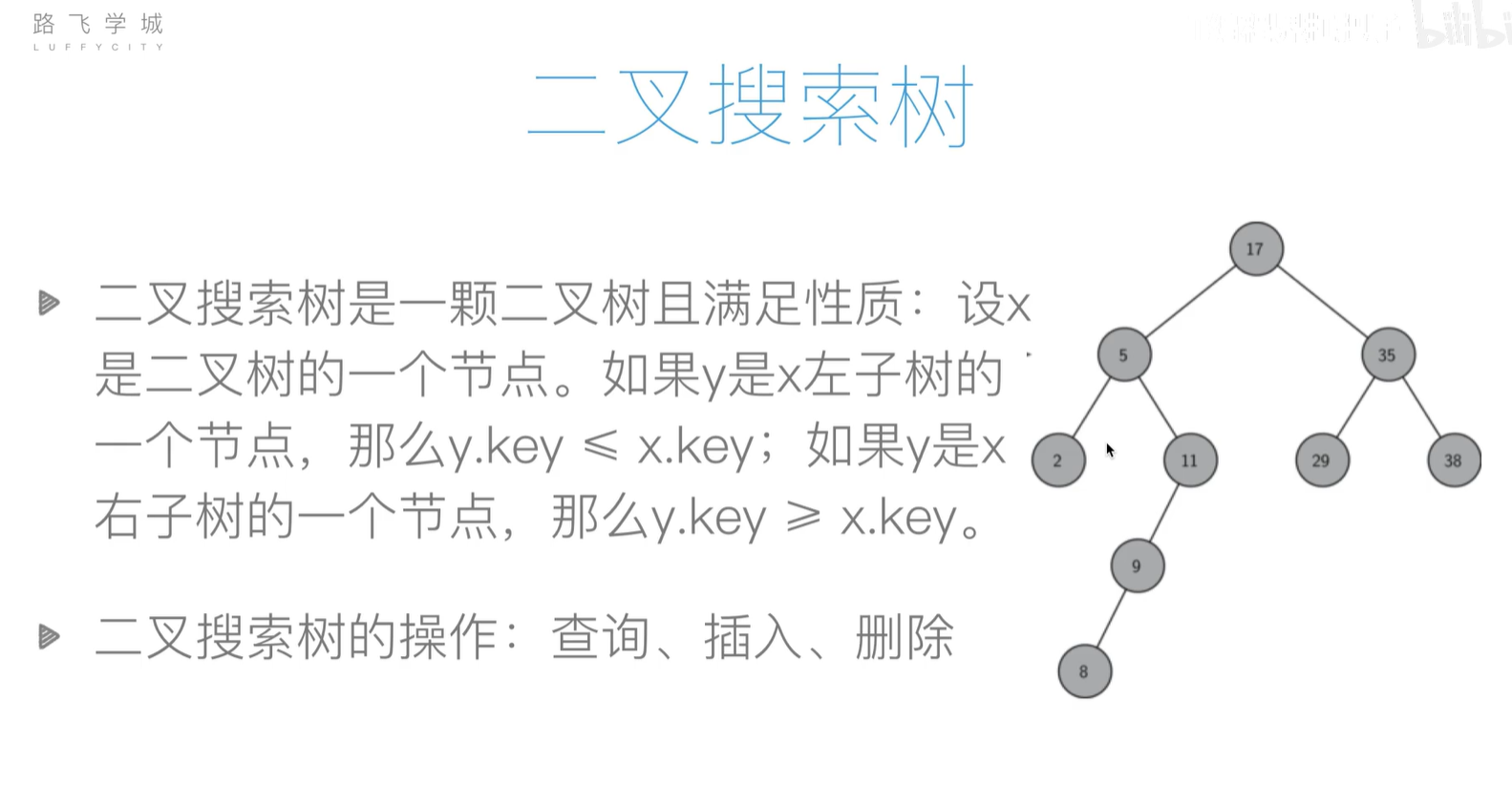
基本操作
- 插入
- 查询
- 删除
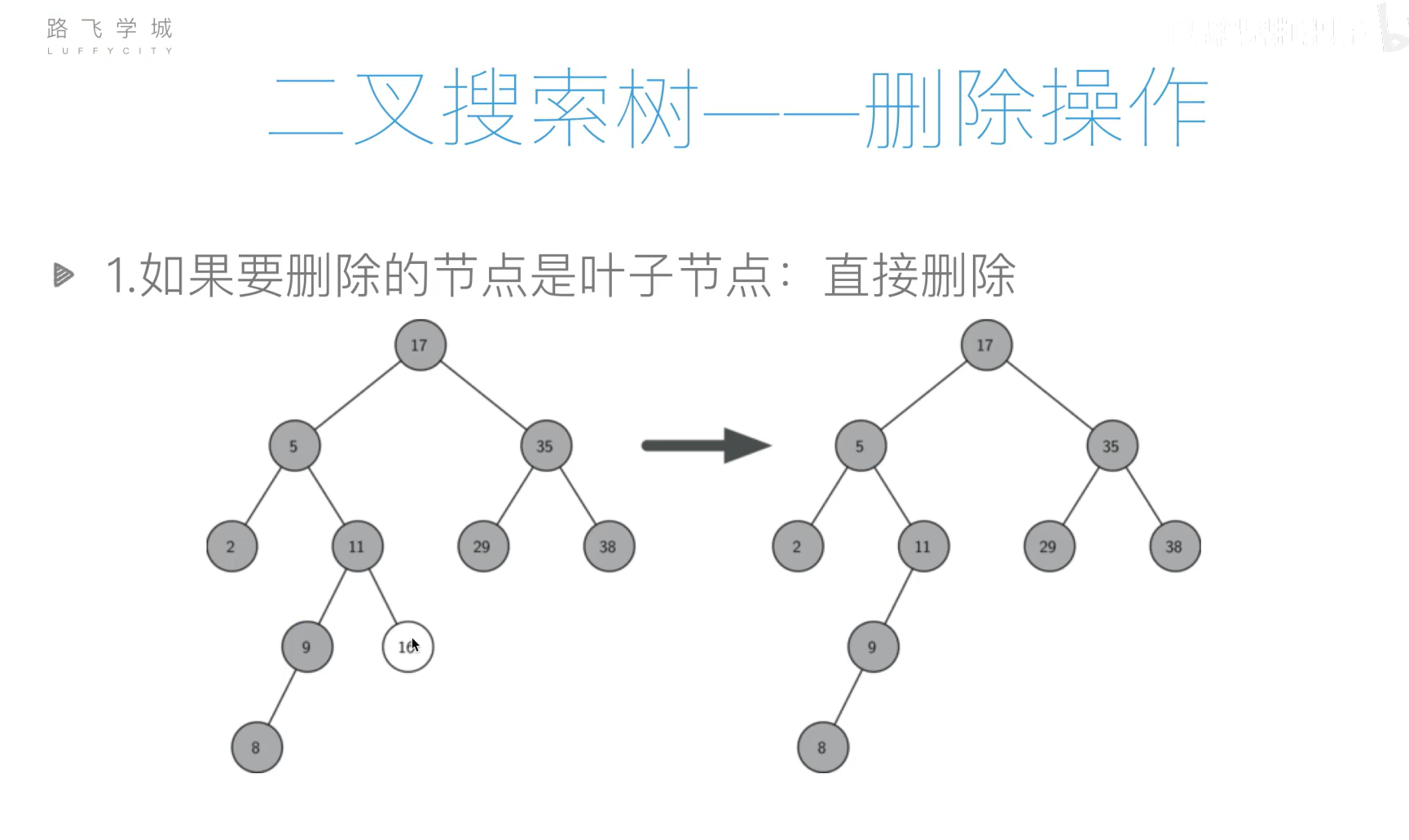
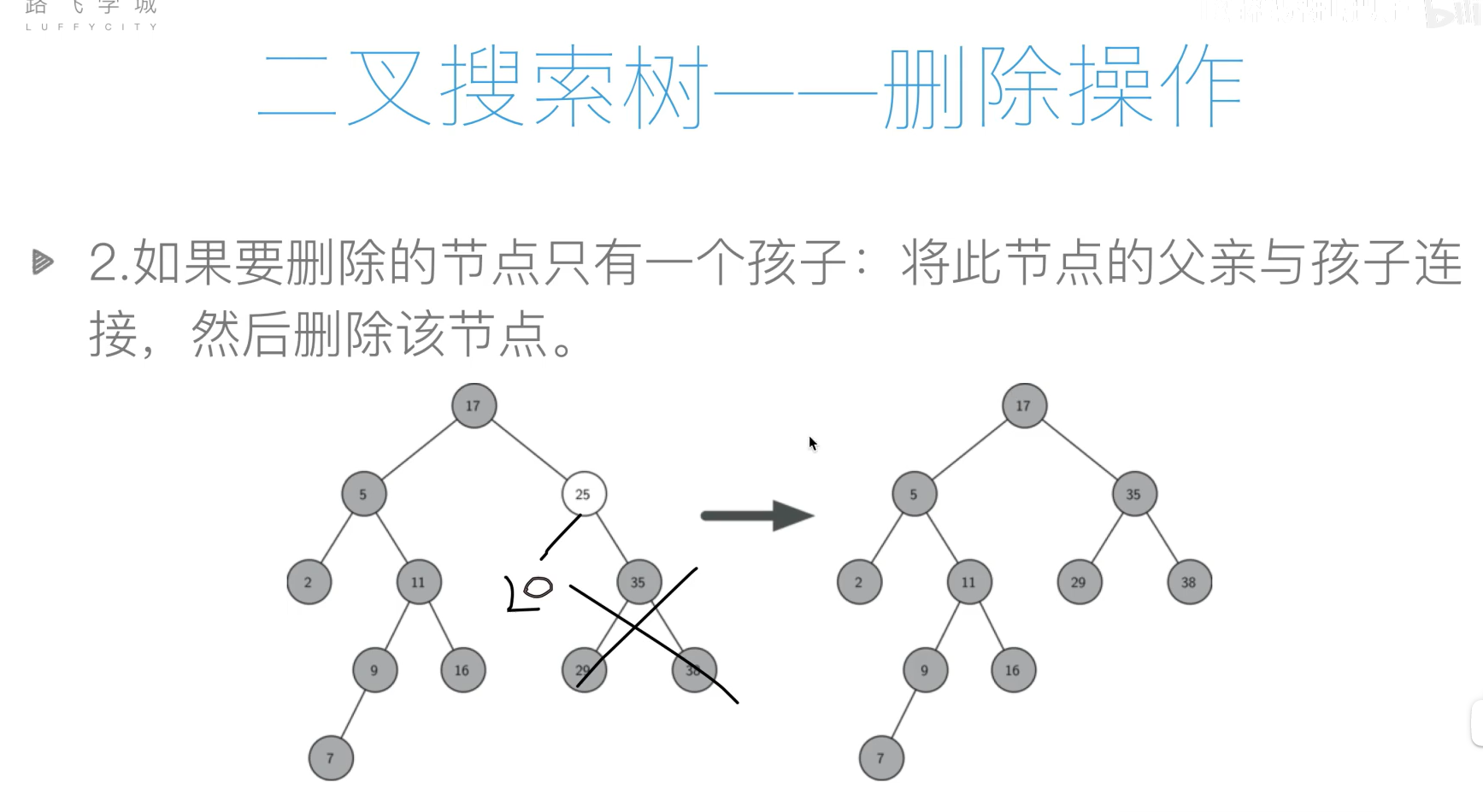
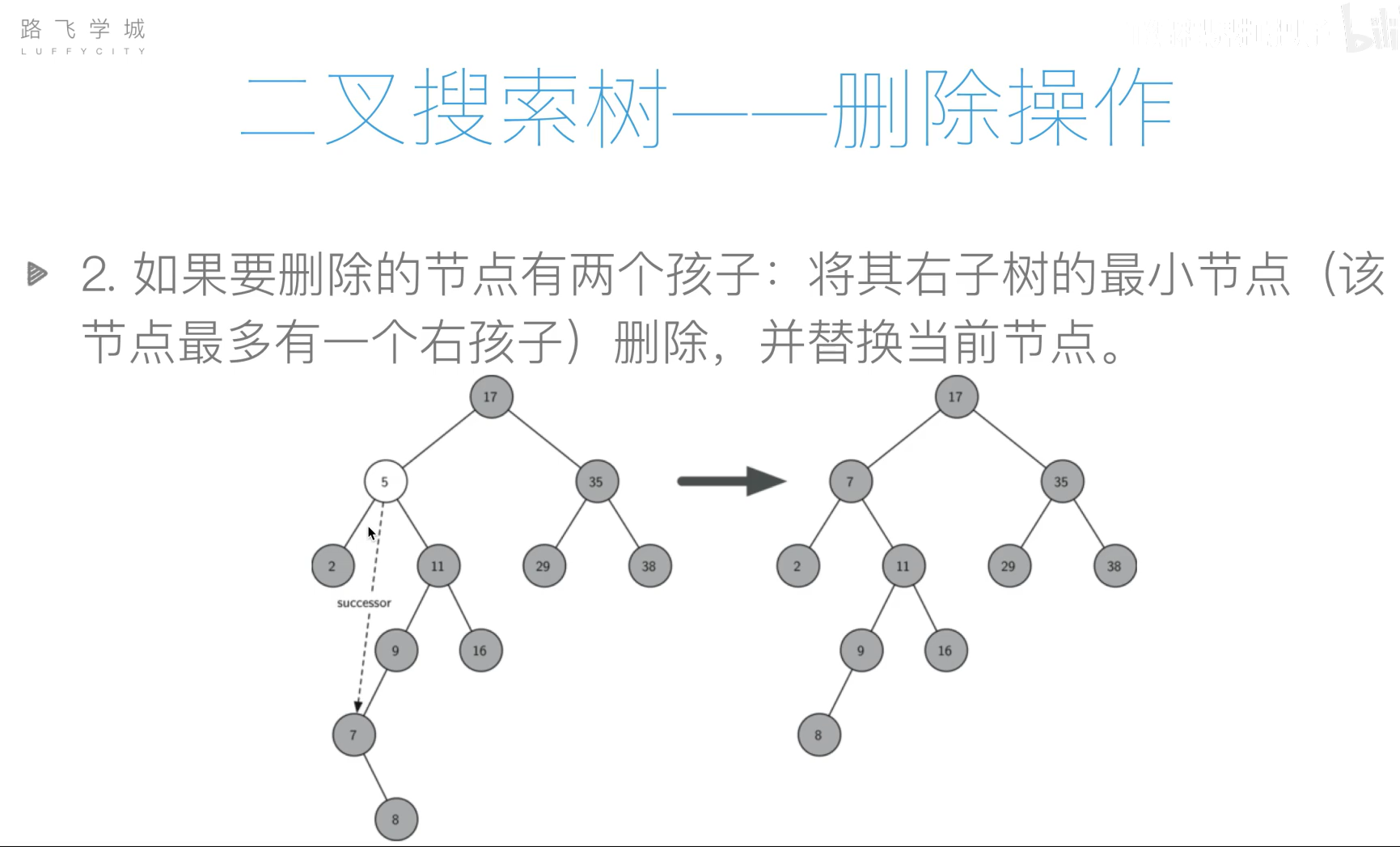
代码
class BiTreeNode:def __init__(self, data):self.val = dataself.left = Noneself.right = Noneself.parent = Noneclass BST:def __init__(self, data: list):self.root = Noneif data:# if self.root is None:# self.root=BiTreeNode(data[0])# data=data[1:]# for i in data:# self.insert(self.root, i)for i in data:self.insert_no_rec(i)def insert(self, node, val):if not node:node = BiTreeNode(val)elif val <= node.val:node.left = self.insert(node.left, val)elif val > node.val:node.right = self.insert(node.right, val)return nodedef insert_no_rec(self, val):p = self.rootif not p:self.root = BiTreeNode(val)returnwhile True:if val <= p.val:if p.left:p = p.leftelse:p.left = BiTreeNode(val)p.left.parent = preturnelif val > p.val:if p.right:p = p.rightelse:p.right = BiTreeNode(val)p.right.parent = preturndef query(self, node, val):if not node:return Noneif node.val < val:return self.query(node.right, val)elif node.val > val:return self.query(node.left, val)else:return nodedef query_no_rec(self, val):p = self.rootwhile p:if p.val < val:p = p.rightelif p.val > val:p = p.leftelse:return preturn Nonedef __remove_node_1(self, node):if not node.parent:self.root = Noneif node == node.parent.left:node.parent.left = Noneelse:node.parent.right = Nonedef __remove_node_21(self, node):if not node.parent:self.root = node.leftnode.left.parent = Noneelif node == node.parent.left:node.parent.left = node.leftnode.left.parent = node.parentelse:node.parent.right = node.leftnode.left.parent = node.parentdef __remove_node_22(self, node):if not node.parent:self.root = node.rightelif node == node.parent.left:node.parent.left = node.rightnode.right.parent = node.parentelse:node.parent.right = node.rightnode.right.parent = node.parentdef delete(self, val):if self.root:node = self.query_no_rec(val)if not node:return Falseif not node.left and not node.right:self.__remove_node_1(node)elif not node.right:self.__remove_node_21(node)elif not node.left:self.__remove_node_22(node)else:min_node = node.rightwhile min_node.left:min_node = min_node.leftnode.val = min_node.valif min_node.right:self.__remove_node_22(min_node)else:self.__remove_node_1(min_node)T = BST([5, 1, 2, 3, 4, 1, 6, 2])
in_order_traversal(T.root)
T.delete(1)
T.delete(1)
T.delete(6)
print()
in_order_traversal(T.root)
AVL树(平衡二叉搜索树)

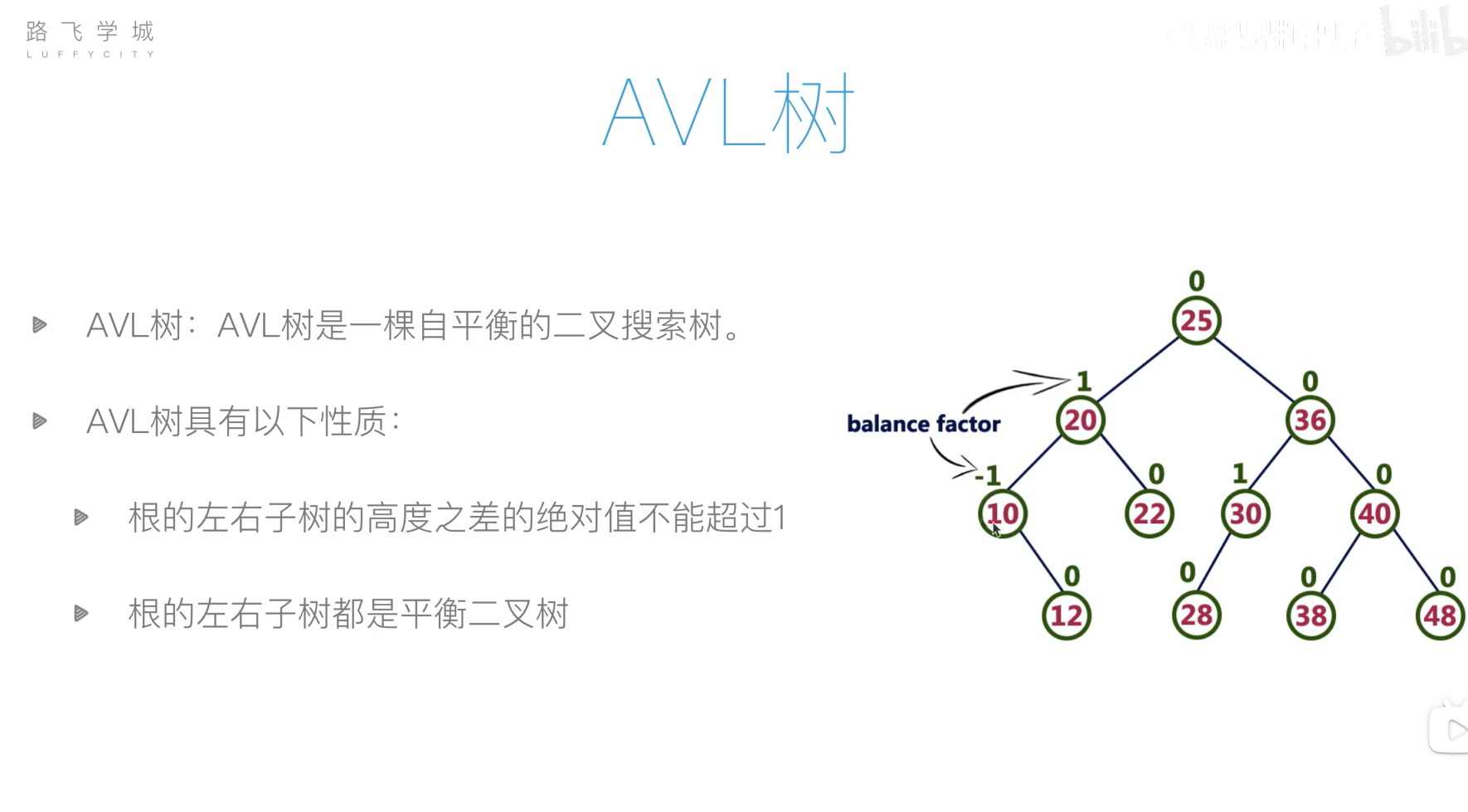

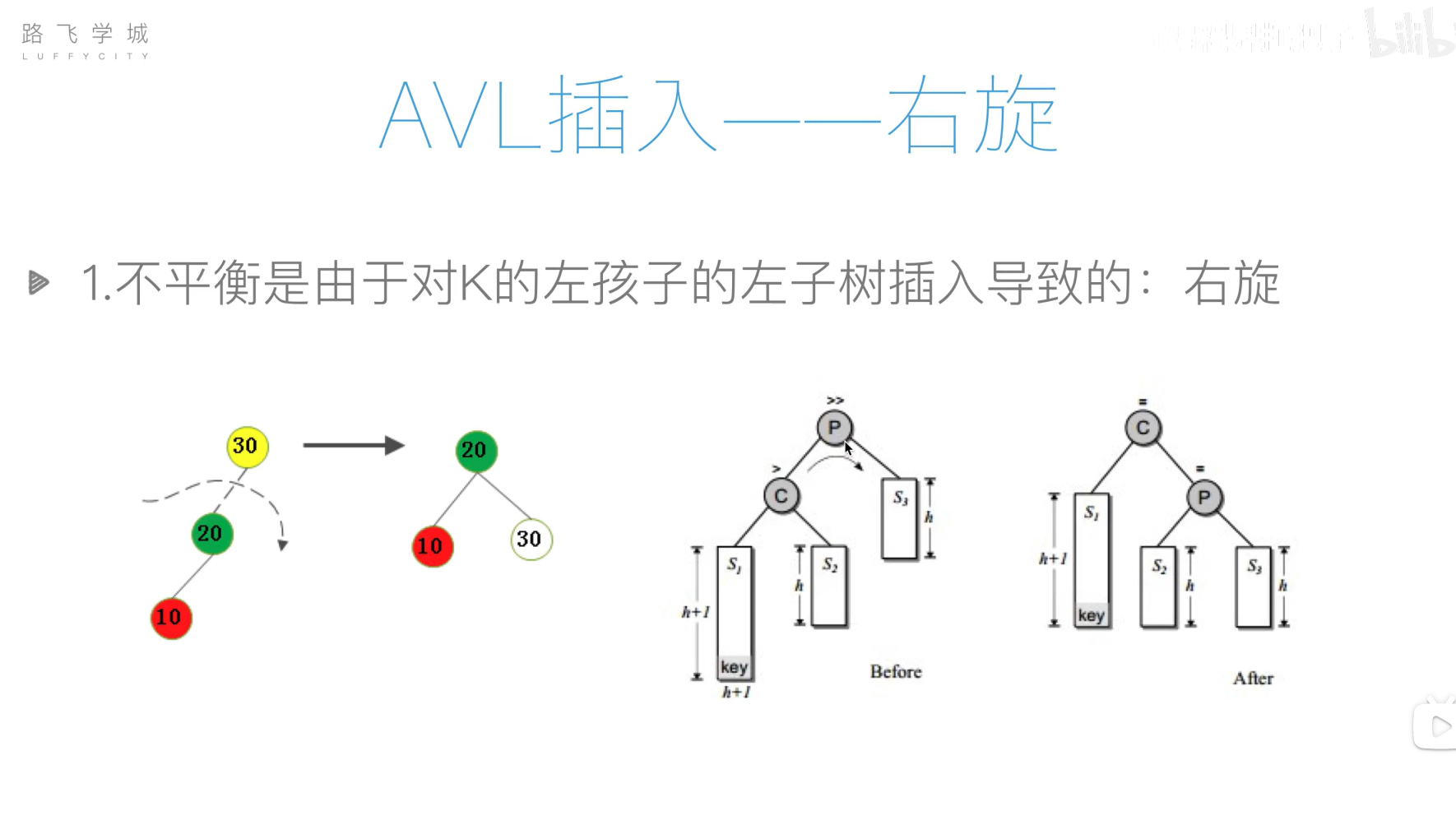
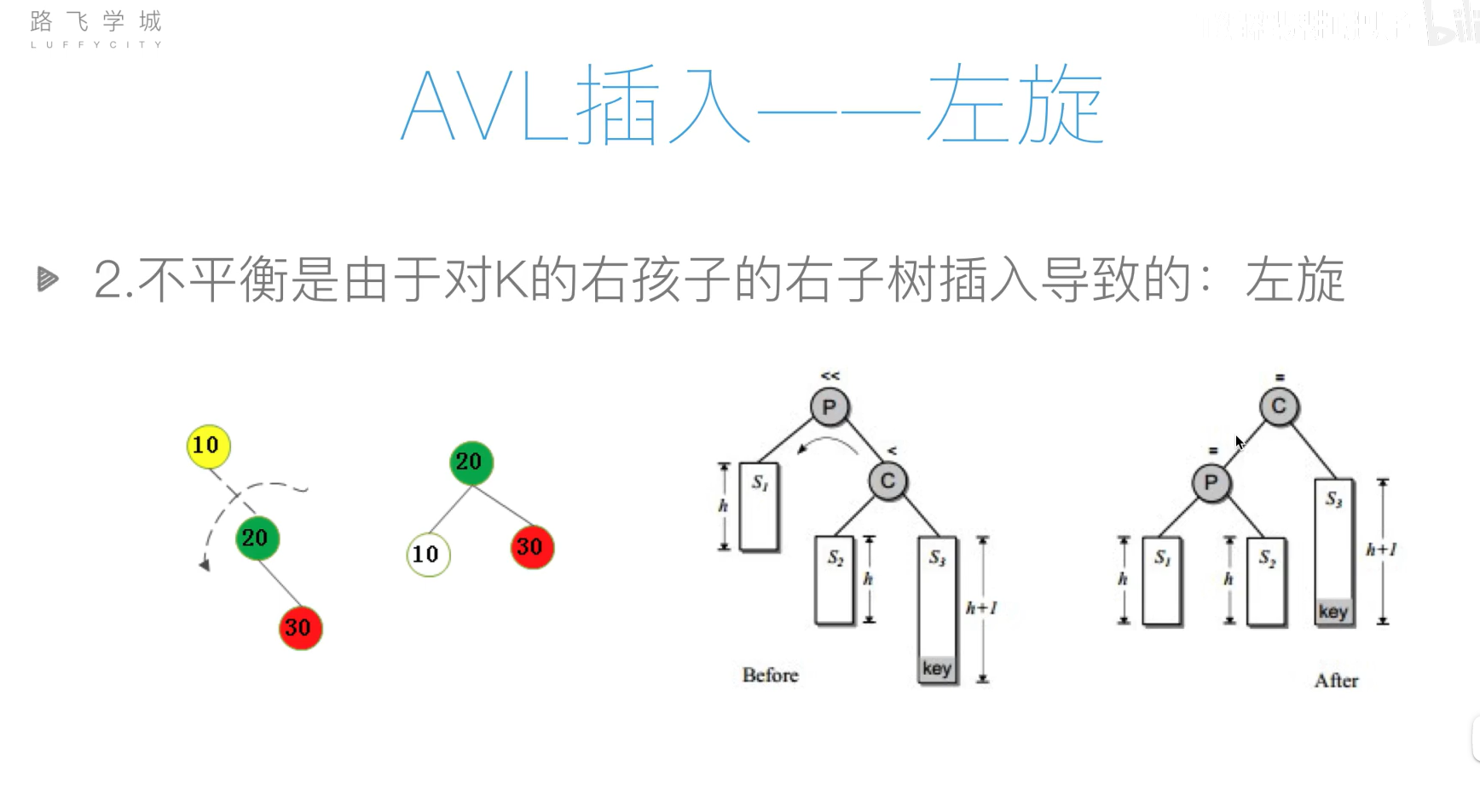
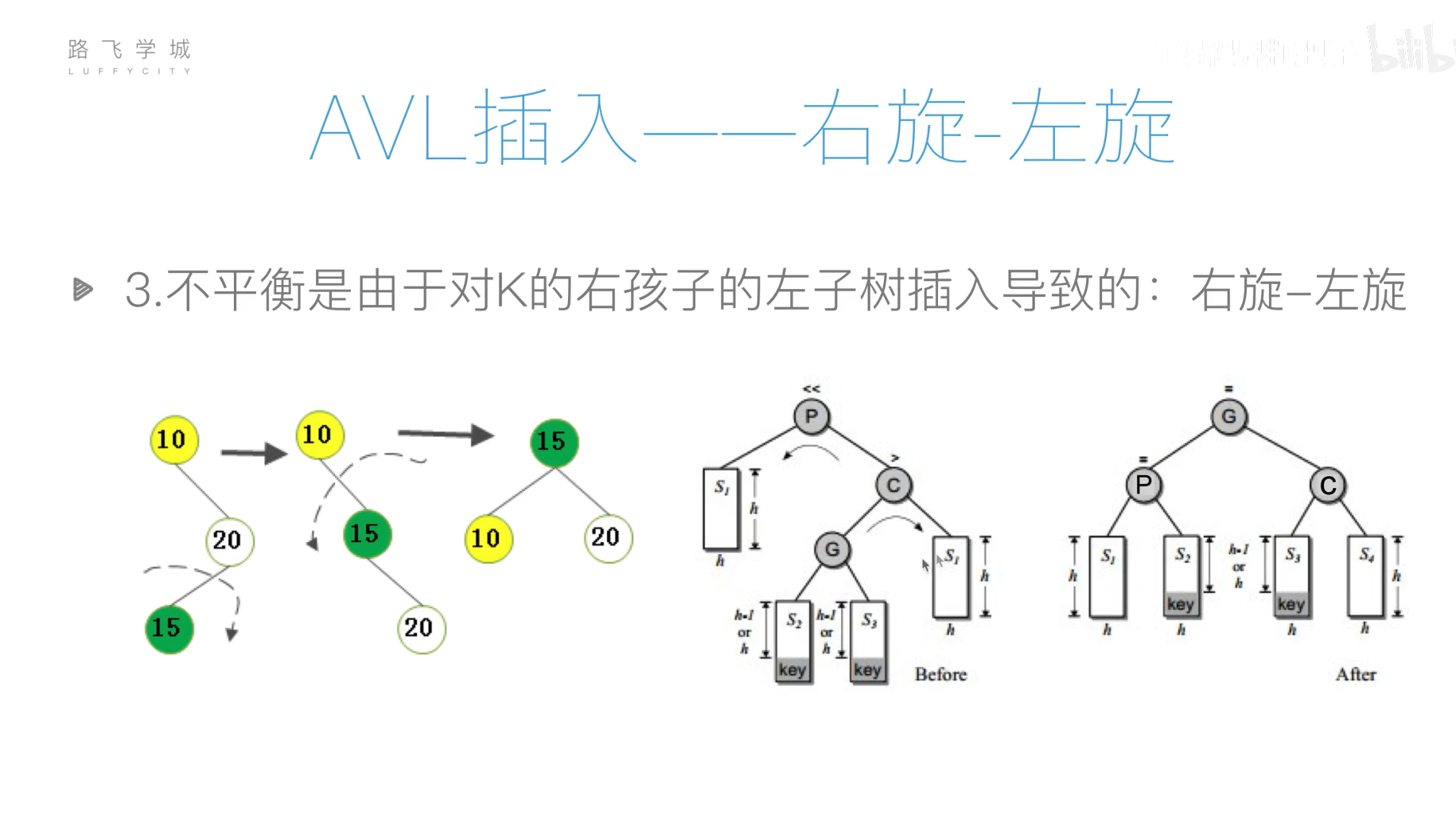
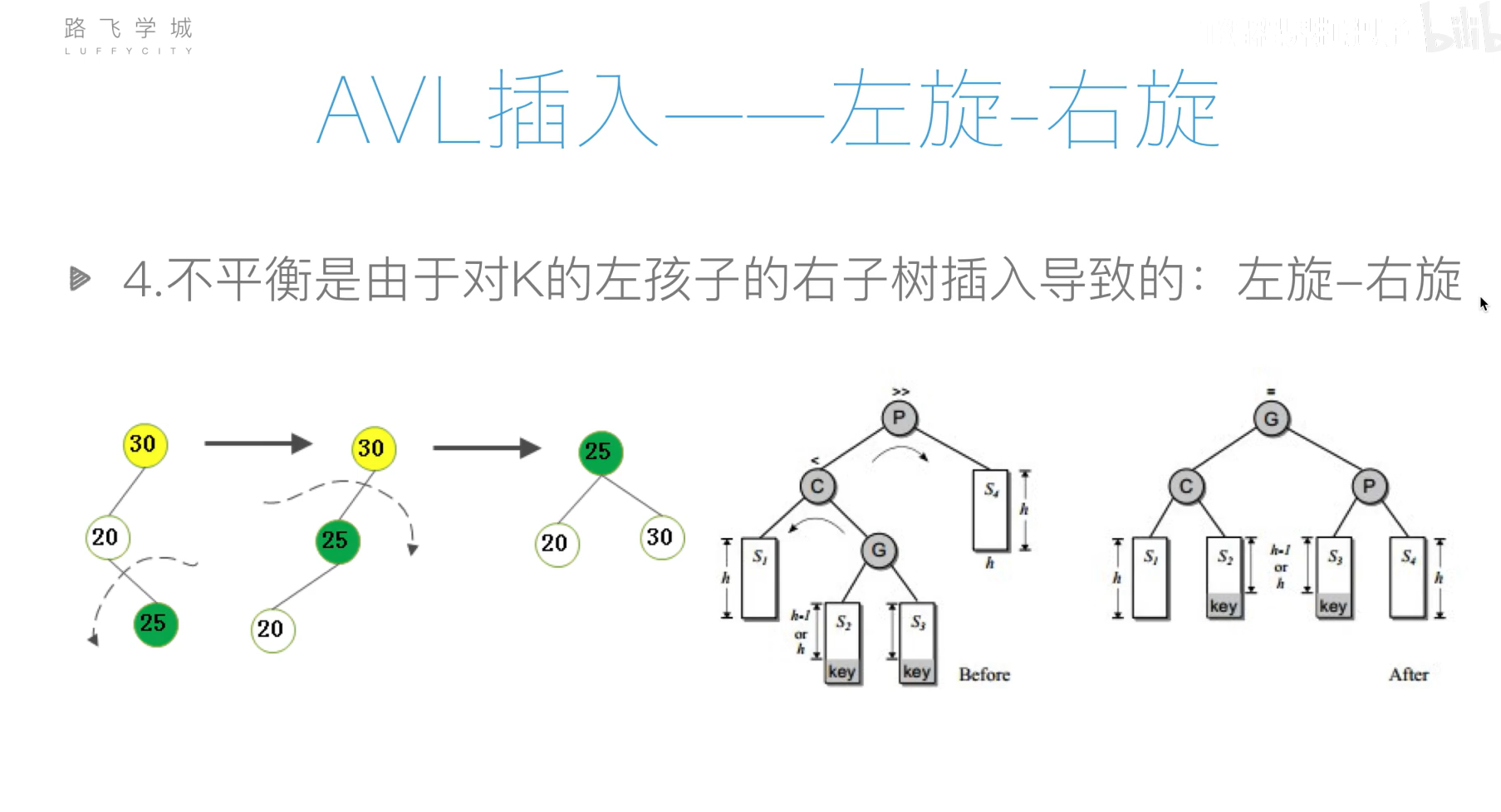
旋转操作过于复杂,可以先将列表元素排好序,然后使用二分递归的方法
代码如下:
二分递归代码
def sortedArrayToBST(nums: list[int]) -> TreeNode:def helper(left, right):if left > right:return Nonemid = (left + right) // 2root = TreeNode(nums[mid])root.left = helper(left, mid - 1)root.right = helper(mid + 1, right)return rootreturn helper(0, len(nums) - 1)li = [1, 2, 3, 4, 5, 6, 7, 8, 9]
root = sortedArrayToBST(li)
in_order_traversal(root)
print()
pre_order_traversal(root)
树和森林
基本概念
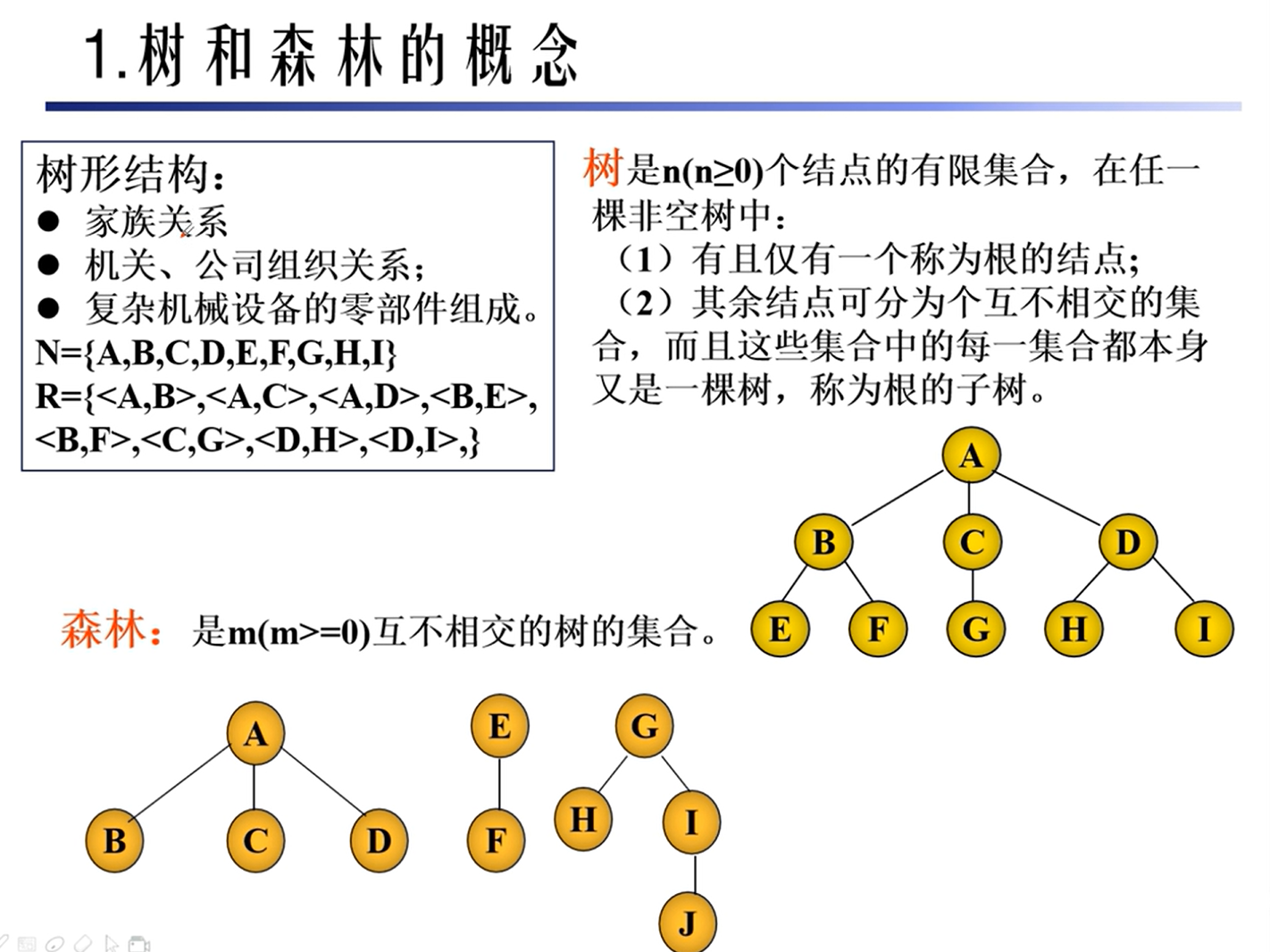
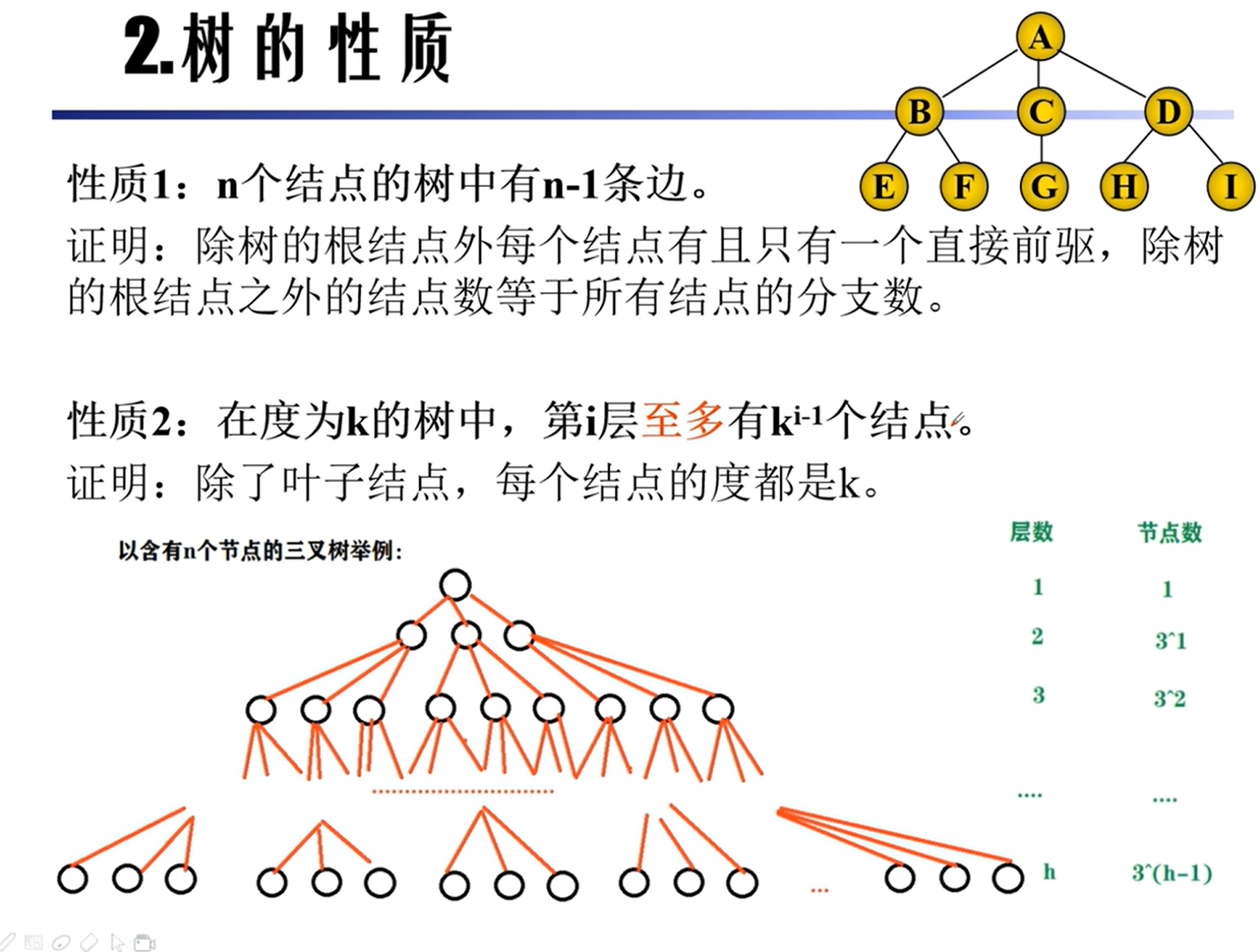
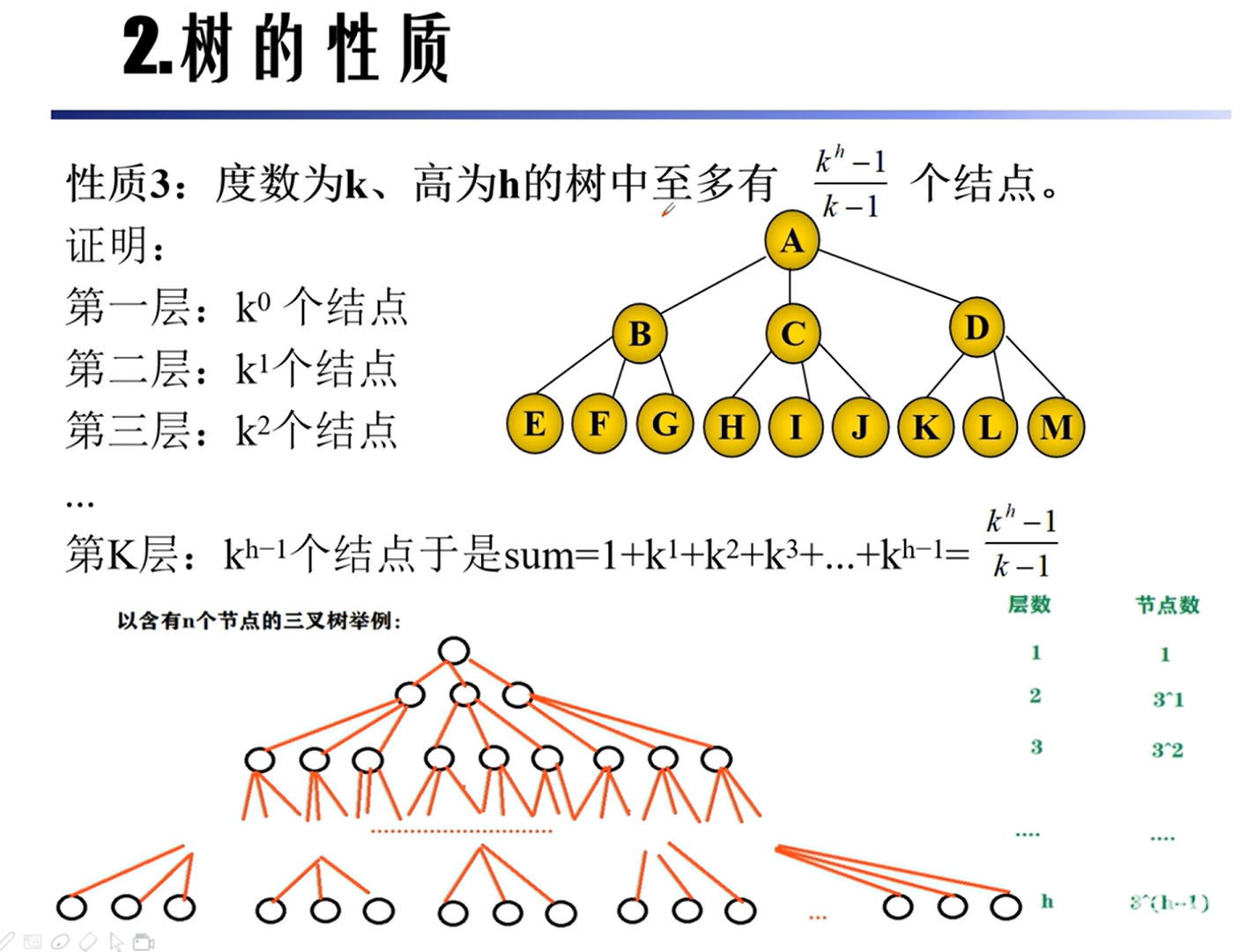
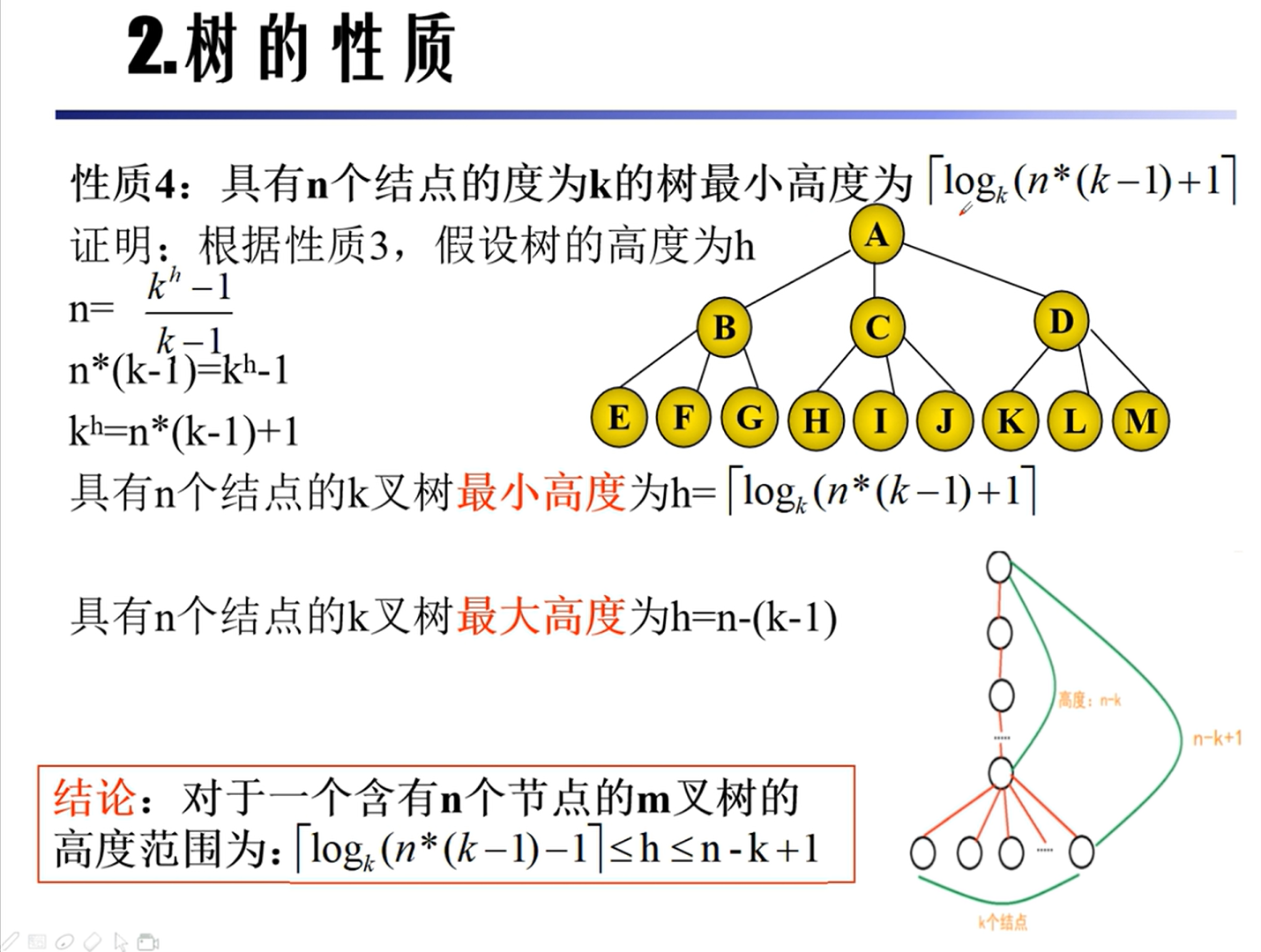
性质
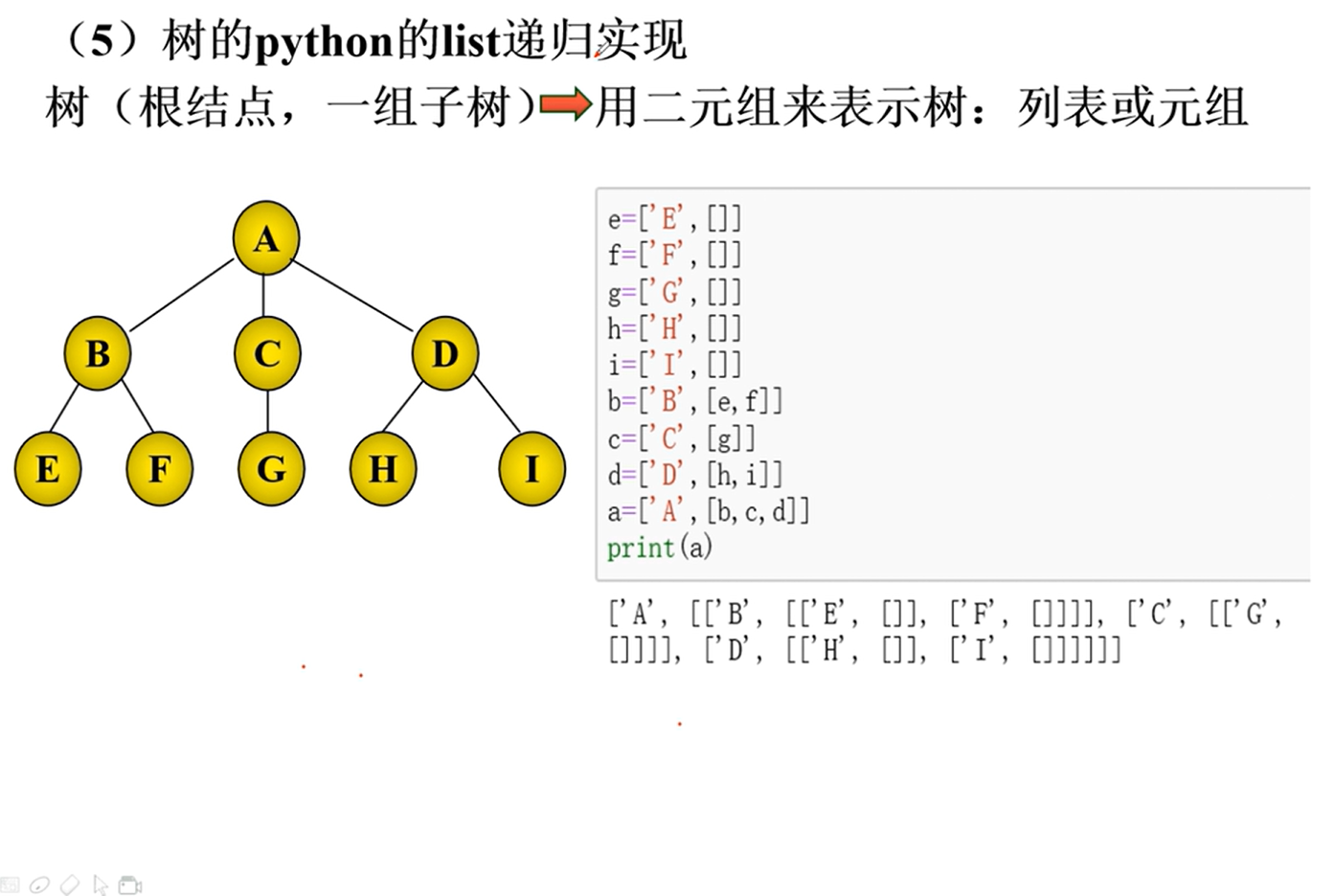
存储

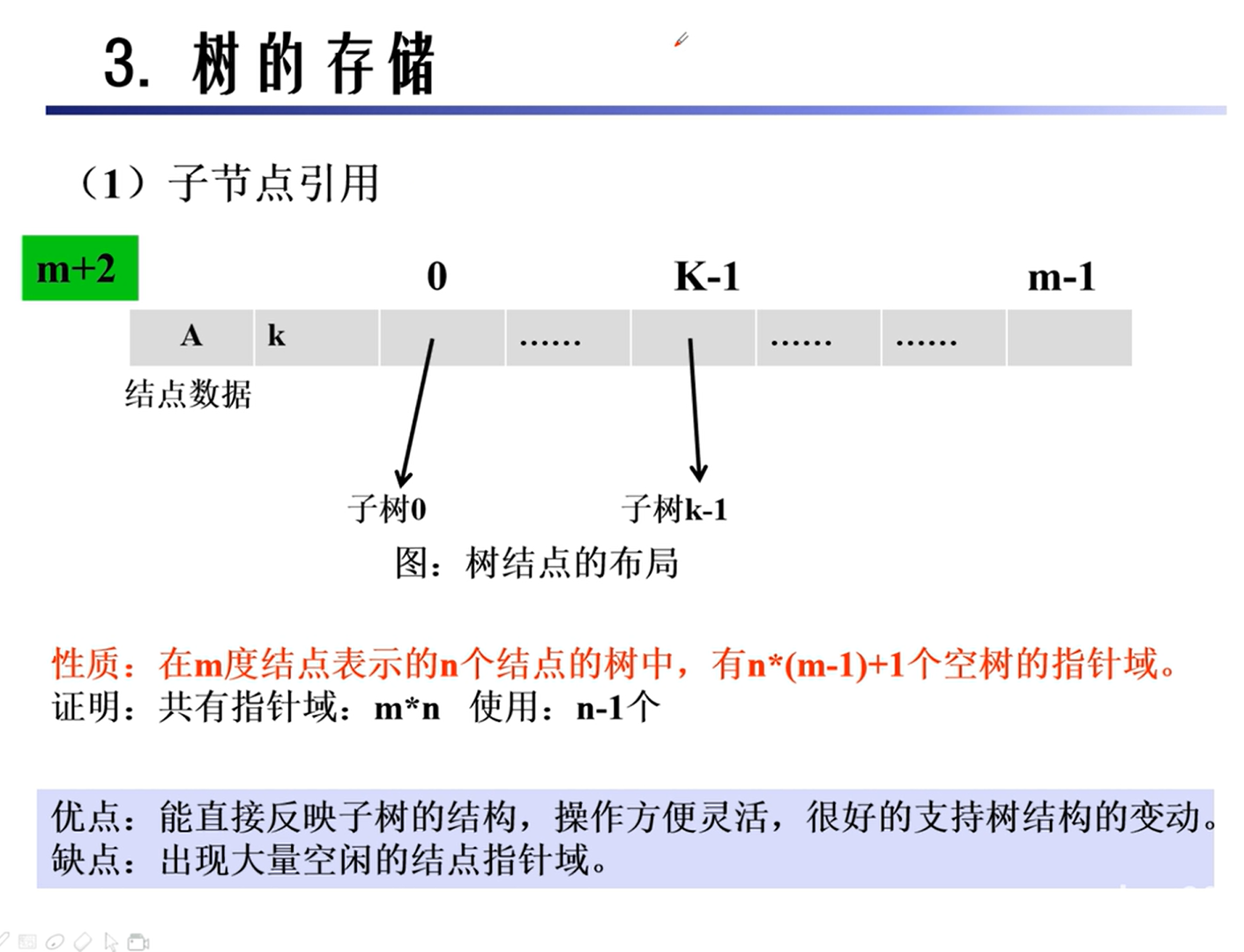
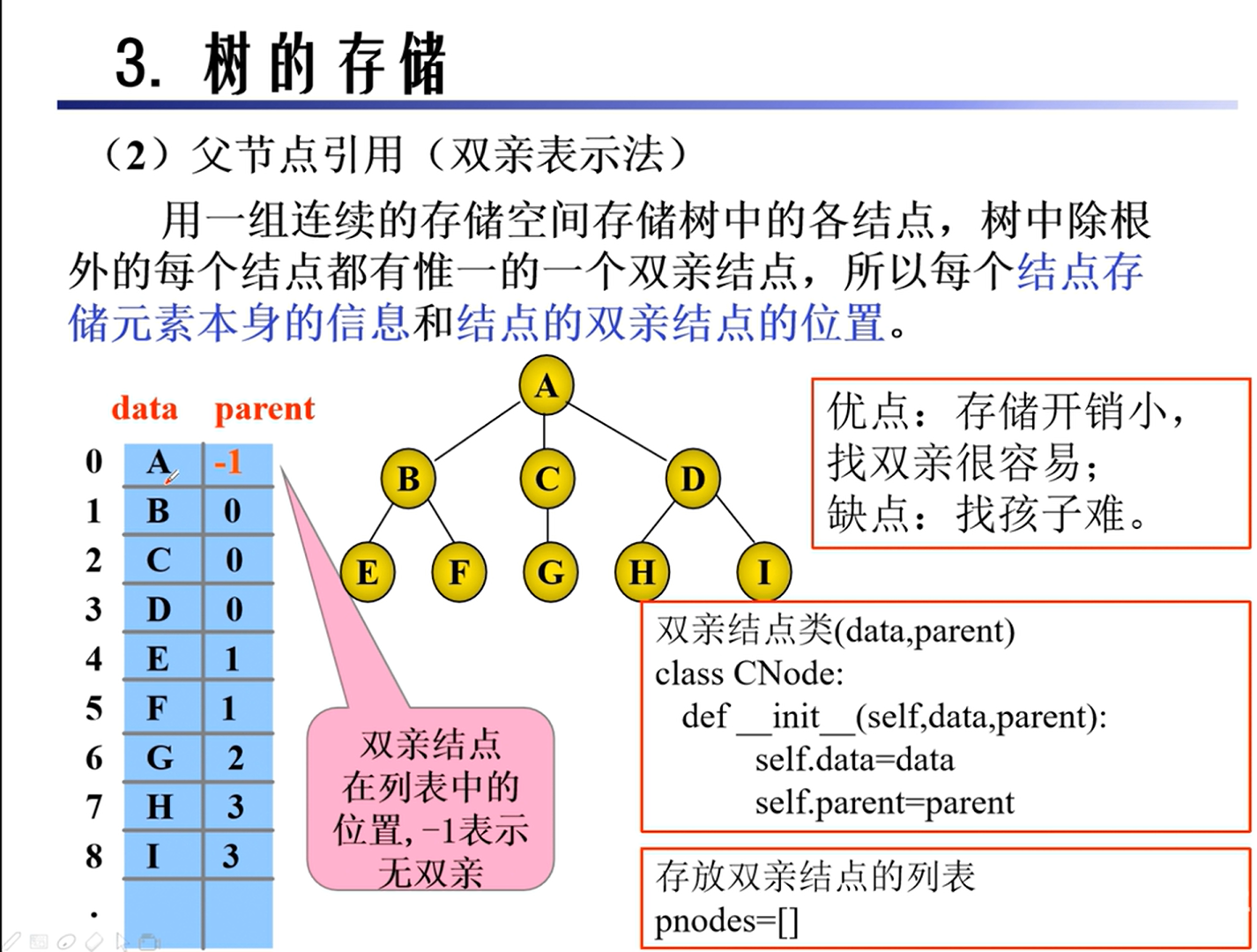
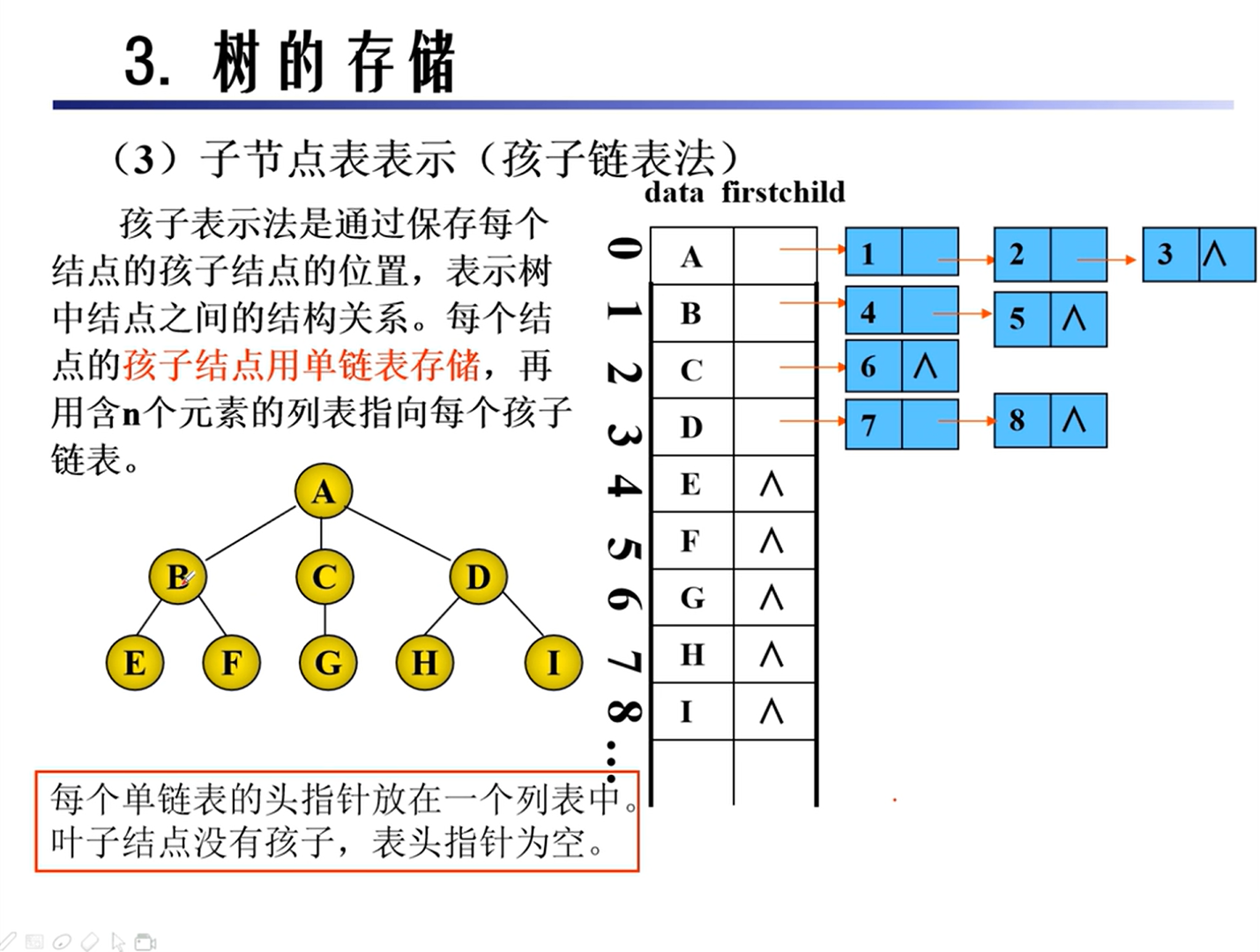
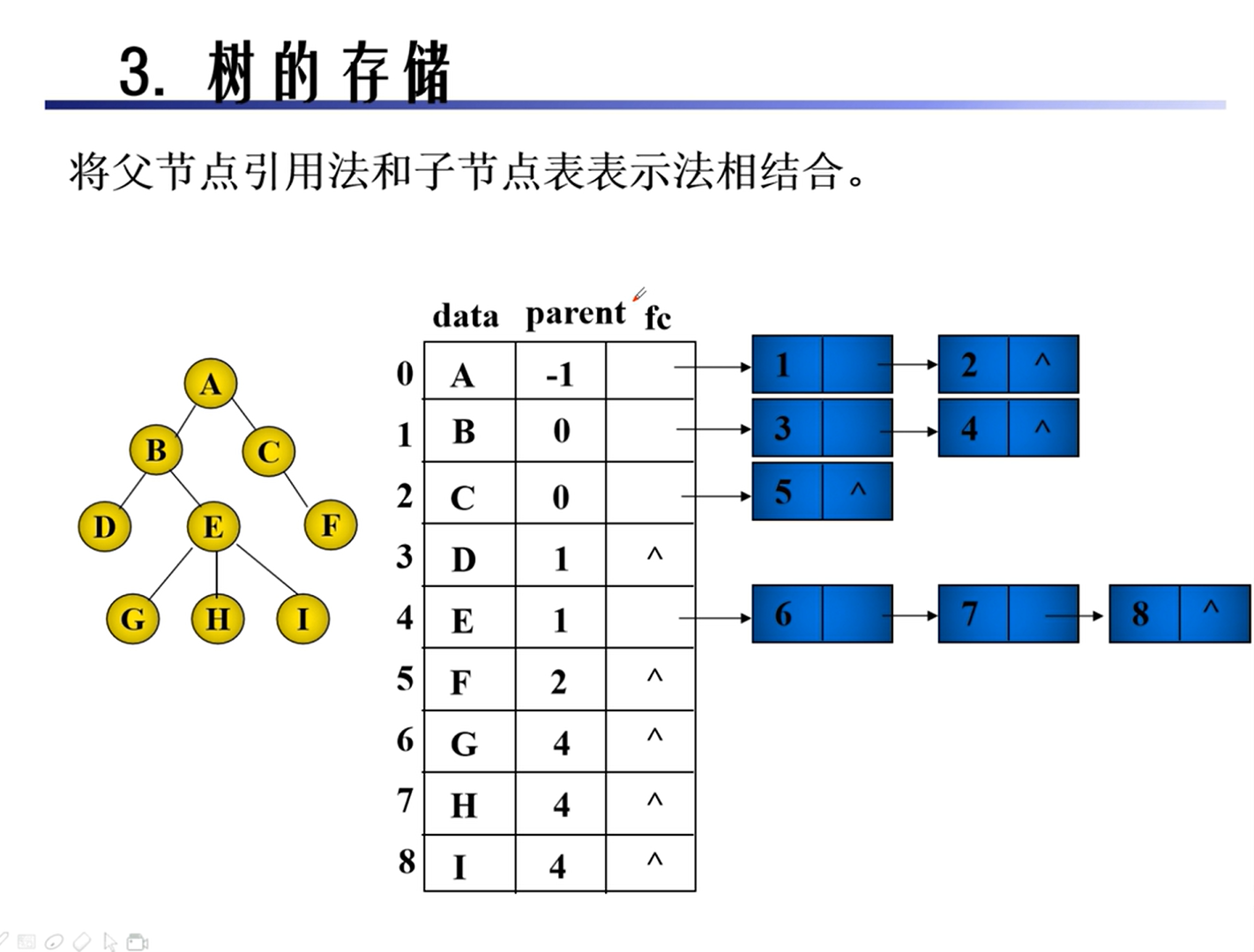
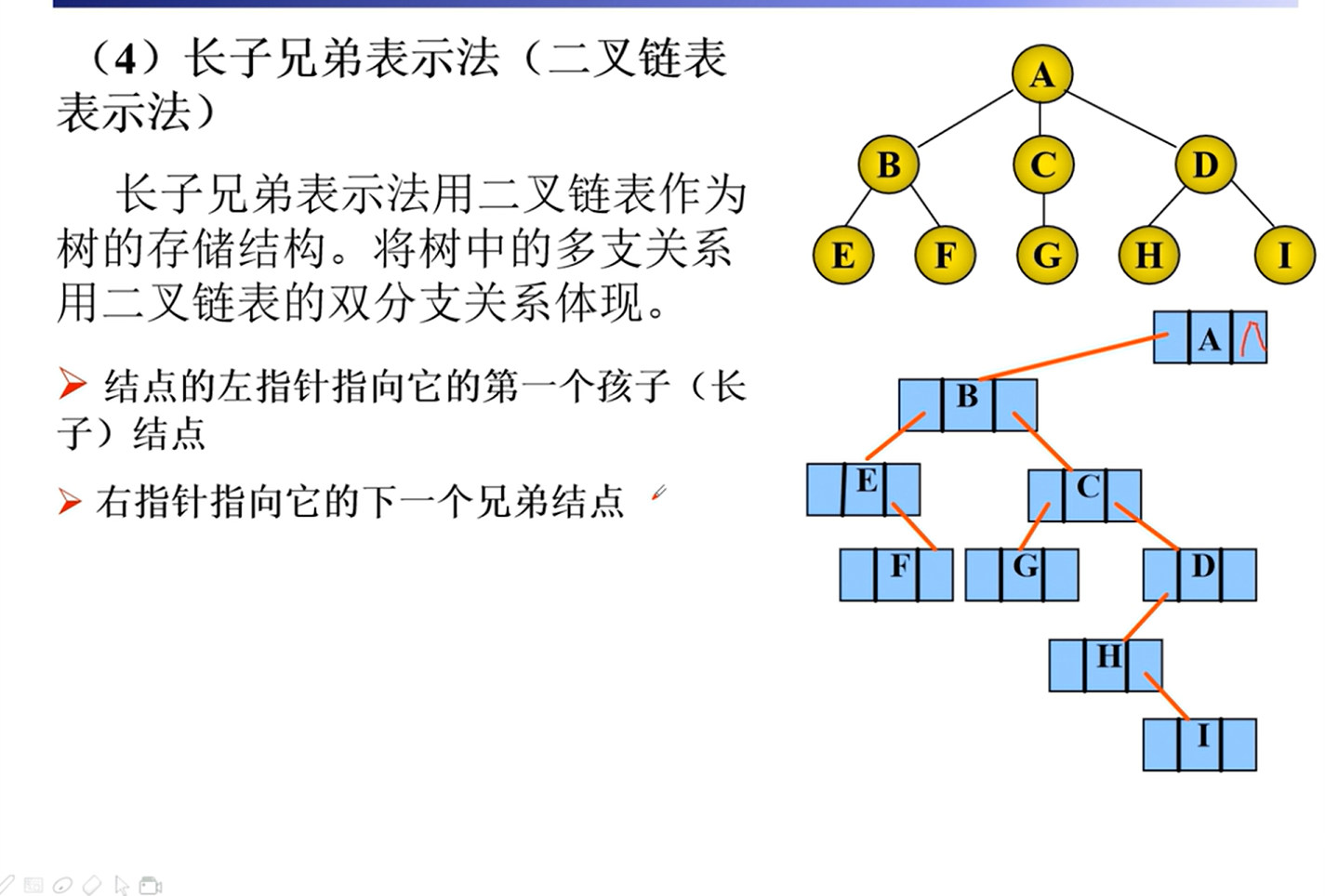
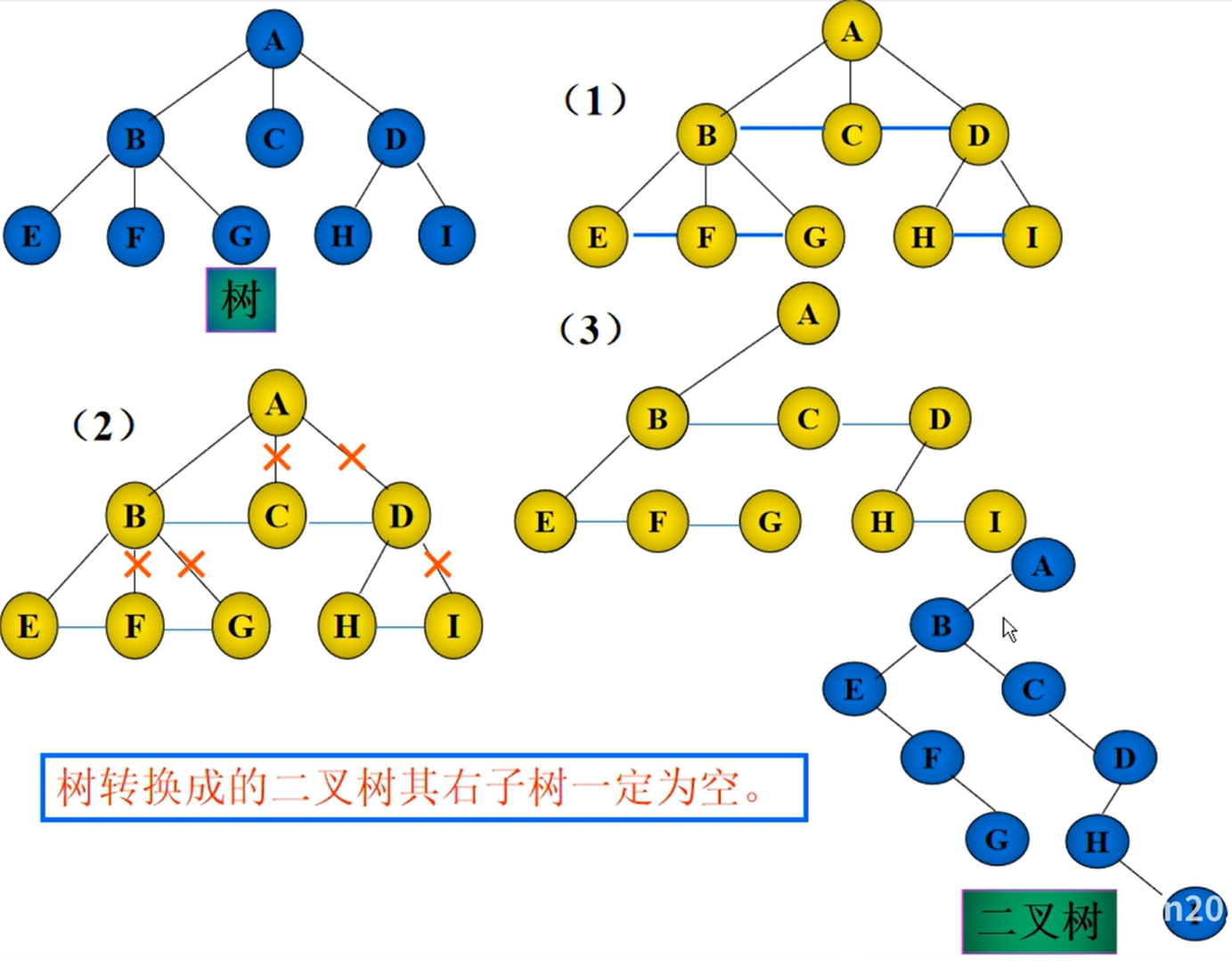
二叉树的转换


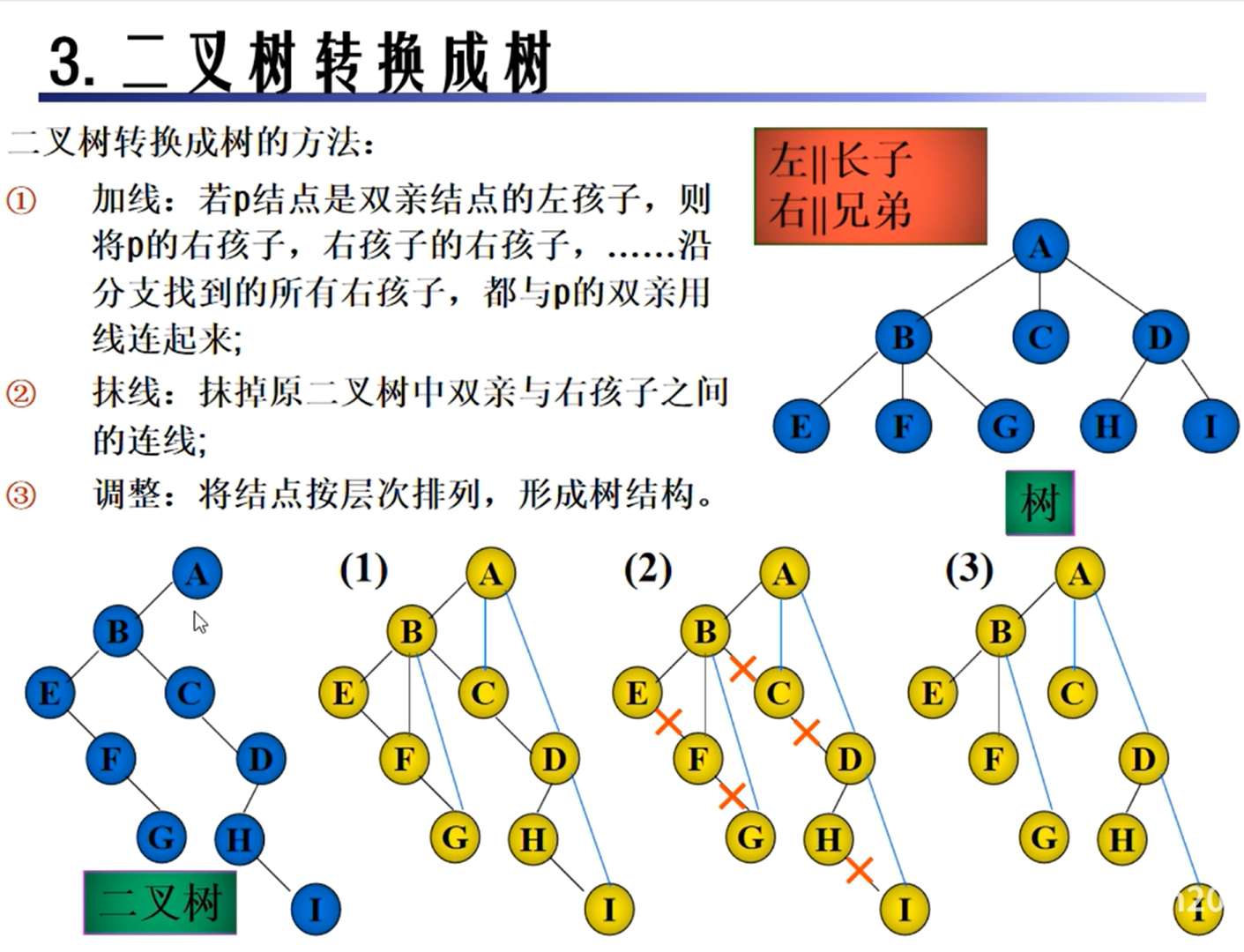
树和森林的转换
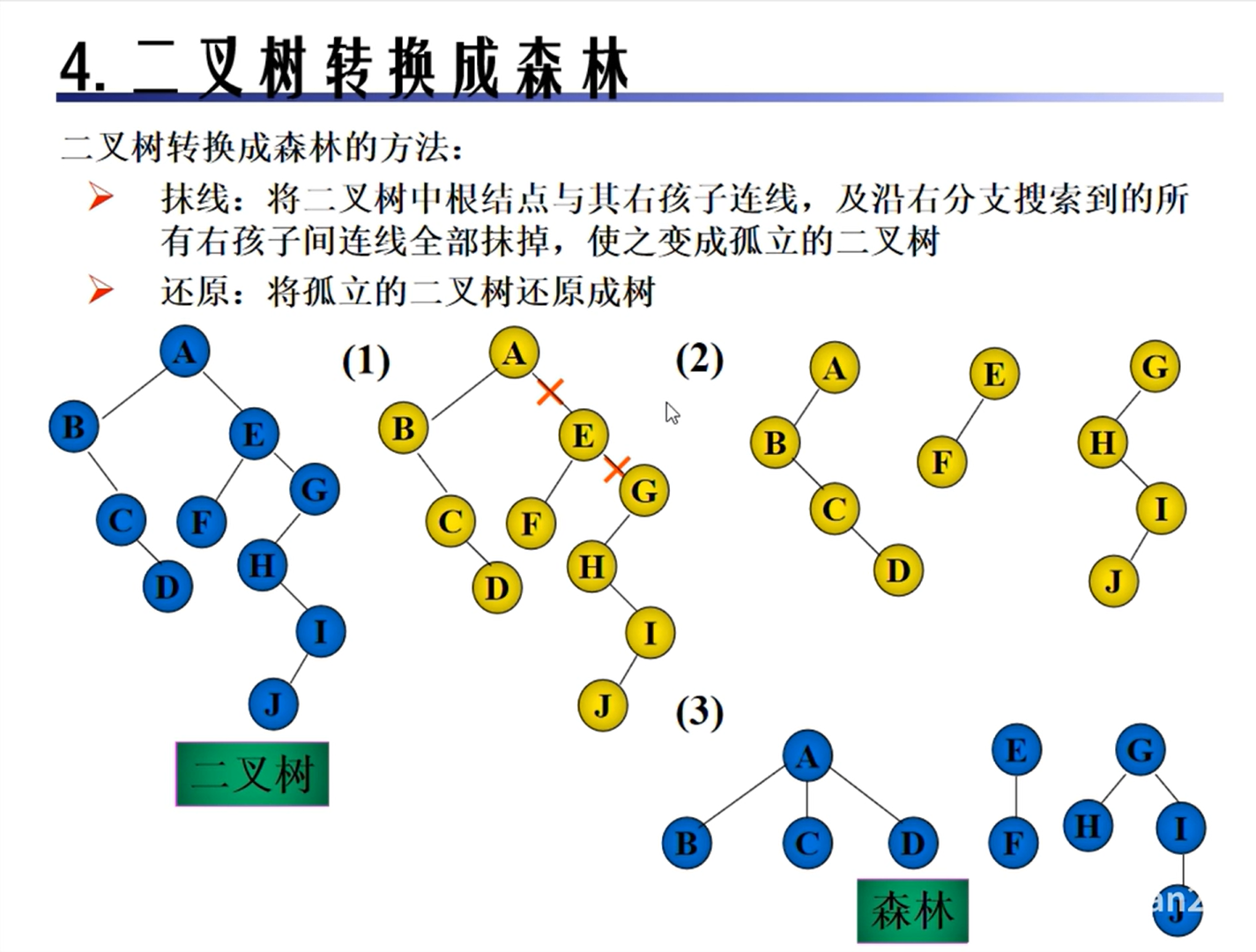
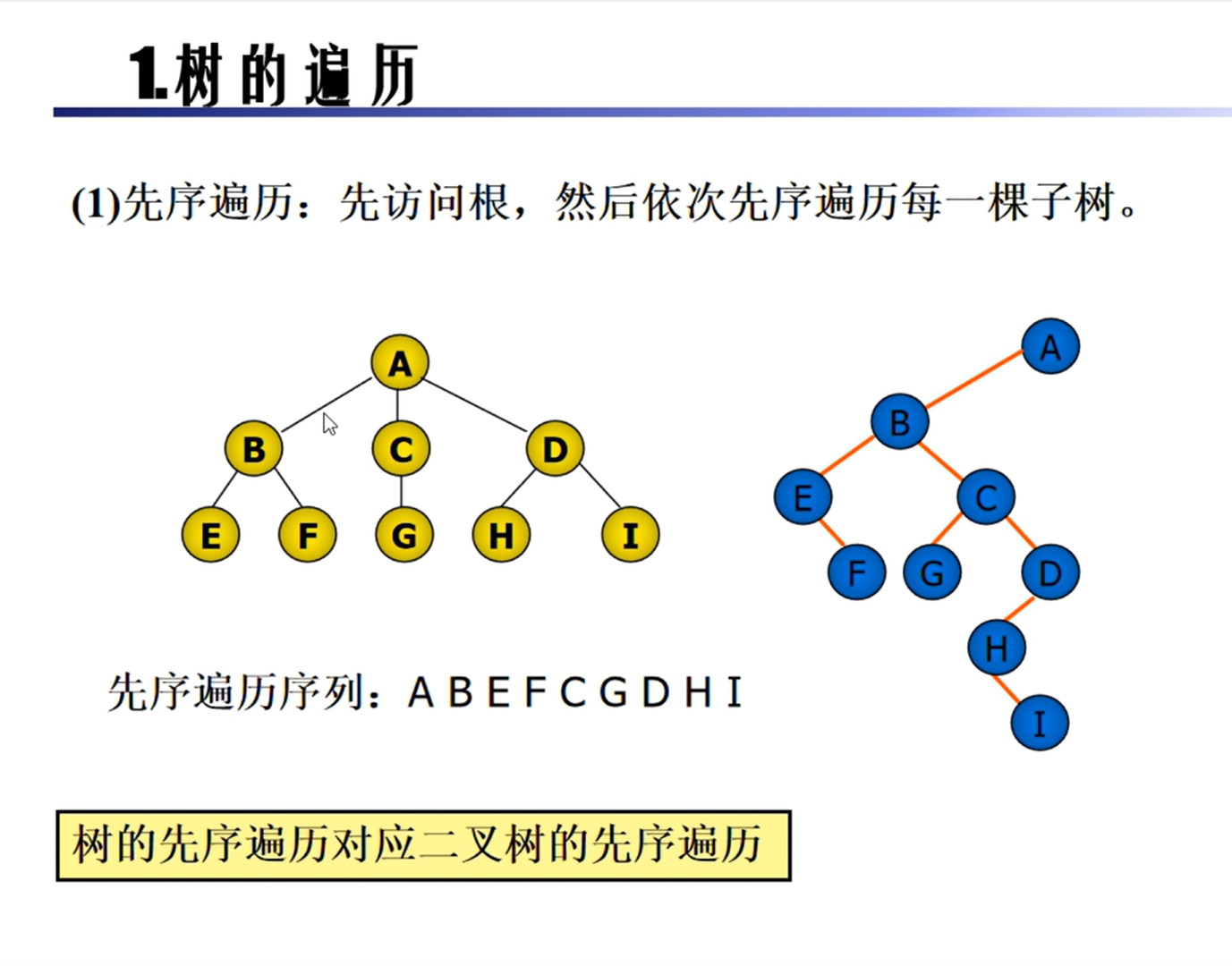
树的遍历
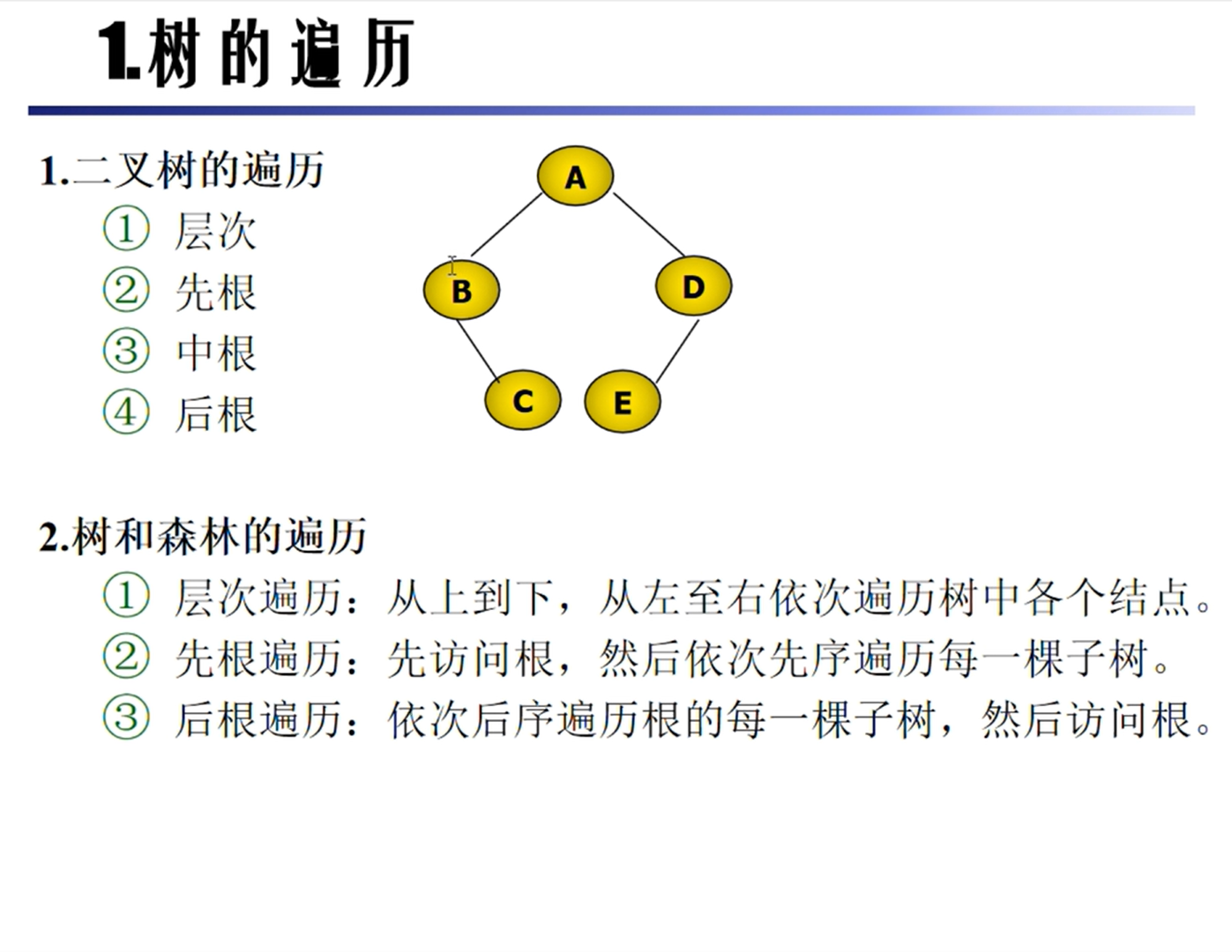
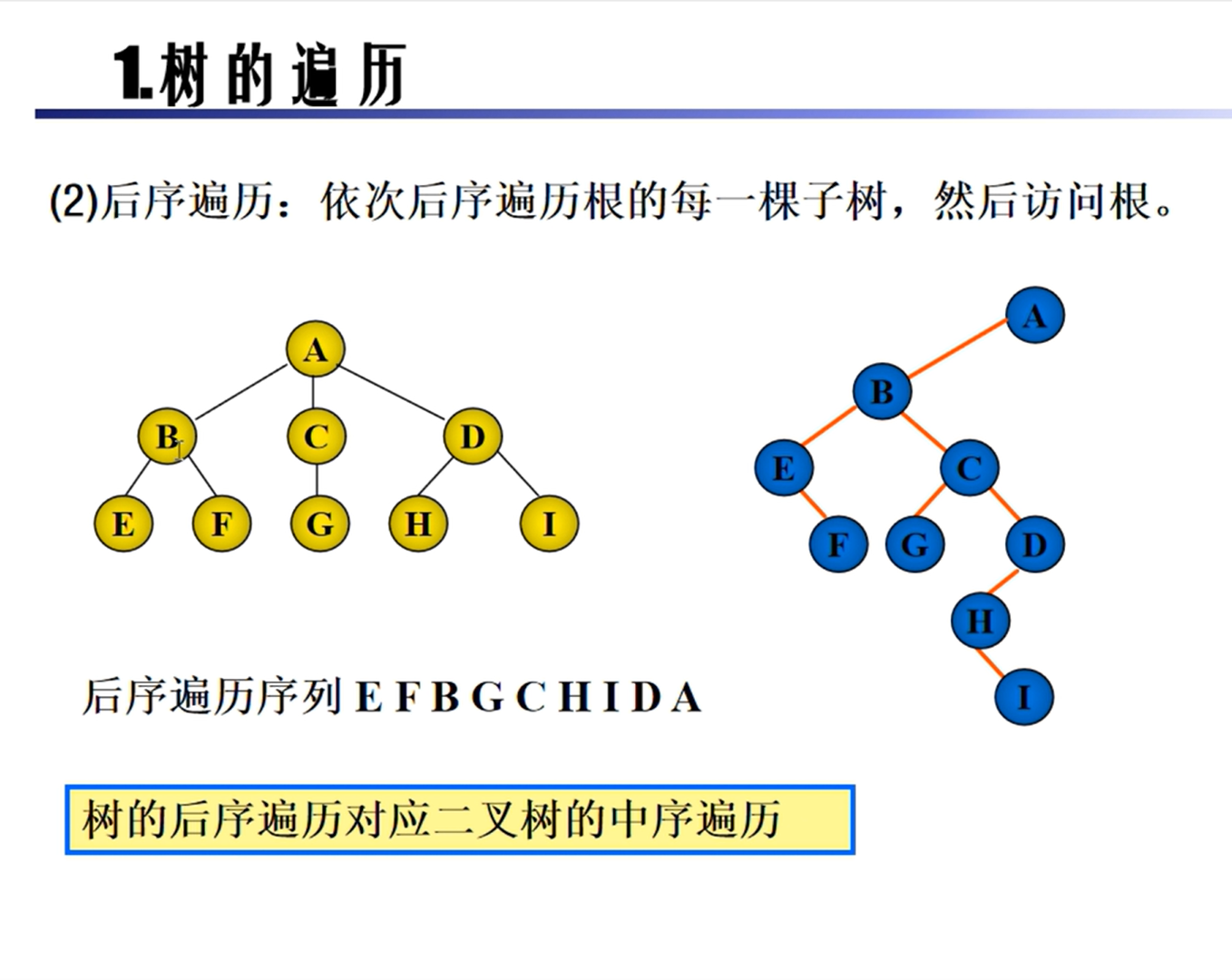
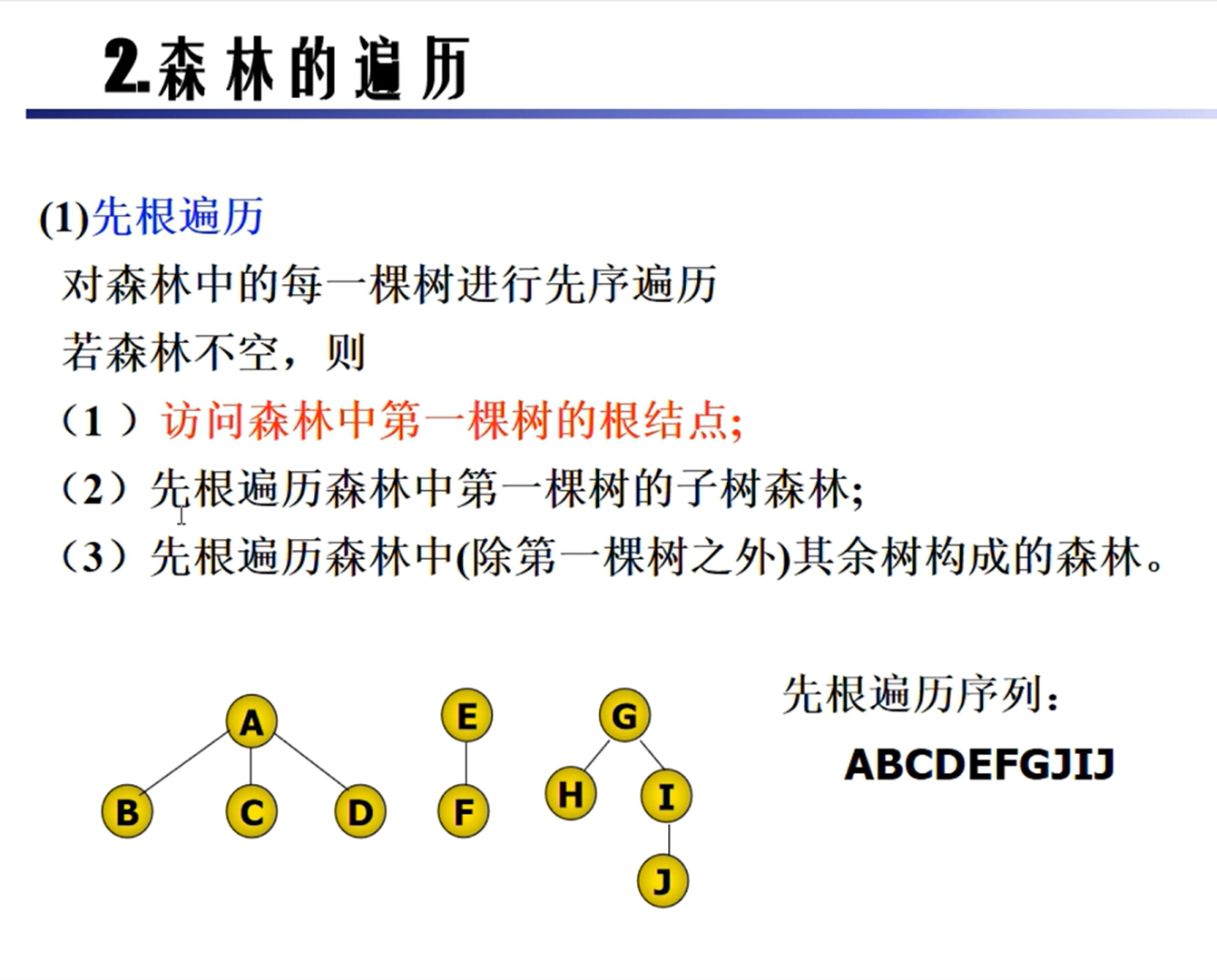
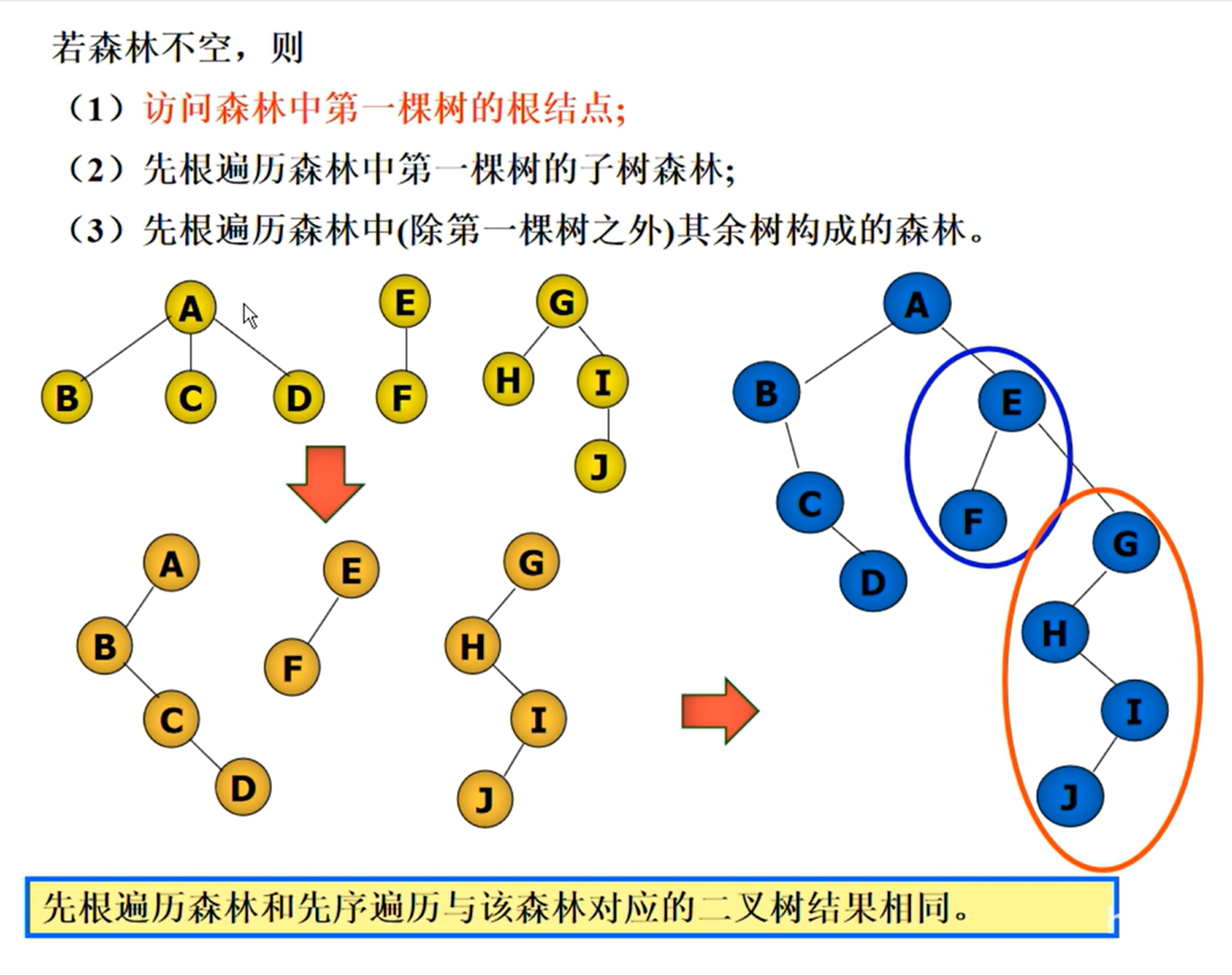
森林的遍历
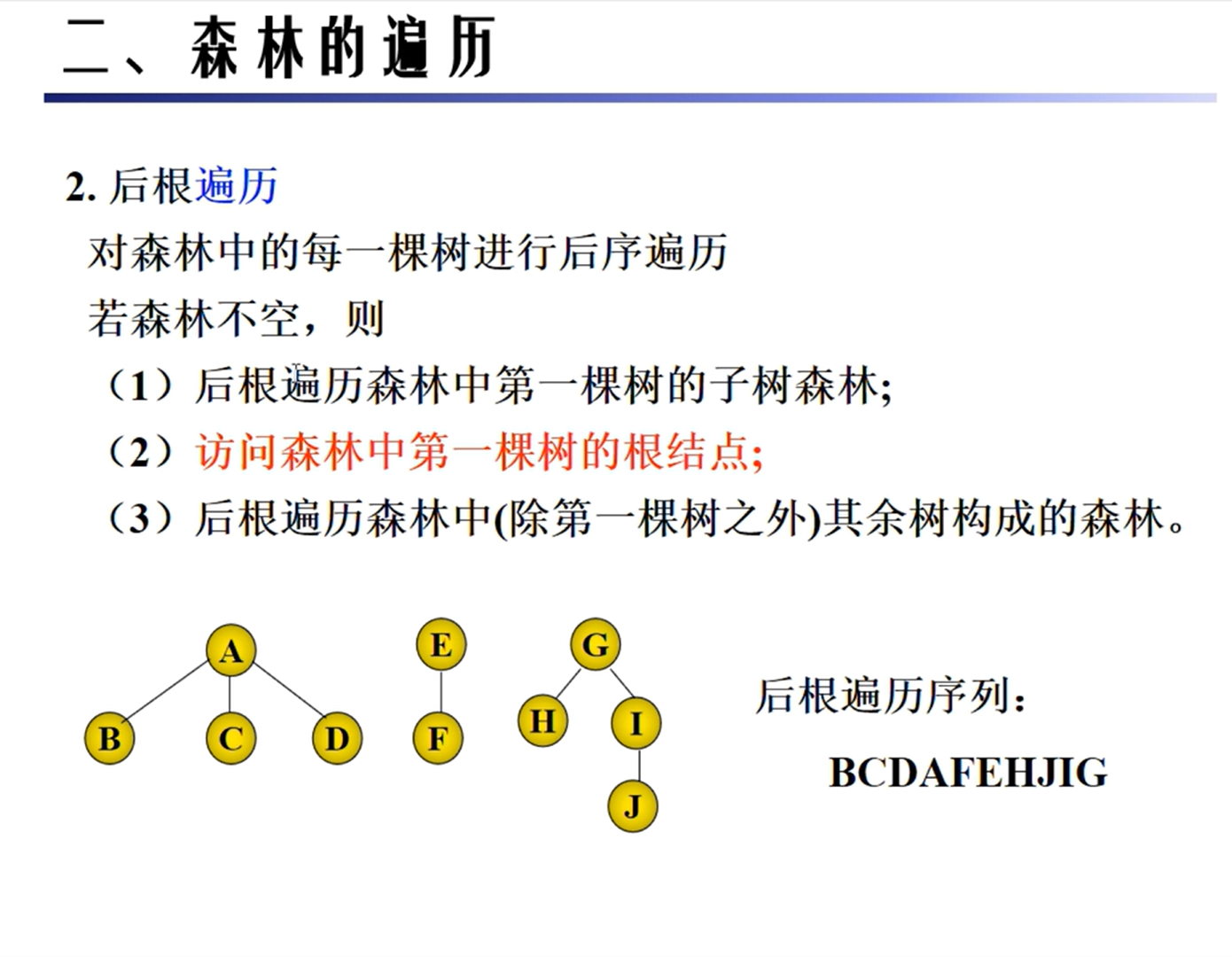
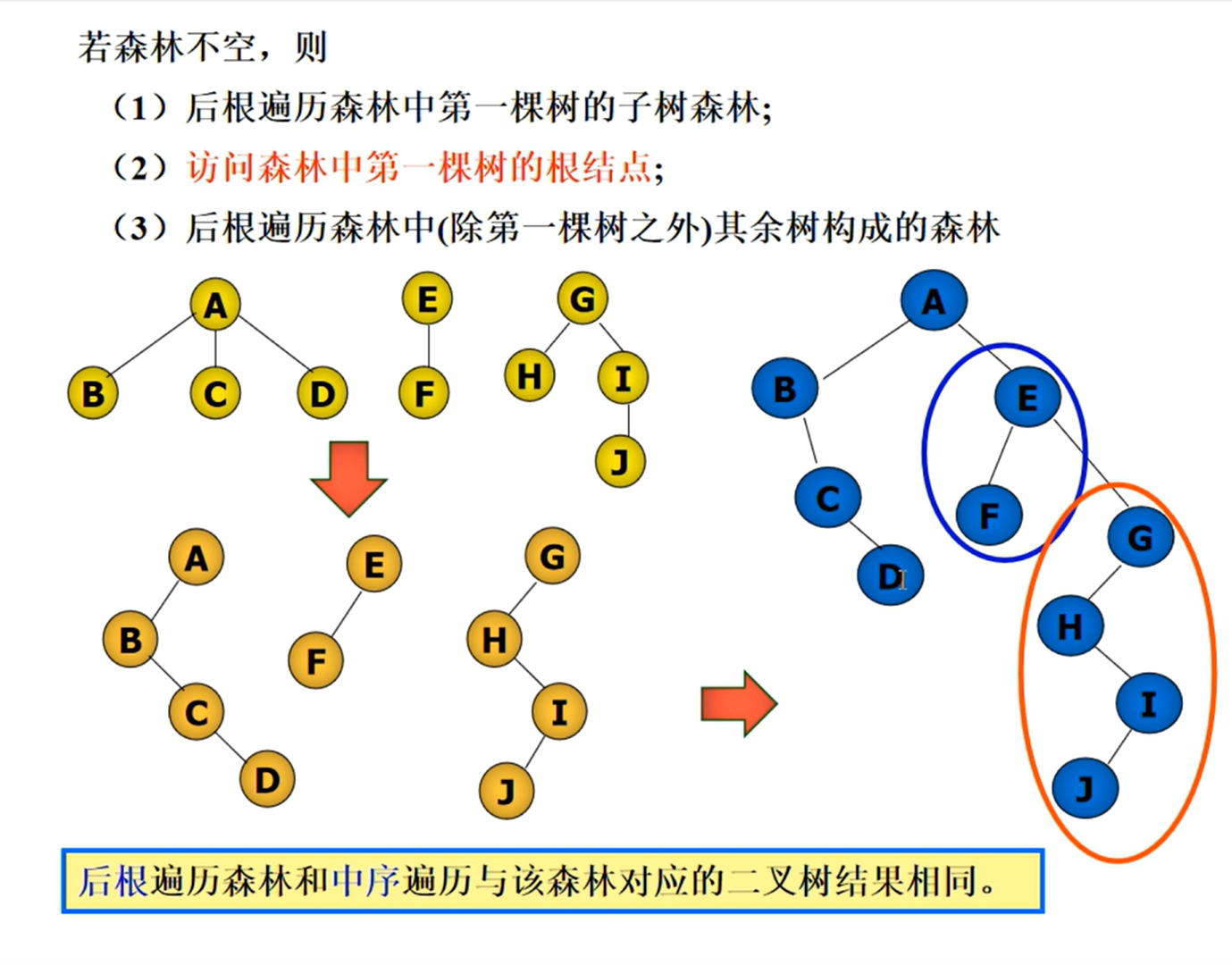
KMP匹配算法
class Solution:def strStr(self, s: str, t: str) -> int:'''KMP模板'''def prefix_function(s): n = len(s)pi = [0] * nj = 0for i in range(1, n):while j>0 and s[i] != s[j]: # 当前位置s[i]与s[j]不等j = pi[j-1] # j指向之前位置,s[i]与s[j]继续比较if s[i] == s[j]: # s[i]与s[j]相等,j+1,指向后一位j += 1pi[i] = jreturn pi'''主程序'''n, m = len(s), len(t)pi = prefix_function(t) # 预处理得到t的前缀函数'''再次基于KMP的思想在s中匹配t'''j = 0for i in range(n):while j>0 and s[i] != t[j]:j = pi[j-1]if s[i] == t[j]:j += 1if j == m: # 匹配到了t,直接返回return i-m+1return -1
图
基本概念
图的定义
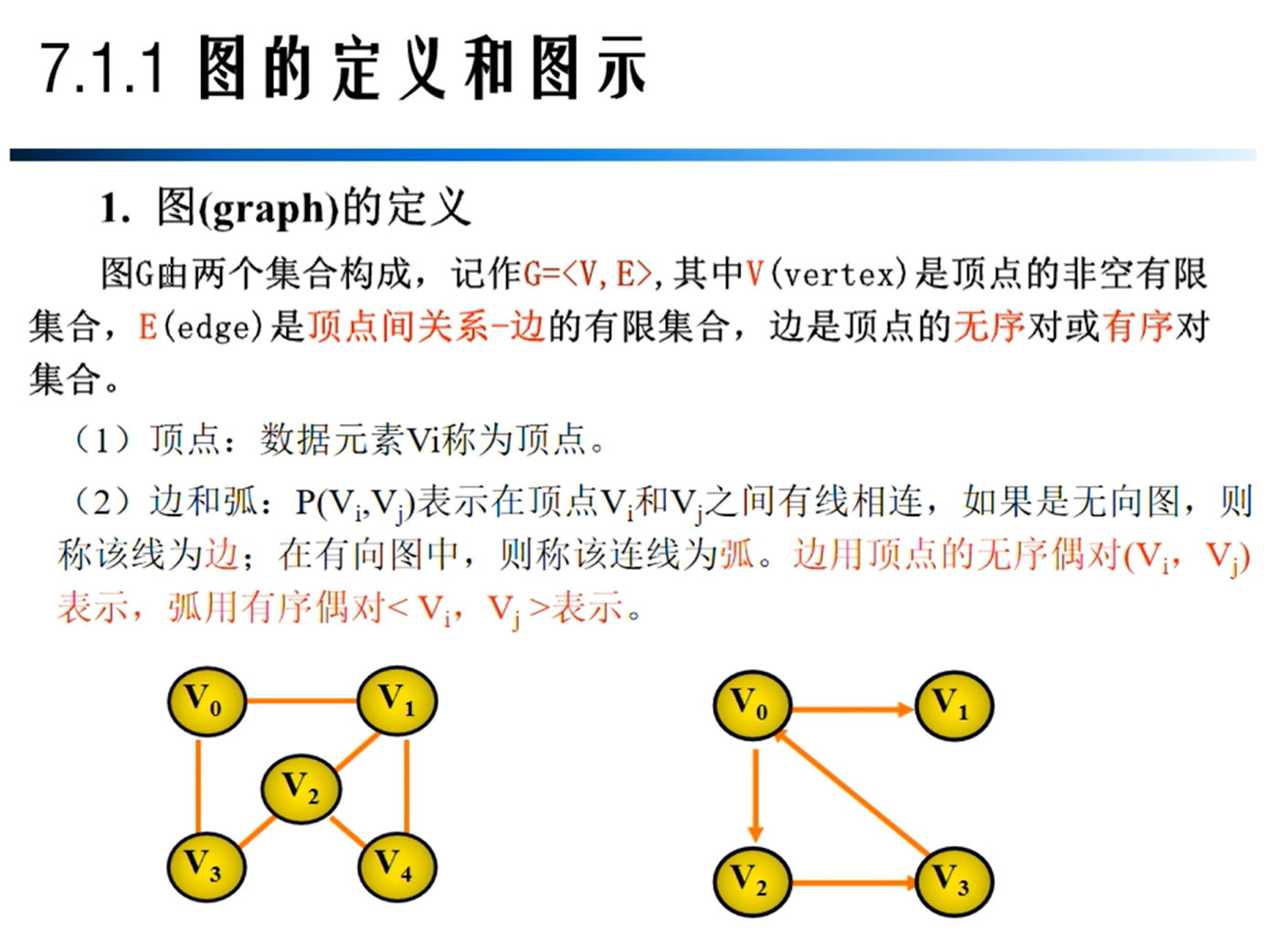

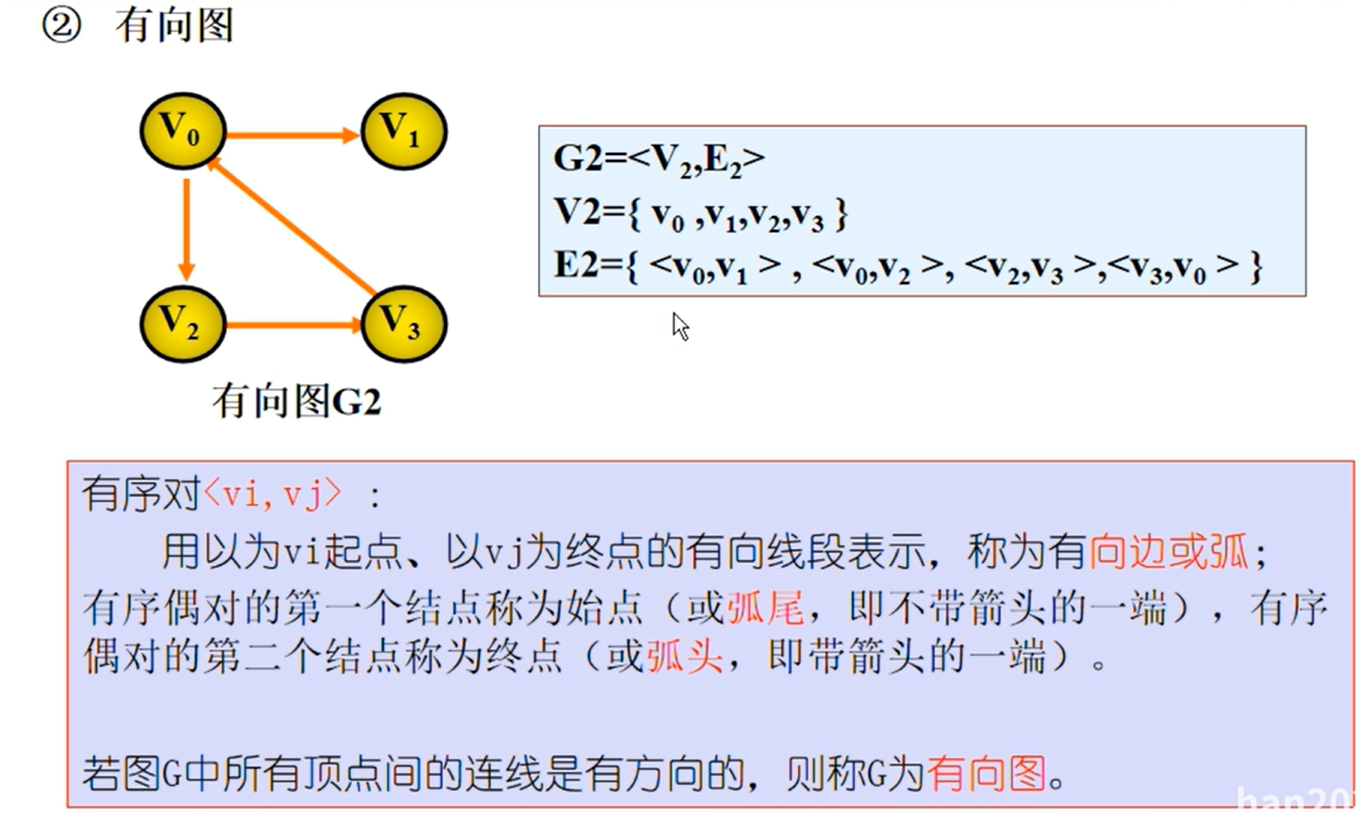
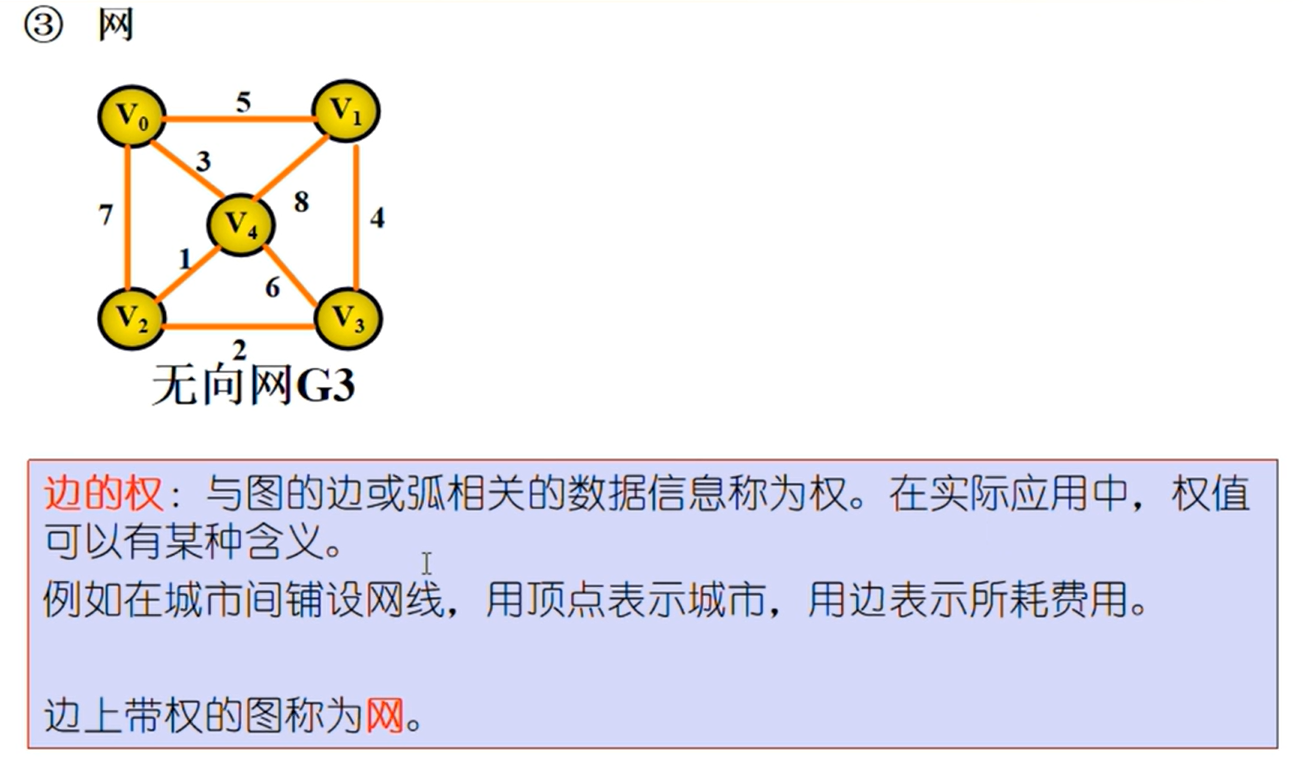
图的相关概念
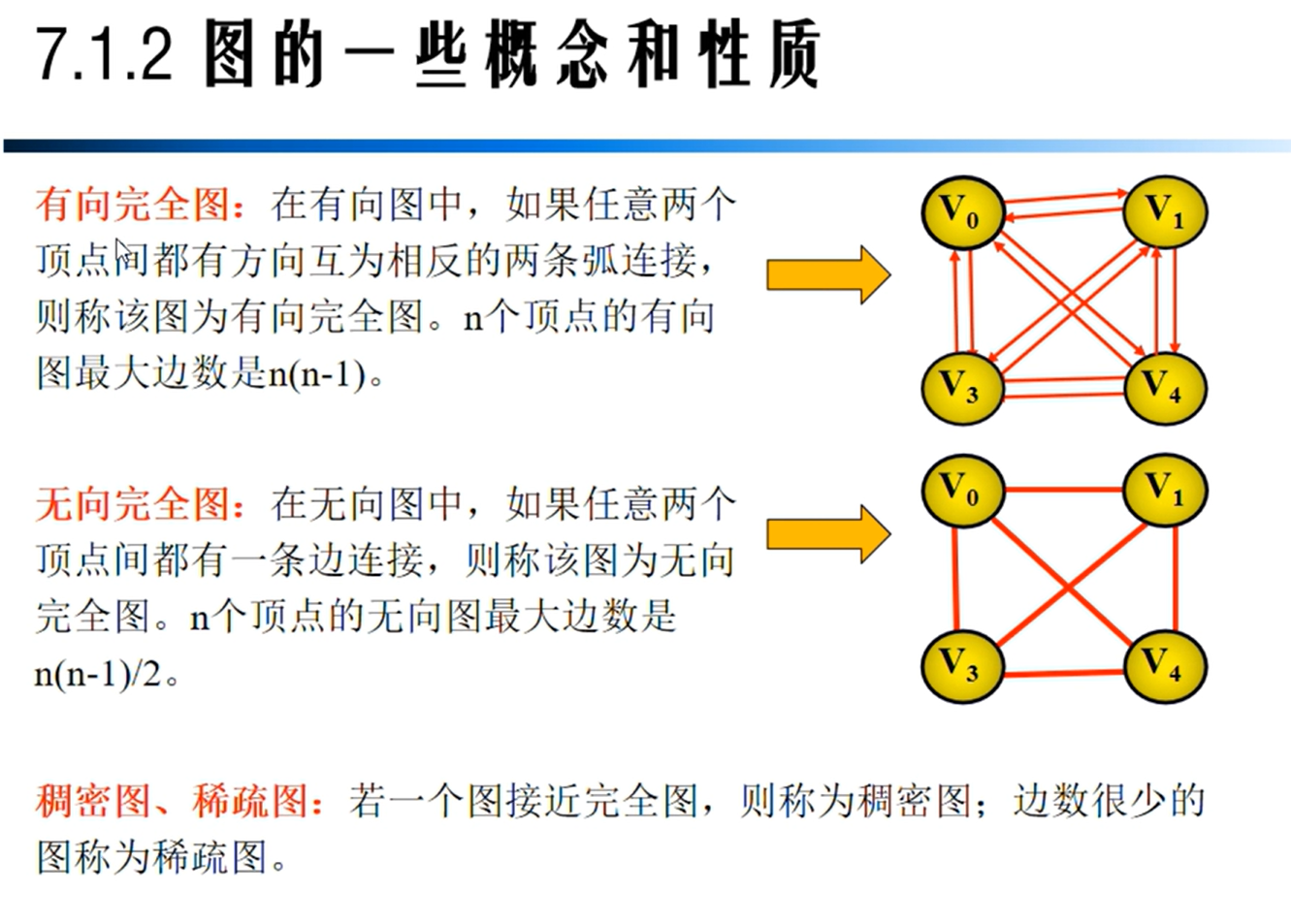
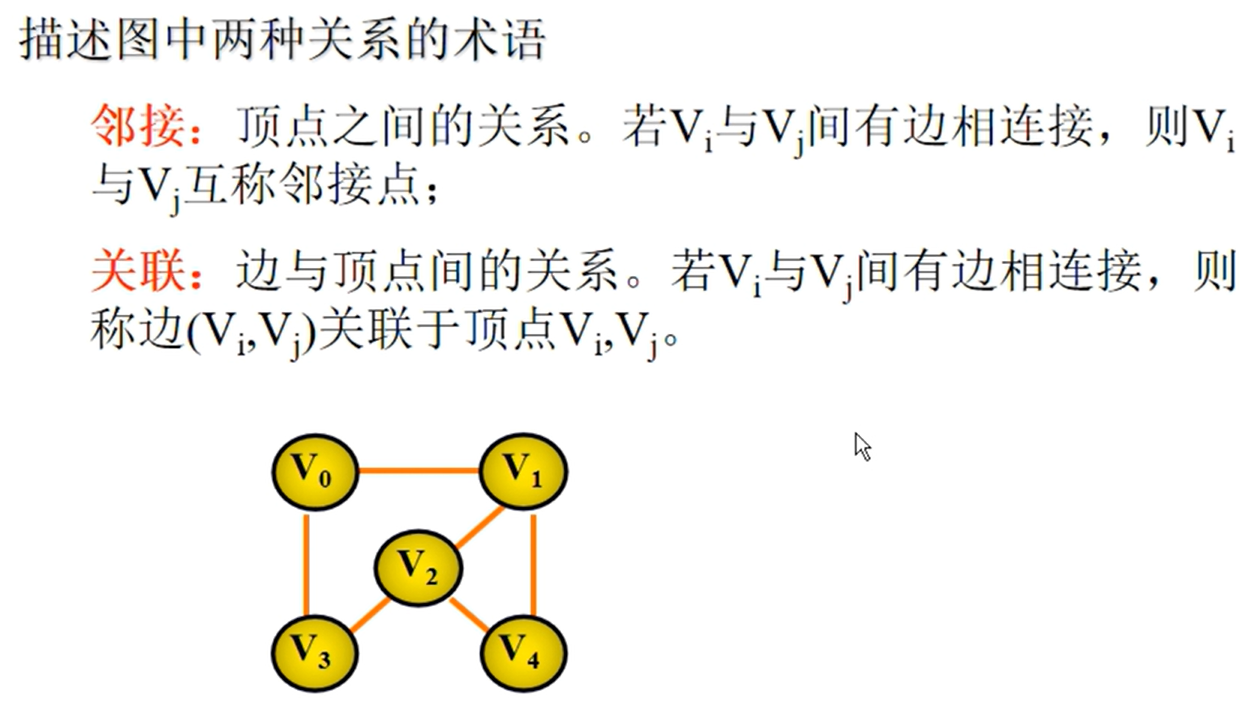
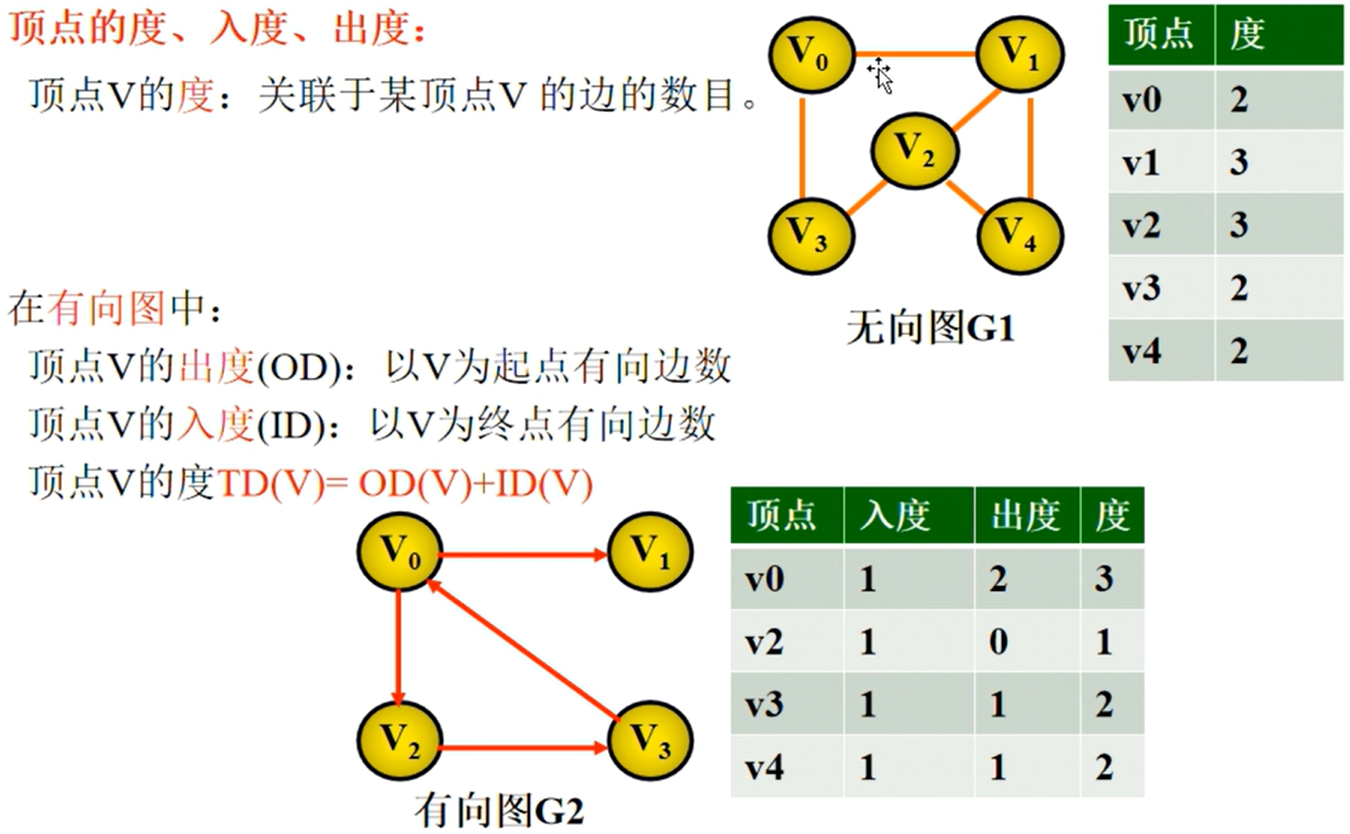
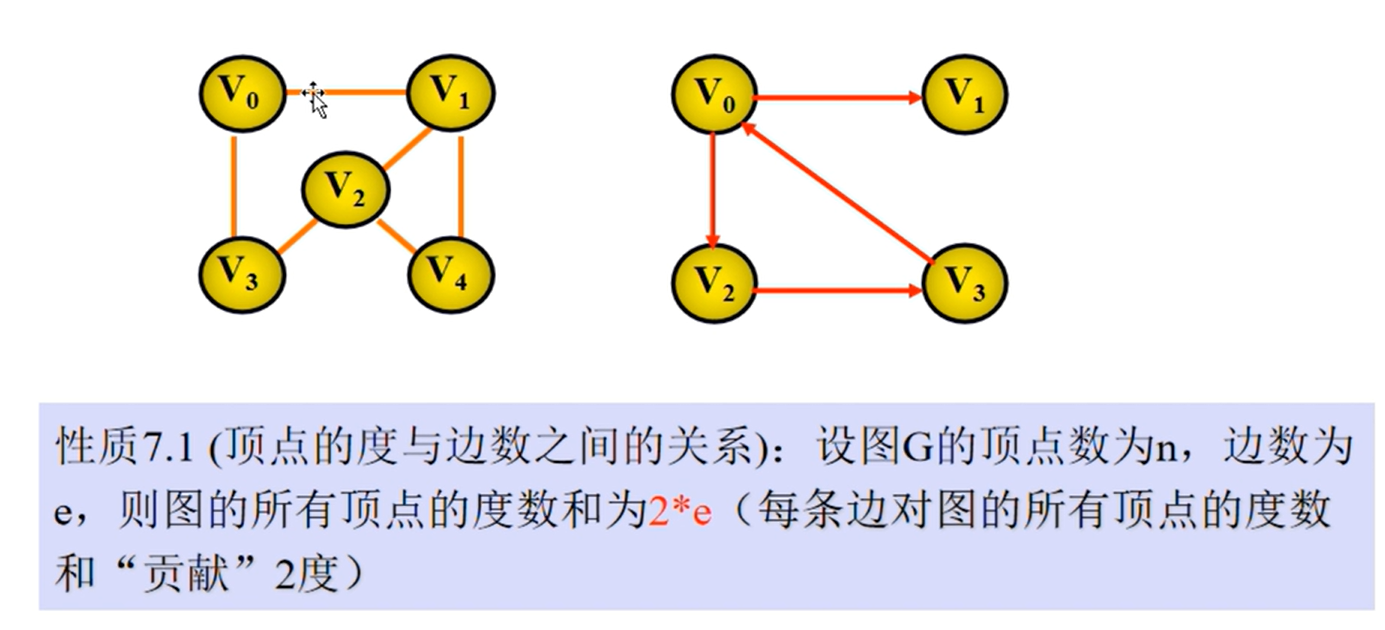
图的相关性质
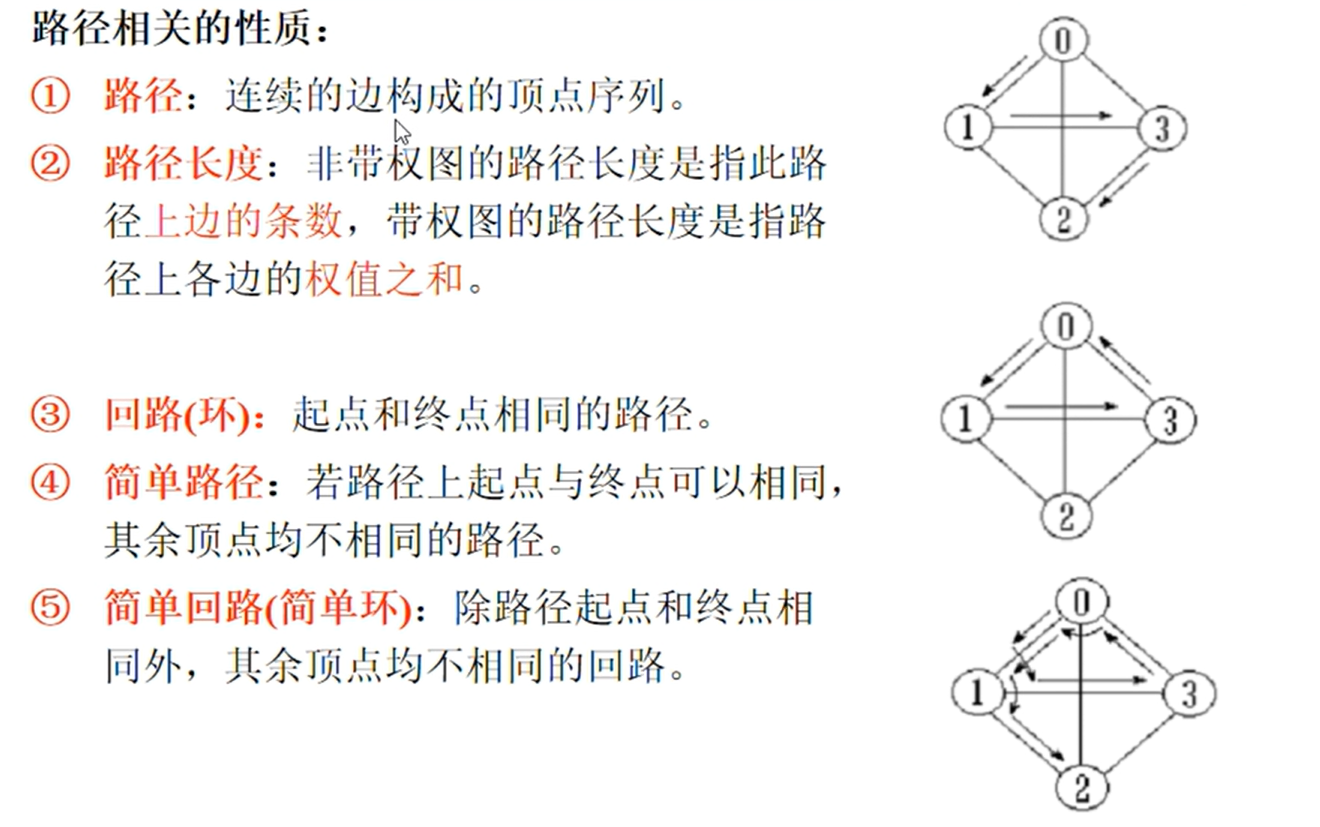
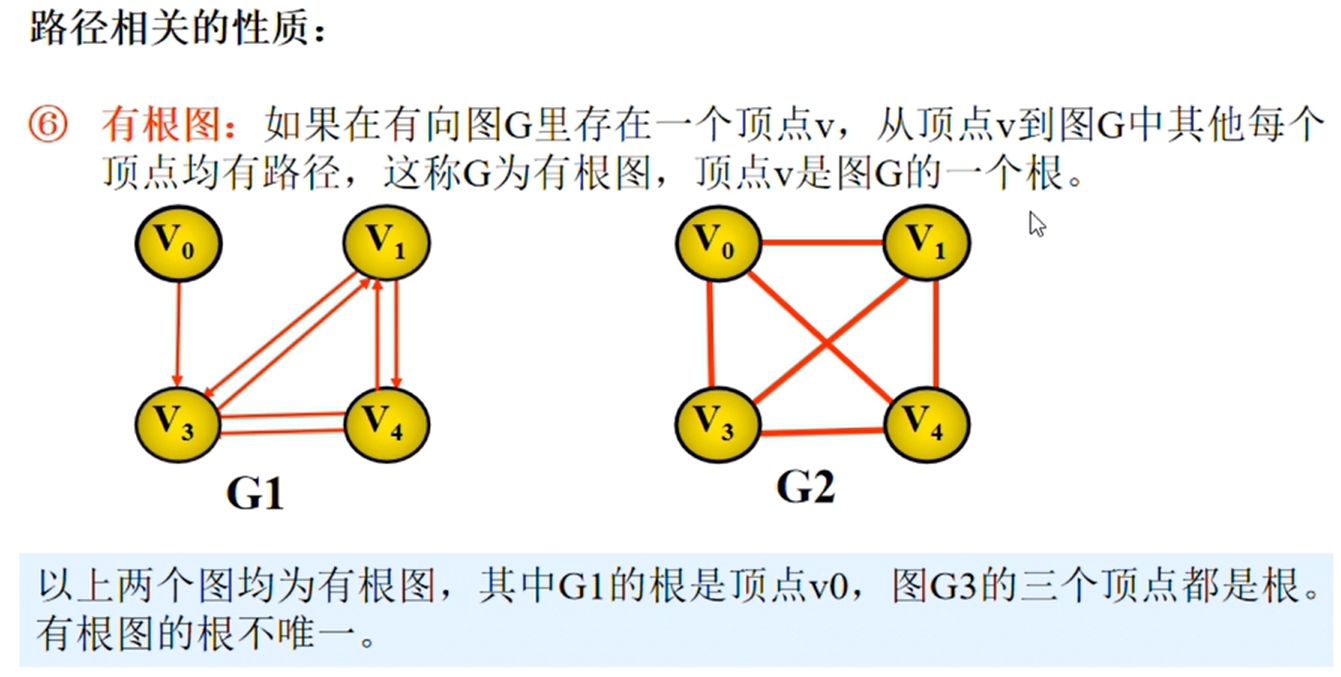
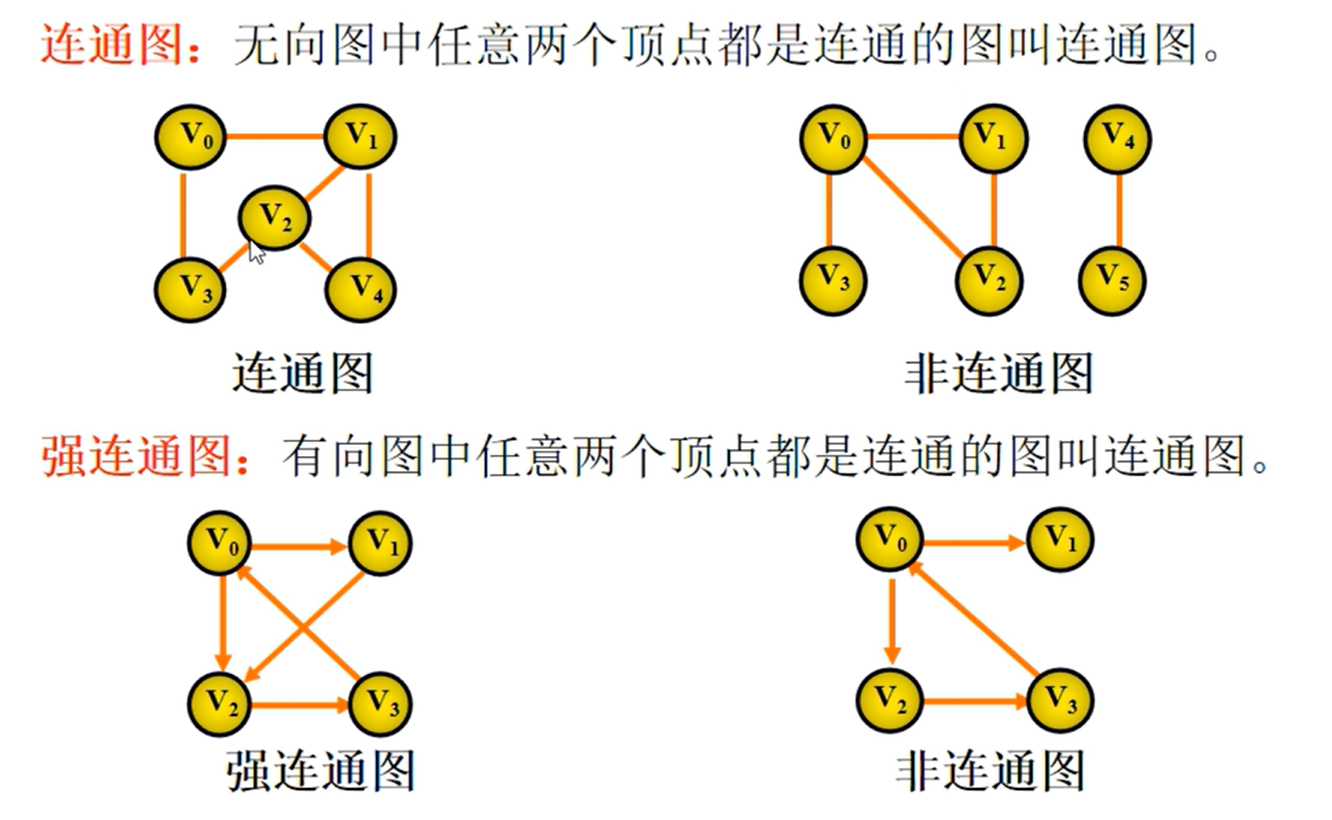
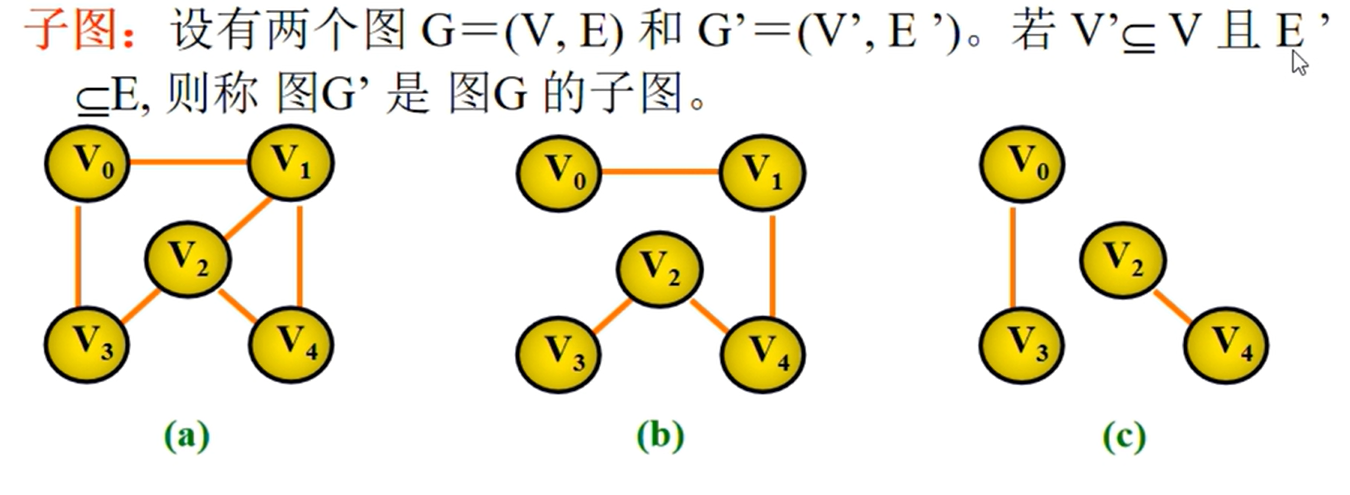
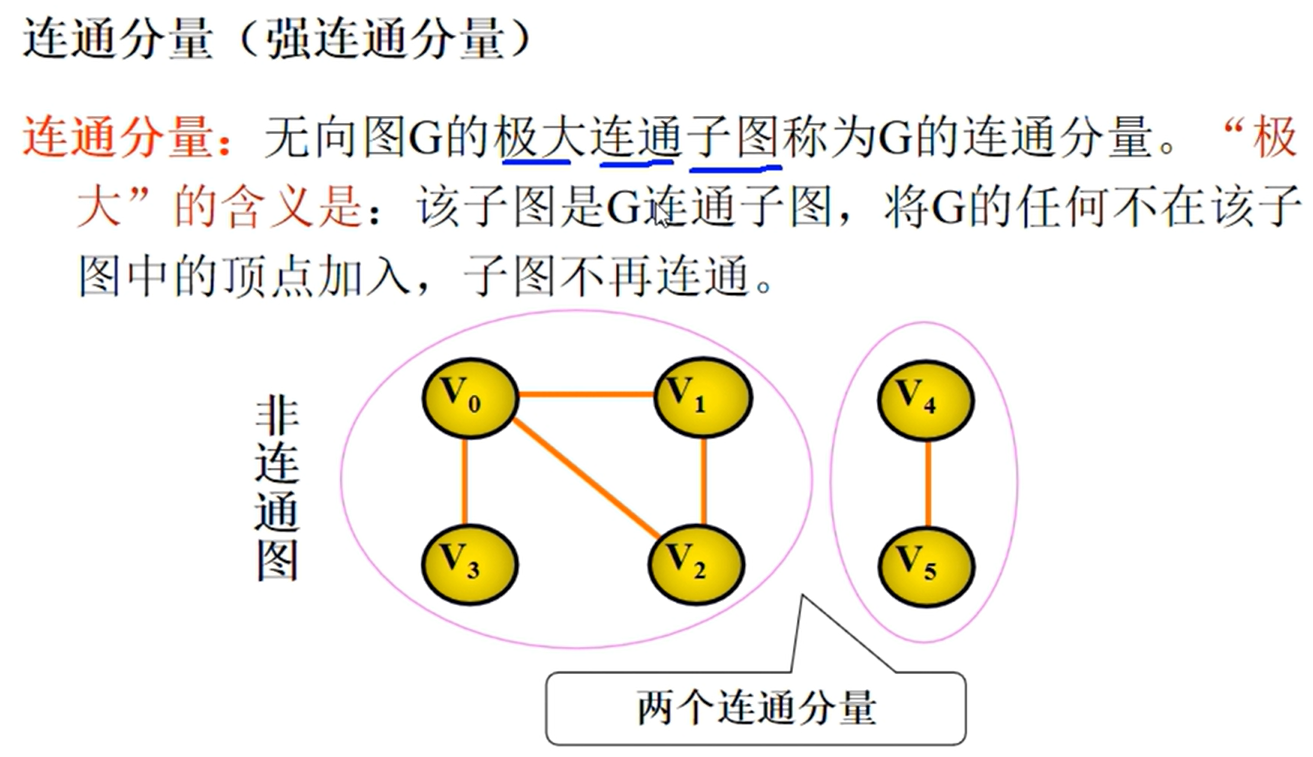
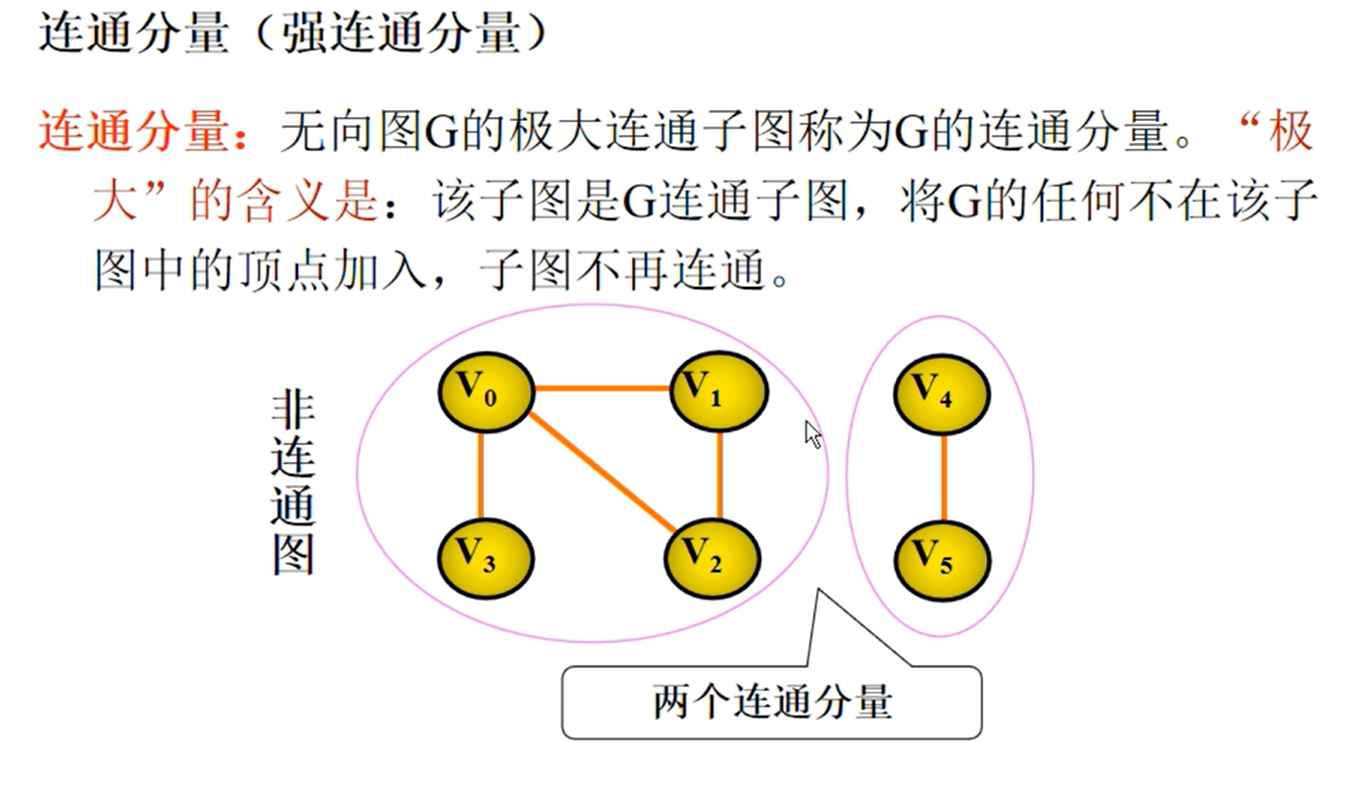
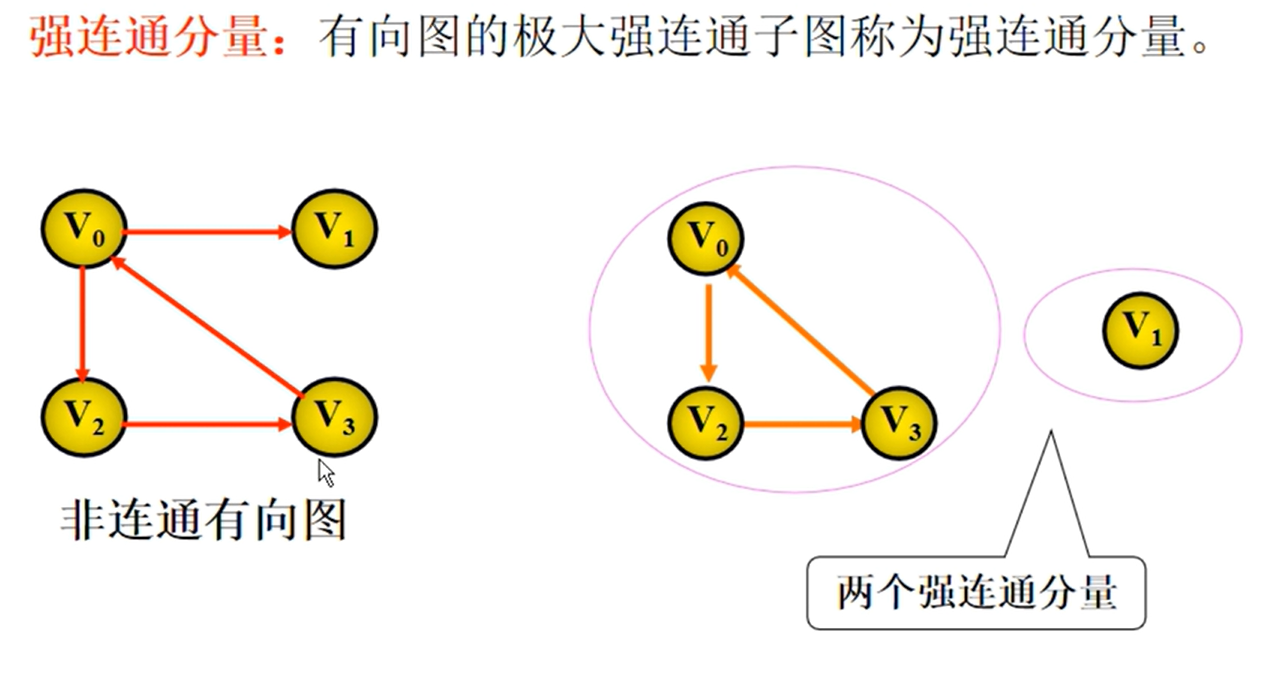
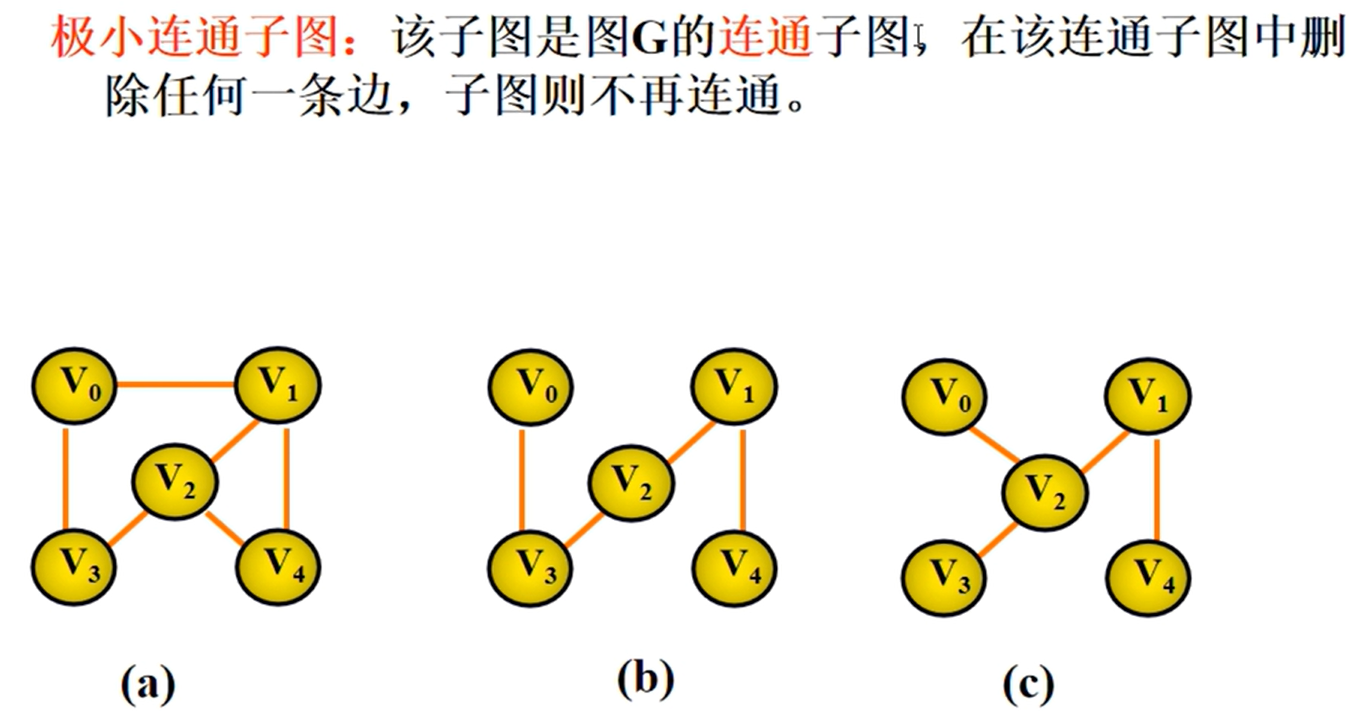
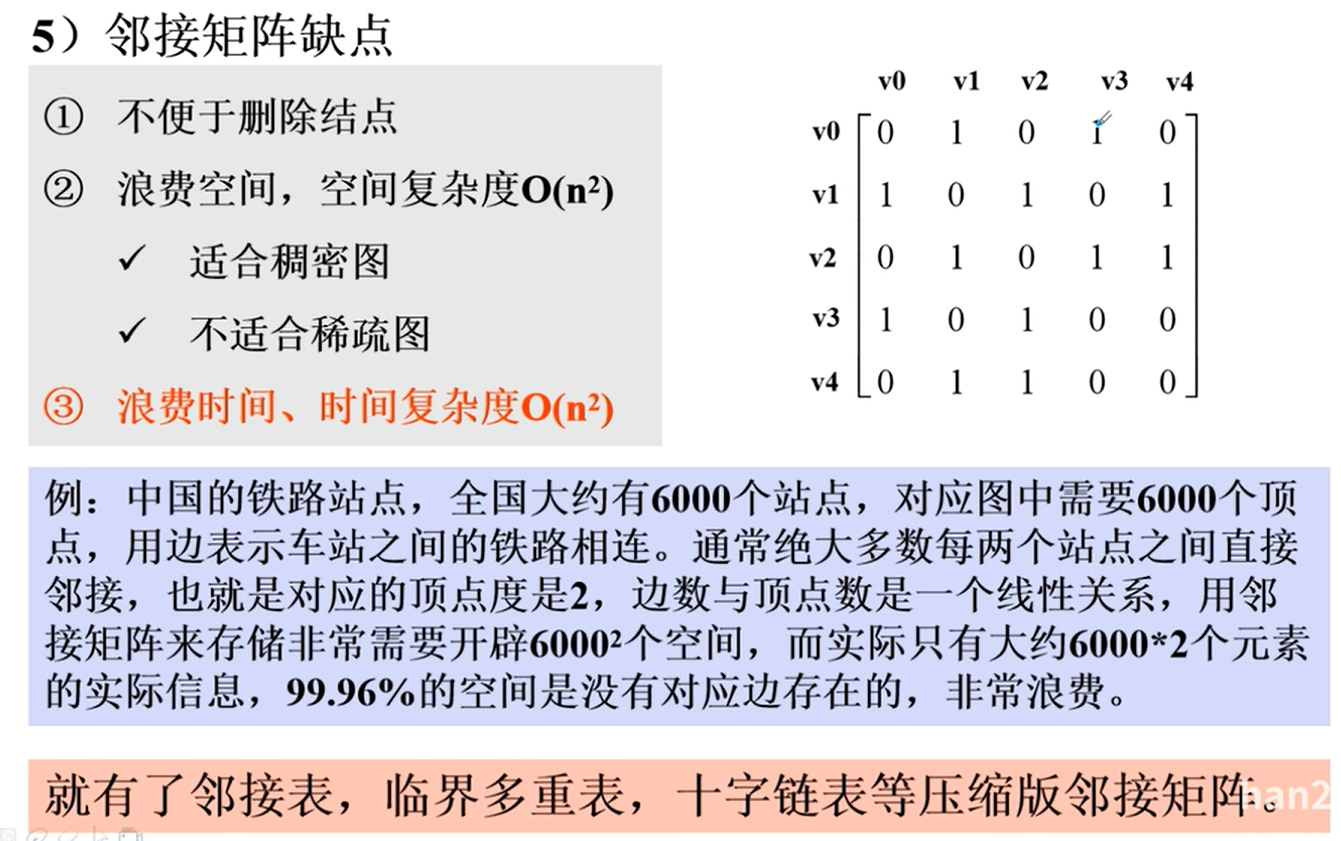
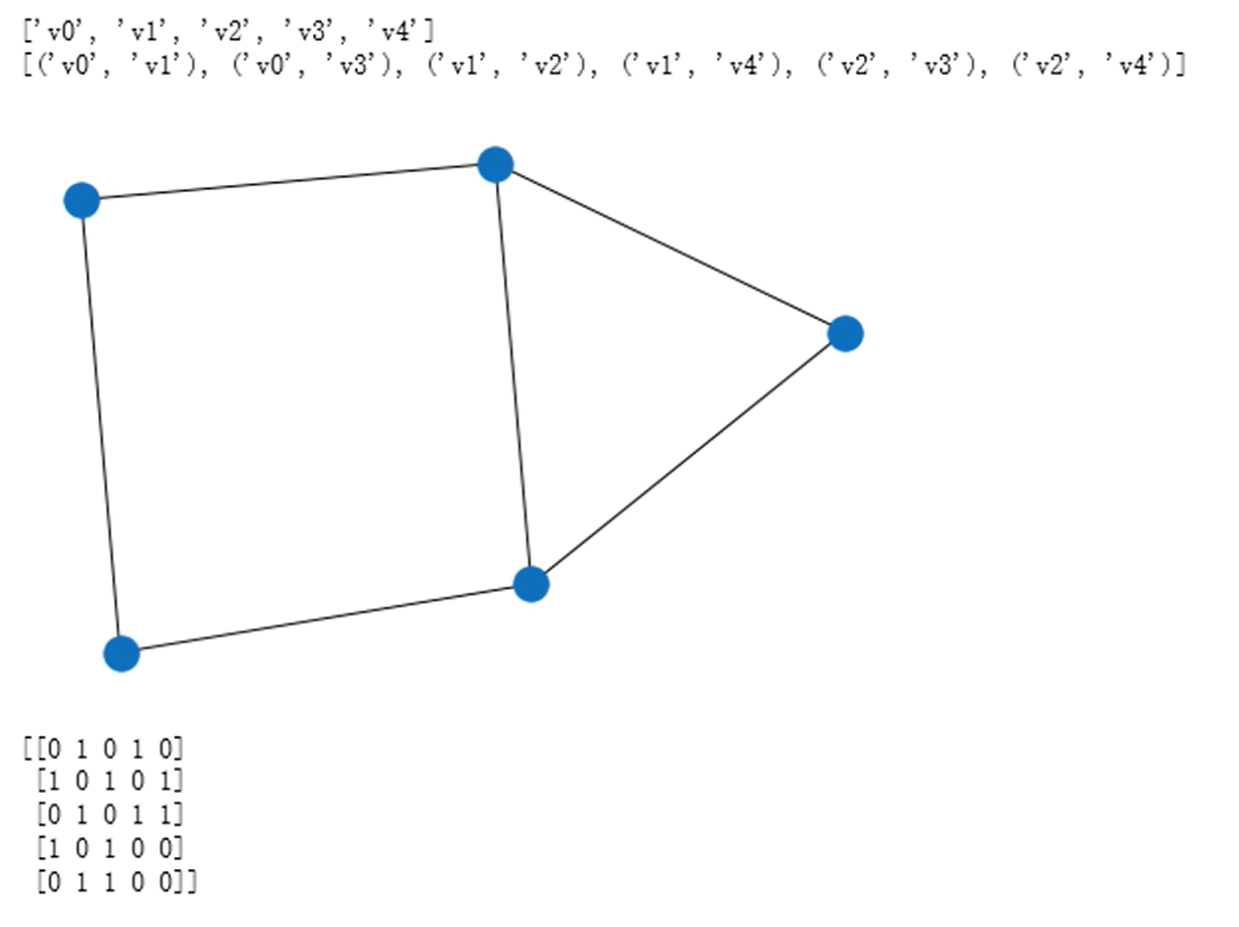
邻接矩阵
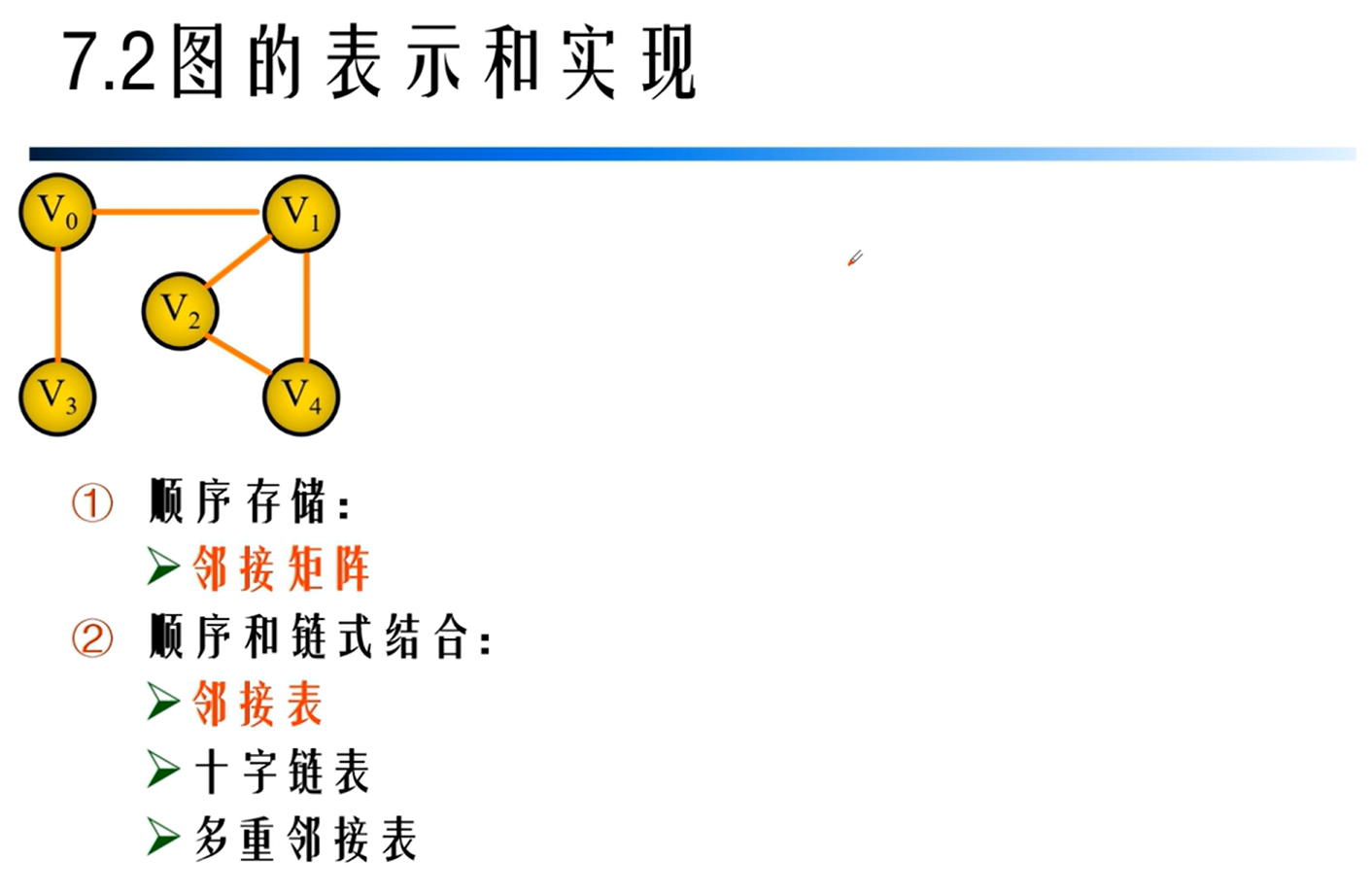

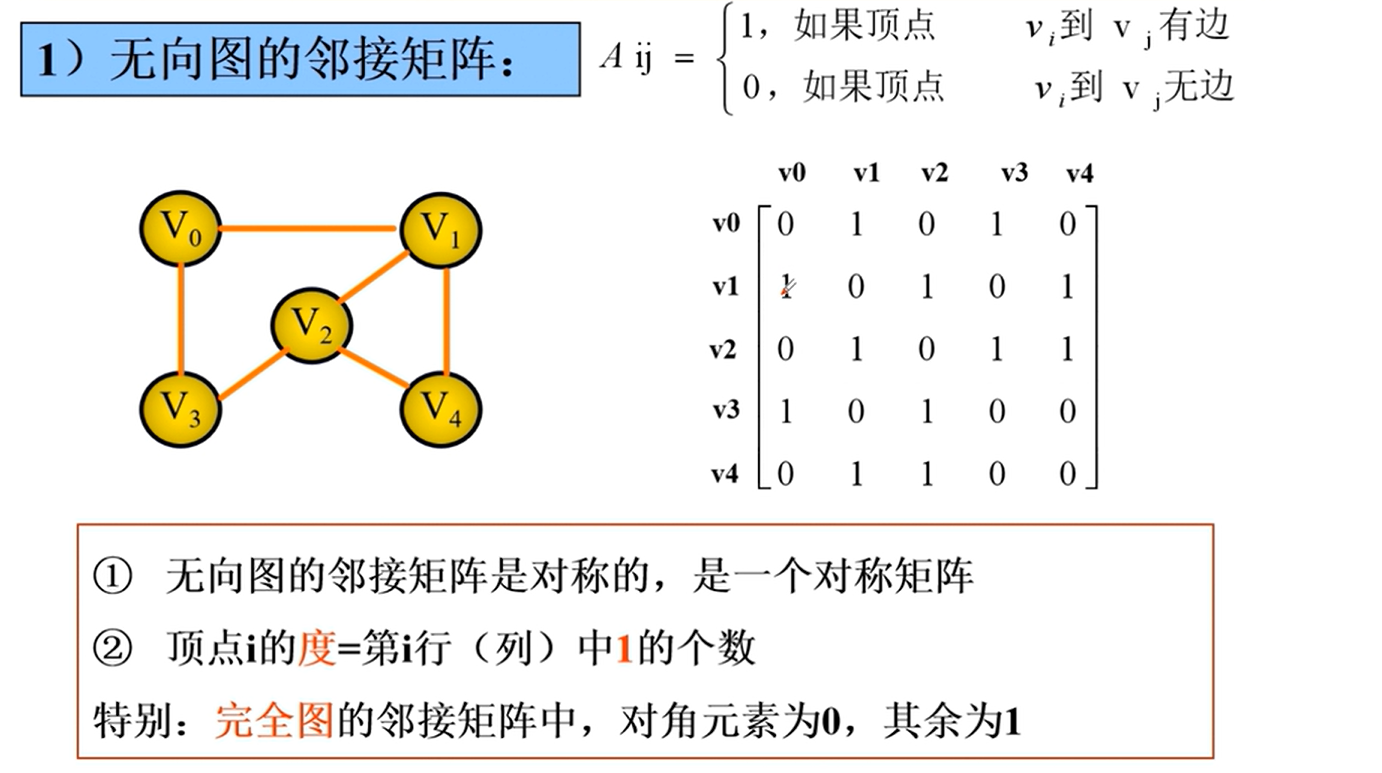
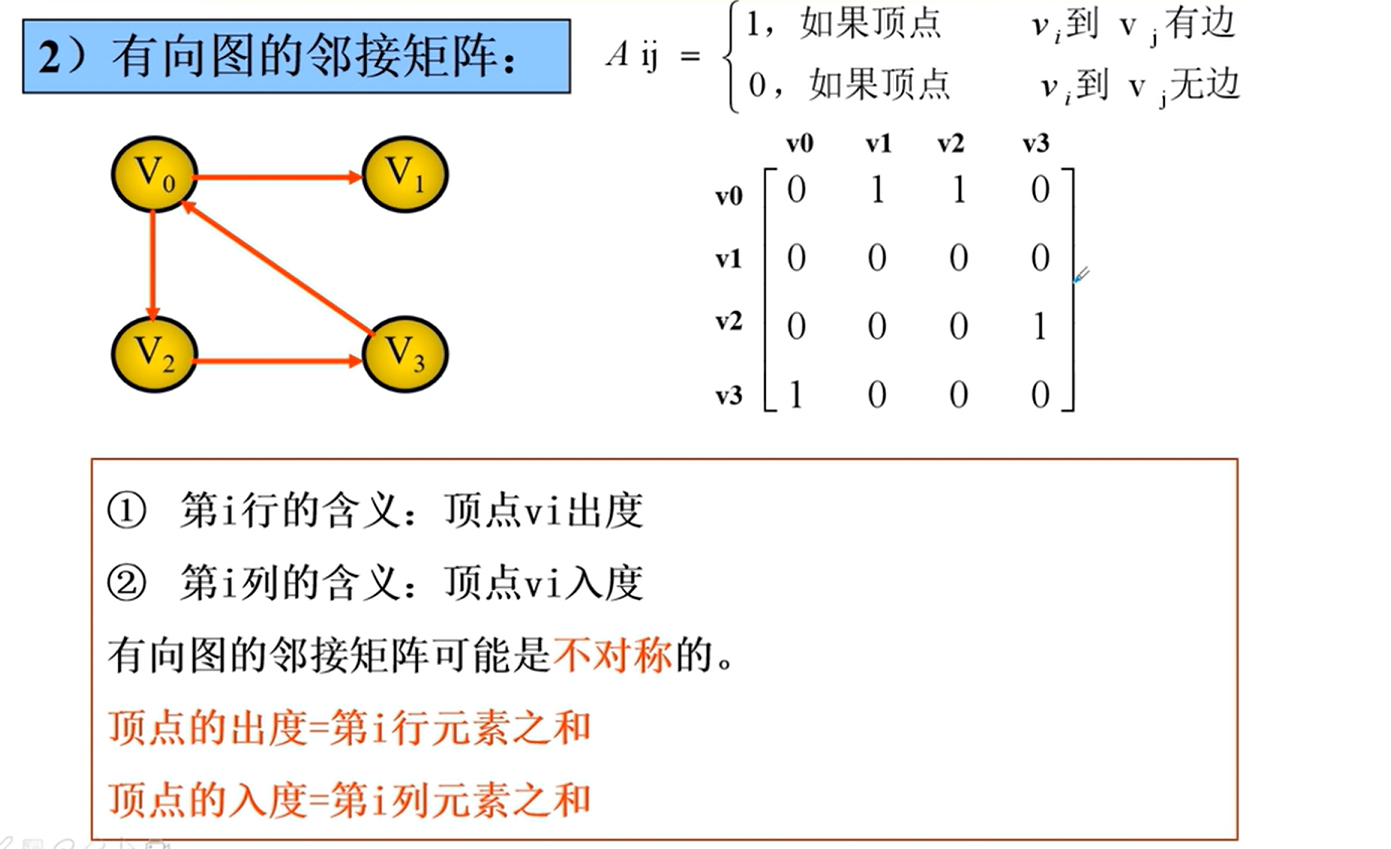
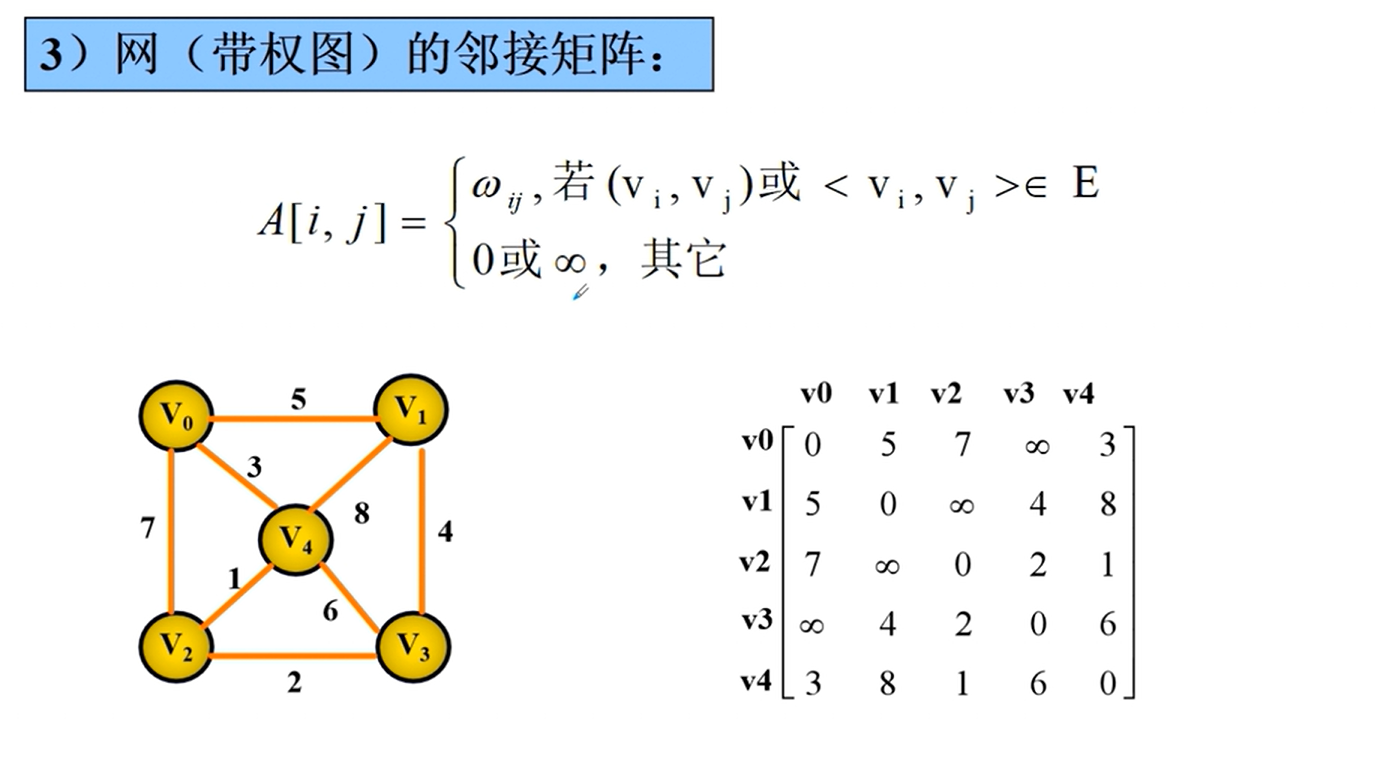
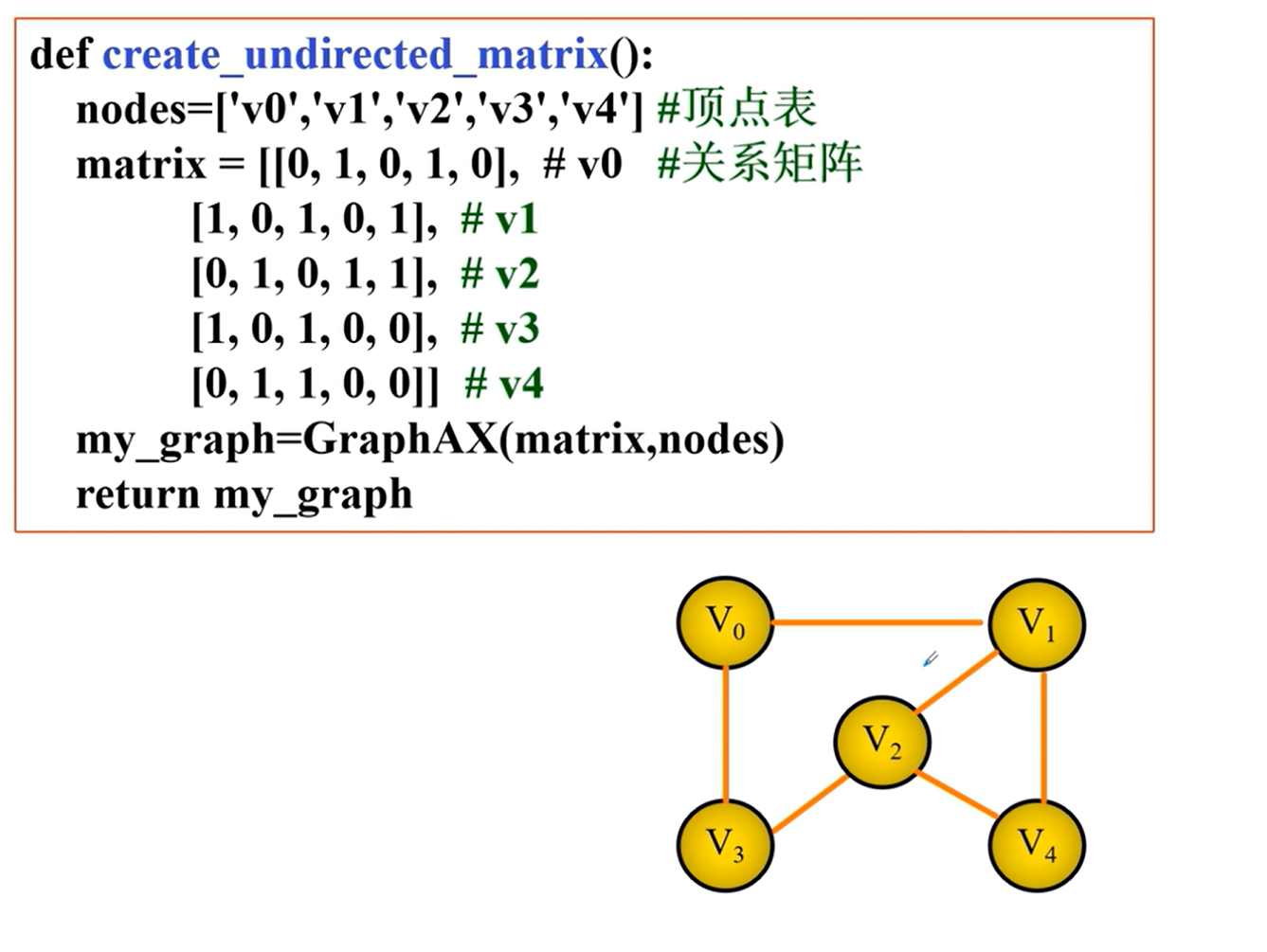
邻接矩阵的实现

邻接矩阵的优劣


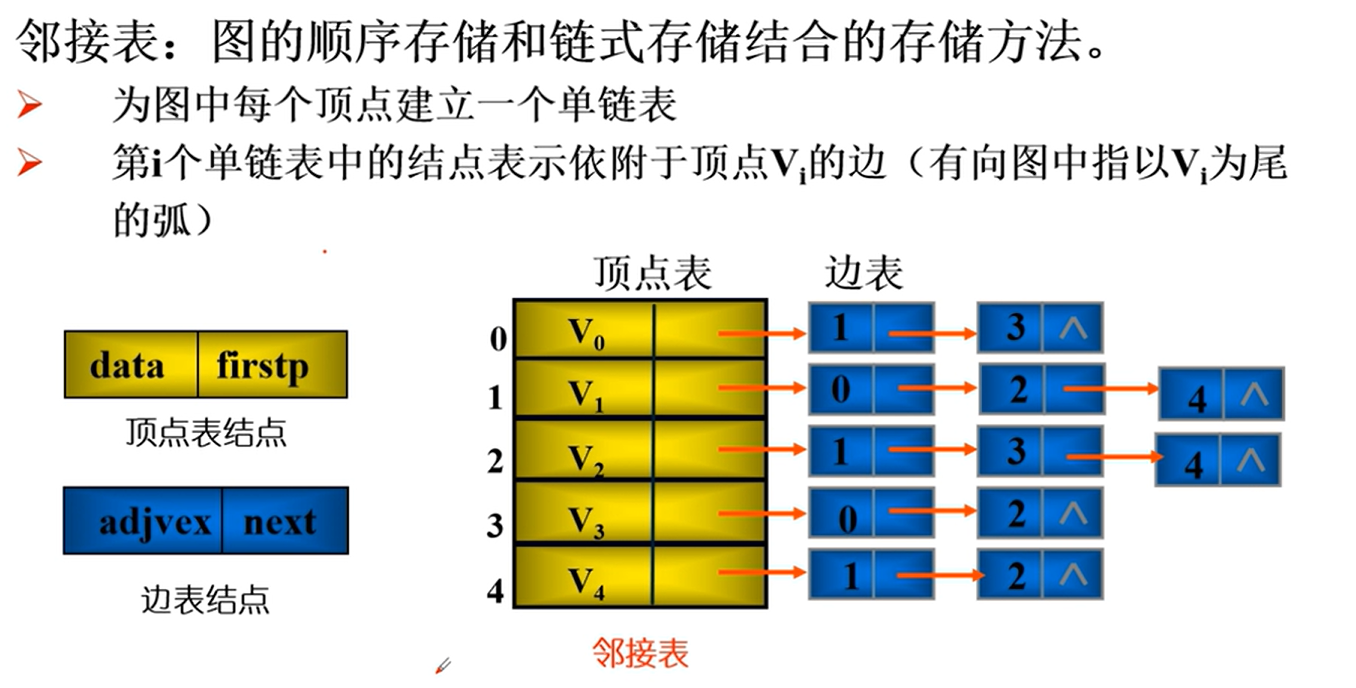
邻接表
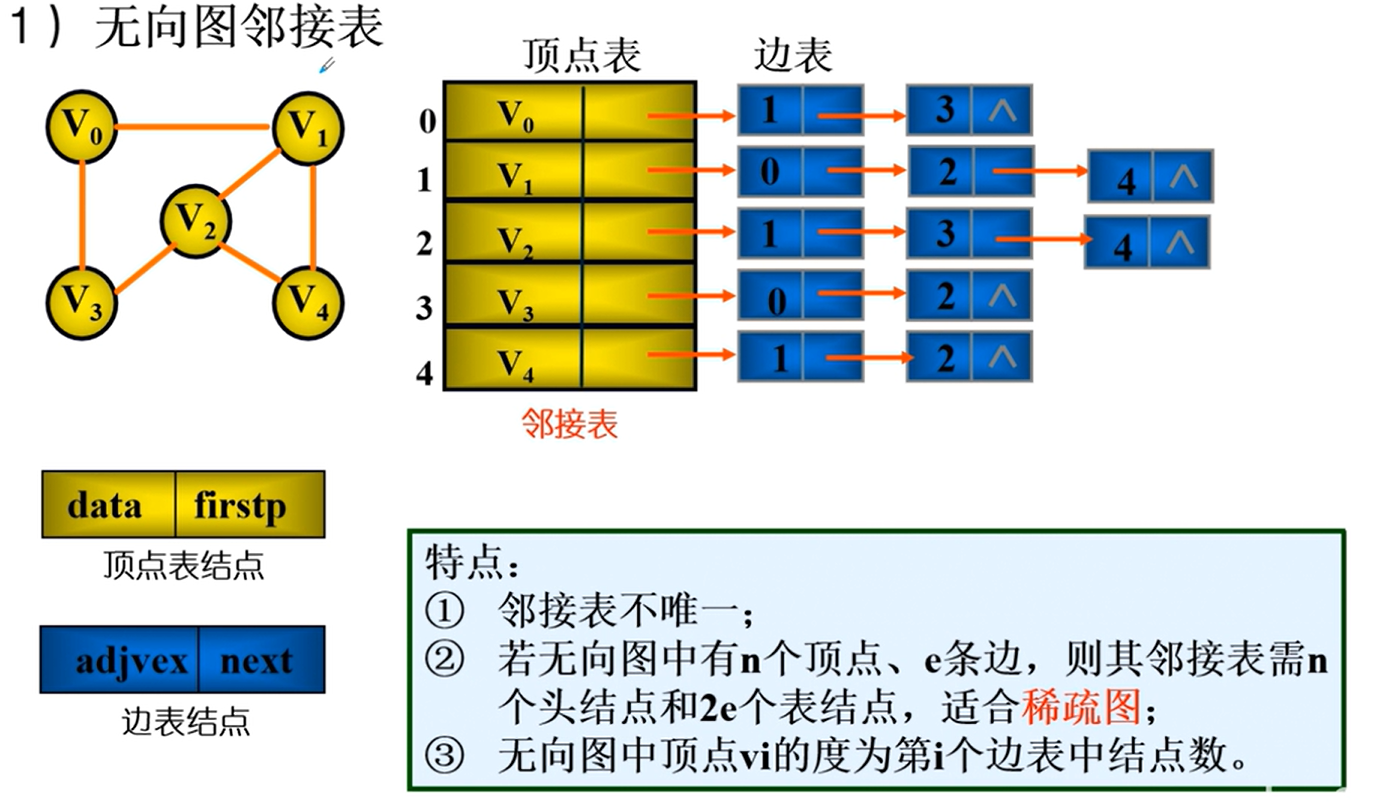
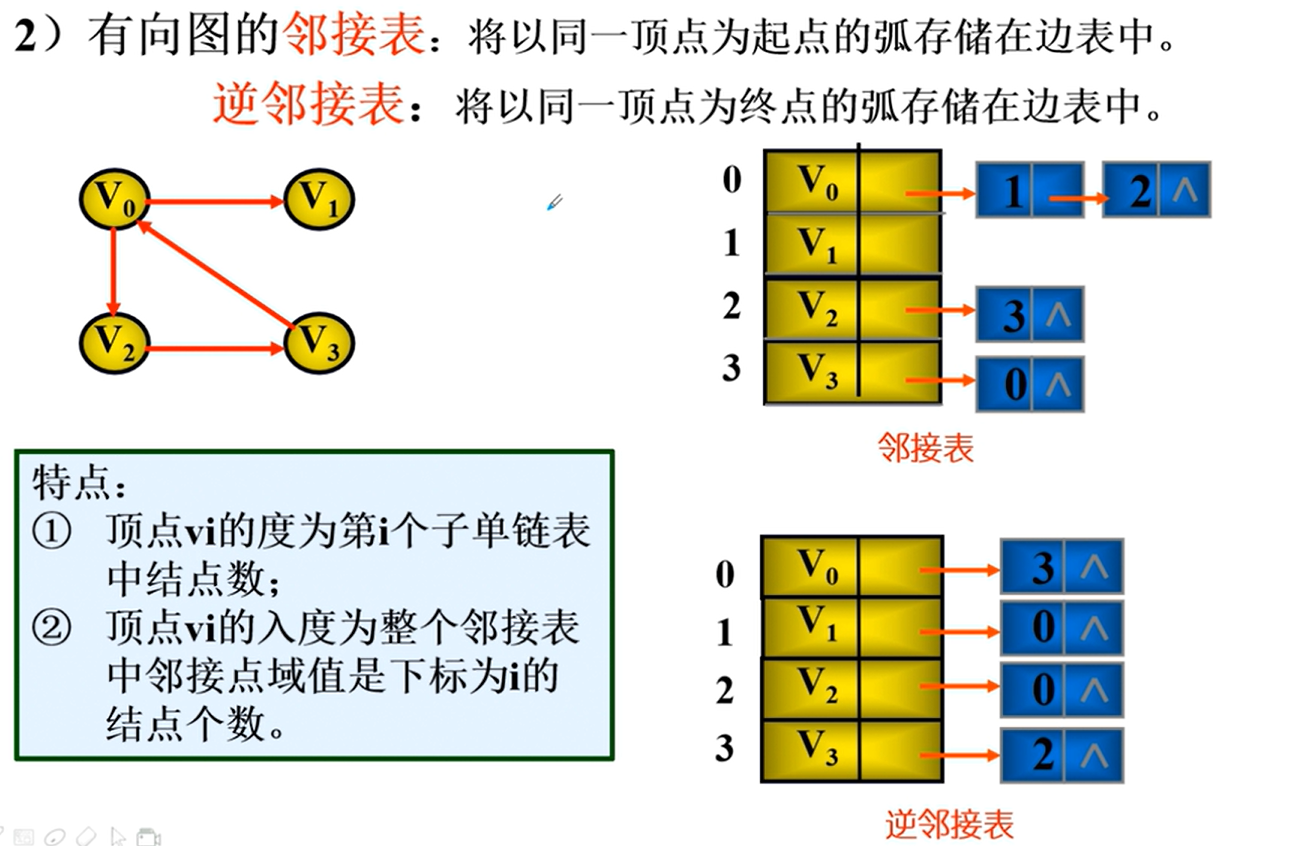
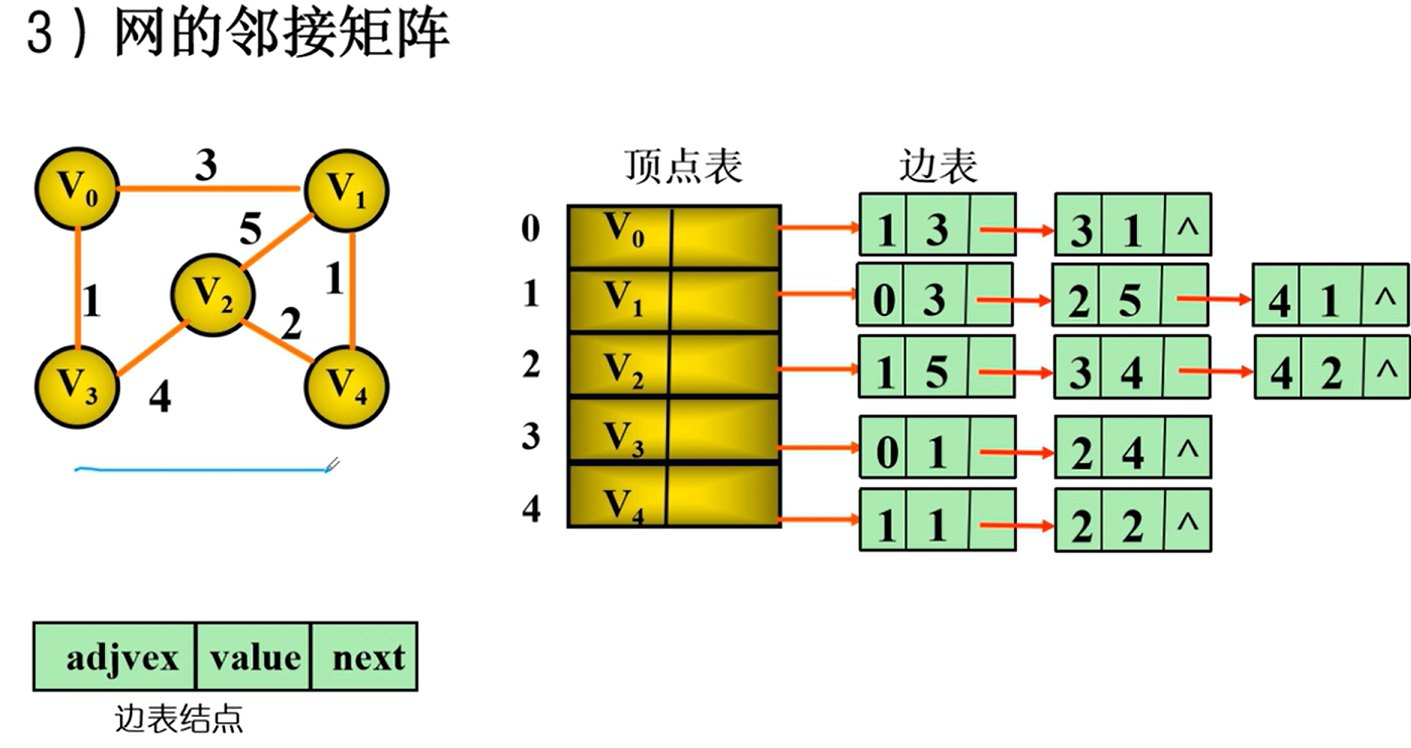
邻接表的实现



特点

库的调用

图的遍历
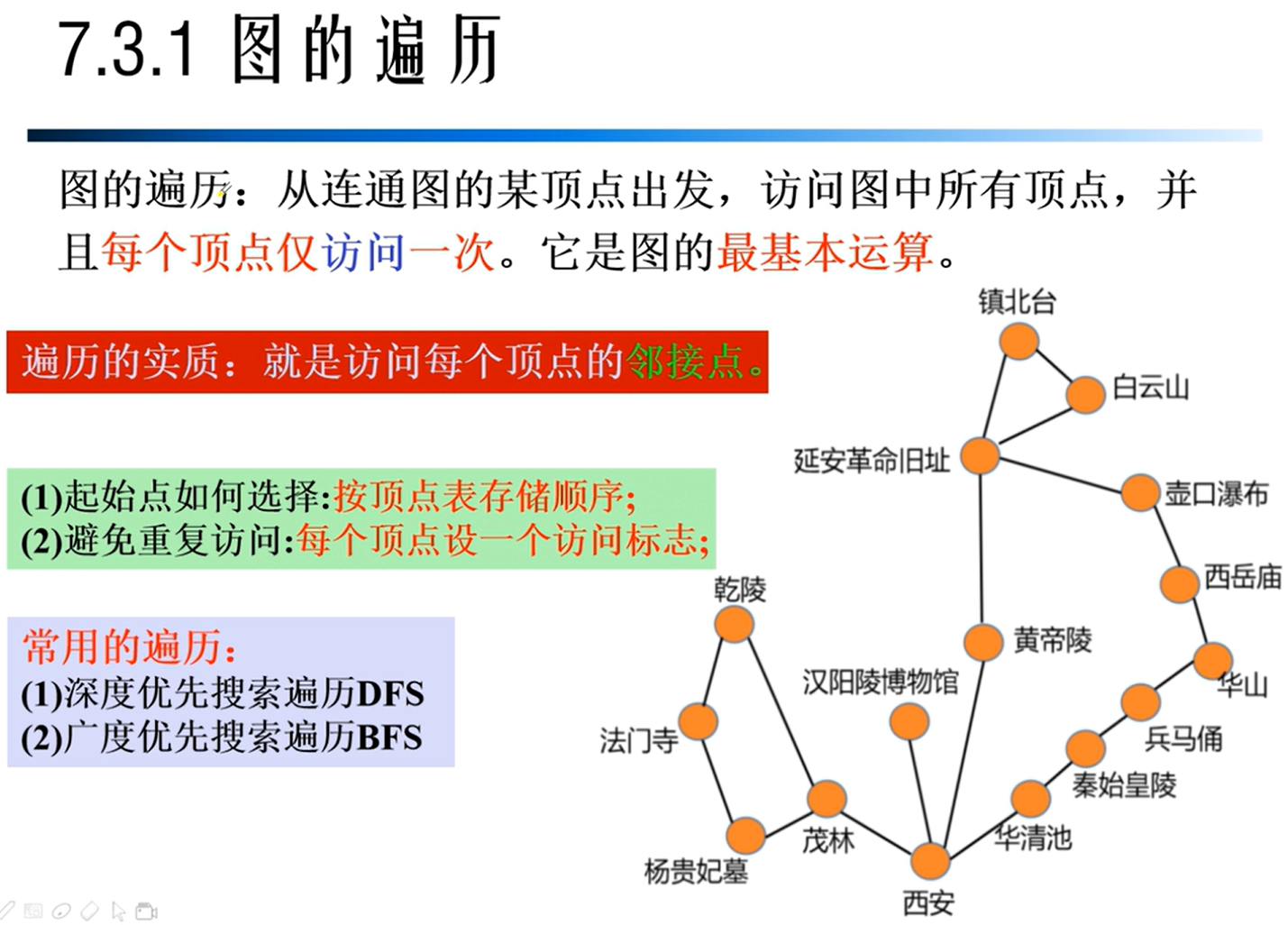
深度优先遍历

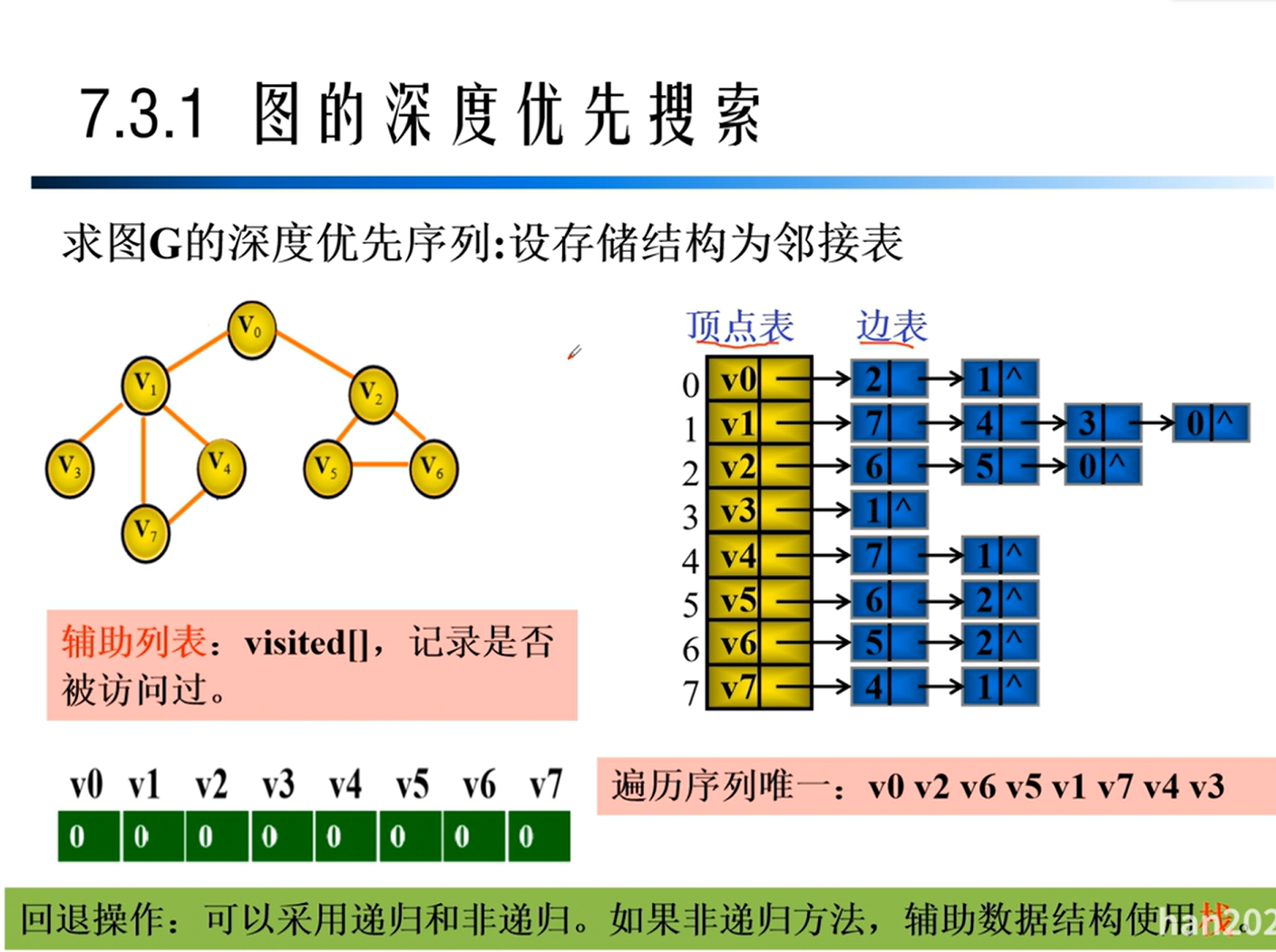

广度优先遍历
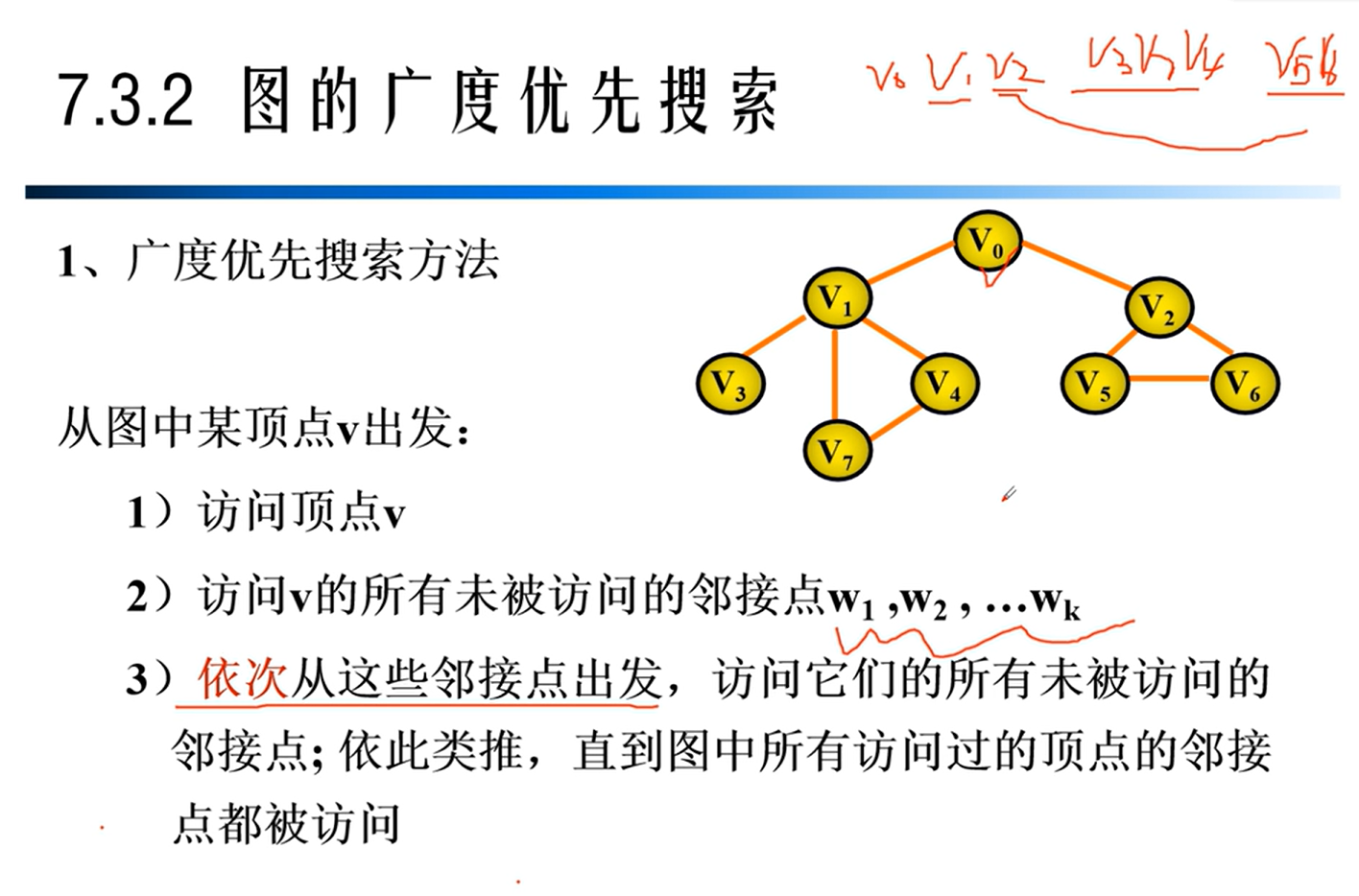
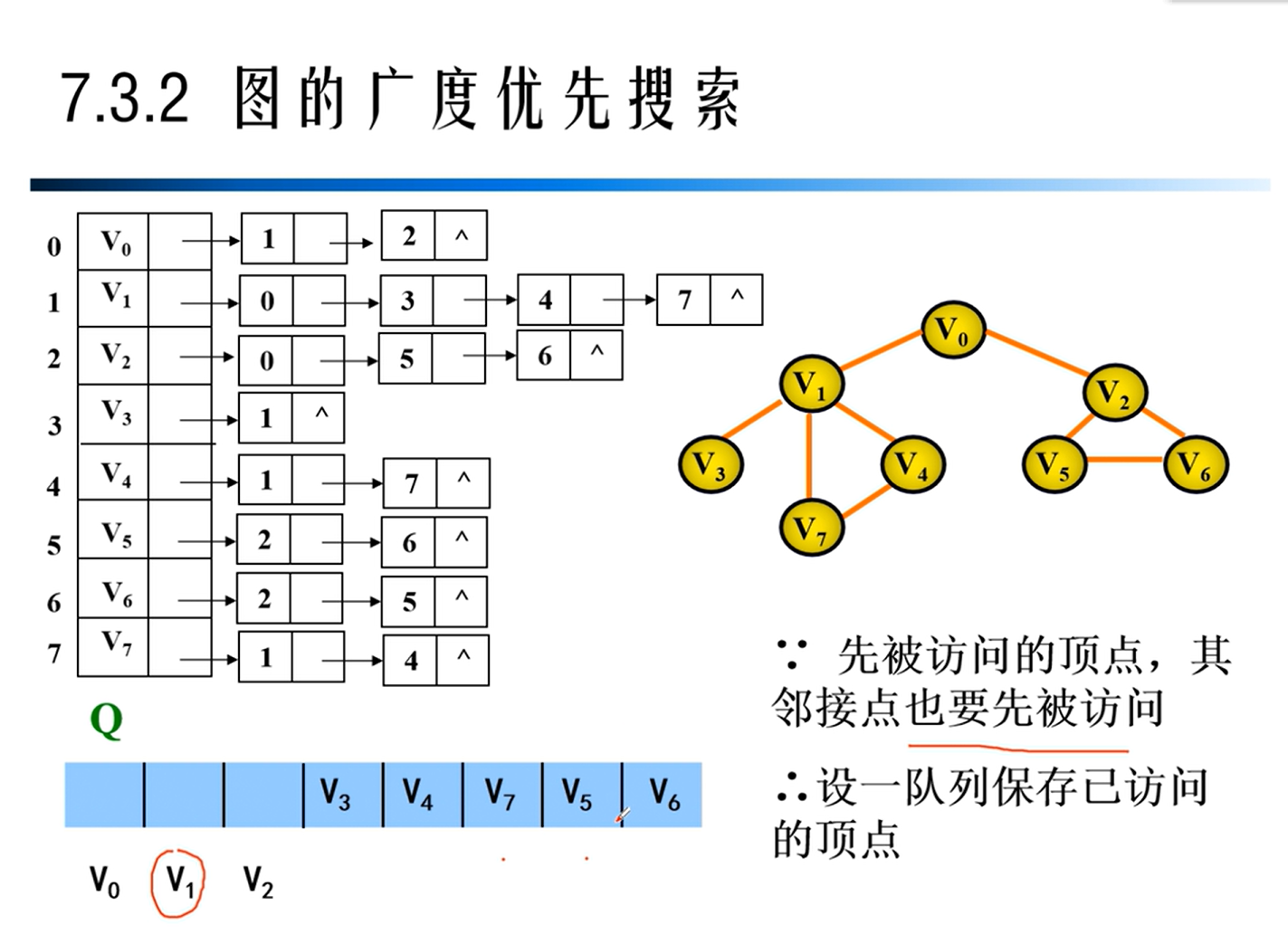

BFS与DFS算法比较

最小生成树
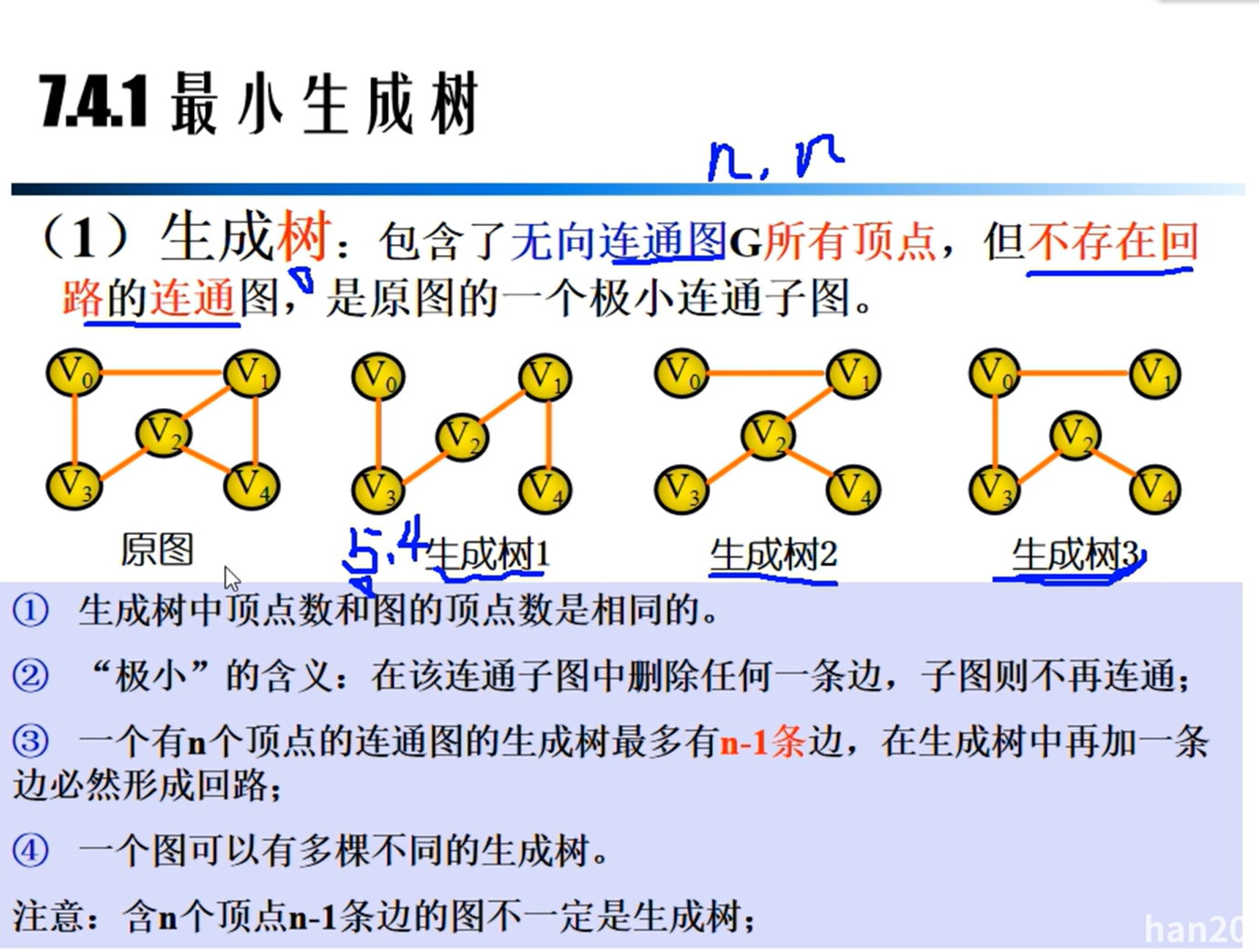
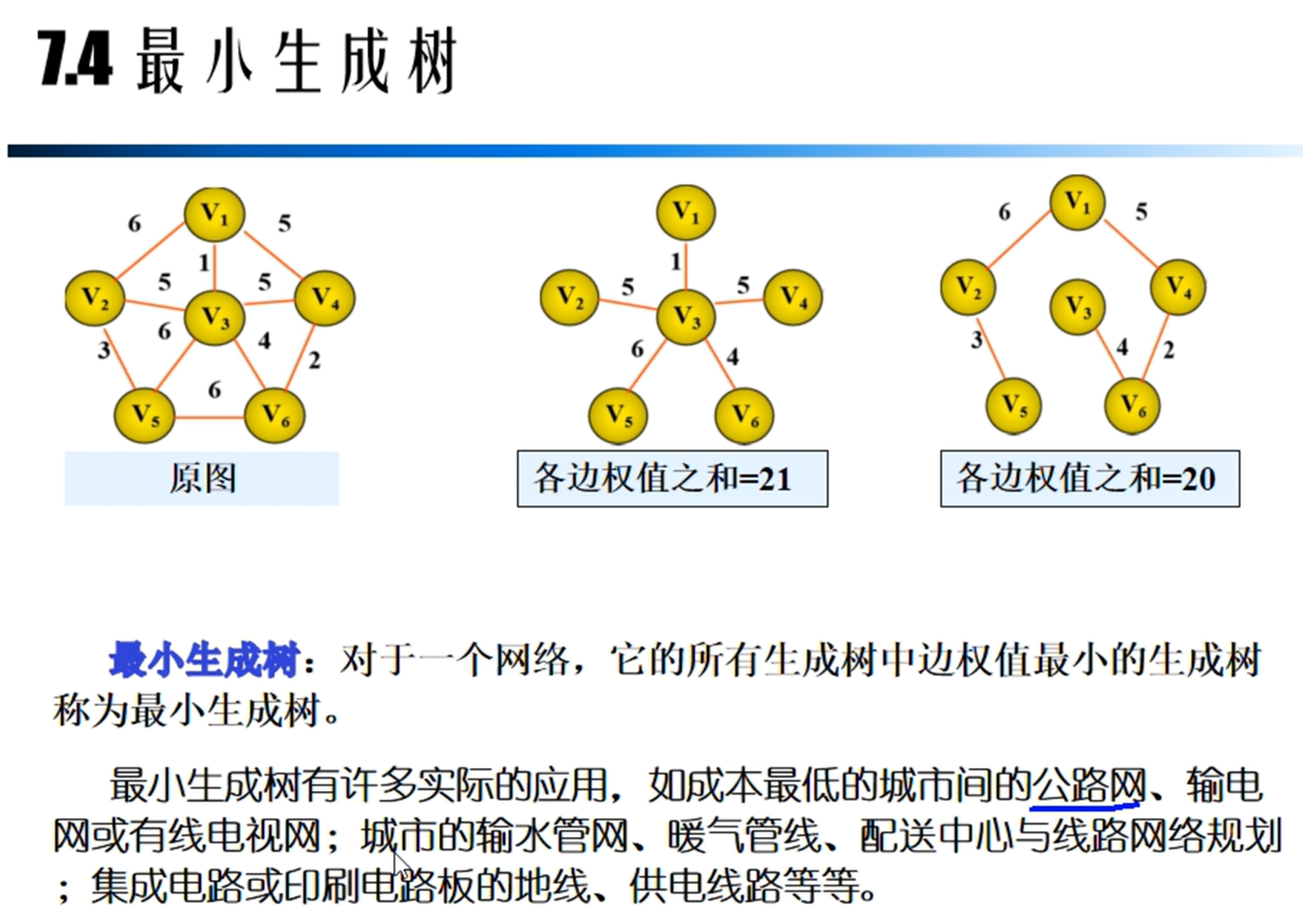
Prim算法
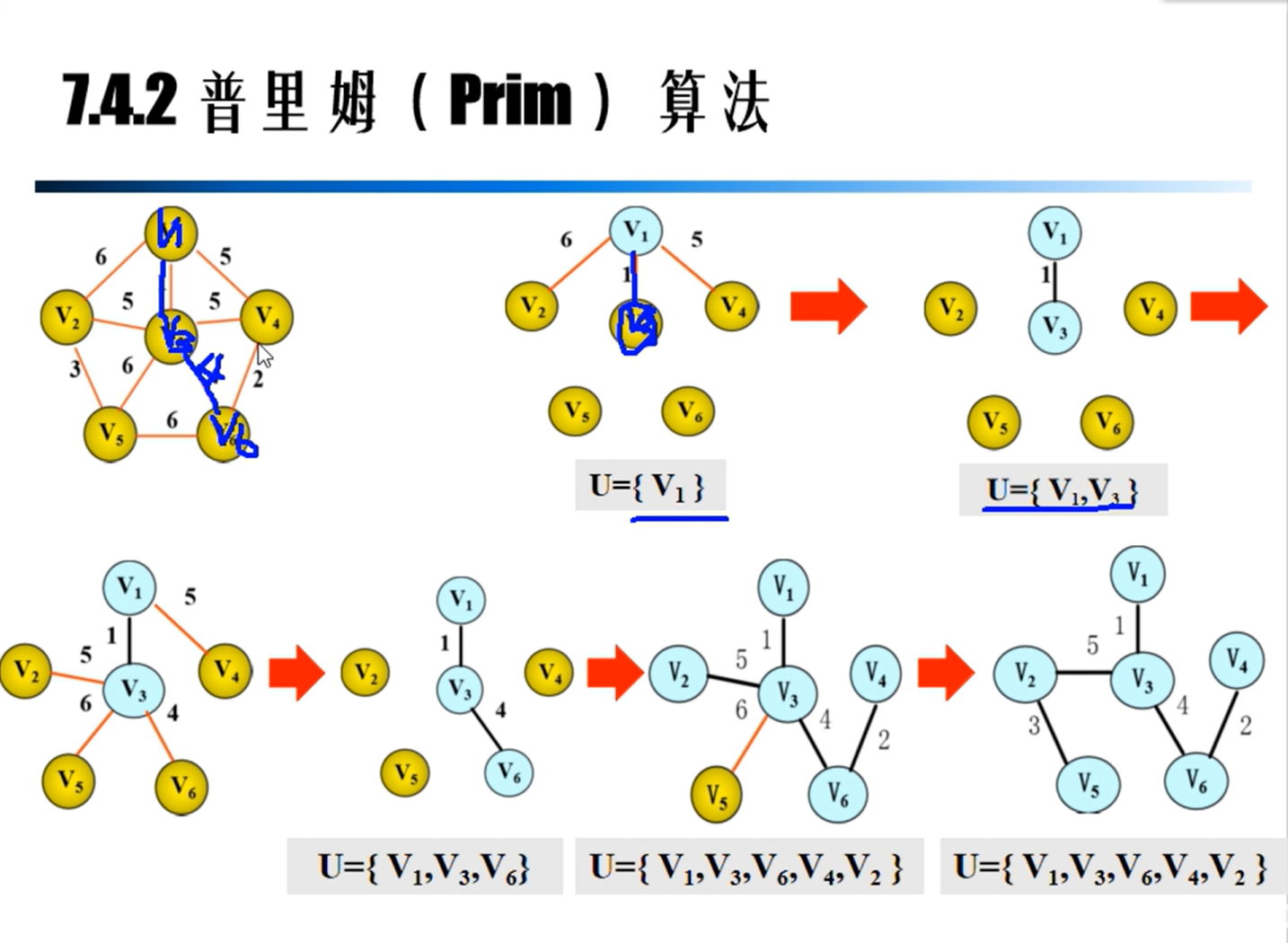
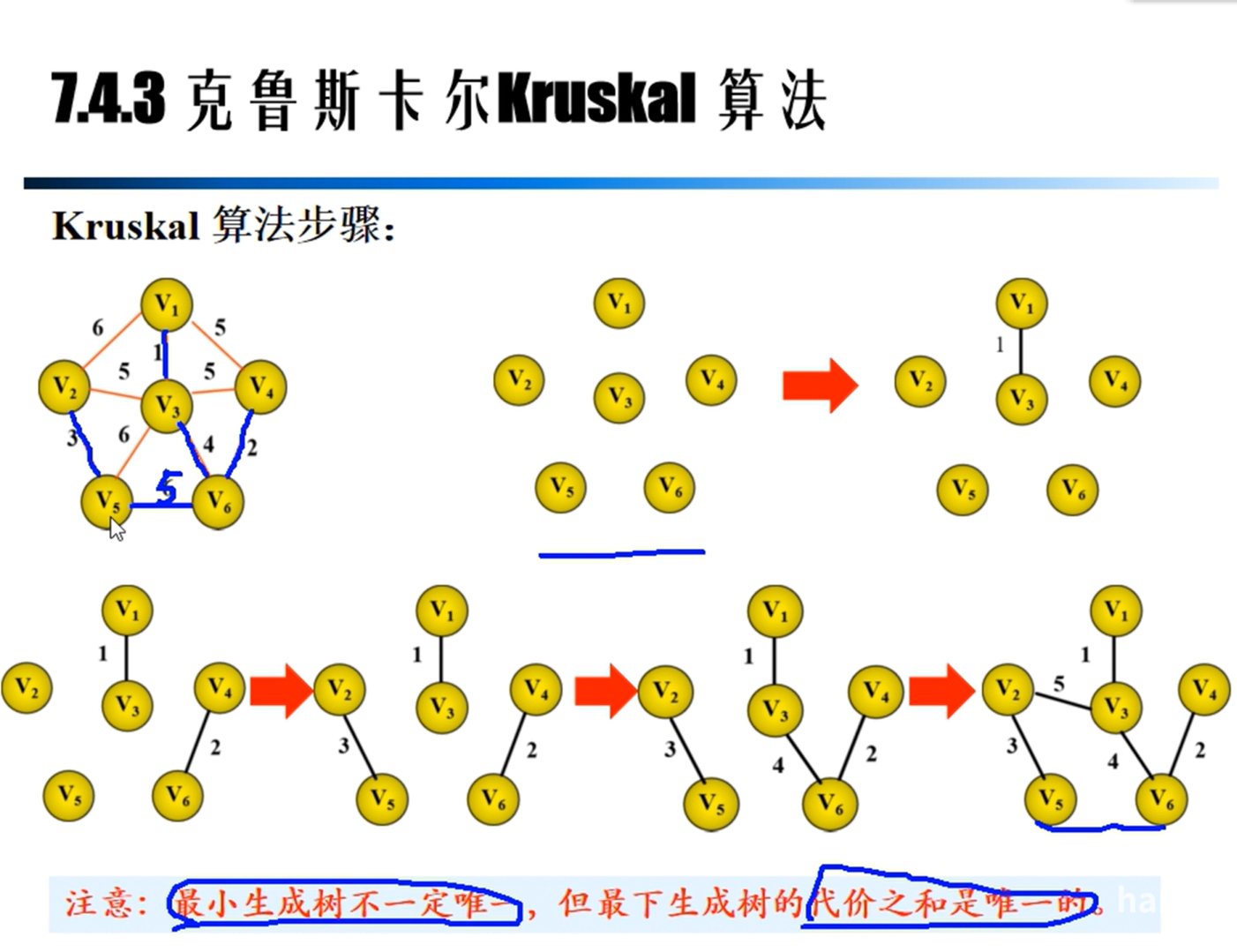
Kruskal算法
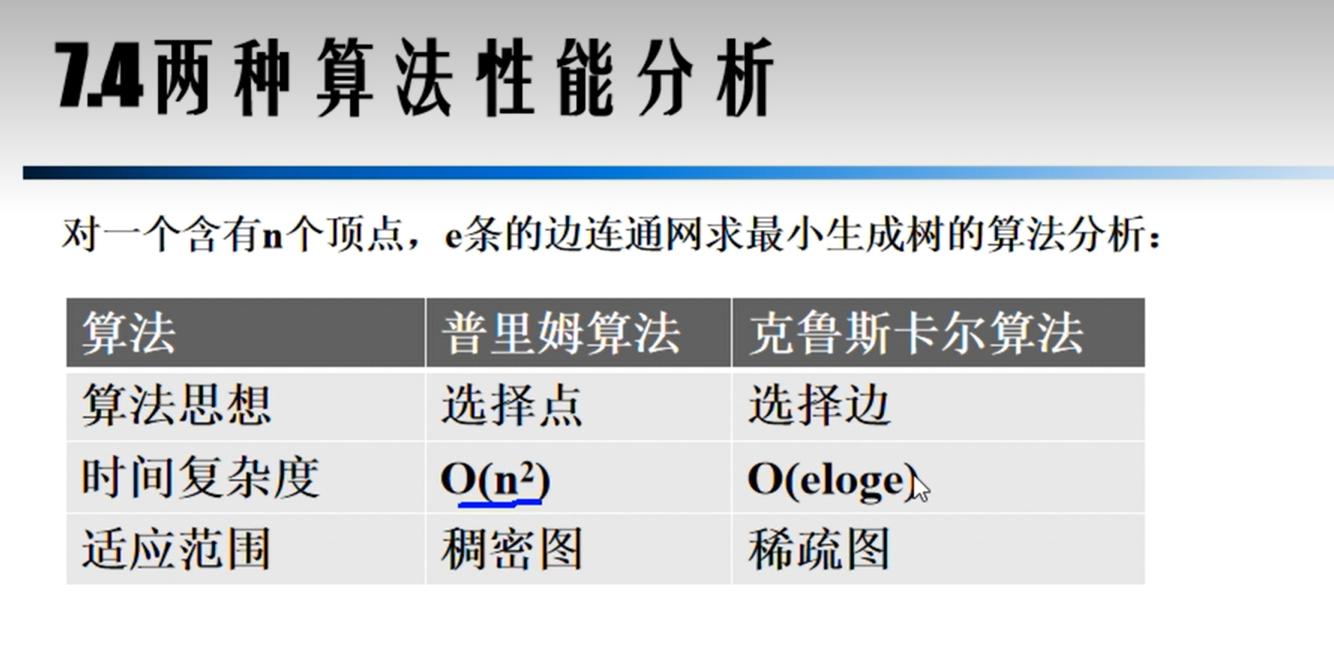
算法比较
最短路径
迪杰斯特拉算法

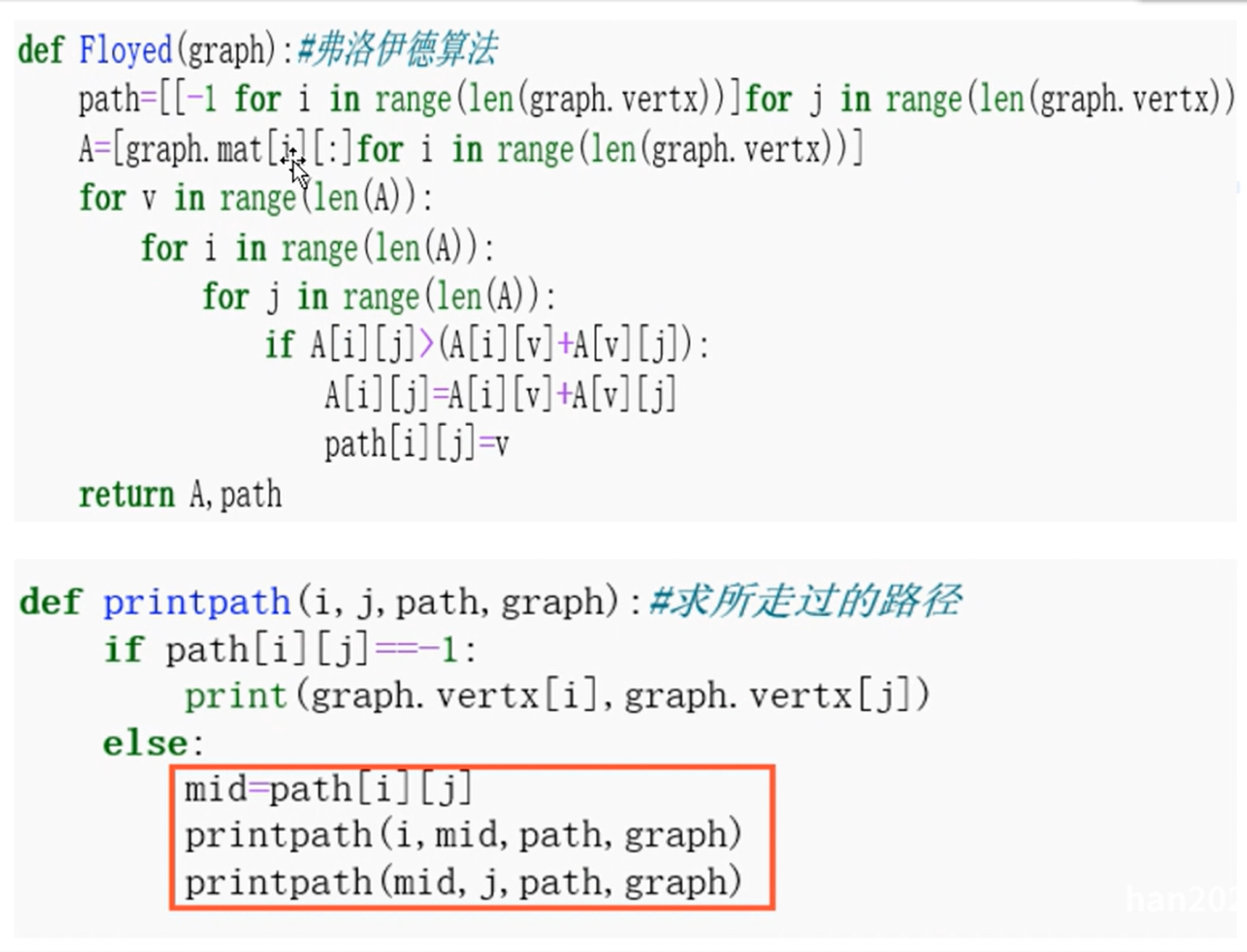
弗洛伊德算法
AOV网
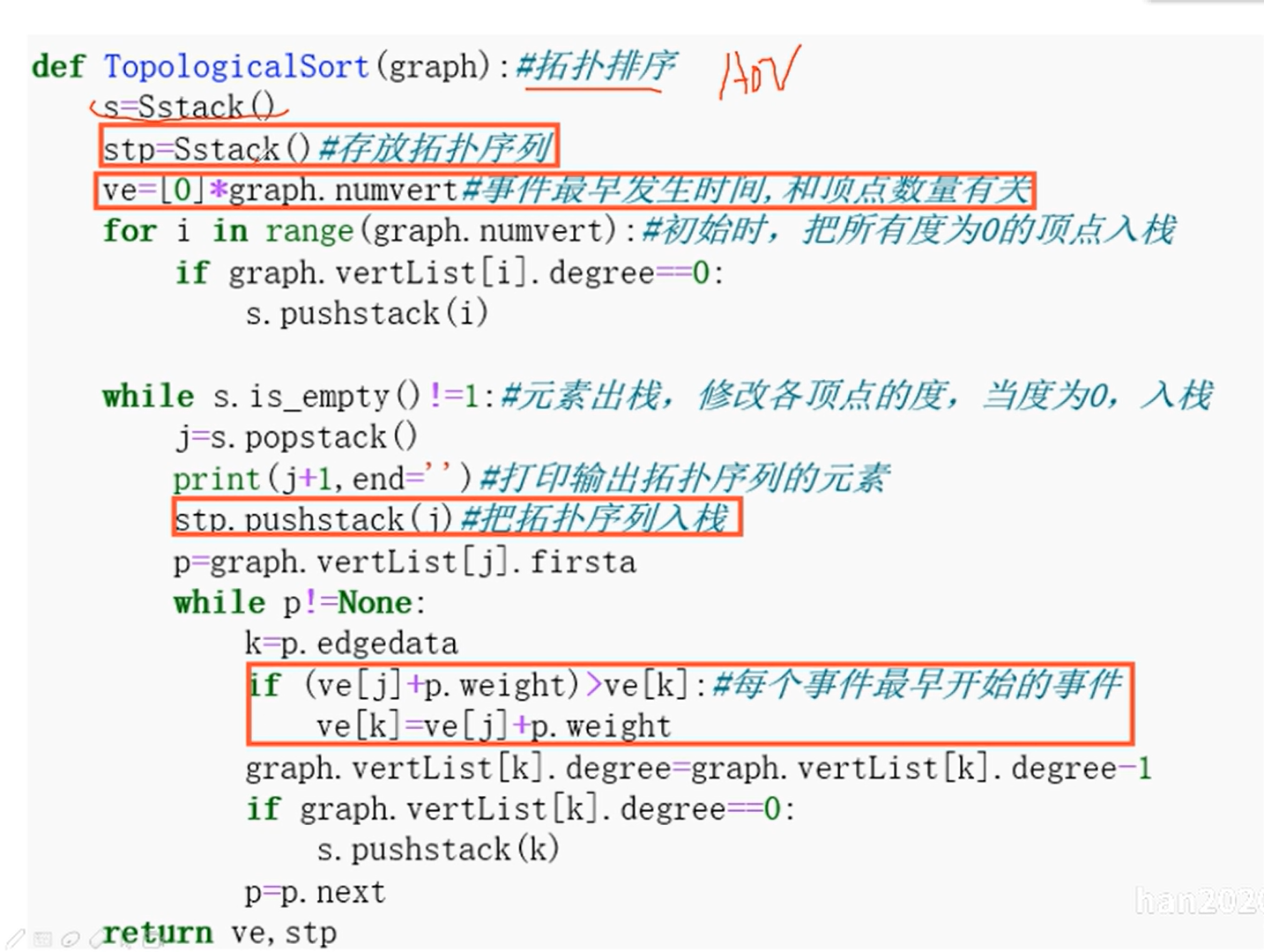
拓扑排序

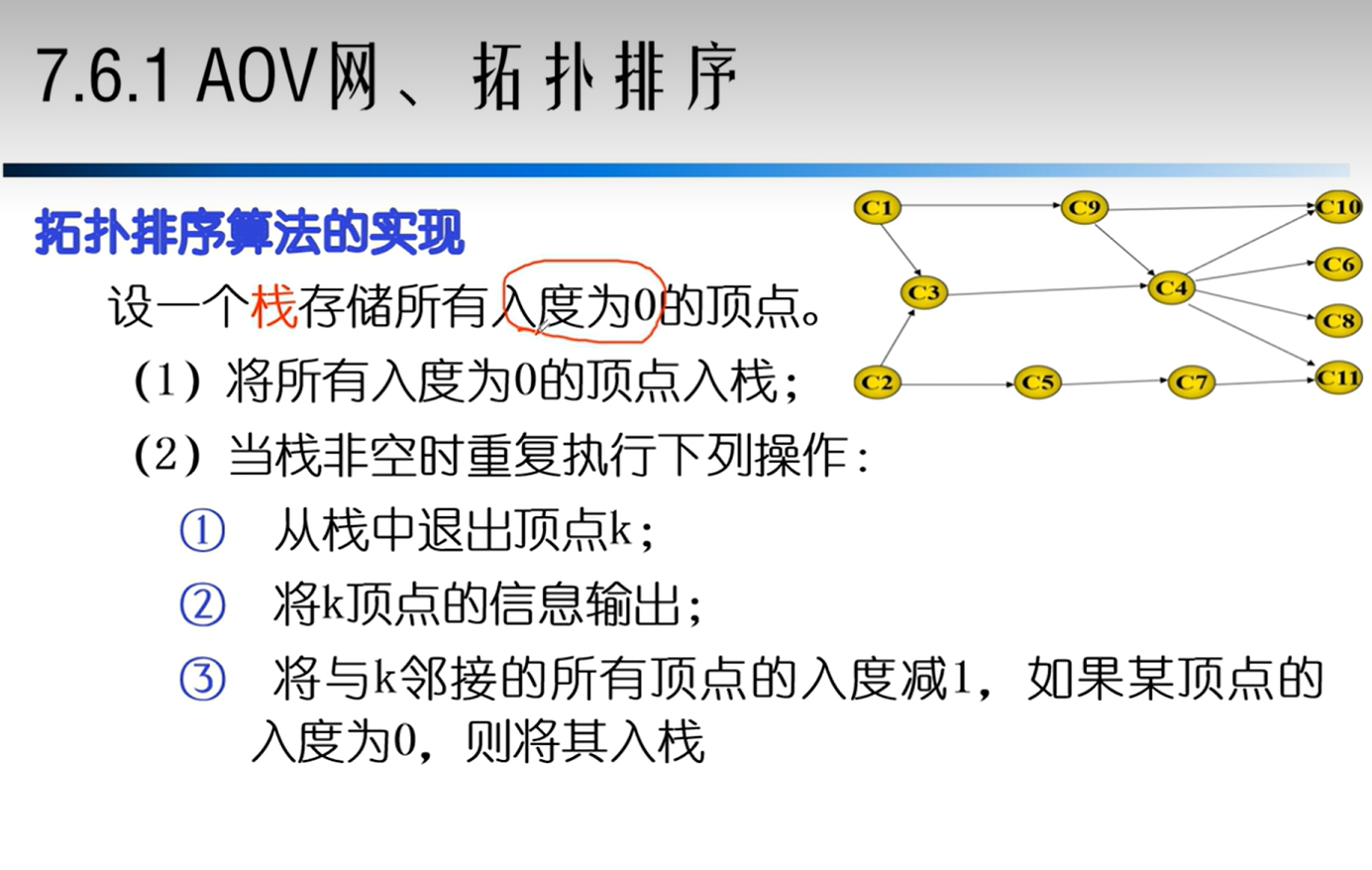
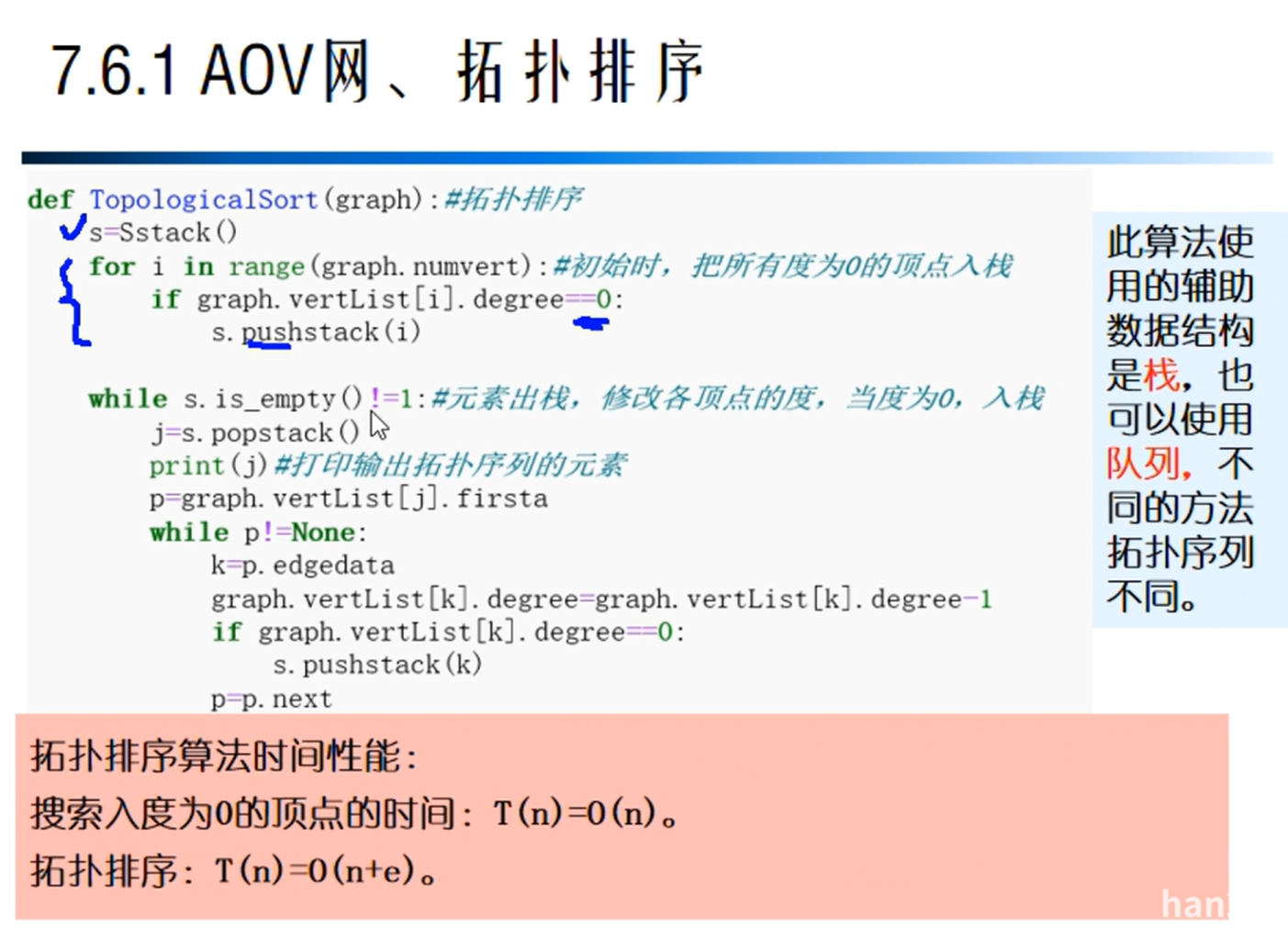
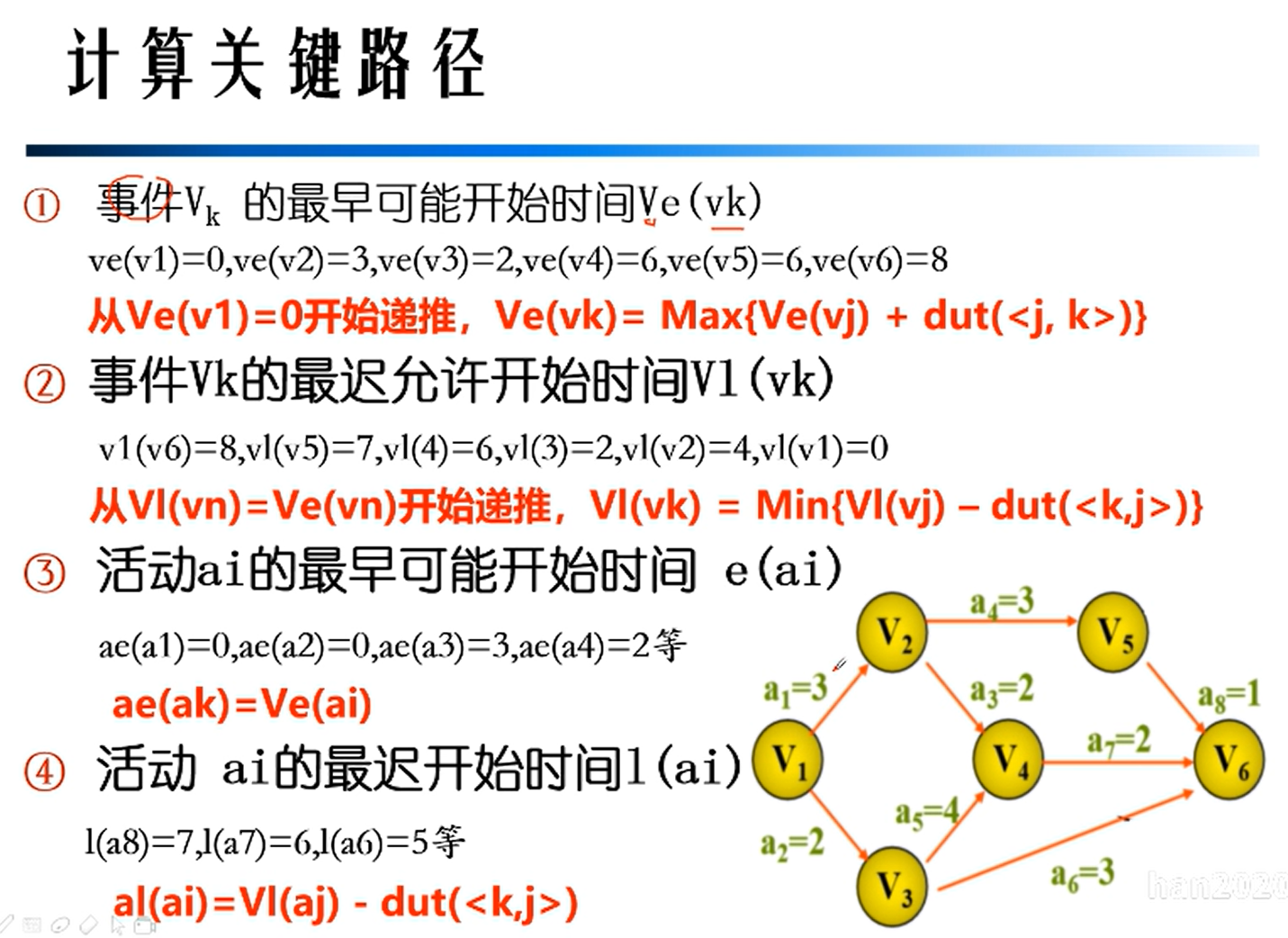
AOE网
关键路径



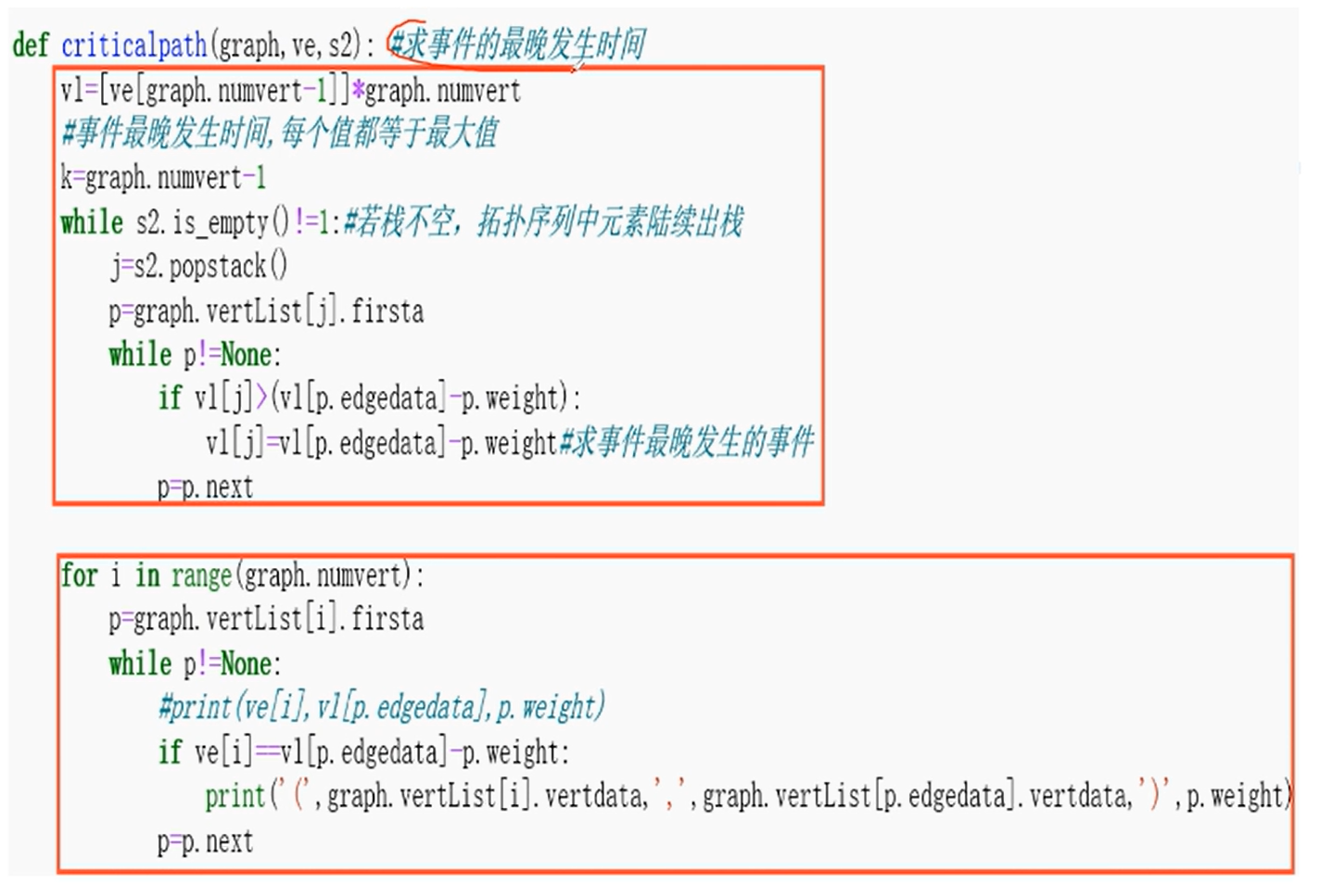
贪心算法

找零问题

代码
t = [100, 50, 20, 5, 1]def change(t, n):m = [0 for _ in range(len(t))]for i, money in enumerate(t):m[i] = n // moneyn = n % moneyreturn m, nprint(change(t, 376))
分数背包问题


代码
goods=[(60,10),(100,20),(120,30)]
goods.sort(key=lambda x:x[0]/x[1],reverse=True)def fractional_backpack(goods,w):m=[0 for _ in range(len(goods))]total_v=0for i,(prize,weight) in enumerate(goods):if w>=weight:m[i]=1total_v+=prizew-=weightelse:m[i]=w/weighttotal_v+=m[i]*prizew=0breakreturn total_v,mprint(fractional_backpack(goods,50))
拼接最大数字问题

代码
from functools import cmp_to_keyli = [32, 94, 128, 1286, 6, 71]def xy_cmp(x, y):if x + y < y + x:return 1elif x + y > y + x:return -1else:return 0def number_join(li):li = list(map(str, li))li.sort(key=cmp_to_key(xy_cmp))return "".join(li)print(number_join(li))
活动选择问题


代码
from operator import itemgetteractivities = [(1, 4), (3, 5), (0, 6), (5, 7), (5, 9), (3, 9), (6, 10), (8, 11), (8, 12), (2, 14), (12, 16)]
activities.sort(key=itemgetter(1, 0))
print(activities)def activity_selection(a):res = [a[0]]for i in range(1, len(a)):if a[i][0] >= res[-1][1]:res.append(a[i])return resprint(activity_selection(activities))
动态规划(DP算法)

钢管切割问题
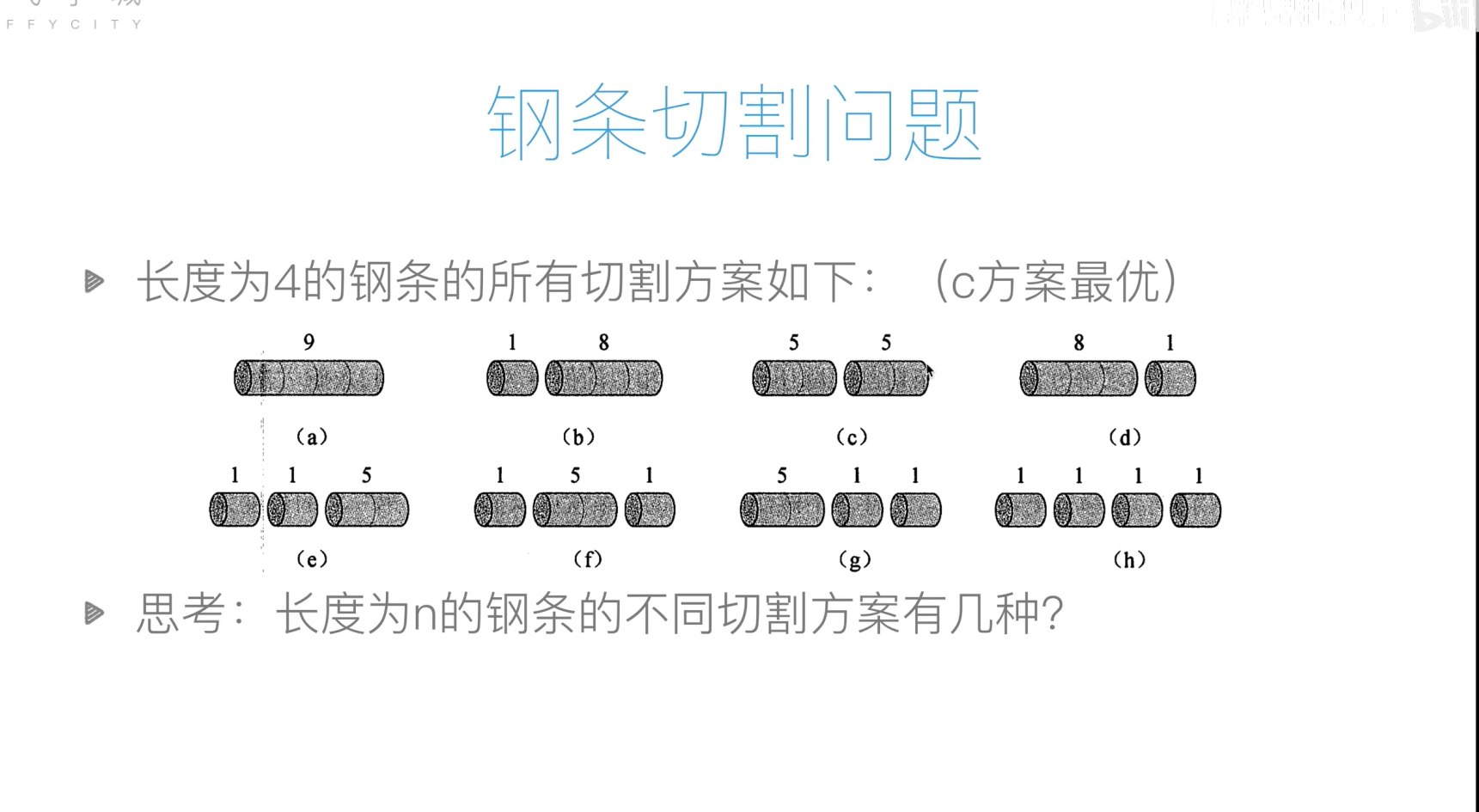
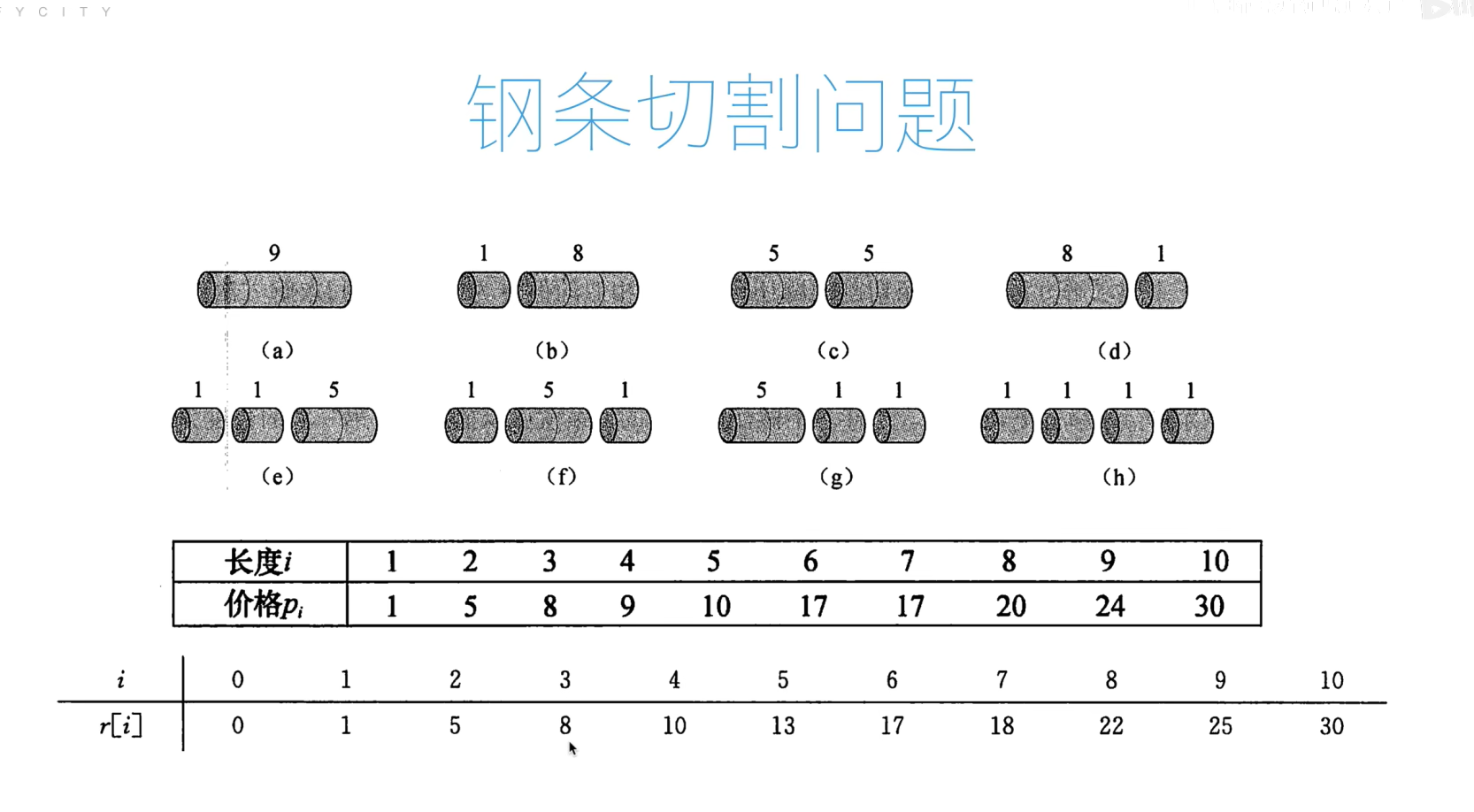




代码
def cut_rot_dp(p, n):r = p.copy()length = len(p)solution_list = []for i in range(1, length):res = r[i]solution = (i, 0)for j in range(1, (i + 1) // 2 + 1):res = max(res, r[j] + r[i - j])if res == r[j] + r[i - j]:solution = (j, i - j)solution_list.append(solution)r[i] = reswhile n >= length:res = 0solution = tuple()for j in range(1, (length + 1) // 2 + 1):res = max(res, r[j] + r[length - j])if res == r[j] + r[length - j]:solution = (j, length - j)solution_list.append(solution)r.append(res)length += 1solution_list.insert(0, tuple())return r[-1], solution_listdef find(li):queue = [li[-1]]res = []while queue:tmp = queue.pop(0)if tmp[1] == 0:res.append(tmp)else:queue.append(li[tmp[0]])queue.append(li[tmp[1]])return resdef cut_rot(p, n):r, solution_list = cut_rot_dp(p, n)res = find(solution_list)return r, resp = [0, 1, 5, 8, 9, 10, 17, 17, 20, 24, 30]
print(cut_rot(p,49))
最长公共子序列问题


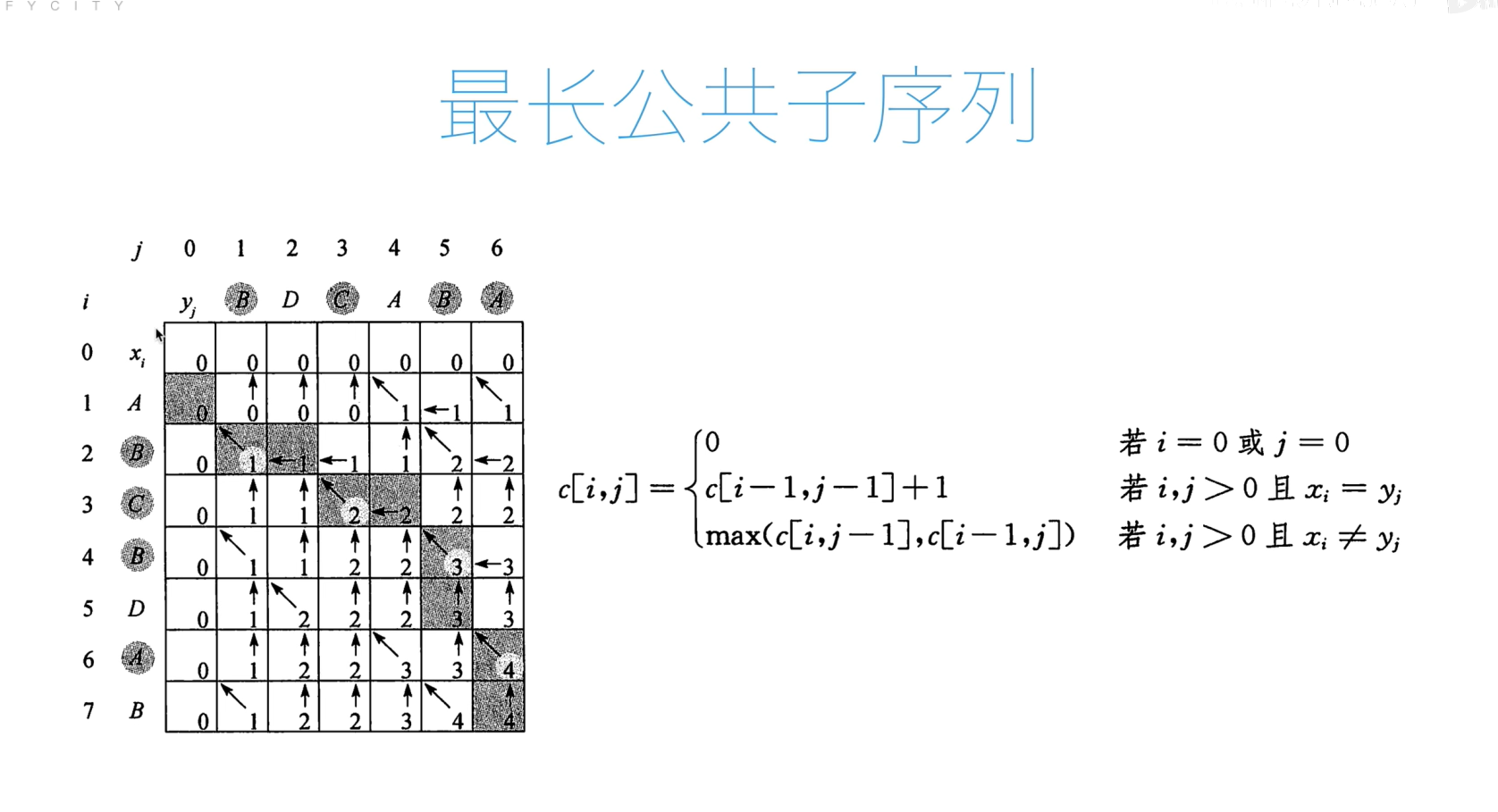
代码
def lcs(x, y):m = len(x)n = len(y)c = [[0 for _ in range(n + 1)] for _ in range(m + 1)]b = [[0 for _ in range(n + 1)] for _ in range(m + 1)]for i in range(1, m + 1):for j in range(1, n + 1):if x[i - 1] == y[j - 1]:c[i][j] = c[i - 1][j - 1] + 1b[i][j] = 1elif c[i - 1][j] > c[i][j - 1]:c[i][j] = c[i - 1][j]b[i][j] = 2else:c[i][j] = c[i][j - 1]b[i][j] = 3return c[m][n], bdef lcs_trackback(x, y):c, b = lcs(x, y)i = len(x)j = len(y)res = []while i > 0 and j > 0:if b[i][j] == 1:res.append(x[i - 1])i -= 1j -= 1elif b[i][j] == 2:i -= 1else:j -= 1return ''.join(reversed(res))print(lcs_trackback("ABCBDAB","BDCABA"))
欧几里得算法(求最大公约数)

def gcd(a, b):if b == 0:return aelse:return gcd(b, a % b)def gcd2(a, b):while b > 0:r = a % ba = bb = rreturn aprint(gcd(12, 16))
print(gcd2(12, 16))
应用

class Fraction:def __init__(self,a,b):self.molecule=aself.denominator=bx=self.gcd(a,b)self.molecule/=xself.denominator/=xdef gcd(self,a,b):while b > 0:r = a % ba = bb = rreturn adef __add__(self, other):denominator=self.zgs(self.denominator,other.denominator)molecule=self.molecule*denominator/self.denominator+other.molecule*denominator/other.denominatorreturn Fraction(molecule,denominator)def zgs(self,a,b):x=self.gcd(a,b)return a*b/xdef __str__(self):return "%d/%d"%(self.molecule,self.denominator)num1=Fraction(2,10)
print(num1)
num2=Fraction(1,6)
print(num1+num2)
RSA加密算法

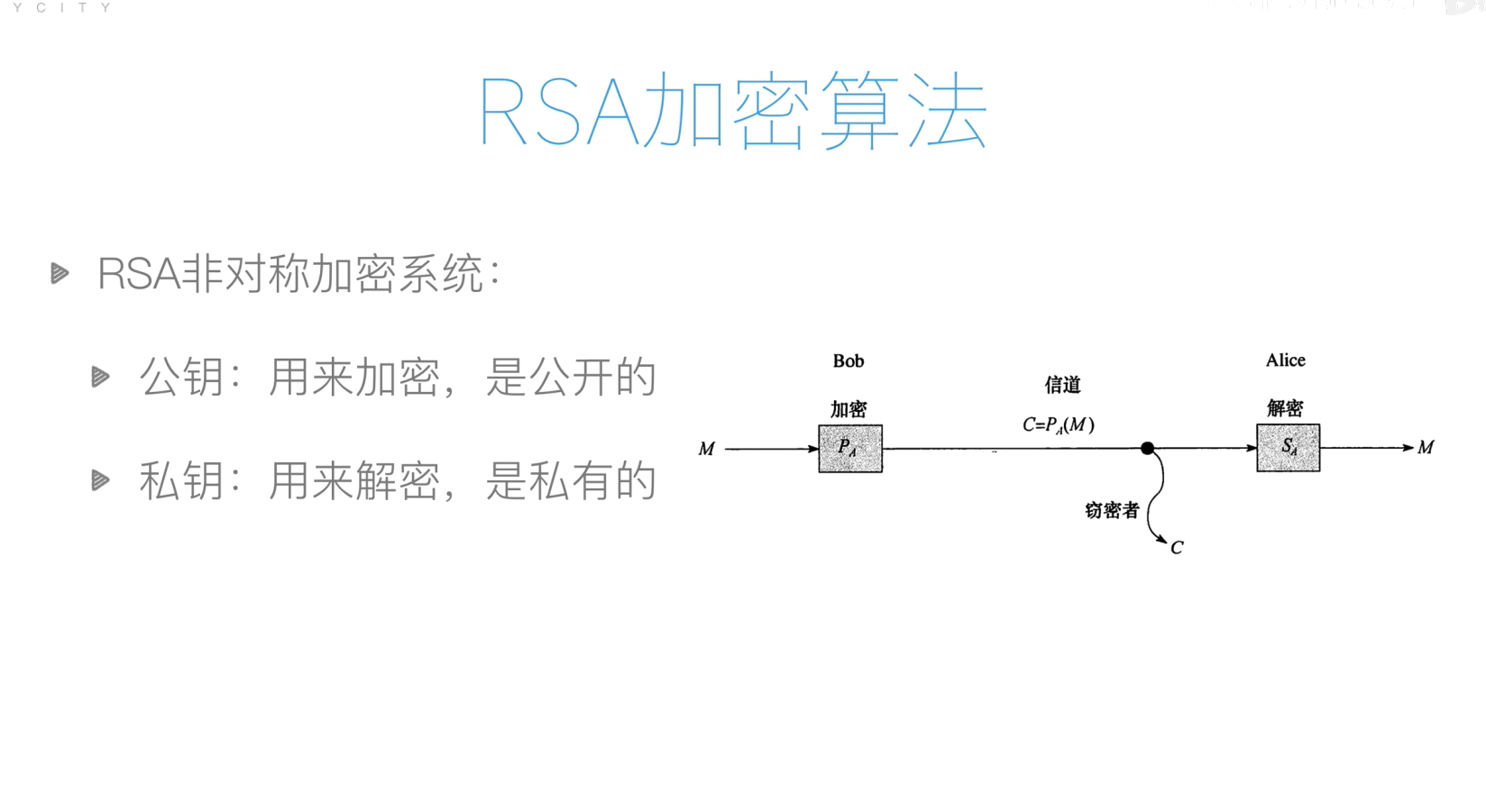


面向对象


设计模式




创建型模式
简单工厂模式


工厂方法模式


抽象工厂模式



建造者模式


单例模式


小结

结构型模式
适配器模式


桥模式



组合模式


外观模式


代理模式


行为型模式
责任链模式


观察者模式


模板方法模式


策略模式







![SQLSTATE[42S22]: Column not found: 1054 Unknown column Color in field list](https://img2024.cnblogs.com/blog/1295962/202407/1295962-20240717124854088-281169181.jpg)
![P9752 [CSP-S 2023] 密码锁P8814 [CSP-J 2022] 解密](https://img2024.cnblogs.com/blog/3503983/202410/3503983-20241003214918313-370669270.png)
