随着大型语言模型(LLMs)的迅速普及,如何有效地引导它们生成安全、适合特定应用和目标受众的内容成为一个关键挑战。例如,我们可能希望语言模型在与幼儿园孩子互动时使用不同的语言,或在撰写喜剧小品、提供法律支持或总结新闻文章时采用不同的风格。
目前,最成功的LLM范式是训练一个可用于多种任务的大型自回归模型。然而,现有的引导生成方法各有优缺点:
- 微调方法虽然有效,但改变了模型权重,可能会降低LLM的性能。此外,如果新应用需要独特的属性组合(如幽默但不具攻击性),就需要微调和部署新的专用模型。
- 即插即用方法不改变模型权重,而是使用额外的轻量级分类器或启发式方法来影响生成过程。这些方法灵活性高,不需要微调或托管专用模型。但由于它们通常只改变最后一层的logits,容易产生解码错误,这些错误会在自回归生成过程中级联并降低输出质量。
- 扩散模型最初在图像生成领域取得了突破,它们通过迭代"去噪"高斯噪声样本来生成目标数据分布的样本。这种迭代生成过程自然允许通过简单的似然函数进行即插即用控制。然而,目前的文本扩散模型在困惑度和生成质量上仍然不如自回归模型。
为了解决这些挑战,研究者提出了一种新的框架:扩散引导语言建模(Diffusion Guided Language Modeling, DGLM)。DGLM旨在结合自回归生成的流畅性和连续扩散的灵活性,为可控文本生成提供一种更有效的方法。
DGLM方法详解
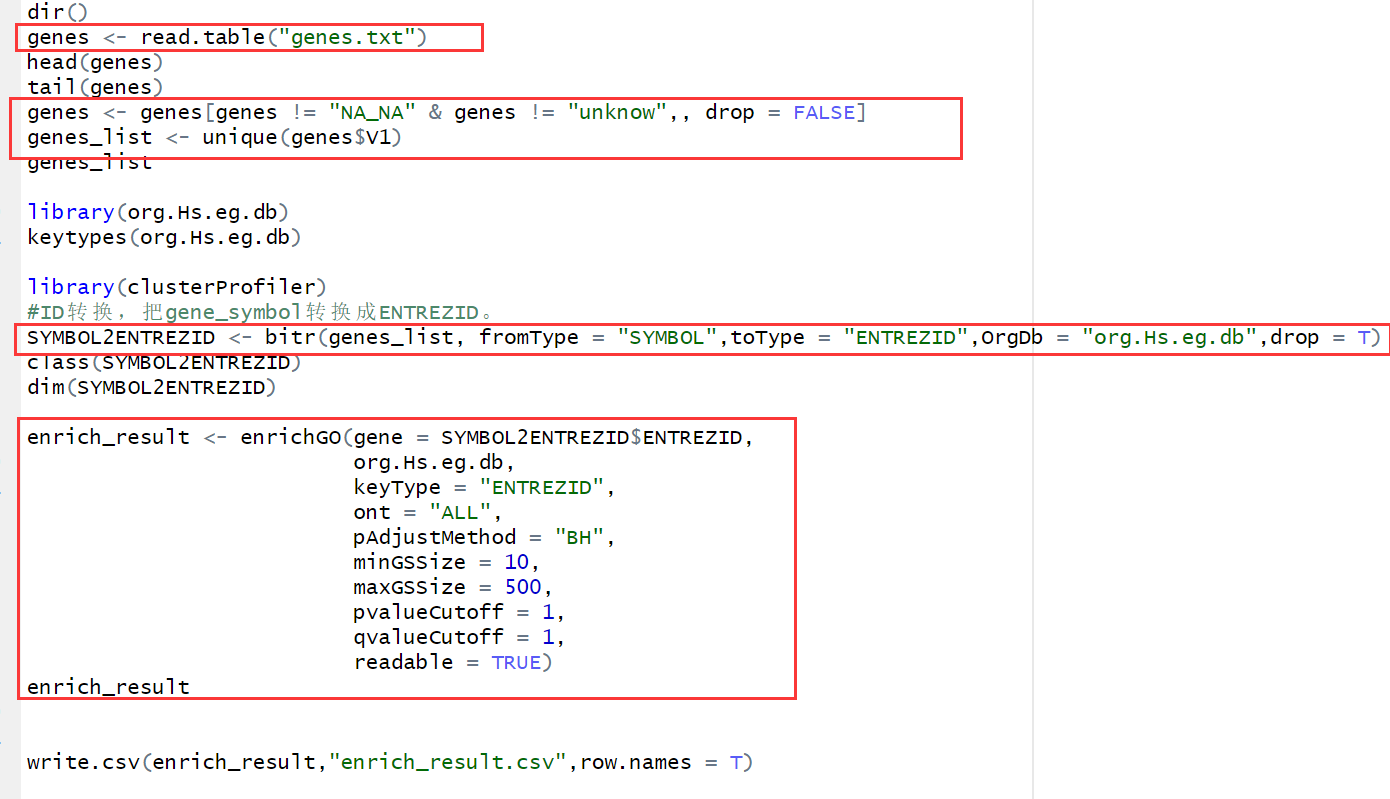
DGLM框架包含三个主要组件:扩散网络、轻量级提示生成器和预训练的自回归解码器。其工作流程如下:
- 给定一些文本前缀,使用扩散模型采样生成可能的延续的嵌入语义提案。
- 在采样过程中,可以选择性地执行即插即用控制以强制某些条件(如低毒性)。
- 采样语义嵌入后,提示生成器将嵌入处理成软提示。
- 软提示引导自回归解码器生成与提案对齐的文本。
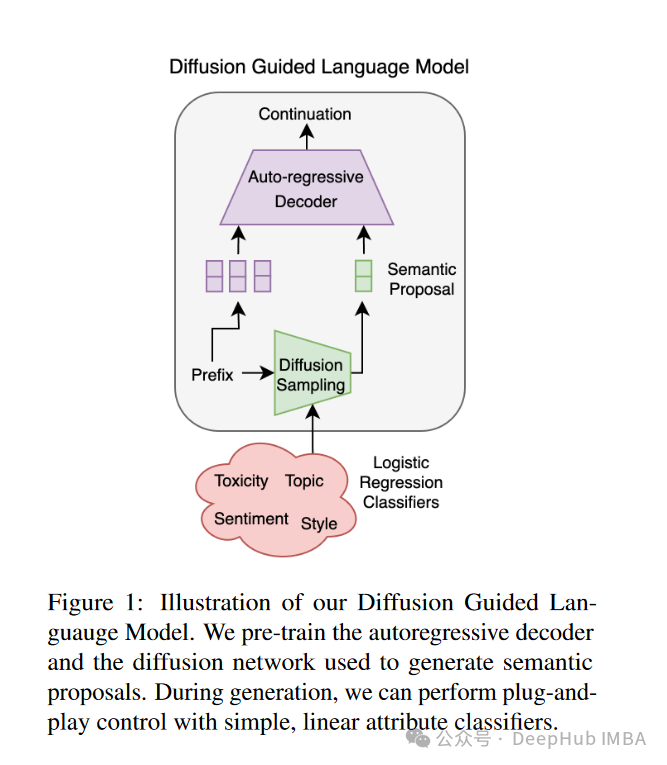
图1: DGLM框架概览。给定一些前缀,我们首先用扩散模型生成语言延续的嵌入表示。在这个阶段,我们可以选择性地用轻量级分类器进行即插即用引导干预。我们将延续嵌入映射到软提示,以引导自回归解码器生成与生成的嵌入语义对齐的语言。
https://avoid.overfit.cn/post/e935645b2c5743458e78e333137a79b8
![day9[探索 InternLM 模型能力边界]](https://img2024.cnblogs.com/blog/3229976/202410/3229976-20241004134318612-607741735.png)

![[leetcode 25]. K 个一组翻转链表](https://images.cnblogs.com/OutliningIndicators/ExpandedBlockStart.gif)