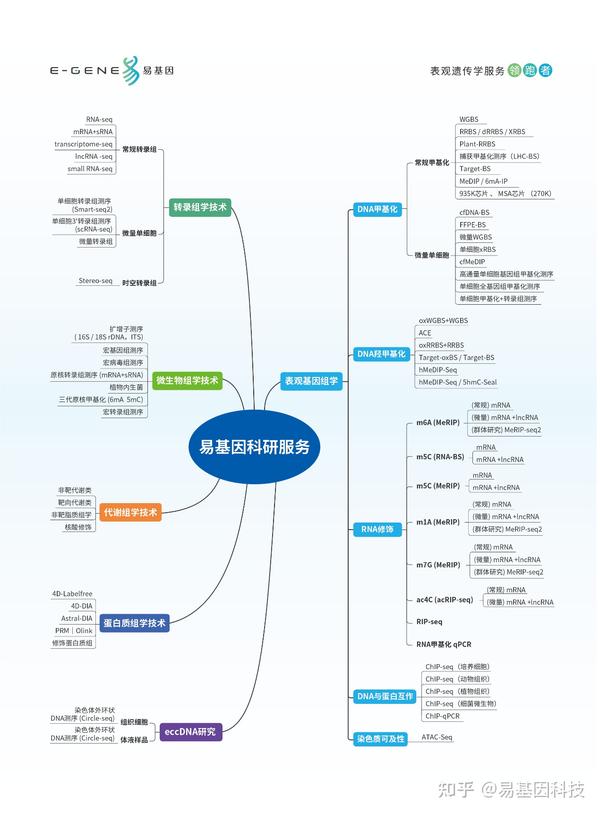
1.YOLOv8-seg简介
YOLOv8-seg是YOLO系列模型的其中一个版本。YOLOv8-seg在继承YOLO系列模型高效性和准确性的基础上,增加了实例分割的能力。
2.数据集
使用的数据集较简单,主要以下目录:
images:存放原始图片(1500张),大小为128x128。部分如下:

images_json:存放labelme标注的json文件与原图。部分图如下:

masks:存放单通道掩码

mask_txt:存放masks中每个标签掩码图对应的每个像素值


palette_mask:存放标签掩码图的调色板图或伪彩色图。

事实上,本次训练任务只需要images与images_json。
3.下载安装包
需要下载ultralytics,github下载或者pip安装(pip安装只有ultralytics),建议github下载,里面内容更全,包括例子与说明。
官网github地址:https://github.com/ultralytics/ultralytics
官网文档:https://docs.ultralytics.com/
下载后,主要关注examples与ultralytics

3.获取YOLOV8-seg训练的数据集格式及文件
YOLOV8-seg模型在进行实例分割时,首先会执行目标检测以识别图像中的物体,然后再对这些物体进行分割。故训练时需要分割预训练权重yolov8n-seg.pt的同时,也需要对应的目标检测yolov8n.pt权重。如果网络良好可以不用下载,当程序检测到没有这些文件时,会自动下载。关于这两个文件直接去官网下载或者网上下载(如图),这里也给个百度盘的链接: 链接:https://pan.baidu.com/s/1Tkzi8bflpIuGTIqR18AFOg提取码:hniz

3.1划分数据集与生成yaml文件
# -*- coding: utf-8 -*- from tqdm import tqdm import shutil import random import os import argparse from collections import Counter import yaml import json# 检查文件夹是否存在 def mkdir(path):if not os.path.exists(path):os.makedirs(path)def convert_to_polygon(point1,point2):x1, y1 = point1x2, y2 = point2return [[x1,y1],[x2,y1],[x2,y2],[x1,y2]]def convert_label_json(json_dir, save_dir, classes):json_paths = os.listdir(json_dir)classes = classes.split(',')mkdir(save_dir)for json_path in tqdm(json_paths):# for json_path in json_paths:path = os.path.join(json_dir, json_path)with open(path, 'r') as load_f:json_dict = json.load(load_f)h, w = json_dict['imageHeight'], json_dict['imageWidth']# save txt pathtxt_path = os.path.join(save_dir, json_path.replace('json', 'txt'))txt_file = open(txt_path, 'w')for shape_dict in json_dict['shapes']:shape_type = shape_dict.get('shape_type',None)label = shape_dict['label']label_index = classes.index(label)points = shape_dict['points']if shape_type == "rectangle":point1=points[0]point2=points[1]points=convert_to_polygon(point1,point2)points_nor_list = []for point in points:points_nor_list.append(point[0] / w)points_nor_list.append(point[1] / h)points_nor_list = list(map(lambda x: str(x), points_nor_list))points_nor_str = ' '.join(points_nor_list)label_str = str(label_index) + ' ' + points_nor_str + '\n'txt_file.writelines(label_str)def get_classes(json_dir):'''统计路径下 JSON 文件里的各类别标签数量'''names = []json_files = [os.path.join(json_dir, f) for f in os.listdir(json_dir) if f.endswith('.json')]for json_path in json_files:with open(json_path, 'r') as f:data = json.load(f)for shape in data['shapes']:name = shape['label']names.append(name)result = Counter(names)return resultdef main(image_dir, json_dir, txt_dir, save_dir):# 创建文件夹 mkdir(save_dir)images_dir = os.path.join(save_dir, 'images')labels_dir = os.path.join(save_dir, 'labels')img_train_path = os.path.join(images_dir, 'train')img_val_path = os.path.join(images_dir, 'val')label_train_path = os.path.join(labels_dir, 'train')label_val_path = os.path.join(labels_dir, 'val')mkdir(images_dir)mkdir(labels_dir)mkdir(img_train_path)mkdir(img_val_path)mkdir(label_train_path)mkdir(label_val_path)# 数据集划分比例,训练集75%,验证集15%,测试集15%,按需修改train_percent = 0.90val_percent = 0.10total_txt = os.listdir(txt_dir)num_txt = len(total_txt)list_all_txt = range(num_txt) # 范围 range(0, num) num_train = int(num_txt * train_percent)num_val = int(num_txt * val_percent)train = random.sample(list_all_txt, num_train)# 在全部数据集中取出trainval = [i for i in list_all_txt if not i in train]# 再从val_test取出num_val个元素,val_test剩下的元素就是test# val = random.sample(list_all_txt, num_val)print("训练集数目:{}, 验证集数目:{}".format(len(train), len(val)))for i in list_all_txt:name = total_txt[i][:-4]srcImage = os.path.join(image_dir, name + '.png')#如果图片是jpg就改为.jpgsrcLabel = os.path.join(txt_dir, name + '.txt')if i in train:dst_train_Image = os.path.join(img_train_path, name + '.png')#如果图片是jpg就改为.jpgdst_train_Label = os.path.join(label_train_path, name + '.txt')shutil.copyfile(srcImage, dst_train_Image)shutil.copyfile(srcLabel, dst_train_Label)elif i in val:dst_val_Image = os.path.join(img_val_path, name + '.png')#如果图片是jpg就改为.jpgdst_val_Label = os.path.join(label_val_path, name + '.txt')shutil.copyfile(srcImage, dst_val_Image)shutil.copyfile(srcLabel, dst_val_Label)obj_classes = get_classes(json_dir)classes = list(obj_classes.keys())# 编写yaml文件classes_txt = {i: classes[i] for i in range(len(classes))} # 标签类别data = {'path': os.path.join(os.getcwd(), save_dir),'train': "images/train",'val': "images/val",'names': classes_txt,'nc': len(classes)}with open(save_dir + '/segment.yaml', 'w', encoding="utf-8") as file:yaml.dump(data, file, allow_unicode=True)print("标签:", dict(obj_classes))if __name__ == "__main__":classes_list = 'circle,rect' # 类名 parser = argparse.ArgumentParser(description='json convert to txt params')parser.add_argument('--image-dir', type=str, default=r'D:\software\pythonworksapce\yolo8_seg_train\data\images', help='图片地址') #图片文件夹路径parser.add_argument('--json-dir', type=str, default=r'D:\software\pythonworksapce\yolo8_seg_train\data\json_out', help='json地址')#labelme标注的纯json文件夹路径parser.add_argument('--txt-dir', type=str, default=r'D:\software\pythonworksapce\yolo8_seg_train\train_data\save_txt', help='保存txt文件地址')#标注的坐标的txt文件存放的路径parser.add_argument('--save-dir', default=r'D:\software\pythonworksapce\yolo8_seg_train\train_data', type=str, help='保存最终分割好的数据集地址')#segment.yaml存放的路径parser.add_argument('--classes', type=str, default=classes_list, help='classes')args = parser.parse_args()json_dir = args.json_dirtxt_dir = args.txt_dirimage_dir = args.image_dirsave_dir = args.save_dirclasses = args.classes# json格式转txt格式 convert_label_json(json_dir, txt_dir, classes)# 划分数据集,生成yaml训练文件main(image_dir, json_dir, txt_dir, save_dir)
上述代码中,生成的数据集,只支持多边形标注与矩形标注。
划分完后,train_data目录下将会生成如下文件:

images中有tain,val两个文件夹,每个文件夹包含原始图片
labels中有tain,val两个文件夹,每个文件夹包含每个图对应的txt文件,文件中每行的最前面为数字类别索引,后面为x1 y1 x2 y2 x3 y3 ......组成的坐标点归一化后的数据。如图:

save_txt为中间生成的,用于划分labels的
segment.yaml为训练时需要配置的文件,nc表示类别数,具体内容如下:

4.训练
from ultralytics import YOLOif __name__ == '__main__':model = YOLO(r"D:\software\pythonworksapce\yolo8_seg_train\yolov8n-seg.yaml",task="segment").load(r"./yolov8n-seg.pt") # build from YAML and transfer weights
results = model.train(data=r"D:\software\pythonworksapce\yolo8_seg_train\train_data\segment.yaml", epochs=200,imgsz=128, device=[0])
注意:我们写的yolov8n-seg.yaml,其实有yolov8-seg.yaml这个文件就可以了,后面的n程序会自动适配到最小的模型,可以参考yolov8-seg.yaml源文件注释。

5.转onnx模型
from ultralytics import YOLO# Load a model # model = YOLO("yolo11n.pt") # load an official model model = YOLO(r"D:\software\pythonworksapce\yolo8_seg_train\runs\segment\train\weights\best.pt") # load a custom trained model# Export the model model.export(format="onnx")
5.onnx推理
可以使用ultralytics自带的onnx推理程序。如图:

这里我稍微添加了几个自定义的函数,推理代码及结果如下:
import argparse import osfrom datetime import datetime import cv2 import numpy as np import onnxruntime as ortfrom ultralytics.utils import ASSETS, yaml_load from ultralytics.utils.checks import check_yaml from ultralytics.utils.plotting import Colorsclass YOLOv8Seg:"""YOLOv8 segmentation model."""def __init__(self, onnx_model, yaml_path="coco128.yaml"):"""Initialization.Args:onnx_model (str): Path to the ONNX model."""# Build Ort sessionself.session = ort.InferenceSession(onnx_model,providers=['CUDAExecutionProvider', 'CPUExecutionProvider']if ort.get_device() == 'GPU' else ['CPUExecutionProvider'])# Numpy dtype: support both FP32 and FP16 onnx modelself.ndtype = np.half if self.session.get_inputs()[0].type == 'tensor(float16)' else np.single# Get model width and height(YOLOv8-seg only has one input)self.model_height, self.model_width = [x.shape for x in self.session.get_inputs()][0][-2:]# Load COCO class namesself.classes = yaml_load(check_yaml(yaml_path))['names']# Create color paletteself.color_palette = Colors()def __call__(self, im0, conf_threshold=0.4, iou_threshold=0.45, nm=32):"""The whole pipeline: pre-process -> inference -> post-process.Args:im0 (Numpy.ndarray): original input image.conf_threshold (float): confidence threshold for filtering predictions.iou_threshold (float): iou threshold for NMS.nm (int): the number of masks.Returns:boxes (List): list of bounding boxes.segments (List): list of segments.masks (np.ndarray): [N, H, W], output masks."""# Pre-processim, ratio, (pad_w, pad_h) = self.preprocess(im0)print("im.shape", im.shape)# Ort inferencepreds = self.session.run(None, {self.session.get_inputs()[0].name: im})# Post-processboxes, segments, masks = self.postprocess(preds,im0=im0,ratio=ratio,pad_w=pad_w,pad_h=pad_h,conf_threshold=conf_threshold,iou_threshold=iou_threshold,nm=nm)return boxes, segments, masksdef preprocess(self, img):"""Pre-processes the input image.Args:img (Numpy.ndarray): image about to be processed.Returns:img_process (Numpy.ndarray): image preprocessed for inference.ratio (tuple): width, height ratios in letterbox.pad_w (float): width padding in letterbox.pad_h (float): height padding in letterbox."""# Resize and pad input image using letterbox() (Borrowed from Ultralytics)shape = img.shape[:2] # original image shapenew_shape = (self.model_height, self.model_width)r = min(new_shape[0] / shape[0], new_shape[1] / shape[1])ratio = r, rnew_unpad = int(round(shape[1] * r)), int(round(shape[0] * r))pad_w, pad_h = (new_shape[1] - new_unpad[0]) / 2, (new_shape[0] - new_unpad[1]) / 2 # wh paddingif shape[::-1] != new_unpad: # resizeimg = cv2.resize(img, new_unpad, interpolation=cv2.INTER_LINEAR)top, bottom = int(round(pad_h - 0.1)), int(round(pad_h + 0.1))left, right = int(round(pad_w - 0.1)), int(round(pad_w + 0.1))img = cv2.copyMakeBorder(img, top, bottom, left, right, cv2.BORDER_CONSTANT, value=(114, 114, 114))# Transforms: HWC to CHW -> BGR to RGB -> div(255) -> contiguous -> add axis(optional)img = np.ascontiguousarray(np.einsum('HWC->CHW', img)[::-1], dtype=self.ndtype) / 255.0img_process = img[None] if len(img.shape) == 3 else imgreturn img_process, ratio, (pad_w, pad_h)def postprocess(self, preds, im0, ratio, pad_w, pad_h, conf_threshold, iou_threshold, nm=32):"""Post-process the prediction.Args:preds (Numpy.ndarray): predictions come from ort.session.run().im0 (Numpy.ndarray): [h, w, c] original input image.ratio (tuple): width, height ratios in letterbox.pad_w (float): width padding in letterbox.pad_h (float): height padding in letterbox.conf_threshold (float): conf threshold.iou_threshold (float): iou threshold.nm (int): the number of masks.Returns:boxes (List): list of bounding boxes.segments (List): list of segments.masks (np.ndarray): [N, H, W], output masks."""x, protos = preds[0], preds[1] # Two outputs: predictions and protos# Transpose the first output: (Batch_size, xywh_conf_cls_nm, Num_anchors) -> (Batch_size, Num_anchors, xywh_conf_cls_nm)x = np.einsum('bcn->bnc', x)# Predictions filtering by conf-thresholdx = x[np.amax(x[..., 4:-nm], axis=-1) > conf_threshold]# Create a new matrix which merge these(box, score, cls, nm) into one# For more details about `numpy.c_()`: https://numpy.org/doc/1.26/reference/generated/numpy.c_.htmlx = np.c_[x[..., :4], np.amax(x[..., 4:-nm], axis=-1), np.argmax(x[..., 4:-nm], axis=-1), x[..., -nm:]]# NMS filteringx = x[cv2.dnn.NMSBoxes(x[:, :4], x[:, 4], conf_threshold, iou_threshold)]# print("x",x)# Decode and returnif len(x) > 0:# Bounding boxes format change: cxcywh -> xyxyx[..., [0, 1]] -= x[..., [2, 3]] / 2x[..., [2, 3]] += x[..., [0, 1]]# Rescales bounding boxes from model shape(model_height, model_width) to the shape of original imagex[..., :4] -= [pad_w, pad_h, pad_w, pad_h]x[..., :4] /= min(ratio)# Bounding boxes boundary clampx[..., [0, 2]] = x[:, [0, 2]].clip(0, im0.shape[1])x[..., [1, 3]] = x[:, [1, 3]].clip(0, im0.shape[0])# Process masksmasks = self.process_mask(protos[0], x[:, 6:], x[:, :4], im0.shape)# Masks -> Segments(contours)segments = self.masks2segments(masks)return x[..., :6], segments, masks # boxes, segments, maskselse:return [], [], []@staticmethoddef masks2segments(masks):"""It takes a list of masks(n,h,w) and returns a list of segments(n,xy) (Borrowed fromhttps://github.com/ultralytics/ultralytics/blob/465df3024f44fa97d4fad9986530d5a13cdabdca/ultralytics/utils/ops.py#L750)Args:masks (numpy.ndarray): the output of the model, which is a tensor of shape (batch_size, 160, 160).Returns:segments (List): list of segment masks."""segments = []for x in masks.astype('uint8'):c = cv2.findContours(x, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_NONE)[0] # CHAIN_APPROX_SIMPLEif c:c = np.array(c[np.array([len(x) for x in c]).argmax()]).reshape(-1, 2)else:c = np.zeros((0, 2)) # no segments foundsegments.append(c.astype('float32'))return segments@staticmethoddef crop_mask(masks, boxes):"""It takes a mask and a bounding box, and returns a mask that is cropped to the bounding box. (Borrowed fromhttps://github.com/ultralytics/ultralytics/blob/465df3024f44fa97d4fad9986530d5a13cdabdca/ultralytics/utils/ops.py#L599)Args:masks (Numpy.ndarray): [n, h, w] tensor of masks.boxes (Numpy.ndarray): [n, 4] tensor of bbox coordinates in relative point form.Returns:(Numpy.ndarray): The masks are being cropped to the bounding box."""n, h, w = masks.shapex1, y1, x2, y2 = np.split(boxes[:, :, None], 4, 1)r = np.arange(w, dtype=x1.dtype)[None, None, :]c = np.arange(h, dtype=x1.dtype)[None, :, None]return masks * ((r >= x1) * (r < x2) * (c >= y1) * (c < y2))def process_mask(self, protos, masks_in, bboxes, im0_shape):"""Takes the output of the mask head, and applies the mask to the bounding boxes. This produces masks of higher qualitybut is slower. (Borrowed from https://github.com/ultralytics/ultralytics/blob/465df3024f44fa97d4fad9986530d5a13cdabdca/ultralytics/utils/ops.py#L618)Args:protos (numpy.ndarray): [mask_dim, mask_h, mask_w].masks_in (numpy.ndarray): [n, mask_dim], n is number of masks after nms.bboxes (numpy.ndarray): bboxes re-scaled to original image shape.im0_shape (tuple): the size of the input image (h,w,c).Returns:(numpy.ndarray): The upsampled masks."""c, mh, mw = protos.shapemasks = np.matmul(masks_in, protos.reshape((c, -1))).reshape((-1, mh, mw)).transpose(1, 2, 0) # HWNmasks = np.ascontiguousarray(masks)masks = self.scale_mask(masks, im0_shape) # re-scale mask from P3 shape to original input image shapemasks = np.einsum('HWN -> NHW', masks) # HWN -> NHWmasks = self.crop_mask(masks, bboxes)return np.greater(masks, 0.5)@staticmethoddef scale_mask(masks, im0_shape, ratio_pad=None):"""Takes a mask, and resizes it to the original image size. (Borrowed fromhttps://github.com/ultralytics/ultralytics/blob/465df3024f44fa97d4fad9986530d5a13cdabdca/ultralytics/utils/ops.py#L305)Args:masks (np.ndarray): resized and padded masks/images, [h, w, num]/[h, w, 3].im0_shape (tuple): the original image shape.ratio_pad (tuple): the ratio of the padding to the original image.Returns:masks (np.ndarray): The masks that are being returned."""im1_shape = masks.shape[:2]if ratio_pad is None: # calculate from im0_shapegain = min(im1_shape[0] / im0_shape[0], im1_shape[1] / im0_shape[1]) # gain = old / newpad = (im1_shape[1] - im0_shape[1] * gain) / 2, (im1_shape[0] - im0_shape[0] * gain) / 2 # wh paddingelse:pad = ratio_pad[1]# Calculate tlbr of masktop, left = int(round(pad[1] - 0.1)), int(round(pad[0] - 0.1)) # y, xbottom, right = int(round(im1_shape[0] - pad[1] + 0.1)), int(round(im1_shape[1] - pad[0] + 0.1))if len(masks.shape) < 2:raise ValueError(f'"len of masks shape" should be 2 or 3, but got {len(masks.shape)}')masks = masks[top:bottom, left:right]masks = cv2.resize(masks, (im0_shape[1], im0_shape[0]),interpolation=cv2.INTER_LINEAR) # INTER_CUBIC would be betterif len(masks.shape) == 2:masks = masks[:, :, None]return masksdef draw_and_visualize(self, im, bboxes, segments, vis=False, save=True):"""Draw and visualize results.Args:im (np.ndarray): original image, shape [h, w, c].bboxes (numpy.ndarray): [n, 4], n is number of bboxes.segments (List): list of segment masks.vis (bool): imshow using OpenCV.save (bool): save image annotated.Returns:None"""# Draw rectangles and polygonsim_canvas = im.copy()for (*box, conf, cls_), segment in zip(bboxes, segments):# draw contour and fill maskcv2.polylines(im, np.int32([segment]), True, (255, 255, 255), 2) # white borderlinecv2.fillPoly(im_canvas, np.int32([segment]), self.color_palette(int(cls_), bgr=True))# draw bbox rectanglecv2.rectangle(im, (int(box[0]), int(box[1])), (int(box[2]), int(box[3])),self.color_palette(int(cls_), bgr=True), 1, cv2.LINE_AA)cv2.putText(im, f'{self.classes[cls_]}: {conf:.3f}', (int(box[0]), int(box[1] - 9)),cv2.FONT_HERSHEY_SIMPLEX, 0.7, self.color_palette(int(cls_), bgr=True), 2, cv2.LINE_AA)# Mix imageim = cv2.addWeighted(im_canvas, 0.3, im, 0.7, 0)# Show imageif vis:cv2.imshow('demo', im)cv2.waitKey(0)cv2.destroyAllWindows()# Save imageif save:from datetime import datetime# 获取当前时间now = datetime.now()# 格式化为 '年月日时分秒毫秒'formatted_time = now.strftime('%Y%m%d%H%M%S') + str(now.microsecond // 1000).zfill(3)cv2.imwrite(f'{formatted_time}.jpg', im)####self def def load_yolov8_seg_onnx_model(onnx_path, yaml_path):yolov8_seg_model = YOLOv8Seg(onnx_path, yaml_path=yaml_path)return yolov8_seg_model####self def def call_yolov8_seg_onnx_inference(img, yolov8_seg_model, conf=0.25, iou=0.45):boxes, segments, _ = yolov8_seg_model(img, conf_threshold=conf, iou_threshold=iou)return boxes, segments, _####self def def get_points_rect_class(boxes, segments):for box, seg_points in zip(boxes, segments):# print("type(seg_points)",type(seg_points))class_index = int(box[-1])confidence = box[-2]# left_topleft_top_x = box[0]left_top_y = box[1]# right_bottonright_bottom_x = box[2]right_bottom_y = box[3]x = int(left_top_x)y = int(left_top_y)w = int(right_bottom_x - left_top_x)h = int(right_bottom_y - left_top_y)seg_points = seg_points.astype(int)yield x, y, w, h, seg_points, class_index, confidence####self def def get_image_paths(folder_path, extension=".png", is_use_extension=False):image_paths = []# 遍历目录for root, dirs, files in os.walk(folder_path):for file in files:# 检查文件扩展名if file.endswith(extension) or is_use_extension == False:# 构造完整的文件路径并添加到列表image_path = os.path.join(root, file)image_paths.append(image_path)return image_paths####self def def get_boxes_contour(points):contour = points.reshape((-1, 1, 2))return contourif __name__ == '__main__':folder_path = r'D:\software\pythonworksapce\yolo8_seg_train\pre'onnx_path = r'D:\software\pythonworksapce\yolo8_seg_train\runs\segment\train\weights\best.onnx'yaml_path = r'D:\software\pythonworksapce\yolo8_seg_train\train_data\segment.yaml'yolov8_seg_model = load_yolov8_seg_onnx_model(onnx_path, yaml_path)images_paths = get_image_paths(folder_path, extension=".png")for img_path in images_paths:print("img_path", img_path)img = cv2.imread(img_path, 1)boxes, segments, _ = call_yolov8_seg_onnx_inference(img, yolov8_seg_model, conf=0.5, iou=0.4) #每个图的结果都在这里if len(boxes) > 0:yolov8_seg_model.draw_and_visualize(img, boxes, segments, vis=False, save=True)
测试的五张图效果如下:
原图

模型推理的效果图(与上图一一对应,这里使用时间命名了)

最后训了一个道路的数据集,看下效果。

数据集(几何图)链接:
通过网盘分享的文件:data.zip
链接: https://pan.baidu.com/s/1ZGnxNYz2pynRC1EtSAagjw 提取码: awie
小结:本文只是对yolov8-seg模型的训练进行了叙述,并未讲解模型结构,后续会再补充。另外本文再使用onnx推理图片时,使用了自带的ultralytics中自带的YOLOv8Seg这个类推理预测,但是也会导致程序冗余,比如会加载不需要使用的torch等包,读者可以研读代码,将核心代码提取出来,重新定义自己的前向预处理,后向结构处理函数。
若存在不足之处,欢迎评论与指正。