协议:CC BY-NC-SA 4.0
译者:飞龙
本文来自【OpenDocCN 饱和式翻译计划】,采用译后编辑(MTPE)流程来尽可能提升效率。
收割 SB 的人会被 SB 们封神,试图唤醒 SB 的人是 SB 眼中的 SB。——SB 第三定律
十五、破解仿射密码
原文:https://inventwithpython.com/cracking/chapter15.html
直到一个文明在包括数学、统计学和语言学在内的几个学科中达到足够复杂的学术水平,密码分析才能被发明出来。
——西蒙·辛格,《密码之书》

在第 14 章中,您了解到仿射密码仅限于几千个密钥,这意味着我们可以轻松地对其进行暴力攻击。在这一章中,你将学习如何编写一个程序来破解仿射密码加密的信息。
本章涵盖的主题
-
指数运算符(
**) -
continue语句
仿射密码破解程序的源代码
选择文件 -> 新文件,打开新文件编辑器窗口。在文件编辑器中输入以下代码,然后保存为affineHacker.py。手动输入myMessage变量的字符串可能有些棘手,所以你可以从www.nostarch.com/crackingcodes的affineHacker.py文件中复制并粘贴它以节省时间。确保dictionary.txt以及pyperclip.py、affinicipher.py、detectEnglish.py和cryptomath.py与affinihacker.py在同一个目录下。
affineHacker.py
# Affine Cipher Hacker
# https://www.nostarch.com/crackingcodes/ (BSD Licensed)import pyperclip, affineCipher, detectEnglish, cryptomathSILENT_MODE = Falsedef main():# You might want to copy & paste this text from the source code at# https://www.nostarch.com/crackingcodes/.myMessage = """5QG9ol3La6QI93!xQxaia6faQL9QdaQG1!!axQARLa!!AuaRLQADQALQG93!xQxaGaAfaQ1QX3o1RQARL9Qda!AafARuQLX1LQALQI1iQX3o1RN"Q-5!1RQP36ARu"""hackedMessage = hackAffine(myMessage)if hackedMessage != None:# The plaintext is displayed on the screen. For the convenience of# the user, we copy the text of the code to the clipboard:print('Copying hacked message to clipboard:')print(hackedMessage)pyperclip.copy(hackedMessage)else:print('Failed to hack encryption.')def hackAffine(message):print('Hacking...')# Python programs can be stopped at any time by pressing Ctrl-C (on# Windows) or Ctrl-D (on macOS and Linux):print('(Press Ctrl-C or Ctrl-D to quit at any time.)')# Brute-force by looping through every possible key:for key in range(len(affineCipher.SYMBOLS) ** 2):keyA = affineCipher.getKeyParts(key)[0]if cryptomath.gcd(keyA, len(affineCipher.SYMBOLS)) != 1:continuedecryptedText = affineCipher.decryptMessage(key, message)if not SILENT_MODE:print('Tried Key %s... (%s)' % (key, decryptedText[:40]))if detectEnglish.isEnglish(decryptedText):# Check with the user if the decrypted key has been found:print()print('Possible encryption hack:')print('Key: %s' % (key))print('Decrypted message: ' + decryptedText[:200])print()print('Enter D for done, or just press Enter to continuehacking:')response = input('> ')if response.strip().upper().startswith('D'):return decryptedTextreturn None# If affineHacker.py is run (instead of imported as a module), call
# the main() function:
if __name__ == '__main__':main()
仿射密码破解程序的示例运行
在文件编辑器中按F5,运行affineHacker.py程序;输出应该如下所示:
Hacking...
(Press Ctrl-C or Ctrl-D to quit at any time.)
Tried Key 95... (U&'<3dJ^Gjx'-3^MS'Sj0jxuj'G3'%j'<mMMjS'g)
Tried Key 96... (T%&;2cI]Fiw&,2]LR&Ri/iwti&F2&$i&;lLLiR&f)
Tried Key 97... (S$%:1bH\Ehv%+1\KQ%Qh.hvsh%E1%#h%:kKKhQ%e)
--snip--
Tried Key 2190... (?^=!-+.32#0=5-3*"="#1#04#=2-= #=!~**#"=')
Tried Key 2191... (' ^BNLOTSDQ^VNTKC^CDRDQUD^SN^AD^[email protected]^H)
Tried Key 2192... ("A computer would deserve to be called i)
Possible encryption hack:
Key: 2192
Decrypted message: "A computer would deserve to be called intelligent if it
could deceive a human into believing that it was human." -Alan Turing
Enter D for done, or just press Enter to continue hacking:
> d
Copying hacked message to clipboard:
"A computer would deserve to be called intelligent if it could deceive a human
into believing that it was human." –Alan Turing
让我们仔细看看仿射密码破解程序是如何工作的。
设置模块、常量和main()函数
仿射密码破解程序有 60 行长,因为我们已经写了它使用的大部分代码。第 4 行导入了我们在前几章中创建的模块:
# Affine Cipher Hacker
# https://www.nostarch.com/crackingcodes/ (BSD Licensed)import pyperclip, affineCipher, detectEnglish, cryptomathSILENT_MODE = False
当您运行仿射密码破解程序时,您会看到它在通过所有可能的解密时产生大量输出。然而,打印所有这些输出会降低程序的速度。如果你想加速程序,将第 6 行的SILENT_MODE变量设置为True来阻止它打印所有这些消息。
接下来,我们设置main()函数:
def main():# You might want to copy & paste this text from the source code at# https://www.nostarch.com/crackingcodes/.myMessage = """5QG9ol3La6QI93!xQxaia6faQL9QdaQG1!!axQARLa!!AuaRLQADQALQG93!xQxaGaAfaQ1QX3o1RQARL9Qda!AafARuQLX1LQALQI1iQX3o1RN"Q-5!1RQP36ARu"""hackedMessage = hackAffine(myMessage)
被攻击的密文作为一个字符串存储在第 11 行的myMessage中,这个字符串被传递给hackAffine()函数,我们将在下一节中研究这个函数。如果密文被破解,则该调用的返回值是原始消息的字符串,如果破解失败,则返回值是None值。
第 15 到 22 行的代码检查hackedMessage是否被设置为None:
if hackedMessage != None:# The plaintext is displayed on the screen. For the convenience of# the user, we copy the text of the code to the clipboard:print('Copying hacked message to clipboard:')print(hackedMessage)pyperclip.copy(hackedMessage)else:print('Failed to hack encryption.')
如果hackedMessage不等于None,消息将打印到屏幕的第 19 行,并复制到剪贴板的第 20 行。否则,程序会简单地向用户输出反馈,告诉他们无法破解密文。让我们仔细看看hackAffine()函数是如何工作的。
hackAffine()函数
hackAffine()函数从第 25 行开始,包含解密代码。它首先为用户打印一些说明:
def hackAffine(message):print('Hacking...')# Python programs can be stopped at any time by pressing Ctrl-C (on# Windows) or Ctrl-D (on macOS and Linux):print('(Press Ctrl-C or Ctrl-D to quit at any time.)')
解密过程可能需要一段时间,所以如果用户想提前退出程序,可以按下ctrl+C(在 Windows 上)或ctrl+D(在 macOS 和 Linux 上)。
在我们继续余下的代码之前,您需要了解指数运算符。
指数运算符
为了理解仿射密码破解程序(除了基本的+、-、*、/和//运算符之外),您需要知道的一个有用的数学运算符是指数运算符(**)。指数运算符将一个数字提升到另一个数字的幂。例如,在 Python 中,2 的 5 次方是2 ** 5。这相当于 2 乘以自身 5 倍:2 * 2 * 2 * 2 * 2。两个表达式2 ** 5和2 * 2 * 2 * 2 * 2都计算整数32。
在交互式 shell 中输入以下内容,看看**操作符是如何工作的:
>>> 5 ** 2
25
>>> 2 ** 5
32
>>> 123 ** 10
792594609605189126649
表达式5 ** 2的计算结果为25,因为5乘以自身等于25。同样地,2 ** 5返回32,因为2乘以自身五次的结果是32。
让我们回到源代码,看看**操作符在程序中做了什么。
计算可能的密钥总数
第 33 行使用**操作符来计算可能的密钥的总数:
# Brute-force by looping through every possible key:for key in range(len(affineCipher.SYMBOLS) ** 2):keyA = affineCipher.getKeyParts(key)[0]
我们知道密钥 A 最多有len(affineCipher.SYMBOLS)个可能的整数,密钥 B 最多有len(affineCipher.SYMBOLS)个可能的整数。为了得到所有可能的密钥,我们将这些值相乘。因为我们将同一个值本身相乘,所以我们可以在表达式len(affineCipher.SYMBOLS) ** 2中使用**操作符。
第 34 行调用我们在affinicipher.py中使用的getKeyParts()函数,将一个整数密钥分成两个整数。在这个例子中,我们使用函数来获取我们正在测试的密钥的一部分。回想一下,这个函数调用的返回值是两个整数的元组:一个用于密钥 A,一个用于密钥 B。第 34 行通过将[0]放在hackAffine()函数调用之后,将元组的第一个整数存储在keyA中。
例如,affineCipher.getKeyParts(key)[0]对元组和索引(42, 22)[0]求值,然后索引(42, 22)[0]对元组的索引0处的值42求值。这只是得到了键值的一部分,并将它存储在变量keyA中。密钥 B 部分(返回的元组中的第二个值)被忽略,因为我们不需要密钥 B 来计算密钥 A 是否有效。第 35 和 36 行检查keyA是否是仿射密码的有效密钥 A,如果不是,程序继续到下一个密钥进行尝试。为了理解执行如何返回到循环的开始,您需要了解一下continue语句。
continue语句
continue语句单独使用continue关键字,不带任何参数。我们在while或for循环中使用continue语句。当一条continue语句执行时,程序执行立即跳转到下一次迭代的循环开始处。当程序执行到循环块的末尾时,也会发生这种情况。但是一个continue语句使得程序执行在到达循环结束之前跳回到循环的开始。
在交互式 shell 中输入以下内容:
>>> for i in range(3):
... print(i)
... print('Hello!')
...
0
Hello!
1
Hello!
2
Hello!
for循环遍历range对象,并且i中的值变成从0到3的每个整数,但不包括0。在每次迭代中,print('Hello!')函数调用在屏幕上显示Hello!。
现在对比一下下一个例子中的for循环,除了在print('Hello!')行之前有一个continue语句之外,下一个例子与上一个例子相同。
>>> for i in range(3):
... print(i)
... continue
... print('Hello!')
...
0
1
2
请注意,Hello!永远不会被打印,因为continue语句导致程序执行跳回到下一次迭代的for循环的起点,并且执行永远不会到达print('Hello!')行。
一个continue语句通常被放在一个if语句的块中,以便在某些条件下,在循环的开始处继续执行。让我们回到我们的代码,看看它是如何使用continue语句根据使用的密钥跳过执行的。
使用continue跳过代码
在源代码中,第 35 行使用cryptomath模块中的gcd()函数来确定密钥 A 对于符号集大小是否互质:
if cryptomath.gcd(keyA, len(affineCipher.SYMBOLS)) != 1:continue
回想一下,如果两个数的最大公约数(GCD)是 1,那么这两个数就是互质的。如果密钥 A 和符号集大小不是互质的,则第 35 行上的条件是True并且执行第 36 行上的continue语句。这会导致程序执行跳回到下一次迭代的循环起点。结果,如果密钥无效,程序跳过对第 38 行的decryptMessage()的调用,继续尝试其他密钥,直到找到正确的密钥。
当程序找到正确的密钥时,通过用第 38 行的密钥调用decryptMessage()来解密消息:
decryptedText = affineCipher.decryptMessage(key, message)if not SILENT_MODE:print('Tried Key %s... (%s)' % (key, decryptedText[:40]))
如果SILENT_MODE被设置为False,则Tried Key消息被打印在屏幕上,但是如果它被设置为True,则跳过第 40 行上的print()调用。
接下来,第 42 行使用来自detectEnglish模块的isEnglish()函数来检查解密的消息是否被识别为英语:
if detectEnglish.isEnglish(decryptedText):# Check with the user if the decrypted key has been found:print()print('Possible encryption hack:')print('Key: %s' % (key))print('Decrypted message: ' + decryptedText[:200])print()
如果使用了错误的解密密钥,解密后的消息将看起来像随机字符,并且isEnglish()将返回False。但是如果解密后的信息被识别为可读的英语(按照isEnglish()函数的标准),程序会显示给用户。
我们显示一段被识别为英语的解密消息,因为isEnglish()函数可能会错误地将文本识别为英语,即使它没有找到正确的密钥。如果用户决定这确实是正确的解密,他们可以键入D ,然后按Enter。
print('Enter D for done, or just press Enter to continuehacking:')response = input('> ')if response.strip().upper().startswith('D'):return decryptedText
否则,用户只需按下回车键即可从input()调用中返回一个空字符串,而hackAffine()函数将继续尝试更多按密钥。
从第 54 行开头的缩进可以看出,这一行是在第 33 行的for循环完成后执行的:
return None
如果for循环结束并到达第 54 行,那么它已经遍历了所有可能的解密密钥,但没有找到正确的密钥。在这一点上,hackAffine()函数返回None值,表示它没有成功破解密文。
如果程序找到了正确的密钥,执行将会从第 53 行的函数返回,而不会到达第 54 行。
调用main()函数
如果我们将affineHacker.py作为程序运行,那么特殊的__name__变量将被设置为字符串'__main__'而不是'affineHacker'。在这种情况下,我们调用main()函数。
# If affineHacker.py is run (instead of imported as a module), call
# the main() function:
if __name__ == '__main__':main()
仿射密码破解程序到此结束。
总结
这一章相当短,因为它没有介绍任何新的黑客技术。正如你所看到的,只要可能的密钥的数量只有几千个,那么用不了多久,计算机就会对每一个可能的密钥进行暴力破解,并使用isEnglish()函数来搜索正确的密钥。
您学习了指数运算符(**),它将一个数提升到另一个数的幂。您还学习了如何使用continue语句将程序执行发送回循环的开始,而不是等到执行到达块的末尾。
方便的是,我们已经在affineCipher.py、detectEnglish.py和cryptomath.py中为仿射密码黑客编写了很多代码。函数技巧帮助我们在程序中重用代码。
在第 16 章中,你将学习简单的替换密码,这是计算机无法暴力破解的。这个密码可能的密钥数超过万亿万亿!在我们的有生之年,一台笔记本电脑不可能通过这些密钥的一部分,这使得密码对暴力攻击免疫。
练习题
练习题的答案可以在本书的网站www.nostarch.com/crackingcodes找到。
-
2 ** 5求值为什么? -
6 ** 2求值为什么? -
下面的代码打印了什么?
for i in range(5):if i == 2:continueprint(i) -
如果另一个程序运行
import affineHacker,是否会调用affineHacker.py的main()函数?
十六、编程实现简单的替换密码
原文:https://inventwithpython.com/cracking/chapter16.html
“互联网是人类有史以来发明的最解放的工具,也是最好的监控工具。不是非此即彼。都是。”
——约翰·佩里·巴洛,电子前沿基金会联合创始人

在第 15 章中,你了解到仿射密码有大约 1000 个可能的密钥,但是计算机仍然可以轻易地破解所有的密钥。我们需要一种密码,它有如此多的可能密钥,以至于任何计算机都无法强行破解它们。
简单替换密码就是这样一种密码,它可以有效地抵御暴力攻击,因为它有大量可能的密钥。即使你的计算机每秒钟可以尝试一万亿个密钥,它仍然需要 1200 万年来尝试每一个密钥!在本章中,你将编写一个程序来实现简单的替换密码,并学习一些有用的 Python 函数和字符串方法。
本章涵盖的主题
-
sort()列表方法 -
消除字符串中的重复字符
-
包装函数
-
isupper()和islower()字符串方法
简单替换密码的工作原理
为了实现简单的替换密码,我们选择一个随机的字母来加密字母表中的每个字母,每个字母只使用一次。简单替换密码的密钥总是一串随机排列的 26 个字母。对于简单替换密码,有 403,291,461,126,605,635,584,000,000 种不同的可能密钥排序。好多密钥啊!更重要的是,这个数字是如此之大,以至于不可能暴力破解。(要了解这个数字是如何计算出来的,请前往www.nostarch.com/crackingcodes。)
先用纸笔试试简单的代换密码。对于这个例子,我们将加密消息“拂晓时的攻击”使用密钥VJZBGNFEPLITMXDWKQUCRYAHSO。首先,写出字母表中的字母和每个字母下面对应的密钥,如图 16-1 。
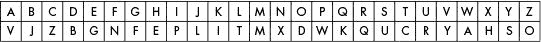
图 16-1:示例密钥的加密字母表
要加密消息,找到顶行明文中的字母,并用底行中的字母替换它。A加密到V,T加密到C,C加密到Z,以此类推。所以这条信息Attack at dawn.加密为Vccvzi vc bvax.。
要解密加密的消息,请在底行的密文中找到该字母,并用顶行的相应字母替换它。V解密到A,C解密到T,Z解密到C,以此类推。
与底行移动但保持字母顺序的凯撒密码不同,在简单替换密码中,底行完全被打乱。这导致更多可能的密钥,这是使用简单替换密码的巨大优势。缺点是密钥有 26 个字符长,比较难记。您可能需要记下密钥,但是如果您这样做了,请确保没有其他人会读到它!
简单替换密码程序的源代码
选择文件 -> 新文件,打开新文件编辑器窗口。在文件编辑器中输入以下代码,保存为simpleSubCipher.py。确保将pyperclip.py文件放在与simpleSubCipher.py文件相同的目录中。按F5运行程序。
简单子
Cipher.py
# Simple Substitution Cipher
# https://www.nostarch.com/crackingcodes/ (BSD Licensed)import pyperclip, sys, randomLETTERS = 'ABCDEFGHIJKLMNOPQRSTUVWXYZ'def main():myMessage = 'If a man is offered a fact which goes against hisinstincts, he will scrutinize it closely, and unless the evidenceis overwhelming, he will refuse to believe it. If, on the otherhand, he is offered something which affords a reason for actingin accordance to his instincts, he will accept it even on theslightest evidence. The origin of myths is explained in this way.-Bertrand Russell'myKey = 'LFWOAYUISVKMNXPBDCRJTQEGHZ'myMode = 'encrypt' # Set to 'encrypt' or 'decrypt'.if keyIsValid(myKey):sys.exit('There is an error in the key or symbol set.')if myMode == 'encrypt':translated = encryptMessage(myKey, myMessage)elif myMode == 'decrypt':translated = decryptMessage(myKey, myMessage)print('Using key %s' % (myKey))print('The %sed message is:' % (myMode))print(translated)pyperclip.copy(translated)print()print('This message has been copied to the clipboard.')def keyIsValid(key):keyList = list(key)lettersList = list(LETTERS)keyList.sort()lettersList.sort()return keyList == lettersListdef encryptMessage(key, message):return translateMessage(key, message, 'encrypt')def decryptMessage(key, message):return translateMessage(key, message, 'decrypt')def translateMessage(key, message, mode):translated = ''charsA = LETTERScharsB = keyif mode == 'decrypt':# For decrypting, we can use the same code as encrypting. We# just need to swap where the key and LETTERS strings are used.charsA, charsB = charsB, charsA# Loop through each symbol in the message:for symbol in message:if symbol.upper() in charsA:# Encrypt/decrypt the symbol:symIndex = charsA.find(symbol.upper())if symbol.isupper():translated += charsB[symIndex].upper()else:translated += charsB[symIndex].lower()else:# Symbol is not in LETTERS; just add it:translated += symbolreturn translateddef getRandomKey():key = list(LETTERS)random.shuffle(key)return ''.join(key)if __name__ == '__main__':main()
简单替换密码程序的运行示例
当您运行simpleSubCipher.py程序时,加密的输出应该如下所示:
Using key LFWOAYUISVKMNXPBDCRJTQEGHZ
The encrypted message is:
Sy l nlx sr pyyacao l ylwj eiswi upar lulsxrj isr sxrjsxwjr, ia esmm
rwctjsxsza sj wmpramh, lxo txmarr jia aqsoaxwa sr pqaceiamnsxu, ia esmm caytra
jp famsaqa sj. Sy, px jia pjiac ilxo, ia sr pyyacao rpnajisxu eiswi lyypcor
l calrpx ypc lwjsxu sx lwwpcolxwa jp isr sxrjsxwjr, ia esmm lwwabj sj aqax
px jia rmsuijarj aqsoaxwa. Jia pcsusx py nhjir sr agbmlsxao sx jisr elh.
-Facjclxo CtrrammThis message has been copied to the clipboard.
注意,如果明文中的字母是小写的,那么它在密文中也是小写的。同样,如果字母在明文中是大写的,那么在密文中也是大写的。简单替换密码不加密空格或标点符号,而只是按原样返回这些字符。
要解密这个密文,将它粘贴为第 10 行的myMessage变量的值,并将myMode改为字符串'decrypt'。当您再次运行该程序时,解密输出应该如下所示:
Using key LFWOAYUISVKMNXPBDCRJTQEGHZ
The decrypted message is:
If a man is offered a fact which goes against his instincts, he will
scrutinize it closely, and unless the evidence is overwhelming, he will refuse
to believe it. If, on the other hand, he is offered something which affords
a reason for acting in accordance to his instincts, he will accept it even
on the slightest evidence. The origin of myths is explained in this way.
-Bertrand RussellThis message has been copied to the clipboard.
设置模块、常量和main()函数
让我们来看看简单替换密码程序的源代码的第一行。
# Simple Substitution Cipher
# https://www.nostarch.com/crackingcodes/ (BSD Licensed)import pyperclip, sys, randomLETTERS = 'ABCDEFGHIJKLMNOPQRSTUVWXYZ'
第 4 行导入了pyperclip、sys和random模块。LETTERS常量变量设置为全部大写字母的字符串,这是为简单替换密码程序设置的符号。
simpleSubCipher.py中的main()函数,类似于前面章节中密码程序的main()函数,在程序第一次运行时被调用。它包含存储用于程序的message、key和mode的变量。
def main():myMessage = 'If a man is offered a fact which goes against hisinstincts, he will scrutinize it closely, and unless the evidenceis overwhelming, he will refuse to believe it. If, on the otherhand, he is offered something which affords a reason for actingin accordance to his instincts, he will accept it even on theslightest evidence. The origin of myths is explained in this way.-Bertrand Russell'myKey = 'LFWOAYUISVKMNXPBDCRJTQEGHZ'myMode = 'encrypt' # Set to 'encrypt' or 'decrypt'.
简单替换密码的密钥很容易出错,因为它们相当长,需要包含字母表中的每个字母。例如,很容易输入缺少一个字母的密钥或两次输入相同字母的密钥。keyIsValid()函数确保密钥可被加密和解密函数使用,如果密钥无效,该函数将退出程序并显示一条错误消息:
if keyIsValid(myKey):sys.exit('There is an error in the key or symbol set.')
如果第 14 行从keyIsValid()返回False,那么myKey包含一个无效的密钥,第 15 行终止程序。
第 16 到 19 行检查myMode变量是否被设置为'encrypt'或'decrypt',并相应地调用encryptMessage()或decryptMessage():
if myMode == 'encrypt':translated = encryptMessage(myKey, myMessage)elif myMode == 'decrypt':translated = decryptMessage(myKey, myMessage)
encryptMessage()和decryptMessage()的返回值是存储在translated变量中的加密或解密消息的字符串。
第 20 行打印屏幕上使用的密钥。加密或解密的消息被打印到屏幕上,并被复制到剪贴板上。
print('Using key %s' % (myKey))print('The %sed message is:' % (myMode))print(translated)pyperclip.copy(translated)print()print('This message has been copied to the clipboard.')
第 25 行是main()函数中的最后一行代码,所以程序执行在第 25 行之后返回。当main()调用在程序的最后一行完成时,程序退出。
接下来,我们将看看keyIsValid()函数如何使用sort()方法来测试密钥是否有效。
sort()列表方法
列表有一个sort()方法,将列表的项目重新排列成数字或字母顺序。当您必须检查两个列表是否包含相同的项目,但它们的排列顺序不同时,这种对列表中的项目进行排序的函数就很方便了。
在simpleSubCipher.py中,一个简单的替换键字符串值只有在符号集中的每个字符都没有重复或丢失字母时才有效。我们可以通过对字符串值进行排序并检查它是否等于排序后的LETTERS来检查它是否是有效的密钥。但是因为我们只能对列表进行排序,而不能对字符串进行排序(回想一下,字符串是不可变的,这意味着它们的值不能被改变),我们将通过将它们传递给list()来获得字符串值的列表版本。然后,在对这些列表进行排序后,我们可以比较这两个列表,看它们是否相等。尽管LETTERS已经按字母顺序排列,我们还是要对它进行排序,因为我们稍后会扩展它以包含其他字符。
def keyIsValid(key):keyList = list(key)lettersList = list(LETTERS)keyList.sort()lettersList.sort()
key中的字符串被传递到第 29 行的list()。返回的列表值存储在名为keyList的变量中。
在第 30 行,LETTERS常量变量(包含字符串'ABCDEFGHIJKLMNOPQRSTUVWXYZ')被传递给list(),后者以如下格式返回列表:['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J', 'K', 'L', 'M', 'N', 'O', 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X', 'Y', 'Z']。
在第 31 和 32 行,keyList和lettersList中的列表通过调用它们的sort()列表方法按字母顺序排序。注意,类似于append()列表方法,sort()列表方法原地修改列表,并且没有返回值。
排序时,keyList和lettersList的值应该是相同的,因为keyList只不过是顺序被打乱的LETTERS中的字符。第 34 行检查值keyList和lettersList是否相等:
return keyList == lettersList
如果keyList和lettersList相等,你可以确定keyList和key参数没有任何重复的字符,因为LETTERS里面没有重复的字符。在这种情况下,第 34 行返回True。但是如果keyList和lettersList不匹配,密钥无效,第 34 行返回False。
包装函数
simpleSubCipher.py程序中的加密代码和解密代码几乎相同。当你有两段非常相似的代码时,最好将它们放入一个函数中并调用两次,而不是输入两次代码。这不仅节省了时间,更重要的是,避免了在复制粘贴代码时引入 bug。这也是有利的,因为如果代码中有 bug,您只需要在一个地方修复 bug,而不是在多个地方。
包装函数通过包装另一个函数的代码并返回包装函数返回的值,帮助您避免输入重复的代码。通常,包装函数会对被包装函数的参数或返回值做一点小小的改变。否则,就没有包装的必要,因为您可以直接调用该函数。
让我们看一个在代码中使用包装函数的例子来理解它们是如何工作的。在这种情况下,第 37 行和第 41 行的encryptMessage()和decryptMessage ()是包装函数:
def encryptMessage(key, message):return translateMessage(key, message, 'encrypt')def decryptMessage(key, message):return translateMessage(key, message, 'decrypt')
这些包装函数中的每一个都调用translateMessage (),这是被包装的函数,并返回translateMessage()返回的值。(我们将在下一节研究translateMessage()函数。)因为两个包装函数使用相同的translateMessage()函数,所以如果我们需要对密码进行任何更改,我们只需要修改这一个函数,而不是encryptMessage()和decryptMessage ()函数。
有了这些包装函数,导入程序simpleSubCipher.py的人可以调用名为encryptMessage()和decryptMessage()的函数,就像他们可以调用本书中所有其他密码程序一样。包装函数有明确的名字,告诉使用这些函数的其他人他们做了什么,而不必看代码。因此,如果我们想要共享我们的代码,其他人可以更容易地使用它。
其他程序可以通过导入密码程序并调用它们的encryptMessage()函数来用各种密码加密消息,如下所示:
import affineCipher, simpleSubCipher, transpositionCipher
--snip--
ciphertext1 = affineCipher.encryptMessage(encKey1, 'Hello!')
ciphertext2 = transpositionCipher.encryptMessage(encKey2, 'Hello!')
ciphertext3 = simpleSubCipher.encryptMessage(encKey3, 'Hello!')
命名一致性是有帮助的,因为它使得熟悉其中一个密码程序的人更容易使用其他密码程序。例如,您可以看到第一个参数始终是密钥,第二个参数始终是消息,这是本书中大多数密码程序使用的约定。使用translateMessage()函数而不是单独的encryptMessage()和decryptMessage函数会与其他程序不一致。
接下来我们来看看translateMessage()函数。
translateMessage()函数
translateMessage()函数用于加密和解密。
def translateMessage(key, message, mode):translated = ''charsA = LETTERScharsB = keyif mode == 'decrypt':# For decrypting, we can use the same code as encrypting. We# just need to swap where the key and LETTERS strings are used.charsA, charsB = charsB, charsA
注意,translateMessage()有参数key和message,还有第三个参数mode。当我们调用translateMessage时,encryptMessage()函数中的调用为mode参数传递'encrypt',decryptMessage()函数中的调用传递'decrypt'。这就是translateMessage()函数如何知道它应该加密还是解密传递给它的消息。
实际的加密过程很简单:对于message参数中的每个字母,该函数在LETTERS中查找该字母的索引,并用在key参数中相同索引处的字母替换该字符。解密则相反:它在key中查找索引,并用LETTERS中相同索引处的字母替换该字符。
程序没有使用LETTERS和key,而是使用变量charsA和charsB,这允许它用charsB中相同索引处的字母替换charsA中的字母。能够改变分配给charsA和charsB的值使得程序很容易在加密和解密之间切换。第 47 行将charsA中的字符设置为LETTERS中的字符,第 48 行将charsB中的字符设置为key中的字符。
下图显示了如何使用相同的代码来加密或解密字母。图 16-2 说明了加密过程。该图中最上面一行显示的是charsA(设置为LETTERS)中的字符,中间一行显示的是charsB(设置为key)中的字符,最下面一行显示的是字符对应的整数索引。

图 16-2:使用索引加密明文
translateMessage()中的代码总是在charsA中查找消息字符的索引,并在该索引处用charsB中的相应字符替换它。所以为了加密,我们让charsA和charsB保持原样。使用变量charsA和charsB将LETTERS中的字符替换为key中的字符,因为charsA被设置为LETTERS而charsB被设置为key。
为了解密,使用行 52 上的charsA, charsB = charsB, charsA切换charsA和charsB中的值。图 16-3 显示了解密过程。

图 16-3:使用索引解密密文
请记住,translateMessage()中的代码总是用charsB中相同索引处的字符替换charsA中的字符。所以当第 52 行交换值时,translateMessage()中的代码执行解密过程,而不是加密过程。
接下来的几行代码显示了程序如何找到用于加密和解密的索引。
# Loop through each symbol in the message:for symbol in message:if symbol.upper() in charsA:# Encrypt/decrypt the symbol:symIndex = charsA.find(symbol.upper())
第 55 行的for循环在循环的每次迭代中将symbol变量设置为message字符串中的一个字符。如果这个符号的大写形式存在于charsA(回想一下key和LETTERS中只有大写字符),第 58 行找到symbol大写形式在charsA中的索引。symIndex变量存储这个索引。
我们已经知道,find()方法永远不会返回-1(来自find()方法的-1意味着在字符串中找不到参数),因为第 56 行的if语句保证了symbol.upper()存在于charsA中。否则,第 58 行就不会被执行。
接下来,我们将使用每个加密或解密的symbol来构建由translateMessage()函数返回的字符串。但是因为key和LETTERS都是大写的,我们需要检查message中最初的symbol是否是小写的,如果是,那么将解密或加密的symbol调整为小写。要做到这一点,你需要学习两个字符串方法:isupper()和islower()。
isupper()和islower()字符串方法
isupper()和islower()方法检查字符串是大写还是小写。
更具体地说,如果这两个条件都满足,isupper()字符串方法返回True:
-
该字符串至少有一个大写字母。
-
该字符串中没有任何小写字母。
如果这两个条件都满足,islower()字符串方法返回True:
-
该字符串至少有一个小写字母。
-
该字符串中没有任何大写字母。
字符串中的非字母字符不影响这些方法是返回True还是False,尽管如果字符串中只存在非字母字符,这两种方法的计算结果都是False。在交互式 shell 中输入以下内容,查看这些方法是如何工作的:
>>> 'HELLO'.isupper()True>>> 'HELLO WORLD 123'.isupper() # ➊True>>> 'hello'.islower() # ➋True>>> '123'.isupper()False>>> ''.islower()False
在 ➊ 的例子返回True,因为'HELLO WORLD 123'中至少有一个大写字母,没有小写字母。字符串中的数字不会影响计算。在 ➋,'hello'.islower()返回True,因为字符串'hello'中至少有一个小写字母,没有大写字母。
让我们回到我们的代码,看看它是如何使用isupper()和islower()字符串方法的。
用isupper()确保大小写
simpleSubCipher.py程序使用isupper()和islower()字符串方法来帮助确保明文的大小写在密文中得到反映。
if symbol.isupper():translated += charsB[symIndex].upper()else:translated += charsB[symIndex].lower()
第 59 行测试symbol是否有大写字母。如果是,第 60 行将字符的大写版本从charsB[symIndex]连接到translated。这导致大写版本的key字符对应于大写输入。如果symbol有一个小写字母,第 62 行将字符的小写版本从charsB[symIndex]连接到translated。
如果symbol不是符号集中的一个字符,比如'5'或'?',第 59 行将返回False,第 62 行将代替第 60 行执行。原因是不满足isupper()的条件,因为那些字符串没有至少一个大写字母。在这种情况下,第 62 行的lower()方法调用对字符串没有影响,因为它根本没有字母。lower()方法不会改变像'5'和'?'这样的非字母字符。它只是返回原始的非字母字符。
else块中的第 62 行说明了symbol字符串中的任何小写字符和非字母字符。
第 63 行的缩进表示第 56 行的else语句与if symbol.upper() in charsA:语句成对出现,所以如果symbol不在LETTERS中,第 63 行执行。
else:# Symbol is not in LETTERS; just add it:translated += symbol
如果symbol不在LETTERS中,则执行第 65 行。这意味着我们不能加密或解密symbol中的字符,所以我们简单地将它连接到translated的末尾。
在translateMessage()函数的末尾,第 67 行返回translated变量中的值,该值包含加密或解密的消息:
return translated
接下来,我们将看看如何使用getRandomKey()函数为简单的替换密码生成一个有效的密钥。
生成随机密钥
键入包含字母表中每个字母的密钥的字符串可能很困难。为了帮助我们做到这一点,getRandomKey()函数返回一个有效的密钥来使用。第 71 到 73 行随机打乱了LETTERS常量中的字符。
def getRandomKey():key = list(LETTERS)random.shuffle(key)return ''.join(key)
注
阅读第 123 页上的随机打乱一个字符串,了解如何使用
list()、random.shuffle()和join()方法打乱一个字符串。
要使用getRandomKey()函数,我们需要将第 11 行从myKey = 'LFWOAYUISVKMNXPBDCRJTQEGHZ'改为:
myKey = getRandomKey()
因为我们的简单替换密码程序中的第 20 行打印了正在使用的密钥,所以您将能够看到函数getRandomKey()返回的密钥。
调用main()函数
如果simpleSubCipher.py作为一个程序运行,而不是作为一个模块被另一个程序导入,程序结尾的第 76 和 77 行调用main()。
if __name__ == '__main__':main()
我们对简单替换密码程序的研究到此结束。
总结
在这一章中,你学习了如何使用sort()列表方法对列表中的条目进行排序,以及如何比较两个有序列表来检查字符串中的重复字符或缺失字符。您还了解了isupper()和islower()字符串方法,它们检查字符串值是由大写字母还是小写字母组成的。您了解了包装函数,包装函数是调用其他函数的函数,通常只添加微小的变化或不同的参数。
简单的替换密码有太多可能的密钥,无法强行破解。这使得它不受你用来破解以前的密码程序的技术的影响。你必须编写更聪明的程序来破解这个密码。
在第 17 章中,你将学习如何破解简单的替换密码。您将使用更加智能和复杂的算法,而不是暴力破解所有的密钥。
练习题
练习题的答案可以在本书的网站www.nostarch.com/crackingcodes找到。
-
为什么不能用暴力攻击来对付简单的替换密码,即使是用强大的超级计算机?
-
运行这段代码后
spam变量包含什么?spam = [4, 6, 2, 8]spam.sort() -
什么是包装函数?
-
'hello'.islower()求值为什么? -
'HELLO 123'.isupper()求值为什么? -
'123'.islower()求值为什么?
十七、破解简单替换密码
原文:https://inventwithpython.com/cracking/chapter17.html
“加密本质上是一种私人行为。事实上,加密的行为将信息从公共领域移除。即使是针对加密技术的法律,也只能延伸到一个国家的边境和暴力地区。”
——埃里克·休斯,《一个赛博朋克的宣言》(1993)

在第 16 章中,你了解到简单的替换密码不可能用暴力破解,因为它有太多可能的密钥。要破解简单的替换密码,我们需要创建一个更复杂的程序,使用字典值来映射密文的潜在解密字母。在这一章中,我们将编写这样一个程序来将潜在的解密输出列表缩小到正确的一个。
本章涵盖的主题
-
单词模式、候选单词、潜在的解密字母和密码字母映射
-
正则表达式
-
sub()正则表达式方法
使用单词模式解密
在暴力攻击中,我们尝试每一个可能的密钥来检查它是否能解密密文。如果密钥是正确的,解密结果是可读的英语。但是,通过首先分析密文,我们可以减少可能尝试的密钥数量,甚至可以找到完整或部分密钥。
让我们假设原始明文主要由英语字典文件中的单词组成,就像我们在第 11 章中使用的那样。虽然密文不会由真正的英语单词组成,但它仍然包含由空格分隔的字母组,就像普通句子中的单词一样。在本书中,我们将这些称为密码。在替换密码中,字母表中的每个字母都有一个唯一的对应加密字母。我们将密文中的字母称为密文。因为每个明文字母只能加密成一个密码字母,并且我们在这个版本的密码中没有加密空格,所以明文和密文将共享相同的单词模式。
例如,如果我们有明文MISSISSIPPI SPILL,对应的密文可能是RJBBJBBJXXJ BXJHH。明文的第一个字和第一个密码中的字母数是相同的。对于第二明文字和第二密码字也是如此。明文和密文共享相同的字母和空格模式。还要注意,明文中重复的字母与密文重复的次数和位置相同。
因此,我们可以假设一个密码对应于英语字典文件中的一个单词,并且它们的单词模式匹配。然后,如果我们能在字典中找到该密码解密到哪个单词,我们就能算出该单词中每个密码字母的解密。如果我们用这种技术破解出足够多的密码,我们就能解密整个信息。
寻找单词模式
让我们检查一下密码HGHHU的单词模式。您可以看到,密码具有某些特征,这些特征是原始明文必须具有的。这两个词必须有以下共同点。
-
它们应该有五个字母长。
-
第一、第三和第四个字母应该相同。
-
它们应该正好有三个不同的字母;第一、第二和第五个字母应该都不同。
让我们想想英语中符合这种模式的单词。Puppy就是这样一个单词,它有五个字母长(P,U,P,P,Y),使用三个不同的字母(P,U,Y)以相同的模式排列(P代表第一、第三和第四个字母;U代表第二个字母;Y代表第五个字母)。Mommy、Bobby、lulls、nanny也符合这种模式。这些单词,以及英语字典文件中匹配该标准的任何其他单词,都是HGHHU的可能解密。
为了用程序可以理解的方式表示一个单词模式,我们将把每个模式分成一组数字,用句点分隔,表示字母的模式。
创建单词模式很容易:第一个字母得到数字 0,此后每个不同字母的第一次出现得到下一个数字。比如Cat的单词模式是0.1.2,Category的单词模式是0.1.2.3.4.5.4.0.2.6.4.7.8。
在简单的替换密码中,无论使用哪个密钥加密,明文字和它的密码字总是具有相同的字模式。密文HGHHU的字模式是0.1.0.0.2,这意味着对应于HGHHU的明文的字模式也是0.1.0.0.2。
寻找潜在解密字母
要解密HGHHU,我们需要在一个英文字典文件中找到所有单词,这个文件的单词模式也是0.1.0.0.2。在本书中,我们将与密码具有相同单词模式的明文单词称为该密码的候选单词。以下是HGHHU的候选名单:
-
PUPPY -
MOMMY -
BOBBY -
LULLS -
NANNY
使用单词模式,我们可以猜测密文可能解密成哪些明文字母,我们称之为密文的潜在解密字母。要破解用简单替换密码加密的消息,我们需要找到消息中每个单词的所有潜在解密字母,并通过排除过程确定实际的解密字母。表 17-1 列出了HGHHU的潜在解密字母。
表 17-1:HGHHU中密文的潜在解密字母
| 密码字母 | H | G | H | H | U |
|---|---|---|---|---|---|
| 潜在解密字母 | P | U | P | P | Y |
M | O | M | M | Y | |
B | O | B | B | Y | |
L | U | L | L | S | |
N | A | N | N | Y |
以下是使用表 17-1 创建的密码字母映射:
-
H有潜在的解密字母P,M,B,L和N。 -
G有潜在的解密字母U,O和A。 -
U有潜在的解密字母Y和S。 -
在这个例子中,除了
H、G和U之外的所有其他密码字母都没有潜在的解密字母。
密码字母映射显示字母表中的所有字母及其潜在的解密字母。当我们开始收集加密消息时,我们将为字母表中的每个字母找到潜在的解密字母,但是因为只有密码字母H、G和U是我们示例密文的一部分,所以我们没有其他密码字母的潜在解密字母。
还要注意,U只有两个潜在的解密字母(Y和S),因为候选字母之间有重叠,其中许多以字母Y结尾。重叠越多,潜在的解密字母就越少,就越容易找出该密码字母解密成什么。
为了用 Python 代码表示表 17-1 ,我们将使用一个字典值来表示密码字母映射,如下所示('H'、'G'和'U'的键值对以粗体显示):
{'A': [], 'B': [], 'C': [], 'D': [], 'E': [], 'F': [], 'G': ['U', 'O', 'A'],
'H': ['P', 'M', 'B', 'L', 'N'], 'I': [], 'J': [], 'K': [], 'L': [], 'M': [],
'N': [], 'O': [], 'P': [], 'Q': [], 'R': [], 'S': [], 'T': [], 'U': ['Y',
'S'], 'V': [], 'W': [], 'X': [], 'Y': [], 'Z': []}
该字典有 26 个键值对,字母表中的每个字母有一个键,每个字母有一个潜在的解密字母列表。它显示了键'H'、'G'和'的潜在解密字母。对于值,其他键有空列表[],因为到目前为止它们没有潜在的解密字母。
如果我们可以通过交叉引用其他加密单词的密码字母映射,将密码字母的潜在解密字母的数量减少到只有一个字母,我们就可以找到该密码字母解密成什么。即使我们不能解决所有的 26 个密码,我们也可以破解大部分的密码映射来解密大部分的密文。
既然我们已经讲述了本章将要用到的一些基本概念和术语,让我们来看看破解过程中的步骤。
破解过程概述
使用单词模式破解简单的替换密码非常容易。我们可以将破解过程的主要步骤总结如下:
-
找出密文中每个密码的单词模式。
-
找出每个密码可以解密成的候选英文单词。
-
创建一个字典,显示每个密码的潜在解密字母,作为每个密码的密码映射。
-
将密码字母映射组合成一个映射,我们称之为相交映射。
-
从组合映射中移除任何已求解的密码字母。
-
用解出的密文解密密文。
密文中的密码越多,映射相互重叠的可能性就越大,每个密码的潜在解密字母就越少。这意味着在简单的替换密码中,密文信息越长,就越容易破解。
在深入研究源代码之前,让我们看看如何使破解过程的前两步变得更容易。我们将使用我们在第 11 章中使用的字典文件和一个名为wordPatterns.py的模块来获取字典文件中每个单词的单词模式,并在列表中对它们进行排序。
makewodpatterns模块
要计算dictionary.txt字典文件中每个单词的单词模式,从www.nostarch.com/crackingcodes下载makewodpatterns.py。确保这个程序和dictionary.txt都在保存本章的simpleSubHacker.py程序的文件夹中。
makewodpatterns.py程序有一个getWordPattern()函数,它接受一个字符串(比如'puppy')并返回它的单词模式(比如'0.1.0.0.2')。当您运行makeWordPatterns.py时,它应该会创建 Python 模块wordPatterns.py。该模块包含一个变量赋值语句,如下所示,长度超过 43,000 行:
allPatterns = {'0.0.1': ['EEL'],'0.0.1.2': ['EELS', 'OOZE'],'0.0.1.2.0': ['EERIE'],'0.0.1.2.3': ['AARON', 'LLOYD', 'OOZED'],
--snip--
allPatterns变量包含一个字典值,将单词模式字符串作为关键字,将与该模式匹配的英语单词列表作为其值。例如,要查找模式为0.1.2.1.3.4.5.4.6.7.8的所有英语单词,请在交互式 shell 中输入以下内容:
>>> import wordPatterns
>>> wordPatterns.allPatterns['0.1.2.1.3.4.5.4.6.7.8']
['BENEFICIARY', 'HOMOGENEITY', 'MOTORCYCLES']
在allPatterns字典中,键'0.1.2.1.3.4.5.4.6.7.8'具有列表值['BENEFICIARY', 'HOMOGENEITY', 'MOTORCYCLES'],它包含三个具有这种特殊单词模式的英语单词。
现在让我们导入wordPatterns.py模块,开始构建简单的替换破解程序!
注
如果在交互 shell 中导入
wordPatterns时得到一条ModuleNotFoundError错误消息,请先在交互 shell 中输入以下内容:
>>> import sys
>>> sys.path.append('name_of_folder')
将文件夹名称替换为wordPatterns.py保存的位置。这告诉交互式 shell 在您指定的文件夹中查找模块。
简单替换破解程序的源代码
选择文件 -> 新建文件,打开文件编辑器窗口。在文件编辑器中输入以下代码,保存为simpleSubHacker.py。确保将pyperclip.py、simpleSubCipher.py和wordPatterns.py文件放在与simpleSubHacker.py相同的目录下。按F5运行程序。
单纯子
黑客. py
# Simple Substitution Cipher Hacker
# https://www.nostarch.com/crackingcodes/ (BSD Licensed)import os, re, copy, pyperclip, simpleSubCipher, wordPatterns,makeWordPatternsLETTERS = 'ABCDEFGHIJKLMNOPQRSTUVWXYZ'
nonLettersOrSpacePattern = re.compile('[^A-Z\s]')def main():message = 'Sy l nlx sr pyyacao l ylwj eiswi upar lulsxrj isrsxrjsxwjr, ia esmm rwctjsxsza sj wmpramh, lxo txmarr jia aqsoaxwasr pqaceiamnsxu, ia esmm caytra jp famsaqa sj. Sy, px jia pjiacilxo, ia sr pyyacao rpnajisxu eiswi lyypcor l calrpx ypc lwjsxu sxlwwpcolxwa jp isr sxrjsxwjr, ia esmm lwwabj sj aqax px jiarmsuijarj aqsoaxwa. Jia pcsusx py nhjir sr agbmlsxao sx jisr elh.-Facjclxo Ctrramm'# Determine the possible valid ciphertext translations:print('Hacking...')letterMapping = hackSimpleSub(message)# Display the results to the user:print('Mapping:')print(letterMapping)print()print('Original ciphertext:')print(message)print()print('Copying hacked message to clipboard:')hackedMessage = decryptWithCipherletterMapping(message, letterMapping)pyperclip.copy(hackedMessage)print(hackedMessage)def getBlankCipherletterMapping():# Returns a dictionary value that is a blank cipherletter mapping:return {'A': [], 'B': [], 'C': [], 'D': [], 'E': [], 'F': [], 'G': [],'H': [], 'I': [], 'J': [], 'K': [], 'L': [], 'M': [], 'N': [],'O': [], 'P': [], 'Q': [], 'R': [], 'S': [], 'T': [], 'U': [],'V': [], 'W': [], 'X': [], 'Y': [], 'Z': []}def addLettersToMapping(letterMapping, cipherword, candidate):# The letterMapping parameter takes a dictionary value that# stores a cipherletter mapping, which is copied by the function.# The cipherword parameter is a string value of the ciphertext word.# The candidate parameter is a possible English word that the# cipherword could decrypt to.# This function adds the letters in the candidate as potential# decryption letters for the cipherletters in the cipherletter# mapping.for i in range(len(cipherword)):if candidate[i] not in letterMapping[cipherword[i]]:letterMapping[cipherword[i]].append(candidate[i])def intersectMappings(mapA, mapB):# To intersect two maps, create a blank map and then add only the# potential decryption letters if they exist in BOTH maps:intersectedMapping = getBlankCipherletterMapping()for letter in LETTERS:# An empty list means "any letter is possible". In this case just# copy the other map entirely:if mapA[letter] == []:intersectedMapping[letter] = copy.deepcopy(mapB[letter])elif mapB[letter] == []:intersectedMapping[letter] = copy.deepcopy(mapA[letter])else:# If a letter in mapA[letter] exists in mapB[letter],# add that letter to intersectedMapping[letter]:for mappedLetter in mapA[letter]:if mappedLetter in mapB[letter]:intersectedMapping[letter].append(mappedLetter)return intersectedMappingdef removeSolvedLettersFromMapping(letterMapping):# Cipherletters in the mapping that map to only one letter are# "solved" and can be removed from the other letters.# For example, if 'A' maps to potential letters ['M', 'N'], and 'B'# maps to ['N'], then we know that 'B' must map to 'N', so we can# remove 'N' from the list of what 'A' could map to. So 'A' then maps# to ['M']. Note that now that 'A' maps to only one letter, we can# remove 'M' from the list of letters for every other letter.# (This is why there is a loop that keeps reducing the map.)loopAgain = Truewhile loopAgain:# First assume that we will not loop again:loopAgain = False# solvedLetters will be a list of uppercase letters that have one# and only one possible mapping in letterMapping:solvedLetters = []for cipherletter in LETTERS:if len(letterMapping[cipherletter]) == 1:solvedLetters.append(letterMapping[cipherletter][0])# If a letter is solved, then it cannot possibly be a potential# decryption letter for a different ciphertext letter, so we# should remove it from those other lists:for cipherletter in LETTERS:for s in solvedLetters:if len(letterMapping[cipherletter]) != 1 and s inletterMapping[cipherletter]:letterMapping[cipherletter].remove(s)if len(letterMapping[cipherletter]) == 1:# A new letter is now solved, so loop again:loopAgain = Truereturn letterMappingdef hackSimpleSub(message):intersectedMap = getBlankCipherletterMapping()cipherwordList = nonLettersOrSpacePattern.sub('',message.upper()).split()for cipherword in cipherwordList:# Get a new cipherletter mapping for each ciphertext word:candidateMap = getBlankCipherletterMapping()wordPattern = makeWordPatterns.getWordPattern(cipherword)if wordPattern not in wordPatterns.allPatterns:continue # This word was not in our dictionary, so continue.# Add the letters of each candidate to the mapping:for candidate in wordPatterns.allPatterns[wordPattern]:addLettersToMapping(candidateMap, cipherword, candidate)# Intersect the new mapping with the existing intersected mapping:intersectedMap = intersectMappings(intersectedMap, candidateMap)# Remove any solved letters from the other lists:return removeSolvedLettersFromMapping(intersectedMap)def decryptWithCipherletterMapping(ciphertext, letterMapping):# Return a string of the ciphertext decrypted with the letter mapping,# with any ambiguous decrypted letters replaced with an underscore.# First create a simple sub key from the letterMapping mapping:key = ['x'] * len(LETTERS)for cipherletter in LETTERS:if len(letterMapping[cipherletter]) == 1:# If there's only one letter, add it to the key:keyIndex = LETTERS.find(letterMapping[cipherletter][0])key[keyIndex] = cipherletterelse:ciphertext = ciphertext.replace(cipherletter.lower(), '_')ciphertext = ciphertext.replace(cipherletter.upper(), '_')key = ''.join(key)# With the key we've created, decrypt the ciphertext:return simpleSubCipher.decryptMessage(key, ciphertext)if __name__ == '__main__':main()
简单替换破解程序的运行示例
当你运行这个程序时,它试图破解message变量中的密文。它的输出应该如下所示:
Hacking...
Mapping:
{'A': ['E'], 'B': ['Y', 'P', 'B'], 'C': ['R'], 'D': [], 'E': ['W'], 'F':
['B', 'P'], 'G': ['B', 'Q', 'X', 'P', 'Y'], 'H': ['P', 'Y', 'K', 'X', 'B'],
'I': ['H'], 'J': ['T'], 'K': [], 'L': ['A'], 'M': ['L'], 'N': ['M'], 'O':
['D'], 'P': ['O'], 'Q': ['V'], 'R': ['S'], 'S': ['I'], 'T': ['U'], 'U': ['G'],
'V': [], 'W': ['C'], 'X': ['N'], 'Y': ['F'], 'Z': ['Z']}Original ciphertext:
Sy l nlx sr pyyacao l ylwj eiswi upar lulsxrj isr sxrjsxwjr, ia esmm
rwctjsxsza sj wmpramh, lxo txmarr jia aqsoaxwa sr pqaceiamnsxu, ia esmm caytra
jp famsaqa sj. Sy, px jia pjiac ilxo, ia sr pyyacao rpnajisxu eiswi lyypcor
l calrpx ypc lwjsxu sx lwwpcolxwa jp isr sxrjsxwjr, ia esmm lwwabj sj aqax
px jia rmsuijarj aqsoaxwa. Jia pcsusx py nhjir sr agbmlsxao sx jisr elh.
-Facjclxo CtrrammCopying hacked message to clipboard:
If a man is offered a fact which goes against his instincts, he will
scrutinize it closel_, and unless the evidence is overwhelming, he will refuse
to _elieve it. If, on the other hand, he is offered something which affords
a reason for acting in accordance to his instincts, he will acce_t it even
on the slightest evidence. The origin of m_ths is e__lained in this wa_.
-_ertrand Russell
现在我们来详细探究一下源代码。
设置模块和常量
让我们看看简单替换破解程序的前几行。第 4 行导入了 7 个不同的模块,比迄今为止任何其他程序都多。第 10 行的全局变量LETTERS存储符号集,它由字母表中的大写字母组成。
# Simple Substitution Cipher Hacker
# https://www.nostarch.com/crackingcodes/ (BSD Licensed)import os, re, copy, pyperclip, simpleSubCipher, wordPatterns,makeWordPatterns--snip--
LETTERS = 'ABCDEFGHIJKLMNOPQRSTUVWXYZ'
re模块是正则表达式模块,它允许使用正则表达式进行复杂的字符串操作。让我们看看正则表达式是如何工作的。
用正则表达式查找字符
正则表达式是定义匹配特定字符串的特定模式的字符串。例如,第 11 行的字符串'[^A-Z\s]'是一个正则表达式,它告诉 Python 查找不是从A到Z的大写字母或空白字符的任何字符(比如空格、制表符或换行符)。
nonLettersOrSpacePattern = re.compile('[^A-Z\s]')
re.compile()函数创建一个re模块可以使用的正则表达式模式对象(缩写为 正则表达式对象或模式对象)。我们将使用这个对象从第 241 页的的hackSimpleSub()函数中删除任何非字母字符。
您可以使用正则表达式执行许多复杂的字符串操作。要了解更多关于正则表达式的信息,请转到www.nostarch.com/crackingcodes。
设置main()函数
与本书中之前的破解程序一样,main()函数将密文存储在message变量中,第 18 行将该变量传递给hackSimpleSub()函数:
def main():message = 'Sy l nlx sr pyyacao l ylwj eiswi upar lulsxrj isrsxrjsxwjr, ia esmm rwctjsxsza sj wmpramh, lxo txmarr jia aqsoaxwasr pqaceiamnsxu, ia esmm caytra jp famsaqa sj. Sy, px jia pjiacilxo, ia sr pyyacao rpnajisxu eiswi lyypcor l calrpx ypc lwjsxu sxlwwpcolxwa jp isr sxrjsxwjr, ia esmm lwwabj sj aqax px jiarmsuijarj aqsoaxwa. Jia pcsusx py nhjir sr agbmlsxao sx jisr elh.-Facjclxo Ctrramm'# Determine the possible valid ciphertext translations:print('Hacking...')letterMapping = hackSimpleSub(message)
hackSimpleSub()不是返回解密的消息或None(如果无法解密的话),而是返回一个删除了解密字母的相交密码字母映射。(我们将在第 234 页的上的相交两个映射中查看如何创建相交映射。)这个相交的密文映射然后被传递给decryptWithCipherletterMapping()以将存储在message中的密文解密成可读格式,你将在第 243 页的中的“解密消息中看到更多细节。
存储在letterMapping中的密码字母映射是一个字典值,它有 26 个大写的单字母字符串作为代表密码字母的关键字。它还列出了每个密码字母的潜在解密字母的大写字母,作为字典的值。当每个密码字母只有一个与之相关的潜在解密字母时,我们就有了一个完全解决的映射,并且可以使用相同的密码和密钥解密任何密文。
生成的每个密文映射取决于所使用的密文。在某些情况下,我们将只有部分解决的映射,其中一些密码没有潜在的解密,而其他密码有多个潜在的解密。不包含字母表中每个字母的较短密文更有可能导致不完整的映射。
向用户显示破解结果
然后程序调用print()函数在屏幕上显示letterMapping、原始消息和解密后的消息:
# Display the results to the user:print('Mapping:')print(letterMapping)print()print('Original ciphertext:')print(message)print()print('Copying hacked message to clipboard:')hackedMessage = decryptWithCipherletterMapping(message, letterMapping)pyperclip.copy(hackedMessage)print(hackedMessage)
第 28 行将解密后的消息存储在变量hackedMessage中,该变量被复制到剪贴板并打印到屏幕上,以便用户可以将其与原始消息进行比较。我们使用decryptWithCipherletterMapping()来查找解密的消息,这将在程序的后面定义。
接下来,让我们看看创建密码字母映射的所有函数。
创建密码字母映射
程序需要为密文中的每个密码词建立一个密码映射。为了创建一个完整的映射,我们需要几个助手函数。其中一个帮助函数将建立一个新的密码映射,这样我们就可以为每个密码调用它。
另一个函数将采用一个密码字、其当前字母映射和一个候选解密字来查找所有候选解密字。我们将为每个密码和每个候选字调用这个函数。然后,该函数将候选单词中的所有潜在解密字母添加到密码单词的字母映射中,并返回字母映射。
当我们从密文中得到几个单词的字母映射时,我们将使用一个函数将它们合并在一起。然后,我们将使用最后一个辅助函数,通过将一个解密字母与每个密码字母匹配来解决尽可能多的密码字母的解密。如上所述,我们不可能总是能够解开所有的密码,但是你会在第 243 页的的“解密信息中找到如何解决这个问题。
创建空白映射
首先,我们需要创建一个空白的密码字母映射。
def getBlankCipherletterMapping():# Returns a dictionary value that is a blank cipherletter mapping:return {'A': [], 'B': [], 'C': [], 'D': [], 'E': [], 'F': [], 'G': [],'H': [], 'I': [], 'J': [], 'K': [], 'L': [], 'M': [], 'N': [],'O': [], 'P': [], 'Q': [], 'R': [], 'S': [], 'T': [], 'U': [],'V': [], 'W': [], 'X': [], 'Y': [], 'Z': []}
当被调用时,getBlankCipherletterMapping()函数返回一个字典,其中的键被设置为字母表中 26 个字母的一个字符串。
给映射添加字母
为了给映射添加字母,我们在第 38 行定义了addLettersToMapping()函数。
def addLettersToMapping(letterMapping, cipherword, candidate):
这个函数有三个参数:一个密码映射(letterMapping)、一个要映射的密码(cipherword)和一个密码可以解密成的候选解密字(candidate)。该函数将candidate中的每个字母映射到cipherword中相应索引位置的密码字母,如果该字母不存在,则将该字母添加到letterMapping。
例如,如果'PUPPY'是cipherword 'HGHHU'的candidate,那么addLettersToMapping()函数会将值'P'加到letterMapping中的键'H'上。然后,该函数移动到下一个字母,并将'U'附加到与键'G'成对的列表值,依此类推。
如果该字母已经在潜在解密字母列表中,那么addLettersToMapping ()不会将该字母再次添加到列表中。例如,在'PUPPY'中,对于接下来的两个'P'实例,它会跳过将'P'添加到'H'键,因为它已经在那里了。最后,该函数更改了密钥'U'的值,因此在它的潜在解密字母列表中有'Y'。
addLettersToMapping()中的代码假设len(cipherword)与len(candidate)相同,因为我们应该只传递一个具有匹配单词模式的cipherword和candidate对。
然后,程序遍历cipherword中字符串的每个索引,检查一个字母是否已经被添加到潜在解密字母列表中:
for i in range(len(cipherword)):if candidate[i] not in letterMapping[cipherword[i]]:letterMapping[cipherword[i]].append(candidate[i])
我们将使用变量i通过索引遍历cipherword的每个字母及其在candidate中对应的潜在解密字母。我们可以这样做,因为要添加的潜在解密字母是密码字母cipherword[i]的candidate[i]。例如,如果cipherword是'HGHHU'而candidate是'PUPPY',那么i将从索引0开始,我们将使用cipherword[0]和candidate[0]来访问每个字符串中的第一个字母。那么执行将移动到第 51 行的if语句。
if语句检查潜在解密字母candidate[i]是否已经在密码字母的潜在解密字母列表中,如果已经在列表中,则不添加它。它通过使用letterMapping[cipherword[i]]访问映射中的密码字母来做到这一点,因为cipherword[i]是需要访问的letterMapping中的密钥。该检查可防止潜在解密字母列表中出现重复字母。
例如,'PUPPY'中的第一个'P'可能在循环的第一次迭代中被添加到letterMapping中,但是当i在第三次迭代中等于2时,来自candidate[2]的'P'不会被添加到映射中,因为它已经在第一次迭代中被添加了。
如果潜在的解密字母已经不在映射中,第 52 行将新字母candidate[i]添加到letterMapping[cipherword[i]]处的密码字母映射中的潜在解密字母列表中。
回想一下,因为 Python 传递了一个对为参数传递的字典的引用的副本,而不是字典本身的副本,所以在这个函数中对letterMapping的任何更改也将在addLettersToMapping()函数之外完成。这是因为引用的两个副本仍然引用第 126 行的addLettersToMapping()调用中为letterMapping参数传递的同一个字典。
遍历完cipherword中的所有索引后,该函数将字母添加到letterMapping变量的映射中。现在让我们看看程序如何将这个映射与其他密码的映射进行比较,以检查重叠。
两个映射的交集
hackSimpleSub()函数使用intersectMappings()函数将两个密码字母映射作为其mapA和mapB参数传递,并返回一个mapA和mapB的合并映射。intersectMappings()函数指示程序组合mapA和mapB,创建一个空白映射,然后将潜在的解密字母添加到空白映射中,前提是它们同时存在于映射中,以防止重复。
def intersectMappings(mapA, mapB):# To intersect two maps, create a blank map and then add only the# potential decryption letters if they exist in BOTH maps:intersectedMapping = getBlankCipherletterMapping()
首先,第 59 行创建了一个密码映射,通过调用getBlankCipherletterMapping()并将返回值存储在intersectedMapping变量中来存储合并后的映射。
第 60 行的for循环遍历LETTERS常量变量中的大写字母,并使用letter变量作为mapA和mapB字典的关键字:
for letter in LETTERS:# An empty list means "any letter is possible". In this case just# copy the other map entirely:if mapA[letter] == []:intersectedMapping[letter] = copy.deepcopy(mapB[letter])elif mapB[letter] == []:intersectedMapping[letter] = copy.deepcopy(mapA[letter])
第 64 行检查mapA的潜在解密字母列表是否为空。一个空白列表意味着这个密码可能会解密成任何字母。在这种情况下,相交密码字母映射只是复制了other映射的潜在解密字母列表。例如,如果mapA中潜在解密字母的列表为空,那么第 65 行将相交映射的列表设置为mapB中列表的副本,反之亦然。注意,如果两个映射的列表都是空的,第 64 行的条件仍然是True,然后第 65 行简单地将mapB中的空列表复制到相交的映射。
第 68 行的else块处理mapA和mapB都不为空的情况;
else:# If a letter in mapA[letter] exists in mapB[letter],# add that letter to intersectedMapping[letter]:for mappedLetter in mapA[letter]:if mappedLetter in mapB[letter]:intersectedMapping[letter].append(mappedLetter)return intersectedMapping
当映射不为空时,第 71 行在mapA[letter]处遍历列表中的大写字母字符串。第 72 行检查mapA[letter]中的大写字母是否也存在于mapB[letter]中的大写字母字符串列表中。如果是,那么第 73 行的intersectedMapping[letter]将这个普通字母添加到潜在解密字母的列表中。
在从第 60 行开始的for循环结束后,intersectedMapping中的密码字母映射应该只具有存在于mapA和mapB的潜在解密字母列表中的潜在解密字母。第 75 行返回这个完全相交的密码字母映射。接下来,让我们看一个相交映射的示例输出。
字母映射助手函数如何工作
现在我们已经定义了字母映射助手函数,让我们尝试在交互式 shell 中使用它们,以便更好地理解它们是如何协同工作的。让我们为密文'OLQIHXIRCKGNZ PLQRZKBZB MPBKSSIPLC'创建一个相交的密码映射,它只包含三个密码。我们将为每个单词创建一个映射,然后组合这些映射。
将simpleSubHacker.py导入到交互 shell 中:
>>> import simpleSubHacker
接下来,我们调用getBlankCipherletterMapping()来创建一个空白字母映射,并将这个映射存储在一个名为letterMapping1的变量中:
>>> letterMapping1 = simpleSubHacker.getBlankCipherletterMapping()
>>> letterMapping1
{'A': [], 'C': [], 'B': [], 'E': [], 'D': [], 'G': [], 'F': [], 'I': [],
'H': [], 'K': [], 'J': [], 'M': [], 'L': [], 'O': [], 'N': [], 'Q': [],
'P': [], 'S': [], 'R': [], 'U': [], 'T': [], 'W': [], 'V': [], 'Y': [],
'X': [], 'Z': []}
让我们开始破解第一个密码,'OLQIHXIRCKGNZ'。首先,我们需要通过调用makeWordPattern模块的getWordPattern()函数来获取这个密码的单词模式,如下所示:
>>> import makeWordPatterns
>>> makeWordPatterns.getWordPattern('OLQIHXIRCKGNZ')
0.1.2.3.4.5.3.6.7.8.9.10.11
为了找出字典中哪些英语单词具有单词模式0.1.2.3.4.5.3.6.7.8.9.10.11(也就是说,为了找出密码词'OLQIHXIRCKGNZ')的候选词,我们导入wordPatterns模块并查找这个模式:
>>> import wordPatterns
>>> candidates = wordPatterns.allPatterns['0.1.2.3.4.5.3.6.7.8.9.10.11']
>>> candidates
['UNCOMFORTABLE', 'UNCOMFORTABLY']
两个英文单词匹配'OLQIHXIRCKGNZ'的单词模式;因此,第一个密码可以解密的唯一两个字是'UNCOMFORTABLE'和'UNCOMFORTABLY'。这些单词是我们的候选词,所以我们将它们作为列表存储在candidates变量中(不要与addLettersToMapping()函数中的candidate参数混淆)。
接下来,我们需要使用addLettersToMapping()将他们的字母映射到cipherword的字母。首先,我们将通过访问candidates列表的第一个成员来映射'UNCOMFORTABLE',如下所示:
>>> letterMapping1 = simpleSubHacker.addLettersToMapping(letterMapping1,
'OLQIHXIRCKGNZ', candidates[0])
>>> letterMapping1
{'A': [], 'C': ['T'], 'B': [], 'E': [], 'D': [], 'G': ['B'], 'F': [], 'I':
['O'], 'H': ['M'], 'K': ['A'], 'J': [], 'M': [], 'L': ['N'], 'O': ['U'], 'N':
['L'], 'Q': ['C'], 'P': [], 'S': [], 'R': ['R'], 'U': [], 'T': [], 'W': [],
'V': [], 'Y': [], 'X': ['F'], 'Z': ['E']}
从letterMapping1值可以看到,'OLQIHXIRCKGNZ'中的字母映射到'UNCOMFORTABLE'中的字母:'O'映射到['U'],'L'映射到['N'],'Q'映射到['C'],以此类推。
但是因为'OLQIHXIRCKGNZ'中的字母也可能解密成' UNCOMFORTABLY',我们也需要将其添加到密码字母映射中。在交互式 shell 中输入以下内容:
>>> letterMapping1 = simpleSubHacker.addLettersToMapping(letterMapping1,
'OLQIHXIRCKGNZ', candidates[1])
>>> letterMapping1
{'A': [], 'C': ['T'], 'B': [], 'E': [], 'D': [], 'G': ['B'], 'F': [],
'I': ['O'], 'H': ['M'], 'K': ['A'], 'J': [], 'M': [], 'L': ['N'], 'O': ['U'],
'N': ['L'], 'Q': ['C'], 'P': [], 'S': [], 'R': ['R'], 'U': [], 'T': [],
'W': [], 'V': [], 'Y': [], 'X': ['F'], 'Z': ['E', 'Y']}
请注意,letterMapping1中没有太多变化,除了letterMapping1中的密码字母映射现在除了'E'之外还有'Z'到'Y'的映射。这是因为只有当字母不在列表中时,addLettersToMapping()才会将该字母添加到列表中。
现在我们有了三个密码字中第一个的密码字母映射。我们需要为第二个密码词'PLQRZKBZB获取一个新的映射,并重复这个过程:
>>> letterMapping2 = simpleSubHacker.getBlankCipherletterMapping()
>>> wordPat = makeWordPatterns.getWordPattern('PLQRZKBZB')
>>> candidates = wordPatterns.allPatterns[wordPat]
>>> candidates
['CONVERSES', 'INCREASES', 'PORTENDED', 'UNIVERSES']
>>> for candidate in candidates:
... letterMapping2 = simpleSubHacker.addLettersToMapping(letterMapping2,
'PLQRZKBZB', candidate)
...
>>> letterMapping2
{'A': [], 'C': [], 'B': ['S', 'D'], 'E': [], 'D': [], 'G': [], 'F': [], 'I':
[], 'H': [], 'K': ['R', 'A', 'N'], 'J': [], 'M': [], 'L': ['O', 'N'], 'O': [],
'N': [], 'Q': ['N', 'C', 'R', 'I'], 'P': ['C', 'I', 'P', 'U'], 'S': [], 'R':
['V', 'R', 'T'], 'U': [], 'T': [], 'W': [], 'V': [], 'Y': [], 'X': [], 'Z':
['E']}
我们可以编写一个for循环,遍历candidates中的列表,并对每一个单词调用addLettersToMapping(),而不是为这四个候选单词中的每一个单词输入四个对addLettersToMapping()的调用。这完成了第二个密码的密码字母映射。
接下来,我们需要通过将密码字母映射传递给intersectMappings()来获得它们在letterMapping1和letterMapping2中的交集。在交互式 shell 中输入以下内容:
>>> intersectedMapping = simpleSubHacker.intersectMappings(letterMapping1,
letterMapping2)
>>> intersectedMapping
{'A': [], 'C': ['T'], 'B': ['S', 'D'], 'E': [], 'D': [], 'G': ['B'], 'F': [],
'I': ['O'], 'H': ['M'], 'K': ['A'], 'J': [], 'M': [], 'L': ['N'], 'O': ['U'],
'N': ['L'], 'Q': ['C'], 'P': ['C', 'I', 'P', 'U'], 'S': [], 'R': ['R'],
'U': [], 'T': [], 'W': [], 'V': [], 'Y': [], 'X': ['F'], 'Z': ['E']}
现在,相交映射中任何密码的潜在解密字母的列表应该仅仅是在letterMapping1和letterMapping2中的潜在解密字母。
例如,'Z'键在intersectedMapping中的列表只是['E'],因为letterMapping1有['E', 'Y'],而letterMapping2只有['E']。
接下来,我们对第三个密码字'MPBKSSIPLC'重复上述所有步骤,如下所示:
>>> letterMapping3 = simpleSubHacker.getBlankCipherletterMapping()
>>> wordPat = makeWordPatterns.getWordPattern('MPBKSSIPLC')
>>> candidates = wordPatterns.allPatterns[wordPat]
>>> for i in range(len(candidates)):
... letterMapping3 = simpleSubHacker.addLettersToMapping(letterMapping3,
'MPBKSSIPLC', candidates[i])
...
>>> letterMapping3
{'A': [], 'C': ['Y', 'T'], 'B': ['M', 'S'], 'E': [], 'D': [], 'G': [],
'F': [], 'I': ['E', 'O'], 'H': [], 'K': ['I', 'A'], 'J': [], 'M': ['A', 'D'],
'L': ['L', 'N'], 'O': [], 'N': [], 'Q': [], 'P': ['D', 'I'], 'S': ['T', 'P'],
'R': [], 'U': [], 'T': [], 'W': [], 'V': [], 'Y': [], 'X': [], 'Z': []}
在交互 shell 中输入以下内容使letterMapping3与intersectedMapping相交,这是letterMapping1与letterMapping2的相交映射:
>>> intersectedMapping = simpleSubHacker.intersectMappings(intersectedMapping,
letterMapping3)
>>> intersectedMapping
{'A': [], 'C': ['T'], 'B': ['S'], 'E': [], 'D': [], 'G': ['B'], 'F': [],
'I': ['O'], 'H': ['M'], 'K': ['A'], 'J': [], 'M': ['A', 'D'], 'L': ['N'],
'O': ['U'], 'N': ['L'], 'Q': ['C'], 'P': ['I'], 'S': ['T', 'P'], 'R': ['R'],
'U': [], 'T': [], 'W': [], 'V': [], 'Y': [], 'X': ['F'], 'Z': ['E']}
在这个例子中,我们能够找到列表中只有一个值的键的解决方案。比如'K'解密到'A'。但是请注意,密钥'M'可以解密到'A'或'D'。因为我们知道'K'解密到'A',所以可以推导出密钥'M'一定解密到'D',而不是'A'。毕竟,如果被破解的字母被一个密码字母使用,它就不能被另一个密码字母使用,因为简单替换密码将一个明文字母加密成恰好一个密码字母。
让我们看看removeSolvedLettersFromMapping()函数是如何找到这些已求解的字母并将它们从潜在解密字母列表中移除的。我们将需要刚刚创建的intersectedMapping,所以暂时不要关闭空闲窗口。
标识映射中已解决的字母
removeSolvedLettersFromMapping()函数在letterMapping参数中搜索任何只有一个潜在解密字母的密码字母。这些密码被认为是已破解的,这意味着在他们的潜在解密字母列表中,任何其他带有这个已破解字母的密码都不可能解密成这个字母。这可能引起连锁反应,因为当一个潜在的解密字母从仅包含两个字母的其他潜在解密字母列表中删除时,结果可能是一个新的已解密码字母。该程序通过循环并从整个密码字母映射中删除新解决的字母来处理这种情况。
def removeSolvedLettersFromMapping(letterMapping):--snip--loopAgain = Truewhile loopAgain:# First assume that we will not loop again:loopAgain = False
因为为参数letterMapping传递了对字典的引用,所以该字典将包含在函数removeSolvedLettersFromMapping()中所做的更改,即使在函数返回之后。第 88 行创建了loopAgain,这是一个保存布尔值的变量,它决定了代码在找到另一个已解决的字母时是否需要再次循环。
如果第 88 行的loopAgain变量被设置为True,程序执行进入第 89 行的while循环。在循环开始时,第 91 行将loopAgain设置为False。代码假设这是第 89 行的while循环的最后一次迭代。如果程序在这个迭代中找到一个新的解出的密码字母,变量loopAgain仅被设置为True。
代码的下一部分创建一个密码列表,该列表中只有一个潜在的解密字母。这些是将从映射中移除的已求解字母。
# solvedLetters will be a list of uppercase letters that have one# and only one possible mapping in letterMapping:solvedLetters = []for cipherletter in LETTERS:if len(letterMapping[cipherletter]) == 1:solvedLetters.append(letterMapping[cipherletter][0])
第 96 行的for循环遍历所有 26 个可能的密码字母,并查看该密码字母的密码字母映射的潜在解密字母列表(即在letterMapping[cipherletter]的列表)。
第 97 行检查这个列表的长度是否为1。如果是的话,我们知道只有一个字母可以被解密,密码就被破解了。第 98 行将解决的解密字母添加到solvedLetters列表中。被求解的字母总是在letterMapping[cipherletter][0]处,因为letterMapping[cipherletter]是潜在解密字母的列表,在列表的索引0处只有一个字符串值。
在从第 96 行开始的前一个for循环结束后,solvedLetters变量应该包含一个密文的所有解密列表。第 98 行将这些解密后的字符串作为列表存储在solvedLetters中。
至此,程序完成了对所有已解字母的识别。然后检查它们是否被列为其他密码的潜在解密字母,并删除它们。
为此,第 103 行的for循环遍历所有 26 个可能的密码字母,并查看密码字母映射的潜在解密字母列表。
for cipherletter in LETTERS:for s in solvedLetters:if len(letterMapping[cipherletter]) != 1 and s inletterMapping[cipherletter]:letterMapping[cipherletter].remove(s)if len(letterMapping[cipherletter]) == 1:# A new letter is now solved, so loop again:loopAgain = Truereturn letterMapping
对于检查的每个密码字母,行 104 循环通过solvedLetters中的字母,以检查它们中的任何一个是否存在于letterMapping[cipherletter]的潜在解密字母列表中。
第 105 行通过检查len(letterMapping[cipherletter]) != 1,和已解决的字母是否存在于潜在解密字母列表中,来检查潜在解密字母列表是否未被解决。如果两个标准都满足,则该条件返回True,并且第 106 行从潜在解密字母的列表中移除s中已解决的字母。
如果这种移除仅在潜在解密字母列表中留下一个字母,则第 109 行将loopAgain变量设置为True,因此代码可以在循环的下一次迭代中从密码字母映射中移除这个新求解的字母。
在第 89 行的while循环已经完成一次完整的迭代而loopAgain没有被设置为True之后,程序移出该循环,并且第 110 行返回存储在letterMapping中的密码字母映射。
变量letterMapping现在应该包含部分或潜在的完全解决的密码字母映射。
测试removeSolvedLetterFromMapping()函数
让我们通过在交互式 shell 中测试来看看removeSolvedLetterFromMapping()的运行情况。返回到创建intersectedMapping时打开的交互式 shell 窗口。(如果你关了窗户,不用担心;你可以重新输入第 235 页的的“字母映射帮助函数如何工作中的指令,然后跟着这个例子做。)
要从intersectedMapping中删除已解决的字母,请在交互式 shell 中输入以下内容:
>>> letterMapping = simpleSubHacker.removeSolvedLettersFromMapping(
intersectedMapping)
>>> intersectedMapping
{'A': [], 'C': ['T'], 'B': ['S'], 'E': [], 'D': [], 'G': ['B'], 'F': [],
'I': ['O'], 'H': ['M'], 'K': ['A'], 'J': [], 'M': ['D'], 'L': ['N'], 'O':
['U'], 'N': ['L'], 'Q': ['C'], 'P': ['I'], 'S': ['P'], 'R': ['R'], 'U': [],
'T': [], 'W': [], 'V': [], 'Y': [], 'X': ['F'], 'Z': ['E']}
当您从intersectedMapping中移除已解决的字母时,请注意'M'现在只有一个潜在的解密字母'D',这正是我们预测的情况。现在每个密码字母只有一个潜在的解密字母,所以我们可以使用密码字母映射来开始解密。我们需要再一次回到这个交互式 shell 示例,所以保持它的窗口打开。
hackSimpleSub()函数
既然您已经看到了函数getBlankCipherletterMapping()、addLettersToMapping、()、intersectMappings()和removeSolvedLettersFromMapping()如何操作您传递给它们的密码字母映射,那么让我们在我们的simpleSubHacker.py程序中使用它们来解密消息。
第 113 行定义了hackSimpleSub()函数,它获取一条密文消息,并使用字母映射帮助函数返回部分或全部解决的密码字母映射:
def hackSimpleSub(message):intersectedMap = getBlankCipherletterMapping()cipherwordList = nonLettersOrSpacePattern.sub('', message.upper()).split()
在第 114 行,我们创建了一个新的密码字母映射,并存储在变量intersectedMap中。这个变量最终将保存每个密码的交集映射。
在第 115 行,我们删除了message中的任何非字母字符。nonLettersOrSpacePattern中的正则对象匹配任何不是字母或空白字符的字符串。在正则表达式上调用sub()方法,该方法有两个参数。该函数在第二个参数中搜索匹配项,并用第一个参数中的字符串替换这些匹配项。然后它返回一个包含所有这些替换的字符串。在这个例子中,sub()方法告诉程序遍历大写的message字符串,并用空白字符串('')替换所有非字母字符。这使得sub()返回一个去掉了所有标点和数字字符的字符串,这个字符串存储在cipherwordList变量中。
在第 115 行执行之后,cipherwordList变量应该包含前面在message中的单个密码的大写字符串列表。
第 116 行的for循环将message列表中的每个字符串分配给cipherword变量。在这个循环中,代码创建一个空白映射,获取密码的候选项,将候选项的字母添加到一个密码字母映射中,然后将这个映射与intersectedMap相交。
for cipherword in cipherwordList:# Get a new cipherletter mapping for each ciphertext word:candidateMap = getBlankCipherletterMapping()wordPattern = makeWordPatterns.getWordPattern(cipherword)if wordPattern not in wordPatterns.allPatterns:continue # This word was not in our dictionary, so continue.# Add the letters of each candidate to the mapping:for candidate in wordPatterns.allPatterns[wordPattern]:addLettersToMapping(candidateMap, cipherword, candidate)# Intersect the new mapping with the existing intersected mapping:intersectedMap = intersectMappings(intersectedMap, candidateMap)
第 118 行从函数getBlankCipherletterMapping ()获得新的空白密码字母映射,并将其存储在candidateMap变量中。
为了找到当前密码的候选,第 120 行调用makeWordPatterns模块中的getWordPattern ()。在某些情况下,密码可能是一个名字或一个字典中不存在的非常不常用的词,在这种情况下,它的词模式可能也不会存在于wordPatterns中。如果密码的单词模式不存在于wordPatterns.allPatterns字典的关键字中,则原始明文单词不存在于字典文件中。在这种情况下,密码没有得到映射,第 122 行的continue语句返回到第 116 行列表中的下一个密码。
如果执行到第 125 行,我们知道单词模式存在于wordPatterns.allPatterns中。allPatterns字典中的值是具有wordPattern中模式的英语单词的字符串列表。因为值是列表的形式,所以我们使用一个for循环来遍历它们。在循环的每次迭代中,变量candidate被设置为这些英文单词串中的每一个。
第 125 行上的for循环调用第 126 行上的addLettersToMapping(),以使用每个候选者中的字母更新candidateMap中的密码字母映射。addLettersToMapping()函数直接修改列表,所以candidateMap在函数调用返回时被修改。
在候选中的所有字母被添加到candidateMap中的密码字母映射后,第 129 行将candidateMap与intersectedMap相交,并返回新的值intersectedMap。
此时,程序执行返回到第 116 行的for循环的开始,为cipherwordList列表中的下一个密码创建新的映射,并且下一个密码的映射也与intersectedMap相交。循环继续映射密码,直到到达cipherWordList中的最后一个字。
当我们得到包含密文中所有密码词的映射的最终相交密码字母映射时,我们将其传递给第 132 行的removeSolvedLettersFromMapping ()以移除任何已解字母。
# Remove any solved letters from the other lists:return removeSolvedLettersFromMapping(intersectedMap)
从removeSolvedLettersFromMapping ()返回的密码字母映射然后被返回给hackSimpleSub()函数。现在我们有了部分的密码解决方案,所以我们可以开始解密信息。
replace()字符串方法
string 方法返回一个替换了字符的新字符串。第一个参数是要查找的子字符串,第二个参数是替换这些子字符串的字符串。在交互式 shell 中输入以下内容以查看示例:
>>> 'mississippi'.replace('s', 'X')
'miXXiXXippi'
>>> 'dog'.replace('d', 'bl')
'blog'
>>> 'jogger'.replace('ger', 's')
'jogs'
我们将在simpleSubHacker.py程序的decryptMessage()中使用replace()字符串方法。
解密消息
为了解密我们的消息,我们将使用已经在simplesubstitutioncipher.py中编程的函数simpleSubstitutionCipher .decryptMessage()。但是simpleSubstitutionCipher.decryptMessage()只使用密钥解密,不使用字母映射,所以我们不能直接使用函数。为了解决这个问题,我们将创建一个decryptWithCipherletterMapping()函数,它接受一个字母映射,将映射转换成一个密钥,然后将密钥和消息传递给simpleSubstitutionCipher.decryptMessage()。函数decryptWithCipherletterMapping()将返回一个解密的字符串。回想一下,简单替换密钥是 26 个字符的字符串,密钥字符串中索引0处的字符是 A 的加密字符,索引1处的字符是 B 的加密字符,依此类推。
为了将一个映射转换成我们容易阅读的解密输出,我们需要首先创建一个占位符密钥,它看起来像这样:['x', 'x', 'x', 'x', 'x', 'x', 'x', 'x', 'x', 'x', 'x', 'x', 'x', 'x', 'x', 'x', 'x', 'x', 'x', 'x', 'x', 'x', 'x', 'x', 'x', 'x']。小写的'x'可以用在占位符密钥中,因为实际的密钥只使用大写字母。(您可以使用任何不是大写字母的字符作为占位符。)因为不是所有的字母都有解密,我们需要能够区分密钥列表中已经填充了解密字母的部分和解密还没有解决的部分。' x'表示尚未解决的字母。
让我们看看这些是如何在源代码中组合在一起的:
def decryptWithCipherletterMapping(ciphertext, letterMapping):# Return a string of the ciphertext decrypted with the letter mapping,# with any ambiguous decrypted letters replaced with an underscore.# First create a simple sub key from the letterMapping mapping:key = ['x'] * len(LETTERS)for cipherletter in LETTERS:if len(letterMapping[cipherletter]) == 1:# If there's only one letter, add it to the key:keyIndex = LETTERS.find(letterMapping[cipherletter][0])key[keyIndex] = cipherletter
第 140 行通过将单项式列表['x']复制 26 次来创建占位符列表。因为LETTERS是字母表中的一串字母,len(LETTERS)的计算结果是26。当用于列表和整数时,乘法运算符(*)执行列表复制。
第 141 行的for循环检查LETTERS中的每个字母是否是cipherletter变量,如果密码字母被求解(即letterMapping[cipherletter]中只有一个字母),它就用那个字母替换'x'占位符。
第 144 行的letterMapping[cipherletter][0]是解密函,keyIndex是从find()调用返回的LETTERS中解密函的索引。第 145 行将密钥列表中的这个索引设置为解密字母。
但是,如果密码字母没有解,该函数会为该密码字母插入一个下划线,以指示哪些字符仍然没有解。第 147 行用下划线替换了cipherletter中的小写字母,第 148 行用下划线替换了大写字母:
else:ciphertext = ciphertext.replace(cipherletter.lower(), '_')ciphertext = ciphertext.replace(cipherletter.upper(), '_')
在用已求解的字母替换了key中列表的所有部分后,该函数使用join()方法将字符串列表合并成一个单独的字符串,以创建一个简单的替换密钥。这个字符串被传递给simpleSubCipher.py程序中的decryptMessage()函数。
key = ''.join(key)# With the key we've created, decrypt the ciphertext:return simpleSubCipher.decryptMessage(key, ciphertext)
最后,第 152 行从decryptMessage ()函数返回解密的消息字符串。现在,我们已经拥有了查找相交字母映射、破解密钥和解密消息所需的所有函数。让我们看一个简单的例子,看看这些函数在交互式 shell 中是如何工作的。
在交互 Shell 中解密
让我们回到我们在第 235 页的的“字母映射帮助函数如何工作”中使用的例子。我们将使用我们在前面的 shell 示例中创建的intersectedMapping变量来解密密文消息'OLQIHXIRCKGNZ PLQRZKBZB MPBKSSIPLC'。
在交互式 shell 中输入以下内容:
>>> simpleSubHacker.decryptWithCipherletterMapping('OLQIHXIRCKGNZ PLQRZKBZB
MPBKSSIPLC', intersectedMapping)
UNCOMFORTABLE INCREASES DISAPPOINT
密文解密到消息“不舒服增加失望”。正如您所看到的,decryptWithCipherletterMapping()函数运行良好,并返回了完全解密的字符串。但是这个例子没有显示当我们没有解决密文中出现的所有字母时会发生什么。为了看看当我们错过一个密码字母的解密时会发生什么,让我们通过使用下面的指令从intersectedMapping中删除密码字母'M'和'S'的解:
>>> intersectedMapping['M'] = []
>>> intersectedMapping['S'] = []
然后再次尝试用intersectedMapping解密密文:
>>> simpleSubHacker.decryptWithCipherletterMapping('OLQIHXIRCKGNZ PLQRZKBZB
MPBKSSIPLC', intersectedMapping)
UNCOMFORTABLE INCREASES _ISA__OINT
这一次,部分密文没有被解密。没有解密字母的密码字母被替换为下划线。
这是一段很短的密文,很难破解。通常,加密的消息会更长。(这个例子被特别选择为可破解的。像这个例子这样短的消息通常无法使用单词模式方法破解。)要破解更长的加密,您需要为更长消息中的每个密码创建一个密码映射,然后将它们交叉在一起。hackSimpleSub()函数调用我们程序中的其他函数来完成这个任务。
调用main()函数
第 155 和 156 行调用main()函数来运行simpleSubHacker.py,如果它是直接运行的,而不是被另一个 Python 程序作为模块导入的话:
if __name__ == '__main__':main()
这就完成了我们对simpleSubHacker.py程序使用的所有函数的讨论。
注
我们的黑客方法只有在空间没有加密的情况下才有效。您可以扩展符号集,这样密码程序就可以加密空格、数字和标点符号以及字母,使您的加密消息更难(但不是不可能)破解。破解这样的信息不仅要更新字母的频率,还要更新符号集中所有符号的频率。这使得破解更加复杂,这也是本书只加密字母的原因。
总结
咻!这个simpleSubHacker.py程序相当复杂。您了解了如何使用密码字母映射来为每个密文字母建模可能的解密字母。您还了解了如何通过向映射中添加潜在的字母、使它们相交以及从其他潜在的解密字母列表中删除已求解的字母来缩小可能的密钥数量。您可以使用一些复杂的 Python 代码来找出原始简单替换密钥的大部分(如果不是全部),而不是强行找到 403,291,461,126,605,635,584,000,000 个可能的密钥。
简单替换密码的主要优点是它有大量可能的密钥。缺点是比较密码和字典文件中的单词来确定哪个密码解密成哪个字母相对容易。在第 18 章中,我们将探索一种更强大的多字母替换密码,称为维吉尼亚密码,这种密码几百年来都被认为是无法破解的。
练习题
练习题的答案可以在本书的网站www.nostarch.com/crackingcodes找到。
-
hello这个词的单词模式是什么? -
mammoth和goggles的单词模式一样吗? -
哪个单词可能是密码
PYYACAO的明文单词?Alleged,efficiently,还是poodle?
十八、编程实现维吉尼亚密码
原文:https://inventwithpython.com/cracking/chapter18.html
“我当时相信,现在仍然相信,广泛普及的加密技术给我们的安全和自由带来的好处远远超过犯罪分子和恐怖分子使用它所带来的不可避免的损害。”
——马特·布雷泽,AT&T 实验室,2001 年 9 月

意大利密码学家吉奥万·巴蒂斯塔·贝拉索是第一个在 1553 年描述维吉尼亚尔密码的人,但它最终以法国外交官布莱斯·德·维吉尼亚尔的名字命名,他是后来几年重新发明密码的许多人之一。它被称为“le chiffre indéchiffrable”,意思是“无法破译的密码”,直到 19 世纪英国学者查尔斯·巴贝奇破解了它,它才被破解。
因为维吉尼亚密码有太多可能被暴力破解的密钥,即使使用我们的英语检测模块,它也是本书迄今为止讨论的最强的密码之一。甚至对你在第十七章中学到的单词模式攻击无敌。
本章涵盖的主题
-
子项
-
使用列表-追加-连接过程构建字符串
在维吉尼亚密码中使用多个字母密钥
与凯撒密码不同,维吉尼亚尔密码有多个密钥。因为它使用了多组替换,所以维吉尼亚密码是一种多字母替换密码。与简单的替换密码不同,仅靠频率分析无法击败维吉尼亚密码。我们没有像凯撒密码那样使用 0 到 25 之间的数字密钥,而是使用字母密钥来表示维吉尼亚。
维吉尼亚密钥是一系列字母,例如一个英语单词,它被分成多个单字母子密钥,这些子密钥对明文中的字母进行加密。例如,如果我们使用PIZZA的维吉尼亚密钥,第一个子密钥是P,第二个子密钥是I,第三和第四个子密钥都是Z,第五个子密钥是A,第一个子密钥加密明文的第一个字母,第二个子密钥加密第二个字母,依此类推。当我们到达明文的第六个字母时,我们返回到第一个子密钥。
使用维吉尼亚密码和使用多个凯撒密码是一样的,如图 18-1 所示。我们对明文的每个字母应用不同的凯撒密码,而不是用一个凯撒密码加密整个明文。
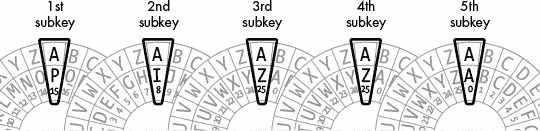
图 18-1:多个凯撒密码组合成维吉尼亚密码
每个子密钥被转换成一个整数,并作为凯撒加密密钥。例如,字母A对应于凯撒密码密钥 0。字母B对应于密钥 1,以此类推直到密钥 25 的Z,如图 18-2 所示。
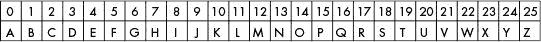
图 18-2:凯撒密钥及其对应字母
让我们来看一个例子。以下是显示在维根耶尔披萨旁边的信息“常识并不常见”。明文显示有相应的子密钥,该子密钥对其下的每个字母进行加密。
COMMONSENSEISNOTSOCOMMON
PIZZAPIZZAPIZZAPIZZAPIZZ
为了用子密钥P加密明文中的第一个C,使用子密钥的相应数字密钥 15 用凯撒密码加密它,这产生密码字母R,并通过循环子密钥对明文的每个字母重复该过程。表 18-1 显示了这一过程。明文字母的整数和子密钥(在括号中给出)相加,得到密文字母的整数。
表 18-1: 用维吉尼亚子密钥加密字母
| 明文字母 | 子密钥 | 密文字母 |
|---|---|---|
C (2) | P (15) | R (17) |
O (14) | I (8) | W (22) |
M (12) | Z (25) | L (11) |
M (12) | Z (25) | L (11) |
O (14) | A (0) | O (14) |
N (13) | P (15) | C (2) |
S (18) | I (8) | A (0) |
E (4) | Z (25) | D (3) |
N (13) | Z (25) | M (12) |
S (18) | A (0) | S (18) |
E (4) | P (15) | T (19) |
I (8) | I (8) | Q (16) |
S (18) | Z (25) | R (17) |
N (13) | Z (25) | M (12) |
O (14) | A (0) | O (14) |
T (19) | P (15) | I (8) |
S (18) | I (8) | A (0) |
O (14) | Z (25) | N (13) |
C (2) | Z (25) | B (1) |
O (14) | A (0) | O (14) |
M (12) | P (15) | B (1) |
M (12) | I (8) | U (20) |
O (14) | Z (25) | N (13) |
N (13) | Z (25) | M (12) |
使用带有密钥PIZZA(由子密钥 15,8,25,25,0 组成)的维吉尼亚密码将普通意义上的明文加密为密文RWLLOC ADMST QR MOI AN BOBUNM。
密钥越长越安全
维吉尼亚密钥中的字母越多,加密信息抵御暴力攻击的能力就越强。PIZZA 不是维吉尼亚关键字的好选择,因为它只有五个字母。一个五个字母的密钥有 11881376 种可能的组合(因为 26 个字母的 5 次方是26 ** 5 = 26×26×26×26×26 = 11881376)。一千一百万个密钥对于一个人来说太多了,无法用暴力破解,但是一台计算机可以在几个小时内尝试所有的密钥。它将首先尝试使用密钥AAAAA对消息进行解密,并检查得到的解密结果是否是英文。然后它可以尝试AAAAB,然后AAAAC,等等,直到它到达比萨饼。
好消息是,该密钥每多一个字母,可能的密钥数就会乘以 26。一旦有千万亿个可能的密钥,计算机需要很多年才能破解这个密码。表 18-2 显示了每种密钥长度有多少种可能的密钥。
表 18-2: 基于维吉尼亚密钥长度的可能密钥数
| 密钥长度 | 等式 | 可能的密钥 |
| --- | --- | --- |
| 1 | 26 | = 26 |
| 2 | 26 × 26 | = 676 |
| 3 | 676 × 26 | = 17,576 |
| 4 | 17,576 × 26 | = 456,976 |
| 5 | 456,976 × 26 | = 11,881,376 |
| 6 | 11,881,376 × 26 | = 308,915,776 |
| 7 | 308,915,776 × 26 | = 8,031,810,176 |
| 8 | 8,031,810,176 × 26 | = 208,827,064,576 |
| 9 | 208,827,064,576 × 26 | = 5,429,503,678,976 |
| 10 | 5,429,503,678,976 × 26 | = 141,167,095,653,376 |
| 11 | 141,167,095,653,376 × 26 | = 3,670,344,486,987,776 |
| 12 | 3,670,344,486,987,776 × 26 | = 95,428,956,661,682,176 |
| 13 | 95,428,956,661,682,176 × 26 | = 2,481,152,873,203,736,576 |
| 14 | 2,481,152,873,203,736,576 × 26 | = 64,509,974,703,297,150,976 |
对于 12 个或更多字母长的密钥,一台笔记本电脑不可能在合理的时间内破解它们。
选择防止字典攻击的密钥
维吉尼亚密钥不一定是像PIZZA这样的真实单词。它可以是任意长度的字母的任意组合,例如十二字母键DURIWKNMFICK。其实不用一个能在字典里找到的词是最好的。尽管单词RADIOLOGISTS也是一个比DURIWKNMFICK更容易记住的 12 个字母的密钥,但是密码分析人员可能会预料到密码学家正在使用一个英语单词作为密钥。
试图使用字典中的每个英语单词进行暴力攻击被称为字典攻击。有 95,428,956,661,682,176 个可能的十二个字母的密钥,但是在我们的字典文件中只有大约 1800 个十二个字母的单词。如果我们使用字典中的 12 个字母的单词作为密钥,这将比随机的 3 个字母的密钥(有 17,576 个可能的密钥)更容易被暴力破解。
当然,密码学家的优势在于密码分析者不知道维吉尼亚密钥的长度。但是密码分析者可以尝试所有的单字母密钥,然后所有的双字母密钥,等等,这将仍然允许他们非常快速地找到字典单词密钥。
维吉尼亚密码程序的源代码
选择文件 -> 新文件,打开新文件编辑器窗口。在文件编辑器中输入以下代码,保存为vigenereCipher.py,确保pyperclip.py在同一个目录下。按F5运行程序。
vigenereCipher.py
# Vigenere Cipher (Polyalphabetic Substitution Cipher)
# https://www.nostarch.com/crackingcodes/ (BSD Licensed)import pyperclipLETTERS = 'ABCDEFGHIJKLMNOPQRSTUVWXYZ'def main():# This text can be downloaded from https://www.nostarch.com/crackingcodes/:myMessage = """Alan Mathison Turing was a British mathematician,logician, cryptanalyst, and computer scientist."""myKey = 'ASIMOV'myMode = 'encrypt' # Set to either 'encrypt' or 'decrypt'.if myMode == 'encrypt':translated = encryptMessage(myKey, myMessage)elif myMode == 'decrypt':translated = decryptMessage(myKey, myMessage)print('%sed message:' % (myMode.title()))print(translated)pyperclip.copy(translated)print()print('The message has been copied to the clipboard.')def encryptMessage(key, message):return translateMessage(key, message, 'encrypt')def decryptMessage(key, message):return translateMessage(key, message, 'decrypt')def translateMessage(key, message, mode):translated = [] # Stores the encrypted/decrypted message string.keyIndex = 0key = key.upper()for symbol in message: # Loop through each symbol in message.num = LETTERS.find(symbol.upper())if num != -1: # -1 means symbol.upper() was not found in LETTERS.if mode == 'encrypt':num += LETTERS.find(key[keyIndex]) # Add if encrypting.elif mode == 'decrypt':num -= LETTERS.find(key[keyIndex]) # Subtract ifdecrypting.num %= len(LETTERS) # Handle any wraparound.# Add the encrypted/decrypted symbol to the end of translated:if symbol.isupper():translated.append(LETTERS[num])elif symbol.islower():translated.append(LETTERS[num].lower())keyIndex += 1 # Move to the next letter in the key.if keyIndex == len(key):keyIndex = 0else:# Append the symbol without encrypting/decrypting:translated.append(symbol)return ''.join(translated)# If vigenereCipher.py is run (instead of imported as a module), call
# the main() function:
if __name__ == '__main__':main()
维吉尼亚密码程序的运行示例
当您运行该程序时,其输出将如下所示:
Encrypted message:
Adiz Avtzqeci Tmzubb wsa m Pmilqev halpqavtakuoi, lgouqdaf, kdmktsvmztsl, izr
xoexghzr kkusitaaf.
The message has been copied to the clipboard.
该程序打印加密的邮件,并将加密的文本复制到剪贴板。
设置模块、常量和main()函数
程序的开头有描述程序的普通注释、pyperclip模块的一个import语句,以及一个名为LETTERS的变量,该变量包含每个大写字母的字符串。维吉尼亚密码的main()函数类似于本书中的其他main()函数:它从定义变量message、key和mode开始。
# Vigenere Cipher (Polyalphabetic Substitution Cipher)
# https://www.nostarch.com/crackingcodes/ (BSD Licensed)import pyperclipLETTERS = 'ABCDEFGHIJKLMNOPQRSTUVWXYZ'def main():# This text can be downloaded from https://www.nostarch.com/crackingcodes/:myMessage = """Alan Mathison Turing was a British mathematician,logician, cryptanalyst, and computer scientist."""myKey = 'ASIMOV'myMode = 'encrypt' # Set to either 'encrypt' or 'decrypt'.if myMode == 'encrypt':translated = encryptMessage(myKey, myMessage)elif myMode == 'decrypt':translated = decryptMessage(myKey, myMessage)print('%sed message:' % (myMode.title()))print(translated)pyperclip.copy(translated)print()print('The message has been copied to the clipboard.')
在运行程序之前,用户在第 10、11 和 12 行设置这些变量。加密或解密的消息(取决于myMode的设置)存储在一个名为translated的变量中,因此它可以打印到屏幕上(第 20 行)并复制到剪贴板上(第 21 行)。
用列表-追加-连接过程构建字符串
这本书里几乎所有的程序都用某种形式的代码构建了一个字符串。也就是说,程序创建一个变量,该变量以空白字符串开始,然后使用字符串连接添加字符。这就是以前的密码程序对translated变量所做的。打开交互式 shell 并输入以下代码:
>>> building = ''
>>> for c in 'Hello world!':
>>> building += c
>>> print(building)
这段代码遍历字符串'Hello world!'中的每个字符,并将其连接到存储在building中的字符串的末尾。在循环的末尾,building保存着完整的字符串。
尽管字符串连接看起来是一种简单的技术,但在 Python 中却非常低效。从空白列表开始,然后使用append()列表方法会快得多。当您构建完字符串列表后,您可以使用join()方法将该列表转换为单个字符串值。下面的代码与前面的例子做同样的事情,但是速度更快。在交互式 shell 中输入代码:
>>> building = []
>>> for c in 'Hello world!':
>>> building.append(c)
>>> building = ''.join(building)
>>> print(building)
使用这种方法来构建字符串而不是修改字符串会使程序运行得更快。您可以通过使用time.time()对这两种方法进行计时来看出不同之处。打开一个新的文件编辑器窗口,输入以下代码:
stringTest.py
import timestartTime = time.time()
for trial in range(10000):building = ''for i in range(10000):building += 'x'
print('String concatenation: ', (time.time() - startTime))startTime = time.time()
for trial in range(10000):building = []for i in range(10000):building.append('x')building = ''.join(building)
print('List appending: ', (time.time() - startTime))
将该程序另存为stringTest.py并运行。输出将如下所示:
String concatenation: 40.317070960998535
List appending: 10.488219022750854
程序stringTest.py将变量startTime设置为当前时间,运行代码使用连接将 10,000 个字符追加到字符串中,然后打印完成连接所用的时间。然后程序将startTime重置为当前时间,运行代码来使用列表追加方法构建一个相同长度的字符串,然后打印完成所用的总时间。在我的电脑上,使用字符串连接来构建 10,000 个字符串,每个字符串包含 10,000 个字符,大约需要 40 秒,但使用列表-追加-连接过程来完成同样的任务只需要 10 秒。如果你的程序构建了很多字符串,使用列表可以让你的程序运行得更快。
我们将使用列表-追加-连接过程为本书中剩余的程序构建字符串。
加密和解密消息
因为加密和解密代码基本相同,我们将为函数translateMessage()创建两个名为encryptMessage()和decryptMessage()的包装函数,它们将保存要加密和解密的实际代码。
def encryptMessage(key, message):return translateMessage(key, message, 'encrypt')def decryptMessage(key, message):return translateMessage(key, message, 'decrypt')
translateMessage()函数一次一个字符地构建加密(或解密)的字符串。translated中的列表存储了这些字符,以便在字符串构建完成时可以将它们连接起来。
def translateMessage(key, message, mode):translated = [] # Stores the encrypted/decrypted message string.keyIndex = 0key = key.upper()
请记住,维吉尼亚密码只是凯撒密码,只是根据字母在消息中的位置使用不同的密钥。跟踪使用哪个子密钥的keyIndex变量从0开始,因为用于加密或解密消息第一个字符的字母是key[0]。
该程序假定密钥全部是大写字母。为了确保密钥有效,第 38 行在key上调用upper()。
translateMessage()中的其余代码类似于凯撒密码:
for symbol in message: # Loop through each symbol in message.num = LETTERS.find(symbol.upper())if num != -1: # -1 means symbol.upper() was not found in LETTERS.if mode == 'encrypt':num += LETTERS.find(key[keyIndex]) # Add if encrypting.elif mode == 'decrypt':num -= LETTERS.find(key[keyIndex]) # Subtract ifdecrypting.
第 40 行的for循环在循环的每次迭代中将message中的字符设置为变量symbol。第 41 行找到了LETTERS中symbol大写版本的索引,这就是我们如何将一个字母翻译成一个数字。
如果第 41 行的num没有设置为-1,那么在LETTERS中找到了symbol的大写版本(意味着symbol是一个字母)。变量keyIndex跟踪使用哪个子密钥,子密钥总是key[keyIndex]求值的值。
当然,这只是一个单字母字符串。我们需要在LETTERS中找到这个字母的索引,将子密钥转换成整数。然后,这个整数被加到(如果加密的话)第 44 行的符号数上,或者被减到(如果解密的话)第 46 行的符号数上。
在凯撒密码中,我们检查了num的新值是否小于0(在这种情况下,我们给它加上了len(LETTERS))或者num的新值是否大于len(LETTERS)(在这种情况下,我们从中减去len(LETTERS))。这些检查处理环绕的情况。
然而,有一种更简单的方法来处理这两种情况。如果我们用len(LETTERS)对存储在num中的整数取模,我们可以用一行代码完成同样的计算:
num %= len(LETTERS) # Handle any wraparound.
例如,如果num是-8,我们想在它上面加上26(即len(LETTERS))得到18,这可以表示为-8 % 26,它的值是18。或者如果num是31,我们想要减去26得到5,并且31 % 26计算为5。第 48 行的模运算处理两种环绕情况。
加密(或解密)字符存在于LETTERS[num]。然而,我们希望加密(或解密)字符的大小写与symbol的原始大小写相匹配。
# Add the encrypted/decrypted symbol to the end of translated:if symbol.isupper():translated.append(LETTERS[num])elif symbol.islower():translated.append(LETTERS[num].lower())
所以如果symbol是大写字母,那么第 51 行的条件是True,第 52 行将LETTERS[num]处的字符追加到translated处,因为LETTERS中的所有字符都已经是大写的了。
但是,如果symbol是小写字母,则第 53 行的条件改为True,第 54 行将小写形式的LETTERS[num]附加到translated。这就是我们如何使加密(或解密)的消息与原始消息大小写相匹配。
现在我们已经翻译了这个符号,我们想要确保在下一次循环中使用 next 子密钥。第 56 行将keyIndex递增 1,因此下一次迭代使用下一个子密钥的索引:
keyIndex += 1 # Move to the next letter in the key.if keyIndex == len(key):keyIndex = 0
然而,如果我们在密钥的最后一个子密钥上,keyIndex将等于key的长度。第 57 行检查这种情况,如果是这种情况,将第 58 行上的keyIndex重置回0,以便key[keyIndex]指向第一个子密钥。
缩进表示第 59 行的else语句与第 42 行的if语句成对出现:
else:# Append the symbol without encrypting/decrypting:translated.append(symbol)
如果在LETTERS字符串中没有找到该符号,则执行第 61 行的代码。如果symbol是一个数字或标点符号,比如'5'或'?',就会出现这种情况。在这种情况下,第 61 行将未修改的符号附加到translated。
现在我们已经完成了在translated中构建字符串,我们在空白字符串上调用join()方法:
return ''.join(translated)
这一行使函数在被调用时返回整个加密或解密的消息。
调用main()函数
第 68 和 69 行结束了程序的代码:
if __name__ == '__main__':main()
如果程序是自己运行的,而不是由另一个想要使用其encryptMessage ()和decryptMessage()函数的程序导入的,这些行将调用main()函数。
总结
你已经接近这本书的结尾了,但是请注意,维吉尼亚密码并不比凯撒密码复杂多少,凯撒密码是你学习的第一批密码程序之一。只需对凯撒密码稍加修改,我们就创造出了一种密码,它拥有的可能密钥比暴力破解的多得多。
维吉尼亚密码不容易受到简单替换破解程序使用的字典单词模式攻击。数百年来,“无法破译”的维吉尼亚密码将信息保密,但这种密码最终也变得脆弱。在第 19 章和第 20 章中,你将学习频率分析技术,这将使你能够破解维吉尼亚密码。
练习题
练习题的答案可以在本书的网站www.nostarch.com/crackingcodes找到。
-
除了维吉尼亚密码使用多个密钥而不是一个密钥之外,维吉尼亚密码与哪种密码相似?
-
一个密钥长为 10 的维吉尼亚密钥有多少种可能的密钥?
-
数百
-
数千
-
数百万
-
超过一万亿
-
-
维吉尼亚密码是什么样的密码?
十九、频率分析
原文:https://inventwithpython.com/cracking/chapter19.html
“在混乱中寻找模式的不可言喻的天赋无法完成它的任务,除非他首先把自己沉浸在混乱中。如果它们确实包含模式,他现在没有以任何理性的方式看到它们。但是他头脑中的某些次理性部分可能会起作用。”
——尼尔·斯蒂芬森, Cryptonomicon

在本章中,你将学习如何确定每个英文字母在特定文本中的出现频率。然后,您将这些频率与您的密文的字母频率进行比较,以获得有关原始明文的信息,这将有助于您破解加密。这个确定一个字母在明文和密文中出现频率的过程被称为频率分析。理解频率分析是破解维吉尼亚密码的重要一步。我们将使用字母频率分析来破解第 20 章中的维吉尼亚密码。
本章涵盖的主题
-
字母频率和符号
-
sort()方法的key和reverse关键字参数 -
将函数作为值传递,而不是调用函数
-
使用
keys()、values()和items()方法将字典转换成列表
分析文本中字母的频率
当你掷硬币时,大约一半的时间是正面,一半的时间是反面。也就是头尾的频率应该差不多。我们可以用百分比来表示频率,方法是将一个事件发生的总次数(例如,我们抛了多少次头)除以一个事件的总尝试次数(即我们抛硬币的总次数),然后将商乘以 100。我们可以通过硬币正面或反面的频率来了解它:硬币的重量是公平的还是不公平的,甚至是双面硬币。
我们还可以从密文的字母频率中了解更多信息。英语字母表中有些字母比其他字母用得更频繁。例如,字母E、T、A和O在英语单词中出现频率最高,而字母J、X、Q和Z在英语中出现频率较低。我们将利用英语中字母频率的差异来破解维根加密的信息。
图 19-1 显示了标准英语中的字母频率。这张图表是利用书籍、报纸和其他来源的文字编辑而成的。
当我们将这些字母频率按频率从高到低排序时,E是最频繁的字母,其次是T,然后是A,依此类推,如图 19-2 所示。
英语中最常见的六个字母是ETAOIN。按频率排序的字母完整列表为ETAOINSHRDLCUMWFGYPBVKJXQZ。
回想一下,换位密码通过以不同的顺序排列原始英文明文的字母来加密消息。这意味着密文中的字母频率与原始明文中的字母频率没有区别。例如,在换位密文中,E、T和A应该比Q和Z出现得更频繁。
同样,在凯撒密文和简单替换密文中最常出现的字母更有可能是从最常见的英文字母(如E、T或A)加密而来的。同样,在密文中最不常出现的字母更有可能是从明文中的X、Q 和Z加密而来的。
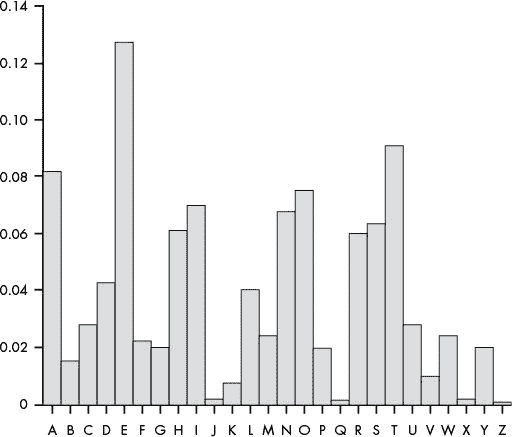
图 19-1:典型英文文本中每个字母的频率分析
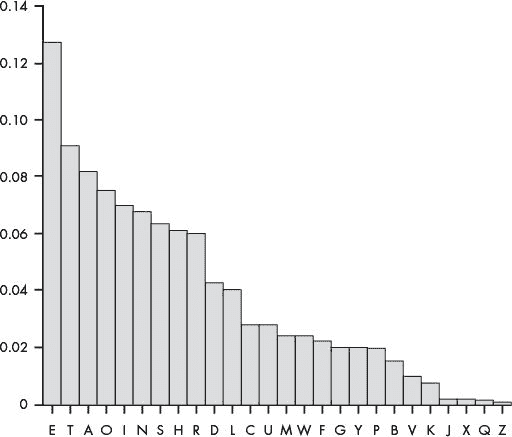
图 19-2:典型英文文本中出现频率最高和最低的字母
在破解维吉尼亚密码时,频率分析非常有用,因为它可以让我们一次一个地暴力破解每个子密钥。例如,如果一条消息是用密钥PIZZA加密的,我们需要用26 ** 5或 11,881,376 个密钥来一次找到整个密钥。然而,为了只暴力破解五个子密钥中的一个,我们只需要尝试 26 种可能性。对五个子密钥中的每一个都这样做意味着我们只需要暴力破解26 × 5或 130 个子密钥。
使用密钥PIZZA,消息中从第一个字母开始的每第五个字母用P加密,从第二个字母开始的每第五个字母用I加密,依此类推。我们可以通过用所有 26 个可能的子密钥解密密文中的每五个字母来暴力破解第一个子密钥。对于第一个子密钥,我们会发现P产生的解密字母比其他 25 个可能的子密钥更匹配英语的字母频率。这将是P是第一个子密钥的一个强有力的指示。然后,我们可以对其他子项重复此操作,直到获得整个项。
匹配字母频率
为了找到消息中的字母频率,我们将使用一种算法,简单地将字符串中的字母从最高频率到最低频率排序。然后算法使用这个有序的字符串来计算这本书所说的频率匹配分数,我们将使用它来确定一个字符串的字母频率与标准英语的字母频率有多相似。
为了计算密文的频率匹配分数,我们从 0 开始,然后每次在密文的六个最频繁的字母中出现一个最频繁的英文字母(E,T,A,O,I,N)时加一个点。在密文的六个最不常用的字母中,每次出现一个最不常用的字母(V、K、J、X、Q 或 Z ),我们都会给分数加一分。
字符串的频率匹配分数可以从 0(字符串的字母频率完全不同于英语字母频率)到 12(字符串的字母频率与常规英语的字母频率相同)。知道密文的频率匹配分数可以揭示关于原始明文的重要信息。
计算简单替换密码的频率匹配分数
我们将使用以下密文来计算使用简单替换密码加密的消息的频率匹配分数:
Sy l nlx sr pyyacao l ylwj eiswi upar lulsxrj isr sxrjsxwjr, ia esmm
rwctjsxsza sj wmpramh, lxo txmarr jia aqsoaxwa sr pqaceiamnsxu, ia esmm caytra
jp famsaqa sj. Sy, px jia pjiac ilxo, ia sr pyyacao rpnajisxu eiswi lyypcor
l calrpx ypc lwjsxu sx lwwpcolxwa jp isr sxrjsxwjr, ia esmm lwwabj sj aqax
px jia rmsuijarj aqsoaxwa. Jia pcsusx py nhjir sr agbmlsxao sx jisr elh.
-Facjclxo Ctrramm
当我们统计这段密文中每个字母出现的频率,从最高频率到最低频率排序,结果是ASRXJILPWMCYOUEQNTHBFZGKVD。A是出现频率最高的字母,S是第二高的字母,以此类推,字母D出现频率最低。
在本例中出现频率最高的六个字母(A、S、R、X、J和I)中,有两个字母(A和I)也是英语中出现频率最高的六个字母之一,它们是E、T、A、O、I和N。因此,我们在频率匹配分数上加 2 分。
密文中最不频繁出现的六个字母是F、Z、G、K、V和D。其中三个字母(Z、K和V)出现在最不频繁出现的字母集中,它们是V、K、J、X、Q和Z。因此我们在分数上再加三分。基于从该密文导出的频率排序 ASRXJILPWMCYOUEQNTHBFZGKVD,频率匹配分数为 5,如图 19-3 所示。
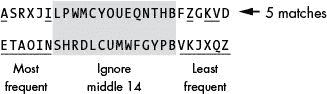
图 19-3:计算简单替换密码的频率匹配分数
使用简单替换密码加密的密文不会有很高的频率匹配分数。简单替换密文的字母频率与常规英语的字母频率不匹配,因为明文字母被密码字母一一替换。例如,如果字母T被加密成字母J,那么J更有可能在密文中频繁出现,尽管它是英语中出现频率最低的字母之一。
计算换位密码的频率匹配分数
这次,让我们计算使用换位密码加密的密文的频率匹配分数:
"I rc ascwuiluhnviwuetnh,osgaa ice tipeeeee slnatsfietgi tittynecenisl. e
fo f fnc isltn sn o a yrs sd onisli ,l erglei trhfmwfrogotn,l stcofiit.
aea wesn,lnc ee w,l eIh eeehoer ros iol er snh nl oahsts ilasvih tvfeh
rtira id thatnie.im ei-dlmf i thszonsisehroe, aiehcdsanahiec gv gyedsB
affcahiecesd d lee onsdihsoc nin cethiTitx eRneahgin r e teom fbiotd n
ntacscwevhtdhnhpiwru"
该密文中最频繁到最不频繁的字母是EISNTHAOCLRFDGWVMUYBPZXQJK。E是最常用的字母,I是第二常用的字母,依此类推。
这份密文中出现频率最高的四个字母(E、I、N和T)恰好也是标准英语(ETAOIN)中出现频率最高的字母。同样,密文中出现频率最低的五个字母(Z、X、Q、J、K)也出现在 VKJXQZ 中,总频率匹配得分为 9,如图 19-4 所示。
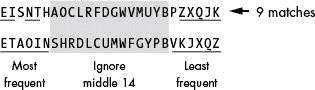
图 19-4:计算换位密码的频率匹配分数
使用换位密码加密的密文应该具有比简单替换密文高得多的频率匹配分数。原因是,与简单的替换密码不同,换位密码使用在原始明文中找到的相同字母,但排列顺序不同。因此,每个字母的频率保持不变。
对维吉尼亚密码使用频率分析
要破解维吉尼亚密码,我们需要单独解密子密钥。这意味着我们不能依靠使用英语单词检测,因为我们不能只用一个子密钥来解密足够多的信息。
相反,我们将解密用一个子密钥加密的字母,并执行频率分析,以确定哪个解密的密文产生最接近常规英语的字母频率。换句话说,我们需要找到哪个解密具有最高的频率匹配分数,这很好地表明我们已经找到了正确的子密钥。
我们对第二、第三、第四和第五个子密钥也重复这个过程。现在,我们只是猜测密钥长度是五个字母。(在第 20 章中,您将学习如何使用卡西斯基检查来确定密钥长度。)因为在维吉尼亚密码中每个子密钥(字母表中字母的总数)有 26 个解密,所以计算机只需对一个五个字母的密钥执行26 + 26 + 26 + 26或 156 次解密。这比对每个可能的子密钥组合执行解密要容易得多,总共需要 11,881,376 次解密(26 × 26 × 26 × 26 × 26)!
破解维吉尼亚密码还有更多的步骤,当我们编写破解程序时,你会在第 20 章中了解到。现在,让我们编写一个使用以下有用函数执行频率分析的模块:
getLetterCount()接受一个字符串参数,并返回一个字典,其中包含每个字母在字符串中出现的频率
getFrequencyOrder()获取一个字符串参数,并返回一个由 26 个字母组成的字符串,在该字符串参数中从最频繁到最不频繁排序
englishFreqMatchScore()接受一个字符串参数并返回一个从 0 到 12 的整数,表示一个字母的频率匹配分数
匹配字母频率的源代码
选择文件 -> 新文件,打开新文件编辑器窗口。在文件编辑器中输入以下代码,保存为freqAnalysis.py,确保pyperclip.py在同一个目录下。按F5运行程序。
freqAnalysis.py
# Frequency Finder
# https://www.nostarch.com/crackingcodes/ (BSD Licensed)ETAOIN = 'ETAOINSHRDLCUMWFGYPBVKJXQZ'
LETTERS = 'ABCDEFGHIJKLMNOPQRSTUVWXYZ'def getLetterCount(message):# Returns a dictionary with keys of single letters and values of the# count of how many times they appear in the message parameter:letterCount = {'A': 0, 'B': 0, 'C': 0, 'D': 0, 'E': 0, 'F': 0,'G': 0, 'H': 0, 'I': 0, 'J': 0, 'K': 0, 'L': 0, 'M': 0, 'N': 0,'O': 0, 'P': 0, 'Q': 0, 'R': 0, 'S': 0, 'T': 0, 'U': 0, 'V': 0,'W': 0, 'X': 0, 'Y': 0, 'Z': 0}for letter in message.upper():if letter in LETTERS:letterCount[letter] += 1return letterCountdef getItemAtIndexZero(items):return items[0]def getFrequencyOrder(message):# Returns a string of the alphabet letters arranged in order of most# frequently occurring in the message parameter.# First, get a dictionary of each letter and its frequency count:letterToFreq = getLetterCount(message)# Second, make a dictionary of each frequency count to the letter(s)# with that frequency:freqToLetter = {}for letter in LETTERS:if letterToFreq[letter] not in freqToLetter:freqToLetter[letterToFreq[letter]] = [letter]else:freqToLetter[letterToFreq[letter]].append(letter)# Third, put each list of letters in reverse "ETAOIN" order, and then# convert it to a string:for freq in freqToLetter:freqToLetter[freq].sort(key=ETAOIN.find, reverse=True)freqToLetter[freq] = ''.join(freqToLetter[freq])# Fourth, convert the freqToLetter dictionary to a list of# tuple pairs (key, value), and then sort them:freqPairs = list(freqToLetter.items())freqPairs.sort(key=getItemAtIndexZero, reverse=True)# Fifth, now that the letters are ordered by frequency, extract all# the letters for the final string:freqOrder = []for freqPair in freqPairs:freqOrder.append(freqPair[1])return ''.join(freqOrder)def englishFreqMatchScore(message):# Return the number of matches that the string in the message# parameter has when its letter frequency is compared to English# letter frequency. A "match" is how many of its six most frequent# and six least frequent letters are among the six most frequent and# six least frequent letters for English.freqOrder = getFrequencyOrder(message)matchScore = 0# Find how many matches for the six most common letters there are:for commonLetter in ETAOIN[:6]:if commonLetter in freqOrder[:6]:matchScore += 1# Find how many matches for the six least common letters there are:for uncommonLetter in ETAOIN[-6:]:if uncommonLetter in freqOrder[-6:]:matchScore += 1return matchScore
按字母顺序存储字母
第 4 行创建了一个名为ETAOIN的变量,它存储字母表中从最频繁到最不频繁排列的 26 个字母:
# Frequency Finder
# https://www.nostarch.com/crackingcodes/ (BSD Licensed)ETAOIN = 'ETAOINSHRDLCUMWFGYPBVKJXQZ'
当然,并不是所有的英语文本都反映了这种精确的频率排序。你可以很容易地找到一本有一组字母频率的书,其中 Z 比 q 使用得更频繁。例如,欧内斯特·文森特·赖特的小说Gadsby从未使用字母 E,这给了它一组奇怪的字母频率。但是在大多数情况下,包括在我们的模块中,ETAOIN 顺序应该足够准确。
对于一些不同的函数,该模块还需要一个按字母顺序排列的所有大写字母的字符串,所以我们在第 5 行设置了LETTERS常量变量。
LETTERS = 'ABCDEFGHIJKLMNOPQRSTUVWXYZ'
LETTERS的作用与前面程序中的SYMBOLS变量相同:提供字符串和整数索引之间的映射。
接下来,我们将看看getLettersCount()函数如何计算存储在message字符串中的每个字母的频率。
计算邮件中的字母数
getLetterCount()函数接受message字符串并返回一个字典值,其键是单个大写字母字符串,其值是存储该字母在message参数中出现的次数的整数。
第 10 行通过给变量分配一个字典来创建变量letterCount,该字典将所有键设置为初始值0:
def getLetterCount(message):# Returns a dictionary with keys of single letters and values of the# count of how many times they appear in the message parameter:letterCount = {'A': 0, 'B': 0, 'C': 0, 'D': 0, 'E': 0, 'F': 0,'G': 0, 'H': 0, 'I': 0, 'J': 0, 'K': 0, 'L': 0, 'M': 0, 'N': 0,'O': 0, 'P': 0, 'Q': 0, 'R': 0, 'S': 0, 'T': 0, 'U': 0, 'V': 0,'W': 0, 'X': 0, 'Y': 0, 'Z': 0}
我们通过在第 12 行使用一个for循环检查message中的每个字符,增加与键相关的值,直到它们代表每个字母的计数。
for letter in message.upper():if letter in LETTERS:letterCount[letter] += 1
for循环遍历大写版本的message中的每个字符,并将该字符赋给letter变量。在第 13 行,我们检查字符是否存在于LETTERS字符串中,因为我们不想计算message中的非字母字符。当letter是LETTERS串的一部分时,第 14 行增加letterCount[letter]处的值。
在第 12 行的for循环结束后,第 16 行的letterCount字典应该有一个计数,显示每个字母在message中出现的频率。本字典从getLetterCount()返回:
return letterCount
例如,在本章中我们将使用下面的字符串(来自en.wikipedia.org/wiki/Alan_Turing):
"""Alan Mathison Turing was a British mathematician, logician, cryptanalyst, and computer
scientist. He was highly influential in the development of computer science, providing a
formalisation of the concepts of "algorithm" and "computation" with the Turing machine. Turing
is widely considered to be the father of computer science and artificial intelligence. During
World War II, Turing worked for the Government Code and Cypher School (GCCS) at Bletchley Park,
Britain's codebreaking centre. For a time he was head of Hut 8, the section responsible for
German naval cryptanalysis. He devised a number of techniques for breaking German ciphers,
including the method of the bombe, an electromechanical machine that could find settings
for the Enigma machine. After the war he worked at the National Physical Laboratory, where
he created one of the first designs for a stored-program computer, the ACE. In 1948 Turing
joined Max Newman's Computing Laboratory at Manchester University, where he assisted in the
development of the Manchester computers and became interested in mathematical biology. He wrote
a paper on the chemical basis of morphogenesis, and predicted oscillating chemical reactions
such as the Belousov-Zhabotinsky reaction, which were first observed in the 1960s. Turing's
homosexuality resulted in a criminal prosecution in 1952, when homosexual acts were still
illegal in the United Kingdom. He accepted treatment with female hormones (chemical castration)
as an alternative to prison. Turing died in 1954, just over two weeks before his 42nd birthday,
from cyanide poisoning. An inquest determined that his death was suicide; his mother and some
others believed his death was accidental. On 10 September 2009, following an Internet campaign,
British Prime Minister Gordon Brown made an official public apology on behalf of the British
government for "the appalling way he was treated." As of May 2012 a private member's bill was
before the House of Lords which would grant Turing a statutory pardon if enacted."""
对于这个字符串值,它有 135 个 A 实例,30 个 B 实例,依此类推,getLetterCount()将返回如下所示的字典:
{'A': 135, 'B': 30, 'C': 74, 'D': 58, 'E': 196, 'F': 37, 'G': 39, 'H': 87,
'I': 139, 'J': 2, 'K': 8, 'L': 62, 'M': 58, 'N': 122, 'O': 113, 'P': 36,
'Q': 2, 'R': 106, 'S': 89, 'T': 140, 'U': 37, 'V': 14, 'W': 30, 'X': 3,
'Y': 21, 'Z': 1}
获取元组的第一个成员
第 19 行的getItemAtIndexZero()函数在向其传递一个元组时返回索引0处的项目:
def getItemAtIndexZero(items):return items[0]
在程序的后面,我们将把这个函数传递给sort()方法,将字母的频率按数字顺序排序。我们将在第 275 页的上的“将字典条目转换为可排序列表”中详细了解这一点。
按频率排序邮件中的字母
getFrequencyOrder()函数将一个message字符串作为参数,并返回一个包含字母表中 26 个大写字母的字符串,按照它们在message参数中出现的频率排列。如果message是可读的英语而不是随机的胡言乱语,那么这个字符串很可能与ETAOIN常量中的字符串相似,如果不是完全相同的话。getFrequencyOrder()函数中的代码完成了计算字符串频率匹配分数的大部分工作,我们将在第 20 章的维吉尼亚 hacking 程序中使用它。
例如,如果我们将"""Alan Mathison Turing..."""字符串传递给getFrequencyOrder (),该函数将返回字符串' ETIANORSHCLMDGFUPBWYVKXQJZ',因为 E 是该字符串中最常见的字母,接下来是 T、I、A 等等。
getFrequencyOrder()函数由五个步骤组成:
-
计数字符串中的字母
-
创建频率计数和字母列表的字典
-
按相反的顺序排列字母列表
-
将该数据转换成元组列表
-
将列表转换成函数
getFrequencyOrder()返回的最终字符串
让我们依次看看每一步。
用getLetterCount()计数字母
getFrequencyOrder()的第一步用message参数调用第 28 行的getLetterCount()来获得一个名为letterToFreq的字典,包含message中每个字母的计数:
def getFrequencyOrder(message):# Returns a string of the alphabet letters arranged in order of most# frequently occurring in the message parameter.# First, get a dictionary of each letter and its frequency count:letterToFreq = getLetterCount(message)
如果我们将"""Alan Mathison Turing..."""字符串作为message参数传递,第 28 行给letterToFreq分配如下字典值:
{'A': 135, 'C': 74, 'B': 30, 'E': 196, 'D': 58, 'G': 39, 'F': 37, 'I': 139,
'H': 87, 'K': 8, 'J': 2, 'M': 58, 'L': 62, 'O': 113, 'N': 122, 'Q': 2,
'P': 36, 'S': 89, 'R': 106, 'U': 37, 'T': 140, 'W': 30, 'V': 14, 'Y': 21,
'X': 3, 'Z': 1}
创建频率计数和字母列表的字典
getFrequencyOrder()的第二步是创建一个字典freqToLetter,它的键是频率计数,它的值是包含这些频率计数的字母列表。鉴于letterToFreq字典将字母键映射到频率值,而freqToLetter字典将频率键映射到字母值列表,因此我们需要翻转letterToFreq字典中的键和值。我们翻转键和值,因为多个字母可能具有相同的频率计数:'B'和'W'在我们的示例中都具有频率计数30,所以我们需要将它们放在类似于{30: ['B', 'W']}的字典中,因为字典键必须是惟一的。否则,类似于{30: 'B', 30: 'W'}的字典值将简单地用另一个键值对覆盖其中一个。
为了创建freqToLetter字典,第 32 行首先创建一个空白字典:
# Second, make a dictionary of each frequency count to the letter(s)# with that frequency:freqToLetter = {}for letter in LETTERS:if letterToFreq[letter] not in freqToLetter:freqToLetter[letterToFreq[letter]] = [letter]else:freqToLetter[letterToFreq[letter]].append(letter)
第 33 行循环遍历LETTERS中的所有字母,第 34 行的if语句检查字母的频率或letterToFreq[letter]是否已经作为关键字存在于freqToLetter中。如果没有,那么第 35 行添加这个键,并以字母列表作为值。如果字母的频率已经作为关键字存在于freqToLetter中,第 37 行简单地将该字母附加到已经在letterToFreq[letter]中的列表的末尾。
使用使用"""Alan Mathison Turing..."""字符串创建的示例值letterToFreq,freqToLetter现在应该返回如下内容:
{1: ['Z'], 2: ['J', 'Q'], 3: ['X'], 135: ['A'], 8: ['K'], 139: ['I'],
140: ['T'], 14: ['V'], 21: ['Y'], 30: ['B', 'W'], 36: ['P'], 37: ['F', 'U'],
39: ['G'], 58: ['D', 'M'], 62: ['L'], 196: ['E'], 74: ['C'], 87: ['H'],
89: ['S'], 106: ['R'], 113: ['O'], 122: ['N']}
请注意,字典的键现在包含频率计数,其值包含具有这些频率的字母列表。
getFrequencyOrder()的第三步涉及到对freqToLetter的每个列表中的字母串进行排序。回想一下,freqToLetter[freq]计算出字母的列表*,其频率计数为freq。我们使用列表是因为两个或更多的字母可能具有相同的频率计数,在这种情况下,列表将具有由两个或更多字母组成的字符串。
当多个字母具有相同的频率计数时,我们希望按照与它们在ETAOIN字符串中出现的顺序相反的顺序对这些字母进行排序。这使得排序一致,并最小化偶然增加频率匹配分数的可能性。
例如,假设字母 V、I、N 和 K 的频率计数对于我们试图评分的字符串都是相同的。我们还假设字符串中的四个字母比 V、I、N 和 K 具有更高的频率计数,而十八个字母具有更低的频率计数。在这个例子中,我将使用x作为这些字母的占位符。图 19-5 显示了将这四个字母按顺序排列的样子。
图 19-5:如果四个字母按ETAOIN顺序排列,频率匹配得分将获得两分。
在这种情况下,I 和 N 给频率匹配分数增加了两分,因为 I 和 N 是前六个最频繁出现的字母,即使它们在这个示例字符串中出现的频率没有 V 和 K 高。因为频率匹配分数的范围只有 0 到 12,所以这两点可以产生很大的影响!但是通过将相同频率的字母以相反的顺序排列,我们可以将一个字母得分过高的可能性降到最低。图 19-6 以相反的顺序显示了这四个字母。
图 19-6:如果四个字母顺序相反,频率匹配分数不会增加。
通过以相反的顺序排列字母,我们避免了通过 I、N、V 和 k 的随机排序来人为增加频率匹配分数。如果有 18 个字母具有较高的频率计数,4 个字母具有较低的频率计数,也是如此,如图 19-7 所示。
图 19-7:对不太频繁的字母颠倒ETAOIN顺序也避免了增加匹配分数。
反向排序顺序确保 K 和 V 不匹配英语中六个最不频繁的字母中的任何一个,并且再次避免将频率匹配分数增加两分。
为了对freqToLetter字典中的每个列表值进行逆序排序,我们需要向 Python 的sort()函数传递一个方法。让我们看看如何将一个函数或方法传递给另一个函数。
将函数按值传递
在第 42 行,我们没有调用find()方法,而是将find作为一个值传递给sort()方法调用:
freqToLetter[freq].sort(key=ETAOIN.find, reverse=True)
我们可以这样做,因为在 Python 中,函数可以被视为值。事实上,定义一个名为spam的函数与将函数定义存储在名为spam的变量中是一样的。要查看示例,请在交互式 shell 中输入以下代码:
>>> def spam():
... print('Hello!')
...
>>> spam()
Hello!
>>> eggs = spam
>>> eggs()
Hello!
在这个示例代码中,我们定义了一个名为spam()的函数来打印字符串'Hello!'。这也意味着变量spam持有函数定义。然后我们将变量spam中的函数复制到变量eggs中。这样做了之后,我们就可以像调用spam()一样调用eggs()了!请注意,赋值语句在spam后不包含圆括号。如果是的话,它将调用spam()函数并将变量eggs设置为从spam()函数得到的返回值。
因为函数是值,所以我们可以在函数调用中将它们作为参数传递。在交互式 shell 中输入以下内容以查看示例:
>>> def doMath(func):... return func(10, 5)...>>> def adding(a, b):... return a + b...>>> def subtracting(a, b):... return a - b...>>> doMath(adding) # ➊15>>> doMath(subtracting)5
这里我们定义了三个函数:doMath()、adding()和subtracting()。当我们将adding中的函数传递给doMath()调用 ➊ 时,我们正在将adding赋给变量func,而func(10, 5)正在调用adding()并将10和5传递给它。因此调用func(10, 5)实际上与调用adding和(10, 5)相同。这就是doMath(adding)返回15的原因。同样,当我们将subtracting传递给doMath()调用时,doMath(subtracting)返回5,因为func(10, 5)与subtracting(10, 5)相同。
向sort()方法传递函数
将函数或方法传递给sort()方法让我们实现不同的排序行为。通常,sort()按字母顺序对列表中的值进行排序:
>>> spam = ['C', 'B', 'A']
>>> spam.sort()
>>> spam
['A', 'B', 'C']
但是,如果我们为关键字参数key传递一个函数(或方法),当列表中的每个值被传递给那个函数时,列表中的值就按照函数的返回值排序。例如,我们也可以将ETAOIN.find()字符串方法作为key传递给sort()调用,如下所示:
>>> ETAOIN = 'ETAOINSHRDLCUMWFGYPBVKJXQZ'
>>> spam.sort(key=ETAOIN.find)
>>> spam
['A', 'C', 'B']
当我们将ETAOIN.find传递给sort()方法时,sort()方法首先对每个字符串调用find()方法,以便ETAOIN.find('A')、ETAOIN.find('B')和ETAOIN.find('C')分别返回索引2、19和11——每个字符串在ETAOIN字符串中的位置。然后sort()使用这些返回的索引,而不是原来的'A'、'B'和'C'字符串,对spam列表中的项目进行排序。这就是为什么'A'、'B'和'C'字符串被排序为'A'、'C'和'B',反映它们在ETAOIN中出现的顺序。
用sort()方法反转字母列表
为了以相反的顺序对字母进行排序,我们首先需要通过将ETAOIN.find分配给key来基于ETAOIN字符串对它们进行排序。在对所有字母调用该方法使它们都成为索引后,sort()方法根据字母的数字索引对它们进行排序。
通常,sort()函数按字母或数字顺序对它所调用的任何列表进行排序,这被称为升序。为了以降序、反向字母顺序或反向数字顺序对项目进行排序,我们将True传递给sort()方法的reverse关键字参数。
我们在第 42 行做了所有这些:
# Third, put each list of letters in reverse "ETAOIN" order, and then# convert it to a string:for freq in freqToLetter:freqToLetter[freq].sort(key=ETAOIN.find, reverse=True)freqToLetter[freq] = ''.join(freqToLetter[freq])
回想一下,在这一点上,freqToLetter是一个字典,它将整数频率计数存储为它的键,将字母字符串列表存储为它的值。键freq处的字母串被排序,而不是freqToLetter字典本身。字典无法排序,因为它们没有顺序:不像列表项那样有“第一个”或“最后一个”键值对。
再次使用freqToLetter的"""Alan Mathison Turing..."""示例值,当循环结束时,这将是存储在freqToLetter中的值:
{1: 'Z', 2: 'QJ', 3: 'X', 135: 'A', 8: 'K', 139: 'I', 140: 'T', 14: 'V',
21: 'Y', 30: 'BW', 36: 'P', 37: 'FU', 39: 'G', 58: 'MD', 62: 'L', 196: 'E',
74: 'C', 87: 'H', 89: 'S', 106: 'R', 113: 'O', 122: 'N'}
注意,30、37和58键的字符串都是以相反的顺序排序的。在循环执行之前,键值对如下所示:{30: ['B', 'W'], 37: ['F', 'U'], 58: ['D', 'M'], ...}。循环之后,它们应该是这样的:{30: 'BW', 37: 'FU', 58: 'MD', ...}。
第 43 行的join()方法调用将字符串列表变成一个单独的字符串。例如,freqToLetter[30]中的值是['B', 'W'],被联接为'BW'。
按频率排序字典列表
getFrequencyOrder()的第四步是按照频率计数对freqToLetter字典中的字符串进行排序,并将字符串转换成一个列表。请记住,因为字典中的键值对是无序的,所以字典中所有键或值的列表值将是一个随机顺序的项目列表。这意味着我们还需要对这个列表进行排序。
使用key()、values()和items()字典方法
keys()、values()和items()字典方法都将字典的一部分转换成非字典数据类型。将字典转换成另一种数据类型后,可以使用list()函数将其转换成列表。
在交互式 shell 中输入以下内容以查看示例:
>>> spam = {'cats': 10, 'dogs': 3, 'mice': 3}
>>> spam.keys()
dict_keys(['mice', 'cats', 'dogs'])
>>> list(spam.keys())
['mice', 'cats', 'dogs']
>>> list(spam.values())
[3, 10, 3]
为了获得字典中所有键的列表值,我们可以使用keys()方法返回一个dict_keys对象,然后我们可以将该对象传递给list()函数。一个类似的名为values()的字典方法返回一个dict_values对象。这些例子分别给出了字典的键列表和值列表。
为了同时获得键和值,我们可以使用items() dictionary 方法返回一个dict_items对象,这使得键值对成为元组。然后我们可以将元组传递给list()。在交互式 shell 中输入以下内容以查看实际效果:
>>> spam = {'cats': 10, 'dogs': 3, 'mice': 3}
>>> list(spam.items())
[('mice', 3), ('cats', 10), ('dogs', 3)]
通过调用items()和list(),我们将spam字典的键值对转换成元组列表。这正是我们需要用freqToLetter字典做的事情,这样我们就可以按频率按数字顺序对字母串进行排序。
将字典条目转换为可排序列表
freqToLetter字典将整数频率计数作为键,将单字母字符串列表作为值。为了按频率顺序对字符串进行排序,我们调用items()方法和list()函数来创建字典的键值对的元组列表。然后,我们将这个元组列表存储在第 47 行名为freqPairs的变量中:
# Fourth, convert the freqToLetter dictionary to a list of# tuple pairs (key, value), and then sort them:freqPairs = list(freqToLetter.items())
在第 48 行,我们将之前在程序中定义的getItemAtIndexZero函数值传递给sort()方法调用:
freqPairs.sort(key=getItemAtIndexZero, reverse=True)
getItemAtIndexZero()函数获取元组中的第一项,在本例中是频率计数整数。这意味着freqPairs中的项目按照频率计数整数的数字顺序排序。第 48 行还为reverse关键字参数传递了True,因此元组从最大频率计数到最小频率计数反向排序。
继续" ""Alan Mathison Turing..."""的例子,在第 48 行执行之后,这将是freqPairs的值:
[(196, 'E'), (140, 'T'), (139, 'I'), (135, 'A'), (122, 'N'), (113, 'O'),
(106, 'R'), (89, 'S'), (87, 'H'), (74, 'C'), (62, 'L'), (58, 'MD'), (39, 'G'),
(37, 'FU'), (36, 'P'), (30, 'BW'), (21, 'Y'), (14, 'V'), (8, 'K'), (3, 'X'),
(2, 'QJ'), (1, 'Z')]
freqPairs变量现在是从最频繁到最不频繁字母排序的元组列表:每个元组中的第一个值是表示频率计数的整数,第二个值是包含与频率计数相关的字母的字符串。
创建排序后的字母列表
getFrequencyOrder()的第五步是从freqPairs中的排序列表中创建所有字符串的列表。我们希望得到一个字符串值,它的字母按照出现的频率排序,所以我们不需要freqPairs中的整数值。变量freqOrder从第 52 行的空白列表开始,第 53 行的for循环将freqPairs中每个元组的索引1处的字符串追加到freqOrder的末尾:
# Fifth, now that the letters are ordered by frequency, extract all# the letters for the final string:freqOrder = []for freqPair in freqPairs:freqOrder.append(freqPair[1])
继续这个例子,在第 53 行的循环结束后,freqOrder应该包含['E',``'T',``'``I',``'A',``'N',``'O',``'R',``'S',``'H',``'C',``'L',``'MD',``'``G',``'FU',``'P',``'BW',``'Y',``'V',``'K',``'X',``'QJ',``'Z']作为它的值。
第 56 行通过使用join()方法将字符串连接起来,从freqOrder中的字符串列表创建一个字符串:
return ''.join(freqOrder)
对于"""Alan Mathison Turing..."""示例,getFrequencyOrder()返回字符串'ETIANORSHCLMDGFUPBWYVKXQJZ'。根据这种排序,E 是示例字符串中最频繁出现的字母,T 是第二频繁出现的字母,I 是第三频繁出现的字母,依此类推。
既然我们已经将消息的字母频率作为一个字符串值,我们可以将它与英语的字母频率('ETAOINSHRDLCUMWFGYPBVKJXQZ')的字符串值进行比较,以查看它们的匹配程度。
计算消息的频率匹配分数
englishFreqMatchScore()函数为message获取一个字符串,然后返回一个介于0和12之间的整数,表示该字符串的频率匹配分数。分数越高,message中的字母频率越接近正常英语文本的频率。
def englishFreqMatchScore(message):# Return the number of matches that the string in the message# parameter has when its letter frequency is compared to English# letter frequency. A "match" is how many of its six most frequent# and six least frequent letters are among the six most frequent and# six least frequent letters for English.freqOrder = getFrequencyOrder(message)
计算频率匹配分数的第一步是通过调用getFrequencyOrder()函数得到message的字母频率排序,我们在第 65 行做了这个。我们将有序的字符串存储在变量freqOrder中。
matchScore变量从第 67 行的0开始,并由从第 69 行开始的for循环递增,该循环比较ETAOIN字符串的前六个字母和freqOrder的前六个字母,为它们共有的每个字母给出一个点:
matchScore = 0# Find how many matches for the six most common letters there are:for commonLetter in ETAOIN[:6]:if commonLetter in freqOrder[:6]:matchScore += 1
回想一下,[:6]片段与[0:6]相同,所以第 69 行和第 70 行分别对ETAOIN和freqOrder字符串的前六个字母进行了切片。如果字母 E、T、A、O、I 或 N 中的任何一个也在freqOrder字符串的前六个字母中,则第 70 行的条件为True,第 71 行递增matchScore。
第 73 到 75 行类似于第 69 到 71 行,除了在这种情况下,它们检查ETAOIN字符串中的最后六个字母(V、K、J、X、Q和Z)是否在freqOrder字符串中的最后六个字母中。如果是,则matchScore递增。
# Find how many matches for the six least common letters there are:for uncommonLetter in ETAOIN[-6:]:if uncommonLetter in freqOrder[-6:]:matchScore += 1
第 77 行返回matchScore中的整数:
return matchScore
在计算频率匹配分数时,我们忽略频率顺序中间的 14 个字母。这些中间字母的频率彼此过于相似,无法给出有意义的信息。
总结
在本章中,您学习了如何使用sort()函数按字母或数字顺序对列表值进行排序,以及如何使用reverse和key关键字参数以不同方式对列表值进行排序。您学习了如何使用keys()、values()和items()字典方法将字典转换成列表。您还了解了可以在函数调用中将函数作为值传递。
在第 20 章中,我们将使用我们在本章中编写的频率分析模块来破解维吉尼亚密码!
练习题
练习题的答案可以在本书的网站www.nostarch.com/crackingcodes找到。
-
什么是频率分析?
-
英语中最常用的六个字母是什么?
-
运行以下代码后,
spam变量包含什么?spam = [4, 6, 2, 8] spam.sort(reverse=True) -
如果
spam变量包含一个字典,如何获取字典中键的列表值?