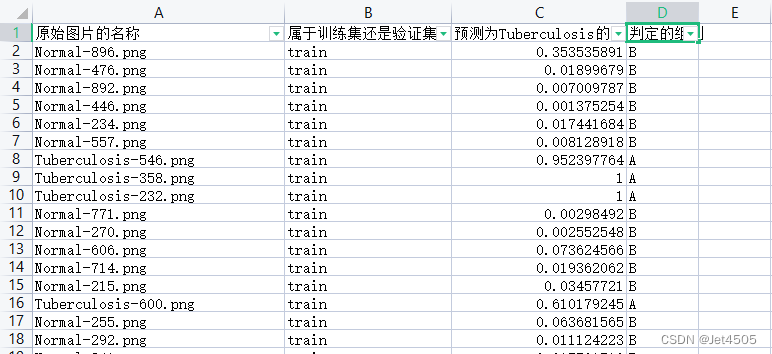
推荐阅读列表:
扩散模型实战(一):基本原理介绍
扩散模型实战(二):扩散模型的发展
扩散模型实战(三):扩散模型的应用
扩散模型实战(四):从零构建扩散模型
在扩散模型实战(四):从零构建扩散模型文章中已经介绍了在原始数据集MNIST中添加噪声以及基于基本的UNet网络训练扩散模型,模型已经可以进行预测,但是发现输入数据噪声量很大的时候预测的效果并不好,如下图所示:

那如何改进呢?
其实思路比较简单,就是按照预测的方向多迭代几次就可以,比如我们从完全的随机数开始按照上述思路进行扩散,下面是实现的代码:
# 采样策略:把采样过程拆解为5步,每次只前进一步n_steps = 5x = torch.rand(8, 1, 28, 28).to(device) # 从完全随机的值开始step_history = [x.detach().cpu()]pred_output_history = []for i in range(n_steps):with torch.no_grad(): # 在推理时不需要考虑张量的导数pred = net(x) # 预测“去噪”后的图像pred_output_history.append(pred.detach().cpu())# 将模型的输出保存下来,以便后续绘图时使用mix_factor = 1/(n_steps - i) # 设置朝着预测方向移动多少x = x*(1-mix_factor) + pred*mix_factor # 移动过程step_history.append(x.detach().cpu()) # 记录每一次移动,以便后续# 绘图时使用fig, axs = plt.subplots(n_steps, 2, figsize=(9, 4), sharex=True)axs[0,0].set_title('x (model input)')axs[0,1].set_title('model prediction')for i in range(n_steps):axs[i, 0].imshow(torchvision.utils.make_grid(step_history[i])[0].clip(0, 1), cmap='Greys')axs[i, 1].imshow(torchvision.utils.make_grid(pred_output_history[i])[0].clip(0, 1), cmap='Greys')
我们执行5次迭代,观察一下模型预测的变化,输出结果如下图所示:

从上图可以看出,模型在第一步就已经输出了去噪的图片,只是往最终的目标前进了一小步,效果不佳,但是迭代5次以后,发现效果越来越好。如果迭代更多次数,效果如何呢?
# 将采样过程拆解成40步n_steps = 40x = torch.rand(64, 1, 28, 28).to(device)for i in range(n_steps):noise_amount = torch.ones((x.shape[0],)).to(device) * (1-(i/n_steps))# 将噪声量从高到低移动with torch.no_grad():pred = net(x)mix_factor = 1/(n_steps - i)x = x*(1-mix_factor) + pred*mix_factorfig, ax = plt.subplots(1, 1, figsize=(12, 12))ax.imshow(torchvision.utils.make_grid(x.detach().cpu(), nrow=8)[0].clip(0, 1), cmap='Greys')

从上图可以看出,虽然在迭代多次以后,生成的图像越来越清晰,但是最终的效果仍然不是很好,我们可以尝试训练更长时间的扩散模型,并调整模型参数、学习率、优化器等。