1.解压
(1)将hadoop压缩包复制到/opt/software路径下

(2)解压hadoop到/opt/module目录下
[root@kb135 software]# tar -zxvf hadoop-3.1.3.tar.gz -C /opt/module/
![]()
(3)修改hadoop属主和属组
[root@kb135 module]# chown -R root:root ./hadoop-3.1.3/

2.配置环境变量
[root@kb135 module]# vim /etc/profile
# HADOOP_HOME
export HADOOP_HOME=/opt/soft/hadoop313
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HADOOP_HOME/lib
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export HDFS_JOURNALNODE_USER=root
export HDFS_ZKFC_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export HADOOP_YARN_HOME=$HADOOP_HOME
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_LIBEXEC_DIR=$HADOOP_HOME/libexec
export JAVA_LIBRARY_PATH=$HADOOP_HOME/lib/native
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop

修改完之后[root@kb135 module]# source /etc/profile
3.在hadoop目录创建data目录
[root@kb135 module]# cd ./hadoop-3.1.3/
创建目录data
[root@kb135 hadoop-3.1.3]# mkdir ./data

4.修改配置文件
进入/opt/module/hadoop-3.1.3/etc/hadoop目录,查看目录下的文件,配置几个必要的文件

(1)配置core-site.xml
[root@kb135 hadoop]# vim ./core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://kb135:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-3.1.3/data</value>
</property>
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131073</value>
</property>
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
</configuration>

(2)配置hadoop-env.sh
[root@kb135 hadoop]# vim ./hadoop-env.sh
修改第54行
export JAVA_HOME=/opt/module/jdk1.8.0_381
![]()
(3)配置hdfs-site.xml
[root@kb135 hadoop]# vim ./hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/opt/module/hadoop-3.1.3/data/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/opt/module/hadoop-3.1.3/data/dfs/data</value>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
</configuration>

(4)配置mapred-site.xml
[root@kb135 hadoop]# vim ./mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>kb135:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>kb135:19888</value>
</property>
<property>
<name>mapreduce.map.memory.mb</name>
<value>2048</value>
</property>
<property>
<name>mapreduce.reduce.memory.mb</name>
<value>2048</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>/opt/module/hadoop-3.1.3/etc/hadoop:/opt/module/hadoop-3.1.3/share/hadoop/common/*:/opt/module/hadoop-3.1.3/share/hadoop/common/lib/*:/opt/module/hadoop-3.1.3/share/hadoop/hdfs/*:/opt/module/hadoop-3.1.3/share/hadoop/hdfs/lib/*:/opt/module/hadoop-3.1.3/share/hadoop/mapreduce/*:/opt/module/hadoop-3.1.3/share/hadoop/mapreduce/lib/*:/opt/module/hadoop-3.1.3/share/hadoop/yarn/*:/opt/module/hadoop-3.1.3/share/hadoop/yarn/lib/*</value>
</property>
</configuration>

(5)配置yarn-site.xml
[root@kb135 hadoop]# vim ./yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.connect.retry-interval.ms</name>
<value>20000</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler</value>
</property>
<property>
<name>yarn.nodemanager.localizer.address</name>
<value>kb135:8040</value>
</property>
<property>
<name>yarn.nodemanager.address</name>
<value>kb135:8050</value>
</property>
<property>
<name>yarn.nodemanager.webapp.address</name>
<value>kb135:8042</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>/opt/module/hadoop-3.1.3/yarndata/yarn</value>
</property>
<property>
<name>yarn.nodemanager.log-dirs</name>
<value>/opt/module/hadoop-3.1.3/yarndata/log</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
</configuration>

(6)配置workers
[root@kb135 hadoop]# vim ./workers
修改为kb135

5.初始化hadoop
进入/opt/module/hadoop-3.1.3/bin路径
[root@kb135 bin]# hadoop namenode -format
6.设置免密登录
[root@kb135 ~]# ssh-keygen -t rsa -P ""
[root@kb135 ~]# cat /root/.ssh/id_rsa.pub >> /root/.ssh/authorized_keys
[root@kb135 ~]# ssh-copy-id -i ~/.ssh/id_rsa.pub -p22 root@kb135
7.启动hadoop
[root@kb135 ~]# start-all.sh
查看进程
[root@kb135 ~]# jps

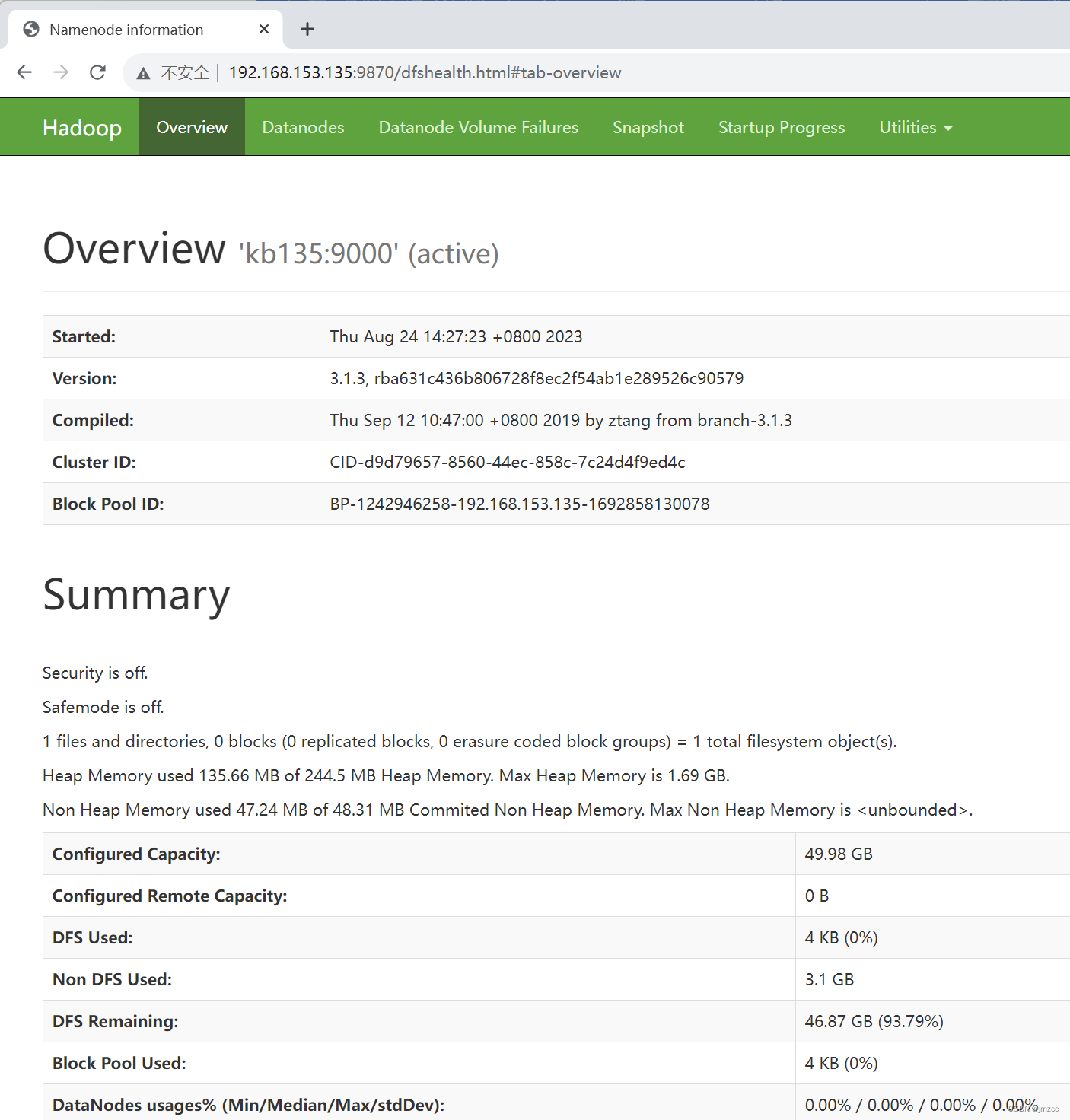
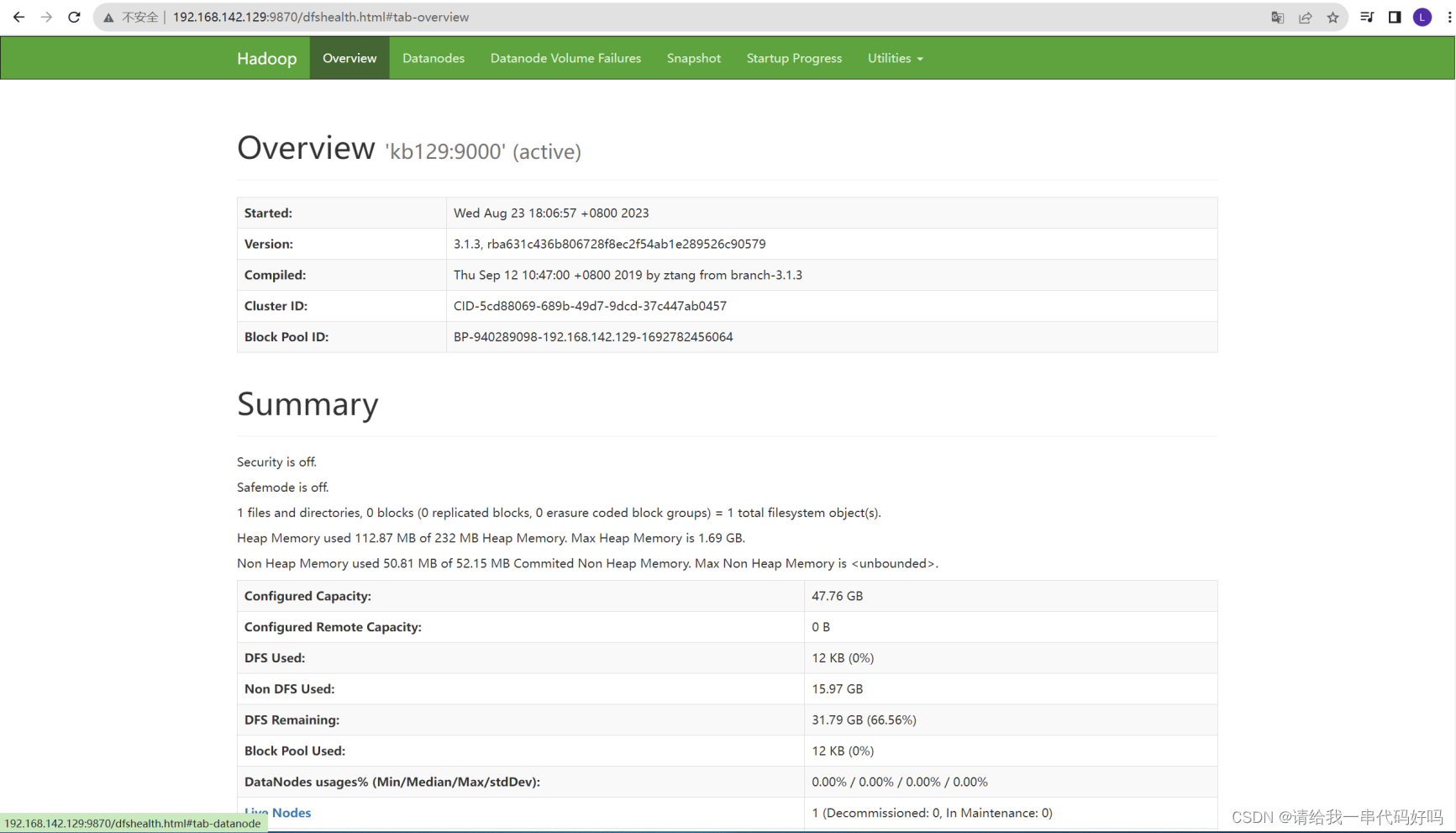
8.测试
网页中输入网址:http://192.168.142.135:9870/