| 码云仓库地址 | https://gitee.com/sun-jiahui22/crawl_project |
|---|---|
| 作业1仓库地址 | https://gitee.com/sun-jiahui22/crawl_project/tree/master/作业2/实验2.1 |
| 作业2的仓库地址 | https://gitee.com/sun-jiahui22/crawl_project/tree/master/作业2/实验2.2 |
| 作业3的仓库地址 | https://gitee.com/sun-jiahui22/crawl_project/tree/master/作业2/实验2.3 |
| 学号姓名 | 102202115孙佳会 |
作业①
要求:
在中国气象网(http://www.weather.com.cn)给定城市集的 7日天气预报,并保存在数据库。
输出信息:
| 序号 | 地区 | 日期 | 天气信息 | 温度 |
|---|---|---|---|---|
| 1 | 北京 | 7日(今天) | 晴间多云 | 17℃/12℃ |
| 2 | 北京 | 8日(今天) | 小雨 | 18℃/12℃ |
爬取7日天气预报
🌱实现思路:
- 一个数据库操作类 (WeatherDB):负责管理SQLite数据库,用于存储天气数据。
- 一个天气预报类 (WeatherForecast):负责从天气网站获取特定城市的天气预报信息,通过forecastCity()方法抓取指定城市的天气预报,并解析页面中的天气信息。(主要)
🎨主要代码:
# 该类处理从天气网站获取天气数据的功能
class WeatherForecast:def __init__(self):# 设置HTTP请求头,模拟浏览器访问self.headers = {"User-Agent": "Mozilla/5.0(Windows;U;Windows NT 6.0 x64;en-US;rv:1.9pre)Gecko/2008072421 Minefield/3.0.2pre"}# 预定义城市与其对应的天气预报代码self.cityCode = {"北京": "101010100", "上海": "101020100", "广州": "101280101", "深圳": "101280601"}# 获取某个城市的天气预报def forecastCity(self, city):if city not in self.cityCode.keys():print(city + " 的代码未找到") # 如果城市不在预定义列表中,打印错误信息return# 构建天气预报的URLurl = "https://www.weather.com.cn/weather/" + self.cityCode[city] + ".shtml"try:# 发送HTTP请求获取网页数据req = urllib.request.Request(url, headers=self.headers)data = urllib.request.urlopen(req)data = data.read()# 使用UnicodeDammit处理编码问题dammit = UnicodeDammit(data, ["utf-8", "gbk"])data = dammit.unicode_markup# 使用BeautifulSoup解析HTML内容soup = BeautifulSoup(data, "lxml")# 选择包含天气信息的<li>标签lis = soup.select("ul[class='t clearfix'] li")for li in lis:try:# 获取日期、天气情况、温度信息date = li.select("h1")[0].textweather = li.select("p[class='wea']")[0].texttemp = li.select("p[class='tem'] span")[0].text + '/' + li.select("p[class='tem'] i")[0].textprint(city, date, weather, temp) # 打印获取到的天气数据# 将数据插入到数据库self.db.insert(city, date, weather, temp)except Exception as err:print(err) # 处理解析过程中可能出现的错误except Exception as err:print(err) # 处理HTTP请求可能出现的错误# 处理多个城市的天气数据def process(self, cities):self.db = WeatherDB() # 创建数据库操作对象self.db.openDB() # 打开数据库连接# 遍历城市列表并获取各城市的天气预报for city in cities:self.forecastCity(city)self.db.show() # 显示数据库中的天气数据self.db.closeDB() # 关闭数据库连接运行结果:
心得体会
- 使用BeautifulSoup解析HTML内容时,最大的挑战在于处理不同网页的编码和结构问题,通过UnicodeDammit,成功解决了不同编码带来的解析错误。
- 将数据库操作和天气抓取逻辑分别封装到WeatherDB和WeatherForecast类中,提高了代码的可读性,让代码更具扩展性和可维护性。
作业②
要求:
用 requests 和 BeautifulSoup 库方法定向爬取股票相关信息,并存储在数据库中。
候选网站:
东方财富网:https://www.eastmoney.com/
新浪股票:http://finance.sina.com.cn/stock/
技巧:
在谷歌浏览器中进入 F12 调试模式进行抓包,查找股票列表加载使用的 url,并分析 api 返回的值,并根据所要求的参数可适当更改api 的请求参数。根据 URL 可观察请求的参数 f1、f2 可获取不同的数值,根据情况可删减请求的参数。
输出信息:
| 股票代码 | 股票名称 | 最新报价 | 涨跌幅 | 涨跌额 | 成交量 | 成交额 | 振幅 | 最高 | 最低 | 今开 | 昨收 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 301522 | N上大 | 79.85 | 1060.61 | 72.97 | 595675 | 5031370784.78 | 582.56 | 102.00 | 61.92 | 61.92 | 6.88 |
爬取股票信息
🌱实现思路:
- 在谷歌浏览器中找到正确的url
-
点击network,
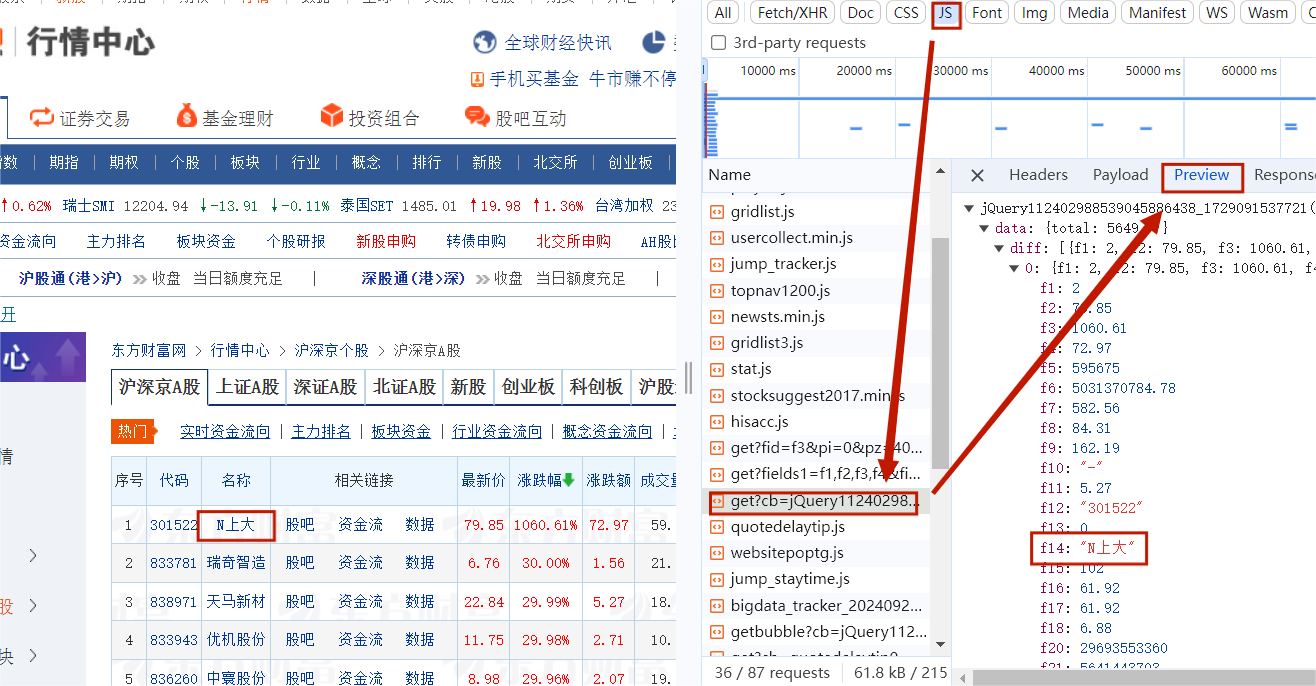
(因为这个截图不是当天截的,所以信息有所变化) -
复制url
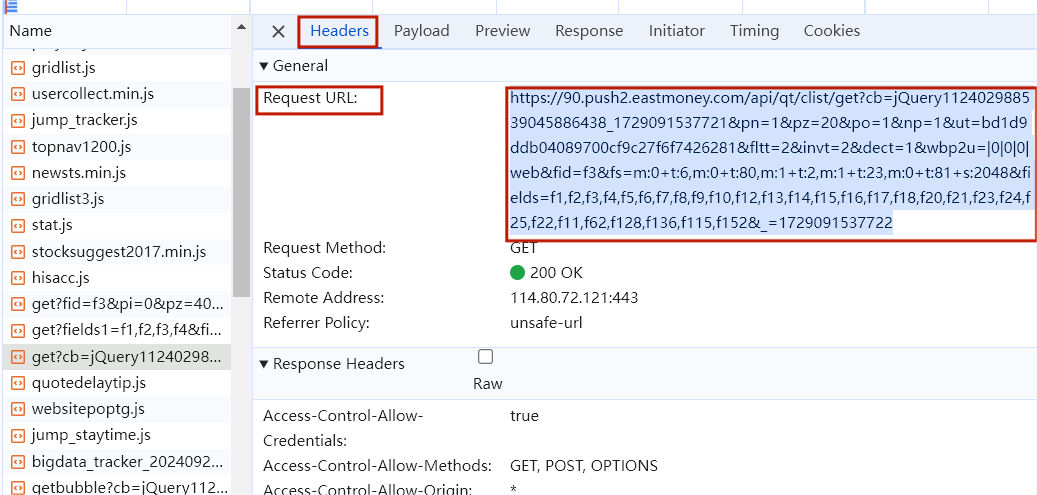
- 数据库初始化
- 创建或连接到一个本地 SQLite 数据库 (
stocks.db)。 - 如果数据库中尚未存在
stock_data表,创建该表以存储股票相关数据
- API 数据抓取
- 使用
requests.get(url)发送 HTTP 请求,获取东方财富股票 API 的响应数据。 - 对返回的 JSON 数据进行解析,提取包含股票信息的部分。
- 数据处理与存储
- 将爬取的 JSON 数据解析后,提取出股票的相关信息,如代码、名称、最新价格等。
- 使用
sqlite3插入 SQL 语句将提取的每一条股票数据插入到数据库中。
🎨主要代码:
只展示如何获取我们需要的股票以及主函数代码,数据库连接和插入到数据库部分不予赘述。
# 获取股票数据
def get_stock_data(url):response = requests.get(url)# 如果返回状态是200,说明请求成功if response.status_code == 200:try:# 提取 JSON 数据,去掉回调函数包裹的部分json_start = response.text.find('(') + 1json_end = response.text.rfind(')')json_str = response.text[json_start:json_end]data_json = json.loads(json_str) # 解析 JSON 数据return data_json['data']['diff'] # 返回股票数据部分except (ValueError, KeyError):print("JSON 数据解析失败。")return []else:print(f"请求失败,状态码: {response.status_code}")return []
# 主函数:爬取数据并存储到数据库
def main():# 数据库连接conn, cursor = create_database()# 获取用户输入的页码范围start_page = int(input("请输入开始页码: "))end_page = int(input("请输入结束页码: "))# 遍历用户指定的页码范围for page in range(start_page, end_page + 1):print(f"正在爬取第 {page} 页数据...")# 定义API URL,动态修改页码参数 `pn`url = f"https://1.push2.eastmoney.com/api/qt/clist/get?cb=jQuery112402758990905568719_1728977574693&pn={page}&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&dect=1&wbp2u=|0|0|0|web&fid=f3&fs=m:0+t:6,m:0+t:80,m:1+t:2,m:1+t:23,m:0+t:81+s:2048&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152&_=1728977574694"# 获取股票数据stocks = get_stock_data(url)# 遍历每个股票信息,并插入到数据库for stock in stocks:stock_data = (stock.get('f12'), # 股票代码stock.get('f14'), # 股票名称stock.get('f2'), # 最新价格stock.get('f3'), # 涨跌幅stock.get('f4'), # 涨跌额stock.get('f5'), # 成交量stock.get('f6'), # 成交额stock.get('f7'), # 振幅stock.get('f15'), # 最高价stock.get('f16'), # 最低价stock.get('f17'), # 今开stock.get('f18'), # 昨收)# 插入数据到数据库insert_data(cursor, stock_data)# 提交事务并关闭数据库连接conn.commit()conn.close()print("数据爬取并存储完成!")# 显示表中数据并带列名display_data_with_columns()运行结果:
(这里爬取了两页)
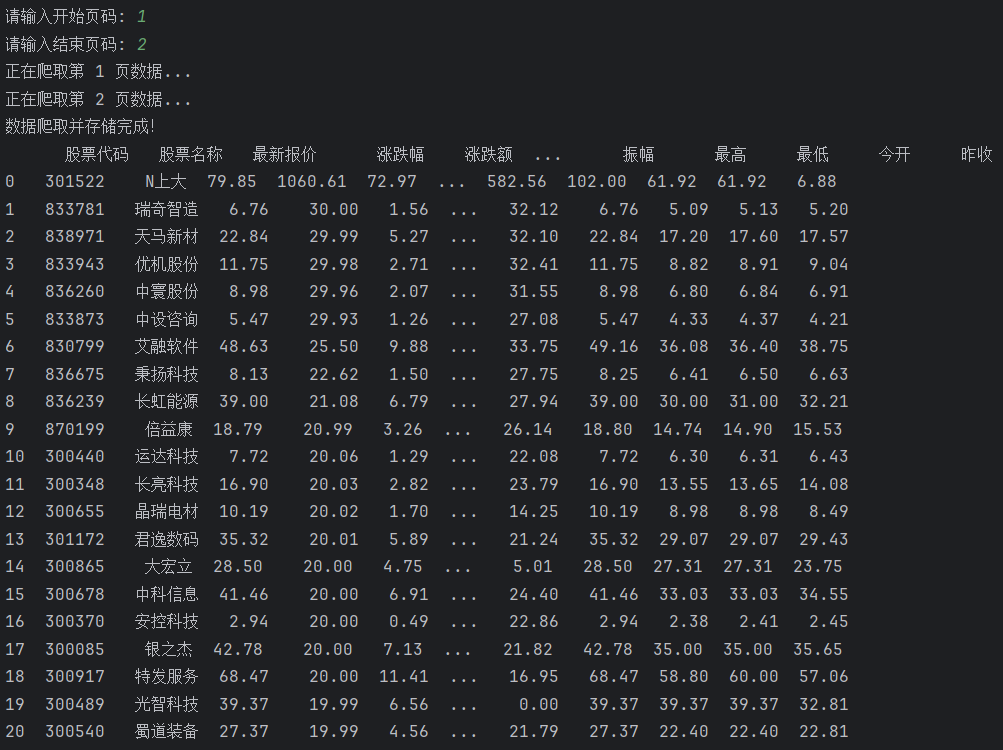
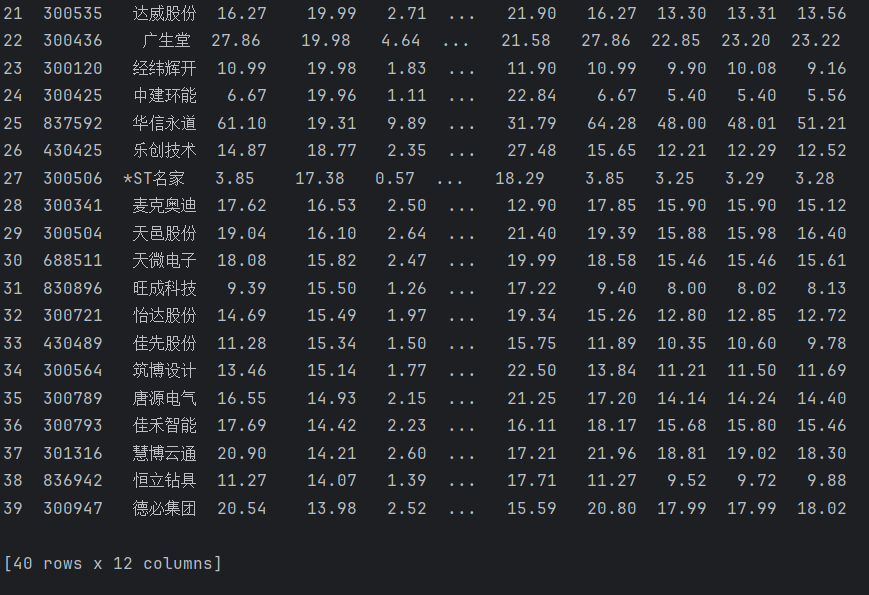
心得体会
- 跟着助教学习了怎样有效获取所需要的url,通过preview查看很直观,提高效率;
- 对抓包获取json文件并解析的过程更加熟悉
作业③
要求:
爬取中国大学 2021 主榜(https://www.shanghairanking.cn/rankings/bcur/2021)所有院校信息,并存储在数据库中,同时将浏览器 F12 调试分析的过程录制 Gif 加入至博客中。
技巧:
分析该网站的发包情况,分析获取数据的 api
输出信息:
| 排名 | 学校 | 省市 | 类型 | 总分 |
|---|---|---|---|---|
| 1 | 清华大学 | 北京 | 综合 | 969.2 |
爬取中国大学2021排名主榜
🌱实现思路:
-
通过F12获得所需url,下面是调试分析的过程,用gif形式呈现:
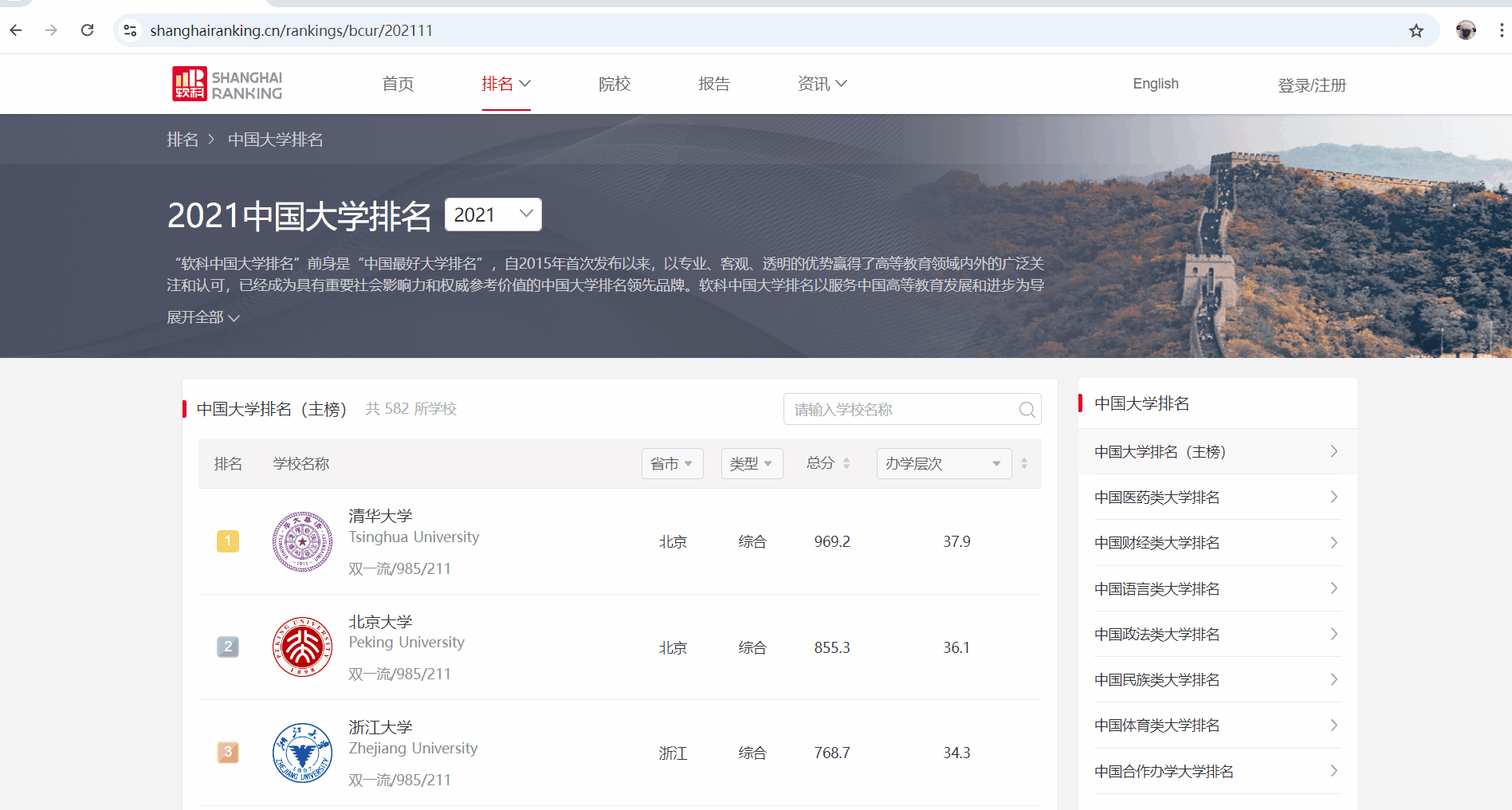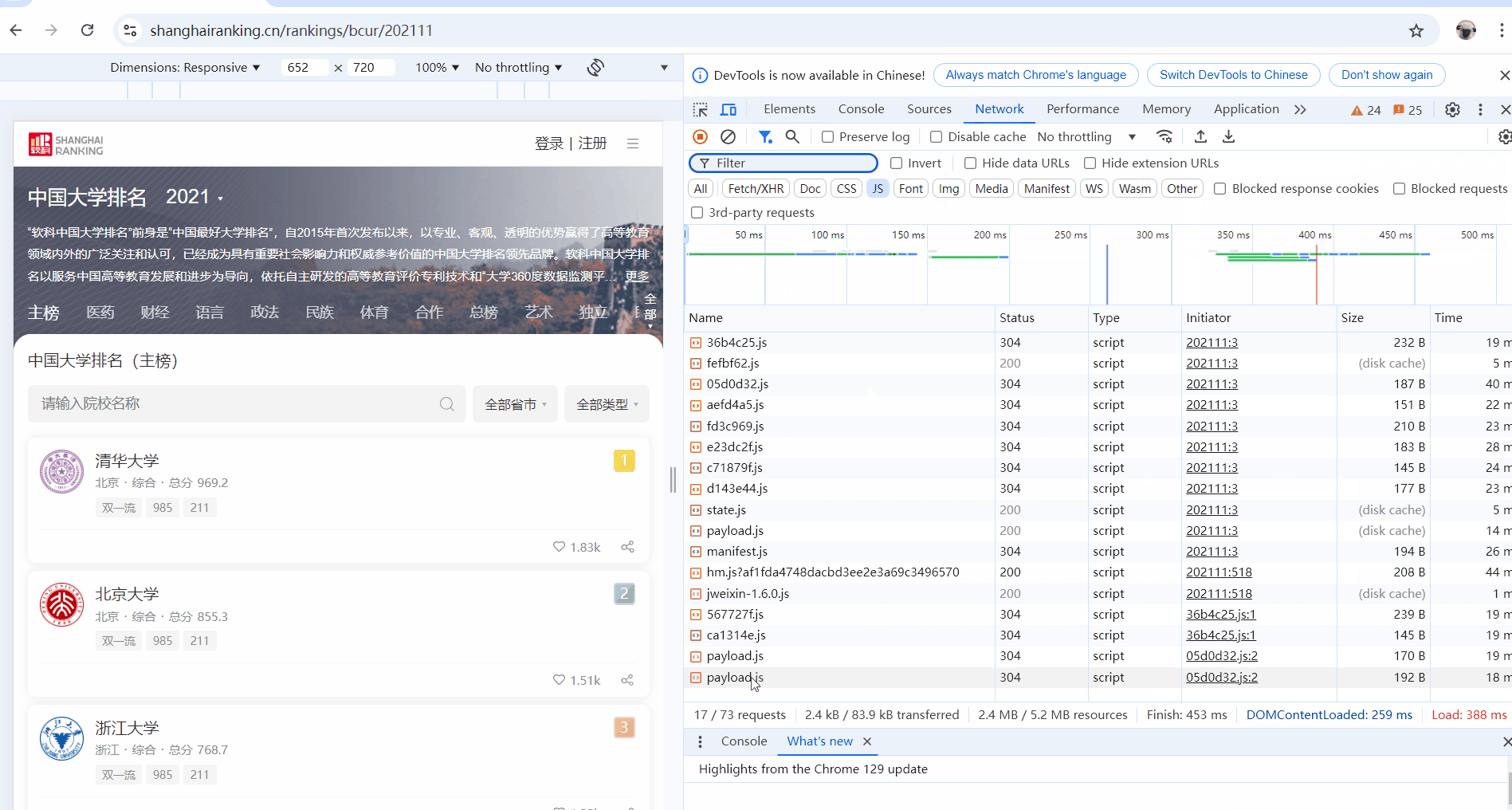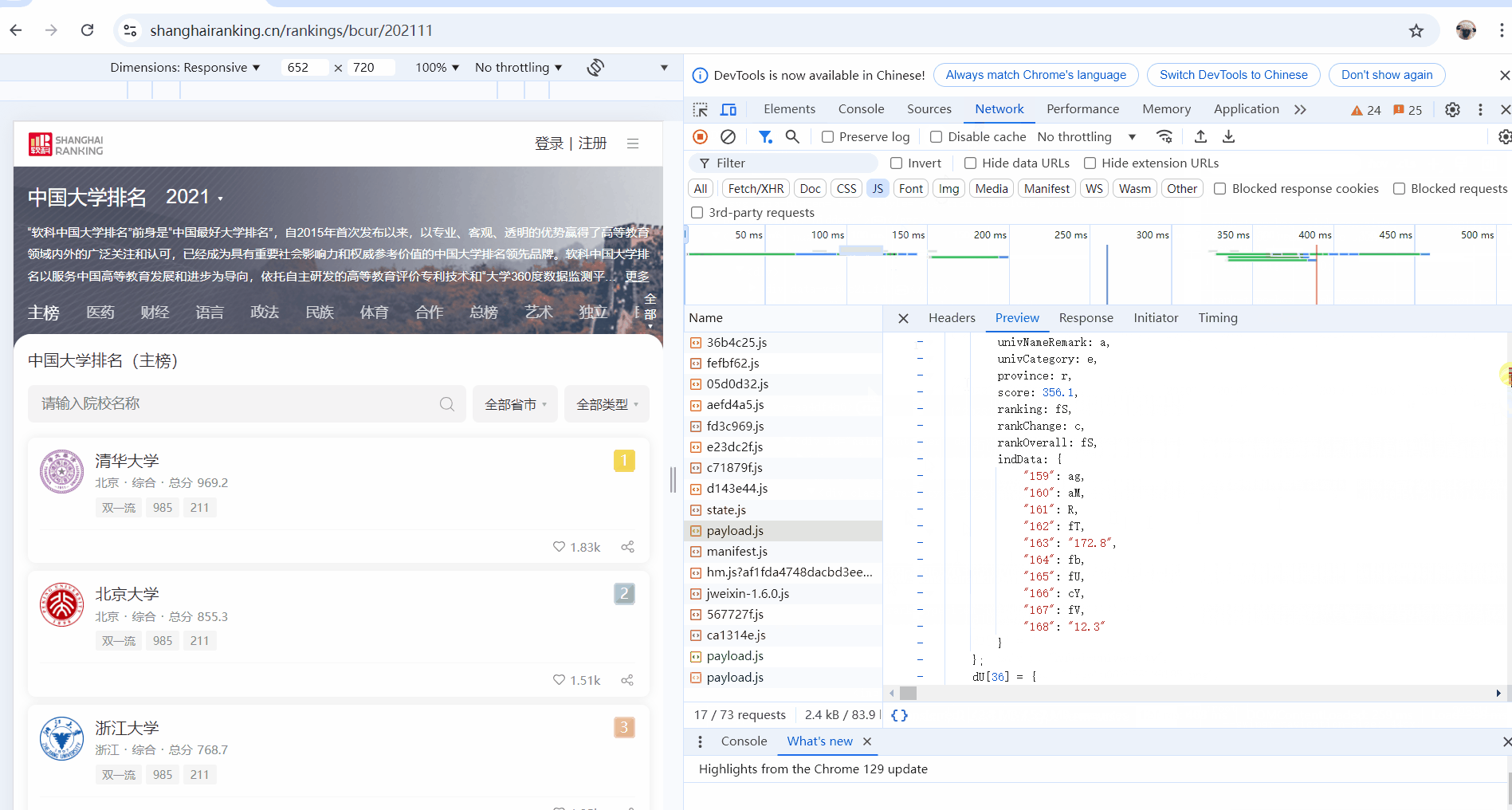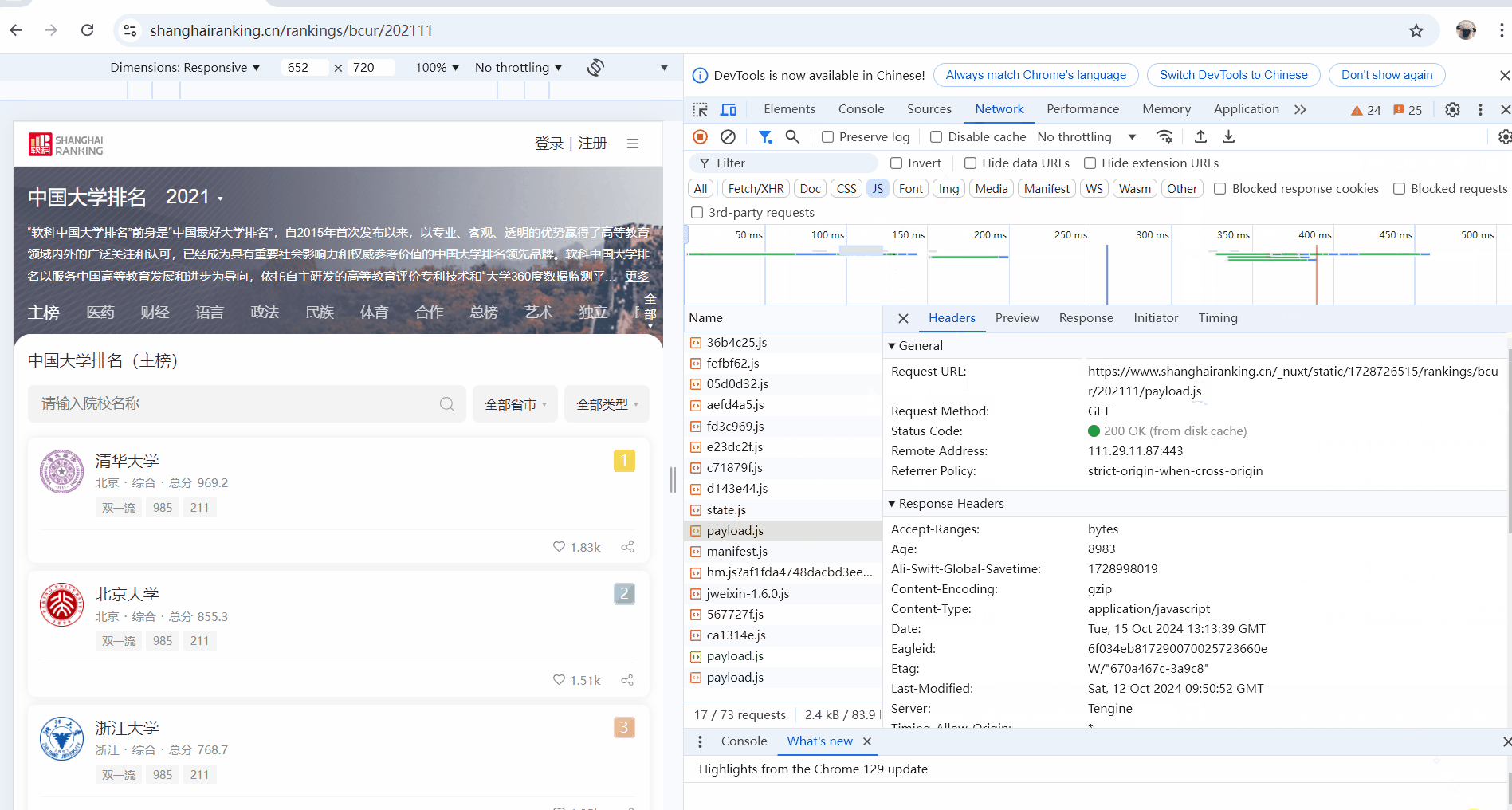
-
请求并获取数据
首先,通过 requests.get() 方法从指定的 URL 请求 JavaScript 文件,该文件包含了中国大学排名的相关信息。通过 response.text 获取返回的文件内容,并将其存储为字符串 js_content。
- 使用正则表达式提取数据
通过正则表达式 re.findall(),提取 JavaScript 文件中定义的所有学校数据对象,这些对象存储在 dU[...] 形式的数组中。提取的每个对象包含学校的名称、排名、省市、类型、总分等信息。
正则表达式的具体作用是匹配所有以 dU[数字] = {...} 形式出现的对象数据,其中 ... 表示学校的详细数据。
- 解析并提取关键信息
对每个提取到的 dU[...] 数据进行进一步解析:
- 学校名称:通过
univNameCn字段提取学校的中文名称。 - 省市:通过
province字段提取省市的符号,然后通过province_mapping将符号映射为实际的省市名称。 - 类型:通过
univCategory字段提取学校类型的符号,再通过category_mapping将符号映射为实际的类型名称。 - 总分:通过
score字段提取学校的总分。
- 将数据存储到 SQLite 数据库
利用 sqlite3 库将所有解析到的大学排名信息存储到本地的 SQLite 数据库中,表名为 rankings_2021。
我们使用 pandas 将提取的数据列表转换为 DataFrame,然后使用 to_sql() 方法将 DataFrame 写入数据库。如果数据库中已经存在同名表,则通过 if_exists='replace' 替换该表。
🎨主要代码:
# 请求数据
url = 'https://www.shanghairanking.cn/_nuxt/static/1728726515/rankings/bcur/202111/payload.js'
response = requests.get(url)
js_content = response.text# 正则表达式提取所有 dU 数组中的学校数据
matches = re.findall(r'dU\[\d+\]\s*=\s*\{(.*?)\};', js_content, re.DOTALL)universities = []
rank = 1 # 从1开始生成排名for match in matches:# 提取学校名称univ_name_cn = re.search(r'univNameCn:"(.*?)"', match)# 提取省份province_key = re.search(r'province:\s*(\w+)', match)# 提取学校类型category_key = re.search(r'univCategory:\s*(\w+)', match)# 提取总分score = re.search(r'score:\s*([\d\.]+)', match)if univ_name_cn and province_key and category_key and score:# 将省市和类型的符号转换为中文province = province_mapping.get(province_key.group(1), "未知省市")category = category_mapping.get(category_key.group(1), "未知类型")university = {'排名': rank, # 按顺序生成排名'学校': univ_name_cn.group(1),'省市': province,'类型': category,'总分': score.group(1)}universities.append(university)rank += 1 # 增加排名# 将数据保存到 SQLite 数据库
# 创建SQLite数据库
conn = sqlite3.connect('university_rankings.db')
df = pd.DataFrame(universities)
df.to_sql('rankings_2021', conn, if_exists='replace', index=False)
conn.close()由于存在地区及学校类型的映射,所以需要在代码中添加这部分:
# 创建省市和类型映射表
province_mapping = {"q": "北京", "u": "浙江", "B": "上海", "v": "湖北", "s": "陕西","k": "江苏", "A": "黑龙江", "y": "安徽", "t": "四川", "w": "广东","E": "山西", "r": "河北", "D": "天津", "J": "内蒙古", "p": "辽宁","z": "山东", "o": "河南", "x": "湖南", "C": "吉林", "H": "江西","L": "福建", "G": "重庆", "F": "贵州", "I": "云南", "ac": "广西","P": "西藏", "al": "青海", "aj": "宁夏", "ah": "新疆", "am": "海南","af": "甘肃"
}category_mapping = {"f": "综合", "e": "理工", "h": "师范", "m": "农业", "S": "医药"# 可以根据需要添加更多的类型映射
}
运行结果:

心得体会
学习到了:
- 理解网络请求和数据抓取:通过使用
requests库,能够模拟浏览器的 HTTP 请求,轻松抓取网页的静态数据。 - 数据存储的简便性:使用
sqlite3和pandas相结合的方式,可以非常方便地将数据存储到SQLite数据库中。通过将提取到的数据转换为 DataFrame 格式,然后调用to_sql()方法,轻松地实现了将数据存储到本地数据库,便于后续的数据分析和查询。这也体现了pandas库的高效和灵活。
遇到了什么问题:
在抓取数据的过程中,遇到字段符号(省市和学校类型)难以识别的问题时,通过逐步调试和引入映射表的方法,最终成功解决了问题。
对数据抓取的思考:
本次项目让我更加意识到网页数据的结构差异以及动态内容和静态内容的不同抓取方式。对于静态网页,直接抓取 JavaScript 文件中的数据是一种很有效的方式,但对于一些需要通过 API 动态加载的数据,我们可能需要借助更复杂的抓取技术。