redis集群
Redis 集群是一种用于分布式存储和管理数据的解决方案,它允许将多个 Redis 实例组合成一个单一的逻辑数据库,提供更高的性能、容量和可用性。
redis集群的优点
-
高可用性: Redis集群使用主从复制和分片技术,使得数据可以在多个节点之间进行复制和分布。这提供了数据的冗余备份,当某个节点发生故障时,集群仍然可以继续运行,不会导致数据丢失或服务中断。
-
横向扩展性: Redis集群支持分片技术,将数据分布在多个节点上。这允许集群在处理更大的数据量和更高的负载时保持性能稳定,因为负载被均匀地分布在多个节点上,避免了单一节点的性能瓶颈。
-
负载均衡: 分片技术确保数据在多个节点之间均匀分布,从而实现了负载均衡。这使得每个节点都能够处理适量的请求,防止某个节点过载而影响整体性能。
-
快速读取和写入: Redis集群使用分片技术将数据分散在多个节点上,这在一定程度上提高了读取和写入操作的性能。对于一些需要高吞吐量和低延迟的应用场景,这是一个重要的优点。
-
自动数据迁移: 当需要扩展集群或某个节点负载过高时,Redis集群能够自动执行数据迁移,将部分数据从一个节点迁移到另一个节点,以平衡负载。这种自动迁移确保了数据在集群中的均衡分布。
-
监控和管理: Redis集群通常提供了集中式的管理和监控工具,使得管理员可以更轻松地监控集群中各个节点的状态、性能和负载情况,并进行必要的调整和优化。
-
容错性: 由于Redis集群可以配置多个主节点和从节点,当部分节点出现故障时,仍然可以保持部分功能。这增加了系统的容错性,确保即使在部分节点故障的情况下,应用仍然可以继续运行。
redis集群的应用场景
-
超大数据集存储:当数据集巨大时,单个Redis节点难以容纳所有数据,需使用Redis集群分片存储于多个节点。例如,社交媒体平台的用户生成内容,如图片、视频和帖子,产生了海量的数据。Redis集群可以将不同用户的数据分片存储在多个节点上,以支持高效的数据访问和管理。
-
高并发写入场景:对于高并发写入需求,单个Redis节点可能成为性能瓶颈。Redis集群分散写入请求,提升并发写入性能。例如,电商平台的秒杀活动期间,成千上万的用户同时试图购买有限的商品。Redis集群可以将写入请求分散到多个节点上,避免单一节点的性能瓶颈,确保订单的及时处理。
-
地理分布式部署:若应用分布于不同地点且需共享数据,Redis集群可实现地理位置间数据复制和同步。例如,一个在线游戏需要在全球范围内提供一致的游戏状态和排行榜信息。通过在不同地理位置部署Redis集群,可以实现数据的复制和同步,确保玩家在不同地区的体验一致性。
-
数据冷热分离:某些情境下,可将热数据存储于高性能内存节点,将冷数据存储于廉价存储介质,Redis集群透过分片实现。例如,微博上的热点话题可以视为热门数据,相反,一些不太引人注目的微博帖子可以被视为冷门数据。Redis集群可以将与这些热点话题相关的帖子存储在Redis集群的高性能节点中,以提高访问效率和用户体验。对于一些冷门数据,可以将其存储在持久化存储中,以节省内存资源,并确保高性能节点用于更具吸引力的内容。
-
数据安全与故障隔离:在多数据中心备份和故障隔离需求下,Redis集群可在多数据中心部署以确保数据和服务恢复。例如,金融机构需要在多个数据中心之间备份和同步交易数据,以确保在某个数据中心发生故障时能够快速恢复。Redis集群的多数据中心部署可以提供数据冗余和故障隔离。
-
多租户应用:为多租户提供独立数据存储与隔离需求,Redis集群能实现租户数据分片存储。例如,云服务提供商为多个客户提供缓存服务,每个客户都需要独立的数据存储和隔离。Redis集群可以将不同客户的数据分片存储,确保数据的隔离性。
-
可扩展性需求:若预计应用将大规模增长,单一Redis节点无法扩展,Redis集群提供可扩展选项。例如,一个实时数据分析平台面临不断增长的数据量和用户量,需要随时扩展以应对负载增加。通过使用Redis集群,可以方便地添加新节点以支持更大规模的数据处理。
-
零停机维护:进行Redis维护或升级时,Redis集群实现零停机,确保服务连续性。例如,一个在线游戏需要进行服务器升级和维护,但不能因此中断玩家的游戏体验。使用Redis集群的节点迁移和数据迁移功能,可以在维护过程中保持服务的连续性。
redis集群相关命令
| 命令 | 描述 |
|---|---|
CLUSTER INFO | 打印集群的信息 |
CLUSTER NODES | 列出集群当前已知的所有节点和相关信息 |
| 节点操作 | |
CLUSTER MEET <ip> <port> | 将指定节点添加到集群中 |
CLUSTER FORGET <node_id> | 从集群中移除指定节点 |
CLUSTER REPLICATE <node_id> | 将当前节点设置为指定节点的从节点 |
CLUSTER SAVECONFIG | 将节点的配置文件保存到硬盘 |
| 槽操作 | |
CLUSTER ADDSLOTS <slot> [slot ...] | 将槽指派给当前节点 |
CLUSTER DELSLOTS <slot> [slot ...] | 从当前节点移除指定槽 |
CLUSTER FLUSHSLOTS | 移除当前节点被指派的所有槽 |
CLUSTER SETSLOT <slot> NODE <node_id> | 将槽指派给指定节点,先从另一节点移除 |
CLUSTER SETSLOT <slot> MIGRATING <node_id> | 将本节点的槽迁移到指定节点 |
CLUSTER SETSLOT <slot> IMPORTING <node_id> | 从指定节点导入槽到本节点 |
CLUSTER SETSLOT <slot> STABLE | 取消槽的导入或迁移状态 |
| 键操作 | |
CLUSTER KEYSLOT <key> | 计算给定键应该放置在哪个槽上 |
CLUSTER COUNTKEYSINSLOT <slot> | 返回指定槽中包含的键值对数量 |
CLUSTER GETKEYSINSLOT <slot> <count> | 返回指定槽中的指定数量的键 |
redis集群的部署
redis集群的案例可以参考这篇博客:https://blog.51cto.com/u_15353497/3750453
博客配套的尚硅谷redis视频:https://www.bilibili.com/video/BV1Rv41177Af?p=37&vd_source=780392db714727eda3832c4fb4c114de
redis中的插槽
Redis集群中的插槽是一种数据分布技术,它使用哈希函数将所有的键映射到一个固定范围的整数集合中,这个集合就是插槽。Redis集群默认有16384个插槽,每个主节点负责一部分插槽,从节点则复制主节点的插槽。插槽的作用是解耦了数据与节点的关系,使得数据可以在节点之间灵活地迁移和扩展。
- 插槽的计算方法:
先对键(或键中的有效部分)使用CRC16算法计算出一个结果,然后对16384取余数,得到一个0到16383之间的数字,这个数字就是插槽编号。例如,键abc的插槽编号是7638。 - 插槽的分配方法:
可以由用户指定,也可以使用redis-trib.rb脚本自动分配。redis-trib.rb脚本会尽量平均地将16384个插槽分配给N个主节点。如果有从节点,脚本会自动将从节点与主节点关联起来。 - 插槽的迁移方法:
可以使用redis-trib.rb脚本实现,也可以使用CLUSTER SETSLOT命令手动操作。迁移插槽的目的是为了平衡集群中的数据分布,或者增加或删除节点。迁移插槽的过程涉及源节点、目标节点和其他节点三方面的协作。 - 插槽的优点:
可以方便地添加或移除节点,提高集群的扩展性和可用性。当需要增加节点时,只需要把其他节点的某些插槽挪到新节点就可以;当需要移除节点时,只需要把移除节点上的插槽挪到其他节点就行了。在这一点上,不需要停掉所有的Redis服务。 - 插槽的缺点:
限制了集群中可用的键数量和主节点数量。因为插槽数是固定的16384个,所以如果集群中有很多键,那么可能会出现哈希冲突的情况,导致不同的键被映射到同一个插槽上。这样会影响集群中键的分布均匀性和性能。另外,因为每个主节点都要负责一部分插槽,所以主节点数量不能超过16384个。而且Redis作者不建议Redis集群节点数量超过1000个,因为这样会导致网络拥堵和心跳包过大。
redis集群实现原理
Redis集群的实现原理主要包括以下几个方面:
-
数据分片:Redis集群将所有的数据分成16384个哈希槽,每个节点负责一部分哈希槽,每个键根据CRC16算法计算出一个哈希槽编号,公式为
slot = CRC16(key) % 16384,然后存储在相应的节点上。这样,集群可以通过简单的算法,快速定位键所在的节点,而不需要维护一个全局的键映射表。 -
节点通信:Redis集群中的节点会通过Gossip协议来交换信息,维护集群的状态。每个节点都会保存一个当前集群的视图,包括所有节点的地址、角色、配置纪元、负责的哈希槽等信息。每隔一段时间,每个节点都会随机选择一些节点(包括自己)发送PING消息,携带自己的视图信息。收到PING消息的节点会回复PONG消息,并根据发送节点的信息更新自己的视图,如果有更大的配置纪元,就接受该配置。通过这种方式,集群中的节点可以相互发现、传播消息、检测故障。
-
主从复制:为了保证高可用性,Redis集群采用了主从复制模型,每个主节点可以有多个从节点作为备份,从节点会复制主节点的数据和哈希槽信息。当主节点发生故障时,集群会自动将一个从节点升级为新的主节点,接管故障主节点的哈希槽和数据,保证服务的连续性。
-
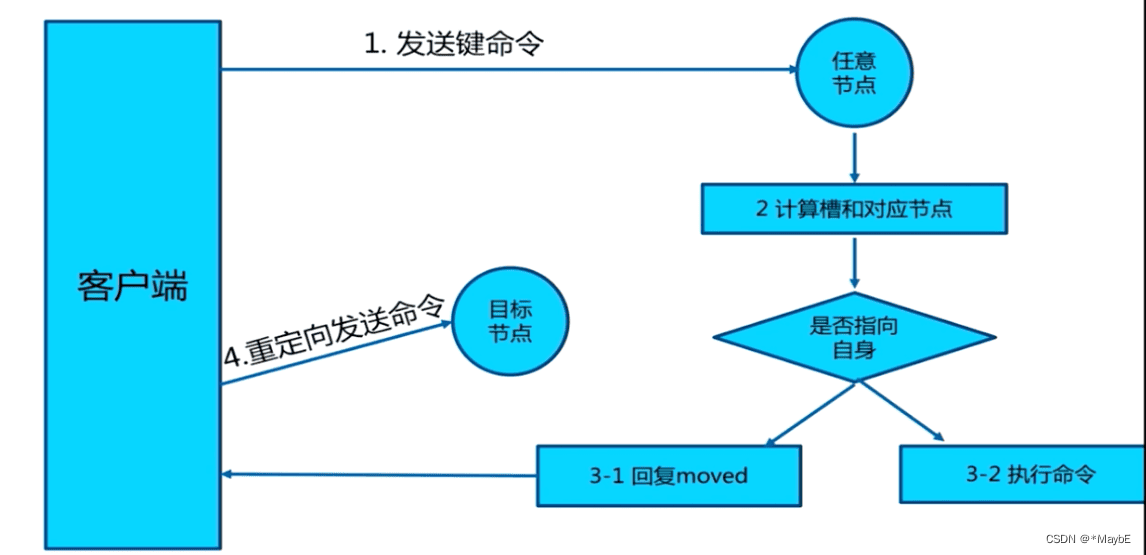
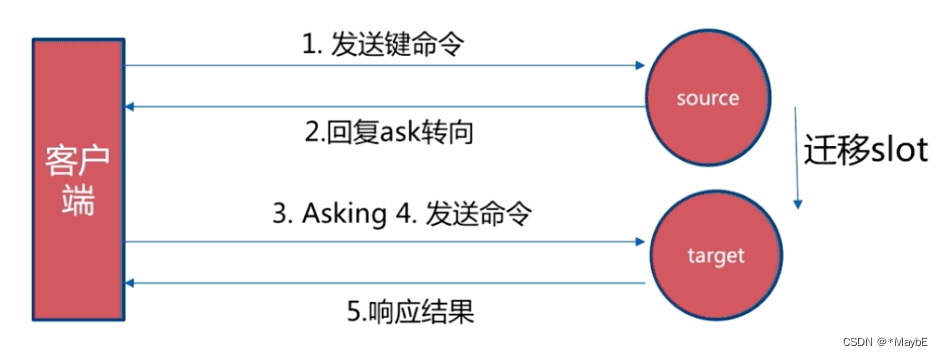
请求重定向:当客户端连接到某个节点时,如果该节点不负责请求的键所在的哈希槽,会返回一个MOVED错误,告诉客户端正确的节点地址。客户端可以缓存这个映射关系,下次直接访问正确的节点,或者重新连接到新的节点重试操作。另一种情况是当集群进行哈希槽迁移时,某些哈希槽可能处于中间状态,既不属于源节点也不属于目标节点。这时候,节点会返回一个ASK错误,让客户端临时访问目标节点获取数据。客户端可以在下次操作之前发送ASKING命令,然后重试操作。
-
复制和故障转移:Redis集群支持主从复制模式,每个主节点可以有多个从节点,从节点会复制主节点负责的哈希槽的数据。当主节点发生故障时,集群会自动从其从节点中选举一个新的主节点,接管故障主节点的哈希槽。集群使用投票机制来选举新的主节点,每个主节点都有一票投票权,当有半数以上的主节点认为某个主节点下线了,并给它的某个从节点投票,那么该从节点就会成为新的主节点。
-
集群管理:Redis集群中的每个节点都会维护一个集群状态信息,包括自己和其他节点的名字、地址、角色、配置纪元、连接状态、哈希槽分配等。每个节点都会定期与其他节点进行通信,交换这些信息,以达成一致的视图。另外,每个节点还会执行一些特殊的命令来管理集群的运行,比如添加或删除节点、迁移哈希槽、执行故障转移等。
redis集群故障恢复
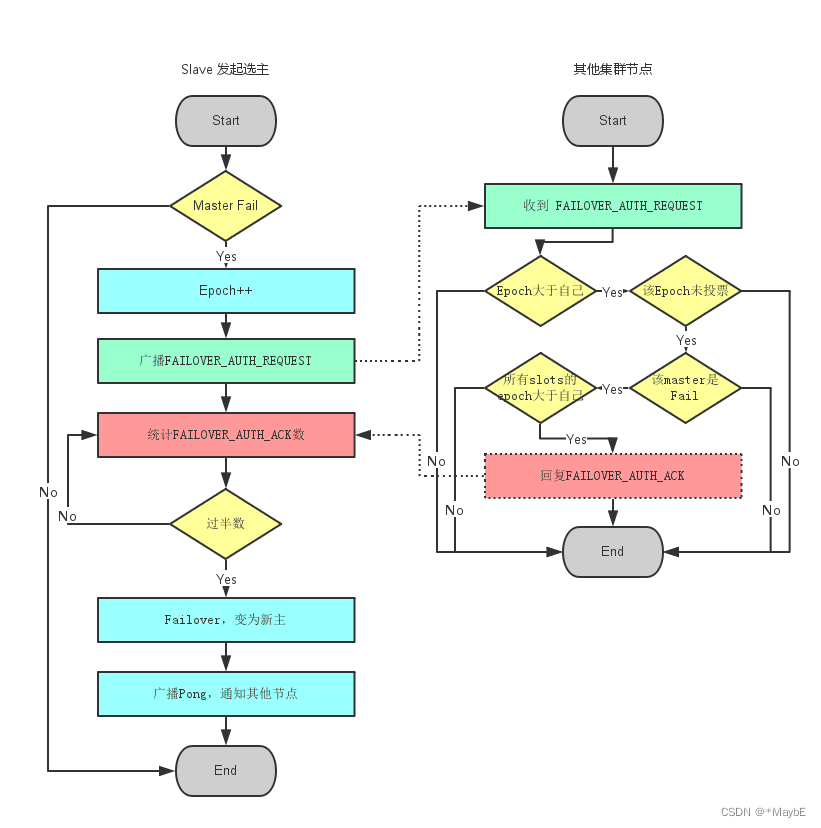
master节点挂了之后,如何进行故障恢复呢?
当slave发现自己的master变为FAIL状态时,便尝试进行Failover,以期成为新的master。由于挂掉的master可能会有多个slave。Failover的过程需要经过类Raft协议的过程在整个集群内达到一致, 其过程如下:
• slave发现自己的master变为FAIL
• 将自己记录的集群currentEpoch加1,并广播Failover Request信息
• 其他节点收到该信息,只有master响应,判断请求者的合法性,并发送FAILOVER_AUTH_ACK,对每一个epoch只发送一次ack
• 尝试failover的slave收集FAILOVER_AUTH_ACK
• 超过半数后变成新Master
• 广播Pong通知其他集群节点
参考:
尚硅谷redis集群
Java 全栈知识体系之redis,一个很好的java学习网站,强烈推荐!

![java八股文面试[java基础]——接口和抽象类的区别](https://img-blog.csdnimg.cn/398c13d3972444f7b64cf221cdece643.png)