本文将演示如何使用PEFT、QLoRa和Huggingface对新的lama-2进行微调,生成自己的代码生成器。所以本文将重点展示如何定制自己的llama2,进行快速训练,以完成特定任务。

一些知识点
llama2相比于前一代,令牌数量增加了40%,达到2T,上下文长度增加了一倍,并应用分组查询注意(GQA)技术来加速在较重的70B模型上的推理。在标准的transformer 体系结构上,使用RMSNorm归一化、SwiGLU激活和旋转位置嵌入,上下文长度达到了4096个,并应用了具有余弦学习率调度、权重衰减0.1和梯度裁剪的Adam优化器。
有监督微调(SFT)阶段的特点是优先考虑质量样本而不是数量,因为许多报告表明,使用高质量数据可以提高最终模型的性能。
最后,通过带有人类反馈的强化学习(RLHF)步骤使模型与用户偏好保持一致。收集了大量示例,其中人类在比较中选择他们首选的模型输出。这些数据被用来训练奖励模型。
最主要的一点是,LLaMA 2-CHAT已经和OpenAI ChatGPT一样好了,所以我们可以使用它作为我们本地的一个替代了
数据集
对于的微调过程,我们将使用大约18,000个示例的数据集,其中要求模型构建解决给定任务的Python代码。这是原始数据集[2]的提取,其中只选择了Python语言示例。每行包含要解决的任务的描述,如果适用的话,任务的数据输入示例,并提供解决任务的生成代码片段[3]。
# Load dataset from the hubdataset = load_dataset(dataset_name, split=dataset_split)# Show dataset sizeprint(f"dataset size: {len(dataset)}")# Show an exampleprint(dataset[randrange(len(dataset))])
创建提示
为了执行指令微调,我们必须将每个数据示例转换为指令,并将其主要部分概述如下:
def format_instruction(sample):return f"""### Instruction:Use the Task below and the Input given to write the Response, which is a programming code that can solve the following Task:### Task:{sample['instruction']}### Input:{sample['input']}### Response:{sample['output']}"""
输出的结果是这样的:
### Instruction:Use the Task below and the Input given to write the Response, which is a programming code that can solve the following Task:### Task:Develop a Python program that prints "Hello, World!" whenever it is run.### Input:### Response:#Python program to print "Hello World!"print("Hello, World!")
微调模型
为了方便演示,我们使用Google Colab环境,对于第一次测试运行,T4实例就足够了,但是当涉及到运行整个数据集训练,则需要使用A100。
除此以外,还可以登录Huggingface hub ,这样可以上传和共享模型,当然这个是可选项。
from huggingface_hub import loginfrom dotenv import load_dotenvimport os# Load the enviroment variablesload_dotenv()# Login to the Hugging Face Hublogin(token=os.getenv("HF_HUB_TOKEN"))
PEFT、Lora和QLora
训练LLM的通常步骤包括:首先,对数十亿或数万亿个令牌进行预训练得到基础模型,然后对该模型进行微调,使其专门用于下游任务。
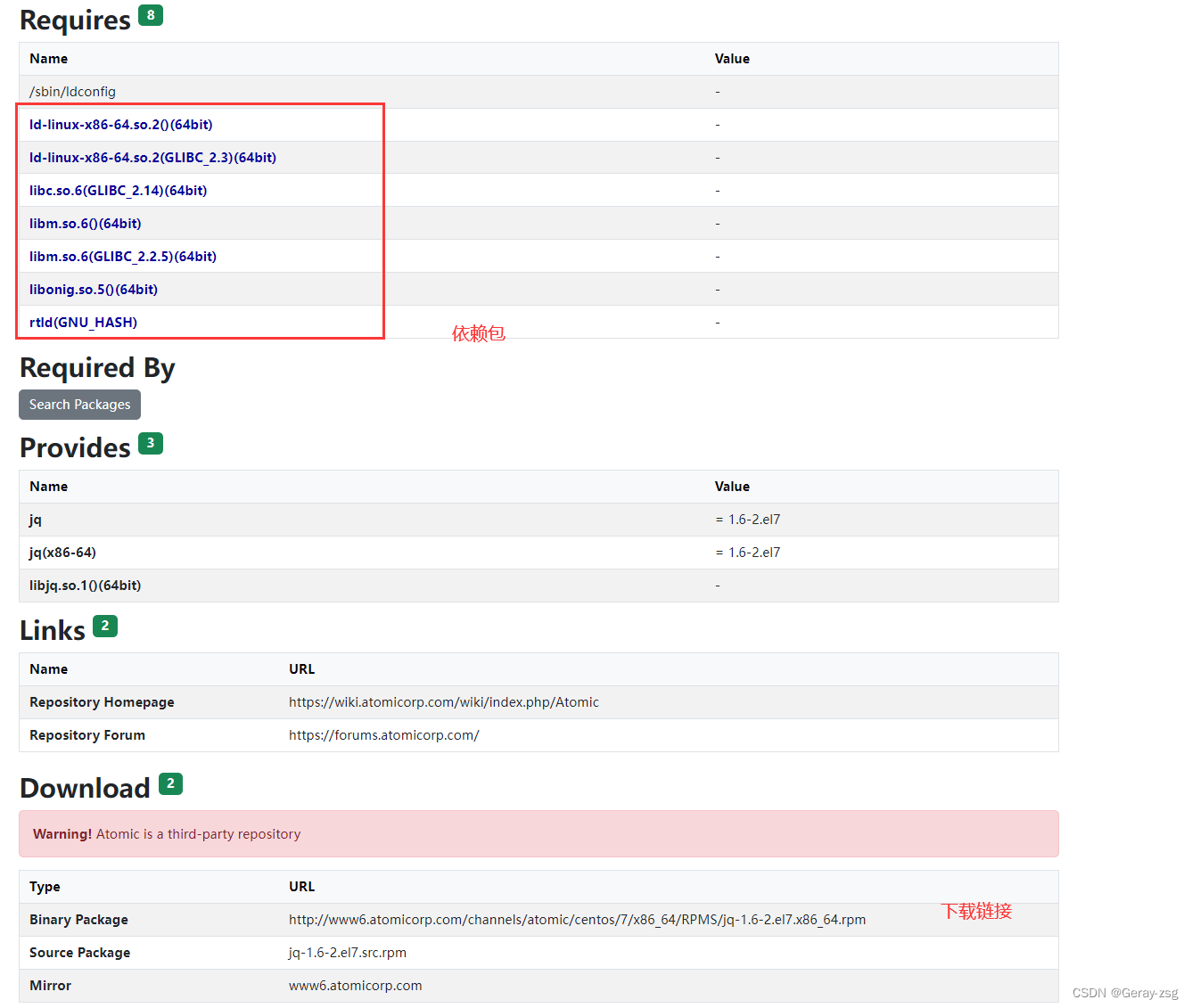
参数高效微调(PEFT)允许我们通过微调少量额外参数来大大减少RAM和存储需求,因为所有模型参数都保持冻结状态。并且PEFT还增强了模型的可重用性和可移植性,它很容易将小的检查点添加到基本模型中,通过添加PEFT参数让基础模型在多个场景中重用。最后由于没有调整基本模型,还可以保留在预训练阶段获得的所有知识,从而避免了灾难性遗忘。
PEFT保持预训练的基本模型不变,并在其上添加新的层或参数。这些层被称为“适配器”,我们将这些层添加到预训练的基本模型中,只训练这些新层的参数。但是这种方法的一个严重问题是,这些层会导致推理阶段的延迟增加,从而使流程在许多情况下效率低下。
而在LoRa技术(大型语言模型的低秩适应)中不是添加新的层,而是以一种避免在推理阶段出现这种可怕的延迟问题的方式向模型各层参数添加值。LoRa训练并存储附加权重的变化,同时冻结预训练模型的所有权重。也就是说我们利用预训练模型矩阵的变化训练一个新的权重矩阵,并将这个新矩阵分解为2个低秩矩阵,如下所示:
LoRA[1]的作者提出权值变化矩阵∆W的变化可以分解为两个低秩矩阵A和b。LoRA不直接训练∆W中的参数,而是直接训练A和b中的参数,因此可训练参数的数量要少得多。假设A的维数为100 * 1,B的维数为1 * 100,则∆W中的参数个数为100 * 100 = 10000。在A和B中训练的人数只有100 + 100 = 200,而在∆W中训练的个数是10000
这些低秩矩阵的大小由r参数定义。这个值越小,需要训练的参数就越少,速度更快。但是参数过少可能会损失信息和性能,所以r参数的选择也是需要考虑的问题。
最后,QLoRa[6]则是将量化应用于LoRa方法,通过优化内存使用的技巧,以实现“更轻量”和更便宜的训练。
微调流程
我们的示例中使用QLoRa,所以要指定BitsAndBytes配置,下载4位量化的预训练模型,定义LoraConfig。
# Get the typecompute_dtype = getattr(torch, bnb_4bit_compute_dtype)# BitsAndBytesConfig int-4 configbnb_config = BitsAndBytesConfig(load_in_4bit=use_4bit,bnb_4bit_use_double_quant=use_double_nested_quant,bnb_4bit_quant_type=bnb_4bit_quant_type,bnb_4bit_compute_dtype=compute_dtype)# Load model and tokenizermodel = AutoModelForCausalLM.from_pretrained(model_id, quantization_config=bnb_config, use_cache = False, device_map=device_map)model.config.pretraining_tp = 1# Load the tokenizertokenizer = AutoTokenizer.from_pretrained(model_id, trust_remote_code=True)tokenizer.pad_token = tokenizer.eos_tokentokenizer.padding_side = "right"
下面是参数定义,
# Activate 4-bit precision base model loadinguse_4bit = True# Compute dtype for 4-bit base modelsbnb_4bit_compute_dtype = "float16"# Quantization type (fp4 or nf4)bnb_4bit_quant_type = "nf4"# Activate nested quantization for 4-bit base models (double quantization)use_double_nested_quant = False# LoRA attention dimensionlora_r = 64# Alpha parameter for LoRA scalinglora_alpha = 16# Dropout probability for LoRA layerslora_dropout = 0.1
接下来的步骤对于所有的Hugging Face用户来说应该都很熟悉了,设置训练参数,创建Trainer。在执行指令微调时,我们调用封装PEFT模型定义和其他步骤的SFTTrainer方法。
# Define the training argumentsargs = TrainingArguments(output_dir=output_dir,num_train_epochs=num_train_epochs,per_device_train_batch_size=per_device_train_batch_size, # 6 if use_flash_attention else 4,gradient_accumulation_steps=gradient_accumulation_steps,gradient_checkpointing=gradient_checkpointing,optim=optim,logging_steps=logging_steps,save_strategy="epoch",learning_rate=learning_rate,weight_decay=weight_decay,fp16=fp16,bf16=bf16,max_grad_norm=max_grad_norm,warmup_ratio=warmup_ratio,group_by_length=group_by_length,lr_scheduler_type=lr_scheduler_type,disable_tqdm=disable_tqdm,report_to="tensorboard",seed=42)# Create the trainertrainer = SFTTrainer(model=model,train_dataset=dataset,peft_config=peft_config,max_seq_length=max_seq_length,tokenizer=tokenizer,packing=packing,formatting_func=format_instruction,args=args,)# train the modeltrainer.train() # there will not be a progress bar since tqdm is disabled# save model in localtrainer.save_model()
这些参数大多数通常用于llm上的其他微调脚本,我们就不做过多的说明了:
# Number of training epochsnum_train_epochs = 1# Enable fp16/bf16 training (set bf16 to True with an A100)fp16 = Falsebf16 = True# Batch size per GPU for trainingper_device_train_batch_size = 4# Number of update steps to accumulate the gradients forgradient_accumulation_steps = 1# Enable gradient checkpointinggradient_checkpointing = True# Maximum gradient normal (gradient clipping)max_grad_norm = 0.3# Initial learning rate (AdamW optimizer)learning_rate = 2e-4# Weight decay to apply to all layers except bias/LayerNorm weightsweight_decay = 0.001# Optimizer to useoptim = "paged_adamw_32bit"# Learning rate schedulelr_scheduler_type = "cosine" #"constant"# Ratio of steps for a linear warmup (from 0 to learning rate)warmup_ratio = 0.03# Group sequences into batches with same length# Saves memory and speeds up training considerablygroup_by_length = False# Save checkpoint every X updates stepssave_steps = 0# Log every X updates stepslogging_steps = 25# Disable tqdmdisable_tqdm= True
合并权重
正如上面我们提到的方法,LoRa在基本模型上训练了“修改权重”,所以最终模型需要将预训练的模型和适配器权重合并到一个模型中。
from peft import AutoPeftModelForCausalLMmodel = AutoPeftModelForCausalLM.from_pretrained(args.output_dir,low_cpu_mem_usage=True,return_dict=True,torch_dtype=torch.float16,device_map=device_map, )# Merge LoRA and base modelmerged_model = model.merge_and_unload()# Save the merged modelmerged_model.save_pretrained("merged_model",safe_serialization=True)tokenizer.save_pretrained("merged_model")# push merged model to the hubmerged_model.push_to_hub(hf_model_repo)tokenizer.push_to_hub(hf_model_repo)
推理
最后就是推理的过程了
import torchfrom transformers import AutoModelForCausalLM, AutoTokenizer# Get the tokenizertokenizer = AutoTokenizer.from_pretrained(hf_model_repo)# Load the modelmodel = AutoModelForCausalLM.from_pretrained(hf_model_repo, load_in_4bit=True, torch_dtype=torch.float16,device_map=device_map)# Create an instructioninstruction="Optimize a code snippet written in Python. The code snippet should create a list of numbers from 0 to 10 that are divisible by 2."input=""prompt = f"""### Instruction:Use the Task below and the Input given to write the Response, which is a programming code that can solve the Task.### Task:{instruction}### Input:{input}### Response:"""# Tokenize the inputinput_ids = tokenizer(prompt, return_tensors="pt", truncation=True).input_ids.cuda()# Run the model to infere an outputoutputs = model.generate(input_ids=input_ids, max_new_tokens=100, do_sample=True, top_p=0.9,temperature=0.5)# Print the resultprint(f"Prompt:\n{prompt}\n")print(f"Generated instruction:\n{tokenizer.batch_decode(outputs.detach().cpu().numpy(), skip_special_tokens=True)[0][len(prompt):]}")
结果如下:
Prompt:### Instruction:Use the Task below and the Input given to write the Response, which is a programming code that can solve the Task.### Task:Optimize a code snippet written in Python. The code snippet should create a list of numbers from 0 to 10 that are divisible by 2.### Input:arr = []for i in range(10):if i % 2 == 0:arr.append(i)### Response:Generated instruction:arr = [i for i in range(10) if i % 2 == 0]Ground truth:arr = [i for i in range(11) if i % 2 == 0]
看样子还是很不错的
总结
以上就是我们微调llama2的完整过程,这里面的一个最重要的步骤其实是提示的生成,一个好的提示对于模型的性能也是非常有帮助的。
[1] Llama-2 paper https://arxiv.org/pdf/2307.09288.pdf
[2] python code dataset http://sahil2801/code_instructions_120k
[3] 本文使用的数据集 https://huggingface.co/datasets/iamtarun/python_code_instructions_18k_alpaca
[4] LoRA: Low-Rank Adaptation of Large Language Models. arXiv:2106.09685
[5]. QLoRa: Efficient Finetuning of QuantizedLLMs arXiv:2305.14314
https://avoid.overfit.cn/post/9794c9eef1df4e55adf514b3d727ee3b
作者:Eduardo Muñoz