七月在线公开课笔记(二十七)
人工智能—机器学习公开课(七月在线出品) - P25:【公开课】数据挖掘与机器学习基础 - 七月在线-julyedu - BV1W5411n7fg
可以是吧?好,那么我们稍等一下啊,稍等一下我们。在8点钟我们就准时开始我们的一个直播的内容。对。那么各位同学之前有过这个积极学习和深度学习相关的一个经验吗?也可以在我们的一个评论区告诉我。对。
医学生完全没有啊,现在嗯现在其实医学的其实也有做数据科学相关的。我分享一个经历啊,就是我在嗯20119年的时候参加了一场呃,就是一个就是也是嗯中国某一个医学会吧所组组组织的一个研讨会。
然后他们线下有一个workshop。workshop呢嗯要我们去挖掘,就是说利用斯坦福的一个医学院的一个数据集,然后去挖掘一些。就是说肺肺部的一些数,就是说病人肺部的一些数据。
然后当时我就跟就是我我是完全是没有医学背景的。当时就跟现场的一个医生嗯也是一个主治医师,然后现场就他出他说想法,我们就就我写代码,就现场做嗯感觉其实收获蛮大的。
但就是说其实那嗯医医学其实也是如果你想发论文的话,或者说想做科学研究的话,其实嗯python还是非常建议学的。因为。现在很多的一些论文里面,他所绘制的一些图啊。一些处理的一些方法,以及这个建模方法。
其实python都是比较适合的。现在有很多一些相关的一些论文,都是啊就是说用一些机器学习的方,用一些机器学习的算法来进行建模的对,其实这个肯定是对你的一个后续的一个发展肯定是有帮助的对。
当然这个交叉的就是两者交叉的一个就是呃非常非常好啊,这种复合型人才。对。当时呃当时我们我去去学,就是说参加活动的时候,那医师就是那主治医生就说,现在就是说嗯很多的学生他学有自己的专业。
就是他学到这个什么地质啊、物理啊、数学啊,他又想就是说做一个实践。因为现在。你假如说去写一篇论文,我不管是写什么论文,都是要画图画表嘛。但是啊你如果不写代码的话,其实现在你不会写代码的话。
其实你现在很难做出相关的一些工作。对。就想学这个,你可以学一下python,就基本上再学一下基础这些。pennda啊基本上的功能其实是能够能够就是说呃就是说相当于是呃能够掌握的对。
数学专业和这个相关嘛啊,数学其实是呃有一定的一个关系的,数学是有一定的关系的。对。数学是有一定的关系的,因为很多的一些。数据挖掘的算法,其实它内在都是一些具体的一些。嗯,不管是由数学公式啊以及。
有我们的一个就是内在的一个基层原理,其实跟数学肯定相相关的。但是呃就是说他可能更加关注于如何进行实践。对,嗯,我们待会儿呢也会给大家讲一讲这些实践的一个过程。你听了之后。
你就可以知道就是它跟数学有什么具体的一些区别。嗯,有同学说他现在在用R都是别人写好的包,自己不会写分析的代码。嗯,说实话吧。嗯,R呢它跟python其实是比较类似的。呃,我我个人我之前也学过R。
然后嗯我感觉R是比较偏向于数,就是说数学专业的。而是比较偏向于数学的。那么就是他不太适合这种是呃,就是他不太适合这种。只是只能适合这种基础的技忆学习。那深度学习呢它就不够。
然后python呢可能就更加多面一些,它可能是能够用在软件开发。然后也可以用在这种数据科学的里域。对,其实它的一个你就是说它的生态可能会更大一些。然后R呢,它比较适合单击,或者说我一个实验室。
就是说几个人协作用R比较好,但是大规模的情况下,R它没有。就是说如果是几十个人,上百个人,可能R语言就不太适合。做啊用R原,它的性能肯定会差一。对。然后如果想要做自己写一些数据分析的话。
其实R和pyython都行。R和pyython其实都行,就是说基本上都是比较简单的都比较简单。对。好,呃,各位同学大家晚上好,我是咱家刘老师。
然后我们今天呢是我们的一步社区和企业在线联合举办的两天入门数据挖掘和记忆学习的第一天。然后呢,我们在这两天的一个学习的过程中呢,希望我们是能够给大家带来一些就是说新的知识。
也希望我们在这个学习的过程中呢,以及我们的学习的内容,就是说教给大家一些新的一些技能。那么我们今天的一个直播呢,就是分主要是讲我们第一天的一个课程内容。我们首先呢来看一看我们两天这个课程到底在讲什么。
以及我们大家能够学到什么。我们这两天的一个课程呢整体而言是偏向于小白的,或者说是入门的同学。嗯,我们这两节课呢基本上是包含了pandas的一个基础,机器学习的一个基础以及机器学习的案例的一个基础的讲解。
就是说如果你之前没有学习过嗯数据挖掘,没有学习过机器学习,也不用担心,因为我们尽可能的用一些简单的案例给你讲清楚。第第二个特点呢就是我们这个课程呢整体是比较完备的内容。我们会给大家讲一些具体的一些算法。
也会讲一讲它的一个具体的入门的一些知识点。第三个呢就是我们在每每节课的一个时间的过程中呢,我们会给大家讲一讲这个具体的一些案例,也会有代码的一个演示的环节。就是我们从头运行这个代码。
然后也有python的这个相关的一个代码的演示啊。如果各位同学有什么问题呢,也可以直接提出来。就是我们两天的一个课程的一个整体的一个介绍。然后呢,在我们的一个第一天呢。
我们主要是给大家讲解一下我们这些知识点。那首先呢我们会讲讲如何使用工具pandas来完成一个数据集的一个处理。然后呢,我们会给大家介绍一下我们的数据挖掘和机器学习的整体的一个流程。然后呢。
我们也会给各位同学介绍一下常见的机器学习模型。然后我们有一个具体的一个时间的案例。嗯,这个我们在第一天的一个主要的内容呢就是如何使用这个penas读取我们的数据,并处理我们的结构化的数据。
这是第一个要点。嗯,paas呢我们待会儿会给大家讲啊,其实也是在python环境下非常非常。就是说建议大家掌握的优个库。嗯,第二个要点呢就是我们的一个数据挖掘和机器学习的整体的流程和步骤。
也就是当你遇到了一个问题之后,我们如何去一步一步解决它。第三个呢就是我们是如何去选择机器学习的模型。对,这个可能会更加难一点啊。那么这三个内容是,我想让大家就是希望大家在听完我们第一节第一天的课程之后。
能够掌握的。那么这个第一天的课程要点在于你能够知道如何处理数据选择模型并进行建模。第二天呢我们会更加深入一点,我们会讲解特征的编码方法,数据的预处理方法,以及集成学习以及数模型。
然后在第二天的课程内容呢,我们会主要会讲解我们的类别特征和数值特征的具体编码方法,以及我们的输出以及输入如何进行一个预处理,以及我们的数模型和集成学习的关系。
在第二天的一个课程要点是希望各位同学能够知道我们如何对数据集进行处理,然后我们才能获得一个比较好的一个精度。好,这是我们两天的课程的一个整体的介绍啊,各位同学可以呃就是说看一看。
或者说截图看一看我们的具体的一个课程的一个特点以及他的一个知识点的安排。那么我们接下来呢就开始我们第一天的一个课程内容。第一天的课程内容。第一天呢我们主要会讲解什么呢?
就是会讲解开始从pinnda讲起好,开始从pinnda讲起。呃,首先呢我们很多同学他其实之前就呃学过一些编程语言,对吧?学过pyython,或者说谢大家或者说R。甚至你可能学过这个go啊等等的,或者C。
其实我们现实生活中呢,其实有很多的一些编程语言。嗯,对吧?嗯,我之前在本科的一个学习的时候,也最开始也是从C开始学起,对吧?嗯,但是呢可能在学的后后续呢可能接触的语言越来越多。呃。
我也会有个人的一个就是说积累,以及在遇到一个问题的时候,我也会去嗯思考我到底用哪一种语言去解决一个问题。在我们现在呢这个数据挖掘和数据科学的一个领域。或者说我们现在假如说你想要使用机极学习的模型。
深度学习的模型,想要做数据的可视化,数据可视化。那么python可能是比较适合你的一个语言编程语言。也就是如果你遇到一个场景是需要做一个这种数据挖掘,或者说数据分析以及建模的这个场景下面。
那么python可能是一个比较适合的语言。那么在python环境下呢,其实我们在课前也给大家举了一个例子。python呢它跟R相比,它的主要的区别在什么呢?python一方面它是一个完备的编程语言。
它是完备的编程语言,它有支持这种函数式编程,也是支持面向对象的。其次呢,python它有非常强大的一些第三方的库。这是什么意思呢?呃,我们在学习这个呃就是说C议元的时候,其实我们在学习CE员的时候。
我们有一些作业就是说读写文件,读文件,对吧?读取文件。那么这个读取文件其实在C语言里面,我们其实是需要很写手写很多的代码,很多行的代码来完整。但是呢在pyython里面。我们假如说用第三方的库。
那么假如说我们用padas,那么可能就需要只需要一行代码就可以完成。因为它的一些其他的一些库文,其他的一些代码都在我们panda里面帮我们写好了。
所以说呢python它它的一个强大的处是在于它有很多的一些第三方的库,它的生态是比较好的啊。第三方的一个库的一个生态是非常好的。你肯定是能够找到完成就是你所需要的库。
那么在我们学习这个数据挖掘和继器学习,以及学习我们的一个嗯数据可视化的一个基础是掌握pindas在pyython环境下,pinnda你是必须要掌握的。panda嗯它。
和和R语言的这个data table其实是非常相似的啊。那么pennda呢它是在python环境下的一个数据分析和数据统计的一个库。它提供了我们快速对数据集进行处理的一个工具。
而且呢也提供了快速的对我们的数据集进行处理的一些方法。呃,我们这个地方呢就是pandaas,它非常适合用来处理结构化的数据。结构化数据结构化结构化数据就是我们的一个数据集长的类似于这种形式。他是由行。
这是行。和和我们的列。所组成的二维的表格,也就是行和列啊,就是说我们这个其实跟我们的一个一excel这种单元格表格其实是一模一样的。但是呢pinas其实它在操作的时候呢,我们是用代码进行操作的。
在pas里面呢,我们有行有列,对吧?那么我们行和列的交叉之处,就是我们的一个取值。在paus里面呢,它的一个可以。帮我们处理就是说几百万行仅一行,就是说很大的表格我们都可以处理。
它比这个excel的一个就是说性能以及它的一些所完成的功能都强大很多。那么pinnda呢也是我们现在排thon单机数据挖掘必备的库,它可以支持我们就是说快速的加载数据,快速的索引数据。
以及快速的对我们的数据集做一个转换。嗯,这个都是pinnda它所具备的功能。那么在pandas里面呢,其实它可以帮我们完成很多的功能啊。首先的呢我们需要知道一些具体的一些这种英文单词。
我们的calon names就是说我们的列明index就是我们的索引,对吧?index索引,然后呢,我们的一个行列的交叉,就是我们的具体的取值,对吧?那么在这个地方。
我们还有一些missing value,就是我们这个地方的NAN。N就是它是一个missing value,或者说是一个缺失值。那么我们有原始的数据集里面有这种字符串类型的,有缺失值的,有数值类型的。
还有我们的这种可能还有一些其他类型的对吧?所以说呢嗯如果你之后遇到一个场景,假如说想要对这种表格类型的数据做一个处理,那么penus可能是你第一的选择。那么我们就继续。呃。
那么我们接下来呢就看一看我们这个就是说使用paus如何进行使用啊。对,然后这个地方呢我们就直接给大家稍微看一些代码,然后给大家演示一下啊。因为呃我觉得这个讲起来可能概念可能会比较空虚啊。
但是呢我们如果看这个代码会更加直观一点。呃,这个地方呢我们假设想要对我们的数据集做一个处理,就是说我们现在拿到一个数据集,这个数据集呢长得这样的。我们有。一列、两列、三列、四列、五列、六列。然后呢。
我们这是我们的列名,这是我们的列名。然后呢,我们在数据集里面,这是一行每每一列它是用逗号进行分隔的,用逗号进行分隔的。现在呢我需要各位同学完成的一个任务是什么呢?我现在需要你对我们的这个数据集的。
进行读取。也就是说我们的H这一列就是32、22、32、27。好,现在需要你这样完成一个就是给另一个TXC的情况下,需要你完成一个数据集的读取,把它读取成表格的形式。好,那么拿到这样一个问题之后呢。
可能你如果都知道pada。的情况下你怎么怎么做呢?可能我们就要手写一个这种处理的一个过程。怎么手写呢?我们就需要读取我们的文件,对吧?读取我们的文件,然后呢对我们的文件的内容进行一个处理。
比如说对于我们这文件内容,我们把它按照我们的逗号进行一个分隔。把它进行逗号进行分隔,对吧?然后我们这个地方我们可以看一看啊,我们定义其实这个地方我们是定义了一个class啊。
在这个class里面呢传入我们的文件名,以它就可以完成个处理。这个地方我们可以就是说。手动实现一些函数。比如说这个地方的,get item函数,就是用我们的一个中括号去索引我们的一个数据。
我们的head函数就是看我们的所数据的前十行。对吧这个地方其实是我们手写的一个对于数据集的一个处理的一个class。那么嗯有同学也会看到。
就是说其实这个class已经是能够完成基础的一个结构化的数据集的读取。但是呢它并不是我们想要的。因为我假如说想要再新增加一个功能,那么我们就需要重新再实现这个。就是说具体的实现,对吧?
那么这个其实是非常繁琐的。那么有没有其他的一些替代品呢?那么就是padaspadas呢其实就是在python环境下的一个第三方库。我们在安装好pandas之后呢,import pendas SPD。
然后pandas呢,它就可以很快速的从我们的一个数据集里面创建一个序列。这个序列就是我们的一列。一列。当然pins它还有一个优点,就是说不仅仅是可以创建一个序列,它可以创建以我们字符串或者说日期一个序。
就是说它这个周期的一个。比如说这个地方我们是传入20130101,就是说想要得到以2013年1月1号开始的6天的一个时间。这就是我们就是说使用padas的一个函数,就可以很快速的完成。当然。
如果我们想要创建一个表格,就更加简单了。在这个地方,我们是可以从我们的一个dict,就是python的一个dict啊,python的一个dict来创建我们的一个表格。在这个地方。
我们在这个dict里面呢,我们传入三列三列,然后每列我们的取值,对吧?AAAA列的取值是4567。对这是我们传入的一个dic,传入到我们的data frame里面。
然后它就返回的是一个data frame的一个对象。这是我们创建的一个表格啊,这个是我们创建的表格。然后呢,左边的这个是我们的index,我们的最上面的一行就是说最上面的一行呢是我们列明。
最上面的一行是我们列名。然后呢,我们这个地方我们创建了这个dataframe之后呢。我们还可以很方便对它进行赋值。比如说我这个地方想要选择我们的1个AA列大于5的行,把它的1个BBBB列复制为负一。
怎么赋值呢?我们的原始的一个。这个地方就是选择了某一列。某一列,然后呢,这个地方其实它是做了一个逻辑的一个计算。逻辑计算就是说整体的这一列是不是大于等于5,对吧?这个四肯定没有大于等于5,它是fse。
这个地方返回为t true true,对吧?也就是说它选中了我们的一个第二行,第三行,第四行。对吧然后呢把它对应的BBB列复制为负一对吧?也就是说这三行的一个这三个取值复制为-一。对吧这个就很明显的。
而且是很方便的,就可以做一个复值。那么如果各位同学之前学过这个矩阵的呢,就这个地方就很简单。因为这个地方其实本质就是。行索引列索引对吧?其实就是矩阵的一个索引。当然这个地方我们在进行嗯具体的赋值的时候。
我们也可以传入多列,传入多列。比如说这个地方的三行,它的B于B列以及CCCC列整体的一个取值做一个复值。好的,那么pas呢,其实这里面的一些函数啊,我感觉是需要各位同学去做一个练习的。
而且呢这个如果你掌握的越好啊,可能对你后续的一个呃就是说数据的处理啊,以及这个相关的一些画图的一些操作啊,就会更加的方便。嗯,我们就是先往后翻啊。在pens里面呢。
其实它可以很方便的完成一些统计的一个操作啊。比如。呃,我们这个地方我们定义了一个data frame。这个data frame呢就是我们的animal age嗯vis priority这4例。
那么在这四列里面呢,假如说我们这个地方很就是说对我们的表格,其实有些时候呢就需要做一个分组的一个聚合。比如说我们统计一下我们的animal列下面哦animal列分组下面的A的一个平均值。这是什么意思呢?
也就是说我们把这个animal把它分成不同的组,对吧?cat分为cat取值为cat的一行,划分为一组,取值为snack的一行划分为几,取值为dog地方啊划分为一组,然后取把它划分成不同的组之后。
然后再去统计它的一个A的一个平均值。这个地方其实你可以看一下这个它就是group by,就是做一个分组。这个地方我们把分组之后的一个行给它打印出来。把它分成catch这一组的,就是我们这些四行。
相当于四行,对吧?它的animal都是取值为我们的catch,然后这是我们的dog,这是我们sack,然后呢,我们就是把它分完组之后,然后统计一下它A级的一个命,对吧?
比如说这个地方我们的一个具体的一个操作呢,你都可以按照我们这个地方来算一算啊,比如说这个地方我们的snack这一这一分组,它的A级,这个地方应该是0。5加上4。5除以2,对吧?就这2。5。
那么这样一个分组聚合能够做什么呢?它其实能够做很多的一些操作。嗯,比如我们拿到了一个学生或者说这个班级的一个信息成绩表。然后呢,我们有班级信息,以及有不同班级的学生的信息。
然后我们通过这个group操作,就可以统计每个班级的一个某个列的一个平均值,或者是说每个班级的一个。的一个最大值对吧?我们每个班级的一个语文分的一个平均分。
语文分的一个最大分以及语文分的最小分都可以通过类似的一个操作来完成。好,那么在pindas里面呢,其实它有很多的一些呃统计啊以及相关的一些操作啊。嗯,这个地方呢我们就不做过多的介绍。
因为这个可能就是呃大家需要下去掌握的。因为这是非常基础的。我们只是给大家讲一个它的一个基础的操作,然后呢如果你学完pindas之后呢,你也可以去看一看。
在pyython下面呢有个叫做mat plotlib的这个库,其实也是需要各位掌握的啊。就是我们借助于m plot能够绘制出很漂亮的一些图形,或者说这种曲线。
这些曲线呢其实不管我们在工作或者说这种上学的过程中啊,写论文的过程中,都是可以很好的来进行完成的。比如说这个地方我们需要绘制一个s的一个函数的一个曲线,然后把它对应的一个取值,这个地方绘制成圆圈,对吧?
或者说我们绘制成散点图,或者说绘制成饼图,然后画成不同的颜色等等。好,这些呢都是在python的一个就是说这种呃编程环境啊,以及相关的库啊都是可以进行实现的。好的,嗯。
这个代码呢大家也可以就是说在加到我们社群之后呢,也可以领取到啊,你不用担心好。刚才呢就是给了各位同学看了一下我们具体的一个penndas呢能够做什么。那么我们在做一个具体的一个数据挖掘的时候呢。
其实第一步是需要读取我们的数据,并使用panda这些软件来完成我们的一个具体的一个数据集的一个分析和它的一个统计。那么我们第二步呢就是需要用一些具体的一些方法去挖掘出我们数据集。
以及我们的一个具体的一个数据中是不是存在某种具体的一个信息。嗯,这个地方呢就给大家介绍一下这个机器学习和我们的一个呃深就是说这种数据挖掘。我们来看一看。
我们的一个具体的一个具体的一个数据挖掘到底的概念是什么呢?嗯,数据挖掘它其实是使用我们的机忆学习和统计以及数据库的一个方法来完成对数据集中挖掘模式和知识的这个过程。呃,数据挖掘呢。
其实它的一个英文名字叫datamin。它其实有点像这种旷工的一个意思,对吧?就是挖掘我们的数据集的一个la似的含义。呃,数据挖掘呢它并不是它并没有指定任意一种机器解决算法。
它指的是具体我们这个整个流程是什么?那么怎么是机器学习呢?机器学习它是更加具体的一个就是说一个概念,它是人工智能的一个分支。然后它是本质上就是说遇到一个问题,我们如何去进行建模,然后解决这个问题。
所以说呢你可以看到这个数据挖掘,它是使用机器学习来完成某个任务的对吧?所以说呢数据挖掘它更数据挖掘它更加关注于这整个流程。机器学习呢更加关注于某个模型。好,这一点呢大家也可以记一下,也是非常非常重要的。
然后呢,我们也可以看从右边这个图可以看出来,就是我们现在的一个数据挖掘机器学习以及我们的人工智能,它各自的一个这个就是说知识点的一个交叉啊,都是现在的一个就是说这种嗯前沿的。
或者说这种数据科学的一个概念呢,都是非常非常联系,非常非常紧密的啊。不管是这种数据库啊,数据挖掘,还是我们的一个统计学。那么数据挖掘它到底能够做什么呢?这个可能有很多同学他之前是第一次接触到这个。
我们就给大家介绍一下数据挖掘到底能够做什么。数据挖掘呢其实它涉及到的一些步骤呢其实非常多。它涉及到数据的一个读取,数据的一个预处理,数据的一个模型的一个训练,以及数据模型的推断。
以及我们的一个具体的一些可视化的操作。然后呢,数据挖掘具体的一些任务呢可以分为以下几类。比如我们的异常检测、关联分析、剧类分类和回归。呃,这个呢可能就比较。就是说讲的比较细了。
它就是一个具体的一个领域问题领域问题。比如我们现在在百度上面,假如你想要学习。这种异常检测的算法对吧?那那么你就可以直接搜异常检测,那么就可以找到很多的机器学习的算法。然后我们想要完成一个分类的一任务。
对吧?然后你搜一个分类的一个机器学习的模型,你可以找到在这个地方呢,我们。列举了这么多任务,是希希望各位同学知道一个点,就在于我们这不同的任务它所完成的一个。就是说结果是不一样的。呃。
我们现在的一个机器学习模型,其实本质仍然是一个基于这种函数式的这种表达。或者说把可以把它抽象为这种函数式的表达。也就是我们输入一个有的输入的之后,我们通过一个建模得到一个具体的一个输出。
这个呢可能不是一个函数,我们可能是一个模型,或者说是一个流水线,也就是一套操作。它通过输入一个数据,然后得到我们的最终的输出。那么我们的一个输入这个X我们。你把它叫做一个input,对吧?我们的Y呢。
我们把它叫做一个output。那么这个地方的湿度和输出不同的情况下,我们得到的一个。就是说如果我们输入和输出不同,那么我们这个问题它可能就不一样了,对吧?那么我们这个地方异常检测啊。
关联分析啊、聚类啊、分类啊回归啊,它各自完成的一个功能是不一样的。嗯,比较典型的就是它的一个Y,我们最终的一个输出结果是不一样。呃,举举个例子啊,就是聚类聚类到底在做什么呢?
剧类就是说我们将这些相似的一个模型,相似的样本,我们需要把它划分成一类一类的。我举一个非常简单的一个例子。假如我们现在有两个维度啊,每个样本有两个维度,X1X2。然后呢,我们可以把它画成一个三点图。
换成散点图啊,我们把所有的样本把它进行一个可视化。好,做完可视可视化之后呢,其实我们很清楚的可以看到,在我们的数据集里面,其实。隐隐约约的有两个相当于是这个数据集呢有两个相当于是两个这种两团数据。
或者说两处数据所组成,对吧?剧类呢就是说我们把这个距离相近的一些样本把它据为一类。对吧相当于是我们把数据集的一个内在的一个分布的规律能够找出来。对吧,这个就是聚类。那么剧类呢其实它是没有用到标签的。
那么我们的如果想要用标签来进行建模的,就是我们的一个分类,或者说我们的回归。分类呢就是我们的一个标签呢,它是我们的类别类型的。类别类型的,也就是。如果我们想要就是说根据一个用户的一个。
或者说根据一个病人他的1个肺部的这种CT图,来去判断一下他是不是有疾病,对吧?那么这个地方我们的一个输入什么,我们的CT图。对吧然后输出的是什么?输出就是说它是yes or low,对吧?啊。
有没有疾病?这个地方其实就是一个二分类。因为我们这个地方有两个类别。有两个类别。好,那么我们如果是回归呢,回归就是举个例子。我么现在呢。需要对一个房屋的一个价格做一个预测。也就是说我们输入。
我们的一个具体的一个房房屋的一个基础信息。对吧我们输出的是一个priice。f呢这个地方。回归呢它的输出的结果就是我们的一个这个呃数值,它不是一个具体的一个类别的,它是一个数值。所以说分类和回归呢。
你可以从我们的一个标签的一个角度去看一看,那到底是一个我们的一个类别类型的,还是我们的一个数字类型。好,我们继续。那么我们在做一个具体一个数据挖掘的时候,其实本质需要做什么呢?
我们需要做的一个操作就是我们。将我们的一个具体的一个。这个任务不断的进行一个拆解,然后分期也能做到分期是什么。我们用理解分期是什么?对,蚂蚁花呗的分期吗?
然后呢我们这个地方的一个具体的一个嗯数据挖掘和机器学习的在学习的时候呢,其实也要学习到的它具体的一个建模的步骤。这个步骤呢就是我们如何一步一步的去完成我们的一个就拿到一个任务之后。
拿到怎么一步一步来进行建模。首先呢我们可能需要对我们的数据集做一个预处理。然后呢对我们的一个特征做一个编码,然后做一个特征工程,然后完成我们的一个模型的训练验证,然后使用我们的常见的机器模型进行建模。
然后最终对我们的一个模型的预测结果进行评价。或者说对我们的一个模型的一个结果进行一个误差的一个分析。好,嗯,这是我们的一个就是呃这就是说具体的一个建模的步骤啊。那么我们在学习的时候,不管你是做科研。
或者说做一个具体的建模,可能都是按照这个步骤来做的对吧?写论文本来就是对吧?我们有一个实验的数据,然后通过实验的数据做一个建模,然后得到一个结果。结果我们需要对它进行分析,以及对它进行评价,对吧。
那么我们接下来呢,我们就看一看在机器学习里面有到底有哪些具体的一些机器学习的模型啊,我们来看一看。嗯,首先呢我们来看一看这个线性模型。信性模型呢其实它是在我们的这个机忆学习里面是最简单的一类。
信息模型呢在我们就是说在我们的一个初中的里面,就初中的一个时候就学到了,对吧?我们对我们的一个。有一条这种取这种直线,对吧?这个直线呢由AX加B或者说KX加B,对吧?来组成。就是说有两个具体的一个参数。
那么这个线性模型,它其实本质它在做什么呢?就是说我们使用一个线性的一个关系去理合我们的一个输入和输出,我们在这个初中的一个学的时候呢,对吧?这个地方中AX加B或者KX加比其实都一样啊,或者是WX加比。
这个只是一个代号。我们在初中或者说我们的一个高中学习的时候,其实我们只有X和Y就是一个取值。就是一个曲值,对吧?那么在我们具体的建模的时候,其实。有可能不是这样的。有可能我们的一个X,它是一个向量。
什么意思呢?我们这个地方的X呢是一个。二维的一个输入。二位的一个输入。那么我们的Y呢仍然是一个一维的输出。意味的一个输出。这个地方呢我们想举个例子啊,举个例子就是我们根据我们的一个。嗯。
他这个房屋的一个面积。和楼层。去预测它的价格。对吧或者说这个租房的价格对吧?房问的面积和楼层去预预测它对租房的价格。那么在这个地方,其实我们的一个AX。它是由两个维度所组成的两个维度所组成的。
所以说这个地方我们在进行建模的时候,就不不能是单纯的一个就是说一个面积乘以A再上上B,对吧?等于我们的价格,这样呢就会丢失掉很多信息。我们这个地方的一个输入的一个X,就是一个二维的,是一个二维的。
所以我们在进行一个具体的一个礼合的过程中呢,我们的X可能是一个多维的。X可能是一个多维的一个输入。这个地方我们举的一个非常简单的例子,是一个二维的,它可能是2100甚至1万,这都有可能。
那么我们的这个具体的一个线性模型呢,就是说我们使用这种线性的关系去理和我们最终的一个输出。比如说这个地方我们得到的这个价格和面积和楼层的关系是什么。我们的这个价格。等于我们的面积。
乘以10加上我们的一个楼层。乘以5,再加上10,这是我们最终的一个。相相当于是一个线性回归。当然我们这个地方其实是举了一个非常简单的一个例子啊,它是一个。相当于是输入的一个X是两个维度的,是两个维度的。
这个地方我们其实本质是在做一个回归的问题。因为我们的价格其实它是一个数值类型的,是一个数值类型的。它其实是用一个线性的一个关系去理合我们的这个面积、楼层和我们的价格。一个同学说到了逻辑逻逻辑回归,对吧?
逻辑回归其实也是我们一种线性模型。嗯,这个这个地方呢就是说我们在进行一个礼合的时候呢,我们其实本质。这个如果我们的一个X是就是说多维的时候,我们这个地方的一个A或者我们W也是多维的对吧?
这个地方为了它让它进行一个进行一个向量的相沉,我们让它进行转制。我们这个地方其实本质哎X是多维的。W是多维的,然后呢,这个地方我们可以让它做一个回归的任务。对吧当然也可以让他做一个分分类的任务。
这个地方呢如果我们想要让他做一个分类的任务呢,我们常见的一个做法就是我们对它的一个。进行。分类的任务的时候呢,我们对它的一个概率进行一个回归,对吧?
这个地方我们就可能涉及到我们的将我们的一个具体的一个礼盒的函数呢,把它加入我们的一个这种就是呃广义线性模型的这种转化。然后可以得到我们逻辑回归的公式。对,如果你感兴趣的呢。
也可以在我们的这个相关的教材里面找到。第二类模型呢就是我们的BS模型。BS模型呢,其实在我们的一个嗯这个呃高中数学,或者说我们大学数学里面有讲到。
就是我们通过这个先验概率和后验概率来计合计算得到我们的一个这种事件的一个联合的一个分布,然后再去求解我们的一个具体的一个概率值。这个地方呢就是会有一个嗯就是说我们一些相关的一些计算啊。
我们对贝列斯呢其实在进行一个计算的时候,其实它本质上就是利用我们的一个类别的就是说这种先应的概率,以及我们的条件的概率来进行一个求解,然后进行转化。这个转化的过程,其实就是这种条件概率公式啊。
那么这个贝模型呢,其实它本质在做什么呢?它就是在做一个计算得到一个联合的一个概率的分布,然后再去求解得到我们的一个某个条件发生的情况下,我们对应的一个就是说概率值是多少。
这个地方我们就是以这个X作为我们的输入。C呢作为我们的一个类别的输出,对吧?我们给定一个。X输入的情况下,我们的一个对应的一个类别输出是多少,对吧?
所以说这个地方我们也是通可以通过这种BS的这种建模来得到我们的一个具体的一个啊分类的任务的。好,这个呢BS模型呢其实也在我们的一些机济学的教材里面也有讲到。第三类呢就是我们的这个决策树模型。树模型。
树模型呢其实呃这个可能会更加直观一点。我们的一个人的一个决策的过程呢,其实就是嗯基于这个就是这个决策的一个过程啊,就是说一个逻辑,就是呃我们看一看这个假设我们想要做一个决策。
这个决策呢就是嗯我们判断一下,明天要不要去呃出去玩,对吧?想想不想出去玩,对吧?那么我们就做这样一个决策,明天我们有没有工作要做,对吧?如果有工作要做,我们就待在家里面,如果没有工作要做。
那么我们就看一看我们的一个外面的天气,我们天气如果是比较晴朗,对吧?那么我们可以去海边,如果是下雨,对吧?如果是下雨的情况下,那么我们看一看朋友忙不忙,对吧?如果朋友很忙,那么我们就待在家。
如果朋友不忙,我们就去一起去看电影,对吧?那么这个地方其实它这个地方。其实是一个树是一个树,每个树呢我们有这个叶子节点,对吧?y子节点就是它没有再进行划分的这个节点,也有我们的非叶子节点。
或者说我们的分裂节点。那么我们的一个具体的决策过程呢,人人的一个逻辑的决策其实跟我们的这个呃数目性的一个决策过程,其实本质是一样的。在我们的一个分裂节点的过程中呢,我们需要有一个逻辑进行判断。
有一个条件做一个判断啊。如果满足我们的条件执行某个分支,如果不满足我们的条件,执行另一个分支。然后呢,我们在进行不断进行分裂的时候,到我们的一个叶子节点,它不可再分的时候。
这个不可再分的时候就是我们最终的一个输出结果。也就是说,如果我们满足某条路径,对吧?满足我们的明天有工明明天没有工作,但是呢明天天气很好,对吧?它按照某种路径就可以得到我们最终的一个输出结果。
这个呢就是我们的决策术,它的一个具体的原理。它本质呢就是对我们的一个原始的一个属性空间进行一个分裂,然后完成一个决策的过程。嗯。
那么你也可以去在我们的积极学习的一些教材和相关的一些课程里面找到这个决策数的一个基础。对,那么我们前面所讲的讲解到的这个呃这个我们的一个线性模型啊,BS模型啊,以及我们的一个决策术模型啊。
其实在我们的日常生活中啊,都是呃非常非常常见的。而且不管你是不是学习这个机忆学习,或者说是不是学习计算机的同学掌握了这些机忆学习的模型啊,其实对你的一个工作啊,其实都是非常非常有帮助的。嗯。
第四类呢就是我们的SVM我们SVM呢其实它可能会更加嗯就是说难以理解一点。它其实本质呢在我们的一个角色的过程中呢,我们不仅仅是想要对我们的一个样本把它做一个。
分类我们可能是想要找到一个最大间隔的一个角色平面。嗯,假如说我们想要对我们的这两类点做一个分类,那么我们怎么分呢?我们可能是用一条直线把它进行分隔开。但是呢这条直线其实我们可以画很多条。
对吧我们可以这样画我们可以这样画,其实都是能够满足我们的把这两类点把它分开的。但是有没有一条完美的直线,或者说相当于是一条比较符合我们逻辑的直线呢?这个比较符合逻辑的直线,就是相当于是尽可能的。
位于我们的一个决策,相当于是它离我们的两类样本都很远,对吧?相当于是在这个决策平面的正中间,角策的这个最中间相当于是最公平的一种情况。那么这个SVM呢,就是说我们在找这个决策平面的时候。
或者是找这条直线的时候,能不能保证它离我们的两类样本。都很远。那么这个地方其实就是有一个先验知识。如果我们这条直线现在离两类样本都很远,那么在未来在我们的测试级的一个具体的一个。嗯,卡了吗?好。
应该没卡吧没卡吧。对。这个地方呢就是说如果我们现在的这条线呢能够将我们的这两类样本能够区分的很好,而且呢在这个决策的最正中间,那么在未来在我们的一个测试级的一个具体的一个分类的过程中呢。
它也是能够最公平的。这个就是SVM的一个具体的一个思路啊,它是能够找到我们的一个决策平面,能够找到这个具体的一个直线,能够和我们的这两类样本,将就是说分相当于是能够找到了一个最大的一个决策的间隔。好。
那么各位同学也可以在我们的一个GP的教材里面,找到SVM相关的一些原理。好,最后一类呢就是我们深度学习的模型,也就是我们现在比较火热的对吧?火热的这种深度学习的模型。
深度学习的模型呢和我们前面所讲解的这些模型有什么区别呢?深度学习的模型,其实它本质是利用这种神经元来代表我们的计算的流程。然后呢,通过这种神经元的一个边的连接来完成具体的一个计算的过程。呃。
这个呢可能和我们的这个神经网络或者深度学习啊,它跟我们人的大脑这种其实是非常相似的。我们人的大脑呢就是有这种相当于是由这个。细胞与细胞之间有一个相互的连接,对吧?
这个细胞的一个具体的信号传输给下一个细胞,或者说突触啊,那么经经过这个细这个突触呢,或者说这个细胞在。在接收到前面的一个信号之后,完成一个处理,然后得到它的一个输出。嗯。
那么这个深度学习其实整体的一个具体的一个这个流程啊,其实跟这个操作,或者说我们的人的这个神经元的一个这种细胞的一个就是说这种这种连接或者计算的操作,其实是非常非常相似啊。
也就是说我们大脑的这个呃内部的一个结构,其实是有参考的。那么我们的深度学习呢就是由多层。所构成的一个神经网络,它是一般情况下是由我们的输入层、隐含层和我们的输入层由着不同的层所构成的。
那么这个地方呢就是我们其实给大家介绍了一些具体的一些机器学习的模型。那么我们在学习这个数据挖解和机器学习的时候,其实本质就在学习我们每类机器学习的算法,它的原理以及它的一些应用案例以及它的一个优缺点。
对,这个就是我们这个如果你想要深入学习数据挖掘和机器学习,那么你就可以从这个角度去学习。比如说线性模型它的原理是什么?线性模型它能够做什么,它适合做什么?它相比于我们的SVM它的优点在于什么?
它的缺点是什么?对,都可以从这个角度去进行学习。好,那么我们接下来呢就看一看我们如何使用这些具体的一些机器学习的算法来解决我们具体的一个案例啊。这个地方。
我们就读嗯就是说仍然是结合padas来完成我们的一个建模。结合我们的一个pas完成我们的建模。我们首先呢读取我们的一个嗯数据集。数据集呢我们是用padas来完成读取的啊。如果各位同学呃在本地没有。
就是说没有配配置好这个pyython环境的啊,也可以自己尝试在呃本地的一个机器呢安装一下这个python的一个环境。然后把这个pandas也安装好。然后我们假如说想要对我们的数据集做一个处理呢,其实。
嗯,非常建议对它进行一个可视化的一个相关的一个处理啊。嗯这个可视化的相关的处理呢,这个地方其实这个案例呢其实是做一个嗯泰坦尼克号的一个呃幸存者,啊,就是说乘客幸存的一个预测。
就是说我们这个就是泰坦尼克号原始就是泰坦尼克这个游轮,它有这个乘客的一些信息。然后它是不是幸存的一个具体的一个标签,对吧?然后呢,我们就基于这个具体的一个信息呢预测一下它具体的一个是不是幸存下来。
那么我们如果拿到这个数据集之后,我们可以做什么呢?我们可以做很多事情。嗯,有同学说这个note book可以分享吗?你可以待会儿加一下我们的一个课程群,我们会在我们的一个课程群里面。
然后嗯会给大家进行一个发放啊。对,可以加一下我们的课程群。然后呢,我们在做一个数据分析的时候,其实呃或者说在我们在做建模的时候,其实数据分析呢是非常有必要的。怎么进行数据分析呢?这个其实非常简单。呃。
我们在做一个数据分析的时候,其实本质就是在做我们的标签如何进行分布做一个统计。我们这个地方其实是呃本质是需要分析一下我们的一个标签。标签呢是这个我们的是不是幸存下来的。
也就是survivve的这个具体的一个字段。那么我们可以统计一下,在我们的性别分组的情况下,这个具体的一个幸存下来的比例。也就是说男性乘客他幸存下来的比例是多少,女性乘客他幸存下来的比例是多少,对吧?
那么我们可以绘制这样的柱状图。这个柱状图其实很简单的啊,或者说啊在英文里面叫bar plot对吧?柱状图。呃,我们在这个地方呢,就是说X轴是我们的性别,它有两个取值。
Y轴就是说这每个性别它所对应的一个概率值,就是说它是不是幸存下来的。比如这个地方我们的非秒,比如说我们的女性乘客,他幸存下来的一个比例。对吧会更大一点,对吧?75%的对吧?
那么就是说这个其实也是泰坦尼克号,它的一个具体的一个是比较偏向于人道主义的对吧?就是相当于是妇女和我们的儿童,它是优先的一个登上这种就登上这种啊就是说这种嗯救生体的。
所以说这个妇女呢或者分娩它的一个具体幸存下来的比例会更大一点。然后呢,我们可以看一看就是船舱等级pak class它所对应的一个具体的一个幸存的比例。对。好。
然后呢我们也可以看一下这个地方的age age就是我们的年龄。这个年龄就是说不同年龄阶段的乘客他所幸存相来的比例。在这个地方,我们的baby对吧baby这个。相当于是我们的小宝宝。
他所幸存下来的比例这最大是吧?Oh。那么我们在做一个具体的一个建模的时候呢,其实是首先可以对我们的数据集参考上述的这种操作啊做一个分析。做完分析之后呢,然后就可以做一个建模。
这个建模呢可能这个代码可能会很多啊,这个代码里面其实细节非常多,它可能涉及到很多的一些啊预处理以及我们的数据清洗。比如说。我们的一个乘客,其实他的名字里面其实是有这个title的。
这个title是什么意思呢?就是说这个称呼这个在呃这个英国人啊,或者说这种美国人,其实他这种国外啊,或者说这种以英语为母语的国家,他其实在这个呃乘客的一个名字里面呢,会加上这个称呼。
比如说他到底是这个呃doctor,或者说是lady,对吧?或者说是这个呃mr或者说miss,对吧?他其实这些称呼呢都是有一个固定含义的。比如他到底结婚没有,对吧?是男性还是女性,对吧?
还是这个具体的一个对应的一个称呼,这个称呼呢,其实我们可以把它抽取出来,因为这个呢其实是我们原始数据机里面所没有的,我们如果把它抽取出来之后呢,也是非常非常有意义的。好。然后呢。
当我们把它抽取完成之后呢,其实接下来就可以做一个建模了。这个地方的一个建模呢其实非常简单。嗯,在我们现在的一个继续学习的一个实践的过程中,其实只要你懂一点。代码就是说你只要懂一些python的一个基础。
然后再去做实践,其实是你不需要去花很多的一些时间去了解机器学习的这个内在的原理。因为我们现在的一些具体的一些机器学习的一些库呢,它是将我们的一个。这个具体的一些模型封装的非常好了。
比如说我们在进行建模的时候呢,我们可以很方便的使用如下的一些模型来完成我们的一个具体的一个分类。我们来待会儿也可以一一给大家看啊。
首先呢我们会将我们的原始的数据器呢把它划分成我们的训练部分和我们的验证部分。嗯,这个地方呢就是我们会以我们的验证集的一个具体的一个精度作为我们最终的评价,对吧?嗯。
就是这个可能就是不能是说你在训练集上进行训练,然后以训练机做一个评价,这个肯定不合适,对吧?我们用一些你没有见过的样本来做评价,才是最公平的。好,那么这个地方就是用一个数据拆分的一个函数。
对我们的数据集做一个拆分,然后以22%的一个数据,就为我们最终的一个验证集。然后呢,我们就来看一看我们具体的一个模型的一个使用,以及它最终的一个精度。其实这个嗯使用起来就非常简单啊。
比如我们在进行使用的时候呢,我们首先导入我们的一个高斯BS斯,这高斯贝S斯呢,其实它也是我们的普斯BS里面的一种实现。那么我们导入进来之后呢,我们就直接对它进行。首先对它进行一个实例化。
这个导入进来的是一个class,它是一个类,在pathon里面是一个类。我们首先对它进行实例化,然后调用它的一个fate对象函数,然然后完成训练,训练完成之后呢,然后完成一个predt。
然后这个predict就可以得到我们的一个测试级的一个,或者说我们验证级的一个预测的结果。然后我们将我们的预测结果和我们的一个真实的结果进行一个。评价也就是通过我们的准确率。
这种相当于是判断两者是不是相等这种准确率的计算方法。那么我们的一个高斯BS,它的最终精度是78%。好,那么我们再看一个啊,我们的逻辑回归。
这个地方逻辑回归from SK learn SK learn呢也是一个机极学习的一个库,里面有很多这些机器学习的模型。那么我们就直接借助它来完成就行了。
from SK learn点 linear model import逻辑回归。这个逻辑回归也是一个class。首先对它进行实例化,然后对它进行训练,然后对它进行预测,然后进行评分,对吧?
逻辑回归最终的精度是79%左右。好,那么在我们的机器学习里面,其实你会发现我只用这几行代码就可以完成我们的一个具体的一个训练,对吧?我们在这个里面呢,我们就是用。Fit。完成训练。
我们用我们的一个predict。完成我们的一个预测,对吧?我们在这个训练和预测的过程中,我们并没有就是说去呃就是说让你需要你知道这个具体的模型的内在原理吧,对吧?我们没没必要。那么在这个地方呢。
就是说我们现在的pyython环境下呢,有很多的一些具体的一些机器学习的库,它可以帮助我们完成这以上的操作,对吧?那么这个地方你只需要按照它的一个语法,或者说它约定速成的一个写法来完写就行了。
那么类似的我们也可以调用我们的这个SVC嗯,也就是我们的SVM的具体实现,然后呢完成我们的一个具体的一个分类的一个操作。好,我们的一个具体的SVM的一个进度是82%会好一点。
那么我们也可以调用我们的一个数模型deciion tree classifier调用我们的数模型呢,用我们的数模型来完成一个训练,以及我们以我们的数模型来完成一个预测。
对吧当然我们也可以使用我们的这个key neighbors。这个K neighbors呢,其实这个就是1个KNKN。也就是说我们在进行一个分类的过程中呢,我们可以以啊这种最近您的一种思路来做一个分类。
也就是说。你这个乘某一个乘客跟他最相似的乘客是谁,对吧?然后他最相似的乘客有没有幸存下来?然后以最相似的乘客的一个标签作为你的一个标签。也就是说我们这个地方就是说如果乘客是相似的。
那么他最终得到的一个标签也是相似的,这就是一个KN的思路,以这个样本的一个维度去找到它相似的样本。好,那么我们最终呢其实就是可以得到这样一个表格,就是我们不同的一个积续学习的模型。
在我们这个问题里面得到了一个最终的精度,其实是存在的一定的差异啊。这个地方可能我们的一个呃grading boosting嗯,我们的一个得到的精度会更高一点啊。
这个模型我们在本节课我没有讲到然后我们的SVM它可能得到的进度会更高,就是说是其次的,我们的KN它得到的最精度是最差的对吧?好,这就是我们的一个具体的一个时间的过程。那么这个时间的代码呢。
我们也会在我们的一个群里面给大家分享出来啊,这个时间代码也是非常非常完备的。Oh。那么在这个学习的过程中呢,其实呃如果你是一个初学者,你在进行学习的时候肯定会很懵逼。因为我也是初学者。
我在我曾经也是初学者,我在最最开始学习的时候,我也写不出来这些具体的一些函数,我也不知道怎么去调用这些模型。所以说呢这个学习肯定是要一定一定的一个积累的,而且是需要有一定的一个循序渐进的一个过程。嗯。
我们再来回过头来看一看我们的步骤啊。其实我们刚才给大家讲的第二份代码就是按照这样一个步骤来完成的。数据的预处理编码训练验证以及我们的评价。对,所以说呢虽然我们的代码它很就是说看起来很少。
但是呢它具体的步骤呢都是包含的啊,都是包含的。好。那么我们在进行建模的过程中呢,我们不仅仅是需要大家掌握这个penndas的这个库,可能其他的一些库也是需要掌握的。
比如我们刚才在给大家进行一个演示的过程中呢,我们一方面最主要的是用到了一个penas的库。另一方面呢,我们是用到了这个SKlon的一个库。在明天我们也会讲到S可能。特征编码是特征提取吗?
这两者其实嗯含义很相似,但是存在一定的区别。我们在明天的课程呢,其实会讲解到特征如何进行编码。嗯,这两者其实编码和提取,其实是非常非常相似的一个概念。
但是编码呢它主要是侧重于我们如何去把它进行一个inco的。提取呢我们可能会侧重于提取一个新特征。对,我们明天会给大家解释这两个的区别啊。对。那,回到我们的PPT呢,就是说我们在学习今天的课程呢就是。
今天课程代码就是以这个penas和S进行展开的啊。S里面呢,其实它实现了很多的一些机器学习的一些模型。比如今天我给大家讲的一个线性模型啊,贝S以及我们的SVM以及我们的一个神经网络。
在我们的一个S里面都有具体实现,对吧?当然你如果自己去实现一下这个机器学习模型,也是可以的。但是呢可能是需要有一定的一个时间的一个成本,以及这个呃就是我们的一个呃这个人力成本。
那么如果我们是是使用我们的一个这个呃SS这个库呢,我们就可以很方便的使用到我们这些模型的对。所以说呢如果大家想要学习一下我们的一个基础呢,就可以结合我们今天的1个PPT的内容。
以及我们给大家准备好的两个nchbook来完成一下我们的一个具体的基础的学习。Okay。好。然后呢,我们的一个第一天的一个内容呢就是呃差不多。然后我们今天呢现在有一个抽奖的一个环节啊。
我们抽奖的一个问题呢就是。嗯,这个抽奖啊是基于我们的问题啊,就是说我们的问题就是pandas对什么类型的一个数据集比较适合进行操作。对,非那是比较适合的对什么类型的数据集进行操作。然后呢。
如果各位同学知道的话,可以在我们的直播间进行一个回答,进行一个参与抽奖。然后呢嗯参与抽奖,就是说前三位回成功回答我们的一个答案的同学呢,获得我们的一个具体的呃这个一步社区所提供的纸质书。对。
然后各位同学如果知道我们的一个答案呢,也可以在我们的一个聊天框里面进行一个打字。然后呢,各位同学在进行一个学习的过程中呢,一定不要我就是说一定要加入我们的一个交流群。
因为我们的一个PPT以及我们的一个呃就是代码都会分享到我们的一个这种微信群里面。然后大家如果还没有加入我们的群里面呢,一定要扫码加入我们的交流群,参与我们的互动的一个呃领取的福利。Pak。嗯。
然后呢我看一看有哪几位同学,您就是说应该是最先回答的回答对的啊,应该是我们的东京都同学以及我们的。呃,黑龙江网友以及山西山西网友这三位同学回答的是最快的啊。当然也有很大的很多其他同学也回答正确了。对。
pandaas呢是比较适合对我们的这种表格类型的结构化数据,或者说我们的关系性数据来做一个处理。对。好。嗯,然后我们的今天的课程嗯就这么多,各位同学对我们今天的课程有什么问题吗?对。
其实今天的课程呢就是带着大家对我们的padas以及具体的一些继极学习的一个。呃,模型的原理以及实践啊来进行一个简单的尝试。对。各位同学有什么问题吗?好。如果有问题的话,可以现在提出来哟。
当然也可以在我们的一个微信群里面进行提问。结构化数据图表类。对的,paus是比较适合用在这么这些的。然后大家如果是刚才嗯嗯就是说最先回答我们的一个问题的三位同学呢。
可以在我们的群里面聊联系一下我们的小助手啊,领取我们的一个奖品。好。各位同学有什么问题吗?怎么入门啊,完全看不懂代码。嗯。我放在最上面啊。Okay。首先你要你要学会pypyython吧。
就是取得这个其实有一些具体的一些技能技能,其实我大致可以给你写一下。你首先我会pyython吧,这个是基础,对,对吧?其次你要你要知道就是说我们的一些库的使用。喷nda师。我们的一个浪派啊。
以及SK no就说你要知道这些库的使用。如果你知道这就是知道这4个。点的一个选使用的话,基本上能够入门,完全看不懂代码,那就说明你的python基础不够。如果你排on基础不够好的话。
这个代码可能会看起来比较困难。老师有推荐的书单吗?嗯,我不太建议你去看书。当然这个我们在义部社区出版的很多的一些纸质书都是非常优秀的。但是呢我不太建议你去看。因为你如果看的话,你你去看书的话。
其实你会发现我我今天所讲解的内容,它在书里面都有。但是你可能是需要把一本书看的。看了好几张,你才有我们今天所讲的课程的一个内容。嗯,所以说呢你可以去尝试去直接去接触一个案例,去自己去动手写一下。
去去实践一下,或者是说。就是看一些视频,一些教程口也可能会更快一些。快书我觉得已经不太适合做一个。数据挖掘以及继续学习的一个学习啊,对,是节奏比较慢的。有嗯小白一枚没有接触过pyython。
你如果没有接触过pyython的话,肯定是比较难的啊,肯定是比较难的。对。老师有在嗯怎么向我学习的?嗯,有继续深入学习的课程吗?嗯,继续深入学习的课程呢,现在我们在一步周期也有一个课程啊。
我们明天会给大家介绍啊。对,今天呢你就把我们的给到家给到大家的这些内容啊,你能够就是说特别是这个代码,能够自己学习一下啊,就是说能够学多少就学多少。对,先学python。
然后再学一下我们今天课程的一些代码。嗯,各位同学还有问题吗?代码在哪里给?我们待会儿发到群里面啊,待会儿发到群里面。你可以呃现在还没有加我们群的同学加一下群,好吧。平时主要就是用SK论吗?嗯。
SK论是基础。SK learn是基础。对。待会儿会发啊,稍等稍等。对。大家还有问题吗?对,然后大家首先要加群啊,这是第一点。第二点呢,就是刚才也有同学问到如何呃就是继续深入学习。嗯。
深入学习呢其实这个学习的一个流程其实是蛮多的。呃,就是我可以给大家看一看,如果慎重学习,它有一些具体的一些步骤啊。嗯,就是我们之前给大家整理的一个具体的一个步骤,我翻一下啊。

我们现在呢在就是汽业在线和一步社区呢共积起推出了一个积器学习集训营。在这个训练营里面呢,我们给大家整理好的一个具体的一个就是学习机器学习的一些具体的一些步骤。
然后呢也是包含了我们的所有的积极学习的入门进阶,然后到我们就业相关的一个就是说技能以及相关的一些课程啊,然后呢我们这个课程呢,其实也是非常非常基础啊。首先从我们pyython学习。
然后到我们的一个机器学习的原理,然后到机器学习的一个实战,然后再到深度学习的一个原理和实战。然后一些具体的一些项目落地。嗯,如果各位同学感兴趣的话呢,也可以在我们的一个群里面找到我们的小助手。
然后给我们就是说跟我们的小助手嗯了解一下我们的一个具体的机器学习集训营的一个细节。对,有这个具体的一个课程的对。


嗯,怎么准备训练的数据呃,怎么准备训练的数据,这其实是一个好问题啊,但是它比较抽象。嗯,首先呢我们需要将我们的训练的数据呢整理成为我们的模型能够接受的。
其次呢我们可能需要做一定的一些特征工程来完成我们具体的一些编码。我们工作用啥呃,我们工作有基于python的,也有基于sk的,都有啊,都有的对。
当然一就是说具体的一些算法其实都是呃非常非常就是说可能在我们PPT里面也讲到的过的对。


老板用什么评价工作价值?嗯,比如举个例子啊,呃在我们的一个集训运营的这个课程里面有一个叫做单电商平台的一个商品推荐系统。这个推荐系统呢就是给用户推荐一些具体的商品,然后去就是说这个商品呢。
可能用户会购买。那么这个评价下工作价值,就是说你这个模型他推荐的商品是不是用户所喜欢的。如果用户他喜欢,那么用户他可能购买的概率就会就更大一些,那么他就会直接反映到这个收益上面来,对吧?
如果你给用户推荐的是他不喜欢的商品,他肯定不会购买。如果你给他推荐他可能喜欢的商品,那么他可能就会下单所带来的就是直接的一个经济的一个收益。对。然后我们这个项目其实就以这个项目做举例啊。
然后大家如果还没有加入我们的一个社群的同学呢,一定要加一下。好,然后各位同学还有问题吗?

对,还有问题的话可以提一下啊。啊,没有对吧?如果没有的话,我们今天的一个直播就到此结束。对,那么大家如果后续有问题的话,也可以在我们的一个群里面进行提问,好不好?好。这个可能性怎么评估?
因为我们有训练数据,我们有训练数据的话,我们就可以进行评价。历史的训练数据。对。有历史的训练数据。对我们这个可能性就是用一些损失函数,我们的评价函数来做评评价的。好,大家如果还没有加群的话。
一定要加一下群啊。然后我们今天的一个具体的一个直播呢,我们今天的具体直播我们就就是到这了啊到这儿了。好,谢谢大家谢谢大家好。


人工智能—机器学习公开课(七月在线出品) - P26:【公开课】数据挖掘与机器学习进阶 - 七月在线-julyedu - BV1W5411n7fg
🎼,好,嗯,各位同学,大家晚上好。然后我们就开始我们今天的一个课程啊,今天呢就是我们继续我们昨天的课程,然后来继续进行讲解。我们首先呢来看一看我们在点今天我们所讲解的内容是什么。我们今天所讲的内容呢。
其实会更加深入一些。如果说我们昨天所讲的一个具体的一个知识点是关于我们的一个数据而言。那么我们今天啊今天呢会更加深入到我们的数据所内内在的就是说原理。比如我们会深入到具体的一个数据集,如何做为处理。
以及我们的一个具体的一个数据集它的一个内别变量数值变量以及相关的一些操作。当然我们也会给大家讲一下这个数媒性和集成学习。这个可能会给大家做一个深入的讲解。好,那我们今天的一个内容呢。
就是希望各位同学能够掌握就是我们拥有数据的情况下,我们如何对数据集做一个处理,然后能够获得一个比较好的一个精度。那么在我们的现实生活中呢,其实我们的数据其实是非常多样的。不管是我们的现实生活中。
还是我们的学术数据集,还是我们的工业类型的数据集,它的数据都是非常多种多样的。嗯,我们在常见最为常见的数据呢就是我们的结构化的数据。结构化的数据,我们英文呢叫tabletular这种类似的这种。
英文单词它这种英文单词所表示的数据集就是什么呢?就是我们上节课。就讲的pandas的这种形式。我们有行,而我们的有列。那么在这个地方呢,结构化的一个数据集,就是我们有有对应的一个行和列。我们来看一看啊。
翻到我们上节课的1个PPT。我们的每一行,比如说这个地方是每一行是一个具体的一个。样本。每一行是一个样本,比如说这个地方呢,每一行应该是1个NBA球员的一个信息,每一列就相当于是一个对应的一个字段。
这个字段描述了这个球员他到底具体的信息是什么。比如说这个球员他所处的球队是什么,他的球球员他的号码是什么,以及他的位置、年龄等等等等啊吧?所以说呢我们的一个具体的一个结构化的数据呢,就是类似于这种形式。
它是长得非常规整的,长得非常规整的,它有行和列来组成我们的一个数据集。那么在我们的一个具具体的数据集而言呢,我们在处理的时候呢,还有一类数据叫做半结构化或者说非结构化。半结构化啊。
我们这个地方半结构化的数据集呢就是一种这种XMLjason或者说email或者说我们的这个web page,这种网页类型的数据集,它就是我们的半结构化。半结构化呢也就是它的一个具体的一个数据。
它有这种有点像结构化的一个数据,有这种字段,但是呢它可能不规整不规整,就是说我们在jason里面其是我们的行和就是我们的列它的字段可以是。就是说不确定的对吧?我们有的样本有三列,有的样本有4列。
在我们的GS里面都是可以的。第三个呢就是非结构化的数据。非结构化数据。比如我们的一个音频视频以及我们的文本,它就是非结构化的数据。非结构化的数据呢就是说我们的现在比如说我们给的一个图片。
那么这个图片而言,其实它有大有小,对吧?那么。嗯,我们的一个文本有长有短。嗯,这个地方它就是一个非结构化数据,需要注意的一点就是我们现在的一个记忆学习的模型。任意的或者说是所有的机忆学习模型。
它的一个输入的格式都是要非常规整的才行。这是什么意思呢?我们在进行一个建模的时候,我们昨天也讲了,其实我们本质是想要输入我们的样本X,然后得到我们的对应的一个标签,输出我们标签。在这个地方。
我们的一个数X一定是要。维度相同的维度相同的。我举一个非常简单的一个例子啊,还是以昨天的一个线性回归的案例给大家讲,我们有X1乘以W1,加上X2乘以W2,再加上我们的B,对吧?这是我们的线性礼盒。
那么假如说我们现在有一个。样本它有X1X2和X3。他想输入到我们的模型里面,它能够输入吗?它是不能的对吧?他必须要选择其中两个。其中两个我们的列或者两个元素来做我们的输入。
比如说我们把这两个字段送到我们的模型里面。或者说把这后面两个字段送到我们模型里面,因为我的模型它只支持两个字段的输入。所以说我现在的一个机器学习的模型啊,它输入的格式它是提前定义好的。
在你确定你的一个训练数据的时候呢,基本上就把我们的一个具体的一个输入的格式给确定好了。那么我们接下来呢就以这种不同格式的一些呃这种特征来讲解如何对它进行一个编码。嗯,这个特征呢其实我们在进行讲的时候呢。
你一定要弄清楚,就是我们具体的一个操作。它到底有什么类型的一个特征?对我们的初学者而言。可以首首先呢去看一看这三类特征。类别数值、日期或者是时间。这三类特征呢在我们的这个具体的一个建模的过程中呢。
其实是呃非常非常建议大家去使用和学习的。那么我们再来就是说比如这个类别啊,我们先讲类别,然后讲数值啊。呃,我们先翻到前面这个NBA球员的那个案例里面。在这个地方,team。它是一个什么类型?
它就是一个类别类型category。为什么是类别类型?这个地方其实它所展示的一个形式,其实是以这种字符扇的形式来作为我们的展示的对吧?我们的应该是波士顿凯尔特人,对吧?然后这个球嗯位置。
这个球员的所在场上的位置,对吧?也是有具体的一个就是说用字符扇的做展示的PG对吧?应该是一个point guard,对吧?我们的应个相当于是这种控球后卫或者得分后卫,对吧?还有这种C。啊。
它是一个类别类型,还有一类就是我们的数值类型。数值比如说我们这个地方呢有一个A。H age这个地方它有我们的1个25。027。0以及我们的29。0,对吧?它就是以一个数数字或者说是一个服务点数。
或者说我们的一个整数来做一个具体的一个展示的啊,这个是我们的一个具体的一个啊,就是这个类比要数值。如果你看到这种形式的一个具体的一个数集,或者说你看到这种形式的一个字段。
那么你就知道它到底是类比还是数值的。那么我们继续。我们首先呢来看一看类别类型。类别类型。类别类型呢其实在我们的日常生活中呢,或者说在我们的一个数据集里面,其实是非常非常常见的非常非常常见的。
那么这个地方呢非常建议大家可以嗯以自己的一个情况来举一些例子啊。比如说我们的个人信息里面我们有性别、城市、省份、民族、户口类型,这些字段都是一个类别类型。对吧那么这个地方我嗯把这个性别拿出来,可能对吧?
这个就是一个类别类型的。因为。他是有。它里面的取值难。铝对吧?有两个取值,而且这个取值呢都是一个以这种字符算形式来做我们的一个存储的。对吧然后我们的颜色这个类别它有红色、白色、黑色、粉色,对吧?
也是以这种字符串类型来进行展开。然后我们国家动物对吧?其实都是有具体的一个取值。内部类型呢其实它还可以做一个具体的划分。也就是我们右边这个图。类别类型呢我们可以分为有序类别和无序类别。Yeah。
在中文里面叫做有序和无序。こと。这有序和无序有什么区别呢?有序就是说它的一个大小是存在一定的一个次序,或者说他们之间存在某种关系。比如我们的一个情感。对于我们的情感而言,对吧?
它有excientgo和bad对于这种情感的一个即性。然后呢,我们的一个无序类别,就是说它他们之间是没有这种大小关系的。penpen和 eraasser对吧?它是没有这种大小关系的。
它就是说它们是相互平等的啊,相互平等的对吧?我们的动物动物之间他们也是没有这种关系啊,也是相互平等的。那么我们嗯这个类别为什么要分成有序和无序呢?因为我们的在进行编码的过程中。
我们其实是根据需要根据我们的具体的一个类别的取值,它的含义来做一个具体的编码的。好。那么对于类别类型,我们怎么做一个处理呢?这个地方其实也有一个关键的一个点。首先所有的机忆学习模型。
它的输入都是需要规整的形式,这是一点。这这个地方我们已经达成了共识。好,第二个点就是所有的机忆学习模型,它的输入都是需要把它编码成数值类型。就是所有的机器学习模型。No。就是精行学习模型。
它输入的一般情况下都是数值。它不能输入类别类型,或者说不能输入字符串。我举一个简单的一个例子啊。假如我们现在仍然是一个线性的一个。回归的一个人务。那么这个地方我们在做一个运算的时候。
其实本质就是在做一个数学数学数学上的一个计算。那么对于自符账而言,其实它是没办法参与这个过程的对吧?所以说我们在进行一个编码的过程中。或者说在进行建模的建模的过程中。
我们是需要将我们的一个具体的一个字符串把它编码成这种数值的。而且它是有必要的。那么对于我们的一个类别类型,就是它原始的一个展示形式,或者说存储形式是这种字符串的话,那么我们就需要考虑对它进行编码。
所以说类比类型呢基本基本上就是在任何时候都需要做处理的一个数据。第二个特点就是类部类型呢,它容易带来一个离散数据。它容易带来一个离散数据。如果我们的一个具体的一个类别类型。
它是有我们的一个取值是非常多的情况下,那么它就是一个高基数的一个类别类型,高基数的一个类别类型。高技术的。那么这个地方呢,这个什么是高基数呢?就是说它一个取值。个数或者取值空间。
我们的一个具体的一个类别类型呢,其实我们本质它是有这一列有取值的。比如性别,它有两个取值,蓝和铝,我们的一个颜色,它有对应的一些取值,对吧?国家有一些对应的取值。
那么在这个地方我们的一个具体的一个在进行编码的过程中呢,你要考虑到这一列或者这个类别类型,它一些取值的个数是多少,或者它取值空间的大小是多少。因为如果你在做处理的时候处没有处理好。
那么就会导致带来一些高基数的这种离散的一个数据。而且呢对于类别类型呢,其实它是很难做一个趋失值填充的。比如啊某位同学他的一个个人信息里面,他的一个性别,他是没有。嗯,写的就是说它是一个缺失的。
那么如果是对于性别,我们需要对它进行做一个缺失值的填充,嗯,怎么办呢?嗯,对于性别而言,我们其实是很难做一个缺失值的填充的。你把它填为男性或者女性都很容易出现问题,对吧?
因为这个地方其实它正确就是填充的时候,正确率可能只有50%,只有50%。对,所以说这是我们类别类型的几类特点。好,那么我们对于这个类别类型,我们怎么做一些相关的处理呢。
我们接下来呢就使用一个案例来做对它进行一个处理。我们在这个地方呢,我们是创建一个表格。在这个表格里面呢,我们记录了这个student IDcountry education以t这四列。
这个地方的一个tarage就是我们的一个标签。标签。在这个标签里面呢,我们其实就是需要对我们的一个利用我们的一个country和educ列,然后去预测它的标签。这个tdent的ID呢相当于是一个标识。
相当于你可以理解就是学生那一个学号。就是那个编号用来把每个学生做的一个具体的编号。好,那么我们就开始我们的一个具体的一个编码。
首先呢我们来看一看这个one portone horseone horse呢其实它的一个原始的一个含义呢就是one OK的这种形式。这个K呢就是我们的一个类别的一个取值空间。大小。
比如我们的一个在对education这一列做一个编码的时候,我们的education这一列它原始的一个取值空间是多少?musster better以及PHD对吧?它这个取值空间是3。
这一列取值空间呢是3。那么如果对它进行一个进行一个编码,指one或指定编码就是one。all three对吧?one of three ishor在三个中间有一个是ho,就是编码为一。
其他位置是仍然是0。那么在这个地方我们就做。嗯,我们就做这样一个处理啊。我们对于我们的一个输入的一个数据呢,我们把它进行一个这样的一个编码。我们把我们的一个原始的education链呢。
把它转成一个1乘以3的这种形式,1乘以三的这种形式,那么在这个形式的过程中呢,我们是把其中的一个位置,把它编码为一,剩余的位置把它编码为0。
比如对于我们的原始的这一列这个mus这个地方呃第一个学生它的一个education是取是原始的取值是ma。那么我们就把它对应的一个musster这个位置复制为一,对吧?
那么第二个学生如果它的一个嗯education的一个取值是ba,那么我们就就把它对应的位置取值为一,其他的位置都是0。那么这个地方呢就是oneone horse就是这样的一种形式,它是把一个字符串。
把它转成了一个1乘以K的一个向量。这个K呢就是我们的一个取值空间。取值空间的一个大小。好,那one horse它有什么一些优点呢?就是说它在做一个编码的时候,其实它是将我们的一个具体的一个。
一个字符串做一个这种转成一个向量,而且呢它其实是能够很好的做一个具体的一个数值的编码的。然后期的一个优点就在于它其实是能够很简单的,很有效的对我们的一个类比特征进行有效的编码。
它的一个缺点就在于它其实是会带来数据的一个维度爆炸和特征的稀疏。因为我们这个地方。原始的一个字符转是一列。那么在通过完好之之后呢,它转变成三列了。转变成三列对吧?
那么在这个地方就是说我们如果是把它转转变成三列之后,它的一个所带来的也有数据的一个稀收的情况,对吧?这个地方有很多零。对吧转出来的三页里面就有很多零。这其实就是非常非常稀疏的一个数据。
非常非常稀疏的一个数据。好,那么one horse呢它的一个就是说优缺点我们已经给大家说了,那么怎么实现one horse呢?呃,这个实现one horse的一个方法,其实很简单。
你可以自己动手尝试写一下。当然在我们的这个python里面呢,其实我们可以使用padas,或者说我们的SK learn来完成我们的具体的一个one horse的一个操作。对。
所以说这个其实也是非常非常呃便捷的,非常非常便捷的。好。再看第二类。第二类呢编码方法呢,我们叫做label encoding。label encoding。
label encoding呢label是什么意思?label就是我们的一个标签的一个意思。labbel就是我们的一个标签的意思。那么label encoding它的一个原始的一个字面意思是什么?
字面意思就是说我们对于我们的一个标签做一个编码。那么它是这样的一个操作。我们是用一个具体的一个数值来去代替原始的一个字符串。Okay。我们注意用一个数字。来代替它。那么这个地方我非举一个非常简单的例子。
比如我们对这个country这一列对它进行一个具体的一个编码。那么在这个地方呢,我们就是对我们的一个具体的一个数值呢,我们是需要将它做一个具体的一个。这样的一个编码。
我们把country对应列的china编码为0USA编码为一,U可以编码为2,ja篇编码为3,对吧?这个地方就是说我们是这样做一个操作。它的一个操作是做什么呢?
它的操作就是说我们是将我们的一个具体的一个用一个数字来代替我们的一个原始的字符串。它的一个优点就在于它是没有增加它的维度的。原始的是一维,那么我们编码之后也是一维对吧?它是没有增加这个维度的。
没有增加维度,这是它的首要的一个优点。它没有增加维度。但是它会带来一个缺点,就是说它会改变我们的类别之间的一个代写的一个次序。它的一个次序的关系就会改变。
比如我们的一个这个地方千档编码为嗯签档编码为0USC编码为一,对吧?中国就比美国小对吧?中国也比UK,我们的英国小,对吧?它就引入了这种大小关系,所以说呢这种label encoing呢。
它比较适合用在有序类别里面。或者说是一些高基数的类别里面,就是说取值空间。非常大的一个情况下,比较适合用。Laabbel encoing。那么在对于我们label encoding呢。
我们怎么对它进行实现呢?可以使用这个pens里面的factorize,或者说我们的Scal的一个具体的label enr来完成。对,这是我们的一个具体的一个操作啊,这是我们具体的一个操作。

好,我们继续。Yeah。呃,sorry啊,我这个PPT。应该是卡了啊,稍等一下啊。

对我再找一下啊,然后翻到后面。对,这个地方的一个label呃label encoding呢就是说我们用一个具体的一个数值来代替。那么对于我们label encoding,我们怎么进行实现呢?
我们就是用padas的一个veize,或者说s clean的一个label ender来做一个具体的编码,这是我们的label encoding。那么它的一个优缺点,我们也给大家讲了。第三类呢。
我们就是一个out哦这种顺序编码。数据编码呢就是说我如果知道我们原始的一个类别,它的一个取值的一个顺序,我如果知道我们原始类别的一个取值顺序,那么我们就对它进行这样一个编码,我们对它进行。
把它的一个education这一列对吧?我们知道这个学历,它之间学历它的一个具体的一个大小关系,或者说这种前后顺序,对吧?我们就把它手动的把它编码成123这种形式。那么顺序编码呢。
就是说它是按照类别的一个大小关系进行编码的,而且它是非常适合用在有序的编码里面。它的一个优点就是它也是增加没有增加类别的一个纬度。原始的是一维编码之后的仍然是一维。
但是呢它的一个缺点就是说它是需要人工知识。对没有出现的一个数值是不太友好的。这个地方的一个顺序编码呢,其实它是传入了一个dt。在python就是python里面的一个dic一个词典来做一个映射,对吧?
dicction里面其实本质就是一个K和value的一个映射关系。那么在这个地方就是我们是用一个字符串。做我们的K,然后把它转成一个具体的一个数值。对吧这是我们的一个dict。嗯,在这个dict里面呢。
其实我们需要手动去维护这个映射关系,对吧?这个映射关系是我们人工做输入写代码的时候写进去的。所以说呢它的缺点就是说它需要人工知识。人工知识,这是第一个缺点。
第二个呢就是说它对于我们呢没有出现的数值是不太友好的。这是什么意思呢?如果我们的一个具体的一个数值或者是字符差。比如我们在训练集里面,我们就是对我们的一个这三个取值做一个编码,对这三个取值做一个编码。
对吧?那么如果我们想要对我们的一个测试集。新加了一个字符串新加了一个字符串。比如说我们这个地方还有一个post。doctorctor对吧?我们的博士后。那么在这个地方,我们还有一个字符上做编码的时候。
这个地方它并不在我们的一个d里面。它并不在我们dt里面,那么它就会报错,或者说直接会把它编码为缺失值。因为它不在我们的一个编码关系里面。好,所以说呢这个顺序编码呢,其实它对我们的没有出现过的一个类别。
或者说没有出现过的这个数值是不太友好的。那么这种顺序编码呢,它的一个实践方法,就是说我们手动通过这种自典音射的关系来完成。我们再来看一类,就是我们之前所讲的这个one horse。你不 encode。
以及我们的这个顺序编码。其实它都是尝试用一个数值或者说一个向量对我们的一个字符上做一个编码。但是呢我们能不能从另一个角度去思考呢?我们能不能从一个这个类别。
它出现的一个次数或者整体的一个分布规律做一个编码呢?这个叫做我们的这个在我们的一个count encoding里面可以做。count encoding呢就是说我们可以将我们的类别。
它整体这一列的一个出现的一个次数,或者它的一个频率做一个编码。比如我们这个地方对于我们的country这一列。我们可以做这样一个编码。在这一列里面,我们的china,它对应出现了两次。
china对应出现了两次,对吧?所以说我们你这个地方china比方把它编码为2。USA出现了两次,然后就把它变码为2UK出现了一次,那么它就把它变码为一。什么意思呢?
我们会看这一列里面它的一个具体的取取值的一个出现的次数。会这样看,那么这个地方呢,它的一个优点就是在于它其实是以一列的一个维度来看的。它能够看到所有的样本在这一列的一个取值,有点像这种上帝视角。
有点像这种上帝视角。为什么这么说呢?因为我们的一个具体的一个机器学习在进行建模的时候啊,常规的机忆学习模型它是可以输入单个样本来进行建模。那么我们这个长体引沟里呢,相当于是它开了这种天眼,对吧?
我们去看了所有的这个样本,它的一个这一列的一个特征,然后再去做一个编码。它不是对单个样本做一个训练,它其实是对所有的样本做就是集合,然后做了一个编码。
那么这个counting勾ing它的一个优点就是说它其实也是非常简单的,没有增加这个维度。它可以从这个整体的一个角度来统计我们的出现的次数,相当于是这个整体的一个频率啊,可以做一个统计。
但是呢它也有它的缺点,就是说如果我们的数据集,它的一个整体的分布,或者说它的一个具体的一个。情况。就就是说整体的一个样本的一个原始来源,它可能是有误差的情况下。
那么也会导致它的一个cont codinging所编码的结果也有存在误差。比如这个地方我们的一个chinaUSAU,比如在现在我们的这个china和USA是编码为二的。那么在下一份数据集里面。
有可能使用这种方法,有可能china的编码成3USA编码之一,这个都是有可能的。所以说呢它其实是跟我们的当前的数据集是有关系的。好,这是我们的一个counting扣点。那么我们就继续啊。
刚才其实我们讲的这个具体的一个类别类型的一些编码。那么我们接下来呢就看一看这个数值类型的数职类型呢,其实在我们的日常生活中呢也非常常见。比如我们的年龄成绩经纬度,它都是一个数值类型的特征,对吧?
数职类型的特征呢?它有什么样的一些呃特点呢?就是说它是有大小关系的。19小于2020小于21,对吧?这是有大小关系的。而且这个地方我们也可以推导得到19小于21。那么这个地方呢这个数值呢?
它是能够做一个大小比较的这是第一点。第二点呢就是说它可以做一个减法或者加法的运算。对吧。这个地方它是存在有一定的具体的含义的。比如说某某位同学他是20岁和某个同学是19岁。
那么我们可以统计一下两位同学他的年龄的差值。对吧零行差值这个减法是有意义的,它是数值减去数值,也得到的是一个数值。字符串它是没办法做减法的对吧?好,那么这是数值特征,其实数值特征它能够。
带来很多的一些有意义的一个信息。但是呢数值特征其实它非常容易出现异常值或者种离群点。为什么这么说呢?比如我们在填写一个学生的一个年龄信息的时候,统计这个学生的年龄信息的时候。
大部分同学呢都是在我们的1个18岁到30岁之间,绝大部分同学都是在这个年龄阶段之间,然后突然有一个同学把他的年龄填成100岁。填成100岁,当然不可否认啊,现在我们的医学这么发达。
肯定100岁当然也是可以就是说成功是就是说就是说也是存在这种啊就是说年龄的。但是在我们的一个整体的一个分布的过程中,或者整体的一个呃就是说数据集的一个场景下,这个地方100岁可能就是填错了。
或者说有人故意填的对吧?那么大部分的同学都是在这个年龄段,那么突然蹦出来一个跟我们这个年龄段,或者说整体的一个数据,整体的大部分同学的年龄相隔比较远,相隔比较远的这个情况,对吧?
那么它就是一个具体的一个异长值。当然还有这种离群点,离群点呢,它跟异常值其实是比较相似的。但是呢离群点可能是呃这样一个含义。比如说大部分的同学的年龄呢都是在18岁到30岁之间。
然后有一位同学他的年龄是15岁。对吧它可能不是异常值,但是呢它跟我们的整体的一个分布呢不太一致,它是偏离了我们的群体的对吧?它不算异常值,但是它是一个离群点。好。
那么在我们的一个具体的一个数值特征的编码的过程中呢,其实我们异常值和离心点都是非常常见的。那么我们怎么做呢?其实对于我们的数职特征呢?就是说我们需要对它可以对它进行一个缩放。
假如说我们拥有的一个呃学生的一个A级A级这一列,就是他的一个学生的一个年龄的这一列。对于年龄这一列呢,我们其实是可以对它进行一个缩放的。对吧我们直接把它缩放的,就是你可以把它进行取整,34。5。
把它转转变成34,对吧?34。5把它转变成34,然后呢,我们也可以考虑把它做一个像,就是说除以10,然后做取整,比如说34。5编码,把它转变成328。9,把它编编码为219。5,把它把它编码为一,对吧?
这个就是具体的一些操作,那么在这个操作的过程中呢,我们为什么这么做呢?其实我们把这一列把它编码成这两列,其实是一个信息丢失的一个情况。也就是说原始的信息是有小数点的对吧?我们其实是把它转成了一个整数。
或者是保留某一位。为什么这么做呢?其实这个地方有很多原因。我们的一个特征呢,其实。或者说age这一列,它包含的信息有点多。为什么这么说呢?在所有的学生里面,只有你一位同学是34。5岁,在所有的同学里面。
只有你一位是28。9岁。对吧那么我在这个机器学习模型在。训练的时候,我看到这个样本。我就直接能够记住你对吧?因为在所有的样本里面,所有的同学里面,每位同学的年龄都是非常非常非常不不一样的。
他是没有共性的。好,那么这个信息多并不一定是好事,信息多不一定是好事。因为这个地方可能会把一些没必要的一些就是说过于精细的这些信息呢也提供给我们的模型呢,让我们的模型呢,它很容易走走偏了。
那么我们怎么办呢?我们相当于是做一个取整或者说缩放,把我们的一个数据把这个A这一列呢,这个字段呢把它转变成一个非常规整的一个形态。比如说34321对吧?其实也有类,它也其实也有这种大小关系。
但是呢它其实是更加规整。为什么呢?因为这个地方它所保留的,它是把整体的信息给它保留了下来。但是呢他把这些过于精细的小数点之后的,把它丢弃掉。它的一个优点就是说我能我我将我们的一个信息。
把它的一个主体的一个位置或者主体的信息给它保留下来。那么这就是round啊,其实它是在绝大部分的场景下都可以做通用的,而且呢它是能够保留绝大部分的一个信息的。
它的一个缺点呢就是说有可能是需要人工来进行参与。然后呢,可能具体的缩话呢,就是完使用这种除法来完成。然后我们还有这种就是说分箱,分箱呢就是我们对于我们具体的一个A级字段,然后通过某种逻辑的判断。
然后判断它是不是小于20岁,是不是在20岁到25岁,是不是在25岁到330岁,以及在30岁以上,对吧?通过这样的分箱,我们都可以完成我们的具体的一个数字特的一个编码。那么对于我们的数值特征呢。
其实我们也需要考虑到如何把它做一个缩放,为什么呢?我们。举这样一个例子。在我们进行建模的过程中。我们仍然以线性模型做举例。我们线性模型其实本质假如我们输入两列。
然后我们需要有两个具体的一个W跟我们的列的一个取值径相乘,然后再加上我们的一个偏值,得到我们最终的一个数值结果。好,假如我们的第一列,它的一个取值空间是0到1。假如说它的具体取值就是0。01呀,0。
1呀这种。它的一个具体的取值范围是从0到1。第二个。X就是X2的维度,它的具体的取值范围是从0到100。比如说34啊,35啊。好,那么如果这样来进行建模的话,就会存在一个问题。存在什么问题呢?
就是你的一个W1和W2,它在进行一个参数的一个优化的过程中,它得到的一个取值,具绝取值会存在就是说差异性,而且这个差异性呢有可能是这个成倍的差异性。这个地方我们的W2,它只要改变一点点。
对我们的精度就影响非常大。但是我们的WE它改变很多,它可能带来的一个标签的一个影响就很小。为什么呢?因为我们的1个X1和X2,它的一个具体的一个取值范围是不一样的。
那么在这个地方我举这样一个非常简单的例子呢,就是想要给大家讲。大家清楚这样一点,对于我们的一个具体的一个输入的一个数据呢,我们可能是需要把它做一个缩放的。特别是对于我们的数值特征。
我们把它做了一个缩放之后呢,我们就可以保证我们的具体的一个所有的数值特征呢处于一个比较规谨的范围内。那么就是按照这样一个例子,如果我们的X1和X2,比如说X1远远大于X2。在这个地方我们的一个就是说。
如果我们的X一远远大于X2。那么这个地方我们所。所需要的1个W1就远远小于W2。因为我们就是说希望它两者就是说这个参他所训练得到的参数啊,肯定是处于这种形态。那么我们如果是处于这种形态。
你会发现我们的一个优化的一个曲线,它有可能是这种椭圆类型的,它就不是一个圆形的。也就是我们的一个在进行一个参数更新的过程中呢,我们就会走这种支字。形态的支子形态的。这种就是说具体的一个优化,它就会走。
就相当于是需要走多步。而且呢很有可能就是对我们的一个具体的一个模型呢会带来这种相当于是梯度爆炸呀,或者说这种不稳定的一个影响。但是如果我们将我们的一个具体的一个输入数据,把它缩放到一个规整的范围内。
X1和X2都是在一个规定的范围内。那么这个地方我们的一个W和W2也可能是在一个规定的范围内,它就是从一个椭圆,把它变变成一个比较规整的一个圆。这样我们优化起来,我们就不会存在模型不稳定啊。
已经梯度爆炸的这种情况。好,这是我们的一个预处理。它的一个为什么要做预处理。对,那么做我们的预处理怎么做呢?呃,有很多种方法比较常见的,就是说我们通过这个呃这一列,这个X是就是其实是一列。
X命呢是一个值。那么我们对这一列呢,我们减去它这一列里面的一个最小值除以它的一个最大值,减去最小值,然后做一个除放,就是做一个缩放。这个呢其实是使用这一列的一个最大最小的一个做处理。
它比较适合用在这种非高斯分布里面。然后呢,它也是能够保留我们的一个数值的绝大部分的信息的。但是呢它非常容易受到异常值或者说这种离群点的影响。因为我们的一个异常值呢,往往都是在最大值和最小值出现。对吧好。
我们继续。那么我们第二类呢就是这种标准化。标准化呢,其实在我们的这个数学里面其实非常常见。对于我们的这个数这一列,我们减去它的一个均值,除以它的方差,对吧?
相当于是把它做了一个减剔除它的一个这种均值和方差项。它就是比较适合用在这种高斯分布的数据集里面。然后处理之后呢,我们的数据集整体的一个分布呢也比较正态化。
但是呢它的一个处理呢可能是需要做一个相关的计算啊,而且对我们的一个分布的要求也比较严格。好,那么刚才就是给大家讲了这个数值的一个特征。那么我们接下来就看一看我们的这这个常见的一些集成学习的一些思路。
稍微给大家介绍一下,这一部分可能会有一些难度啊。那我们来看一看这个集成学习呢,其实是这样的,集成学习就是说我们能不能集成多个模型来完成一个具体得到一个新的模型。比如我们一个非常简单的一个例子。
就是三个臭皮匠能不能顶一个诸葛亮,这个就是一个机身学习,或者说我们投票。对吧投票都是非常常见的集成学习的思路。投票选班长啊,通过多次摇骰子来进行投票啊,这就是一个集成学习的思路。
那么在我们的具体集成学习的过程中,到底有哪些集成学习的一些想法呢?在机器学习里面,我们比较常见的有这种baggingbagging是什么?begging就是这种民主集中的思路。啊。
这个就是民主是什么意思?民主就是说我们每个模型。都是相互平等的。每个模型相互平等,每个模型有一个预测结果。然后最终呢我们会将这个预测结果把它进行一个投票,然后得到最终的一个预测结果。那么这个地方呢。
begging呢它其实是可以做一个并行的训练模型的。因为每个模型之间它是相互独立的模型与模型之间是相互独立的,所以说我们可以并行训练多个模型。那么它怎么进行训练呢?我们可以对我们的数据集做一个采样。
然后进进而可以训练多个模型。好,这个地方其实是有一个鲜应的一个呃假设的。什么假设呢?就是说。我们有了模型一。我们有了模型2。我们有了模型3。我们希望这三个模型分别做一个决策,然后把它做一个投票。
得到我们最终的结果。这个地方其其实是有一个假设这个假设就是说我们这三个模型它是有一定的差异性。差异性是要有的,为什么呢?就举个例子啊,假如说我们在选班长投票的时候,所有同学都投某一个就是相同的一个。
同学,那么这个。这个投票就没有什么意义,这个投票就没有什么意义,它没有多样性,它不能就相当于是它最终的结果其实就没有什么价值。每个同学他的一个选择都是一样的。
那么这个地方呢就是说我们希望我们的模型是有差异性的。每个学每个每个同学他可能自己的一个就是说投票的一个这个决决定啊是不一样的。我们最终呢是以相当于是取相当于是少数服从服从多数这种心态。
如果我们的所有的模型都一样的话,那么它的就是说最终的一个。结果也是一样的,或者说他投票的一个结果,或者是说预测的结果也是一样的。那么对我们最终的一个。精度是没有什么。改变的啊,或者说没有什么提升的。
就是说我们是需要比我们的模需要我们的模型有多样性。我们最终呢它的一个预测结果才有多样性。如果你预测结果没有多样性,那么就没有什么轻度的收益。好。
那么这个地方的一个关键点就在于我们如何去得到我们的模型有多样性,或者说如何让我们的模型有多样性。这个地方呢其实是有一定的一些具体的操作。我们再进行训练深度学习,训练任何的一些模型。
不管是机器学习模型还是深度学习模型,我们其实是可以把我们的数据集做一个采样。比如说行采样列采样,然后采样得到不同的一个数据集。
然后就可以得到我们的一个相当于是原始的数据集是一个10101万行乘30列的一个样本,我们可以把它采样成。990千0行乘20列的一个样本,或者说是9。5000行乘以18列的一个数据集。
也就是说我们把原始的一个样本空间行和列做一个采样,采样得到一个新的数据集,然后通过模型训练,可以训练得到新的模型。由于我们的输入的数据不一样,那么我们的模型也会存在不一样的一些差异性。
然后最终通过一个投票得到我们最终的结果。好,这个就是一个bagging的思路啊。第二个呢是bosting boostsing呢就是说我们通过这种串就种筛进行筛选的一个思路来串联我们多个模型。
它是什么意思呢?就是说我们的一个记忆学习模型啊,不仅仅是让可以让他训练一次,我可以让它迭代多次。比如说这个地方举一个简单的一个例子啊。我现在要打靶,我现想要这个深度学习。
想要这个模型呢能够命中我们的一个靶心。这有个圆圈,有个中心,命中了个靶心。那么我们怎么办呢?我们最开始的一个模型,有可能它的命中位置在这儿,离我们的一个最优的一个位置,其实相隔很远。
对吧那么我我们下一次预测呢,我们就是基于。你上一次预测结果就一个二次预测。这一次我遇就是说他打的比较远,牵都比较远,哎,我就往右偏一点。对吧然后呢我们不断去调整,不断去调整。
我们可以尽可能的去靠近我们靠近我们的一个最优值,这个就是一个bosing思路。就是说我们的模型它可以不断的通过某种方式来进行一个进化。这个进化呢。
我们是可以通过本能模型对我们的一个上能模型做一个继续的一个迭代或者礼盒这样的一个操作来完成。bosting呢它可以就是说对我们的一个模型的精度有很好的一个呃就是说提高啊,因为它是一个迭代的操作。
而且呢bosting它是能够对我们的一个模型能够做一个继续学习的啊,这一个继续学习的。这是boasting的一个思路。那么这个boosasting和我们的一个dagon。
其实在我们的现在的一些机器学习的模型里面,其实就是很常见啊,或者说有一些具体的一些体现啊。我们的一个具体的在我们的随机森林,随机森林这个嗯继忆学习模型里面。
我们其实就是可以对我们的一个具体的一些数据集来完成这样的一个操作。我们对我们的数据集呢对它进行一个采样,也就是我们的把我们数据集按照行和列做一个采样,然后呢把我们的数据集采样完成之后呢。
然后分别把它训练我们的数模型。训练了数模型之后呢,然后通过我们的模型将它进行投票,然后得到我们最终的结果。这就是我们的一个具体的一个这种嗯随机森林一个非常简单的一个例子啊。森林。森林是什么?
森林就是多棵树,多棵树,对吧?树多了就成了森林了。那么这个地方其实就是字面意思啊,我们每棵树做一个决策,然后最终将这多棵树的一个结果把它进行一个继承。好。那么我们这就是一个随机森灵的一个案例啊。然后呢。
我们接下来看一看我们的具体的一个代码实践啊。这个地方我们来看一看。我们的具体的一些特征编码的一些代码,我们都是给大家准备好的啊,就是说直接是用pandadas可以完成的。
直接通过我们的padas来可以完成的。然后呢,我们的一个padas呢,这个地方其实就是。呃,我们的paus它可以首先创建我们的数据集,创建我们的数据集完成之后呢。
然后接下来就可以得到我们的一个具体的一个表格。表格完成之后呢,我们就可以对它进行一些相关的操作啊。比如说进行一个one hot。对吧把它转转变成这相关的一个往后。
然后呢或者说通过一个label encoder label encode对吧?把我们的原始的这一列把它转变成这种数值类型的。或者说或者说这种顺序编码在我们的这个代码里面都是帮大家实现了的啊。
帮大家实现的。所以说如果大家想要领取我们的代码的话,一定要加我们的群啊,一定要加我们的群。然后在我们的群里面,我们会把我们的代码和课件发出来。好,然后呢我们的一个具体的一个模型呢,其实。
这个地方我们的随机森林呢其实在SK learn里面也有具体的实现啊,在SK learn里面也有实现。在也就是在我们的SK learnasseemble的一个模块里面,还是有具体的一个实现的。
在这个实现的过程中呢,我们直接是定义好我们的模型,然后可以完成让我们的模型完成一个训练的过程,然后完成一个这个地方我们也可以将我们的一个特征的一个重要性可以打印出来。
这个地方的特征重要性呢就是我们的模型认为哪些特征是比较重要的,哪些特征是比较重要的啊,就是特征重要性。好。这是我们的一个随机森林。当然这个代码呢其实还包含很多的一些其他的内容啊。比如说其他的数模型。
比如那HGBM以及嗯这个叉Gbos,其实都是在我们的这个代码模块里面是有的是有的对。然后呢,我们接下来呢花一点点时间给大家讲一个这个房屋的一个就是说也是一个具体的一个案例啊,它的一个案例呢其实也很简单。
就是呃做一个房屋的一个价格和这个热度的一个预测。我给大家看一个这个地方。在我们的数据集里面,其实是有很多的一些字段的。有一些字段呢它是不就是说有可能是非规整,或者说是这种文本类型的。
那么对于这种文本类型的一些具体的一些怎么对它进行题取特征呢?其实你可以参考这种结构化的一些数据集的体育特征,我们统计一段文本有多少个单词,我们统计一下这个图片,它到底有多少张图片,对吧?
或者说统计一下我们的具体的一个。日期它的一些年系年月日信息,这个都是可以给它提取的。当然在我们做特征工程的时候,或者说特征编码的时候,我们其实不仅仅是可以做一个编码,我们还可以提取一些新的特征。
在我们上节课其实也有同学问到了,我们能不能提取一些新的特征呢?比如我们有了房屋的一个价格以及房屋它的到底有多少个卧室的情况下,我们就可以算一下,平均每个卧室,它平摊的一个价格是多少?
或者说我们有了这个房屋的一个卧室的一个个数和它的一个就是。它的一个呃就相当于是厕所的个数,我们就可以算出它相当于是总共有多少个房间。对吧通过这样的一些操作,其实都是非常有意义的。
而且它能够构建得到一些新的特征。这些新的特征呢,它在我们的原始数据集里面是不存在的。好,那么如果各位同学想深入学习啊,这些都是呃对大家非常非常有帮助的,非常非常有帮助的。
它其实就是我们具体在做一个案例的时候,我们对数据级做一个编码,然后做一些构建特征的操作。好,我们继续。当然在我们的一个数模型里面,我们也可以将我们的数模型结合这种bos性的思路。
让让我们的数模型呢让它不断做一个礼合。第二个树基于第一棵树做一个礼合,然后不断进行一个呃礼合。然后最终呢可以将我们的多棵树的一个结果进行一个继承。好。那么我们这个具体的一个知识点呢。
其实也就是说两天的知识点也给大家讲完了。那么我们接下来给大家总结一下啊,稍微总结一下。第一个呢就是说需要大家知道第第一点,特别要记得第一点啊。特别是小白同学啊。机器学习和深度学习的一个区别是什么?
这一点一定要记住,我们其实这两天的一个知识点都是在讲机器学习,他没有讲深度学习。深度学习其实现在也非常火热,而且是非常建议建议大家学的。但是呢需要知道的一点。
就是说机极学习和深度学习它是有一个范围的一个划分的。深度学习它是机极学习之中的一个一种。深度学习,它是以这个人脑神经元网络结构为代表的一种机忆学习算法。它是记忆学习算法中的一种。
所以说呢在我们学习这个具体深度学习的时候,如果你想要学,那么你可以先学习一下记忆学习的一个基础,然后再去学习一下深度学习。你不要将两者对立起来。其实这两者它是存在知识点的交叉的啊,它是存在交叉的。
在我们的深度学习里面,也有我们今天所讲的这个提升学习的思路的。好,这是第一点。第二点呢就是说有很多同学在我们的上节课学完之后,人家就问我,就是说我们学习这个具体的与记忆学习有什么一些具体的一些路径啊。
首先呢我们这个地方在我们的一个具体的一个。哦,在昨天给大家介绍的课程里面,其实也有一些路径。当然这个地方我给大家抽象一下。第一个呢可以学习一下这个机忆学习的一个理论。
特别是机忆学习模型的一些原理和它的模型的构造过程。第二部分呢可以学习一下证明模型它常见的一些应用。以及它的一些模型的优缺点。也就是说当我们遇到一个场景之后,我们怎么知道是选择一个模型。
第三个呢就是深入去挖掘我们的一个模型,它的应用的案例。对,这个其实就是不断学习、深度学习以积极学以及积极学习的一个步骤啊,按照这三步走就行了。然后呢,我们呢具体的一个建模的流程就是提出问题,准备数据。
分析建模的出结论。这个流程大家也可以记一下。好。

那么在我们学习的过程中呢,其实很多同学会遇到一些相关的问题啊,或者说小白同学找不到我们的学习的资料啊,或者说遇到没有老师进行指导啊。
那么我们现在呢在我们的一步社区和我们的7约在线呢开设了一门课程叫做机器集训营。现在呢这个集训营也是开到第1六期的。这个集训营呢,其实它是非常干货的。因为在这个集训营里面呢。
我们今天和昨天所讲解的所有的内容以及我们所有的实践代码都是在我们的集训营里面是有的。这是第一点。第二点呢是我们的集训营呢,它是包含了很多的实践的项目。在这个实践的项目过程中呢。
它包含这种比如说这种CV类型的项目,以及我们的问答类型的项目,比如或者说这种聊天机器人啊,或者说这种推荐系统的项目。那么这个些具体的项目呢,其实在可能你自己去学习。你不知道它到底如何去进行实践。
也不知道它到底就是说在。

间的过程中会有什么一些难点。所以说我如果大家有就是说在学习的过程中,不知道学习的路径,不知道我们学习这个具体的这个它的侧重点,或者说不知道如何去学习这些项目。
都是非常推荐大家就可以了解一下我们的机器学习集训的。那么这个集器云呢,其实它的一个办着个集训营的目的,其实就是希望各位同学通过我们的集器云能够入门我们的人工智能。
而且呢通过我们集器云能够拿到比较好的一个offer。而且呢我们的往期呢其实有很多的一些同学通过我们的集训云呢都是拿到很高的一些互联网的一些offer的。对。
那么如果各位同学想对我们的学信想要啊就是说报名的话,都可以在我们的群里面聊,就是私聊我们的一个就是说班主任啊,然后可以做一个更加详细的一个介绍。我们的一个机器学习的集训营呢。
其实它所涵盖的知识点是非常多的。从我们的一个具体的一些机器学习的一个原理,到实践,再到深度学习,再到CVNRP3那个方向的一个具体的项目实战,都是非常非常完备的。
其次呢这个集训营它是包含这个具体的实践平台的。有我们的一个GPU的云平台,所以你不用担心里面有这个计算资源。只要你报名的集训营呢,都是有这些相关的一些实践的环境。
而且呢我们都有这个助教和老师在我们的一个群里面给大家进行答疑。做一V1的一个辅导。我们的一个具体集训营呢包含的项目是非常多的。比如CV的车道性检测呃ARP的智能问答推荐系统的商品推荐。
以及我们CV的大规模这个形程重事别的一些项目。对嗯,老师基础比较弱,能学会吗?是可以的。因为因这个集训营呢,它是包含的一些基础的一些python知识在里面的。它是包含python的。
所以说如果你是之前没有python的一个基础,你也不用担心啊,这个我们的所有的内容,或者是说跟机器学习相关的一些内容,都在我们的一个具体的一些集训营里面是有的。双十一有什么优惠?
我们现在报名我们的课程就是有1个1600的一个优惠报名。我们刚才的一个班主任也发了。对。然后我们的也有这些实训的项目啊都是非常非常多的。比如基于SK,基于来GBM的,基于ten flow的。
以及基于我们的CV的这些实训项目呢,我们在集训里面也都是有的。然后这些呃根使用医学数据完成那个分类,或者说对我们的一个。就是一些行人做一个目标检测,或者说做一个新闻分类的一些相关的操作。对。
在我们集训营里面都是有的。然后呢,我们的集训营里面,其实很多的一些呃历史的学员呢都是很多都拿到很比较好的offer。然后大都是起了一些分享的。如果大家感兴趣的话呢,也可以看一看我们的网届的一些学员。
他的一个具体的分享啊。对,我们在这个双十一的活动期间呢,有就是说具体的一个优惠啊,对吧?我们的班主任也发了领取,可以领取1600元的一个优惠券,不过只有5个名额。对,如果大家感兴趣呢。
都可以在我们的群里面就是说艾特我们的班主任啊,或者说私聊我们的班主任。对我们的历史的学员呢,其实是很多都是拿到比较好的一个offer的。好。那么我们的一个具体集训呢,也有这个结业证书。
是由企月在线和阿里云填持的这个具体的一个结业证书。然后呢,其实也是非常非常有就是说有价值的。好。那么我们第二天的一个知识点和我们的一个课程内容呢就到这儿。我们今天呢也有一个抽奖的环节啊。
我们今天的一个抽奖问题啊,今天的一个抽奖问题是我们的一个这个问题啊。我们的一个集成学习有到底有哪些分支,或者是说集成学习有哪些方法。那么如果大家知道我们的这个具体的一个答案的话呢。
也可以在我们的一个微信群里面来进行参与啊。微信群,大家如果还没有加入我们的微信群的话,可以加一下。然后呢,第一位在我们的微信群里面回答问题的同学就可以领取我们西部数呃这个西部数据的一个硬盘。一个啊。对。
这个是相当于是比我们昨天的一个。哦,就是呃它的一个书的一个价值更高的啊。好,我们已经看到有同学发了啊。对。那么就是我们的一个这个CEDTTEK同学是啊领取了我们的一个奖品了。对。
那么大家对我们的今天所讲解的一个内容有什么问题吗?对,大家还没有加群的同学一定要加一下我们的群啊,扫码加群。我们的一个代码和我们的一些具体的一些课件呢,都在我们的一个群里面发给大家。
大家对我们的今天的一个课程有什么问题吗?嗯,大在我们的一个具体的机器云里面呢,其实呃这个有我们的具体的一些介绍啊。嗯。对,这是哦sorry啊,这是我们的一个现在的两天的一个课程。对。
然后呢如果大家想要了解我们集器云的一个具体的一些,就是这些资料啊,都可以在我们的一个具体的一个微信群里面私聊我们的班班老师。嗯,视频中的数据集怎么获取?
我们会把这个数数据集的一个获取方法在我们代码里面写好的对。对,大家如果想要继续详细了解我们集训云的,一方面呢可以私聊我一下我们的班班老师啊。另一方面呢就是也可以在我们的一个看一下这个链接。


这这个链接网现在打不开了。

你可以在我们的这个网页上面找到啊继极学习继训习。现在报名是我们的有优惠的啊,现在报名是我们有优惠的,双十一的双十一的一个优惠的。

对,那么如果各位同学对我们今天的一个课程内容有什么问题的话,也可以现在提出来啊。对。对,大家对我们今天的课程内容有什么问题吗?也可以在我们的微信群里面进行提问啊。
对我们的双十一现在报名我们的一个机器云的话,是有我们的1个16001600元的一个优惠的。如果大家想要报名的同学,或者说想要跟我们一起继续学习的同学啊,一定不要错过这个机会。
这个机器云其实包含的一个知识点是非常多的,而且它的学习周期是应该是到半就是说不是几个月,是半年啊,这是半年的,不是一个短期的课程对。大家如果想要了解或者报名的同学啊,一定要去联系一下我们的班主任。
仅有55个优惠名额啊,就说我们现在双十一的这种。优惠价格。对大家如果有问题的话,可以现在提问。好的。本科生学习这个适合就业吗?适合的适合的。只要你跟着我们的一个节奏来学的话,很非常适合的。对。
很多的一些项目,它不需要很多的一些基础啊。对你按照我们的一个这个地方其实。呃,一方面我们昨天和今天所讲解的内容都在我们的一个集训里面。对。嗯,你可以按照我们的学习这样一个流程来学。嗯,大专呢。
这个其实也是有可能的也是有可能的对。深度学习学过之后,将来找哪类工作?深度学习学完之后,一方面你可以找哦算法开发,或者说大数据平台工程师,或者说数据分析都是可以找的。就是跟IT沾边的。
特别是跟数据科学、数据挖掘这种记忆学习沾边的都是非常适合的。对,大家还有问题吗?在我们的集训营里面,其实有深度学习,有机忆学习啊,所以你又不用担心。好。大家有问题的话可以提问啊。对。
或者说大家后续呢也可以在我们的一个微信群里面进行一个提问。也都可以的。对,我们现在的这个集训营呢应该正在火热招生啊,因为我们的名额也是有限的。如果大家想要继续学习呢,可以跟着我一起报名啊。
我们的这个集训营呢,现在第16期应该是在我们的12月份开课啊,就是说12月份开课。对。而且呢如果是按照我们的节奏学习完成的话,你有我们的老师呢给大家推荐或者说类推相关的一些岗位啊,都是可都是可以的。好。
大家还有什么问题吗?好,我看大家也没什么问题啊,大家后续有什么问题呢,也可以在我们的一个微信群里面进行提问。好的,那么我们今天的一个直播就到此结束啦,也谢谢各位两天的一个陪伴。好的。
那么我们今天的一个直播就到此结束,谢谢各位。


人工智能—机器学习公开课(七月在线出品) - P27:手把手带你挖掘电商用户行为 - 七月在线-julyedu - BV1W5411n7fg

hello,各位小伙伴。😊,大家晚上好。😊,OK啊,那么呃今天晚上呢呃主要是呃我们企业在线跟CSDN啊联合来做这样的一个公开课,那么公开课的一个主题呢。😊,手把手带大家去完成一个什么呢?电商用户行为呃。
分析也好啊,数据挖掘也好啊,OK啊,都是差不多的一个概念啊,主要就是带大家来熟悉一下呢,我们整个这个数据挖掘它的一个基本的一个流程啊,流程OK啊,那么接下来呢给各位小主汇报一下。
我们今晚要做哪一些这样的一个内容啊,我们今晚的课程安排呢,一共分为三个环节。那么第一个呢。项目的讲解啊,第二个呢啊抽奖对吧?第三个呢答疑啊,那么抽奖呢我会穿插在这个项目讲解的过程当中啊,那么这个答疑呢。
我们放到最后啊,最后来集中的给大家来进行。答疑啊,那么今天的奖品有哪一些是吧?啊,这下面我简单罗列了一下啊,呃,有几个课是吧?数据分析实战的5个,然后呢首推MAL的5个OK啊。
这些课程呢大家可以直接到7约在线呃这个呃网站上官网上啊,直接点开啊,可以去搂一眼啊,搂一眼。然后还有什么呢?书对吧?啊,这里面我就截了几张图片哈,一共有这么几本书,对吧?包括这个人工智能的啊。
机器学习、理论、导演啊,包括算法导论啊三个啊3个。😊。


OK然后还有一个什么呢?VIP月卡啊,这个相当于在这里面应该是啊价值最贵的对吧?啊,最贵的对吧?5个名额,那么这个VIP里面哈,一共有有好几百个啊,好几百个课OK啊,大家可以在一个月的时间内啊。
多听一听。那么如果大家对这个机器学习这一块啊,有比较强烈的一个兴趣啊,或者说想了解一些这方面的一个内容。OK啊,可以加这个右上角杨老师的一个微信啊。😊。

他会给你做一些,比如说职业规划呀,对吧?啊,课程那些引导。那么课程这一块呢,大家可以直接到企业在线官网呃,来进行一些,比如说机器学习机运营方面的一些课程的浏览。OK啊。
那么后面呢我会给大家简单的去讲一下啊,讲一下O那么回归到我们本次课程的一个主题,对吧?啊,来完成一个电商用户行为的一个。挖掘。😡,OK啊,那么呃。😊。
这个课程呢其实跟机器学习呢啊是有非常强的一个关联性啊。那么因为我们整个的数据挖掘跟这个机器学习啊,它是密不可分的。那么我们整个项目这一块呢啊是通过一个啊电商数据。那么这个数据呢是一个比赛的一个数据。
对吧?我们拿到这个数据了以后,怎么对这个。里面的数据来进行一些分析,对吧?然后呢达到我们的一些目标啊这样子的一个动作。OK啊,那么通过这样的一个案例呢,来梳理一下。
比如说我们对于这个呃数据挖掘啊啊机器学习它的一些呃流程啊。OK那么比如说从我们的数据分析呀、特征选择模型预测啊,最后呢得到一个决策性的这样的一个结果。OK啊,这样一整套流程下来。
那么啊虽然说我们今晚只有一节课,对吧?时间也不是特别的长啊,那么呃还是希望呢通过呃。这样一个多小时的一个时间,对吧?来呃通过这样的一个项目给大家带来一点小小的一个收获。OK啊,那么啊废话就不多说了。
我们就来开始今晚的一个课程。OK啊,那么。😊,往下来走啊那么其实首先第一部分啊,我们呃给大家先梳理一下我们数据挖掘的一个基本的一个流程啊。那么我们把这个流程OK了以后,然后呢,我们比如说拿到数据了以后。
我们知道该怎么去做这样的一个事情。


OK那么我们先回顾一下啊,或者说啊什么叫做数据挖掘。啊,什么叫做数据挖掘?其实这个呃概念啊啊有很多了,对吧?啊,看你怎么去理解。那么呃我理解的数据挖掘是什么呢?啊?其实就是一种泛化规律,对吧?
比如说我们从过去大量的数据当中去进行一些总结,那么总结出来某一些泛化的规律,那么这个规律呢可能有不同的这样的一个形态。比如说有呃类似于比如说什么假设函数,对吧?啊,可能是我们计算型的这样的一些模型。
比如说还可以什么从这个X啊到Y的一个映射啊,也可以是比如说是啊规则模型啊,我们比如说在这个机器学习集训营里面啊,会讲到这个什么数模型,对吧?啊,角色数啊等等。
那么我们为什么要来学习这样的一个数据挖掘这样的一门课程啊,其实呃大家应该也会发现啊,就是说现在对于数据这一块啊,企业的一个重视程度,啊,都会很高很高啊。
那么数据挖掘呢主要是呃比如说我们可以帮助企业去提取数据中嗯,它的一些呃商业价值,对吧?主要提高企业的一个竞争力。那么我们用这个数据挖掘能够完成什么样的一些呃事情啊,或者说它的一个任务有哪一些。
比如说我们可以完成一些什么分类呀啊预测呀,还有一些比如说像什么聚类分析呀啊关联规则呀,还有一些什么呃类似于什么偏差检测啊,智能推进啊推送啊等等啊这样的一些方法。啊,其实啊数据挖掘它本身是一种什么呢?
数据驱动的一个啊,你可以理解为是一个解决方案。那么所以在这个过程当中呢,我们要关注的点就相对来说就比较多了。那么像下面啊可能列出来123456啊,6个这样的一个呃大的一个框架。Okay。
那么呃除了说关注我们数据本身以外啊,那么呃其实我们还需要去关注,比如说数据的一些规律啊,数据的一些规律,还有它的一些模式啊,包括我们后面会呃这个关注这个模型这一块算法这一块啊。
包括模型的选择呀啊模型的调优啊啊等等。拿到我们解决方案后,哎,怎么去完成后续的这样的一个部署,还有什么呢?还有这个呃比如说监控啊,部署的一个监控,还有一个系统的维护等等。OK啊。
那么下面呢啊这我给大家列了一个大致的啊我们整个数据挖掘这一块的一个标准的一个基本的流程。OK啊,包括这个目标的定义,然后是数据的采集,数据的整理,包括啊模型的构建,对吧?然后呢这个模型的评价啊。
最后模型的发布。OK那么这里面又涉及到很多小的一些呃小的一些点啊,小的一些点。OK啊,这里面我们可以稍微的来扩展一下啊。比如说首先第一个哈我们目标的定义这一块,对吧?哎,我们定义我们挖掘的一个目标。
对吧?那么我们针对具体的数据挖掘这样的一个应用的一个需求。那么首先呢其实我们就需要去明确这个我们目标是什么,对吧?或者说我们明确本次的一个挖掘目标是什么?然后系统完成了以后呢。
哎能够达到什么样的一个效果。啊,这是我们需要去思考的对吧?那么因此呢我们必须去分析。比如说我们当前的一些应用的领域,对吧?比如说哎我应用中的各种的,比如说什么知识呀啊,还有一些应用的目标呀。
包括了解相关领域的一些情况,对吧?熟悉我们的一些啊比如说背景知识啊,对吧?或者说啊调研一些用户的需求,对吧?那么要想要充分的去发挥我们这个数据挖掘的一个价值呢,啊,必须对我们的目标。
要有一个非常清晰明确的定义,也就是什么?你想要干什么。啊,你一定要把这个先搞出来,到底想干什么,要不然你拿到一堆数据以后,可能你就呃无厘头啊,可能就不知道从哪儿下手啊。
那么首先啊你一定要先要有一个清晰明确的定义,然后呢。才知道下一步往哪走。那么呃举个例子哈,比如说以我们今晚的例子为例,对吧?我们今晚是讲一个电商企业的一个用户行为数据的一个挖掘。
OK啊那么其实我们就可以呃定义几个目标对吧?啊几个目标。比如说电商里面大家拿到这个数据以后啊,一般比如说我们要实现商品的什么智能推荐啊,智能推荐来帮助我们比如说呃这个这个几方共赢吧。
比如说哎客户能够快速的找到自己感性的兴趣,感兴趣的这样的一个商品,然后同时呢呃比如说这个这个这个也确保我们推荐给用户的这个商品,也是比如说企业所期望呃,比如说给到用户的。
那么实现比如说这个企业和用户之间的一个呃类似于双赢的这样的一个效果,OK那么还有什么呢?比如说我们还可以对用户来进行细分,对吧?我们了解不同的用户他们的一些比如说特征,对吧?
比如他们的消费特征啊购买特征啊O然后呢分析这些客户他的一个价值优先级,对吧?然后哪一些是需要重点关注的,那么对于不同的用户,我们可以采取不同的营销策略。对吧比如说他看了看了一个商品,然后比来比去,对吧?
哎,可能是因为价格问题,对吧?那我们就咔给他一张优惠券啊,那么呃这个方法有很多了啊有很多。那么我们可以呢将优先的这些资源集中到价值更大的这些用户上面,然后实现什么呢?比如说精准营销,对吧?
那么基于我们的还有什么呢?比如说历史数据啦啊,历史的一些销售情况啊,然后对商品来进行一些预测,对吧?那么这里面可能需要去注意的一些点,可能就是一些特殊的一些什么节假日啊啊等等啊,这些基本的一些内容。O。
然后还有什么?第二部分,比如说我们的数据采样这一块。那么数据采样哈基本上呃在我们明确了明确了我们需要进行数据挖掘的目标以后。那么接下来呢,我们就要从这个业务系统中哎抽出来啊。
或者说抽取一个跟我们目标挖掘相关的样本数据的呃字集。OK来做这样的一个呃数据采样啊,那么在这里面哈问大家一个问题啊啊,问大家一个问题。比如说我们要抽取数据,那么抽取数据的标准是什么?OK啊。
这里面有没有同学啊知道啊,比如说我们呃要从业务系统中去抽取一个啊跟我们目标挖掘相关的这个样本数据的一个子集,对吧?那么。我们抽取这个数据的标准。是什么呢?对吧?啊,它肯定是有一些标准,你不能说呃随便抽。
对吧?啊,随机的啊,那你得到的结果啊可能会相差会比较大啊,相差会比较大。OK啊,有同学知道的啊,可以呃在我们这个右侧的评论区啊来进行这个文字型的呃这个这个这个呃交流啊交流。OK啊,我重复一下对吧?啊。
问题是什么呢?对吧?我们把目标啊定义好了,对吧?要完成什么呢?啊,比如说要拿数据了,那么拿数据肯定是从我们当前的这个业务系统中面去抽,对吧?那么抽什么样的数据,他有没有一个标准。OK啊。
如果有知道的同学呢,可以在右侧的聊天对话框来进行交流啊?啊,其实这个标准呢我们在呃企业里面啊,它是有几点啊,我们需要去遵守的啊。那么这里面我给大家去讲一下哈。
那么首先第一个哈就是相关性啊相关性你出具的数据要跟你的目标啊要有一定的相关性。第二个呢。可靠性啊可靠性。第三个是有效性,而不是说我们拿一些全部的数据全部都拿过来,对吧?那么我们通过对这个样本数据的一个。
比如说精选啊,我们不仅能够减少数据的一个处理量啊,然后呢还可以帮助我们去节省我们的一个呃系统资源啊,系统资源。OK啊,这是我们在这个抽取数据的时候啊,需要去注意的一个地方啊,那么还有一个什么呢?
可靠性啊,可靠性就是说我们需要去嗯找规律性,更加呃,比如说凸显。这样的一些数据来进行采样,而且呢一定要严把这个质量关OK啊,不能忽视数据的一个质量。OK这是这个这个这个。抽取数据的一些标准啊标准。
OK那么再问大家一个问题哈,比如说我们对于数据的抽取这一块哈啊除了说我们的一个标准以外,那么还有什么呢?还有方式,对吧?哎,那么我们有什么样的一些抽取的方式呢?啊,有没有同学知道了啊。
知道了可以在右侧的聊天对话框啊来进行提问。😊,啊,或者说交流啊,也不能说提问了。啊,抽样的一个方式哈啊,其实这个也有很多种啊很多种。啊,可以说出一种、两种、三种、4种、5种。OK啊。
那么啊还是我来说吧啊,那么比如说哈我们常见的有哪一些,对吧?比如说随机的啊随机抽样,那么呃在我们呃采用随机抽样的方式这种情况的时候啊,那么数据集中的每一组观察值。那么啊都有可能被抽到啊。
都有可能被抽到啊,这是随机的。那么还有什么呢?比如说我们还可以用这个等距的抽样啊,比如说我们按照多少的比例来在嗯。😊,多少条数据里面啊,或者说在多少组这个数据里面来进行等距的一个抽样。
那么还有可能比如说分层,还有这个分类啊,还有一些,比如说什么按顺序来进行抽样啊,都行啊,都行啊,分层抽样。对啊,这个呃python啊tyle这个同学对吧?应该是对这方面是有一定的了解。OK啊。
那么呃这是第二部分啊,数据采集这一块对吧?那么还有什么呢?数据的一个嗯。其实这里面哈啊数据的一个整理这一块啊,应该是我们在数据挖掘里面啊比较核心的一块这样的一个内容啊。因为你数据处理的好坏。
会直接影响到你后续的一个结果啊,因为其实模型这一块呢呃差异化呢并不是特别大啊,模型化差异并不是特别大。那么像一般哈不管你是来打比赛呀,或者是在我们实际的一些呃落地的一些工业界啊场景里面,对吧?啊。
那么呃。其实更多的我们的工作啊是在做这样的一个数据整理这一块。那么数据整理这一块呢啊比如说我们有探索性的数据分析,对吧?数据的清洗,对吧?还有一些比如说数据的一些预处理啊等等这样的一些工作。
那么比如说哈数据的探索。那么我们为什么要来做这样的一个动作?对吧这里面其实就要反过头来去往前再推啊,那么我们前面所讲的哎数据取样对吧?那么多少呢多多少少啊,就是说你在取样的时候,不管是采用哪一种方式哈。
都会带着比如说哎我们如何去实现数据挖掘目标的鲜艳的认识来进行这样的一种探索。那么当我们去拿到了一个这样的一个样本集以后。它是否达到,比如说我们原来设想的一个要求,就样本中哈。
它并没有什么明显的这样的一些规律跟趋势啊。OK啊,没有这样的一些啊明显的规律跟缺失。啊,比如说哎这里面有没有出现过从没有你想到过的一种数据状态啊,属据之间哎,到底有没有一些相关性,对吧?啊。
他们可以区分成什么样的一种。比如说类别啊,这些呢其实都是我们在进行这个数据探索的时候要做的一些事情。那么对于抽样的一个样本数据呢来进行。比如说探索呀啊审核呀啊必要的一些加工处理OK啊。
这是都是我们最终来保证数据挖掘模型质量这一块非常非常重要的一个环节。啊,非常非常重要的一个环节。OK啊,然后后面比如说还有一些数据的预处理,对吧?那么数据的预处理这一块呢。主要比如说呃降维啊,对吧?
当我们采样数据维度过大的时候,哎,我们如何进行一些降维处理啊,包括唉我们采样的时候会发现有一些缺失值,对吧?那么缺失值处理的时候,对吧?怎么去办啊,你是填充还是直接把它给干掉,对吧?啊。
那么由于我们采样中啊啊,有很多很多的这样的一个噪声啊,会导致我们这个数据集可能不完整啊,甚至不一致的这样的一些呃情况,那么对我们数据挖掘所涉及到的数据对象OK啊,我们一定要对它进行什么呢?
预处理这样的一个动作。那么怎么去呃或者说如何对我们的数据来进行预处理啊,或者说改善我们数据的一个质量来达到。比如说哎我们最终想要的呃某一个结果。OK这个是需要大家在进行这个数据预处理的时候。
我们需要去思考的一个问题。啊,思考。那么呃这里面啊再跟大家去进行一些啊,比如说再问你们一个问题啊,那么比如说我们数据预处理吧啊,数据预处理包含哪一些这样的一个动作啊,有哪一些动作,对吧?
这里面啊大家可以在这个右侧聊聊天框啊来进行交流。就是说我们数据预处理这一块,对吧?唉,你常见了有哪一些啊常见有哪一些?嗯。比如说啊以我啊我日常中会用到什么呢?比如说啊首先从第一步开始啊,数据的一个筛选。
对吧?完事以后,数据的比如说转换啊,这里面可能涉及到一些数据类型的一些转换啊,变量的一些转换。然后呢,哎我们看一些缺失值对吧?来对缺失值来做一定的处理。然后对于比如说坏数据的一些处理。然后呢。
哎最后比如说把这个数据标准化啊等等。OK啊,就是对于数据这一块。那么呃大家如果呢想要对这一部分,就是说呃数据怎么去呃探索性的进行一些呃分析啊,怎么进行一些呃处理啊清洗啊等等啊这样的一些动作。
大家可以比如说啊看我们企业在线机极学习集训营。那么这里面呢会从零带大家去完成这个内容啊,包括像n呀pandas啊这样的一个呃基础的一个内容,包括可视化那么math啊啊等等啊。
来完成什么的数据分析这一块的呃内容OK啊那么。数据的整理OK了以后,那么往下来走啊,就建模了,对吧?啊,建模啊,那么可能很多人都觉得建模这块很重要啊,确实很重要啊,但是。
那如果说你是从事这样的一些数据挖掘呀啊,或者说呃。比如说这个这个偏工业界的一些东西,其实更多的是你的业务。更重要啊,比这个我觉得比这个呃模型本身哈啊要重要很多。
因为更多的你是需要去根据你的业务场景去解决问题的啊,因为模型哈,毕竟比如说啊不管是我们这个传统的这个啊监督无监督啊,还是一些新的一些东西啊,包括像现在的什么深度学习啊啊等等等等啊。
有很多很多层出不穷的算法出来啊,但是啊最终他们要做的事情啊,还是去解决这个问题OK啊,那么我们一定要去从问题本身去出发。那么这样可能会好很多。OK啊,那么我们回过来来讲这个呢构建。啊。
模型的一个数据建模这块啊,构建我们的一个模型,对吧?那么啊其实这个就比较简单了哈,就是说你需要去思考什么呢?哎,我数据挖掘应用中的一个问题,对吧?你到底要干啥啊,你是分类呀,还是聚类呀。
还是关联规则呀啊等等啊,选哪一个算法来进行模型的构建啊,这是也是属于我们数据挖掘里面比较核心的一个动作,对吧?你首先要把问题给搞清楚。然后呢,选哪一个模型算法,OK啊,这就是呢经验了啊。
这里面会涉及到一些经验。然后模型的一个评价。那么模型的评价呢,那么就相当于什么呀?哎,我选了某一个模型,或者说我在进行目标定义的时候,对吧?我就需要去定义标准,达到什么样的一个标准啊。
才符合这个这个这个呃才能OK对吧?那么这个时候你需要去设定什么呢?评价的标准啊,然后做一些比如说优化,对吧?你可以换模型啊,多模型的对比啊,也可以在模型本身来进行一些优化啊等等OK啊。
最后就是什么呃模型的一个呃发布啊啊上线呢,然后呢它的一些呃重构啊,也就是说它的一些维护。那么其实整个数据挖掘这一块呢啊呃更多的更多的是在一个反复探索的一个过程啊,因为我们在实际工业的一些场景啊。
不可能说哎你咔从头到尾搞一遍就完事了啊,可能我们会回过头来再到第二步或者再到第三步啊,再来反过头来来不断的来进行验证啊,反复的去探索这样的一个过程,对吧?哎。
我们怎么去帮助我们所在的这个企业从数据中去啊,比如说啊洞察商机啊,怎么去提取价值啊,这是目前所有企业都关心的啊,比如说像很多这个推荐方向的啊,这个工程师推荐方向的行业专家对吧?为什么那么值钱呢,对吧?
因为他带来了呃很大的价值啊,很大的价值OK那么同样啊我们数据挖掘这一块啊,一样能够为企业带来很大的一个价值。OK啊。😊,呃,那么基本哈它的一个流程这一块呢,我们就过完了,对吧?啊,过完了OK。OK啊。
那么呃其实流程掌握清楚了以后啊,其实大家主要就是呢比如说我们先把这个流程给梳理好了。其实后面的啊这些代码啊很多很多啊很多很多啊,但是呢从我个人来说,其实它并不是重点啊,那么呃代码这个东西呢。
其实呃可以说是固定的啊固定的啊,因为都是一些什么API的一些调用,对吧?那么更多的呢是我们要去掌握这里面的一个逻辑,对吧?哎,我知道怎么样的一个顺序来完成这样的一个内容,对吧?
然后每一个里面可能涉及到哪一些环节。然后呢啊碰到了这些问题以后,我该怎么去处理?OK啊,这是我们需要去思考的这样的一个问题。okK啊,这个这轮okK了,对吧?啊,okK了,那么我们往下来走啊,往下来走。
😊,也就是我们这个项目的一个背景啊,项目的背景。OK然后我们来进入到这样的一个呃项目这一块啊,项目这一块啊,那么项目这一块呢,其实呃它也是根据我们刚才啊我们刚才在过这个呃整个数据挖掘它的一个。
流程的时候啊,基本上呢把我们整个项目这一块的一个整个的流程也就过完了。那么接下来呢无非就是按照上面的流程来做一些细节性的一些呃内容啊,来做细节性的一些内容。OK啊。
那么前面对吧我们的餐前甜点已经做完了啊。那么接下来啊我们进入到我们的一个。主菜的环节。OK啊,那么通过我们实际的电商数据来做数据的分析和挖掘。那么首先哈第一个哈我们先要去了解一下我们当前的一些背景啊。
其实电商这个我们都很熟了哈啊,我们网上购物现在是越来越流行,对吧?那么人们对于这个购物的这种需求呢啊,同样哈也是变得越来越高啊,而且会遇到什么问题啊,有很多这个比如说哎网上上的商品千千万万,对吧?
那么对于我们用户来讲。😊,哎,很好的东西就是推荐算法。给我们带来很好的用户体验,对不对?哎,我们可以使用推荐算法来做一些什么精准营销啊,比如说让这个什么呃呃这个这个头条啊。
还有什么京东啊啊淘宝啊啊等等啊,这样的一些平台得到了呃更大的这样的一些啊发展的一些机遇,对吧?啊,但是呢呃同样哈竞争也很激烈。那么在这种啊,比如说电商平台激烈竞争的一个大背景下面,哎。
我们怎么去呃比如说呃除了说提高商品的质量以外啊,或者说降低商品的价格以外啊,或者说我们平台本身以外啊,那么我们需要去掌握用户的行为来实现什么呢?精准营销啊,实现精准营销,提高效率。那么对于电商企业而言。
对吧?那么我们数据挖掘的一个基本的任务呢?其实哎就从这个电商企业里面,比如说哎我们采集各种商品的一个销量,对吧?啊,比如说呃啊。这些销量信息呀,还有什么成本单价呀啊还有一些比如说呃。
其他同行的一些数据啊等等等等。然后呢,利用我们数据分析的这样的一个手段来实现什么呢?商品的一个呃精准推荐啊,然后呢达到比如说啊促销啊啊,或者说呃这个这个这个呃精准营销,对吧?啊,增加我们的营运能力啊。
为我们的电商企业来降低整个的一个运营成本啊,提供这样的一些啊智能的一些服务支持。OK啊,这是我们项目的一个背景啊,那么这个项目呢,其实主要就是围绕着我们的用户的一个行为,对吧?那么就用户来说啊。
我们就把自己当成一个用户。你在电商这个平台上你会干嘛呢啊,你会干嘛呢?啊,无非就是点开APP吧?点点击对吧?然后看中自己比较喜欢的干嘛呢啊,要么就咔直接支付了对吧,要么有的人有的人想想哎尽管是双十一。
对吧?我等一等啊,我先把它给他么收藏了啊,等到双十一的时候再买啊,然后呢,还有呢,比如说先加入到购物车啊,然后呢呃找我的另一半啊,帮我清一清购物车,对不对啊,就这些行为啊,那么除了这些呢啊。
还有其他的啊,但是我们主要就围绕着啊,这几种,比如说点击啊收藏啊加购物车支付啊。😊,这是4种行为。OK啊,那么我们往下来走。那么这里面啊我们首先啊要来确定我们挖掘的目标啊,挖掘的目标。
那么我们就先来对这个目标来进行分析一下,对吧?那么这个数据呢啊到时候也会给到大家啊,代码也会给到大家。对吧我们先拿到我们user点CSV啊这样的一个文件,对吧?哎,读了一下啊,通过什么呢?
paasok啊paas。斯来读取一下数据,然后我们看一下这个数据的一些基本的一些概况啊,你可以通过head呀啊infer啊啊,还有什么啊discriptO啊。
都可以去查看一些我们这个数据的一些基本的情况。OK那么我们查看完这个数据了以后,对吧?那么在这里面我们可以啊大致的给他去做一些总结,对吧?我们整个数据一共有多少条呢?啊,可以看一下对吧?
一共有呃2000多万啊,2000多万条数据还可以对吧啊,还可以中等数据量啊,中等数据。如如果说再加个零对吧?那么跟我们实际在呃头部电商企业,它的数据量基本上都一样了啊,差不多了,对吧?那么这个呃。
在我们学习过程当中,这个数据量啊算很大了。算不错了啊,O那么还有什么哪一些数据呢?对吧?我们看一下它的一个。呃,这个这个呃有什么user ID对吧?有ite ID啊,有什么用户的ID对吧?还有什么呢?
商品的ID啊,那么其实每个数量啊,这里面都可以去做一些统计啊,就是说哎有多少个用户,对吧?有多少个商品啊,包括这个什么呢?哎用户的一个行为啊,但是用户行为这一块,你一看一2。应该是什么呢?
脱敏以后的结果。对吧啊,我们刚才说是吧,有点击啊,有这个这个这个呃收藏啊啊购买啊OK他应该是把这些行为啊换成我们的一个数字啊来进行一个通明,对吧?那么还有什么呢?比如说。这个地理位置啊。
这里面就很多啊发现什么呢?NAN是不空数据了啊,有空数据对吧?啊,一会我们怎么去办,然后还有什么呢?我们这个啊商品的类目,对吧?哎,它属于哪一个商品对吧?手机呀啊,还有什么其他的呀等等。
那么还有他的一个什么时间啊时间OK完事了以后,对吧?我们对这样的一个数据呢,有了一个基本的认识了以后,那么我们就哎哎想对吧?哎我们今晚到底要干什么呢?啊,根据我们现在已有的数据啊。
我们要来定一个目标目标就是什么呢?我要预测下一个时间日期,我们用户对这个商品子集的一个什么比如说购买情况啊,或者说购买的数据啊,来做这样的一个预测啊,来做这样的一个预测。啊,这是我们的一个任务,对吧?
那么哎我怎么判断你这个任务到底完成的好或者是不好呢?对吧?啊,这里面就有评价评估的一个标准啊,那么像上面啊,我们在做任务的时候啊,其实呃需要去做什么呢?啊,划定问题啊,划定问题。
那么需要去知道我们最终的目标是什么?也就是说哎我知道是什么样的一个问题,怎么去解决,哎,达到什么样的一个效果。OK啊,这是你在公司里面存在的一个价值啊存在价值照你进去就是让你去解决问题的对吧?
那所以我们一定要知道哎最终的目标是什么啊,预测下一个时间日期,用户对商品子己的购买情况,对吧?那么我们就可以把这个预测,比如说哎,你可以抛开来看预测问题,我是不是可以看成一个是二分类的问题,对吧?啊。
要么就是买要么就是买不买。就完事了,对吧?搞定,然后我们确定一下样本力度,对吧?比如说我们的user ID啊,艾 ID啊,然后呢我们呃再来选择模型的时候,对吧?啊,比如说我们可以选一些常规的对吧?
逻辑回归啊,GDBT啊,我们今天晚上里面啊用的就是比较常规的。那么后面你可以在这个基础上来进行扩展。那我们可以抽一个模型,对吧?啊,但是呢也别让这个训练的过程太慢了,对吧?
那么如果太慢了呢啊会影响到你的一个工作效率。OK啊。然后标准这一块呢哈,我们就选择F1啊F1啊F1呢,其实就是我们综合考虑。比如说哎通过什么呢精确率和召回率的一个什么标准啊,标准。
这上面是什么呀计算公式啊,计算公式。那么所以说我们要想去获得一个比较好的F1。那么需要去平衡我们比如说推荐的条数还有我们准确率之间的一个什么关系。那么我们用户行为分析呢。
就是可以让哎比如说我们的产品更加的详细清楚的了解到我们用户的行为习惯,对吧?那么了解了以后,是不是我们就可以从哎比如说什么网站呀app呀啊,还有一些其他的一些什么推广渠道啊,等等等等啊,这个啊各种产品。
里面比如说呃存在的一些啊比如说问题啊等等啊,这样呢都可以嘛帮助我们的产品来发掘。比如说怎么去转化,对吧?啊,把我们的页面搞漂亮一点啦,对吧?啊,让这个产品的一些营销对吧?更加的精准有效啊。
提高我们的一个业务转化率OK那这是我们要去做的。OK啊,往下来走。啊,其实呢呃对于这样的一个预测呢啊,其实准确来说啊,你可以往推荐方向去靠啊,往推荐方向去靠啊。但是对于推荐算法这个工程领域啊。
其实我个人的一个理解啊,它的业务程度啊。非常重要啊,超过什么模型算法本身。那么所以说除了我们这个算法本身以外啊,我们需要去关注其他的一些内容啊,比如说这里面我们就涉及到很多的一些业务方面的一些内容啊。
比如说啊像这个用户行为的一些啊分析模型啊啊,对吧?有哪一些啊啊,包括啊可能还会用到什么呢?比如说我们运营里面的,用的什么AR这样的一个模型啊,也有可能会用到。OK啊,那么往下来走啊。
那么数据的采集和整理,这个就比较简单了哈。那么采集这一块呢,我们刚才基本上已经啊因为是现成的数据集嘛,O那么这里面其实我们采集,就嗯不需要去采集了啊,我们直接拿来用就OK了啊。
那么如果说我们自己没有数据,那该怎么办呢?你可以使用一些方法啊,比如说我可以使用爬重啊,但然这个呢啊大家一定要在合理的范围啊,合法的范围啊来进行使用。那么还有一些比如说我去一些公共平台自己去拿对吧?啊。
或者说你可以花钱去一些呃平台去啊进行一些购买啊,等等O啊方法有很多。😊,OK那么我们数据有了以后,对吧?我需要对这个数据呢来进行一些处理啊啊来进行一些处理。那么啊其实呢也就是说啊观察我们这个数据。
就像我们刚才在做这个数据预处理呀啊,包括探索性的数据分析,这样的一个过程里面啊,其实就是放在这个里,对吧?那么在这里面啊我们看到这个数据了以后,对吧?我们通过什么呢?啊infer这样的一个函数,对吧?
来看一下我这里面数据的一些基本的情况,它的一些类型等等啊,那么可以看到啊,我们这里面有一个什么呢?啊,有一个我们的一个。地理位置这样的一个字段,对吧?它的类型是吧?object。
对吧那么其实这个呢啊我们呃用用处不是很大啊,像这个呢一般啊我们就不怎么去用它。因为大多数哈就是说在我们企业里面啊,他都是做了一些加密的处理。啊,而且大多数都是买空啊空的啊,你根本就无法用。
所以说哎像这个啊我们就可以把它什么呢直接干掉啊,没用的东西干掉。那么干掉的时候呢,我们可以用呢jo这样一个函数,对吧?啊,把它直接干掉,对吧?我们轴啊设置为啊我们的这个这个一对吧?
也就是什么纵向的啊纵向。OK完了事以后我们来验证一下是吧?哎,跟上面来进行一个什么呢?对比啊,是不是我们这列啊地理位置这列就已经被干掉了啊,干掉了。然后呢,我们再来看机看一下,哎。
有没有什么呀缺失值对吧?有没有缺失值啊,一看哇塞,真的一个都没有,对吧?这个实际上是不存在的啊,就是说实际企业里面啊,我们多少啊,会有这种呃这个这个这个这个数据的一个怎么说呢?异常啊,异常啊。
不可能说这么完美啊,这个因为是某一个比赛的一个数据,对吧?啊,它是做过处理啊,所以说我们拿到以后是比较OK的。结果显示没有缺失值。OK那么在这里面啊问大家一个问题啊,问题又来了,对吧?
那么当我们的数据有缺失值的时候,哎,我们该怎么去处理这样的一个问题?其实我刚才在上面的时候有讲过啊有讲过怎么去处理呢?啊,可能呃常用的啊两种对吧?比如说我们要么把它给什么干掉啊,要么就什么填充啊填充啊。
其实第二个问题也随之而来,对吧?哎,你怎么干掉,对吧?你干掉的标准是什么啊,一般啊不能超过百分之啊,我们是10%啊,超过10%的话,就需要去做一些呃填充的一些处理啊。
但是一般哈我们正常哈都是需要去做填充的,你直接删除,可能呃会对后面的有一些影响啊,但是啊这个也不是绝对的,像刚才对吧定理位置,这个里面大部分都是空的对吧?啊,或者说一些加密的一些数据。
我们拿到其实也没用啊,所以说呢这个呢我们可以直接把它给干掉。那么还有第二个啊填充对吧?那么填充的方式又有哪一些对吧?啊,这里面有很多了,比如说有什么均值啊方差呀啊,前后左右的一些什么参考值啊啊等等OK。
Yeah。嗯,OK啊那么当然哈啊这里面所涉及到的一些啊知识啊,比如说啊这个n派的一些知识啊,pandas的一些知识啊,OK啊,如果呃比如说怎么去分组,对吧?怎么去合并啊,这样的一些基本的一些操作的时候。
OK啊,大家可以关注企约在线机器学习集训。OK那么这个课呢我们已经推到16期了啊,那么整个课程的体系呢呃非常完善。那么细节部分呢OK啊。跟我们的学员啊有深度的匹配啊,很到位。
那么大家呢有兴趣哈可以到企月在线官网啊,搂一眼啊,搂一眼。我们企月在线呢继续学习集训营课程。OK往下再来走,对吧?那么没有确失值,我们就啊不要处理它了啊,那么往下来走,对吧?啊,来呃,比如说做一些去重。
对吧?那么下面都是些统计了啊,count这样一个函数来做统计来做分组,对吧?我们对于什么 ID对吧?我们用户的ID来统计一下,对吧?还有什么呢?比如说我们对于这个ite ID啊来做这样的一个。
去重这样的一个操作,对吧?哎,我们来做统计完了以后啊,那么我们基本上大概对这里面,比如说哎到底有多少个我们的用户是不是2万个用户对吧?然后呢,有多少个商品,对吧?然后这里面你可以看到有40075万对吧?
啊,有很多很多OK那么往下来走是吧?也就是说我们刚才对于我们的一个用户行为这一块啊,它这里面其实是用1234啊来表示的对吧?那么我们可以把这1234呢赋予实际的一个值啊,实际值。
比如说它到底是干什么的对吧?啊,到底是干什么的啊,比如说有点击啊,比如说这个啊PB我们就把它当成点击了,对吧?
然后这个是当成我们的一个比如说啊收藏购物车啊购买这样的一个动作OK然后呢用这个什么logo进行一个什么值的一个替换啊,替换完了以后是吧?我们在下面可以。通过head啊来看一下。
其实我们这一列下面所对应的这样的一个值呢,就已经被什么替换掉啊,替换掉。OK啊,那么做了一些处理了以后啊,其实这里面啊大家在做替换的时候,除了这个呢local啊,还有什么Iloc啊。
像最早的时候还有什么IX啊,但是这个呃已经被呃废弃了,对吧?我们现在用这个loal啊会更多一些啊更多一些。那么往下来走是吧?我们就再来分析什么呢?我们的一个时间这一块,对吧?
那么大家可以看到我们的时间这一块上面啊是一个什么time,对吧?那么这里面有年月日啊,有年月日,那么我们想要把这个呃给它分开啊,分开分成什么呢?时间日期和什么呢?星期对吧?那该怎么办呢?啊。
下面啊做了一些呃不是这样的一个操作,我们先对它来进行切分,对吧?啊,先对我们time。这样的一个呃特征来做什么呀?切分。那么切切分完了以后啊,我们再来做什么呀?新的这样的一个列,对吧?我么分成了三列啊。
有d有time有 weekO完事了以后啊,你会看到下面会啊出现这三个,也就是把我们刚才的一个time啊,切分成三个部分。那么为什么要来进行这样的一个切分呢?
那么主要哈啊是呃为了便于我们通过时间的维度来进行什么呢,来进行分析,对吧?哎,比如说呃它是哪一天的对吧?啊,它是呃星期几的对吧啊,具体的时间啊是几点对吧?这样呢分析起来会更加的准确。嗯。
OK那么往下来走,就是我们数据分析啊跟这样的一个展示的一个部分啊,其实这一块呢呃。嗯,怎么说呢?啊,我先问大家一个问题吧那么比如说就在我们电商这个领域里面。啊。
电商这个领域里面大家知道哈呃或者说其他领域也可以哈啊知道哪一些用户行为的分析。哎,比如说哎你拿到这些数据了以后,这些用户行为啊,你已经知道啊,比如说有点击对吧?有加购物车啊。
还有什么购买啊这样的一些行为,对吧?哎,你怎么来对这样的一些行为来进行分析呢?对吧啊这里面其实啊需要有一有一些业务背景啊,如果说你不是在电商行业里面可能稍微有一点不一样啊,稍微有一点不一样。
但是啊大体的逻辑还是一样,主要还是根据我们的业务啊,根据业务来。OK啊,那么这里面。😊,嗯。OK有知道的同学可以在这里面啊。😊,交流一下哈,就是说我们嗯有哪一些。
比如说你在你的工作当中对于用户行为分析这一块,嗯,你有哪些分析的方法?🎼比如说啊我们啊今天讲的这个哎,就是买。嗯,比如说用户的行为分析对吧?那么还有什么呢?还有一些呃,比如说行为的事件分析,还有什么。
比如说什么用户的留存呢啊,还有比如说什么转化分析啊啊等等,对吧?那么后面呢其实我们在这里面都会有讲到啊都会有讲到。那么这里面我们也看到哈,我们一共有4块啊,分4块来讲啊。第一个是什么呢?
我们用户的流量分析。流量分析。然后第二个呢是我们用户的消费行为分析。第三个呢是我们商品销售情况分析。然后第四,我们用户的价值分析。OK啊,通过这4个啊这四个啊,其实这里面每个里面又有细分的一些东西了啊。
又有细分的一些东西。比如说啊第一个我们电商的用户流量这一块,那么流量这一块,比如说哎我们是按照什么样的一个时间段,对吧?比如说我们按照月我们用户一个月的PV和UV对吧?啊,或者说我们按照天N对吧?
一个月内每一天的PV和UV是是这个是我们需要去分析的。对吧啊这里面就列了一些对吧?啊,比如说用户一个月的啊,还有什么用户每一天的啊每一天的这样的一个数据。啊,做一个什么统计。OK啊。
统计那么统计完了以后啊,这里面呃生成了一张图啊,那么这个图呢是拿这个mspl label啊画的。那么这里面哈除了说。呃,我们用这个 label啊,你也可以用什么?
比如啊都可以啊来完成这种可视化啊工具有很多O啊那么呃通过这张图完事了以后啊,会得到一个什么呢?啊,得到一个结果啊你会发现有一个峰值,对吧?其他的其实差异性并不它并不太大啊。
这有一个峰值那那么可以看到它所对应的日期啊,日期啊,这里面呃我这是黑色的背景啊啊,可能看的不太清楚啊,而且这个数字有点重叠啊,到时候可以把它斜过来啊,把这个数字啊换一个角度啊写一下。
那么呃其实结果呢是什么呢?这一天啊这一天所对应结果是12月12号啊,12月12号啊,刚好这天有一个活动对吧?双2那么它所对应的PV和UV增加的幅度会比较大。😊,OK然后呢哎过了几天以后又慢慢恢复正常啊。
说明这次活动怎么样,非常成功,对不对啊?引流的效果很棒。嗯。那么呃还有什么呢?还有我们这个啊往下去翻啊往下去翻。比如说什么独立的一个访问量啊,独立的访问量。OK啊。
也就是说我们可以呃对他们进行PV跟UV来进行什么呢?独立的一些分析啊,独立的一些分析。那么往下来走啊往下来走。那么独立的分析这一块呢啊就啊。
针对于每一块吧啊每一块啊它的1个PV还有它的一个嘛UV啊来进行这样的一个内容啊,或者说我们可以针对什么总体啊总体。比如说哎我们整体的一个分析,我们统计什么呢?某一个时间内它的一个总访问量。
比如说一个月的对吧啊,一个月的OK啊,然后呢它的日均呢访问量啊是多少或者说呢我们以这个呢日期为维度对吧?来进行统计啊,或者说我们还可以什么来进行比较,对吧?哎我的一个日增长率是多少啊,给它算出来啊。
算出来,那么同样UV也是一样的啊,UV跟这个啊PV啊算法或者说它的流程上是一模一样的啊,一模一样,对吧啊它的日增长率。然后最后呢啊可能会比如说我们可以画一些图是吧?让它更清晰的展示出来啊。
更清晰的展示出来。那么第二个呢就是这个用户的消费行为这一块啊,那么用户的消费行为啊,这里面我列了几个哈,比如说从这个时间维度来分析我们这个用户消费行为的习惯呀啊,用户行为的转化分析啊。
包括它的一个复购率啊,还有一些什么呀啊它的一个购买跟不购买的一个路径分析,对吧?OK啊,通过这几个方法。OK来完成什么呢?用户消费行为的一个分析。OK那么往下来走啊,其实都一样的啊,通过这几个维度啊。
通过这几个维度,也就是说我们四种行为嘛,对吧?啊,这个呃点击加入购物车对吧?收藏购买啊,就这么四种四种啊,它的PV它的UV啊,它的啊这个这个这个啊通过这个这个一个可视化对吧?来展示一下啊,展示一下。
其实通过这个结果呢,我们其实。大概的可以呢样看得出来啊,他。它是什么样子的啊,它是什么样子的对吧?啊?比如说我们X轴对吧?是我们的一个这个这个这个时间,对吧?那么Y轴是我们的一个公因数。
那么我们用户在一天当中,比如说它的一个呃逛电商时间,哎,习惯是啥时候,对吧?啊,包括他自身的一个呃休息时间,你可以分析一下,基本上是重叠的啊,你看到这个波浪线,它的一个呃比如说它的走向啊。
基本上形状是一样的啊,那么其实这个就可以证明什么呢哎。每一个人对吧?一天当中逛街商的时间习惯跟他自身的休息啊,或者说呃。呃,这个这个休息时间啊是基本上是一致的。那么哪一个时间段可能会比较多呢?啊。
往上走呢?可能哎比如说上午对吧啊,这个这个呃往这走是么大九点的时候对吧啊,十这个前面啊,这个一直比较高,一直到到到这对吧啊,到这儿啊,可能这个是1617或者18啊,19对吧?啊。
七八点钟这个人数是比较多的啊,非常活跃,那么对应的值可能是15000也就或者16000。啊,1万0左右,那么往下面再往前面来走啊,可能哎到了7点啊,7点以后啊,到这个比如说10点钟这个人数是最多的。
是不是它的峰值是最高的对吧?那么证明这个时候呢,我们的用户是最活跃的对吧?那么这个时间段也是我们购物的什么黄金时间段,然后呢,往后走可能就慢慢的啊成下降的一个趋势。然后呢,再到第二天。
比如说哎5点钟慢慢的再往前啊,在逐步的一个上升,对吧?那么那么我们既然知道了一个用户的一个,比如说哎时间的一个匹配程度,对吧?那么我们就可以利用用户的空闲时间来进行营销了。啊,来进行营销,对吧?哎。
提高这个用户的一个购买率。对吧?比如说哎我在呃中午饭的时间跟晚上,比如说7点到11点的时候啊,来做一些什么呃,比如说大范围的一些呃什么什么优惠呀啊,或者说做一些其他的一些策略啊等等。啊。
那么下面是对于什么UV的啊UV的一个。情况对吧?那么这个是按照什么星期了,对吧?这是按照什么星期weake啊,weake来进行这样的一个分析。那么可以分析一下,哎,什么时候最高呢啊,可能是呃周几啊。嗯。
周末跟平时它的一个UV数其实变化没有那么大啊没有那么大啊,基本上差不多那么购买人数在呃周五啊,周四啊,周四啊时候可能会呃。比较比较多啊比较多OK啊,那么可能的原因啊,比如说我们可以猜测一下,对吧?
双十二当天做活动对吧?啊,增加了这个购买的人数,其他都是什样差不多的啊差不多。那么往下来走,对我们用户的一些行为的一些呃转化分析。对吧?那么这个转化这一块呢呃无非就是什么这样几个对吧?
我们当我们用户浏览了这个商品的一些页面,对吧?那么你可以直接购买啊,你也可以加入购物车啊,你也可以收藏,然后再购买,对吧?那么我们用户收藏跟加入购物车以后,其实。这个呢它并没有必然的一个联系。
对吧也就是它不存在什么上下级啊啊这样的一个关系。那么所以说OK那么这里呢我们不能说啊单一的做一些什么转化的一些漏斗,对吧?那么啊一般哈我们在这里面啊,对于这个呃漏斗图的一个画,我们一般都是么画PV啊。
到其他三种行为转化率的一个漏斗,对吧?那么这下面啊,比如说啊往下来走啊,是画了一个总体的一个漏斗图啊,总体的一个漏斗图,OK啊也就是我们PV到其他三种行为的一个什么漏斗图。OK用户行为总体的漏斗图。
那么通过这个图。能够发现一个问题。啊,发现个问题。比如说哎我从用户的一个点击到购物车到收藏,还是到购买,它的转化率其实什么都是偏低的啊,偏低的啊其中我们点击转化成为比如说购买的转化率是最低的对吧?
比如说哎这个什么1。06OK很低了啊很低。那么这里面啊有计算公式啊,计算公式在这里面啊。在这里面OK大家可以吗呃大致的去呢算一下啊,大致的去算一下。也就是我们比如说啊下单的总数除上1个PV对吧?啊。
其实就得到这样的一个结果。O。嗯,那么还有一些什么呢?比如说我们呃。这个这个这个PV你怎么去算啊啊,这里面啊,如果说电商的大家应该都清楚一些啊,都清楚啊。比如说呃首页的点击对吧?然后呢。
首页商品页面的点击,然后通过这个搜索商品页面的点击啊,基本上呃等于他们几者的一个和啊,记者的一个核。那么往下来走啊,就是呢UV这一块了啊,基本上跟上面的。呃,步骤呢是一样的啊一样的啊。
那么啊你也可以通过一些啊比如说漏斗图啊来完成这样的一个动作,那么往下来走,对吧?OK啊,比如说通过一些啊换了一个啊职肪图或者条件图啊来展示一下我们四种行为,各自的一个什么呀UV啊UV的一个情况,对吧?
那么在这里面呃展示出来的一个结果啊,结果,也就是说嗯我们一个月这个月里面啊有访问记录的,比如说这种呃独立的啊独立的人群啊,可能有呃1万。9999对吧?那么呃你可以算一下它的一个什么啊购买的一个转化率。
那购买是多少呢?这个by是什么?1764除上一个什么呢?这个这个这个19199999啊等于多少?对吧?那么其实说明什么?大多数人其实都都是愿意付费的啊,对平台的一个什么忠诚度哎蛮高的。
有很大的一个成长空间。OK啊。😊,我现在走什么?比如说我们的什么复购率对吧?按月啊,一个月以内购买次数,比如说超过一次的,那么这样的一个用户,我就算上啊就给他算上。还有什么呢?它的一些路径的一些分析。
那么路径的分析呢啊无非啊就这么几种啊,下面我写了几个啊,比如说这个呃点击到购买,点击,然后呢加购物车,然后到购买,然后点击收藏,然后到购买啊,最后啊点击加购物车收藏,然后到购买。OK啊。
其实这里面啊大家也可以呢画个图来进行什么呢?这个这个这个。这个。展示一下啊展示一下。那么最后呢就是我们商品的一些什么销售情况的一个分析啊,销售情况的分析。那么啊其实这里面哈,比如说我们销售的总数啊。
包括什么销售两次以上的商品的一些数量啊,包括什么前十的这些商品。啊,等等OK啊,那么呃分析完了以后啊,分析完了以后,其实我们可以总结出什么呢?哎,我们总共销售了多少个商品,对吧?哎。
有多少个商品销售的是什么呀?啊,比如说两次以上的,然后它的一个占比的一个情况,对吧?还有什么前十的一个商品啊,有哪一些对吧?然后呢,唉一看。结果啊是是啥?对吧?那么呃我们通过这个结果能够做一些。
比如说什么通过什么啊这些啊好卖的对吧?多备一点库存啊啊等等啊,来优化我们整体的一个运营的成本。然后最后什么呢我们这个用户的一个价值这一块啊,那么这里面啊我是做了一个弄图对吧啊。
帮大家去呃更清楚的啊来嗯看看到我们用户价值啊,这一块的一些基本的一些情况啊,基本的一些情况。


那么往下来走哈,就是就说什么呢?就是说在这里面哈,其实我们更多的应该去关注我们整个的一个什么呀业务层面啊,业务层面。然后从这个不管是用户行为间的一些转化分析哈,还是用户行为的习惯分析啊。
包括我们的内容偏好,还有什么用户价值这一块,对吧?啊,比如说我们现在讲到用户价值,用户价值,你就会你可以把它什么,我这里面是进行了什么分类,对吧?啊,来进行分类。那么分成哪几类呢啊,往下面来走啊。
那这几类。比如说我们是保留用户还是什么呀保持用户还是发展用户还是什么呀价值用户啊,给它划分这几个标签啊,这几个标签,那么这几个标签啊,你可以去按照你的实际需求来进行什么定义。比如说有价值的对吧?啊。
最近有购买,而且购买次数很多,那么这个时候我又可以给他设计什么呢?比如说VIP服务啊,专享服务绿色通道。那那么像这个。


发展用户呢对吧?最近有购买,但是呢比如说哎他买的次数比较少,说明有提升的空间,对吧?那么这个时候我就需要什么制定一些啊策略啊,比如说与他上一次购买,比如说相关的一些商品啊,对吧?
通过一些其他的策略来提升购买的一个品次啊等等,其他的啊一样的啊一样。OK啊,那么整个的分析过程呢啊基本上啊。大概就这么多啊大概就这么多。那么其实分析完了以后啊,我们在这里面其实一定要生成一个结论啊。
结论。那么也就是说你分析完了以后,对吧?你有了这些数据分析了以后哎。你对整个的这个数据这一块有了一定的了解啊,一定要给它落到纸面上来啊,落到纸面上来。比如说哎我们逛这个电商平台的时候,对吧?哎。
它跟我们的作息时间是保持一致的对吧?包括我们用户的一些购买路径,对吧?包括我们用户的啊,或者说呃活跃用户的一些占比啊,包括啊我们的一些什么啊复购啊,还有一些什么转化率啊等等。OK啊。
那么根据我们这样的一系列的这样的一些结果啊,我们尽可能去提高。比如说首页,比如说什么个性化推荐啊,它的一些什么准确度啊啊,降低我们的一些跳失率啊等等。那么来引导我们的用户啊。
比如说对商品的一个啊收藏啊架购啊啊,鼓励用户去收藏架购啊,然后呢最后达成满成交OK。过呢这部分内容啊讲的时间会有点长,对吧?OK啊我们啊这部分主要是对于数据的一些呃处理这块啊。
它的一些内容主要是我们通过什么一系列的一些操作来对我们已经拿到的这样的一个数据呢来做一些有针对性的一些了解。OK啊,其实嗯。😊,整个这个。嗯,数据分析这一块哈嗯是数据挖掘理念啊,应该来说你以后从事工作。
可能这部分所占用的时间是最多的。那么像后面啊,比如说模型的选择呀、构建哪啊跳征这一块啊。嗯,也很多啊,特征这一块也会占用很多的时间啊,像这个模型的选择,包括模型的构建这一块,什么训练啊。
这块其实时间并不多啊并不多。OK那么呃这部分完事了以后啊,我们赶紧往下来走啊,还有什么呀模型的一个。构件啊,还有什么呢?这个模型的评价两个部分啊,其实这两个部分就比较简单一些了啊,可能嗯。
比如说啊第一个啊我们来完成什么呢?模型的构建分三个部分,对吧?啊,怎么去构建数据集,对吧?数据集有了以后怎么去选特征,对吧?然后呢,怎么去来选模型。😊,那么首先第一个啊,怎么去构建数据集?
那这里面啊问大家一个问题啊,这个问题就比较简单了啊。比如说啊我们对于一个数据集,对吧?我想要把它进行一些划分,对吧?啊,一般啊可以分成哪几种啊,这个是很简单的。OK啊。
有知道的同学可以在右侧对话框来进行这个这个这个啊交流啊。OK然后刚才刚才就是说发的那几轮奖品哈,如果有中到的同学啊啊可以加这个右上角啊,右上角啊,我们这个杨老师的微信。
然后呢找他去来进行这个奖品的领取啊,像这个呃实体书啊啊或者说这个呃课程啊,可以直接找杨老师来领取啊,一会儿就像这个课件哈,都是一样的啊。OK啊,都可以找杨老师来进行领取。
OK那么这里面啊我我简单说一下哈,就是呃这个东西比较简单哈,就是数据集的划分这一块呢一般啊可以分成三个,对吧?我们的训练集测试集还有什么验证集啊,三个部啊,三个部OK那么呃数据集完事了以后啊。
也就是呢你怎么去进行它的一个划分,对吧?啊,按照什么样的一个比例啊,一般哈我们像这个这个这个这个训练集跟测试集,一般都是82比啊,82比来完成这样的个内容。OK然后呢完事以后,数据集你划分好了以后。
对吧?那么接下来就进行什么呢?比如说啊我们的一个呃特征的一个选择。😊,啊,特征的一个选择对吧?那么特征选择这一块呢啊,我给大家又列了一些,对吧?比如说我们可以通过很多种方式啊。
比如说我们呃基于什么统计类的特征,还可以什么呀?基于类比类的特征啊,笔值类的这样的一个特征,还有什么呢?比如说啊下面还有什么?基于我们的用户品牌的特征。OK这里面同样都要进行什么呀分析。
然后呢进行什么呀对比啊,来进行分析对比OK啊,下面其实就是把这些我们的内容给大翻译一遍啊,用。代码的方式给他翻译一遍。那么呃这个呢啊代码到时候呢会发给大家啊,大家可以啊对照着这个上面啊所写的。
其实这个呢呃相当于给大家一个思路啊,思路。那么呃如果有兴趣的同学,我建议啊就根据啊这上面所写的这些文字,对吧?啊,大家自己去复现,然后复现如果有问题的话,可以参考一下啊,我的代码。啊。
参考一下我的代码对吧?然后特征OK了以后,接下来就是什么模型的一个选择。那么这里面哈我设计的模型。😊,啊,因为课程时间有限啊,我觉得选两个简单的啊,一个是LR的,还有一个什么呀GDBT啊。
2个比较简单的啊比较简单的。OK然后在这里面啊跑了一下啊,跑了一下,结果还可以啊。然后呢,最后呢就是模型的一个评价了。那么我们就是按照我们最早所定义的这个F一的目标,对吧?
这样的一个标准来完成啊这样的一个动作。啊,完成这样的动作。那么这里面哈呃给大家主要讲的就是一些思路啊,那么像这些细节部分啊,比如说模型怎么去调用啊SK learn怎么去用呢啊这样的一些内容啊。
大家可以什么样关注契约在线机器学习集训营的课程啊,里面非常详细啊,对于什么特征工程啊啊这样的一些呃机器学习的一些内容。我们是从什么呀原理,然后到实战啊,实战性非常强啊,主要都是通过一些呃。
比如说案例来带大家去呃走完整个过程啊,像今天这个内容啊会啊比如说啊我们正式课程里面会讲的非常非常的详细啊,每一步啊都会给大家去讲到为什么啊,为什么会用到这个内容。O。😊,那么最后啊模型的这样的一个评价。
其实我们根据我们所定义的这样的一个标准啊,其实就OK了,对吧?来算一下啊,来算一下啊,它的一个嗯F1它的一个cr啊就可以。啊,得到作。结果得到结果以后呢,其实我们最后呢做了一个么排序啊。
做了一个排序这样的一个动作。OK啊基本上哈我们整个一个课程这一块的内容呢啊我们基本上就OK了啊,O了。那么OK了以后呢嗯。课程啊完事了啊,最后呢对吧啊我是带着任务来的啊,要。嗯。
做一波硬广啊硬广硬广的内容是啥呢?我们啊完成。宣传一下机器学习继训营啊。第16期。那么呃我们7月在线呢啊大家呃如果是做算法,多少啊都会经过我们,对吧?我们在呃AI这一块啊。还是呃有点知名度对吧?
那么呃对于机器学习这一块,我们已经是做了16期啊16期我们整个的一个课程这一块呢,嗯从大纲啊,包括讲师这一块啊。OK我点开,让大家看一下。哎,这个为啥点不动?

我copy一下。考比一下。


OK啊OK然后呃这里面哈这里面。😊,嗯。呃,给大家简单去讲一下啊,就是说啊我们机器学习集训营这一块,它是从零开始啊,从零开始,也就是从什么python基础啊。
我们整个的这个机器学习它就都是基于python语言啊,thon语言来完成啊,包括啊我们前面讲这个python的一个呃基础。然后呢到这个数据分析啊,里面比如说像n呀pandas呀net呀。
然后到后面比如说我们机器学习的一些原理啊,像这个LL啊GDBT呀SBM呀,还有一些什么ge呀啊,包括呃其他的一些呃模型O导入原理部分完事了以后,对吧?这里面应该有这个课程大纲哈,课程大纲啊。
我来看一下有没有啊课程大纲。

应该是呃在。

啊这里面只有一个课程简介,对吧?Yes。嗯。OK啊,大家有兴趣呢啊,可以直接到这个网站里面啊,来点开来看一下啊,这上面我好像没看到。

这个那个这个细节的部分是吧?课程的简介。啊,应该是呃是不是要注册一下是吧,注册一下,然后才能够看得到哈啊,这个大家可以去试一下。然后整个课程这一块呢,除了我刚才所讲的对吧?
然后机器学习原理完了以后到实战实战完了以后呢,到这个深度学习的原理,然后到深度学习的实战。然后最后呢是项目这一块。那么项目这一块哈呃企业在线所推出的这样的一个机器学习第16期项目呢很多哈。
比如说像这个是比较新的对吧?自动驾驶啊,车道的一个检测,这应该属于CA方向啊,CA方向的一个项目。然后包括什NIP这一块的智能问答。

机器人还有什么呢?还有什么啊电商平台对吧?它的一个推荐系统。okK包括什么呀?这个大规模的形式识别。其实这些项目都是目前工业界非常非常常见的这样的一些项目啊,落地性非常强OK啊。
那么如果哈同学们想要去进入这个行业里面啊,或者说你是传统IT的啊,或者说你是做数据分析的,对吧?你想要去往这个机器学习这一块来走OK啊,那么这个机器学习集训这个课程,非常适合大家。啊。
那么除了这些啊硬性的内容以外,对吧?我们原有的知识体系对吧?原有的这些项目,那么还有哪一些软服务,对吧?也就是说企月在线所推出的什么特色服务啊,那么这里面特色服务,对吧?有一个什么12位一体的教学模式。


那么这里面大家可以搂一眼啊搂一眼。那,比如说我们的呃课程对吧?有直播对吧?啊,然后呢实时答疑,有阶段考试,有作业,有毕业考核,哎,还有什么呢?唉GPU跟CPU这样的一个双平台啊,这个是比较贵的啊。
如果你自己买很贵的。OK啊。然后还有什么呢?啊对应的一些联合认证啊,比如说跟阿里云啊啊,包括呃其他的一些机构来做一些什么认证啊这样的一个动作。OK啊,然后这个项目这一块呢都是么标准化的一个流程啊。
标准化的一些流程,包括从这个呃项目的介绍环境的搭建啊,数据的准备啊,包括呃特征工程啊,对吧?模型的构建迭代优化总结啊,评估上线啊等等啊,一条龙服务。然后还有什么呢?呃助教老师对吧?啊。
有全职的助教老师给大家来做什么呢?这种呃。类似于呢班级啊这个独立的一个教学辅导啊,独立的教学辅导。

OK然后还有一个啊需要去隆重讲的就是什么呢?讲师团队啊讲师团队啊,那么讲师团队这一块呃非常强。

从这个比如说啊陈博士对吧?啊,这个呃浪潮集团数据科学家,他是我们呃接术在线AI跟ARP方向的技术专家啊,包括什么呢?serveven模式,刘老师、赵老师、丁老师啊等等。OK啊。
我们呃整个的讲师团队啊非常强。所以说对于整个课程这一块,除了说我们这个整个的课程体系,然后包括里面的内容,包括这些细节,包括唉我们这些项目啊可以落地的项目。


OK包括我们的啊全职的助教。全职的服务。啊,包括我们还有什么呢?GPUCPU啊这样的一些双平台OK啊,硬孚软服。相结合来给。大家提供什么样更好的服务。OK啊,这是任务啊,任务已经OK了啊,并广结束。
然后今天的这些课件哈,同样哈课件代码数据OK啊,我同样也会给到杨老师。😊,OK有问题啊,可以在右侧的对话框来进行提问啊。🤧O好,我们等几分钟吧,我们等到9点半啊,我们来结束啊。
OK啊我们呃其实我们在刚才的一个课程学习当中啊,大家呢注意什么呢?我们整个的一个呃思路,对吧?也就是说我们不管是做数据挖掘,对吧?还是做机器学习这一块啊这个基本上你的一个流程啊,大致是不变的啊。
那么其实区别在于哪呢?可能比如说你进大厂或者是进中小型的企业,对吧?可能稍微有一些区别,那么如果你进大厂啊,可能更多的是一个萝卜一个坑,对吧?你可能只负责某一个很小的一块啊,比如人家推荐这一块。
你可能就负责金牌,对吧?你可能就负责召回,啊,其他你不用管啊,一个萝卜一个坑,但是如果说比如说你到中小型的企业里面,对吧?那么可能呃你需要负责的东西就很多了啊,比如说呃。
从这个啊可能从上到下你都需要去参与啊,包括这个顶层的设计,对吧?啊等等等等啊这样的一些内容。那么同学们有什么问题哈,可以在右侧的聊天对话框来进行提问啊。那么我们今天所讲的内容呢,除了说这个数据分析呀。
机器学习里面所呃讲到的一些什么模型的一些构建呢啊,包括模型的选择呀,模型的一些评价啊等等这样的一些内容。OK那么嗯。今天哈主要给大家去讲了一些大概的一些思路啊等等啊,这些代码呢其实不重要啊不重要。
大家可以慢去参考。然后更多的一些细节的部分呢,大家可以关注什么呢?7月在线啊,然后他这个我看啊即时六即时六应该是他的开课日期应该很近啊,1012月27号啊,12月27号12月27号啊开课啊。
所以说呃有需要的同学啊,可以抓紧时间啊,联系什么呢?我们杨老师,然后找他去啊进行一些啊奖品兑换啊,课件的一些领取啊。如果说啊你要报名这个啊机器学习16期应该是今天双十一应该是有活动的啊,有活动的。
应该是有比较大的一个优惠。然后呢呃可以直接去咨询这个杨老师啊,他会给你专业详细的解答。



人工智能—机器学习公开课(七月在线出品) - P28:4.14【公开课】企业风险预测:特征工程与树模型实战 - 七月在线-julyedu - BV1W5411n7fg
🎼。Yeah。

嗯,各位同各位进入直播间的同学再稍等一下下啊,我们待会儿就开始啊,8点钟准时开始。嗯。对,大家之前学过继续学习吗?我们这节课呢就是以这个企业风险预测,然后来讲解这个一些基础知识。对。
各位同学之前学过继续学习吗?自己动手过吗?对,你可以在我们的一个屏幕区,然后打字跟我进行沟通。嗯,没学过好,就看来是入门的同学啊。对,没学过的话,你可以跟着我的一个嗯就是说课程来听一听啊,来找一找感觉。
好。那么我们就开始我们今天的一个课程内容。呃,我是刘老师。然后呢,我们今天的一个课程内容是以企业风险预测来给大家讲解的一个就是。嗯,以这种特征工程和数模性的一个角度来讲解这个案例。

在我们开始我们今天的一个课程之前呢,我们先给各位同学介绍一下趣车在线。契车在线是一家成立于2015年的专注于呃AI相关的人才培养的公司。在人才培养方面呢,讲师累计超过了200人。
均是由国内外的名校博士和硕士组成。然后总付费人员呢也是呃40万。然后我们的课程的一个数量呢也是几百门。然后呢,我们今天所给大家讲解的一个知识点呢,也是在我们的具体的一个呃就是呃集训营。
我们的继极学习集训营里面啊,然后呢我们来看看今天我们将会学到什么。我们今天呢首谓具体讲解的知识点呢包含以下这几个。第一个呢会讲解一下结构化的一个数据集的基础。第二部分呢会讲解一下特征工程的一个入门。
然后第三部分呢会讲解一下这个我们的一个数模型的一个原理,以及它的一个基础使用。然后第四部分呢,我们会讲解这个就是说企业风险预测的这个具体的一个实践。好,那么我们就先开始第一部分啊,这样在讲的过程中呢。
如果各位同学有任何疑问,或者说听不懂的地方呢,也可以及时的就是说提出来啊好。首先呢我们来看一看呃结构化的一个基础。呃,大家知道什么叫做结构化数据吗?结构化数据。对。
那么我们这个地方给大家介绍一下结构化数据呢,就是我们的一个数据集,它是以这种非常规整的一种形式来进行存储的。比较典型的就是我们的这种二维表格的形式,二维表格的形式啊,表格类型的。表格类型的。
那这谈到表格类型呢,你就肯定会想到这种我们常见的这种数据库,对吧?常见的数据库以及我们的excel。都是常见的这种表格类型的数据。表格类型的数据呢又叫做结构化的数据。那么结构化的数据有什么样的特点呢?
它相比于半结构化数据以及这种非结构化数据,它有什么特点呢?结构化数据我们的一个表格呢是以这种行和列。的这种形式来组成的行和列这种形式来组成的。其中呢我们的行代表什么呢?我们的行代表了我们的一个样本。
我们的列呢,它就是一个具写一个字段。这个地方的字段呢你可以理解就是一个。我们。也可以理解它是一个特征。如果我们这个地方的一个样本是我们的一个学生信息的话,那么我们的一个字段可能是学生的一个age。
或者说他的一个sex性别,或者说是他的一个score,他的成绩等等的。也就是说对于我们的每个学生呢,我们是可以统计它具体的一些就是说我们的一个特征的。比如说对于所有的学生的年龄,它都是存在同一列。
对于所有学生的一个sex,他的性别都是存存在同一列的。在我们的一个具体的建模过程中呢,结构化的一个数据。结构化的数据它其实就是以这种行列形式来组成的。
行列的一个交叉位置就是这个样本在这个字段它下面的一个取值。这个样本在这个具体的一个字段下面的一个取值,这就是我们的一个行列,它的一个交叉的一个位置啊,行列的一个交叉的位置好。
那么我们在学习记忆学习的时候,其实我们会学到很多的一些算法,比如分类回归排序和这种无监督记忆学习。那么我们在学的过程中,到底有哪些就是说怎么进行学,或者说怎么去选择这些算法呢?其实在学习的过程中呢。
还是建议大家就是说啊多去思考一下你的学的这个算法能用在什么样的一个场景上面。那么我们今天呢在我们的一些教材里面,其实呃教材呢,比如说像呃这个机器学习,就是周志华老师的机器学习。
或者说这个李航老师的统计学习方法的话呢?其实它本质就在就在讲解一些比较基础的一些算法,对吧?那么这些算法能够用在什么样的场景上面呢?其实大部分的这些基础的算法呢,都是能够用在这种结构化的数据集上面。
比如预测一下用户是不是违约用户,预测一下这个用户的一个房,就是说他的一个具体的房子,房屋的房价以及这个房屋的热度,然后预测一下这个温度的走势,或者说这个交通拥堵的情况。以及识别一下我们的一个道路。
他的一个行人,对吧?那么这些呢都是我们的一个机器学习的一个应用的案例。那么在这些案例里面,我们怎么去选择一些具体的算法呢?也就是说我们选如果遇到。到了一个问题,你怎么去选择合适的一个算法呢?
比如说遇到了需要你去预测一下这个用户是不是违约。那么你具体用什么算法呢?这个可能就是我们的一个从业者,或者说你学了积极学习和数据挖掘之后,你就应该知道的这个问题。好。
那么在我们的这种结构化的数据集里面呢,我们是以这种数目型居多数木型居多。因为数木型它。对我们的类别特征啊,在处理的时候是非常非常友好的。然后我们继续。呃。
第二部分呢是这个我们的一个半结构化数据和这种非结构化数据。半结构化和非结构化的一个就重要的区别就在于半结构化,它也有这种结构化的一个信息。但是呢它是介于结构化信息和半结构和非结构化信息的时候,比如说。
我们的一个jason类型的一个数据。jason类型的一个数据。jason类型的一个数据呢就是比较典型的这种半结构化的数据。它是以这种我们的一种dict这种形式来存储的对吧?dic类型呢。
它是呃在存储的时候,我们不需要它的一个所有样本需不需要它就是说具备相同的字段。好,这是我们的半结构化数据。那么我们的这种非结构化数据,比如说我们的这个呃图片呃我们的这个音频。
我们的这些文本它们就是这种很典型的一个非结构化数据,每个样本,它的一个长度不同。那么如果你去整整体的看一看这个结构化数据,半结构化数据和这种非结构化数据,你就你就会发现这三类数据的一个主要的区别在什么?
这三类数据主要区别就在于数据是否规整。数据是否规整?也就是说我们的所有的一个样本,每个样本是不是能够用一行比较规整的来表示,这个是我们的一个关键数据是否规整。好,我们继续。那么我们在做一个建模的时候。
我们嗯特别是需要做什么呢?或者说我们的一个应用的时候,我们的一个整体的流程是什么样的?其实基本上是呃以如下的这个思路识别问题,然后理解数据,然后对数据进行一个处理。然后通过模型建模并进行对模型进行评估。
这个是我们的一个数据挖掘,它的一个整体的一个脉络。也就是说从头至尾是可以以这种形式来进行展开的。但是呢我们在展开的时候呢,其实我们的每一部分,其实我们的一个侧重点是不一样的。
每一部分我们侧重点是不一样的。比如说我们在理解数据的时候呢,我们可能是更加关注于我们去呃这个数据本身它有什么规律没有,对吧?或者说这个数据本身它呃跟我们的标签分布有什么样的一些规律。
这个是我们在做理解数据的时候做的。那么我们在做一个分析的时候呢,我们最关键的就是说能不能找到我们的字段和标签的一个分布的规律,并以此呢来做一些额外的操作啊,额外的操作。
这整个是我们的一个比较完整的我们的一个建模的啊,这种流程。好,那么有同学可能就会问到,老师在你做一个建模的时候。

你会使用哪些具体的一些算法呢?或者说你用哪些模型呢?这个地方呢我们给大家介绍一下,我们在实践的过程中,我们会用到哪些的一些基础啊。

首先呢我们在做一个建模的时候呢,我们现在呢百分之呃就是说90以上的环境啊,90%以上的环境啊。不管是在呃就是说做这种学术啊,还是在我们的一个工业界里面啊。
大部分这种建模呢都是基于我们这种python的一个环境来进行的python的环境。所以说呢你是需要掌握一下python的,掌握一些python的这是第一点。第二点呢,就是呃使用python的时候呢。
我们是有一些第三方库。那么我们接下来就看一看我们就是说如何去使用这些第三方库来完成我们的一些建模。呃,这个地方呢我们就是呃大致讲一个就是说基础的建模流程啊。好。
我们这个地方呢是以一个泰坦尼克号的一个数据集来展开的。他的哪个号大家呃应该都知道呃,就是说一个游轮,游轮上面呢有很多乘客。这个乘客呢我们需要利用乘客的一些信息去预测它是不是幸存下来的。好。
这个是我们使用pandas来读取得到的我们的一个数据集。使用pandas得到的我们的数据集。在这个数据集里面,我们这个就是一个叫做data frame的一个。表格在pas里面,它叫data frame。
然后呢,这一行就是一个乘客,这一行就是一个乘客。然后这一列就是我们的一个字段。比如说在我们的这个数据集里面,我们的这一列叫做passenger IDD,相当于是一个乘客的ID。好。
比如说在这一列是我们的passenger的它的一个name。也就是说是这个乘客的姓名。好,在这个数据集里面,它就是一个典型的一个结构化数据。典型的一个结构函数据行和列的一个交叉位置。
代表了这个乘客他的具体的pasen加ID,或者说这个乘客他具体的姓名。好,这是我们的一个结构化的数据集。那么在我们的结构化梳据集里面呢,我们是需要知道一些基础的。比如说我们哪些数据是我们的一个特征。
哪些数据是我们的标签呢?也就是我们在做建模的时候,我们有这个feature。以及我们有我们的tage。对吧或者说。你可以理解它是X,它是Y,对吧?我们需要去构建一个模型。去离合我们的Y对吧?好。
那么这个地方我们的哪些字段是我们的一个就是说特征呢?这些字段是我们的特征。这些字段是我们的特征。好。这个字段是我们的标签。
是我们的标签survivved这个survivved就是用来标识这个乘客是否幸存的。那么标识这个乘客是否幸存下来的一呢代表他幸存下来的啊,零代表他没有幸存下来。好。
那么有同学可能说老师这个地方还有一个passenger IDD。这个地方的pasenent IDD它是我们的特征吗?或者说是我们的标签吗?好,我们的第一个互动。对。
大家认为这个是我们的标签还是我们的特征,或者说它既不是标签,也不是特征。对,然后呢我们呃前十位回答,我们就是说互动同学呢,我们赠送我们契车在线的月卡10张。对,有没有同学想回答的?有没有同学想回答的?
这个地方我们的一个paenger ID是我们的什么?有同学说了啊,都不是有同学说标签。好。对,其实正确答案都不是都不是,为什么都不是呢?这个地方我们的1个ID。😡,它是一个用户的一个唯一标识。
或者说你可以理解。这个地方就是我们的一个乘客,在我们的一个船上的一个身份证,每个人的身份证号是不一样的对吧?所以说这个地方它既不是我们的一个特征,也不是我们的标签。好好,这个地方啊。
我看一看有嗯很多同学已经回答对了啊,我截一下图。呃,就是呃钱现在已经回答的这些同学啊,就是可以领取一下我们的一个缺在线的一个月卡。然后呢,我们待会儿会把这个领取的方式啊,发给大家啊。😊,呃。
有同学说了这个地方ID你可以理解它是一个K主K可以的,很好啊,就是说你可以理解它就是我们在数据库里面的一个主件主件。好,那么我们这些siveve是我们的一个。😊,具体的标签。
我们的除了是pasenger IDD以及svivve的,剩下的就是我们的一个特征。好,那么这是第一个知识点,我们的标签和特征,然后继续。那么我们的这些列它到底是什么类型的呢?好。
这是第二个这些列到底是什么类型的。比如说我们这个地方的name name呢,在我们的一个上面通过我们的describe函数呢,可以看到它是一个object类型的。object类型,也就是说它是一个。
strrange的这个地方很明显,它是一个trainrangeish的。然后呢,我们的一个sex。sex呢它也是一个object类型的,它存储的形式也是这种t类型的。对吧好。
然后呢我们还有这个ticket。😊,对吧这它也是我们的tra类型的,还有我们的这个ageage呢是我们的一个flow类型的。好,那么我们在拿到一个数据的时候呢,你就会发现我们的数据集它的每个字段。
它的类型。又是不一样的。😡,类型就是不一样的。也就是说我们在做建模的时候。我们要知道我们的字段是什么类型的,标签是什么类型的对吧?如果我们的标签是我们的这种离散类型的,那么它就是分类问题。如果我们。
这个标签是这种连续类型的,它就是一个回归问题。那么反过来想,那么我们的字段。他是什么类型的呢?这个地方的一个字段的类型跟我们的一个建模也是非常相关的非常相关的。那么怎么去看这个字段的类型呢?
我我们通过这个pandas的一个infer函数。paless的info函数就可以看到它的具体的一个存储的类型,这是它存储的类型啊,就是有映酬类型的。object类型的。有我们的一个fo类型的。好。😊。
那么这个地方的一个类型呢,D type是这种数据的存储类型。它并不是说是这个数据这个字段它本身的一个类型啊。也就是说我们的1个sX,它在存储的时候呢,是以这种字符串进行存储的。
但是呢其实它是一个类别类型。它是一个类比类型,对吧?那么我们的name呢,它是以这种字符串存储的。那么它在在含义上面呢也是这种字符串。😊,也就是说这两列虽然说都是以这种字符串存储的。
但是它的类型是不一样的啊,类型是不一样的。好,那么我们呢在做建模的时候,我们一方面要查看我们的一个字段的类型,接下来也要看什么,要看我们的一个字段,它是不是有缺失值。是不是有确失值,对吧?
我们对于我们的字段,每个字段去查看它具体有什么缺失值没有。比如说我们在这个字段里面发现我们的age字段以及我们的carbin这两个字段是包含包含的蛮多确失值的。😊,包含的馒头确实值的。好。
这些呢都是我们在做一个。数据分析的过程中,以及我们对数据的理解的过程中需要做的。好,那么有同学可能就是说老师这一部分我怎么学啊?这部分你就去学这个pandas就行了,你就学pandadas。对。
padas就是库。对数据进行一个读取,然后对它进行一个统计,进行分析,统计进行分析。这些都是panda的一些语句。德斯的语句,所以说你不要就是说完完全全只是了解这个就是理论啊,实操还是很重要的。
因为在企业内部,他不管你去有没有理论或者是怎么样,我只要看结果,对吧?给你一份数据,你能不能把它做出来,这是我关心的。至于怎么做出来,对吧?中间遇到什么困难,或者说你遇到用具体用了什么算法。
可能我并不关注我只要结果,对吧?在企业内部它是以这种问题为导向或者结果为导向的。好,所以说这个也给大家提出了一个新的要求,如果遇到一个问题,拿到一个数据集。
你能不能分析出来它具体的类型以及具体的具体的一些趋势值呢?这个可能就是需要大家有一定的一个啊,就是说动手能力啊。

然后呢,我们刚才给大家讲的呃,就是说说的这个月卡呢,就是我们在。

呃企实在线的一个这个地方有1个VIP的1个月卡。嗯,这个月卡呢就是可以免费的去看我们的很多的一些小课啊。所以说后续呢待会儿我们还是有还是有抽奖的。待会儿如果还想领取我们月卡的同学啊。
呃就是积极参与我们的一个互动。


好。那么我们继续刚才呢就介绍了一下我们的第一部分,我们的一个数据集,特别是我们的一个结构化的一个数据,它的一个整体的一个基础。好,然后呢我们接下接下来看第二部分特征工程入门特征工程入门。好,我们继续。
那么我们在做一个具体的一个建模的时候呢,我们并不是说数据它本身是怎么样,它就一定是怎么样,对吧?我们的一个具体的一个数据集,它是需要进行一个嗯进行一个转换的。嗯,就是说可以这样举一个例子,也就是。
我们在学习的时候学习理论的时候呢,经常就是说啊我有一个什么样的模型,这个模型通过怎么样改变,让它变得更强。对吧比如说从F1把它转变成F2。然后呢,再转变成F3。模型。怎么怎么演变模型怎么怎么改进。
这个可能是我们在就是说学习理论知识的时候,对吧?我们的书模型怎么进行改进,减脂啊,我们怎么做bagging啊等等等等。但是呢我们在实操的过程中呢,我们可能并不是说去对我们的模型做改进。
我们可能呢就是对我们的数据做改进。Yeah。我们对我们的数据做改进。好,这个呢可能就是呃哎sorry啊。我们去对我们的数据所改进。这个呢可能就是说大家之前我们在学习理论跟我们的一个实操过程中重要的区别。
理论更加偏向于模型的改进。实操呢更加偏向于怎么去对数据。去做一些处理。好,那么我们接下来看一看啊,对于我们的原始数据集,它可能的。是以这种我们类似于这种jason。或者说这种dict的存储形式。
对吧这个地方我们是存储了一个房屋的一个信息,这个信息里面包含了房屋的一个嗯room以及bedroom以及str name以及它的一个呃就是说bas basementement rooms等等的一些信息。
好,那么在这个地方,这些原始的数据集,它可能就是说字段有这种数字类型的,有字符串类型的,也有我们的一个。就是说呃就是类别类型的都有可能。那么。在存储的时候在存储的时候啊。
就是说如果大家学过这个数据库的话,你应该知道我们现实生活中或者说。在我们的编程语言里面,它常见的数据类型就有哪几种啊interflows。我们的train。对吧或者说我们的d time。
就说我们在存储的时候,基本上就是这些类型。但是呢我们在做建模的时候,你会发现我们现在的一些机器学习的模型,基本上输入的时候都是需要你把它处理成数值类型的。数字类型的对吧?它可以是浮点数。
或者说是是这种我们的整数都行。但是呢是需要你的一个数据是我们的这种非。非我们的这种就是说这种字符串类型的,非我们的这种日期类型的对吧?因为我们的日期和字符串,它没办法参与计算啊,对吧?没办法参与计算。
好,那么我们在做一个数据处理的时候,这个地方我们将我们的一个数据把它处理为我们直接能送到我们的模型的这一步呢,就叫做我们的一个数据预处理和特征工程。也就是说我们首先输入的是一个原始的一个数据。
我们的原对原始数据呢可能对它进行一些预处理。嗯,purport嗯预处理啊,这个地方啊单词拼错。予处理。然后呢,再对他做一些特征工程。再得到我们最终的可以送到模型的这个特征。也就是说。
原始数据它可能并不是特征。原始数据呢我们一般把它叫做字段比较多。但是这个字段并不一定是特征。字段并不一定是特征,或者说这个字段它可能是原始存储的,它可能在我们建模的时候是不需要的。好。
也就是说我们在做一个建模之前或者送到模型之前,我们是需要做很大的一些操作的。比如说我们对于我们的一个。在做转换的时候,如果原始的一个字段,它就是我们的这种数值类型的。
那么我们就是可以直接把它copy过来。那么如果它是这种思串类型的。字付串类型的。那么我们就可以考虑把它做一些额外的编码。比如说把它做一个one horse的这些编码,one horse的这些编码。
这是可以的都是可以的。好,那么这个地方有同学可能就是说老师。字符串它不是有这种呃TFIDF吗?那么为什么要选呃选择这种oneport呢?这个就跟我们的一些具体的编码方式是相关的。
具体的编码方式是相关的好。那么我们接下来看一看我们的一个类比特征。类别特征啊,它的一个英文名字叫做category features。
categoryry features啊类别特征类别特征的一个含义就是说它的一个具体的一个产生得到的。然上得到的它是一个以这种。数值啊以这种字符串类型存储。但是呢它的取值空间有限。取值空间有限。
取值空间。有线这个有限是什么意思呢?也就是说我们的这个类别类型,比如说这个性别这个字段,性别这个字段就是我们的取值空间是非常非常少的。男性女性或者不确定,对吧?
我们的城市省份、民族、户口类型都是比较典型的我们的类别特征。那么我们的名名字name name呢它就不是一个类别特征。为什么呢?name它的一个。取值空间就非常非常大了,它就不是说可以直接便利完的对吧?
好,那么我们这个地方类别特征,我们怎么对它进行编码呢?类别特征是在我们的建模的时候,无论什么时候都是需要处理的。因为我们的现在的的一些机器学习模型,它是没办法识别这个类比特征的。
这个地方我们的字符串它是没法参与我们的一个训练过程的啊,字符串它是没办法直接参与我们的训练过程。所以说我们需要考虑对它进行一个编码,对它进行一个编码。好。这是第一个。第二个呢就是说对于类比特征。
它的一个处理呢会容易带来离散数据。移算数据这个地方有一个叫做高基数的类比特征,高基数的类比特征。这个是什么意思呢?就是取值空间非常大的一些类比特征。比如说我们的国家国家这个类比特人对吧?
全球的国家应该是上百个,对吧?全球的国家是上百个。那么对于这么多国家,如果你想要对它进行一个编码的话。你就需要。可有可能会把它转转成这种非常非常稀疏的一个项链。非常非常稀数的型的。
那么这种高基数特征就是表明啊就表示它的一个原始的一个取值空间非常大。好,那么对于我们的类别特征呢,它还有一个特点,就是说它其实是很难进行缺失值填充的。比如说某国同学他的一个性别缺失了。性别缺失了。
就是性别这个字呢他没有填。那么你去你去怎么去填充呢?其实根据这个用户他的一个就是名字。嗯,其实很难挖掘出他的一个具体的一个就是说性别的对吧?好。嗯。我们继续。那么对于我们类别特征呢。
其实可以把它分成嗯就是说多种类型的。第一种呢叫做有序的类别。第二种呢叫做无序对比啊。这个地方呢我们的一个有序类别和一个无序类别是什么?有什么区别呢?
这个地方其实它重要的区别就在于无序类别它是啊这个取值之间是相互平等的,也就是说我们的动物与动物之间是相互平等,没有什么大小关系。然后呢我们的有序类别就是它是有这种大小关系的。
或者说有这种呃发生次序的关系,或者说一种某种关系,比如说我们的情感,对吧?呃,开心不开心非常开心,我们的一个就年级对吧?一年级、二年级、三年级。对吧或者我们的大中小班,对吧?
这些都是我们的比较常见的这些有序类别和无序类别。那么我们在做编码的时候,我们也是需要考虑这个字段,它到底是一个有序类别还是一个无序类别呢?这个其实是。需要注意的。好。那么我们继续。那么对于类别特征呢。
我们接下来讲一讲这些具体的一些例子啊,给大家就是说让大家感受一下对于这是类别特征,我们怎么对它进行编码。那么我们首先来看一看这个数据集,就是说我们创建了一个da frame。
这da frame呢它是有这个四列有四列。这四列呢就是一个students ID country education以及tar四列。然后呢分别的是这个学生的一个country。
学生的一个education信息,以及这个target就是一个我们的一个标签。那么我们接下来看一看我们怎么对这几列做一个编码。首先呢对于类比特征。
就是说比较常见的这个编码方式呢是这个one horseone horses。王后是他的一个就是说具体的操作,就是嗯你可以使用这个pandas的get du来做。
one hot的一个含义呢就是说是把它编码为one O K is hot这种形式。也就是说其在某个位置是被编码的,其他位置是没有编码的。这个地方的K呢是什么意思呢?这个K代表的是这一这一列。
它的一个取值空间。取值空间。我们来看一看这个地方的education这个例子。对于我们的这个education这一列呢,其实它是有三个取值空间的。所以说这个地方我们是将原始的这一列。
比如说这个地方是一个一列,把它转变成一个三列。对吧三点的,为什么是三点?因为这个地方我们对于每个学生呢是把它转变成了一个1乘以3的一个向量,1乘以3的一个向量。好,这是我们的一个oneho。
oneho它的一个优点就在于它是比较简单的,它是能够将所有的特征把它进行有效编码的,而且呢它没有改变我们的字段与字段的。嗯就是说大小关系。比如说我们的be和master在编码之后,它仍然是相互平等的。
不信我们来看一看010和100以及我们的001。这三这三个相顶,它们之间的一个距离仍然是相相互平等的。也就是说我们的w horse其实他没并没有改变我们的一个取值的大小的次序,这是它的优点。
那么one horse它有它的缺点,就是说one horse它是会带来维度的一个增加,很有可能会带来我们的一个维度的爆炸。在通过我们的一个具体的一个编码的过程中呢。
它也很有可能会带来一个特征稀数的一个情况,带来一个特征稀数的一个情况。好,嗯,我们在做的时候呢,我们其实是呃需要考虑到我们的是不是值得做完火,值得做完后情。好。那么我们怎么实现这个呢?
就是说在pas里面可以做这个get duing,或者说在S pen里面,我们使用这个one horse enr就行了啊,做one horse encode就行了。好,我们继续。
那么第二种呢叫做这个label encode。label encode就是说我们的一个具体的一个编码,它是使用类似于这种标签编码的形式。标签编码呢就是说我们是用一个具体的一个label。
这个label呢。label原始就是指的是标签。这个地方呢label in code原始就是默认就是对我们的一个标签做一个操作,对我们的一个标签做一个操作。好。
那么我们的一个具体的一个这个地方leve encode用在我们的特征编码的时候,就是将我们的类别字段把它用一个独立的数字ID做一个替换。比如说这个地方,我们的country。
china编码为0USA编码为1,UK编码为2,接喷编码为3,以此类推。这就是我们的一个label in code。labeling code它是比较适合在我们的数模型里面使用的。
它的一个优点就在于它是比较简单的,它不没有增加我们的一个特征的一个维度啊,没有增加我们特征的一个维度。但是它的一个缺点就在于它其实是改变了这个标签的一个次序关系的。
比如说这个地方我们的一个国家在编码之后,你就会发现其实他们。就是说是。国家他们国家之间有数值的表示呢,它就有这种大小关系的对吧?为什么china比US小?
为什么这个呃就是说我们的japan和 Koreaorea它就比较大,对吧?这个就是说我们在做一个。编码的过程中会遇到这种问题。那么具体的实现呢,就是说我们使用这个paas的 factorize。
以及我们的S clean中的label encodeder,可以做这个编码啊,可以做这个编码。好,这是我们的一个类别特征的一个编码方式。好,那么我们接下来做我们的这个继续抽奖啊,继续抽奖。
那么各位同学呃就是说在我们的生活中有没有遇到哪些嗯额外的一些类别特征呢?可以这个地方打字啊,这个地方我看嗯就是说哪位同学说的比较好,我们就送一本我们的书对我们的西瓜书啊,西瓜书纸质书送一本包邮的。😊。
对,大家遇到日常生活中遇到哪一种,你是怎么尝试对它进行编码的呢?对大家可以来参与我们的抽奖啊。对,第一个发言的啊,第一个发言的第一个合理发言的,我们就送给他。😊,好。有没有同学啊。
这个地方应该大家都在打字啊。好,我我们就继续稍微等大家一下啊,稍微等大家一下。😊,对。有没有同学想要我们的纸质书的?嗯ん。好。啊,有同学说音乐类型数据,天气玩火喜欢的运动项目日期嗯,挺好的。
但是这个日期呢其实并不是并不是说直接用这个呃就是说他一般情况下,我们不不是把它当单独当做类别特征的啊。嗯这个地方呢就是恭喜我们的手机用户呃,微信用户545494同学啊,就是说可以加一下我们的杨老师啊。
就是说领取我们的一个直质书,或者说直接联系我们的你在呃任意的就是说微信里面的任意一位我们的7月在线的老师啊。对,恭喜这位同学。好,还有同学说这个电商的类别啊也可以的也可以的好。
那么我们就继续啊我们就继续。那么在我们做一个建模的时候,就是说有同学可能就是说老师我怎么去用这些啊,其实用的话其实并不是特别难。假如说你想要用这个模型的话,或者用这些具体的编码的话,其实并不会特别难。
怎么说呢?因为这些具体的一些编码呢,它在我们的一个就是说建模的过程中嗯,是你必须要去面对的,你必须要去面对的。比如说。我这个地方再举一个例子。假如我们的一个数据集里面,其实它假如存在一种形式呢。
是这样的。我们的ear,这个是我们的一个原原始字段的工作连线,它是一个year,就是说是呃取值为one year two year three year这种对吧?那么我们在这个地方。
我们对它进行编码呢,其实我们是可以直接把它做一个手动映射。这东西是对吧?直接把弯一2。编码为一,推页编码为去,类似的这些方式方式来做一个编码。这些都是我们在做就是具体的建模的过程中,很方便来做的。
很方便来做。也就是说,这个编码并不是one火,也并不是label in code,它是我们手动的手动的做一个有序编码,手动的做一个有序编码。好,我们继续。那么我们接下来啊看一看我们的一个呃数模型。
它的原理和这个使用啊数模型。好,那么我们接下来看来我们的第第二第三次抽奖啊,也是抽我们的月卡。那么大家用过什么样的数模型呢?呃,也可以发一下啊,前十名的同学送我们的一个雀在线的一个月卡。
就是说刚才还没有抽到我们月卡的同学,现在可以来说一下。😊。

对。呃,什么样的数模型都行啊?手机用户678875同学说性别啊性别男性男性为一,女性为0啊,可以的,这种是可以的。叉g boost嗯可以的啊。嗯从前有座山同学以及手机用户68075同学啊。
手机用户77875783765同学啊,叉GlashGBM以及开嗯,挺好的,挺好的。GBM嗯,看来大家都对这些数模型有一定的一个了解啊,有一定的一个了解。对,非常好。好啊,恭喜这些嗯这几位同学啊。
恭喜这几位同学可以嗯,就是说待会儿就是说我已经截图了啊,待会儿就可以直接讲找一下我们的契约在线的老师领取我们的这个月卡。有很多小课都可以直接看的啊,可以直接看的。😊。

好。那么我们就继续啊我们就继续。接下来呢我们就介绍一下我们的一个数模型,它的一个原理啊。随以接像您啊,有同学还在还在说很好很好好。我们继续。在讲解随机森林的呃,在讲解我们的数模型的时候,其实数模型呢。
刚才有同学说的数模型其实它是一种非常基础的这种数据结构,对吧?有同学说它是我们的这种二叉树。对吧这个是其实是可以的,或者是多差数也可以的。在我们在做数目型的时候,其实本质上就是说。
它本质上有点类似于这种if else的这种逻辑。If else啊 if else。也就是说,满足我们的某个条件走左边,不满足呢走右边。满足下面一个条条件,走左边不满足左右边。
它有点类似于我们的这种ef的逻辑。但是呢我们的数模型其实是一个非常非常优秀的一个机学习器。它其实是一个就是说机学习器。机础机器呢就是说你可以理解它就是说是非常简单的非常基础的这种学习器。
那么我们可以基于这种积础机器呢,可以把它组合成一些高阶的模型。比如说我们的是机森林。对吧那么怎么去利用我们的数模型,把它构建成一些高阶模型呢?
比如说我们可以在我们的数模型里面加入我们的这种begging的一个操作。begging的一个操作。这个buing的一个操作呢就是说我们是可以把它具体的一个。操作过程呢是可以并行训练。
begging就是说是类似于这种民主的一个思路,并行训练,并行训练。也就是说我们可以训练一个模型,我们也可以训练多个模型。那么训练多个模型的情况下,我们可以将这多个模型把它集合到一起。
也就是说我们有第一棵树。我们也有第二个数。我们有第三个数,对吧?每个数有一个具体的预测值,我们接下来将这三个预测值把它进行一个投票,或者说做一个加线求和,这个就是我们最终的结果。
那么bagging呢它可以定行训练,定行训练啊,这种这种提成的思路。它的一个优点就是说它能够减少我们的一个方差。它的一个缺点就在于它其实是增加了我们的一个时间开销的,而且呢是需要我们的模型具备有多样性。
也就是说,如果你的一个模型。没有多样性的话,那么你最终得到的一个结果仍然是不好的。什么意思呢?就是说如果你将同一个模型相同的模型把它就是说预测三次,然后再进行一个集成。其实对于我们的模型而言。
其实它并没有任何的一个长进。对我们最终结果而言是没有任何改变的。所以说这个地方我们是要有模型的一个多样性的。如果模型多样性越多,或者说多样性越大,它所带来的一个争议。积极资就是说精度自信就会越高。
这个地方的一个民主就是说不是我们每个独立的模型要相互独立,或者是说尽可能它的一个就是说多样性会好一点。那么怎么去保证我们的一个模型有多样性呢?可以从两个角度。第一个呢是从我们的一个数据的角度。
就是说做我们的行列采样,做我们的行列采样。那么行列采样行是我们的样本级别做采样。列是我们的特征空间的纬度数采样。那么有了我们的行列采样之后,我们的数据上有多样性。
其次呢我们也可以对模型的超参数进行一个调整。超参数做一个调整。超参数它决定了我们的模型的多样性,模型的多样性。那么我们就可以基于我们的一个这两个维度啊,去得到我们的一个多样性的模型。好。那么我们继续。
那么我们在做一个建模的时候,有了我们的多样性呢,我们接下来就可以去年多个模型,然后将我们的结果进行集成。那么我们还有这种bo死性的思路。bosting呢跟我们的一个baagon其实不一样的。
bosting呢它就是我们是基于这种基因筛选的一个思路,串行的训练,串行的训练。什么叫基因筛选呢?也就是说我们的一个本次迭代,是基于上一轮迭代的一个就是说基础上来做的。
我们本轮迭代是对上一轮的一个模型进行一个继续的礼合,或者说对上一轮模型,它的一个错误样本,然后进行一个调整。这个就是我们的一个。ボスのゆろ。不行呢它可以减少我们的一个偏差。
也就是说我们类似于这种打靶的这种形式,你最开始模型预测的比较远。对吧那么我们有了这个间隔之后,我就不断的去调整。最终呢希望你是能够接近于我们的一个最终的目标的。这个就是我们的一个bosing的一个思路。
那么我们的关键点在于我们是怎么去基于上一轮的一个模型进行一个继续学习呢?bosing的关键点就在于这个地方,有两种方法。第一个呢是基于错误样本进行调节权重,也就是说对于错误样本的一个权重进行调整。
第二个呢是礼合上应的模型的一个误差,对残差进行一个学习。残差进行学习。好,这是我们的一个bosing的思路。那么我们现在呢有很多的一些高阶的模型,比如我们刚才。同学们已经说到了这个letsBM。
那么这些高阶的模型跟普通的数模型有什么区别呢?这些高阶的模型和普通的数模型最大的区别是在于它的在工程上面有一些具体的一些实现上面的优化。就是说你在使用的过程中呢。
其实nBM其实在工程上面是做了很多优化的。比如说。他在做具体的一个节点拆分的时候呢,就是我们的一个分裂节点的时候,它其实是使用这种直方图的一种算法来做一个近似的。我们的一个就是说最优分类级的一种查找。
这个地方其实它本质上呢就是我们在分类节点的时候,是从我们的一个直方图。直肪图或的分筒的这个形式来去得到我们的分离起令。那么这种直方图的算法呢,其实是对于我们的一个内存和速度上都是有一定友好的。
那么这个直方图也它也会带来一定程度上的一个政则化的一个操作。也就是说它避免了我们就是说这种数模型出现过离合的可能性。其次呢在我们那7BM里面,其实还有很多,比如说这个特征捆绑啊,以及。
它的一个具体的一个bagging的操作啊,这些都是很多的。那么我们在学习的过程中,一方面你可以学习这个lesBM的一个原理。另一方面呢,你也可以去学习它的一个具体的一个模型的使用。
这个就是呃我们从业者或者说学习者是需要具备的啊。那么怎么去学习这个ICBM它的一个使用呢?其实对于一个数模型而言。对于一个数模型而言,其实本质上呢就是从以下的这个角度去可以学习。呃。
基本上对于所有的模型啊,对于所有的模型基本上都是从可以从如下的一些角度可以学习的。就就就具体的使用啊。怎么读取数据集,怎么训练模型,保存模型,怎么去算这个模型它的一个特征重要性,以及怎么加载模型。
怎么继续训练,以及怎么去修改这个超参数,以及如何定义这个损传函数以及这个模型的调参方法分析方法以及部署模型。也就是说对于任意的一个模型啊,这个地方是以这个nCGBM举例。
对于任意一个模型都可以这样来说来学习啊。就是说使用加载调参部署分析这些基础的步骤啊。那么我们来看一看NCBM它在使用的过程中的一些细节。那GBM呢它在训练的过程中呢。
其实是有两种接口的两种接口的这个地方其实我们在这个代码里面其实是有演示的啊有演示的。这种letGBM的train呢LGB点train是letTGBM的一个原生的接口。
他也letBM呢也有这种和我们的1个SK。搭配的这种接口。啊,也有跟我们的S呃就是说SK搭配的这种接口,或者叫SK的接口。比如说LGBMclassifier。那么。有两种接口,一种是原生的LGB点论。
一种呢是这个leCGBM的这种接口。这两种接口呢两类接口都是可以使用的。唯一的区别呢就在于啊这两种接口如果你使用这种。SK learn类型的接口了。
那么我们就可以搭配一些SK learn的一些啊就是说内置的函数来进行使用。比如说我们可以搭配这个SK learn中间的一个网格调餐来进行操作。搭配我们的一网格调餐来做操作,对吧?
比如我们的一个具体的一个超单数的一个搜索的过程。这个通过我们的一个lessBM是可以很方便的得到的。或者说去搜通过这种BS调三去搜索到我们的具体的一些超单数,这些都是我们的一个nCGBM。
它还可以很方便的得到的。好,这部分呢就是说也是需要各位同学熟悉的啊,也是需要各位同学熟悉的。好,那么我们接下来的时间呢,我们就讲解我们的一个具体的一个建模的案例。呃。
这个案例呢就是以这个呃某一个就是非法集资的一个企业的一个数据集来做一个预测啊。在这个呢,它也是一个具体的一个呃实际的一个数据集啊。呃,这个背景呢就是说有一些企业呢它是呃在进行一个呃运行的过程中呢。
有可能有这种存在这种非法集资的这种风险的一个情况。我们就需要构建一个模型去识别出呃这些非法集资的一个企业非要集资企业。然后呢,我们的一个训练集,包含了这个25000家企业信息。
然后我们的一个具体的一个测试集呢是嗯大概是15000条我们的一个信息。好,我们来看一看我们的一个就是说建模过程。我们。😊,这个数据集呢其实是一个多表的一个数据集。多表数据集。
也就是说如果你拿到我们代码之后啊,这个代码我们待会儿会发给我们的这个就是说che在线的老师。然后大家可以加了他们的微信之后呢,就可以直接从他们领取得到啊。这个地方我们的数据集呢它是一个多表的多表的。
什么意思呢?在这个地方,我们的每张表格,或者说我们的每家企业的每种信息呢是把它存在不同的位置的。存在不同的位置的。这个地方呢就是说我们的一个。需要。将我们的每个表格进行读取,然后对每个表格进行一个分析。
这个是我们在做的时候需要做的啊,需要做的。对我们的每个表格去做哪个表格去做。那么首先呢是这个base info。base info这个表格。base info这个表格呢,它是做什么呢?
base info其实是包含了企业的一些基本信息。比如说这个企业的一些经营范围、行政编码以及它的一个就是行业类型。对吧以及注册资本,这个是我们的一个base informed这个表格。好,读取进来了。
读西进来之后接下来做什么呢?我们可以去做一些确认值分析。我们可以将这个每一列它的一个缺失值的一个情况做一个可视化,对吧?比如某些列它都是完全缺失的,或者说嗯基本上都是缺失的对吧?
这个通过我们的一个呃缺失值的一个直方图可以很清楚的可以看到。那么我们就可以考虑将这个缺失值这些缺失。嗯,就是说比呃就是说缺失比例比较多的一些列呢,我们是可以把它进行一个剔除的,把它剔除的。好。类似的呢。
我们也可以去算一下我们的这个每一列它的一个取值空间的大小,每一列取值空间的大小对吧?这个都是可以来做的。好。这是我们的第一张表格,那么其他的表格也是一样的,读取进来,然后看它的趋势值。
但是呢对于每张表格,你会发现它的每张表格的含义是不一样的。比如说我们的第二张表格。这第二张表格是这个企业的一个。联报信息在这个联报信息里面,它包含了一些具体的一个数据字段,就跟我们之前的是不一样的对吧?
这个地方它可能包含的是这个企业,它包具体的一个经营经营的这个员工的这个个数,对吧?以及它的一个具体的一些下岗员工的个数。这个就是说每张表格其实存储的一个信息是不一样的。好,读取进来之后也是以此类推。
对于每张每个字段可以做一个分析。好,第三个表格是这个我们的一个企业的一个纳税行为。纳税行为。也就是说每个企业它有可能有可能有这种纳税的信息,我们也是可以把它进行一个具体的一个呃读取啊编码的。好。
还有的呢是它的一个就是说企业变更信息以及企业的一个新闻舆论信息,以及企业的一些注册商标和这个判决文书的一些信息。以及我们的一个最终的一个标签,对吧?有非法集资的风险的一些企业,以及没有风险。
没有这种非法非法集资风险的一些企业。好,也就是说我们的一个整个数据集其实是包含了多个表格的啊,多个表格的。那么我们在做建模的时候,我们就需要考虑是不是呃将我们的多个表格把它合并成一张表格呢?对吧?
我们在做一个建模的时候,我们就需要考虑到啊,我们是不是需要把它合并起呀。好,那么接下来我们怎么对它进行建模呢?首先呢我们可以考虑这个地方是我们对于每张表格做编码啊。
这个首先是我们的第一张表格bsase in表格。做读取,然后删除它的一个纯空的列,以及它的一些缺失值比较多的列。然后第二张表格连报信息也是一样,读取进来,然后删除一些列。第三张表格读取进来。
但是呢在读取进来之后呢,我们也可以把它做一些编码。比如说它总共的一些列的和,就是说我将这个数据集,它的一些具体的一些字段,把它做一个聚合,把些字段把它进行求和,得到一个新的列,这个是可行的。
这个是可行的,对吧?然后呢,对于我们的一个新闻的啊,就是说公司的新闻的一些表格舆行信息的表格,我们也可以对它进行。吸取它的一个年月日,以及它最近的我们的一个新闻的一个时间。对吧这边都是可以提取得到的。
好,那么对于我们的这种纳税的这种数据呢,我们是可以把它做这样一个聚合的。group bygroup by,然后做我们的AGG。
group by AG这个地方的一个AGG是我们的一个aggregate的一个操作。做我们的一个聚合的操作aggregate。那么。怎么做聚合呢?
group by我们的ID这个地方的ID就是我们的一个企业,它的一个编码,统计一下它的一个交税的种类,统计一下它总共交税的最大值、单笔、最大值、单笔、最小值以及每笔的一个平均值。
对吧这个就是我们的一个分组聚合。分组聚合,也就是在我们的一个结构化的数据集里面,建模所必备的啊所必备的。好,那么我们也可以继续对其他的也是一样的啊。比如说我们的一个企业联报信息,它所有的一个注册的人员。
他所有的一个联报的一个状态,对吧?以及下岗人员的一个总和,我们都可以把它统计一下。做分组句划,分组句划可以统计。好。那么如果我们将这些信息都把它统计好了之后,接下来做什么呢?
接下来我们就把它墨迹到一起就行了。接下来我们就把它磨迹到一起就行了。比如说。😊,我们有base info。以及我们的训练级的标签,我们把它都默制到一起。对吧merge的时候呢。
我们就指定一下它的主件就行了。主件就使用我们的一个公司的1个ID公司的1个ID来做mer迹,对吧?好,这是我们的一个merge得到的训练集。这个呢是我们merage得到的一个测试集。
对吧这个就是我们的一个训练集,最终得到训练集,以及我们最终得到的一个测试集。Oh。那么得到了我们的训练集和我们的测试集之后,接下来呢我们就可以进行一个训练了。对吧我们接下来就可以做一个训练,怎么训练呢?
我们就可以写一个呃交叉验证的这个方法。交叉验证的这个方法。呃,我们这个地方呢是为了我们的一个呃精度会更加呃可靠一些啊。所以说我们这个地方呢是使用我们的这种实折交叉验证,实折交叉验证来做。
直者这相验制在做这个交叉验证就是将我们的一个训练题划分成训练部分和我们的验证部分。然后呢再将我们的一个训练集做训练,然后在我们的验证机上做验证,并加入我们的一个earlytop的这个机制。
这样呢可以防止我们模型的过滤盒,防止我们的过过滤盒啊,这是我们的一个二。Yes。那么我们交叉验证呢是训练多个模型,然后最终呢可以将我们的一个测试器也做多次预测。也就有多次宇测。对。
所以说如果你想要追求精度的话,也可以考虑一下用我们的一个交叉验证。好。那么通过这如上的一些操作,我们接下来就可以最终呢就可以对我们的一个测试集做预测的,对吧?我们最终将我们的一个预测结果把它进行。
如果你预测了多次,那么你就可以将最终的一个预测结果把它进行一个求均值,得到了我们最终的结果,得到我们最终结果。好,那么我再来总结一下我们的这个案例啊。这个案例的一个难点就在于它是包含了多张表。
包含了多张表,我们是需要对这多张表,我们去做一个聚合,多张表做一个聚合。这个地方的一个多张表是什么意思啊?就是说有可能有同学之前没有接触过的,可能还会有点懵。每张表它的含义是不一样的。
每张表是含义是不一样的啊,画个图啊。我画个图给大家体会一下啊。也就是说我们的一个一行。我们这个地方呢一行。Yes。もし?这个地方比不听使唤的啊。我就在这儿放吧。在这儿好。还是最最下面画啊,在这画。
我们的一个数据集呢,它是可以其实合并之后呢,是一个很长很长的一行很长很长的一行。但是呢这一行虽然说是一个样本。但是呢它有一些有一些列,比如说这部分列来自于我们的一第一张表,这部分列是来自于第二张表。
这部分列是来自于第三张表,这一部分列是来第四张表。也就是说我们有这个地方有几个啊,总共是有6个6个不同的一个数据集。也就是说我们最终呢是需要将我们的这6个不同的数据集把它合计合并成一张表。合并成一张表。
这个是在这个案例里面的一个难点。如果你能够成功的把它合并为一张表,那么接下来做建模就非常简单了,对吧?在这个地方,如果合并成一张表之后,我们再接下来就是直接训练和预测就行了,训练预测就行。好。
那么有同学可能就是说老师我直接把这6张表墨迹到一起不行吗?😡,我直接把这6张表默集到一起不行吗?不行的不行的。为什么我们在这上面要做一个聚合操作呢?这个地方我们为什么要做一个聚合呢?因为我们的有些表。
它其实是包含了多条。公司的信息。比如说我们的一个企业年报,它其实是包含了多每个公司,它多年的一个。信息的。比如说2019年的信息,以及2022010年的信息是吧?
也就是说我们的数据集这张表格其实它包含了它是一个多记录的。它是一个单表多记录的这种情况。也就是说一张表里面,它可能是对于我们的样本呢,同一个公司有可能有两条记录。
那么我们在做的时候可能是需要把它做一个聚合,然后再做我们的一个合并的啊,先做一个聚合再做一个合并的。好。大家对我们的这个案例有什么问题吗?对大家对这个案例有什么问题吗?
我们如果有问题的同学可以及时提出来哦。现在提问也是呃参与我们的抽奖的啊,送我们的月卡。对大家有什么问题吗?好。那么我们再送最后一本书啊,我们最后的一个一本书。呃,我们送这本书的一个问题。
就是说我们这个地方为什么要用数模型来解决我们的这个在这个数据里面,我们为什么要用数模型来做?我们为什么不用其他的模型来做。为什么数模型它在这个数据里面的一个精度会比其他模型的精度要高。对。
如果想要领取我们书的同学可以来参加我们的一个就是回答啊,为什么数模型它的一个精度就比其他模型的一个精度会高一些。在这个数据几里面。为什么?有没有同学知道的?有没有同学知道的?怎么做特征选择呢?
特征选择其实是呃有很多种筛选方法。特征选择其实是有很多种筛选方法的。嗯,可以通过特征重要性。他真重要性。以及它的缺失值比例。以及他的一个就是。呃,信息商。以及它具体的对我们的一个精度的贡献程度。
这些都是可以来计算得到的,可以量化的。对,可以用这些的方法。对于缺失纸和类比变量,输入模型有自己的一个优势。对,是的啊,这是非常好的一回答。就是手机用户583765同学。
恭喜你啊可以领取一本我们的一个职业书。对,老师做非线性的一个回归预测,怎么做?这个地方其实也是一个很好的问题。对于我们的一个回归问题。如果是非线性的,就是说标签。为非线性。非线性的推荐你呢。
你是把标签转为正态分布。正态分布的啊,推荐你把标签把它转成正态分布,或者说把它转成这种细线性的。因为呃如果你想让你的模型去拟和一个比较。非线性的一个分布的话,它可能很难去理合。
但是你如果想让它直接去理合一个线性分布,或者说是一个正态分布的话,它可能会更加简单一些。你可以考虑将我们的一个标签做一个呃非线性的一个转换。对。然后呢,大家现在还有疑问的话,也可以及时提出来啊。
任何相关的疑问。我们接下来呢就给各位同学介绍一下,我们现在在7约在线开设的一门课程,叫做机器学习集训营的这门课程。这门课程呢,我们刚才所讲的一些代码知识点都在我们的这门课程里面。然后呢。
这门课程呢其实也是非常干货的,它也是涵盖了我们的机器学习。所有的理论知识和我们的一个实操知识。在我们的集训营里面呢也是提供了我们的一个GPU的一个云平台,以及我们的一个实训项目。
我们基本上是每周都是由我们的班主任带监督着大家做我们的具体的一些作业。也有我们的老师在我们的一个群里面进行答疑和直播。所以说呢我们的集训营是非常非常干货的一个特课程啊。大家如果想要报名我们集训营的同学。
或者说想要了解的同学呢,都可以从我们的一个缺在线的一个官网就业转型营,然后点击我们的积极学习和深度学习,点击进去就可以找到我们的机器学习集训营。


我们今天报名我们的一个机器营,呢可以再去优惠我们的1000元啊。我们的一个今天晚上报名,我们集器营的同学可以再去优惠我们的1000元啊,在这个基础上再优惠1000元。对。
然后呢我们的一个集训营是有两两个套餐。第一个套餐是嗯就是说价格稍微高一点。但是呢它是赠送了我们的大数据集器营和这个深度学习机器营的。
而且呢我们的也是赠送了两年的1个VIP我们的一个套餐二呢是不赠送我们的一个大数据集器营和深度学习集器营。然后也是一年的一个VIP这个地方的一个两年VIP和一年的VIP呢。
都是包含了我们的一个GPU的一个云平台使用的,也是非常干货的。然后如果大家想要报名的同学不要错过我们今天的这一部分啊,我们今天这个课程。然后呢我们在课程里面呢。
我们会给大家介绍一下我们的很多的一些实战项目。比如说CV检测的一个就是说我们的性检测,以及我们的一个智能问答机器人以及我们的一个电商平台的这些推荐系统,这些呢都是在我们的这个机器学习集训营里面会包括的。
😊。



老师超参数对模型最终的精度影响会很大吗?如果是呃机器学习的模型影影响不会特别大。如果是机器学习的模型,影响不是特别大。如果是深度学习的模型,影响可能会比较大。对,如果是机器学习的模型。
影响可能会稍微小一点啊。那么怎么去做模型部署呢?这个模型部署的话,其实呃我这个地方也有代码,但是也有相关的一些操作。其实本质上。模型部署的话就是将模型把它训练下来,然后把它保存下来。
然后呢再去写一个部署的服务就行了。这个部署服务呢,你可以使用任意的一些代码来写。比如说你使用一些呃这个网络编程的一些代码,网络编程的,比如。嗯,这个地方。
你可以使用这个tonado或者说fask写一个模型部署的代码,这个就是一个tonado的一个模型的部署。tonado的一个letsBM模型的部署,就是我们加载这个模型啊。
我们加载我们的模型load进来之后,然后再做一个预测,这就是我们的一个模型的部署。嗯,其实就是这种HGTP部署模型的,不署模型的对,这个其实也是呃非常简单的非常简单的。好。
然后呢我们这个模型部署呢其实也是在我们的一个就是说课程里面也是包含的。如果大家感兴趣的话呢,也可以非常欢迎大家来去浏览一下我们的一个课程大纲。当然就是说你如果不报名也没有关系啊。
你可以去看一看我们的课程大纲做一个查漏补缺,对吧?知识点的,也是非常非常推荐大家呢可以看一下,也是就是说整体的知识点是非常全的啊。我们在这课程里面呢。
我们会讲这个大数据的一些特征工程PYpar的也会讲我们的一些模型部署的一些案例。对。😊。


基础太差了呃,基础太差了,这个也可以学的。因为我们在这个课程呢,我们的课程是从python开始学的。我们的课程是从开pyython开始学的,不是说一上来就学记忆学习。对。
如果大家想要跟着我们一起来学习呢,就是说我们是从零基础啊,基本上就是零基础带着大家学的。不是说一上来就学这种呃比较深的一些知识。对。是从。谭son开始学的啊。好。그。大家还有问题吗?还有问题吗?同学们。
然后呢,我们今天报名的同学呢,可以在我们的一个今天的这个价格的基础上再优惠1000元,优惠1000元。如果大家感兴趣的话呢,都可以加一下我们的杨老师。
然后或者说咨询我们另一位的其业在线的一个微信老师就可以。大家还有问题吗?嗯。对,大家之前加过任意的7位在线的老师都可以都可以啊。大家还有问题吗?同学们。没有问题了,这个课程会涉及深度学习基础的讲解吗?
会有的,我们就是它的一个基础呃知识点就是先是python的基础,然后呢就是机极学习的理论和这个实操。然后接下来就是这种深度学习的一个基础和实操,会有这种机机极学习,深度学习的都有的都有的。都有的。嗯。
都有的啊。还有问题吗?同学们。呃,我们的这个课程也是非常干货的啊,包含的知识点非常多的,基本上学完我们的课程呢,很多同学都是通过我们的一个课程呢找到了比较好的工作。对,如果大家感兴趣的话呢。
就是非常欢迎来报名啊,非常欢迎来报名。😊,好。还有问题吗?同学们。如果想要领取的呃,如果之前还没有加我们杨老师的同学啊,可以加一下,或者说咨询我们任意的这个呃就是企业在线的老师都行。好。😊,没有问题吗?
同学们。😡,没有问题,我们今天的一个直播就到这了。同学们,然后如果想领取我们代码和PP的同学呢,可以稍等一下啊。好。那么我们今天的一个直播就到这儿了。呃,谢谢各位同学。对,部署代码可以的。
我可以把那个发给你,没问题,没问题,可以发给你的啊。哎,可以发出来的。😊,哦。可以的,可以发的可以发的嗯。😊,好,大家还有问题吗?这个都可以发的啊,这个没有关系。嗯。好,大家还有问题吗?
那么我们今天的一个直播就到这儿啦,后续有问题的话也可以咨询我们的汽车在线的老师。好的,谢谢大家谢谢大家。😊。

拜拜。

人工智能—机器学习公开课(七月在线出品) - P3:K-means聚类 - 七月在线-julyedu - BV1W5411n7fg

。首先我们说这个剧类这个东西本身哈。很简单,它就是对大量没有标注的这些数据集,按照内在的相似性,将数据集划分成说若干个类别,使得类别以内的数据相似度比较大,而类别之间的相似度呢又比较小。
因此这里面有两个问题哈,第一个就是未标注的数据,它是一个无监督的。第二呢就是我们需要根据相似性来去将它分成若干个类别。请问如何定义相似性呢?第二,如何选择几个类别呢?对吧?这就是聚类需要涉及的两个问题。
如何定义相似性和如何选择类别数目。所以第一个话题我们需要说一下如何计算相似度。我们先先说明一个问题啊,就是说呃两个样本之间,他们我们给出这么一个说法,就是说两个样本之间不管是给定的是物理上的那个点。
还是给定的一个样本,我们总是认为两个样本之间是可以求距离的。在剧类这个PPT这这今天咱的课程里面哈,凡是谈到距离就约等于不相似度。不相似相似度就大概就约等于呃距离的。近的程度就是这么个意思哈。
就是越相似,他们就越近。然后越不相似,距离就越远。所以相似度和距离这两个词哈几乎就是一个问题两个方面,对吧?所以说我们先说明这个记号哈,这个词语是什么意思,然后呢,我们再来看后面这些关于要么是距离。
要么是相似度,本质都是做一样的东西,就是度量,两个要素之间如何去算他们的相似度或者距离,对吧?🤧。其实最最简单的一种相似度的匹配方案就是欧式空间的欧式距离,对吧?
因为我们生活的三维空间就是符合欧式空间的对吧?就是XIX和Y求距离怎么求啊?就是XI和YI各自坐标,它们的平方,然后加起来再。开平方开平平根或者是这个P等于2,就是我们经典的欧式距离,对吧?
很显然我们可以把这个P,把这个二变成P某一个值,这样的话我们就会把这样的欧式空间的距离,把它改个名字,叫做有时候就把它叫马氏距离,或者叫呃米科夫斯级距离,都一个东西哈,有有人把它叫马氏距离。
就这个东西哈,然后只不过P取别的值,这里边其实可以有种特殊情况,就是如果P取一的时候,显然就是若干个值加起来,对吧?P取一的时候,我们有时候把它叫做曼哈顿距离,就是或者叫街区距离。
就是假定这个城市是它的道路是这个东西南北特别垂直的两点就这种这种公路哈,比方说像北京市这种比较。平直的南北向东西向这种不像上海是那种渔网状的哈。
就是假定是呃就是北方若干城市那种四四四方方一座城那种感觉哈。然后两点之间求它的街区的距离,按照这个街道走,只能横着走竖着走,对吧?所以沿着X坐标走完,完了为什么就走完。
这样的话其实是P等于一的时候的情况,那还等距离哈。另外如果把这个P取无穷大的时候。就相当于啥类?大家会发现哈P如果取无穷大的时候,这个XI和YI的值谁的差值最大,那么谁占的因素就最强,对吧?
因素无穷大嘛,这块P很大,它的底下这个底数越大,它的反馈就更高嘛,所以说相当于我就只去求某一。某一个坐标下坐标细坐标下,它们两个差之最远的那个就定义为它们之间的距离,对吧?
所以这些东西都可以归纳到这样一个公式里面去哈,对吧?这是第一种计算相似度或者计算距离它的公式。另外一种,如果说给定这个X和Y不是这样两个坐标点,给定的是集合呢。最简单的一种方案。
我们把它叫做这种呃ja卡的这么一个距离,或者叫相似度哈,它就直接去把A和B这两个。这个集合求一下交,再求一下并,然后交的交集的这个数目,交集里面这个元素的数目除以并级的数目。没错。
推荐系统用的非常多的就这一类的东西,因为它会出现若干个。这个用户若干个商品嘛,推荐系统用的最非常多的,用这用这个公式哈。当然有可能会对这个公式做一点点的这个变形,对吧?那是那是咱实践里面的说法。
就是咱基本公式。都这么用,对吧?呃,第三个就是会发现什么呢?就是咱可以根据X和Y。然后呢,如果给定两个底坐标点的话,我总可以去求这两个坐标点之间,它们的余弦值,对吧?因为它们的点乘除以它们的各自的长度。
就是那个他们夹角的余弦嘛。那这样的话,以夹角移弦值是这个东西。OK我这样一个东西也可以用来度量A和B之间的夹角,它们之间的距离,对吧?另外就是我们如果把这里边的这个A和B看作是两个随机变量X和Y。
我们就可以去求X和Y的斜方差以及各自的这个方差,这样子我们就能求出所谓的相关系数来,或者把它叫皮尔逊相关系数,就是我们所说的那个相关系数哈,对吧?相关系数公式还记得吗?就把它写开了哈。
是它其实是长这样子的啊,它其实再写开就这样子对吧?就是在样本样本上哈,对吧?就这样一个公式,这就是所谓的这个皮尔逊相关系数哈,也是一个度量啊,对吧?呃,另外咱在。最大商模型里面探讨过。
如果给定两个随机这个。那个随机分布。一概率分布,一个P1个Q,他们这两概率分布怎么样去求它们之间的距离呢?可以用KL距离或者叫相对商,对吧?用这样一个公式去求它相对商。
其实本质上就是求的P对Q在log求完对数之后,对它在P这么一个。直下求他期望嘛,对吧?这个也是一个度量。另外呢我们知道KR距离不是一个对称的,就是P对Q和Q对P一般是不相等的。如果让他们俩相等。
他们俩就得是这个P和Q本身相等,然后距离都是0,它们俩相等。此外,他们距离一般是不相等的对吧?然后得到这个东西哈,另外呢就是我们可以做它给出一个所谓的对称的一个距离,就是P和Q的对称距离。
我们可以给这样一个对称的化的一个公式。对吧就叫这么一个距离哈,然后这个距离可以一个阿尔法有一个参数,就是我阿尔法取不同的值,这样子就会有不同的结论出来这样一个距离哈。总之。
咱在聚类这一部分里面哈可能会用到各种各样的距离的度量。当然用的最多的是欧式距离了,对吧?但是呢保不齐你在实践里面可能会用的是某一种,所以我把它尽我所能啊,做了一个罗列。大家看一下哪些是你所需要的。
哪些是这个我们可以当这个知识先了解一下,因为它保不齐要用嘛,对吧?这么一个内容哈。好了,我们看看大家的问题哈。😊,这里边其实我们就要说一个事情,一米阳光问了这个问题,为什么文本分类要用鱼弦?
这种一个东西来去算呢,你比说为什么我不用正常的这种别的事情啊,对不对?对吧呃,你比方说我可以把文本看作是一个。单词的集合。那这样的话,A和B我们之间求它的并级,求它交集,用这个样做不就可以吗?对吧。
我们现在呢先把它做个讨论哈。首先看一下这个。这个里边哈。对于刚才这样一个式子。我们让其中的这个阿尔法等于0。阿尔法等于零的时候,这个大体上就是写成这样一个形式,对吧?阿尔法等于0嘛,这是开方,这是开方。
这是两倍,对吧?然后这样一个东西。把它写开嘛,二减2倍的嘛,这个二呢,我先把它写个这个这个2。给一个一,这是积分是一嘛,这个积分是一嘛,所以它一样的对吧?然后既然这样的话。
把这个东西都是对X积分都把它写在一起写成这样一个形式。那显然这个东西可以写成根号PX减去根号QX的平方,对吧?这样呢我们特殊把它叫做DH这么一个距离哈。
这种东西它其实是首先咱说明哈它其实真的是满足三角不等式的,它是一个对称的,并且是肯定非负吧。因为对任意一个东西平方做积分嘛,对吧?这个对积函数本身是大于等于零的积出来肯定大于等于零的这个东西,对吧?
所以它是一个对称非负的一个距离哈,呃,并且它跟相似度之间还是有关系的。比如说我要这个阿尔法等于。正-一。阿尔法等于正-一,其实就是一个东西了哈。哎,温佳瑞是有咱那个算法班的吗?是不是也加加入了。
咱正好讲过C姆哈希哈。😊,对吧这种拉心其实它算法很简单的对吧?啊一搞它,然后分词,然后加权,然后罗着加起来就降维一出来了,对吧?嗯,这里边我们把这个话题引开哈,因为我们会看到这里边其实除了余弦相似度。
其他这几个都很很有道理。对吧很有道理,就是这么个做法,只有余先兄都看起来这夹角也能算吗?并且文本中用了这么多,大家是怎么理解这个事情的?我想卖个关子啊,大家觉得怎么理解这个事情?余显相似度。
跟别的你看别的都是这是距离的。咱推广嘛,这是他们之间的并的,除以交的,除以并的对吧?然后这个是我们正常的XY之间求它的那个呃严格论证过相关系数,对吧?它是从负一到正一的,如果是正负一的话。
他们就是这个呃不相关的对吧?等等等等一些一些结论,对吧?所以这个正负一的话,就是那个线性相关的,等于零的话,就是不相关的对吧?然后这个相对商咱也解释过,它到底是为什么这么来做,这个呢咱到时候会再再说哈。
好。我忘了在咱的这个课上讲没讲过哈,但是再说一下胰显相似度跟皮亚逊相关系数是什么关系?首先我们看一下哈。N维的向量XY求夹角,咱怎么做这个公式把它写开,这是XY点成就长这样子。
X的距离是这个Y的长度是这个,这是余弦相似度的计算公式。而。夹角鱼弦怎么算的呢?它是这个。这个分开就这个。对吧就是上面是这个,底下是这个嘛,大家发现这个东西和底下这个东西有什么区别?区别仅仅在于。
这个X如果说它的。均值是0。Y的均值是0,那么说它的。皮亚性相关系数就是我们的夹角的鱼弦。对吧其实二者之间的关系非常紧密,仅仅是XY坐标,然后各自平移到原点。没错,去均值,然后就是所谓的夹角余弦了。
这就解释了在文档里面,其实用用距离为什么用夹角余弦,它其实表证的是文档去均值以后的这种相关系数。对吧因为这不是就是一个均值嘛,把这均值已去掉,然后咱们不考虑均值了,直接算,就是说加角余弦,对吧?
如果是这我们直接算相关系数,那就是你再减去均值再去算一下就是了嘛。所以它之间的区别哈非常近,我就闭着眼睛假定你的均值是0,我就算一遍。它其实我就认为这是他们他们的夹角余弦了,对吧?它其实就是相关系数嘛。
我就认为你是围绕着原点去做分布的。因为各个词之间,我认为要么存在,要么不存在它。统一而言,它的均值我们我们如果去猜测它是零的话,都是围绕原点的话,这不就解决问题了吗?对吧这就是关于二者之间的这个联系哈。
所以。看起来这些东西好多好多公式哈,大家其实可以再近似的去想想这个所谓的这个粘这个字我都不懂我不知道啊,就这么个东西哈,它的相关系数,这个东西的相关系数集合这个相关系数,还有一线相似度和P亚相关系数。
他们之间是有关系的。其实。然后相对熵和hiage这个距离它也是有关系的。其实。把这个阿尔法取正-一就去就能把它变成这个相对商。大家注意阿尔法取正-一,这个值是是。是是是是02除以0。
所以阿尔法要近趋近于正负一去近似于这样一个过程哈。所以这是这样一个内容哈,其实它大体上都是有相互之间是有关联的这些距离哈。啊,好了,这是关于距离本身的一个探讨哈。那个咱就先把话题先引到这儿哈。
大体上就是一个呃这样一个说法哈呃,有问题吗?大家。距离是计算两个特征向量的,两文档的特征向量是什么呢?哦,不大海的意思是指的那个如何去度量一个文档是吧?就说咱往往会用最简单的一种方式来去度量文档哈。呃。
就是说怎么做呢?就是假定说。我现在统计一下这个我的所有的词是什么?就我我的词汇量,我的词词典这词是什么?我都统计完哈,然后呢。假定是有V个,就这个V是很大的一个一个一个一个长度,对吧?V很大哈。
V个哈用V。V一个,然后呢这个我就看看这篇文档,那么说第一个呃单词它出现了,OK我就在我的文档里面,这个这打个一,第二个单词出现了,ok打个一。第三个出现打个一。
这样的话我就得到一个长度是V的1个零1向量。对吧就是这个一表示是这个词在这个文档中出现过。零表示这个词在文档中没有出现。对吧这样的话我就可以将一个文档变成了一个向量。OK那这样的话我就我就可以用这个。
向量就是这样的话,在我眼中一个文档就是一个向量嘛。OK这个向量A另外一个文档向量是B,我就能求它的夹角异弦了吧。O这样清楚了吗?OK了是吧?好了,我们再看下面的问题啊啊那个谭楚丰说了TFIDF对吧?
就是我有一种方案,就是如何去度量一个词在这个文档中的。那个全值的时候,我如果不想用01而去用一个词来去度量它的重要度的话,可以用TFIDF这种方式哈。一个是词频。呃, frequency就是TF哈。
一个是这个inverse document frequency,一个是逆文档频率,就是指的是如果一个词在文档中老是会出现,ok这就是它的词力频率很高嘛。那么这个词的权重要高。
如果一个词在这篇文章中老出现,而在别的文档中老是不出现。那么说这个词对于这篇文档来讲,它是很重要的。它的权值也要很高。这就所谓TFIDF哈,它是度量一个维度上如何去算的哈,那是另那是这个事情。好的。
那这样一缕阳光这个问题应该解决了是吧?就是文档的距离不是很懂,这样应该清楚了是吧?文档相似度啊,是的。嗯,是的,大海数字典。卡卡说这个到这个是怎么算的呢?哈这不是这个是二嘛?这个是二的话。
这个积分是一啊,因为概率嘛,这个概率积分是一啊,所以把它故意写开了。写开之后我就可以把这仨写在一起,然后写成这样子,然后就写成一个的平方了哈,就这你简单一个数位变换哈。😊,呃。
2一米阳光说了二进制变码是吧?是的,就是像01嘛,对吧?看起来就像是二进制的一个东西,对吧?是的,文档向量它呃如果是那个呃我的词典大,而文档短的话,文档向量就会是一个稀数的。很正常哈。🤧嗯好了。
我们现在呢这个开始第一个内容哈,聚类聚类其实我们现在先说明那个聚类的一个形式化的说法哈,就是说嗯给定一个有N个对象的数据集。我们想构造一个K个促的话就是聚。K个促哈,K个那个部分,那这样怎么办呢?
我们保证每一个醋至少包含一个对象,并且说每一个对象至少属呃属于且只属于一个促,其实它是属于唯一的一个促的。这样子我们把它叫做K个促哈,就是这是肯定的哈,这个这个其实不说大家都明白,对不对?
然后我们现在其实基本思想就这样子的做均值的时候,就是给定这个类别是我们K之后呢,首先我们作为一个初始的划分。不同不停的去迭代改变这个样本,然后使得它隶属的这个样本和促的隶属关系不停的去迭代。
然后使得每一次改进之后的划分方案都比前一次要好一些,这样子去得到这个过程哈。贪心的思路对吧?比如说咱咱再次强调一遍啊,比方说像这个梯度下降,像决策数都是贪心的思路,对吧?
这个绝类第一个K均值也是一个贪心的思路。你们看一下啊K均值有时候把它叫做K means或者是K平均这么一个东西哈。用处是我个人觉得是很广泛,并且可以说它是最广泛的,它是几乎其他聚类方法的基础。就是。
谈剧类一定会先谈K剧K进制剧类,对吧?虽然他这实践当中呃有它的极限了,等会会看到啊。假定说我们样本是S1S2的XM怎么办呢?我们首先随机的去选择K个中心,随机选选中mU1到谬K。
然后对于某一个样本XI计算这个XI和我的聚类中心MG的距离。这个XI和MJ谁的距离是最近的,我就把那个最近的那个点假那叫做J哈,把那个值取出来,记为I号样本。它的。那个隶属那个促对吧?
然后每一个句律做完这个事情之后哈,每一个呃样本都属于自己的错了,对吧?okK这样子我的这个新的这个醋有了,把所有的样本重新做一个平均,这样子谬不就得到更新了吗?
然后回过来接着把每个样本再根据新的剧离中心再去做聚类,然后不停的做这两件事情,最终使得它的变化,或者达到最大次数,或者是剧离中心发生变化,或者是一些某一个这。指标你觉得可以了。
比方说最小平衡误差或者是一些东西哈,对吧?这样子就完成了这个K进值的聚类。它是很简单的一个思路哈,对吧?就是比方说取两类哈,那就我随便取两取两值OK平面一一批,左边这一半都属于蓝色的。
右边这一半都属于红色的OK蓝色这半再重新算它们的中心,可能是在这儿红色这一坨再算它的中心,可能是在这儿,对吧?然后再用这两个。垂直平线然又分成两部分,对吧?
然后两分钟这个蓝色的再取中心等在这儿红色再取中心到这儿,对吧?然后这个两个东西再次取水平分线,再进行聚类,对吧?然后聚离之后发现唉没什么变化了。OK慢慢慢慢的这个距离过程就结束了。对吧?
这是关于K均值的聚类。有问题吗?那不可能每个类都属于每个地方属于多个类嘛,因为我是取最小的嘛。就它总有一个最小的,我就把最小的取出来放到这个类别里面去,它不可能有取多个类,多一个对象属于多个类啊。
只有一种情况就是它到某两个类之间的距离是一样的O那你应该就属于边界上。对吧你你这个也属于中国,也属于俄罗斯,那你就在边儿上嘛,你在边儿上的话,那就那就无所谓了,随便来来一个就是了,对吧?对的边民是吧?
嗯,O这样的话呢。首先我们多说一句哈。呃,多说一句什么呢?就是。K均值是一种贪心的思路。他其实呃。做的本质上就是一个平方向的平方差误平均方误差的一个梯度下降,本身是这样子,但是咱不会咱不那么讲哈。
但是咱算法上咱咱就这么理解就是了。但是数学上是那么回事哈,大家知道就好。然后呢,因为它是贪心的,每次迭代到时候搞不定了就停止了。所以说K均值初值是敏感的。就你比方说这四个类别,我如果随机选了这四个点。
你最后聚类的时候,或许聚成这样子的四个类别。再也不会动了。或许会这样,那显然不合理嘛。对吧按照我们的说法的话,应该是这个这个这个这个是四类吗?你要记成这样就不对了。对吧所以说。
有些时候咱的时间里面要想做K金值。随机选择这些点,然后做聚类,也可能你再随机选择一些点,再做聚类,再随机选再做聚类。最后呢看哪种最好选哪个。这是要说明的第一点哈,就是K均值,它是对初值是敏感的。
这是第一个问题啊。所以说咱把它做剧类结束的时候,那一点仅仅是一个局部最优,不是全局最优。这句话很重要哈,对吧?这是第一个问题,这个代码就简单看一下吧,就是我给定数据。然后呢。
这个数据我求出那个它的长度来,对吧?这是样本的数目,然后呢,这个求出它的这个零这个它的长度,那其实就维度嘛,然后呢,我先做一下这个它的这个聚体中心,句体中心呢,我就假定都那个。做就是M个样本。
它到底属于哪个类别,对吧?我要求这个嘛,然后把所有值都数为负一,相当于我现在没有做,对吧?就是现什么都不知道的。然后呢,我算一下它的距离中心是什么。距离中心呢,我最开始先为空嘛,什么都不知道。
就是一共做K个,对吧?然后都是空的。然后呢,这个CC的意思指的是我除了聚类的时候,还需要做下一轮聚类呢。所以说这个CC是呃gluster center的,我我就随便写了一个叫CC哈。
就是下一轮聚类的那个东西,那个做迭代用的。然后C number指的是我每一个醋里面当前拿到手的有多少个样本,这个是配合CC来用的哈,这是这几个变量。然后呢,我随机选择促中心,对吧?怎么做呢?
这段是随机选择触中心的代码啊,就是我。这个先给个I等于零,表示我现在手头上随机选了零个距离触值中心了。只要这个I的值是小于K的就做这个事情做什么呢?我从零到M减一随便的去选一个数J对吧?
只要这个J和我的这个聚列中心的这个值某一些值是相似的对不起这个值我就不能我得选一个跟它不一样的,对不对?所以我我要做个判断,如果不如果跟所有的值都不一样,这个class里面有好多值了。
所有值都不一样我就把这个新的这个data把所有的值都复制到c center里面去第个就复制好了,对吧?另外呢我顺手把这个新的聚列中心为空哈,负零,后面我要用到,然后呢我多了一个样本不停的做这个事情。
这样这个 center里面就做好了K个聚类中心,对吧?那这样我怎么做呢?假定我做40次这么一个迭代过程,我这里面就随便写了个40,我发现其实做几十次足以了这。万级这种样本哈就是万级千级这样一个样本。
使了4次方,使了3次方这么多样本啊,无所足以。其实。做什么呢?对于。这个里面所有的样本样本数样本数是M个哈,所以说我是I从取出样本数啊,最多到M减一个,从那M减1做什么呢?
我看一下这个dataI和哪一个聚列中心是最近的,这是我写的一个辅助函数哈,得到C那这样的话,既然C是最近的O你这个样本就属于C这个类别,C这个类别里面的样本数目就多了一个。
然后呢我把这个dataI这个样本是值,我加到CC这个C里面去,等会要用哦,对吧?这样子其实这一步就是把所有的样本都做完了。后面呢就来做点统计,就是把所有的这K的处做点事情。
把CCI除以这个C的number,这样子不就是我得到了这个嗯新的聚列中心了嘛,这样子这个。这个促里面的样本数把它清掉,然后我把新的这个CC复制给我的下一次要用的class center。
这个东西是给这儿用的对吧?然后我再把这个CCI的清掉,这样子也是在这儿再给它下次再用,对吧?这样子就完成这个事情了。做的时候,我把这个第几次和新的基值什打出来看一眼就完了哈。这样一个很简单的一个代码哈。
对吧?我们就可以把这个K均值做出来了。好了,这是关于这样一个代码,这样子大家应该就明白,就糊涂跪糊涂说的那个事情哈。就是四个点怎么分类,对吧?你这个K几个点都可以分类一样的对吧?嗯。
A similar是一样的A similar就是我看一下这个data I这个这个class center里面现在有K减一个点,对吧?
我看一下这个dataIdataJ这个点是不是已经在这个class center里面去了。就是说这个点是不是跟它离得特别近。因为有可能我选的随机数选两个随机数是一样的。
就是这一次跟下一次甚至有可能我的样本里面也有重复的,我别选一样的,这样的话我代码就失效了。对吧你失效的话,我这你两个距律中心最开始选在一起了。那么说你最后也分不开。对吧所以这个块很关键啊。
所以我一定要确保它不能在一起,不能很相似。当然你相似,你自己写个函数就好了,你是怎么度量它相似,只要是差距在多少多以内,你就认为它相似了,对吧?自己写个就好了哈。呃,是的,我这个就是求欧式距离做的。嗯。
对对对,没错,就是剔除这个剔除这东西哈。好了,大海问了一个非常关键性的问题,就是如何。决定K取几,对吧?我们等会儿再来探讨K取几的问题哈,这是一个非常t的问题,非常。就是剧类里面最难。
最让人头疼的就是几个类。对吧。这是最麻烦的哈。嗯,当然最常见的一种情况就是说如果你有这个应用背景,你应用层面我需要聚成几个类,那没跑就是几个类。对吧你比方说咱的应用里面就需要把这个人分成这个呃。
青年中年这个老年,还有这个儿童就分这四类。那你就得这么干,对吧?这是我们实践所要求的,把它分成男类和女类,对吧?就这么个东西哈。当然实践里面你可以把它一个试哈,从3个4个5个一直试过去哈。呃。
这里边呢我们需要。做一点思考哈。第一个思考就是说K均值里面我们做的是什么?做的是所有点求均值。对吧把它的均值作为新的至心,然后去做事情或者叫重心,对吧?那如果这个醋里面最开始有异常值的话。
这个均值偏的是比较严重的。比方说给你,如果是这个醋里面现在是1234100,求均值是22,你算一下就好了嘛,对吧?那。这个22其实离我大多数1234还是很远的一个东西哈,对吧?那我要求它中位数呢。
那稍微稳妥一点,对吧?平均之后取中位数,中位数它可能更好一点,对不对?所以说可以把K均值聚类变成K中值聚类,就是这样一个聚列方式哈,对吧?这是这么一个想法哈。另外呢这个不管是你做什么。可以中职也好。
可以均职也好,初值总是会对他产生影响的。而怎么样去一定程度的避免它呢?或许可能会这样子啊,就是这个图给大家看不太清楚。我我说一下,就是说呃这是一块数据,这是一块数据,这是一块数据。然后呢,这有个加号。
然后这个这有加号,这个加号,这个加号,就最终我聚列成这三类了哈。那这样聚类之后,其实是不合理的。相当于这么一大坨三角形是一一部分,这是圆圈是一部分,这个方块是一我那肯定不对,对吧?那我怎么办呢?
我可以算一下这么一个类别,这么一个醋和这个醋里面各自的均方误差,我可以算一下。对吧如果我发现某一个醋里面的均衡误差特别大,老是降不下去。OK我就可以判断可能你这个醋锯的不对,你的初值选的不行,对吧?
怎么办呢?我就强制性的把这一个类啪分成两类。然后呢,再选择某两个距离中心最近的,把它再合成一类。因此他们俩合成一个类别,把它再随便选两个值,又得到三个点了嘛?OK我重新再锯一遍。
然后或许就能得到这样一个结果,这样子就好多了嘛。对吧所以说这是一个能够一定程度避免出汁敏感的一个思路,对吧?做二分嘛。就可以搞定这个事情了。对吧。OK这样解释一米阳光。可以吗?然后呢,我们再来看哈。
拿几个实例来去做一下啊,这个数据是我随便取的哈,我随便我自己生成的样本,然后呢。用刚才写好的代码配均值对这样的样本做聚类。如果这样一个样本分四类的话,是这样一个样子,看起来还行。对吧。
如果你把它写成我要聚六类,那就得到这样一张图。大家会发现这么个图吧,你真的很难说它就不对是吧,但是。可能没有这样好,对吧?所以说这里面有一个很。
非常让人纠结的问题就是你有时候真的判断不出来分几类是最好的。你说这个六类就真的比这个要差很多吗?事实上我这个数据哈,我是分成四类,把它凑到一块,叠在一起扔给算法的对吧?但是话说后来你分成这么类。
我我觉得也不是太差,对吧?所以这这就说不清了,对吧?所以说你分几类,你这个东西就。所以。对吧我反正我是觉得分六类有也没啥呀,对不对,对吧?就是所以我我所以你说分几类合适啊,这个东西人都看不出来。
你说让机器能看出来吗?对不对?所以说剧类里边哈好多题目都是。不太方便去判断它是哪个好,哪个差,对吧?你说四好还是6好,对不对?这个东西就得是看你的。你你你就是打怕你建一个指标出来,然后说他谁好谁坏。
你都没有一个。标准的,所以只能够根据业务逻辑看看到底分几类可能更合适一些,对吧?要通过别的这是第一个要说明的问题哈。第二个,我如果不是生成这样子的数据,我我随便生个这样的数据。
就是我这个数据本来是分成了12345分了5叉。压在一起,我自己生了这么个数据出来哈,这样子的数据分五类,12345,它真的给我分出五类来了。但很显然,这种分类方式是不好看的吧。
按道理给我分成这5个叉分成五类是最合理的,对不对?但是他给我分的是这中间算一类,这是一类,这是这是一类还行,它这分两类,这双先算一类,因为离得很近啊。对吧这两个差离得最近,所它分成一类了。
这个就不是合理的情况了,对吧?这就是K进值的特点。它适合的情况是什么呢?我考大家一下,大家通过咱给定的这个距离,大家能猜到它最适合什么样的分布的情况吗?太好了太好了太好了。
这个大家已经对这个积极学习越来越。有有感觉了哈,就是类圆形的这种分布。凸形状的这种分布,或者我们说的在。高雅一点,类似于高斯分布的那种情况。他是最适合的,他做的是平方,你用那个这种欧式距离去做。
但是他就是跟高斯那个东西是一样的。只要是它类似于高斯分布的那种情况,我基本上是能分的不错的。但是像这种分叉的是不合理。对吧这是它的一些说明哈,对吧?首先算法很简单,并且适合于大数据集也可以做,对吧?
因为我的那个狭度复杂度低啊,伸缩性啊、效率啊都是可以保证的。促近似高四分布的时候,效果是比较不错的。这句话注意哈。对吧那反过来的意思就是说嗯。不是高斯分布,它的效果就不好了。对吧。另外它有几个缺点。
第一个我们要算的是把它求均值再去做。第一,样本之间如何求均值,如果你根本就无法定义样本的均值。对吧你对于某一个场景下,你定义不了OK那你这算法完全失效,肯定不适用,对吧?
第二就是你必须先时先给定这个K这个K的值,对吧?这个K的值呢一定义下,你其实可以通过二分K均值给它一定义一下自适应去做,对吧?只是那个东西啊,并且它刚才说了,对初值是敏感的。
所以我对不同的初值导致不同的结果要多做几次调最好的。他对高斯分布好,就意味着对其他的飞图形状的醋大小差别比较大的醋就不行。另外,对噪声,对孤励点。比较敏感,因这个我们经解释过了,对吧?
1234100就不行,对吧?这样的话我们用把改成K中值距离还是到好一点了,对吧?另外呢,为什么非要提他呢?因为它是其他区的基础,比如说等会儿谈讨得到的。普鸡类就是一个哈。文祥瑞马上问了个问题。
那么说这样子的一个带分叉的东西,我就不能用K均纸量,用别的可以吗?这个东西用土句类分的非常好。呃,哎大海说了一个很好的说法,就是说K均值聚类其实就是高速混合模型聚类的一个特例。
所以说这高速分布情况特别好。我们可以这么去说哈,这是这个这个说法。呃。反正我是说过。我我我我都不知道你在哪听说的这个一个东西哈,其实真的是这样子。就是说咱在某几次课会跟大家再探讨EM算法。呃。
EM算法是可以去算一个样本点,隶属于某一个类别的后验概率的。聚类呢倒是很难去做这个事情哈。而那个EM算法呢,这个用的高速模型是我们一个入门EM的一个非常好的东西。
而K均值呢正好是聚类里一个入门类很好的东西。他们二者都是适用于高速分布的。对吧这刚才我们其实已经刚才简单的证明过,简单的想象过,对吧?实验告诉我们是真的,并且这是一个平方的一个什么东西。
那一定就是一个高速分布的,它家没跑。对吧。

人工智能—机器学习公开课(七月在线出品) - P4:SVM数据试验 - 七月在线-julyedu - BV1W5411n7fg
我们来再清晰一点的例子啊,我们先从简单例子开始。像我们这样这样本着,我们顺逆时针啊2。34好。5。六。7。好。抛一下,我们来看看这个阿尔法的这个跟我们刚才描述的是不是。7个啊。
记住是我是这个逆势正反冲值,1234567。我们现在如果说。我们不看的话。这个式子应该是什么?在这个判别平面上,它应该是夹在零和C之间啊,我们参数在这。应该加在零和一之间,对不对啊,第二个。
明显应该是0,对不对?第3个明显应该是0这个点。啊,似乎应该等于,它也有可能在就是至少如果说。可要么等于要么就比小那么一点点啊,就在这个线上,这这个也是一样,有是比较接近这个。在01之间啊。
有可能是一啊,因为它在这个线上看不清楚,那这个明显应该是。这个明显应该是等于一的啊,这个是等于0的。也就是说。也就是说什么一个数啊,小零和C之间。00啊0和一之间啊,这个应该是。零和一之间0。
一我们看是不是啊。零和一之线00。啊,这个也是零和一之间啊,它就在这条线上。然后呢,接下来这个呢-5点几E的负4器啊,当然是零嘛,对不对?对不对?哎,这个是一对,就这个线是一在这对不对?跟我们差不多。
我说这肯定在,要么就比一小一点点,要么就接近一,那就是一。没错的。接下来这个。0。833G啊,零和C之间再接下来是0,再接下来这个是一。对不对?好。我们再看看。线性和啊,我们现在呢加一个错误的分类。
负样的,我加一个加到这个位置来啊,再点击一下测试。变解了。啊。变成了这个样本呢,这个样本应该是继续,它还是只剩向量吧。应该还是这个0到C之间,也就是0到1之间,这个是0。然后呢。
这个玩意呢应该还是0到谁之间,就是0到1之间,他们两个构构造了这条线,对吧?这个别分错了,它应该是等于一。这个他参与构造了这条线,它应该是在0到C之间,就是0到1之间。这个那等于0,它完全分类的。
对不对?这个明显被分错了,它应该是等于一的,这个也应该等于一的那因此后面两个都等于一,对不对?看看是不是。啊,后面两个都等于一这个等于0啊,这个等于等于0,对吧?那这个0。59几,这个就参与这条直线了。
对不对?啊好。我们现在C是等于零的啊,我们现在简单的看看这个C。在在这个我们的线性的这个里面,C是什么关系?啊,我们加大1,我们先看大点的,谁看看怎么。哦,没有变,不要紧,加到100,我们看一下啊。啊。
这个注意这个。你改了代码以后,呢个点击一下这个我没有点啊,装载到内存里面去。好。我们看到C搭了以后。发生什么什么性变化呢?我们的这个marin啊变小的了。啊,如果说我们这个时候看现在的这一组阿尔法啊。
还是一样,肯定不会错啊,这我们就不用看了。啊,但是我们发现我我们在线性核下啊,如果说我们用这个加大了C啊。那么。我们就把这个marin变变什么变小点了。对不对啊,把这个marg变成小的啊。
因为我们这里存在一个,如果说我再加大。100。我看一下啊。更小了。对不对?他妈就越来越小。啊,那我们加大C的好处,马景变窄了以后呢,带来几个呢,我等于零的这个项变多了。变成这个项变零了。这个项变零了。
正向边。对不对?但是呢。这是因为它的 margin景变小了以后,那么它跟我们这个最初所设想的这个。maxim margin啊就是这个这个这个距离啊是矛盾的。因为我们加大了分错的项,因为我们这里存在着。
分错的可能。对不对?啊,所以说C越大什么?我们看到这个margging是会发生变化的。啊,好。接下来我们看看换一种核函数啊,我们看有什么区别。啊,好。我们还是个例子啊,我们还是用。2。
0比如说啊我们这里呢换成这个RBF内核,就和高斯核。好,我们来点击一下测试哎。他马上就彻底变掉了吧。啊刚才的这种这种这种样子都已经露出来了,对不对?好,我们发现这个这个怎么解释呢?我们看它的阿尔法项。
所有的这个红色的啊。都没有落在这个亮色区域里面,就绿色这个点和这个点可能是落在两,其他的,对不对?这就说明什么呢?这个这种图如果如果说我们说明什么呢?我们的这个sigma。学太小了。
我们看看这个加大西格ma是什么样的意思啊。你改成1。5。点击一下。哎,这个时候就就变成我们说。觉得还不错的数据了。啊。🤧大家看到。啊。这个亮色的区域变成这样子的形状,对不对?这个变成这样的形状啊。
变成这样的曲线了,对不对?这个我我们不用这个例子,因为这个例子比竟比较接近线性的,对不对?我们换一个例子啊,我们就用稍微非线性一点的例子啊,注意我们也是来构造marin,对不对?我们的样本。
我们前面说了啊,我的样本是西数。可能是边界上没有这么多点啊,但隐约是存在了一个明显的一个马景的,对不对?哦,样本是一个弯的线啊,我们看看能不能。给我把这个先给我找出来。好。哎。
这个判变平面是是一条弯曲的曲线,我们发现有错的,对不对?好,就跟我们前面做的实验一样,我们看看这个高适和下面改变C会什么感觉?我们现在改成20。好,然后点击一下。店仔啊。我几乎都分对了,但是呢变材料了。
对不对?啊,因此呢我们这个C呢明显控制的就是这个marin的这个。呃,这个这个这个宽度对不对?我们就我们就看这个我们的这个样本分类啊,它是密集程度如它越密呢。那你的C呢应该把它。
加大如果你的密集程度不够的时候呢,我们是呢建议呢就不要用太大的字。啊,因为我们这还是比较偏明显在边界上,我是很密密麻麻的纸用用大点的才。这样的话,我的这个曲线呢啊,我这边界线呢就描绘的比较清楚啊。
这个C音呢跟那个线性核呢是一样的。好,接下来我们重点来考察一下这个sigma。啊,我们现在用了个标准呢个1。5啊,如果说我们变成。5。5啊,我们来看看啊哎。变成什么了?很很奇怪,对不对啊。
变成一个这样距近接近直线的线。对不对?什么意思?这个码控制什么?这个码控制的是我们用这条线之前我们说PPT有页,我们说会。会来给我们解释的这样子的一个线来看啊,就是这条线。西格ma我们控制的是什么呢?
每一个样本都是一个三嘛,对不对?那么西格ma是控制这个三是不是很胖还是很瘦。如果说我们的西格玛区的很大,那说明我们这个山峰啊是很胖的,对不对?很胖的话。那么我这样横着一刀切过去,它的曲线就应该是。
这样子的连在一起了吧。啊,连在一起了。啊,也就是说我的西格玛越大,它的偏越偏线性。啊,越偏线性啊,就是就是非线性的落点。那如果说。我减到很小呢,于说我减到0。05呢,大家看一下效果啊。这什么?
这是K进0。啊,这个在这张图的意思就是说我切到了最顶点上,这每一个样本啊只保留那么一点点区域。啊,那那这个的极端的就最极端的情况。对绿色样本来说啊,只要是绿的附近的一点点,我认为是绿的。
其他全认为是红色的。啊,所以这个西格玛呢必须取得一个什么样的值呢?但这里我们是有可视化,对不对?我们大概看得出来哦,应该在1。0附近91。0,其实也还是。1个okK的字啊,没问题的。啊,那。
我们有可视化,当然是可以辅助来确定这些参数的。但是我们在工程中高维的数据。我们是没有办法可视化的,对不对?因此呢这个同时呢我们又观察到这个C和西格ma呢是紧密相关的啊,西格玛可以控制这个。
我们刚才说的这个这个这个这个线形和非洲这个线的弯曲啊,同时C又可以控制这个线的这个胖,就这个这个这个这个区域的胖和瘦啊,对不对?因为它是相互关联的啊,正是因为它相互关联。所以我们在实际工程应用中。
我们必须使用这种。参数选择的方法。啊,就是说我们要做很多的。交叉验证来验证我到底是取得设计一个什么样的C啊,设计什么样的C干嘛啊,也正是因为高斯荷有这么强的灵活性。啊。
我我可以做的很我们可以举个很突出的一个例子啊,琼色啊琼色嘿哎,不对不对,这样子啊,琼色。红色红色。然后呢,我们这里呢取红色。不色。红色。然后样本呢绿色。啊,然后呢嗯。😔,我们把它交叉下啊,绿色。
绿色绿色。绿色。绿色。律史。哦,红色。红色红色。啊,然后呢绿色。绿色,然后呢这里放些红色。哎,不对不对哦,是搞错了,红色红色,然后呢红色红色红色红色。然后呢,红色红色红色红色红色红色。然后呢。
我们绿色呢是比较奇怪的,哎,我们交叉分布。好,我们看一下啊。交叉分布啊。这样子的很奇怪的样子分布,我们看看在这1。0和20的情况下会什么样子。好像。不不够那个明显啊,没关系。把这个加大。诶。
就大家看到啊,这可以表现表示出一个非常复杂的一个曲线出来,但是呢都没有体现出那个画格子吧。我们把这个呢。更小一点点。好,这个时候就体现出来。画格子的味道了吧,如果说我们再把这个啊减到0。1。ok然后呢。
我们把这个呢。啊,0。1还是稍微0。3。啊,这个银格,我们继续补啊,我可以再把这个副样本副样本副样本副样本副样本。增阳板增阳板增阳板增阳板。复样本复原本复样本。然后呢。这样这样的很好呢。明白O。啊,好。
我们。诶?大家看到棋盘格已经出来了吧。对不对啊,这个例子告诉我们什么呢?高斯和可以表示很复杂的这个描述非常复杂的这个这个。啊,这个这个这个分割平面。那这意味着什么呢?它容易overfi。啊。
所以说希望个所以就这意味着两个意思。第一个它有很强的分类分类能力。这也是说这也是啊人们经常最喜欢说的,它是一个无高斯合。对应的维度提升是无限维的。啊,这是因为它有这个特征啊。
那可以形成各种各样复杂的分类函数啊,包括像这么复杂的,我们都可以做把它分分开来。🤧对吧。啊,那。诶。那也是正是因为它太强了啊,有的时候呢反而人家不建议你使用啊,这也是为什么有人会诟病这个原因啊。
但这个大家就知道一下就可以了啊,就是说用这个意思就是说用高适和虚谨慎啊,因为它能力太强啊。测能力强就是来自于他无所谓的无限维嘛。啊,OK好。这个我们就这样子的话呢,我们就把这个几个实验项目做完了。
第一个阿尔法和自撑向量的关系啊是取0。取0到C还是C,对吧?然后核函数。很大的区别,线性和就是直线,对吧?高时合有很强的能非线性的能力。好。😊,然后C参数的选择以及高时恒是西格玛的选择。啊,好。
那接下来这卡go的这个数据呢,我就啊大家看看自己去点点做做就可以了啊。那么只是简单介实介绍这介绍一下这个卡go,卡go就是一个数据数据的一个竞赛啊,那么这个还是比较水水平。还是比较高的啊。如果。
能进到一个。10分之1啊,就是说top的10%呢还是挺困难的啊,更别说进了前三了啊,那是相当困难的啊,这个我可以这里然后呢。开国数据上呢有很多各种各样的类型的数据。啊,它不只是领域数据。啊。
很多的是通用数据,所以大家都可以去试看。啊,可以去。可以去试试看耍一耍啊,这是给大家介绍一下卡go。


人工智能—机器学习公开课(七月在线出品) - P5:半小时torch教程 - 七月在线-julyedu - BV1W5411n7fg
好呃,今天我们给大家来介绍一下这个呃一个机器学习的框架啊,这是一个非常流行的一个框架之一toch。OK首先呢我们来介绍下toch是一个什么样的东西啊,为什么说它。值得向大家呃推荐啊。好。那首先来说呢。
套起呢。它是一个这个科学计算框架啊,它这是他这是他的正式的官方的说法啊。那么它主要呢我们可以简单的认为呢,它是一个面向啊这个机器学习的。
一个现代的一个类似于mate labb的一个这样子的一套工具和框架啊,为什么说它像mate labb呢?等我们会解释一下啊。好,那么拓景呢主要还是面向这种机器学习的。然后呢,同时为什么说它是现代呢?
因为。他很好的支持了。GPU啊以及一些。呃,哭打还有类似于open sale这样子的比较。这样子的这种back end的这种库啊,所以它适合于在现当下啊,我们现在来学习。
通过tor弃来呃进入这样子的深入学习呃,深深入学习这样的领域啊好。就是拓奇是一个什么样的概括啊,那么拓奇的网站呢就是这个。torch点CH啊,就这个网站啊,那么toch的核心呢是一个什么东西呢?
toch的核心啊,它呢是一个提供了一个。N维的一个。数组我们把它叫做张量啊,就是tenser啊。那么它的核心呢最核心的地方呢就是这个tenser库啊,那么它围绕这个tenser库呢,提供了类似于啊这个。
各种各样的,比如说啊indexingslicingtransposing啊,就是我们各种的缩引也好啊,各种各样的这个矩阵的变换也好,以及我们对应的这种啊线性代数的各种各样的算法。
比如说我们求矩证的乘法呀,求这个矩证的逆举证啊等等等等啊。好,那么在这个最最核心的这个。张亮的这个。库的基础上啊。那么提供了大量的类似于像神经网络啊,这个数字优化等等等等相关的这个机器学习算法的包啊。
这个就是拓取的这个重要的组成。就是一个核心核心是什么?核心就是一个。核心就是一个张量库啊,一个tensortensor library。然后在这个t library之上啊提供了各种各样的。
机器学习的算法包啊。okK同时呢它又是一个完整的,像类似于matelab那样的完整的一套工具和框架啊,这个就是toch。好,那么。大家学一套型的安装呢。那第一步呢,我们当然就是要来安装它啊。
安装呢是非常非常简单的啊。

我们直接就点这个。在拓节的官方网站上啊,我们直接点这个。Get a start。嗯,只需要呢okK那么。

当然目前这个toch呢啊只支持这个。OS ten啊以及这个乌邦图的linux啊,那不太呃暂时没有一个windows的支持啊,但我相信这应该不是。呃,很重要的一这相当比较容易克服啊。
我们只需要找一台装一个lininux的机器就可以了。那么安装整个安装过程非常非常简单,只需要执行下面三个命令。O如果你的乌关图机器上没有安装get,那么先用先需要安装get就后面就后续的工作啊。
都会通过脚本自动完成啊,大概这样的一个安装过程呢,可能需要如果说你是在在一台全新的一台乌班图上的话啊,大概可能需要将近啊半个小时的时间。因为它下载非常多的工具啊,编译工具开发工具啊,然后呢要去编译啊。
那么费比较大的时间啊,这是这个安装okK如果说你要想支持那个。GPU的开发。那你要在这个安装之前呢,去那个NVdia的网站上去下载这个酷达的安装啊,这里酷达的安装就不再详细展开。
大家可以在通过搜索引擎就可以找到啊,这个酷达开发工具的安装的非常多的资料啊,这里面可能会碰到一些啊那个比如说出错啊或者安装跟桌面啊会有些冲突。因为毕竟牵扯到这个显卡的问题啊,驱动程序啊。
那么大家尽量都可以通过这个google啊,找到一些解决方案啊,这里就不再详细展开OK。当你安装完啊,按照这个文档啊,就是instoring torch这个文档的指导装完以后呢,我们可以看一下。
首先呢我们可以看一下toch提供的什么东西。

啊,首先这个套气呢就安装好以后呢,我们可以运行加一个TH这样子的一个程序。在这个。呃,在这个我们在我们的终端之下,okK好。啊,这是在终端的一个环境下啊,运行toch它首先会有一个banner的显示啊。
就这些东西啊okK然后呢。这个时候呢我们就我们为什么之前为什么说它提供一个类似于maclab的工具呢?这是to提供的几个工具中的第一个啊是一个交互的交互工具啊。
这是一个这是一个呃基于命令行模式的一个交互工具。为什么它是说它是交互工具呢?啊,我们来试试看啊。多钱,我打个。这个时候我摁一下tab键。哎,他就会告诉我有206种可能点个Y啊,大家会看到toch内置的。

这个也就是这个张量库啊,to取的核心是我们说的是张量库啊,它提供了各种各样的这种函数啊,以及功能模块。

对吧好,那我们给这就是。唾弃的核心了OK我们比如做个最简单的例子啊。我们呢创建一个3乘以3的这个张量,叫做A啊,A等于toch点re随机。

🤧哎,我们可以打看一下A那,这个就很方便,对不对?这就非常方便,我们就可以嗯。那么这样子的一套这样子的这种呃,为什么说很方便呢?这样子的这种交互式呢,你可以呃非常容易的啊学习这个tor气里面的这些。
最基本的这些呃各种各样的函数啊,比如说我们在做个实验,B等于t7。EXP。一个比A,那么也就是说对A这个矩证啊,因为它是两回的。那么我对每一个矩阵的元素啊都用指数去运算,那么就得到BO这就是B的值啊。
对不对?因为A是一个随机矩阵随机数啊,那么BEXP啊执行一个指数啊,这样的话okK那我们再举个例子。我们构建一个我们把这个神经网络的库把它装载进来。好,那进来以后,我们可以看一下,我们我们做一个。
比如说我们做过卷机网络的地址啊。好,它就有很多的这个卷积网络的相关的这种。这种实现对不对?ok那我们做个最简单的例子啊,最最最标准的这种卷机网络的。哎,我们创建一个3乘以3的一个库啊。
3乘以3的一个啊输入是一输出是3,然后呢,3乘以3的科隆啊这些带。对,然后呢后面是一。一啊,可以啦。我要。为什么说这个交互式的环境非常好用?就是说我们可以通过简单的这种命令,不需要去开发程序啊。
我们就可以呢。来验证我们的这个。呃,这个库的这个使用啊,比如说我现在构建一个图像。啊,这个图像呢是由。是三维的O我们把它变成十是16个像素乘以16像素的啊,假设是这样子。

OK我们可以看一下这个image,它就是一组随机数,对吧?好,这个这个时候呢我们可以imB呢,我们就可以等于这个卷积网络啊,我们让它去执行一下这个神经网络中的foword的计算啊,我们用image。
这个作为输入,我们就可以得到imageB。诶。😊,这个时候我们因为基B就可以看到结果啊,我们就可以看到这数值及数值的值。那正是因为有这样的交互工具,我们就可以了解。这些我们比如说这个神经网络下面的。

有这么多的模块啊这么多的模块。

他们每一个模块啊到底是怎么用的啊,就是说我们很方便的就可以马上可以马上所见即所得啊。马上就可以看到这个下面这些这些模块呢。他们的使用的结果啊,这一点呢非常方便大家的这个调试啊,就是说呃我我我一程序。
可以在这个交互式的环境下,随时去查看变量,随时去查看函数,随时看函数输出等等等等。啊,这也是toch和toch的这种模式呢,非常利于学习的一个优点之一啊,它不像这个tenflow这样子,或者说sno。
基于符号计算的这种方式。那么那种方式呢呃如果你想调试某一个模块呢啊就相对来说。就会非常的困难啊,没有那么直观啊,不像我刚才我就自。

直接简单的一步计算,然后我就可以看到这个值啊,如果说。你看在tensor floor里面。也去看一个卷积计算到底是怎么算的,它那个参数。啊,是怎么怎么配的什么结果,对吧?啊,你要写好几行代码啊。
你要创立一个session,然后run那个session,对吧?O那我们可以。

我们可以刚才说了啊,我我随时就可以调整我的这个参数。对不对?5乘以52,这样的话我就知道这种卷积操作啊,它是。

它是怎么使用的,对不对?啊,O这个时候因为GB的尺寸。


啊,366为什么是为什么是66啊,那这里不我不解释了啊,但是这样的话我们就可以。很方便的来学习。这个这个呃。这个比如说神经网络的这个这个这个这个各个模块的这个使用啊。
这是toch的交互是提供提供一个交互的开发环境给我们啊,就是直接。

那,直接运行GH,然后呢啊你就用通通过手输入命令的方式啊,你可以包括。

啊,比如说神经网络库啊,它有各种各样的啊函数,对吧?然后你可以包括。啊,这是CUN是什么呢?就是哭打啊。一样,我们可以。我们可以看一下这个,因为我这台机器上是已经安装了这个。呃。
GPU的O我们可以看一下get。呃,我们可以看一下device properties,然后呢,我输入了一。好,那你可以打印出来哦,这是1个Gfor的GTX980TI的显卡啊。
它的memory呢现在有6个多G啊,然后呢最大等等等这些参数啊,它就全部给你列出来啊,里面的执行单元。啊有多少个啊,内存有多少啊等等等等啊,这个就是。嗯。这个这个安装好以后呢。
我我也比较方便我们去调试啊,这这个是这个是。to的第一个优点提供啊第一个提供提供的个工具给我们,就是这个教式的一个工具啊,这个呢。呃,其他的库呢因为是基于牌上的OK那拍上呢。
你需要去找一个呃呃拍上的第三方的这样的一个。呃,交互式的一个环境啊,那toch呢本身就有一个啊好。这是第一点。那。这个。拓呢除了给我们一个这个工具的,还几还有还提供了一个。啊,一些可视化的工具啊。
我们来我们来看一下啊。可视化工具呢,那比如说我们来最简单的例子。require我们1个GNU。PLPLOT啊,大家知道这是一个绘图的库,对吧?好。那我X line呢,我随便去随机一个数。Randdom。
比如说啊。我随机100个数字okK这个没问题,对吧?好,它基是100个数字。那我就可以GNU。PLOT这个我就可以看一下这一个。这是一个数组,对不对?我看看这个数组把它画成一条线。
我们看看直接可以看到效果。OK这已经出来了啊,进proO那就是个随机数嘛,对不对?它有总共有100个嘛,它的值啊啊这就是。

类似于matetterlab里面的PLT这个命令对吧?pro这个命令O这以是我刚才为什么一直说它非常像这个这个呃这个这个呃matelab啊。好,它不只提供了这样子的一些工具啊,可视化工具。
还提供了一些类似于呃。

呃,还提了一个很好的一个可视化工具,是ip pthon啊,这个呢。这个工具呢啊。我给大家演示一下。好。大家演示一下啊啊ittoch那么。No book。好。

然后呢,我们浏览器打开这个页面。

好,我们点这个。这ipad notebookbook的文件啊,这个时候呢我我这是另外一种通过web的啊可视化的工具啊,就是说你可以执行你的代码啊,可以你也可以通过这个ito image。
我们来试验一下啊,我这里。可以加一个。你说 will require呃。呃。Iage积 ok。然后呢,我们搞一个lener的图啊,这个太有名了,大家都知道的。IMGLEN a。好,然后呢X。
然后I to这个I套是。你,运行itto它内置的一个库啊,已经加载好了。那么因为。这个那好,我们执行一下。那出来了啊,这就是一个最最最最最最简单的这个通过I套的一个。一个可视化的工具啊,它不只是图像啊。
这个例子是我们在这个深深入学习的课里面啊,会会会讲的,但我就不不讲过滤过过得去。那我想想后面它的可视化的,它一样也可以通过这个pro这种工具。啊,通过外b的方式啊。哎,直接去查看这些呃。
比如说我们的我们训练的一个过程啊。啊,这是外部的这种可视化的呃方式O。

We hearない。

好。刚才讲了一个交互式的工具啊,又讲了一些可视化工具。还有一个很强大的一个。toch的一个特点啊,就是toch它提供了一个包管理工具。也就是说你可以。这个。
通过撸耳源把撸耳源的各种各样的第三方的这种呃工具包,或者说软件包通通加载进来啊。它附附送了一个什么样的工具呢?叫做lua locks啊,我们可以list似的看一下啊,这就是上面安装的各种各样的。

各种各样的这个这个工具啊,包括刚才前面的那些。来。这个por的工具也是其中之一啊,各种各样的啊,它所有的这个呃所有的这个toch也好,还有这个。神经网络包也好。
机器学习包都是通过这个撸瓦的这个包管里的工具啊,加载可以各种各样的安装卸载啊,更新啊都可以啊。那正是因为这个toch呢它不像。呃,因为它这个拓起呢是是一个闭环的系统。也就是说。
他只是需要维护他自己的兼容性就可以了啊啊,因此呢它上面。你在你应用这个toch的时候呢。绝大多数的这些开发包呢安装呢通常都比较顺利啊,它不会经常有一些兼容性的问题啊,那拍上语呢。
可能你会碰到一些okK他他的不同的库可能是开不同的目的啊,可能会有一些偶尔会碰到一些,但也不是那么主要。但是这个套起呢经常还比较的相对来说会比较的。呃,一个顺利。
我们比如说我们来给大家展某一个很有趣的一个例子啊,这个是集成了。呃,我们可以看一下lu locks list。啊,它集成了一个什么呢?open CVV的。啊,好。

East。看一下啊。这里有一个。

呃,我看一下啊。camera的一个一个一个一个一个演示啊,我给大家演示一下好了,直接。在OK这是一个集成了open CVV的一个库的一个例子啊。lu语的为什么toch会选择用lu语言啊?
那么最最重要的原因。就是入语言是一个非常容易集成C语言开发库的一个胶水式的。脚本语乐啊,这是这是它最重要的原因。O我们可以看一下这个用open CV的一个demo的这个演示啊。
这也是一个深度学习的一个例子啊,大家可以看一下。


啊,他天天去调open CV。打开这个camera。OK他就把人脸呢识别出来,并且呢性别也告诉你啊,这是一个训练的一个卷积网络。okK他会告诉你这个性别啊以及年龄。啊。
而且是可以做到实时的一个demo啊,这就是我说的呃lua呢这个它有我把它推出来OK。啊,你就说呢。呃,它有呢各种各样的第三方库啊,这是我想说说的这个撸的一个。奉送的一个。啊,第三个东西啊。
第一个它是一个交互式的一些开发工具,对吧?刚才我们说了,就是通过这种cil的,那么他还送了他还呢又有了一些这个。可视化的工具。okK啊,可视化的,我就说刚才说的那个类似于prota。
类似于ittoch啊,那还有呢很丰富的第三方的开发库啊,那所有的这个toch的。

这些资源的总入口呢啊就是这个页面。就这个它的chet sheet啊,那么。这个汽的这段汽的系统呢把这个。透起的几乎所有的这些重要的。开发资源啊,以及第三方的库啊,还有文档的入口啊。
全部都可以在上面找到啊。比如说我们现在要去找一个。唾弃的这个。tenser库就是tensor的这个使用,我们就点touch这里。OK然后呢拉到下面来啊,这下面就有各种各样的文档。比如说。张量库的文档。
你们可以看一下。啊,然后这里就是它也会有一些非常写的非常好的一些文档啊,怎么样去。构造一些张量库,然后怎么。各种各样的线性的线性代数的函数怎么调用啊,比如说这是。三天库ok那我们也可以去看看这个。
积续学习相关的啊慢训 learningning啊,神经网络的这是最重要的。啊,他除了神经网络之外呢。😊,那也提供了一些,比如说看这个unerervis learning的,它提供了PCA啊。
提供了这个呃。很多啊包括SVM,包括啊又包括优化算法啊呃包括像。啊,这些啊各种各样的KNN啊也提供了啊,对不对?然后呢,K命也有啊,这都有啊,常规的呃很多的这种继续学习算法呢都会有一个toch的一个。
实现。但然它最重要的啊就目前用的最广泛的还是它有关于神经网络的这部分啊。OK那我们可以看看NN的这个文档啊。拿到下面来。啊,这些它的文档啊,神经网络的这个比如说各种各样的文档,各种各样的layer。
比如说我们点进去看一下。啊,各种各样的线性的库等等。我们就可以看到这个这个这个呃文档就写的呃,它托起的文档还是相对来说还是比较的呃清晰啊呃,非常容易看懂的OK好。

这样的话。接下来呢。😊,我们再来介绍一下这个。为什么给大家给大家推荐这个toch作为一个呃深度学习的一个入门的工具呢?除了前面这些易用的这些特点之外呢,还有一项啊。
我我认为我自己我认为啊是一个还是非常呃非常好,就是它拥有大量的。

开源软件的这种学习的例子啊,我给大家举几个例子。啊,这些这些。这些工程也好。这些工程都是。用的都是非常多的广泛的啊,我给大家看一下。大家举几个例子啊,第一个例子。如果说。诶。😊,第一个例子是什么例子呢?
哦,这是一个用我们看到呃撸的对吧?撸的语言开发的这是一个呃在这个动漫界非常有名的。他实现了一个什么呢?它实现了一个智能的一个图像领域啊,实现了一个智能的一个放大啊,可以把这种。动画呢放大的非常的漂亮。
而不会像一般的软件的放大啊,带来一些毛刺啊,它可以去掉这些图像的这些毛刺啊。这个问题实际上在图像里面是一个比较难处理的问题啊。但是它通过这个深度学习的方法提供了一个工具啊。
那大家可以看到这个项目的大有5000多个。这这是非常了不起的一个一个一个一个一个一个一个一个应用啊,大家可以看到这个这这套深深度学习的这套这一套。工具呢在著名的这个B站啊,大家哔哩哔哩啊。
相信大家都很清楚,使用很多用户就用这个。透气开发的这套工具来压缩啊这些动画动画片啊OK啊,这些这些这些卡通。那,确实会。比传统的这种视频处理的要非常的清晰啊,这是这是第一个例子啊,大家可以看到。
5000多的啊非常非常有意思啊,这也是用托器开发的。🤧好,再给大家举几个例子。第二个例子我是给大家举的是这个例子哎。OK啊,这个例子。这个例子叫做呃这个例子是一个有google最先做呃,最先。做出来啊。
就是那个类似于deep stream的这种东西。但是这个呢更有意思,这是那个。

就是图像的这个风格化啊。啊,比如说。这张图啊是圆这张图我们知道大家这个应该是很有名的一幅油画,对不对啊?这张图呢是我们拍摄的照片,我们可以把油画的这个风格呢融入到这种我们实际拍摄的照片当中啊。
形成下面这张画的神奇的效果啊,大家可以看到这个例子非常漂亮。这是一张照片,这是一张油画,最后可以形成各种各样的这种。啊,这这是原图啊,这是那种瘸出来的各种各样的风格化啊。
这个是让人非常着迷的一个一个一个一个一个一个项目啊,非常有意思,做到非常棒。可以形成各种各样的这种呃画啊,对不对?很有意思吧。可以这个。

所以呃这个就就就非常有意呃非常非这是一个非常非常有意思的一个项目。给以大家看到哇,这个四大数已经超过6000多。啊,这这都是用套气啊,你对不对啊,这是这个也是用啊用套气来开发的。
OK我再给大家举一个例子啊。O敲错了。啊,这个例子。这个例子是一个什么例子呢?嗯,这是一个那个。输入一张图片啊输入一张图片,然后呢输出一个这张图片的文字的描述的一个一个用这也是用toch来开发的。啊。
给大家看一看啊,这个网络比较慢一点,特不要紧。这个是一个做的非常棒的一个这个开源软件的一个项目啊,它的s大的数目呢也能超过2000多啊。大家可以看到啊。
一个 man sitting a table with a laptop啊,说一个人坐在一个桌子上,然后呢拿着一个笔记本电脑。okK啊。
一个 littlettle boy standing in the field of kind把风筝识别出来了,小孩识别出来了啊,就是你输入一张图片。好,给出这个图片的描述啊,这个这个很非常非常好玩吧。
这个项目对吧?这个。也,从这个呢也是用透气来开发的啊,大家可以把这个管件下载下来,然后呢直接给跑,也可以有它既有圈引圈引的代码。也有应用的代码。OK好,再给大家举个例子啊,前面举的都是些图像领域的。
对不对?那也有一也有一些。这个是什么例呢?这是一个嗯。这是一个那个NLP的例子啊,是用的是LSTM那这是字符模型啊。这个项目是什么呢?我们通过一些文本的训练,我们输出一个文本生成生成器。啊,O。
这个呢我它这是个非常有名的一个项目啊,也是非常有名的项目。然后呢,它生成的东西呢,我们可以看下来在文章啊,它的文章在这。啊,这篇文章背景用的非常多啊,大家如果如果如果知道这个。呃,O。
通过这个模型呢啊刚才那个工程呢,我们可以学到呢生成一个东西就是。我们可以生成什么文本呢?啊,我们可以生成比如说莎士比亚的文章啊,这些都是它生成的啊,虽然它。我们可以看到它它它有的单词根本是不准的。
但是它的样子啊,大家仔细一看,它的样子啊非常象征的啊,甚至呢它甚至可以输出呢。这个维基百科的这种呃正式的这种文本,你通过这个维基百科的文本去训练,然后呢它生成一个文本训练器输出器。
它可以输出啊维基百科的类似于维基百科的这种文字啊,甚至还包括像。论文啊,大家看到这个论文是假的啊,这个论文是是通过这个神经网络啊,是度深度学习这种模型啊,自动生成出来的,根本没有意义。
但是呢你乍眼看过去啊,你区别不了啊,对不对?包括还包括呃很多啊还包括这个这个这个。linux科录代码啊,这是很神奇的一个这个叫做呃charact level level language model啊。
这是一个呃在这个。LLP领域这个很重要的一种模型啊,那它这个呢啊也是用这个tor起来进行开发的。也就说okK我们拓起也可以开发,除了开发这种类似于卷积网络啊,前面说的那同样它也可以去开发,类似于。
RNN啊STM呢这种都没有问题啊,这个这个不像卡啡,咖啡做RN会比较相当的费劲啊,但是这个套起没有这个问题。OK好。

那。刚才介绍了这个吗?套起的又一个的特点啊。还有。丰富的。开源软件啊,就是有丰富的这种。以及人家做好的工程,你可以拿来学习和参考的。啊。这样的呃。工程啊很有意思,对吧?那通过这些呢。
优秀的这些开源软件呢,你可以迅速的。进入到深度学习一些比较有意思的一些领域。一些点啊,我们可以再看一下这个。

哦,前面都是举的这都是一些比较有意思的一些例子啊,工程例子。当然我们也可以看一下。学术界、政治和工业界正儿八经,他们用套起做的一些事情啊,我们可以看看这个这个。拓弃网站上的这个bb这一项。
那因为呢pch这背后的使用者呢,有大量的人呢是存在这个啊。可以看一下okK。ok比较稍微网络比较差一点点。ok出来。主要是什么人呢?那么。呃 who are we。啊,那么主要是。
那么主要的维护者呢是facebook的facebook啊以及这个google的deep mind啊,他们这些人呢啊大家看到这些如果大家去看这些都可以是经常能收到他们的论文的人啊。
他们是也是活跃在这个学术与工业界的一线的这些研究者啊,由他们来维护这个工具,主要是主要的两个贡献。我们可以看到就是就是facebook啊。
一个是google的dep mind啊对 one达都手阿尔法 go就是这个。就是这家公司开发的啊ok。正是因为如此呢,所以说。我们可以看到呢,这个用toch一样也会用在一些学术的。学术的这种圈子里面啊。
比如说。呃,最近这个最流行的这个长插网络,对吧?那OK那face可呢很快也就给出了一个。啊,他很快就会给出一个自己的实线啊,大家可以看到是在这。
这是facebook开开开放出来的这个用tor做的啊长插网络的训练啊呃大家也可以去通过这些这些工程啊,比如说长插网络啊,再比如说像啊很有名的一个。对抗网络的一个一个一个一个一个工程啊。
这些呢同也是用也可以用这种套气啊,去跟踪目前一些最深度学习领域,一些最新的啊一些模型,一些算法啊,比如说我举了两个例子,一个是长插网络啊,然后一个是对抗网络啊。
都是那在这个领这些领域的这些学者或者工业界的这些。科学家们也用套析作为工具啊来进行这个深度学习的研究啊,那okK那举得这么多例子啊,最后我们来这个。

评价一下这个to析。就说。我自己的观点,他非常适合深度学习的初学者以及入门。啊,同时他也是本身也是个不错的一个。工具啊。当然了也有台,但是啊也我们也说下他这个一些不足之处了。第一,他用的是这个。呃。
这个撸啊。如话语为我先呃。因为它这一款这是一个。还有用撸外语言其实是一个非常好的,它也广泛的用在这个互联网啊互联网领域。比如说这个最有名的一个eng的一个扩展啊,open rest P是吧?
这个就是卢尔开发的。🤧嗯。那这是它的一个小众的个地方啊,不像别的。库啊绝大多数库呢用的都是这个python啊,他呢选择了如啊,这是他的一个一个呃跟别人比啊。
不是那么那么那么那么那么突出的一个一个一个一个点啊,那还有一个呢toch和卡费呢。那么都是使用的。我们刚才给大家演示过啊,就是说。都是基于这个层的啊,我们可你看神经网络有多少度啊,它都是一个个组件啊。
每一个组件呢每一个层呢都有这个固定的一些函数啊,是基于layer的,就是是就是说。

他不是像这个。这个现在更加技术上更加怎么说呢?应该说理念更加好的一个就是。基于符号计算的啊,我们可以看一下这个。

呃,这个tensor flow的这种。

这种一个举举一个最简单的例子给大家。


好了,举一个最简案例到这里。我们可以看一下啊,待会就给大家一个。

一个。

嗯,在?

Okay。哦,我知道了,不好意思,再等一下啊。


OK我们看一下tensor floor的这种例子啊。给大家对比一下。

啊,Otensorflow的例子呢是这样子,它所有的。

并不是基于成的概念啊,我们会看到这个最后这个所有的网络呢。

啊,这个X其变量啊都是事先啊都是不知道的啊,就说是一个符号的啊,是一个未知的。但是呢它通过串在一起一个计算的一个。

呃,我们它叫做graph这样的一个东西。最后通过通过一个comppier的过程,生成一个最后你要的神经网络的这个计算的这个实际的代码啊,这种理念呢跟我们今天介绍的torch呢是完全两种啊。
所以我建议大家呢。


通过套起。掌握。入门啊,然后呢接下来可以去学习一下tenorflow啊,类似于sno这样子的基于符号的。我相信。啊,这两种风格啊,如果说。都接触和掌握的话啊,会对这种。啊,这个至少在学习框架上。
在这种深度学习框架上啊,会有一个更深更好的这样子的一个啊理解啊,这是我的一个简单的一个自己个人的一个建议。好,那今天我们再回顾一下啊,我们介绍了套起是一个什么东西,对吧?

这个我们看到这是toch的主要的网站,对吧?我们简啊,然后呢。

我给我们给大家介绍了一下这个toch提供了什么样的一种。开发工具啊,它有一个交互式的开发工具啊,它有一个。可视化的工具啊,同时它又有一些。各种各样的第三方的库啊,同再呢。
我又介绍了一些基于套系的很有趣的一些也非常有名的一些。开用软件啊。很容易吸起大家引起大家兴趣的一些开源软件啊,然后呢我们在最后呢再给大家介绍一下这种to起的这个。思路啊以及这个基于符号计算的一个思路。
就以t flow作为一个例子。那今天的这个介绍呢就结束到此为止,谢谢大家。






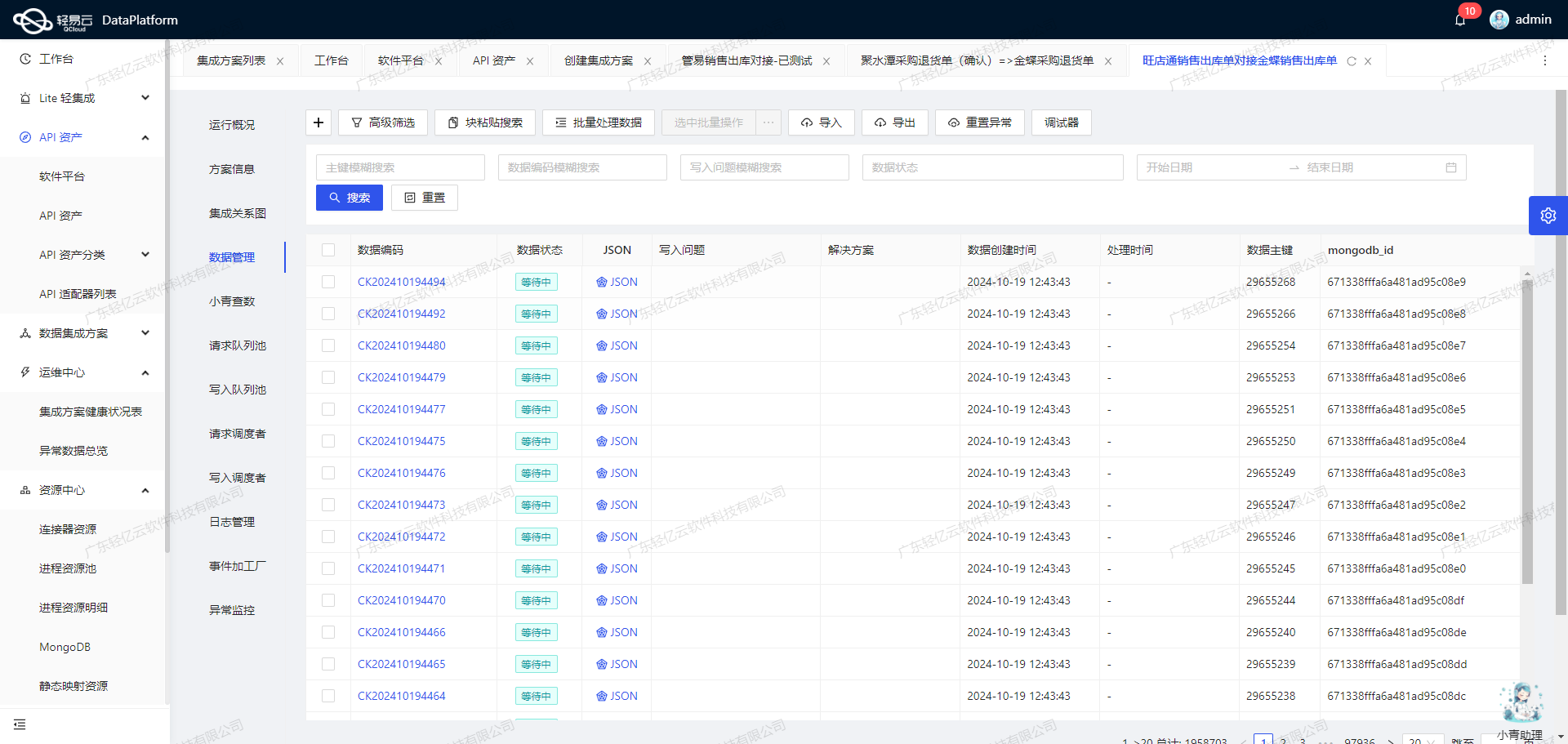

![[LibreOffice Calc]打印表格时自动缩放到与纸张尺寸匹配](https://img2024.cnblogs.com/blog/1324435/202410/1324435-20241023180847841-1688722778.png)