作业①:7日天气预报爬取
1. 作业代码与实现步骤
我们将在中国气象网爬取北京、上海、广州的7日天气预报,并将数据保存到数据库中。以下是实现步骤。
步骤详解
-
打开中国天气网:在浏览器中访问中国天气网。
-
搜索城市:输入“北京”并打开其天气页面。
-
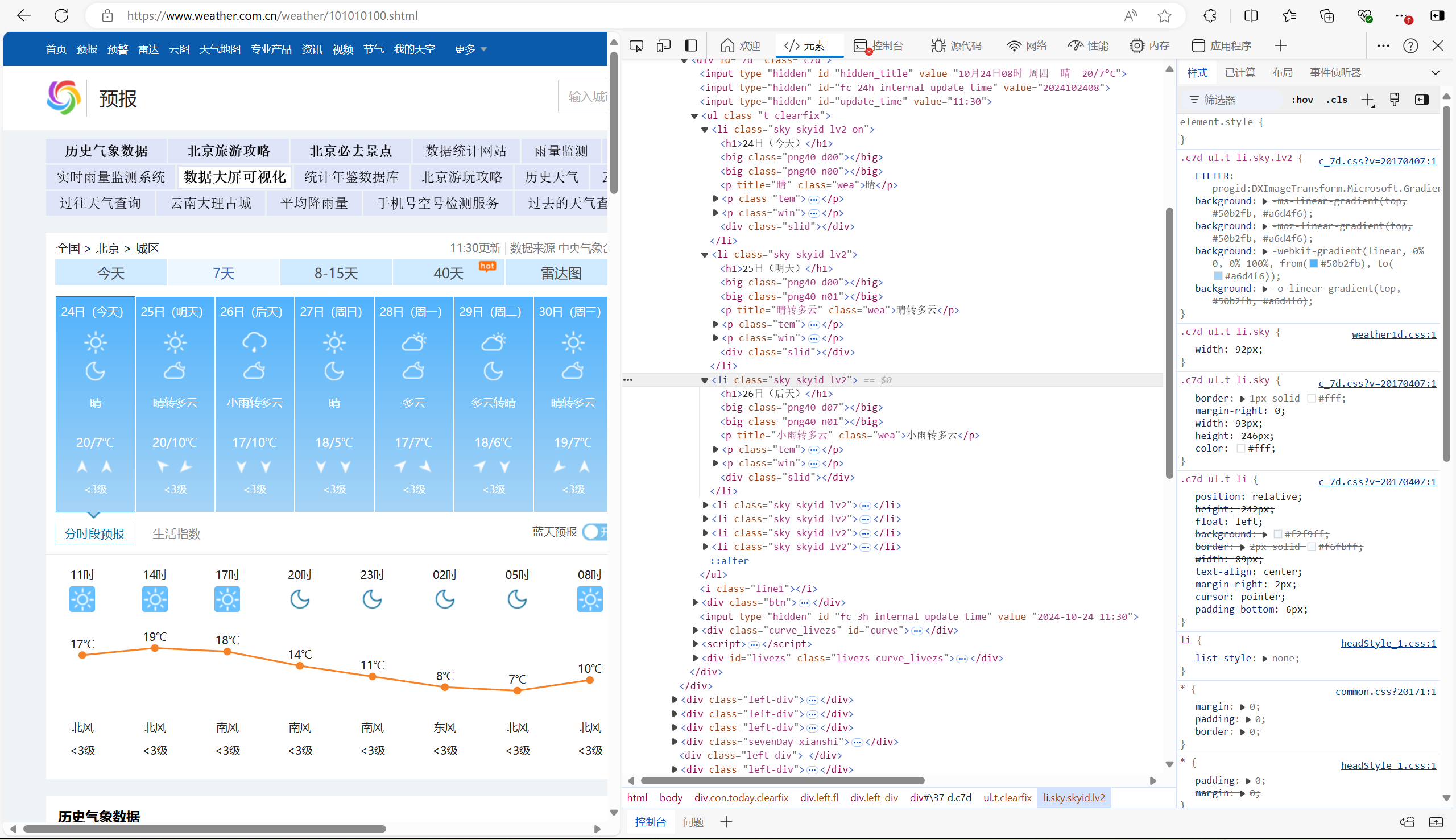
检查网页结构:使用浏览器的开发者工具(按F12)查看网页的HTML结构。
- 每天天气信息存放在一个ul元素的li元素中。
- 日期在li下的h1元素中。
- 天气状态在li下的class为'wea'的p元素文本中。
- 温度信息在class为'tem'下的p元素中的span和i元素中。
-
获取城市编码:北京的城市编码为101010100,据此我们再分别获得上海和广州的城市编码,我们将其存储在字典中,以便构造URL使用。

-
使用BeautifulSoup进行数据爬取:使用CSS选择器查找HTML元素并提取信息。
代码示例
# 给定城市集的城市ID列表(北京、上海、广州)
cities = {"北京": "101010100","上海": "101020100","广州": "101280101"
}# 爬取每个城市的7日天气数据
for city_name, city_id in cities.items():url = f"http://www.weather.com.cn/weather/{city_id}.shtml"try:headers = {"User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre"}req = urllib.request.Request(url, headers=headers)data = urllib.request.urlopen(req)data = data.read()dammit = UnicodeDammit(data, ["utf-8", "gbk"])data = dammit.unicode_markupsoup = BeautifulSoup(data, "lxml")# 获取7天天气预报信息lis = soup.select("ul[class='t clearfix'] li")for li in lis:try:date = li.select('h1')[0].text # 获取日期weather = li.select('p[class="wea"]')[0].text # 获取天气情况temp_high = li.select('p[class="tem"] span')[0].text if li.select('p[class="tem"] span') else "N/A"temp_low = li.select('p[class="tem"] i')[0].texttemperature = temp_high + "/" + temp_low # 获取温度(高温/低温)# 打印天气信息print(f"{city_name} - {date}: {weather}, {temperature}")# 将数据插入数据库c.execute("INSERT INTO weather (city, date, weather, temperature) VALUES (%s, %s, %s, %s)",(city_name, date, weather, temperature))conn.commit()# 关闭数据库连接
conn.close()print("所有城市的天气数据已保存到数据库!")
图片展示
打印结果
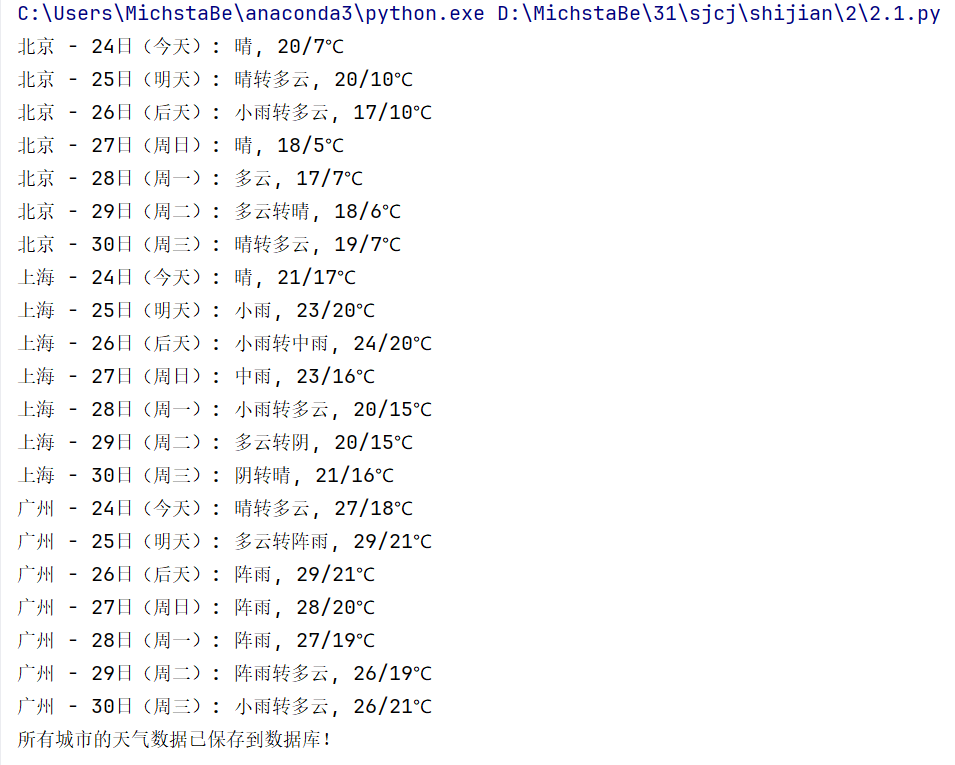
数据库结果
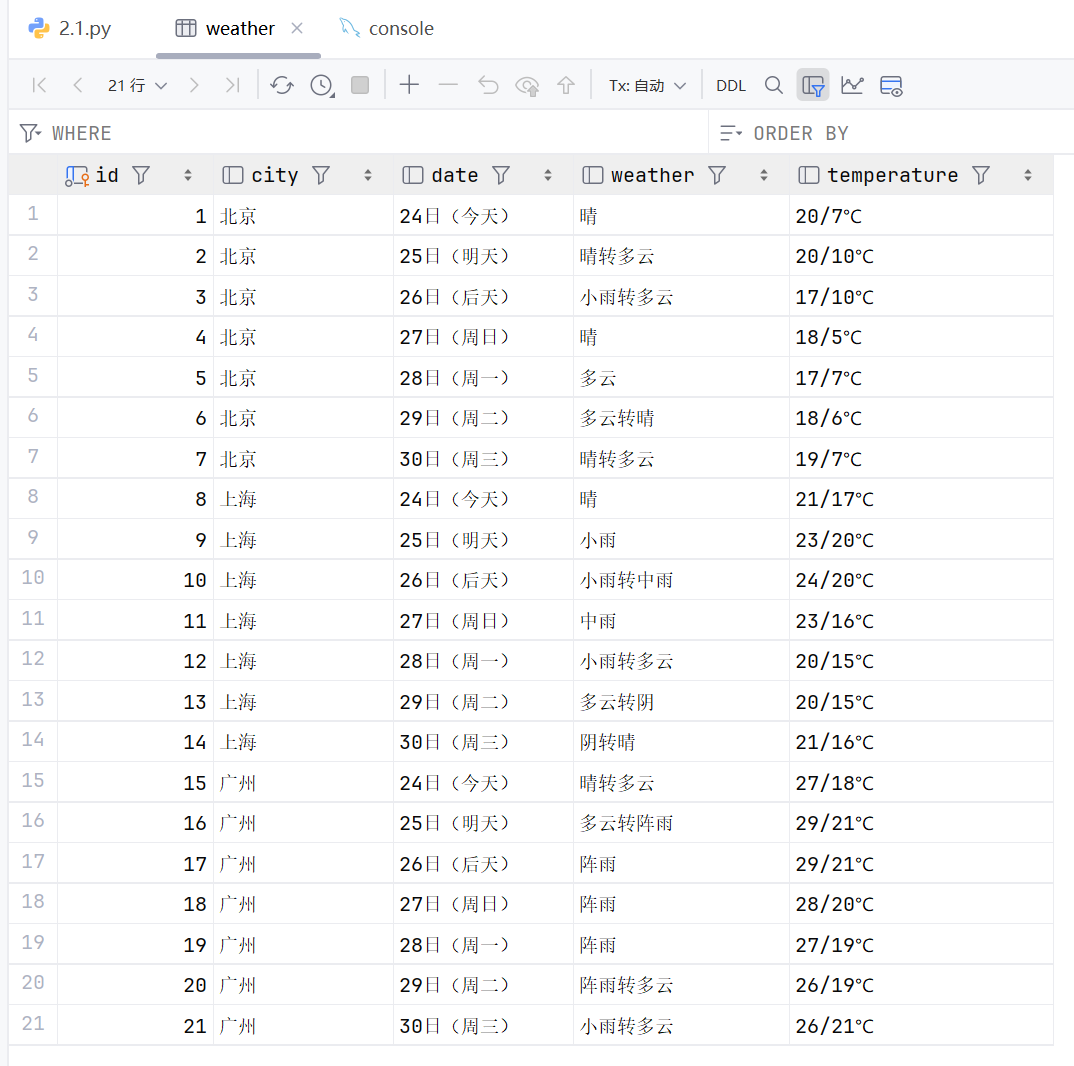
2. 作业心得
在这个作业中,我深入了解了如何从网页中提取结构化数据。通过分析HTML结构,我能够高效地使用CSS选择器定位所需信息,并将其存储在数据库中。此外,学习到城市编码的管理,使我能够灵活处理不同城市的天气数据。这些知识对我今后的学习与实践都大有裨益。
作业②:股票信息爬取
1. 作业代码与实现步骤
接下来,我们将使用requests和BeautifulSoup库爬取东方财富网的股票相关信息,并将其存储到数据库中。
步骤详解
- 选择股票信息网站:以东方财富网为例,访问 东方财富网。
- 分析网页结构:打开开发者工具(F12),观察股票列表的加载情况。
- 查找数据API:通过网络请求(Network)标签,寻找股票数据的API地址,并分析请求返回的数据格式。
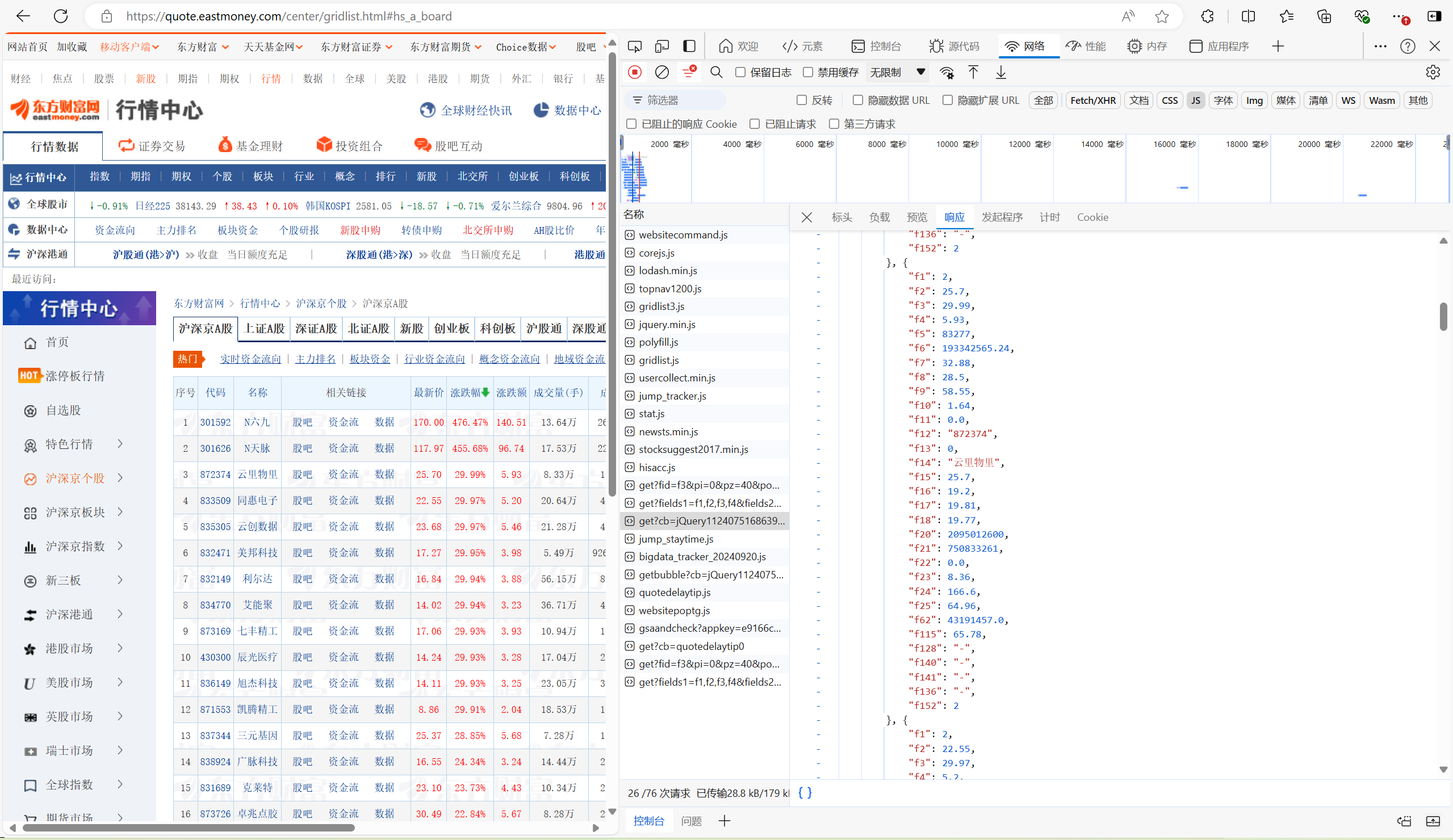
- 提取url,获取单页数据:直接通过requests库的get就可以直接加载数据,对应的文件数据如下。通过分析,我们可以得到单只股票的数据都以字符串的形式被存放在“data”下面,而且控制翻页的参数主要是p参数,所以只要用一个page变量来替代页码,构造新的URL,再通过for循环就能实现提取多页数据。

代码示例
def get_html(cmd, page):url = f"https://7.push2.eastmoney.com/api/qt/clist/get?cb=jQuery112409467675731682619_1703939377395&pn={page}&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&wbp2u=|0|0|0|web&fid={cmd}&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152&_=1703939377396"response = requests.get(url, headers=header)data = response.textleft_data = re.search(r'^.*?(?=\()', data).group() # Extracting the callback function namedata = re.sub(left_data + '\(', '', data) # Removing the callback function namedata = re.sub('\);', '', data) # Removing the endingdata = eval(data) # Evaluating the string as a Python expressionreturn datacmd = {"沪深京A股": "f3&fs=m:0+t:6,m:0+t:80,m:1+t:2,m:1+t:23,m:0+t:81+s:2048",
}null = "null"
for market, command in cmd.items():page = 0stocks = []while True:page += 1data = get_html(command, page)if data['data'] != null:print(f"正在爬取 {market} 第 {page} 页")df = data['data']['diff']for index in df:# 处理数据,确保插入时不出错#插入的数据会有“-”的出现latest_price = float(index['f2']) if index['f2'] != '-' else None change_rate = float(index['f3']) if index['f3'] != '-' else Nonechange_amount = float(index['f4']) if index['f4'] != '-' else Nonevolume = float(index['f5']) if index['f5'] != '-' else Noneamount = float(index['f6']) if index['f6'] != '-' else Noneamplitude = float(index['f7']) if index['f7'] != '-' else Nonehighest = float(index['f15']) if index['f15'] != '-' else Nonelowest = float(index['f16']) if index['f16'] != '-' else Noneopen_price = float(index['f17']) if index['f17'] != '-' else Noneclose_price = float(index['f18']) if index['f18'] != '-' else Nonevolume_ratio = index['f10'] if index['f10'] != '-' else Noneturnover_rate = float(index['f8']) if index['f8'] != '-' else Nonepe_ratio = index['f9'] if index['f9'] != '-' else Nonepb_ratio = index['f23'] if index['f23'] != '-' else Nonestock_dict = {"代码": index["f12"],"名称": index['f14'],"最新价": latest_price,"涨跌幅": change_rate,"涨跌额": change_amount,"成交量(手)": volume,"成交额": amount,"振幅(%)": amplitude,"最高": highest,"最低": lowest,"今开": open_price,"昨收": close_price,"量比": volume_ratio,"换手率": turnover_rate,"市盈率(动态)": pe_ratio,"市净率": pb_ratio,}stocks.append(stock_dict)# 将数据插入数据库c.execute("INSERT INTO stocks (code, name, latest_price, change_rate, change_amount, volume, amount, amplitude, highest, lowest, open, close, volume_ratio, turnover_rate, pe_ratio, pb_ratio) VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)",(index["f12"], index['f14'], latest_price, change_rate, change_amount, volume, amount, amplitude,highest, lowest, open_price, close_price, volume_ratio, turnover_rate, pe_ratio, pb_ratio))conn.commit()else:break# 关闭数据库连接
conn.close()print("所有股票数据已保存到数据库!")
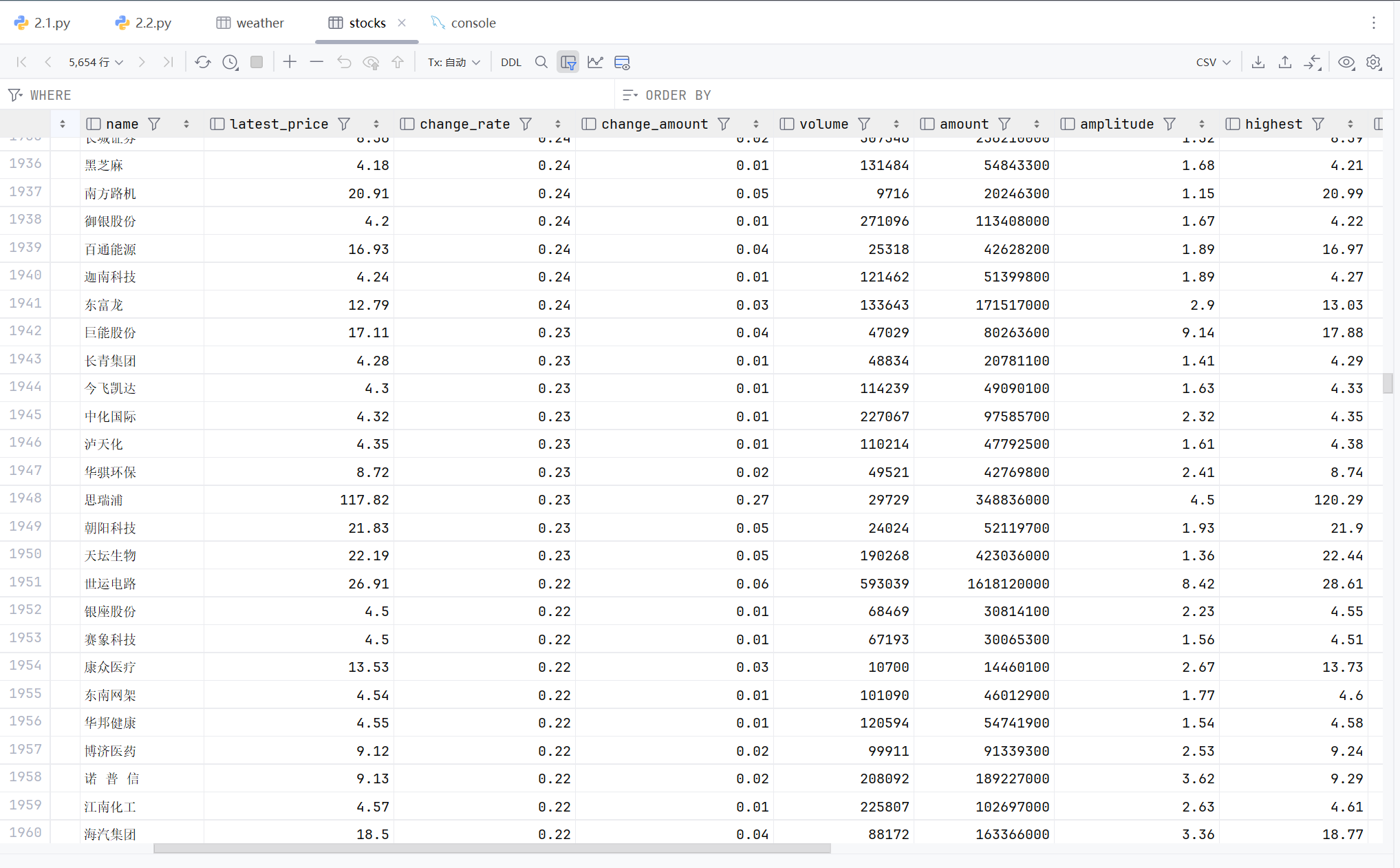
图片展示
打印结果
数据库结果
2. 作业心得
通过爬取股票信息,我更加熟悉了网络数据的获取和处理过程。在分析网页结构和API请求时,我掌握了如何有效提取和存储数据。这不仅增强了我的编程能力,还让我对金融数据的实时更新有了更深的理解。
作业③:中国大学2021主榜爬取
1. 作业代码与实现步骤
最后,我们将爬取中国大学2021主榜的所有院校信息,并将其存储到数据库中。
步骤详解
-
访问目标网站:前往 中国大学2021主榜。
-
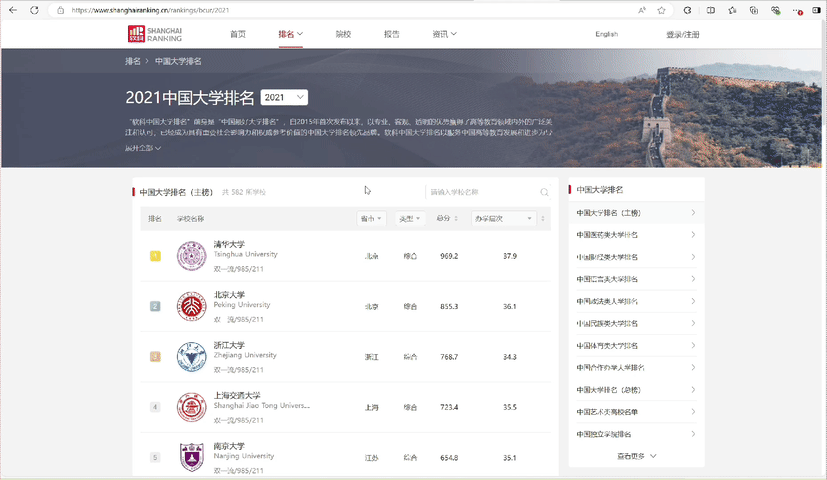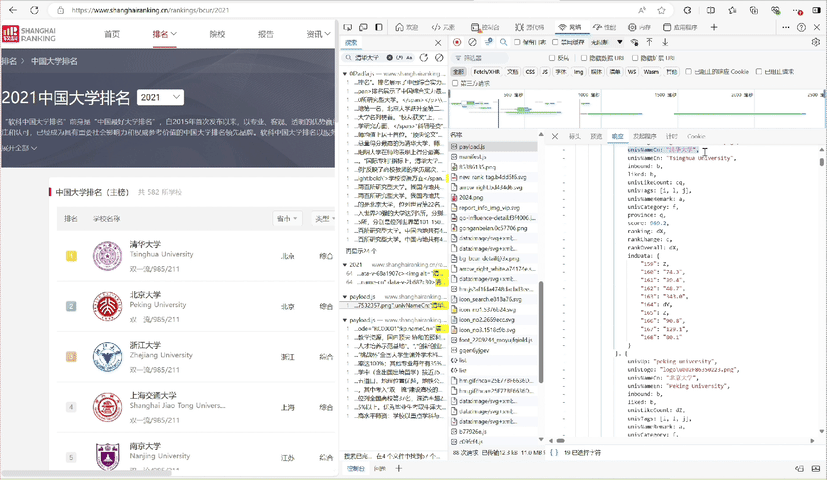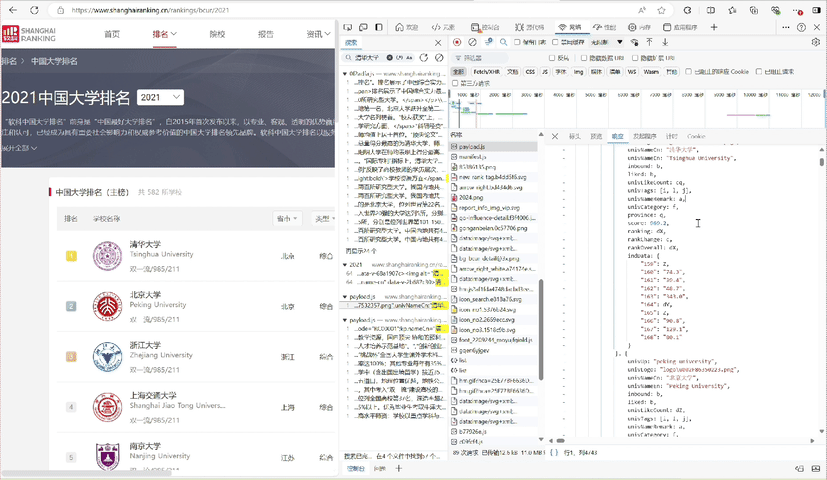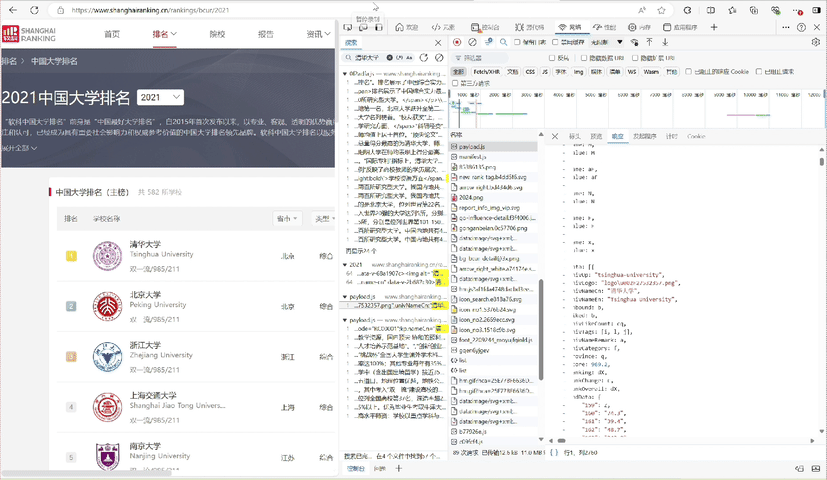
检查网页结构:使用F12打开开发者工具,分析表格结构。
-
循环遍历提取:使用BeautifulSoup提取排名、学校名称、所在城市、类型和总分。

-
存储数据:将提取的数据保存到MySQL数据库中。

代码示例
def printUnivList(ulist, html, num):data = json.loads(html) # 对数据进行解码# 提取 数据 rankings 包含的内容content = data['data']['rankings']# 把学校的相关信息放到 ulist 里面for i in range(num):index = content[i]['rankOverall'] # 排名name = content[i]['univNameCn'] # 学校名称province = content[i]['province'] # 省市score = content[i]['score'] # 总分category = content[i]['univCategory'] # 类型ulist.append([index, name, province, score, category])# 将数据插入数据库c.execute("INSERT INTO university_ranking (`rank`, name, province, score, category) VALUES (%s, %s, %s, %s, %s)",(index, name, province, score, category))conn.commit()# 打印前 num 名的大学tplt = "{0:^10}\t{1:{3}^10}\t{2:^10}\t{4:^10}\t{5:^10}" # {1:{3}^10} 中的 {3} 代表取第三个参数print(tplt.format("排名", "学校名称", "省市", chr(12288), "总分", "类型")) # chr(12288) 代表中文空格for i in range(num):u = ulist[i]print(tplt.format(u[0], u[1], u[2], chr(12288), u[3], u[4])) # chr(12288) 代表中文空格def main():uinfo = []url = 'https://www.shanghairanking.cn/api/pub/v1/bcur?bcur_type=11&year=2020'html = getHTMLText(url) # 获取大学排名内容printUnivList(uinfo, html, 30) # 输出排名前30的大学内容main()# 关闭数据库连接
conn.close()
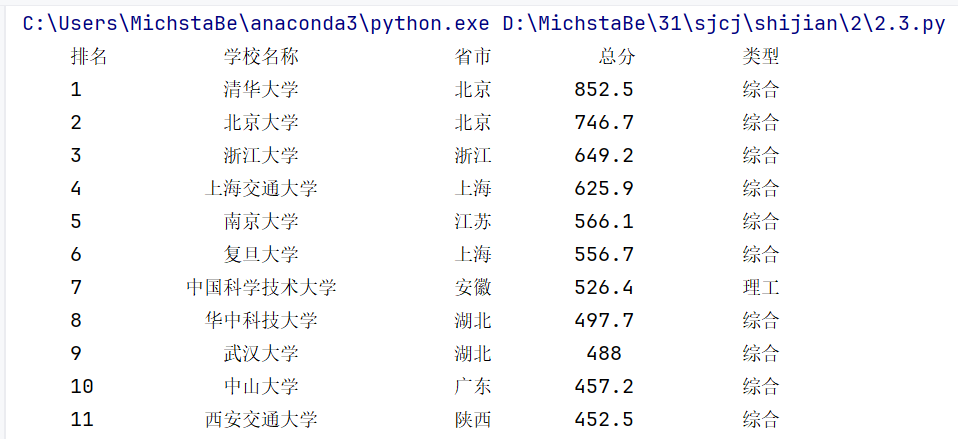
图片展示
打印结果
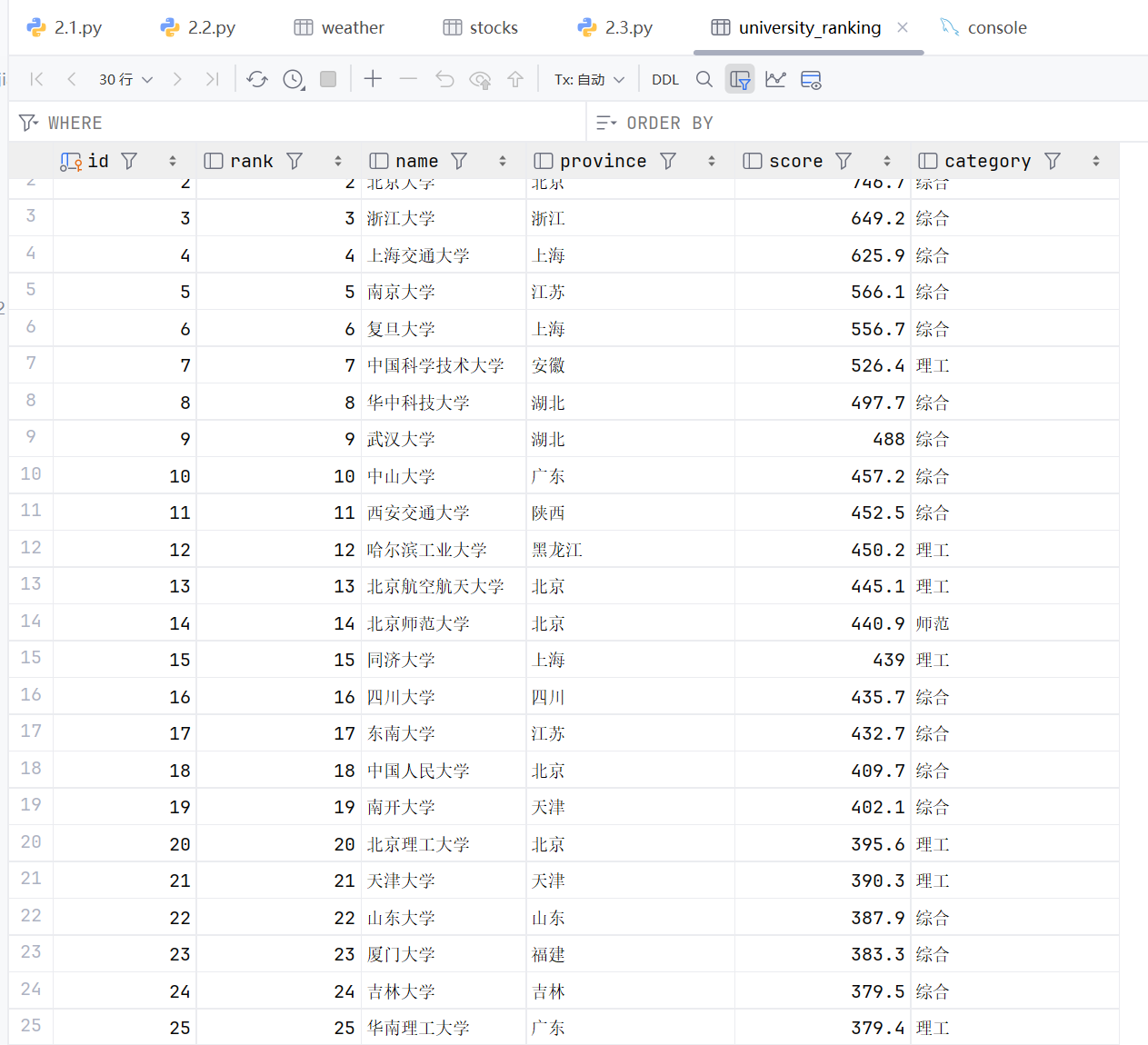
数据库结果
2. 作业心得
通过爬取中国大学的排名信息,我对数据的结构化处理有了更深入的理解。整个过程让我认识到数据获取和整理的重要性,并掌握了如何有效地将这些数据存储到数据库中。记录调试过程也让我对每一步的操作有了直观的了解,这为我后续的学习奠定了良好的基础。